 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
K-Planes: Explicit Radiance Fields in Space, Time, and Appearance
Jan 24, 2023

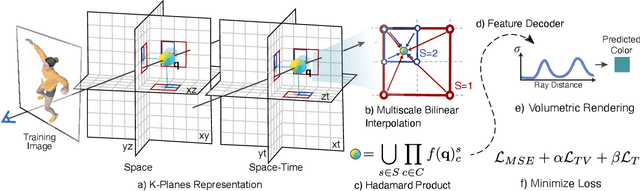

We introduce k-planes, a white-box model for radiance fields in arbitrary dimensions. Our model uses d choose 2 planes to represent a d-dimensional scene, providing a seamless way to go from static (d=3) to dynamic (d=4) scenes. This planar factorization makes adding dimension-specific priors easy, e.g. temporal smoothness and multi-resolution spatial structure, and induces a natural decomposition of static and dynamic components of a scene. We use a linear feature decoder with a learned color basis that yields similar performance as a nonlinear black-box MLP decoder. Across a range of synthetic and real, static and dynamic, fixed and varying appearance scenes, k-planes yields competitive and often state-of-the-art reconstruction fidelity with low memory usage, achieving 1000x compression over a full 4D grid, and fast optimization with a pure PyTorch implementation. For video results and code, please see sarafridov.github.io/K-Planes.
Real-time Trajectory Optimization and Control for Ball Bumping with Quadruped Robots
Oct 11, 2022
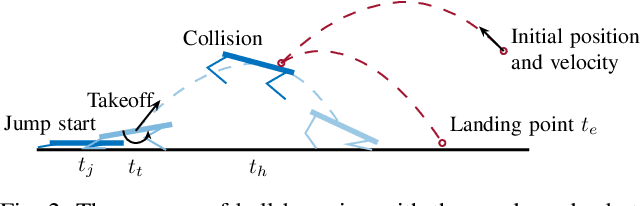

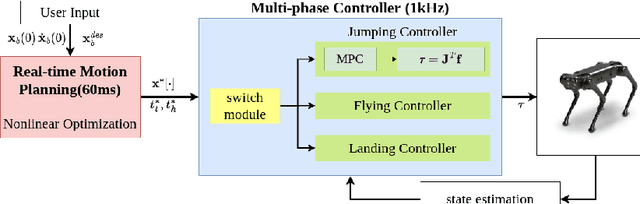
This paper studies real-time motion planning and control for ball bumping motion with quadruped robots. To enable the quadruped to bump the flying ball with different initializations, we develop a nonlinear trajectory optimization-based planning scheme that jointly identifies the take-off time and state to achieve accurate ball hitting during the flight phase. Such a planning scheme employs a two-dimensional single rigid body model that achieves a satisfactory balance between accuracy and efficiency for the highly time-sensitive task. To precisely execute the planned motion, the tracking controller needs to incorporate the strict time-state constraint imposed on the take-off and ball-hitting events. To this end, we develop an improved model predictive controller that respects the critical time-state constraints. The proposed planning and control framework is validated with a real Aliengo robot. Experiments show that the problem planning approach can be computed in approximately 60ms on average, enabling successful accomplishment of the ball bumping motion with various initializations in real time.
Decorate the Newcomers: Visual Domain Prompt for Continual Test Time Adaptation
Dec 08, 2022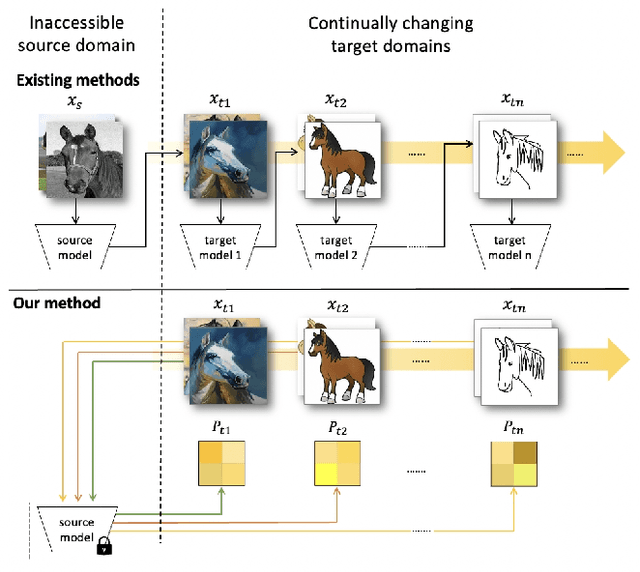

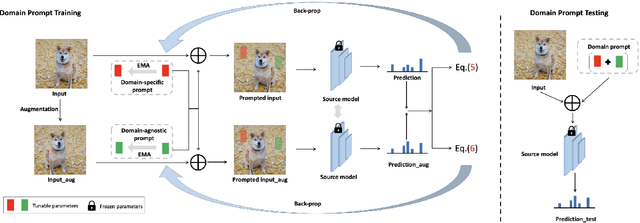

Continual Test-Time Adaptation (CTTA) aims to adapt the source model to continually changing unlabeled target domains without access to the source data. Existing methods mainly focus on model-based adaptation in a self-training manner, such as predicting pseudo labels for new domain datasets. Since pseudo labels are noisy and unreliable, these methods suffer from catastrophic forgetting and error accumulation when dealing with dynamic data distributions. Motivated by the prompt learning in NLP, in this paper, we propose to learn an image-level visual domain prompt for target domains while having the source model parameters frozen. During testing, the changing target datasets can be adapted to the source model by reformulating the input data with the learned visual prompts. Specifically, we devise two types of prompts, i.e., domains-specific prompts and domains-agnostic prompts, to extract current domain knowledge and maintain the domain-shared knowledge in the continual adaptation. Furthermore, we design a homeostasis-based prompt adaptation strategy to suppress domain-sensitive parameters in domain-invariant prompts to learn domain-shared knowledge more effectively. This transition from the model-dependent paradigm to the model-free one enables us to bypass the catastrophic forgetting and error accumulation problems. Experiments show that our proposed method achieves significant performance gains over state-of-the-art methods on four widely-used benchmarks, including CIFAR-10C, CIFAR-100C, ImageNet-C, and VLCS datasets.
Robot Navigation in Risky, Crowded Environments: Understanding Human Preferences
Mar 15, 2023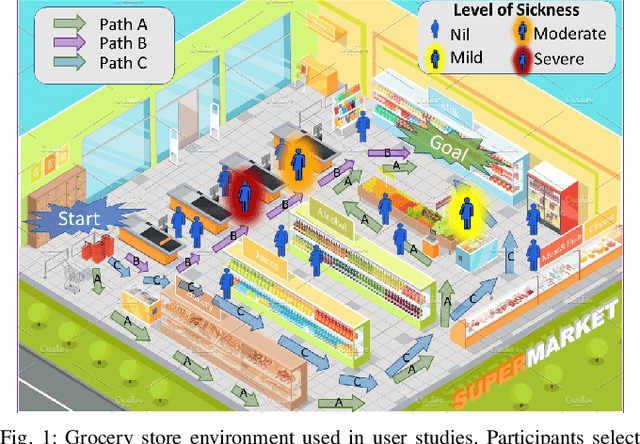
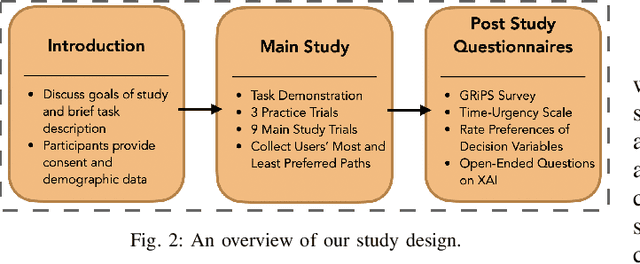
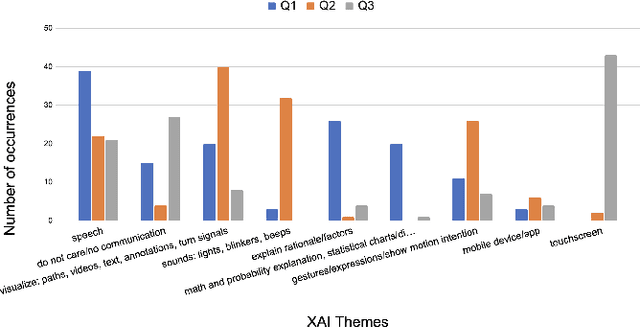
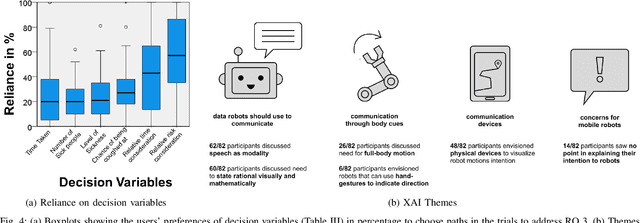
Risky and crowded environments (RCE) contain abstract sources of risk and uncertainty, which are perceived differently by humans, leading to a variety of behaviors. Thus, robots deployed in RCEs, need to exhibit diverse perception and planning capabilities in order to interpret other human agents' behavior and act accordingly in such environments. To understand this problem domain, we conducted a study to explore human path choices in RCEs, enabling better robotic navigational explainable AI (XAI) designs. We created a novel COVID-19 pandemic grocery shopping scenario which had time-risk tradeoffs, and acquired users' path preferences. We found that participants showcase a variety of path preferences: from risky and urgent to safe and relaxed. To model users' decision making, we evaluated three popular risk models (Cumulative Prospect Theory (CPT), Conditional Value at Risk (CVAR), and Expected Risk (ER). We found that CPT captured people's decision making more accurately than CVaR and ER, corroborating theoretical results that CPT is more expressive and inclusive than CVaR and ER. We also found that people's self assessments of risk and time-urgency do not correlate with their path preferences in RCEs. Finally, we conducted thematic analysis of open-ended questions, providing crucial design insights for robots is RCE. Thus, through this study, we provide novel and critical insights about human behavior and perception to help design better navigational explainable AI (XAI) in RCEs.
Digital Twins for Trust Building in Autonomous Drones through Dynamic Safety Evaluation
Mar 15, 2023The adoption process of innovative software-intensive technologies leverages complex trust concerns in different forms and shapes. Perceived safety plays a fundamental role in technology adoption, being especially crucial in the case of those innovative software-driven technologies characterized by a high degree of dynamism and unpredictability, like collaborating autonomous systems. These systems need to synchronize their maneuvers in order to collaboratively engage in reactions to unpredictable incoming hazardous situations. That is however only possible in the presence of mutual trust. In this paper, we propose an approach for machine-to-machine dynamic trust assessment for collaborating autonomous systems that supports trust-building based on the concept of dynamic safety assurance within the collaborative process among the software-intensive autonomous systems. In our approach, we leverage the concept of digital twins which are abstract models fed with real-time data used in the run-time dynamic exchange of information. The information exchange is performed through the execution of specialized models that embed the necessary safety properties. More particularly, we examine the possible role of the Digital Twins in machine-to-machine trust building and present their design in supporting dynamic trust assessment of autonomous drones. Ultimately, we present a proof of concept of direct and indirect trust assessment by employing the Digital Twin in a use case involving two autonomous collaborating drones.
Panoptic Mapping with Fruit Completion and Pose Estimation for Horticultural Robots
Mar 15, 2023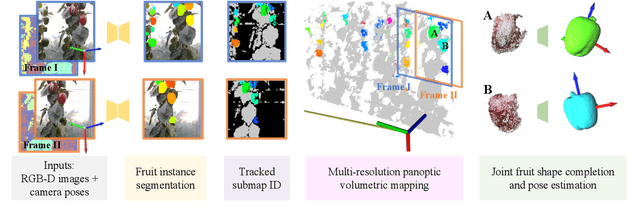

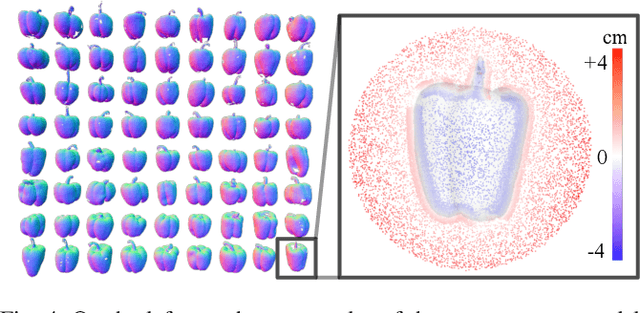
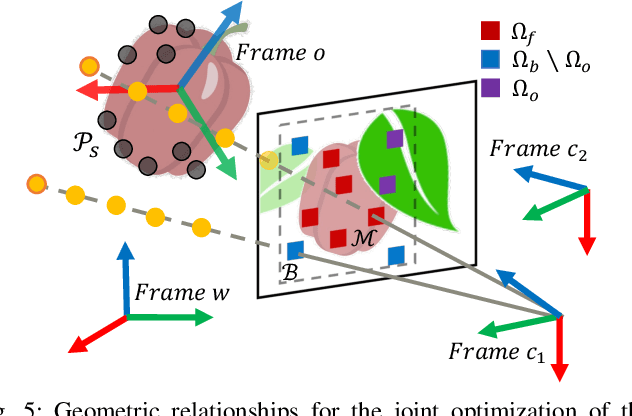
Monitoring plants and fruits at high resolution play a key role in the future of agriculture. Accurate 3D information can pave the way to a diverse number of robotic applications in agriculture ranging from autonomous harvesting to precise yield estimation. Obtaining such 3D information is non-trivial as agricultural environments are often repetitive and cluttered, and one has to account for the partial observability of fruit and plants. In this paper, we address the problem of jointly estimating complete 3D shapes of fruit and their pose in a 3D multi-resolution map built by a mobile robot. To this end, we propose an online multi-resolution panoptic mapping system where regions of interest are represented with a higher resolution. We exploit data to learn a general fruit shape representation that we use at inference time together with an occlusion-aware differentiable rendering pipeline to complete partial fruit observations and estimate the 7 DoF pose of each fruit in the map. The experiments presented in this paper, evaluated both in the controlled environment and in a commercial greenhouse, show that our novel algorithm yields higher completion and pose estimation accuracy than existing methods, with an improvement of 41% in completion accuracy and 52% in pose estimation accuracy while keeping a low inference time of 0.6s in average.
Large-scale End-of-Life Prediction of Hard Disks in Distributed Datacenters
Mar 20, 2023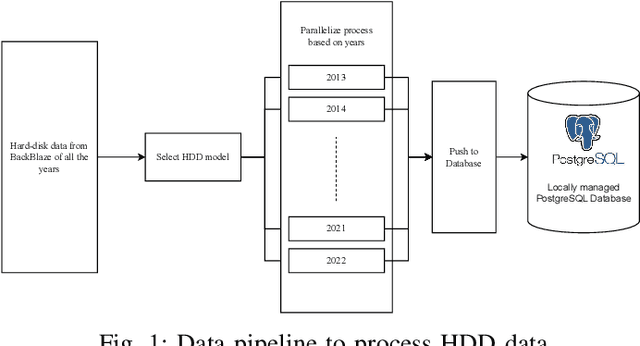
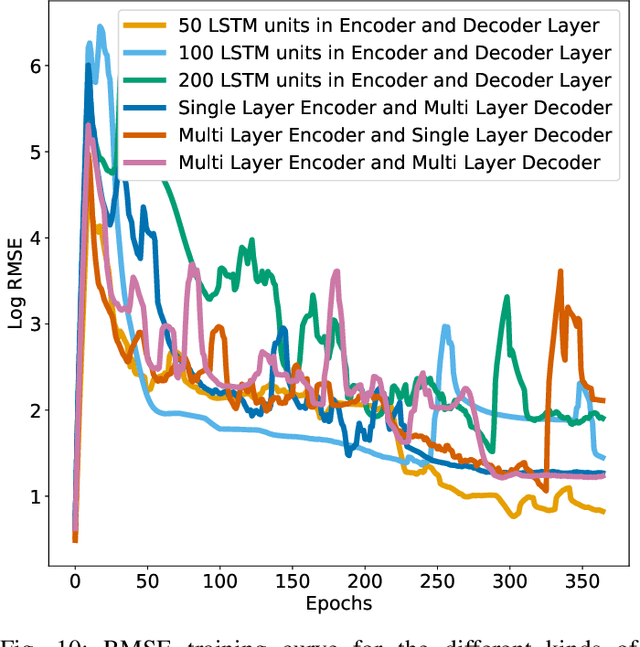
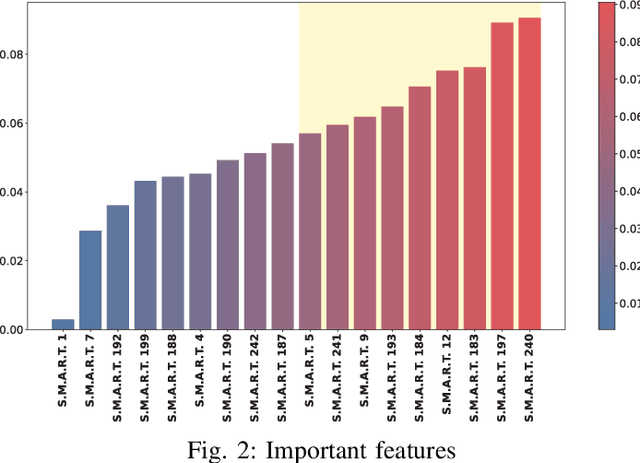
On a daily basis, data centers process huge volumes of data backed by the proliferation of inexpensive hard disks. Data stored in these disks serve a range of critical functional needs from financial, and healthcare to aerospace. As such, premature disk failure and consequent loss of data can be catastrophic. To mitigate the risk of failures, cloud storage providers perform condition-based monitoring and replace hard disks before they fail. By estimating the remaining useful life of hard disk drives, one can predict the time-to-failure of a particular device and replace it at the right time, ensuring maximum utilization whilst reducing operational costs. In this work, large-scale predictive analyses are performed using severely skewed health statistics data by incorporating customized feature engineering and a suite of sequence learners. Past work suggests using LSTMs as an excellent approach to predicting remaining useful life. To this end, we present an encoder-decoder LSTM model where the context gained from understanding health statistics sequences aid in predicting an output sequence of the number of days remaining before a disk potentially fails. The models developed in this work are trained and tested across an exhaustive set of all of the 10 years of S.M.A.R.T. health data in circulation from Backblaze and on a wide variety of disk instances. It closes the knowledge gap on what full-scale training achieves on thousands of devices and advances the state-of-the-art by providing tangible metrics for evaluation and generalization for practitioners looking to extend their workflow to all years of health data in circulation across disk manufacturers. The encoder-decoder LSTM posted an RMSE of 0.83 during training and 0.86 during testing over the exhaustive 10 year data while being able to generalize competitively over other drives from the Seagate family.
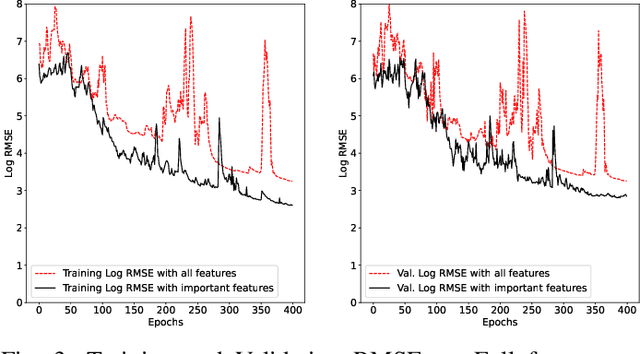
CoGANPPIS: Coevolution-enhanced Global Attention Neural Network for Protein-Protein Interaction Site Prediction
Apr 03, 2023
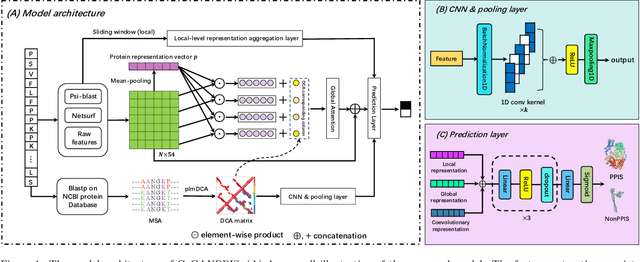
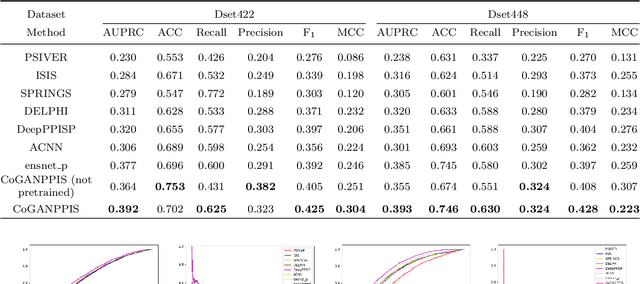
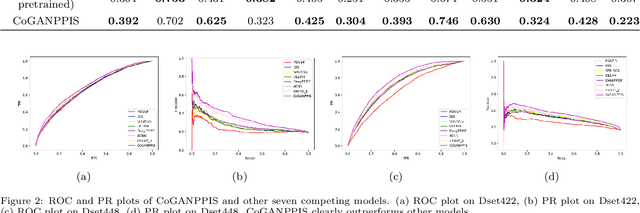
Protein-protein interactions are essential in biochemical processes. Accurate prediction of the protein-protein interaction sites (PPIs) deepens our understanding of biological mechanism and is crucial for new drug design. However, conventional experimental methods for PPIs prediction are costly and time-consuming so that many computational approaches, especially ML-based methods, have been developed recently. Although these approaches have achieved gratifying results, there are still two limitations: (1) Most models have excavated some useful input features, but failed to take coevolutionary features into account, which could provide clues for inter-residue relationships; (2) The attention-based models only allocate attention weights for neighboring residues, instead of doing it globally, neglecting that some residues being far away from the target residues might also matter. We propose a coevolution-enhanced global attention neural network, a sequence-based deep learning model for PPIs prediction, called CoGANPPIS. It utilizes three layers in parallel for feature extraction: (1) Local-level representation aggregation layer, which aggregates the neighboring residues' features; (2) Global-level representation learning layer, which employs a novel coevolution-enhanced global attention mechanism to allocate attention weights to all the residues on the same protein sequences; (3) Coevolutionary information learning layer, which applies CNN & pooling to coevolutionary information to obtain the coevolutionary profile representation. Then, the three outputs are concatenated and passed into several fully connected layers for the final prediction. Application on two benchmark datasets demonstrated a state-of-the-art performance of our model. The source code is publicly available at https://github.com/Slam1423/CoGANPPIS_source_code.
Dsfer-Net: A Deep Supervision and Feature Retrieval Network for Bitemporal Change Detection Using Modern Hopfield Networks
Apr 03, 2023

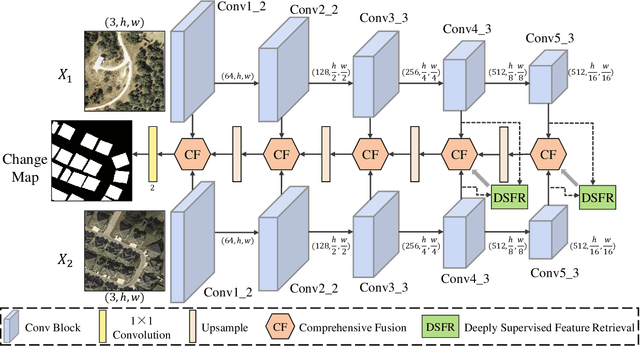
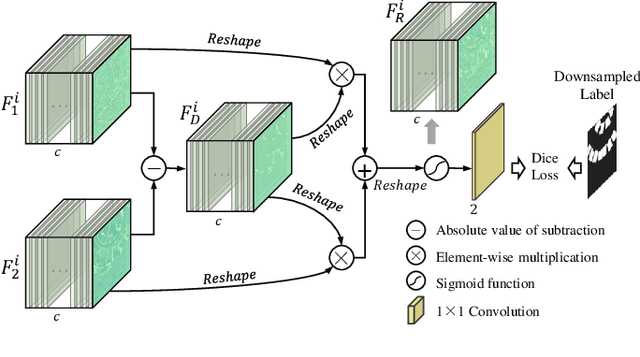
Change detection, as an important application for high-resolution remote sensing images, aims to monitor and analyze changes in the land surface over time. With the rapid growth in the quantity of high-resolution remote sensing data and the complexity of texture features, a number of quantitative deep learning-based methods have been proposed. Although these methods outperform traditional change detection methods by extracting deep features and combining spatial-temporal information, reasonable explanations about how deep features work on improving the detection performance are still lacking. In our investigations, we find that modern Hopfield network layers achieve considerable performance in semantic understandings. In this paper, we propose a Deep Supervision and FEature Retrieval network (Dsfer-Net) for bitemporal change detection. Specifically, the highly representative deep features of bitemporal images are jointly extracted through a fully convolutional Siamese network. Based on the sequential geo-information of the bitemporal images, we then design a feature retrieval module to retrieve the difference feature and leverage discriminative information in a deeply supervised manner. We also note that the deeply supervised feature retrieval module gives explainable proofs about the semantic understandings of the proposed network in its deep layers. Finally, this end-to-end network achieves a novel framework by aggregating the retrieved features and feature pairs from different layers. Experiments conducted on three public datasets (LEVIR-CD, WHU-CD, and CDD) confirm the superiority of the proposed Dsfer-Net over other state-of-the-art methods. Code will be available online (https://github.com/ShizhenChang/Dsfer-Net).
Among Us: Adversarially Robust Collaborative Perception by Consensus
Mar 27, 2023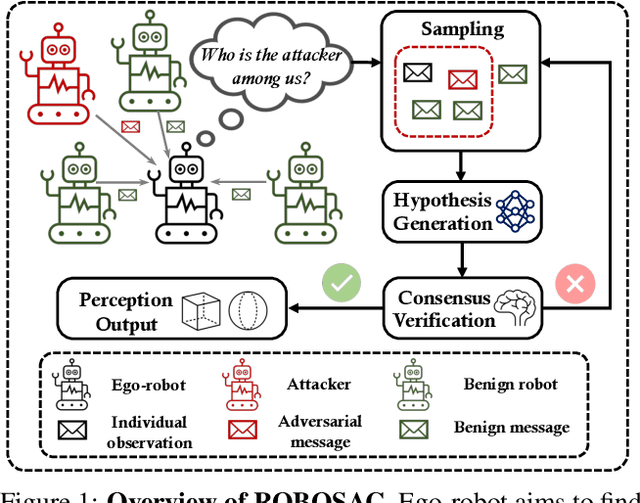

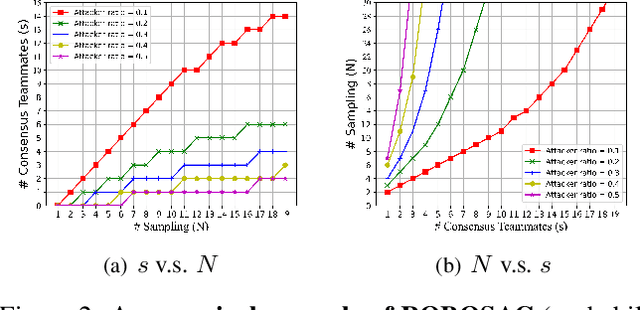

Multiple robots could perceive a scene (e.g., detect objects) collaboratively better than individuals, although easily suffer from adversarial attacks when using deep learning. This could be addressed by the adversarial defense, but its training requires the often-unknown attacking mechanism. Differently, we propose ROBOSAC, a novel sampling-based defense strategy generalizable to unseen attackers. Our key idea is that collaborative perception should lead to consensus rather than dissensus in results compared to individual perception. This leads to our hypothesize-and-verify framework: perception results with and without collaboration from a random subset of teammates are compared until reaching a consensus. In such a framework, more teammates in the sampled subset often entail better perception performance but require longer sampling time to reject potential attackers. Thus, we derive how many sampling trials are needed to ensure the desired size of an attacker-free subset, or equivalently, the maximum size of such a subset that we can successfully sample within a given number of trials. We validate our method on the task of collaborative 3D object detection in autonomous driving scenarios.