 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FP8 versus INT8 for efficient deep learning inference
Mar 31, 2023
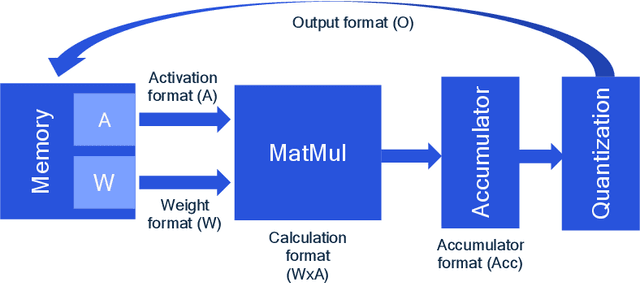
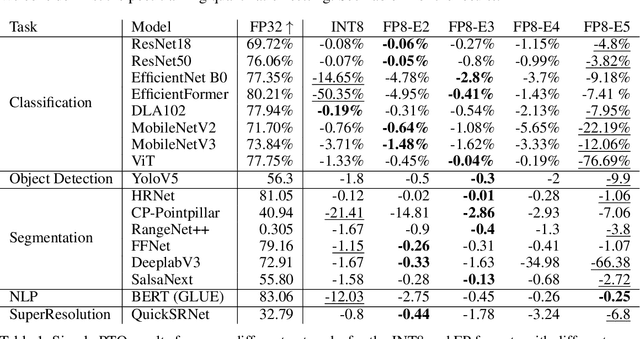
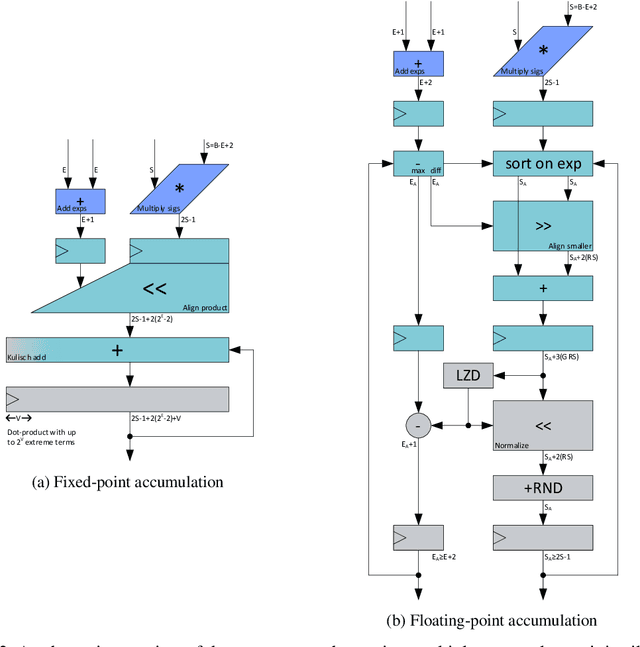
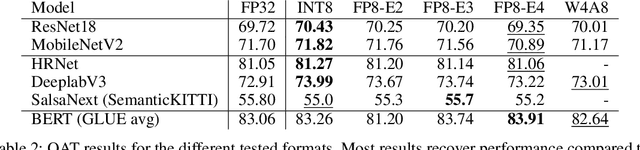
Recently, the idea of using FP8 as a number format for neural network training has been floating around the deep learning world. Given that most training is currently conducted with entire networks in FP32, or sometimes FP16 with mixed-precision, the step to having some parts of a network run in FP8 with 8-bit weights is an appealing potential speed-up for the generally costly and time-intensive training procedures in deep learning. A natural question arises regarding what this development means for efficient inference on edge devices. In the efficient inference device world, workloads are frequently executed in INT8. Sometimes going even as low as INT4 when efficiency calls for it. In this whitepaper, we compare the performance for both the FP8 and INT formats for efficient on-device inference. We theoretically show the difference between the INT and FP formats for neural networks and present a plethora of post-training quantization and quantization-aware-training results to show how this theory translates to practice. We also provide a hardware analysis showing that the FP formats are somewhere between 50-180% less efficient in terms of compute in dedicated hardware than the INT format. Based on our research and a read of the research field, we conclude that although the proposed FP8 format could be good for training, the results for inference do not warrant a dedicated implementation of FP8 in favor of INT8 for efficient inference. We show that our results are mostly consistent with previous findings but that important comparisons between the formats have thus far been lacking. Finally, we discuss what happens when FP8-trained networks are converted to INT8 and conclude with a brief discussion on the most efficient way for on-device deployment and an extensive suite of INT8 results for many models.
Non-separable Covariance Kernels for Spatiotemporal Gaussian Processes based on a Hybrid Spectral Method and the Harmonic Oscillator
Feb 19, 2023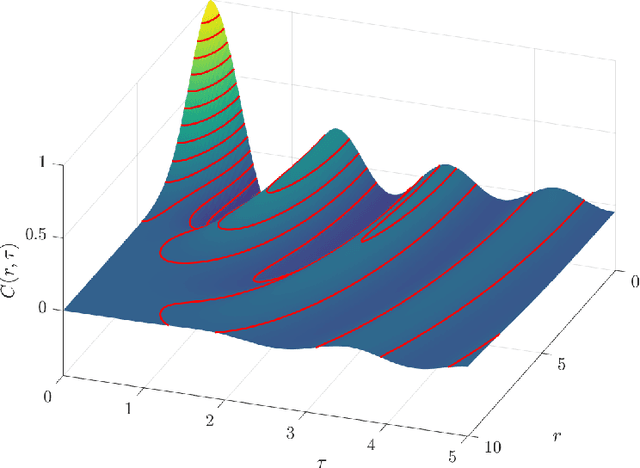
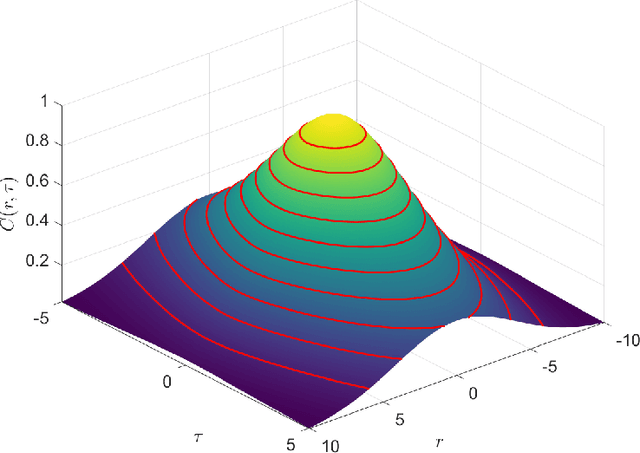
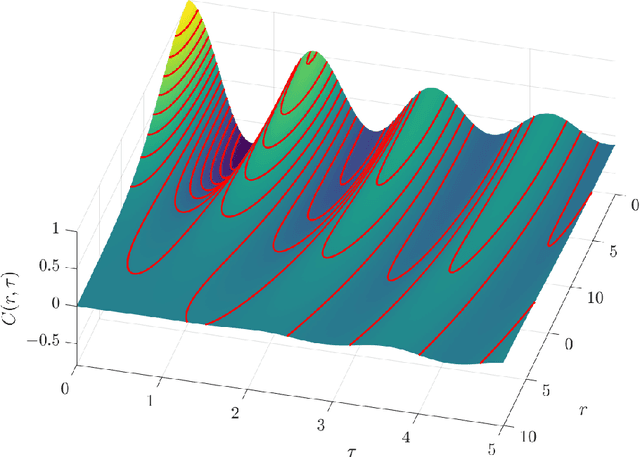
Gaussian processes provide a flexible, non-parametric framework for the approximation of functions in high-dimensional spaces. The covariance kernel is the main engine of Gaussian processes, incorporating correlations that underpin the predictive distribution. For applications with spatiotemporal datasets, suitable kernels should model joint spatial and temporal dependence. Separable space-time covariance kernels offer simplicity and computational efficiency. However, non-separable kernels include space-time interactions that better capture observed correlations. Most non-separable kernels that admit explicit expressions are based on mathematical considerations (admissibility conditions) rather than first-principles derivations. We present a hybrid spectral approach for generating covariance kernels which is based on physical arguments. We use this approach to derive a new class of physically motivated, non-separable covariance kernels which have their roots in the stochastic, linear, damped, harmonic oscillator (LDHO). The new kernels incorporate functions with both monotonic and oscillatory decay of space-time correlations. The LDHO covariance kernels involve space-time interactions which are introduced by dispersion relations that modulate the oscillator coefficients. We derive explicit relations for the spatiotemporal covariance kernels in the three oscillator regimes (underdamping, critical damping, overdamping) and investigate their properties.
A Universal Question-Answering Platform for Knowledge Graphs
Mar 01, 2023
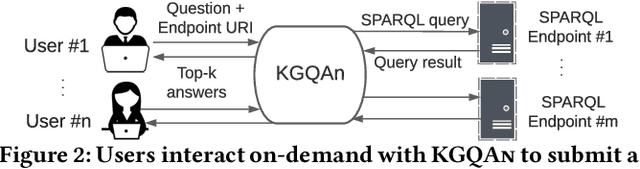

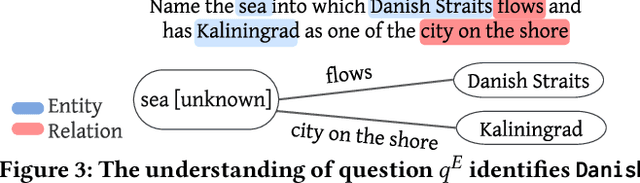
Knowledge from diverse application domains is organized as knowledge graphs (KGs) that are stored in RDF engines accessible in the web via SPARQL endpoints. Expressing a well-formed SPARQL query requires information about the graph structure and the exact URIs of its components, which is impractical for the average user. Question answering (QA) systems assist by translating natural language questions to SPARQL. Existing QA systems are typically based on application-specific human-curated rules, or require prior information, expensive pre-processing and model adaptation for each targeted KG. Therefore, they are hard to generalize to a broad set of applications and KGs. In this paper, we propose KGQAn, a universal QA system that does not need to be tailored to each target KG. Instead of curated rules, KGQAn introduces a novel formalization of question understanding as a text generation problem to convert a question into an intermediate abstract representation via a neural sequence-to-sequence model. We also develop a just-in-time linker that maps at query time the abstract representation to a SPARQL query for a specific KG, using only the publicly accessible APIs and the existing indices of the RDF store, without requiring any pre-processing. Our experiments with several real KGs demonstrate that KGQAn is easily deployed and outperforms by a large margin the state-of-the-art in terms of quality of answers and processing time, especially for arbitrary KGs, unseen during the training.
Non-contact, real-time eye blink detection with capacitive sensing
Nov 10, 2022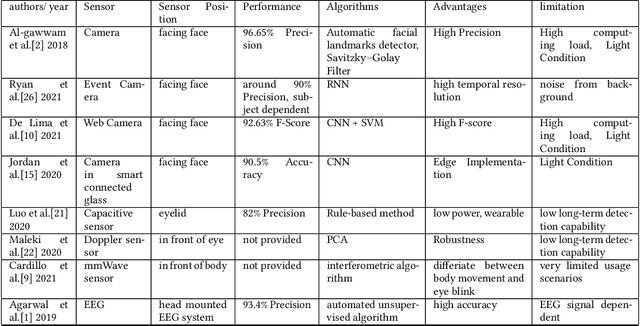

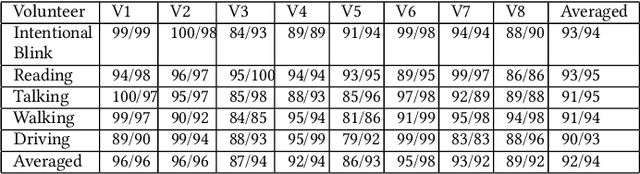
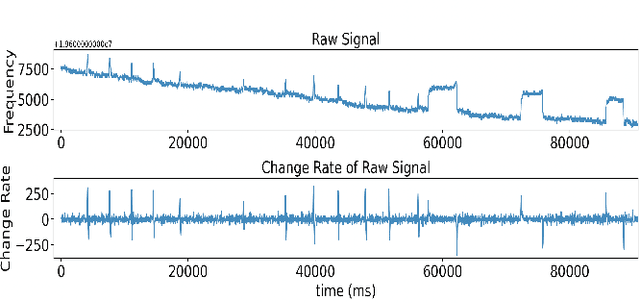
This work described a novel non-contact, wearable, real-time eye blink detection solution based on capacitive sensing technology. A low-cost and low-power consumption capacitive sensing prototype was developed and deployed on a pair of standard glasses with a copper electrode attached to the glass frame. The eye blink action will cause the capacitance variation between the electrode and the eyelid. Thus by monitoring the capacitance variation caused oscillating frequency shift signal, the eye blink can be abstracted by a simple comparison of the raw frequency signal with a customized threshold. The feasibility and robustness of the proposed solution were demonstrated in five scenarios performed by eight volunteers with an average precision of 92\% and recall of 94\%.
CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
Mar 02, 2023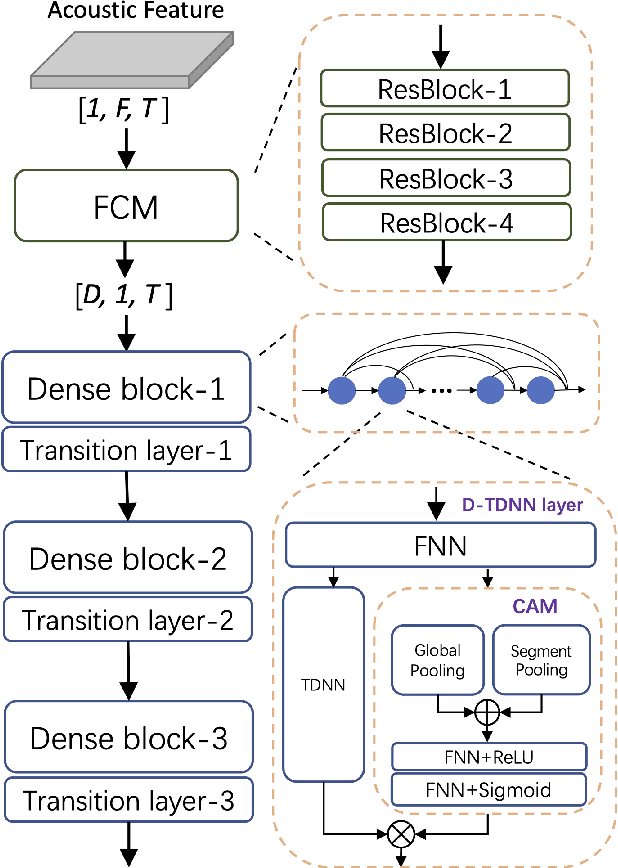
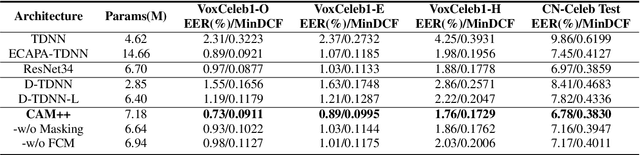
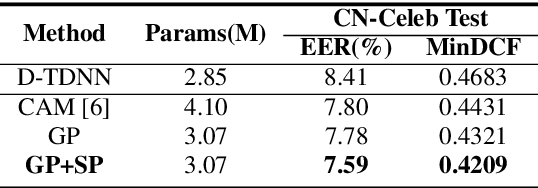

Time delay neural network (TDNN) has been proven to be efficient for speaker verification. One of its successful variants, ECAPA-TDNN, achieved state-of-the-art performance at the cost of much higher computational complexity and slower inference speed. This makes it inadequate for scenarios with demanding inference rate and limited computational resources. We are thus interested in finding an architecture that can achieve the performance of ECAPA-TDNN and the efficiency of vanilla TDNN. In this paper, we propose an efficient network based on context-aware masking, namely CAM++, which uses densely connected time delay neural network (D-TDNN) as backbone and adopts a novel multi-granularity pooling to capture contextual information at different levels. Extensive experiments on two public benchmarks, VoxCeleb and CN-Celeb, demonstrate that the proposed architecture outperforms other mainstream speaker verification systems with lower computational cost and faster inference speed.
Route to Time and Time to Route: Travel Time Estimation from Sparse Trajectories
Jun 21, 2022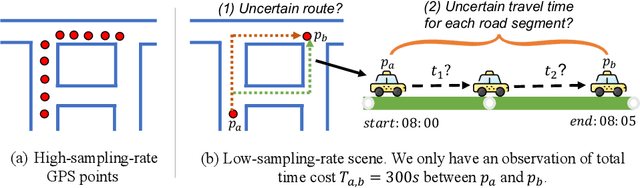
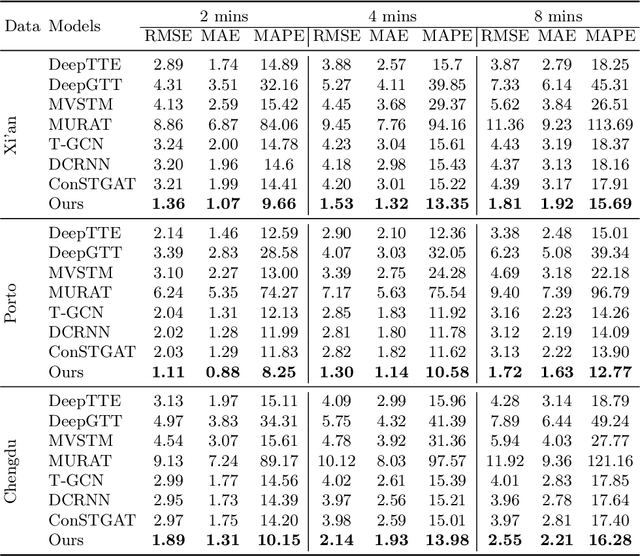
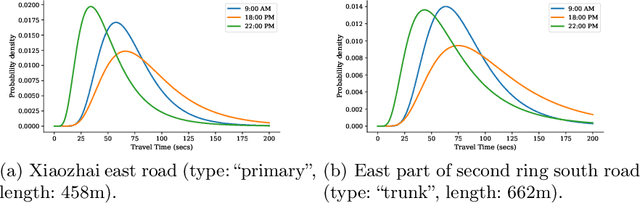
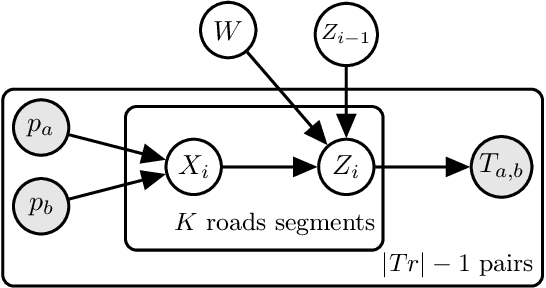
Due to the rapid development of Internet of Things (IoT) technologies, many online web apps (e.g., Google Map and Uber) estimate the travel time of trajectory data collected by mobile devices. However, in reality, complex factors, such as network communication and energy constraints, make multiple trajectories collected at a low sampling rate. In this case, this paper aims to resolve the problem of travel time estimation (TTE) and route recovery in sparse scenarios, which often leads to the uncertain label of travel time and route between continuously sampled GPS points. We formulate this problem as an inexact supervision problem in which the training data has coarsely grained labels and jointly solve the tasks of TTE and route recovery. And we argue that both two tasks are complementary to each other in the model-learning procedure and hold such a relation: more precise travel time can lead to better inference for routes, in turn, resulting in a more accurate time estimation). Based on this assumption, we propose an EM algorithm to alternatively estimate the travel time of inferred route through weak supervision in E step and retrieve the route based on estimated travel time in M step for sparse trajectories. We conducted experiments on three real-world trajectory datasets and demonstrated the effectiveness of the proposed method.
AutoOptLib: A Library of Automatically Designing Metaheuristic Optimization Algorithms in MATLAB
Mar 12, 2023
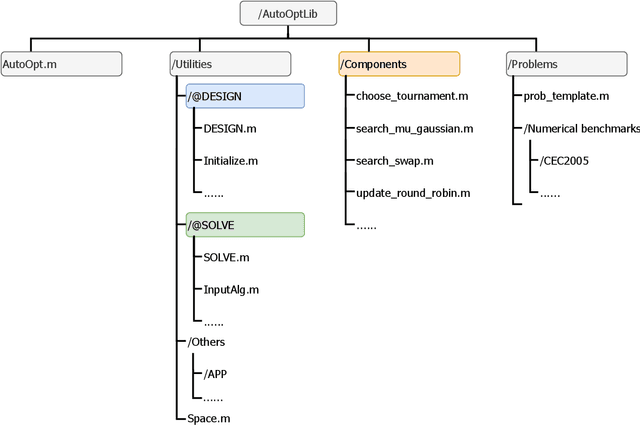

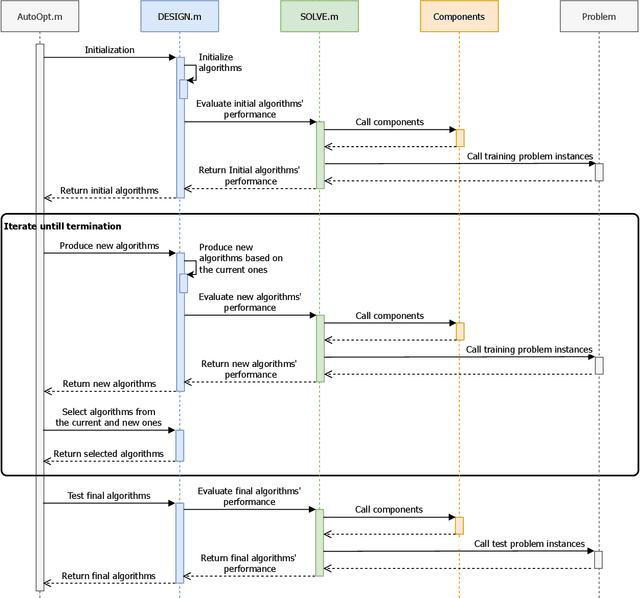
Metaheuristic algorithms are widely-recognized solvers for challenging optimization problems with multi-modality, discretization, large-scale, multi-objectivity, etc. Automatically designing metaheuristic algorithms leverages today's increasing computing resources to conceive, build up, and verify the design choices of algorithms. It requires much less expertise, labor resources, and time cost than the traditional manual design. Furthermore, by fully exploring the design choices with computing power, automated design is potential to reach or even surpass human-level design, subsequently gaining enhanced performance compared with human problem-solving. These significant advantages have attracted increasing interest and development in the automated design techniques. Open source software is indispensable in response to the increasing interest and development of the techniques. To this end, we have developed a MATLAB library, AutoOptLib, to automatically design metaheuristic algorithms. AutoOptLib, for the first time, provides throughout support to the whole design process, including: 1) plenty of algorithmic components for continuous, discrete, and permutation problems, 2) flexible algorithm representation for evolving diverse algorithm structures, 3) various design objectives and design techniques for different experimentation and application scenarios, and 4) useful experimental tools and graphic user interface (GUI) for practicability and accessibility. In this paper, we first introduce the key features and architecture of the AutoOptLib library. We then illustrate how to use the library by either command or GUI. We further describe additional uses and experimental tools, including parameter importance analysis and benchmark comparison. Finally, we present academic and piratical applications of AutoOptLib, which verifies its efficiency and practicability.
An Efficient Two-stage Gradient Boosting Framework for Short-term Traffic State Estimation
Feb 21, 2023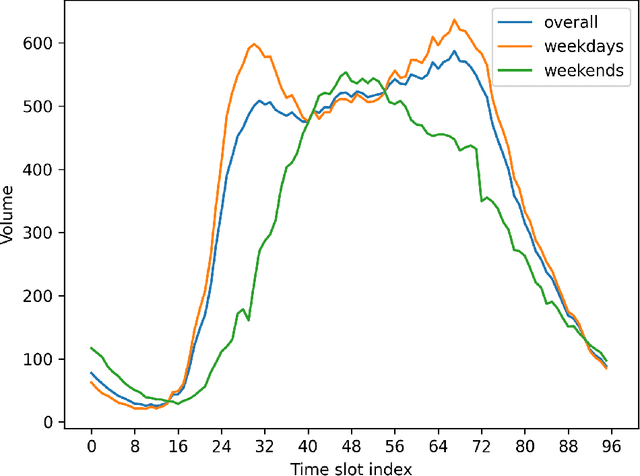

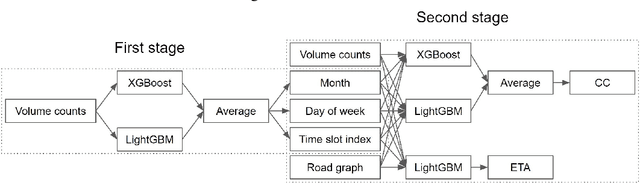

Real-time traffic state estimation is essential for intelligent transportation systems. The NeurIPS 2022 Traffic4cast challenge provides an excellent testbed for benchmarking short-term traffic state estimation approaches. This technical report describes our solution to this challenge. In particular, we present an efficient two-stage gradient boosting framework for short-term traffic state estimation. The first stage derives the month, day of the week, and time slot index based on the sparse loop counter data, and the second stage predicts the future traffic states based on the sparse loop counter data and the derived month, day of the week, and time slot index. Experimental results demonstrate that our two-stage gradient boosting framework achieves strong empirical performance, achieving third place in both the core and the extended challenges while remaining highly efficient. The source code for this technical report is available at \url{https://github.com/YichaoLu/Traffic4cast2022}.
Renaissance canons with asymmetric schemes
Feb 27, 2023



By a "scheme" of a musical canon, we mean the order of voice entry with the time and pitch displacement of each entering voice. When the time displacements are unequal, achieving consonant sonorities is especially challenging. Using a first-species theoretical model, we quantify the flexibility of schemes that Renaissance composers used or could have used. We craft an algorithm to compute the flexibility value precisely (finding in the process that it is an $h$-th root of a Pisot number). We find that Palestrina consistently selected some of the most flexible schemes, more so than his predecessors, but that he by no means exhausted the feasible schemes. We close by presenting a new composition within the limits of the style utilizing an unexplored canonic scheme.
Transitions between quasi-stationary states in traffic systems: Cologne orbital motorways as an example
Feb 28, 2023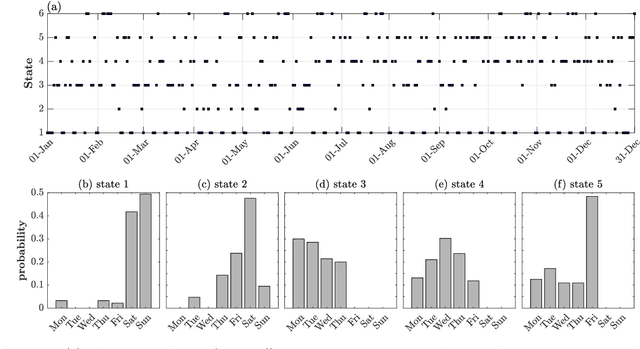
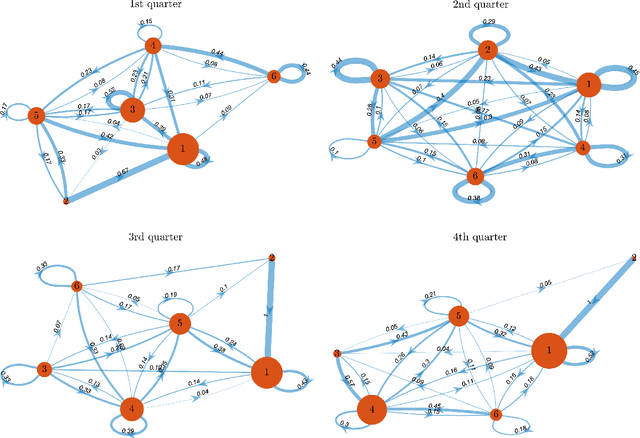
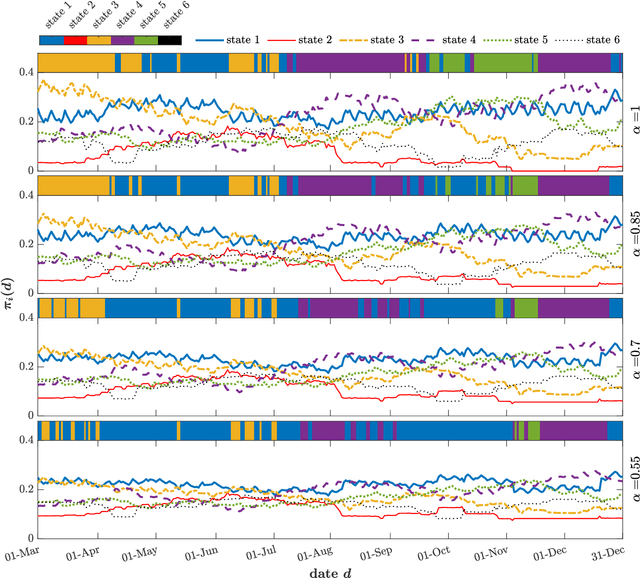
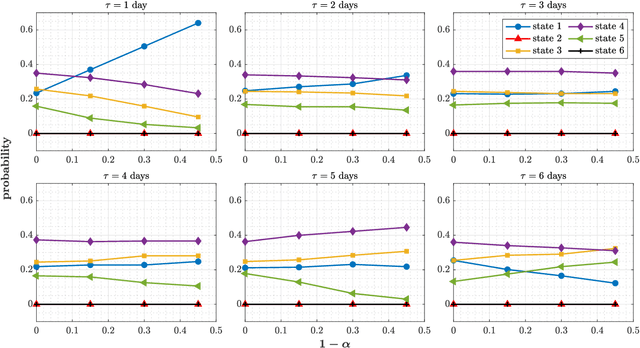
Traffic systems can operate in different modes. In a previous work, we identified these modes as different quasi-stationary states in the correlation structure. Here, we analyze the transitions between such quasi-stationary states, i.e., how the system changes its operational mode. In the longer run this might be helpful to forecast the time evolution of correlation patterns in traffic. We take Cologne orbital motorways as an example, we construct a state transition network for each quarter of 2015 and find a seasonal dependence for those quasi-stationary states in the traffic system. Using the PageRank algorithm, we identify and explore the dominant states which occur frequently within a moving time window of 60 days in 2015. To the best of our knowledge, this is the first study of this type for traffic systems.