 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Momentum Multi-Marginal Schrödinger Bridge
Mar 03, 2023

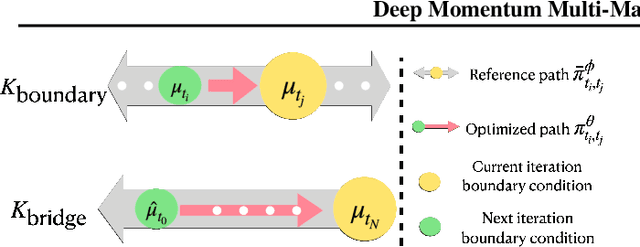

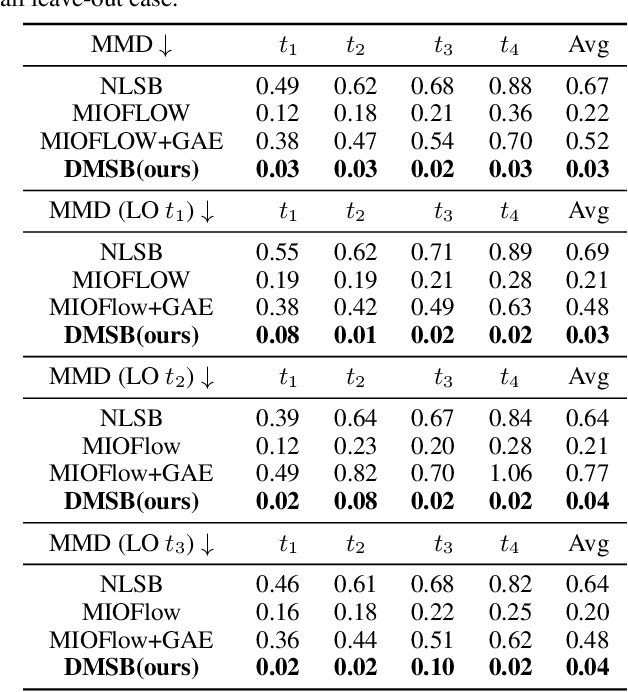
Reconstructing population dynamics using only samples from distributions at coarse time intervals is a crucial challenge. Recent data-driven approaches such as flow-based models or Schr\"odinger Bridge models have demonstrated appealing performance, yet the inferred sample trajectories either fail to account for the underlying stochasticity or are unnecessarily rigid. In this article, we propose $\underline{D}$eep $\underline{M}$omentum Multi-Marginal $\underline{S}$chr\"odinger $\underline{B}$ridge(DMSB), a novel computational framework that learns the smooth measure-valued spline for stochastic systems without violating the position marginal constraints across time. We first extend the scalable mean matching objective used in the state space SB algorithm into the phase space. We next carefully craft a multi-constraint optimization training method based on Bregman Iteration that enables effective phase space means matching training for the high-dimensional dataset. We demonstrate that the resulting training algorithm significantly outperforms baselines on both synthetic datasets and a real-world single-cell RNA sequence dataset.
Generalized Semantic Segmentation by Self-Supervised Source Domain Projection and Multi-Level Contrastive Learning
Mar 03, 2023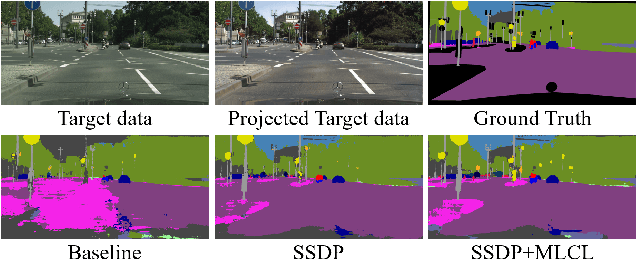
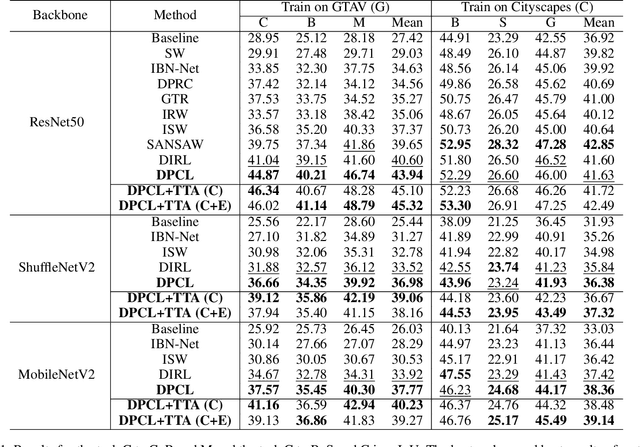
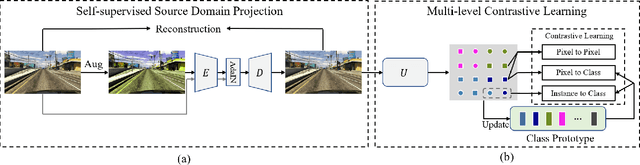
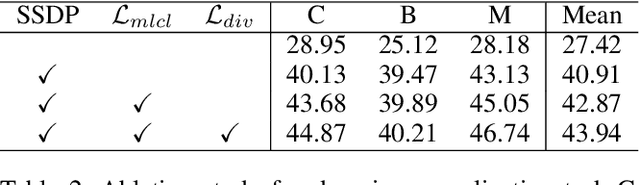
Deep networks trained on the source domain show degraded performance when tested on unseen target domain data. To enhance the model's generalization ability, most existing domain generalization methods learn domain invariant features by suppressing domain sensitive features. Different from them, we propose a Domain Projection and Contrastive Learning (DPCL) approach for generalized semantic segmentation, which includes two modules: Self-supervised Source Domain Projection (SSDP) and Multi-level Contrastive Learning (MLCL). SSDP aims to reduce domain gap by projecting data to the source domain, while MLCL is a learning scheme to learn discriminative and generalizable features on the projected data. During test time, we first project the target data by SSDP to mitigate domain shift, then generate the segmentation results by the learned segmentation network based on MLCL. At test time, we can update the projected data by minimizing our proposed pixel-to-pixel contrastive loss to obtain better results. Extensive experiments for semantic segmentation demonstrate the favorable generalization capability of our method on benchmark datasets.
RAFEN -- Regularized Alignment Framework for Embeddings of Nodes
Mar 03, 2023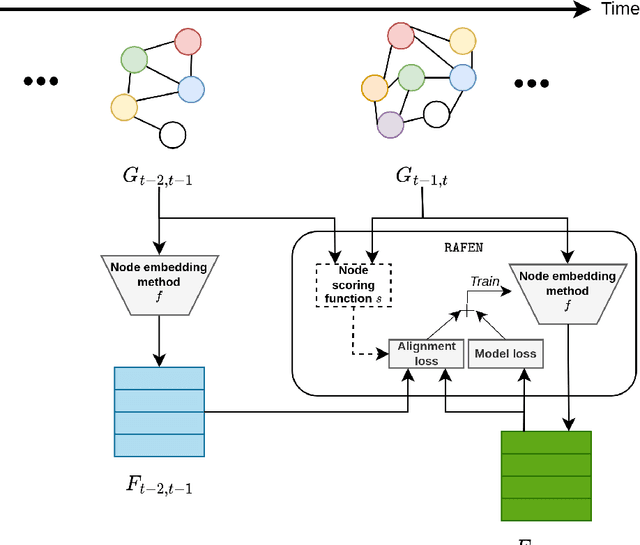
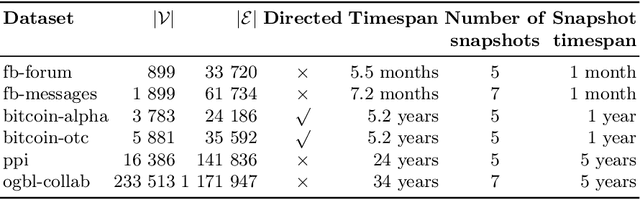
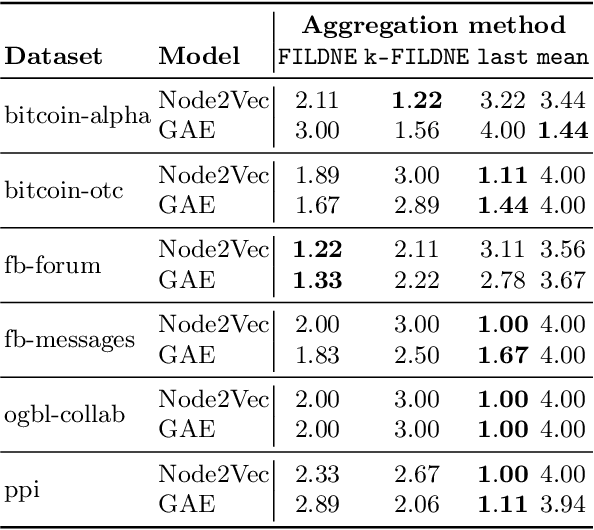
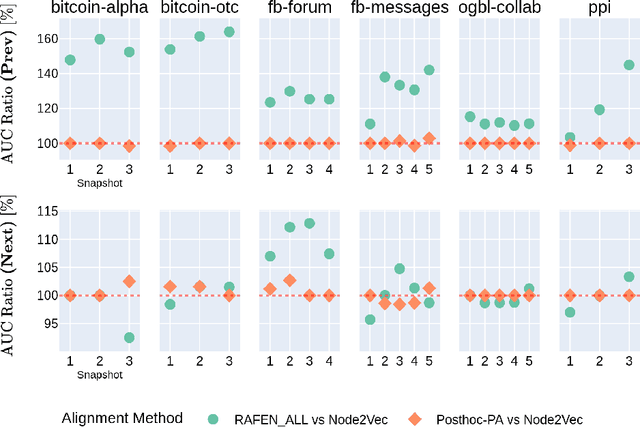
Learning representations of nodes has been a crucial area of the graph machine learning research area. A well-defined node embedding model should reflect both node features and the graph structure in the final embedding. In the case of dynamic graphs, this problem becomes even more complex as both features and structure may change over time. The embeddings of particular nodes should remain comparable during the evolution of the graph, what can be achieved by applying an alignment procedure. This step was often applied in existing works after the node embedding was already computed. In this paper, we introduce a framework -- RAFEN -- that allows to enrich any existing node embedding method using the aforementioned alignment term and learning aligned node embedding during training time. We propose several variants of our framework and demonstrate its performance on six real-world datasets. RAFEN achieves on-par or better performance than existing approaches without requiring additional processing steps.
Visual-Language Prompt Tuning with Knowledge-guided Context Optimization
Mar 23, 2023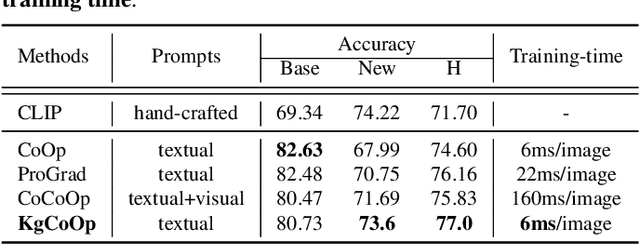
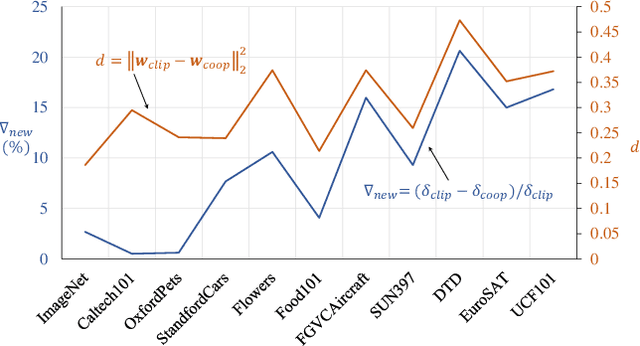
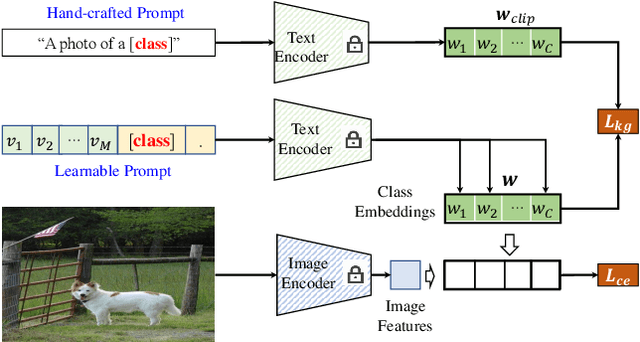
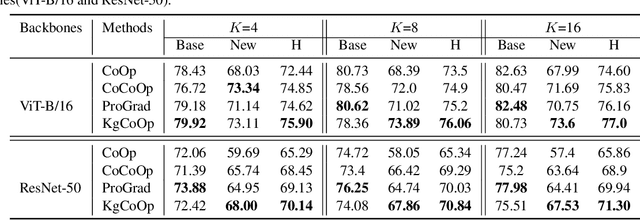
Prompt tuning is an effective way to adapt the pre-trained visual-language model (VLM) to the downstream task using task-related textual tokens. Representative CoOp-based work combines the learnable textual tokens with the class tokens to obtain specific textual knowledge. However, the specific textual knowledge is the worse generalization to the unseen classes because it forgets the essential general textual knowledge having a strong generalization ability. To tackle this issue, we introduce a novel Knowledge-guided Context Optimization (KgCoOp) to enhance the generalization ability of the learnable prompt for unseen classes. The key insight of KgCoOp is that forgetting about essential knowledge can be alleviated by reducing the discrepancy between the learnable prompt and the hand-crafted prompt. Especially, KgCoOp minimizes the discrepancy between the textual embeddings generated by learned prompts and the hand-crafted prompts. Finally, adding the KgCoOp upon the contrastive loss can make a discriminative prompt for both seen and unseen tasks. Extensive evaluation of several benchmarks demonstrates that the proposed Knowledge-guided Context Optimization is an efficient method for prompt tuning, \emph{i.e.,} achieves better performance with less training time.
Attention-based Speech Enhancement Using Human Quality Perception Modelling
Mar 23, 2023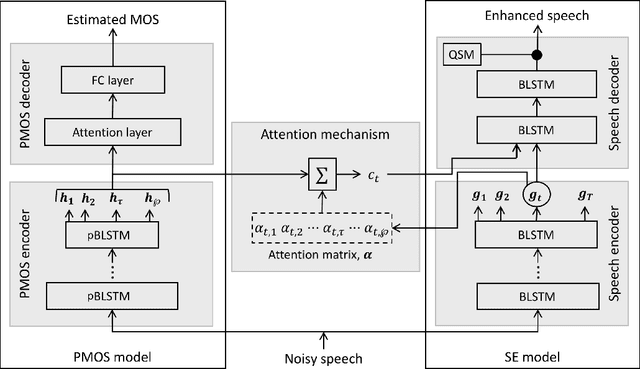
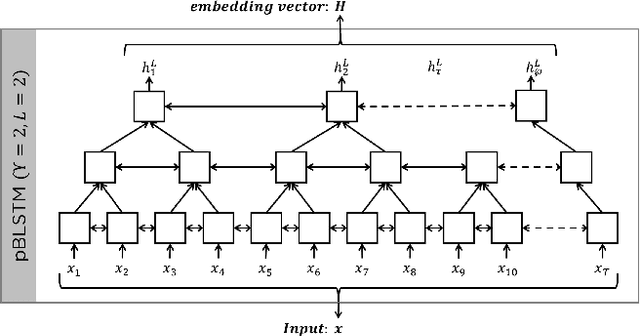
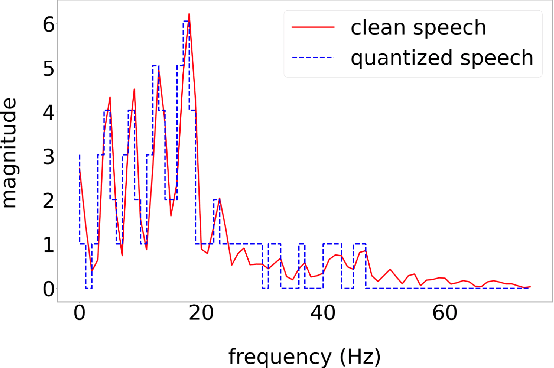
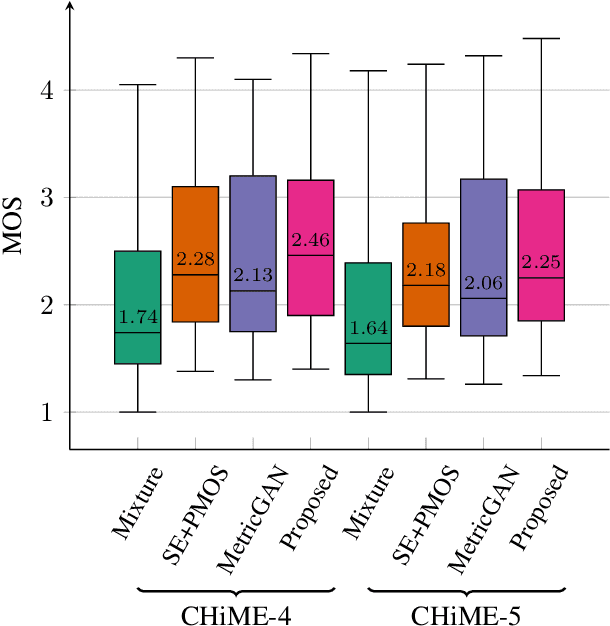
Perceptually-inspired objective functions such as the perceptual evaluation of speech quality (PESQ), signal-to-distortion ratio (SDR), and short-time objective intelligibility (STOI), have recently been used to optimize performance of deep-learning-based speech enhancement algorithms. These objective functions, however, do not always strongly correlate with a listener's assessment of perceptual quality, so optimizing with these measures often results in poorer performance in real-world scenarios. In this work, we propose an attention-based enhancement approach that uses learned speech embedding vectors from a mean-opinion score (MOS) prediction model and a speech enhancement module to jointly enhance noisy speech. The MOS prediction model estimates the perceptual MOS of speech quality, as assessed by human listeners, directly from the audio signal. The enhancement module also employs a quantized language model that enforces spectral constraints for better speech realism and performance. We train the model using real-world noisy speech data that has been captured in everyday environments and test it using unseen corpora. The results show that our proposed approach significantly outperforms other approaches that are optimized with objective measures, where the predicted quality scores strongly correlate with human judgments.
Artificial-intelligence-based molecular classification of diffuse gliomas using rapid, label-free optical imaging
Mar 23, 2023Molecular classification has transformed the management of brain tumors by enabling more accurate prognostication and personalized treatment. However, timely molecular diagnostic testing for patients with brain tumors is limited, complicating surgical and adjuvant treatment and obstructing clinical trial enrollment. In this study, we developed DeepGlioma, a rapid ($< 90$ seconds), artificial-intelligence-based diagnostic screening system to streamline the molecular diagnosis of diffuse gliomas. DeepGlioma is trained using a multimodal dataset that includes stimulated Raman histology (SRH); a rapid, label-free, non-consumptive, optical imaging method; and large-scale, public genomic data. In a prospective, multicenter, international testing cohort of patients with diffuse glioma ($n=153$) who underwent real-time SRH imaging, we demonstrate that DeepGlioma can predict the molecular alterations used by the World Health Organization to define the adult-type diffuse glioma taxonomy (IDH mutation, 1p19q co-deletion and ATRX mutation), achieving a mean molecular classification accuracy of $93.3\pm 1.6\%$. Our results represent how artificial intelligence and optical histology can be used to provide a rapid and scalable adjunct to wet lab methods for the molecular screening of patients with diffuse glioma.
Planning Goals for Exploration
Mar 23, 2023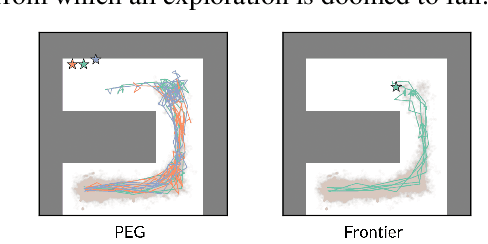
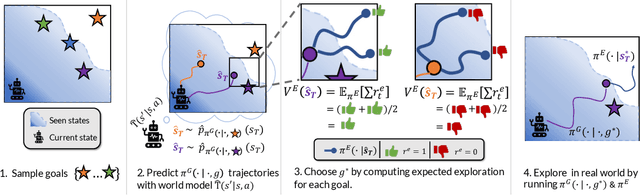


Dropped into an unknown environment, what should an agent do to quickly learn about the environment and how to accomplish diverse tasks within it? We address this question within the goal-conditioned reinforcement learning paradigm, by identifying how the agent should set its goals at training time to maximize exploration. We propose "Planning Exploratory Goals" (PEG), a method that sets goals for each training episode to directly optimize an intrinsic exploration reward. PEG first chooses goal commands such that the agent's goal-conditioned policy, at its current level of training, will end up in states with high exploration potential. It then launches an exploration policy starting at those promising states. To enable this direct optimization, PEG learns world models and adapts sampling-based planning algorithms to "plan goal commands". In challenging simulated robotics environments including a multi-legged ant robot in a maze, and a robot arm on a cluttered tabletop, PEG exploration enables more efficient and effective training of goal-conditioned policies relative to baselines and ablations. Our ant successfully navigates a long maze, and the robot arm successfully builds a stack of three blocks upon command. Website: https://penn-pal-lab.github.io/peg/
A Universal Question-Answering Platform for Knowledge Graphs
Mar 01, 2023
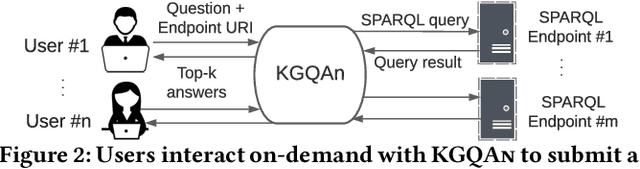

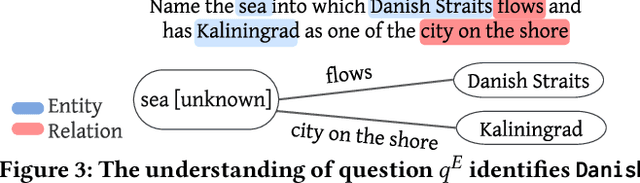
Knowledge from diverse application domains is organized as knowledge graphs (KGs) that are stored in RDF engines accessible in the web via SPARQL endpoints. Expressing a well-formed SPARQL query requires information about the graph structure and the exact URIs of its components, which is impractical for the average user. Question answering (QA) systems assist by translating natural language questions to SPARQL. Existing QA systems are typically based on application-specific human-curated rules, or require prior information, expensive pre-processing and model adaptation for each targeted KG. Therefore, they are hard to generalize to a broad set of applications and KGs. In this paper, we propose KGQAn, a universal QA system that does not need to be tailored to each target KG. Instead of curated rules, KGQAn introduces a novel formalization of question understanding as a text generation problem to convert a question into an intermediate abstract representation via a neural sequence-to-sequence model. We also develop a just-in-time linker that maps at query time the abstract representation to a SPARQL query for a specific KG, using only the publicly accessible APIs and the existing indices of the RDF store, without requiring any pre-processing. Our experiments with several real KGs demonstrate that KGQAn is easily deployed and outperforms by a large margin the state-of-the-art in terms of quality of answers and processing time, especially for arbitrary KGs, unseen during the training.
CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
Mar 02, 2023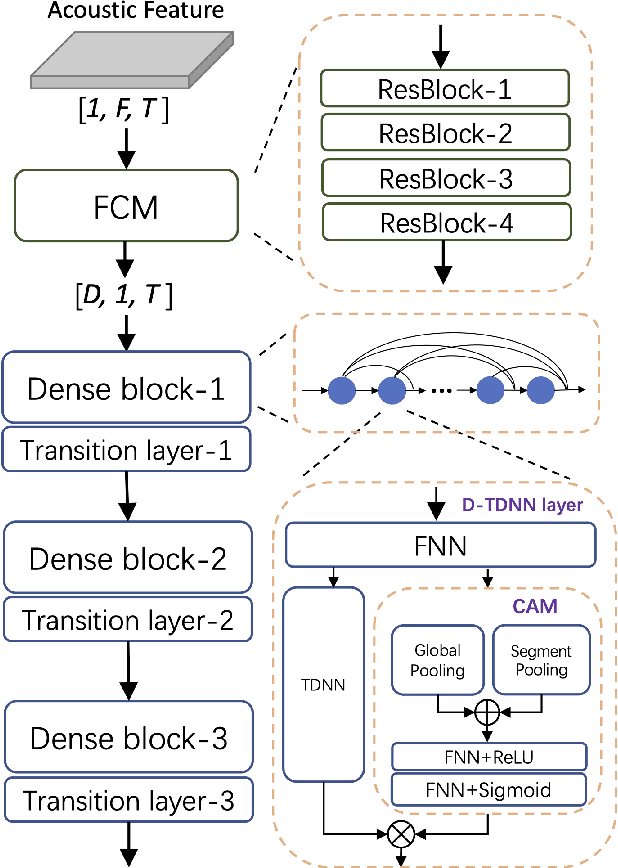
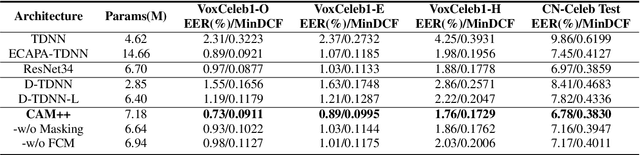
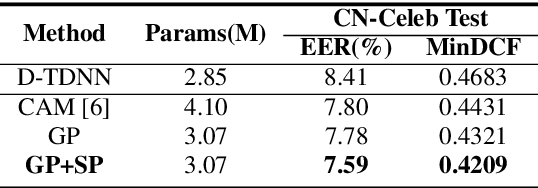

Time delay neural network (TDNN) has been proven to be efficient for speaker verification. One of its successful variants, ECAPA-TDNN, achieved state-of-the-art performance at the cost of much higher computational complexity and slower inference speed. This makes it inadequate for scenarios with demanding inference rate and limited computational resources. We are thus interested in finding an architecture that can achieve the performance of ECAPA-TDNN and the efficiency of vanilla TDNN. In this paper, we propose an efficient network based on context-aware masking, namely CAM++, which uses densely connected time delay neural network (D-TDNN) as backbone and adopts a novel multi-granularity pooling to capture contextual information at different levels. Extensive experiments on two public benchmarks, VoxCeleb and CN-Celeb, demonstrate that the proposed architecture outperforms other mainstream speaker verification systems with lower computational cost and faster inference speed.
Data-driven Real-time Short-term Prediction of Air Quality: Comparison of ES, ARIMA, and LSTM
Nov 16, 2022
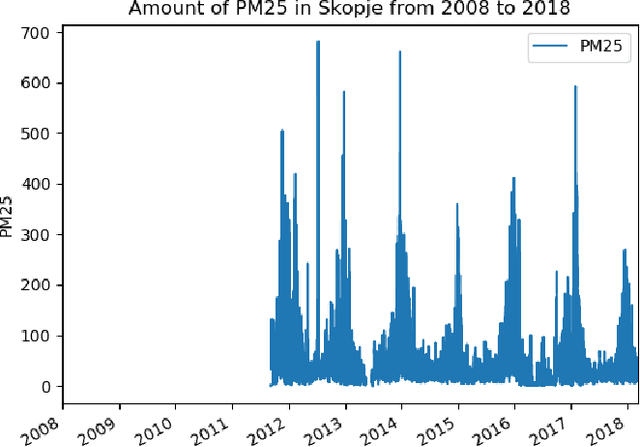
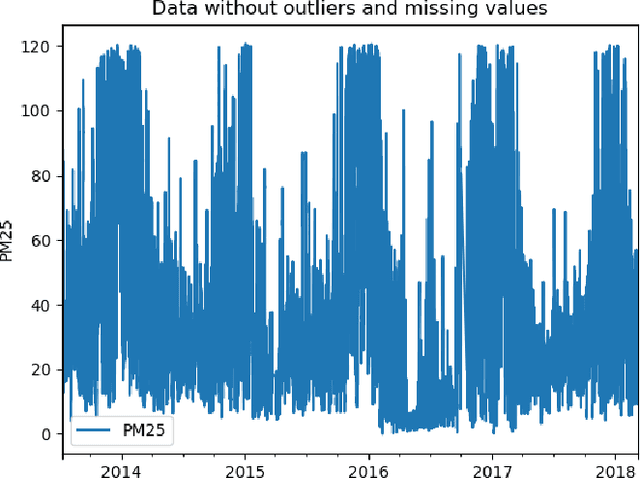
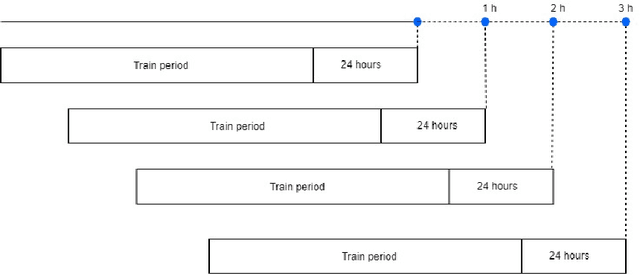
Air pollution is a worldwide issue that affects the lives of many people in urban areas. It is considered that the air pollution may lead to heart and lung diseases. A careful and timely forecast of the air quality could help to reduce the exposure risk for affected people. In this paper, we use a data-driven approach to predict air quality based on historical data. We compare three popular methods for time series prediction: Exponential Smoothing (ES), Auto-Regressive Integrated Moving Average (ARIMA) and Long short-term memory (LSTM). Considering prediction accuracy and time complexity, our experiments reveal that for short-term air pollution prediction ES performs better than ARIMA and LSTM.