 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LRDB: LSTM Raw data DNA Base-caller based on long-short term models in an active learning environment
Mar 15, 2023
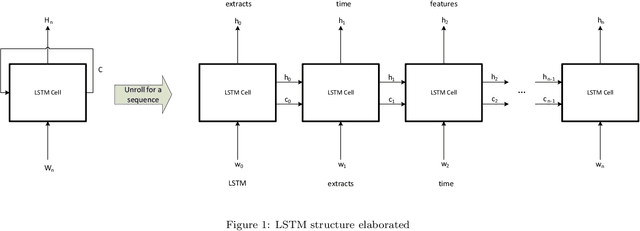
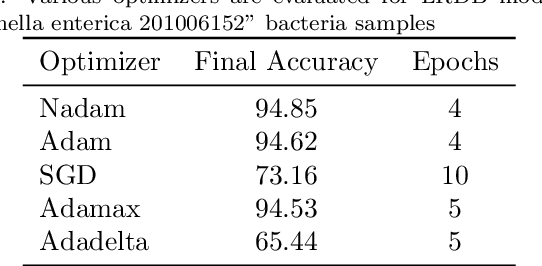
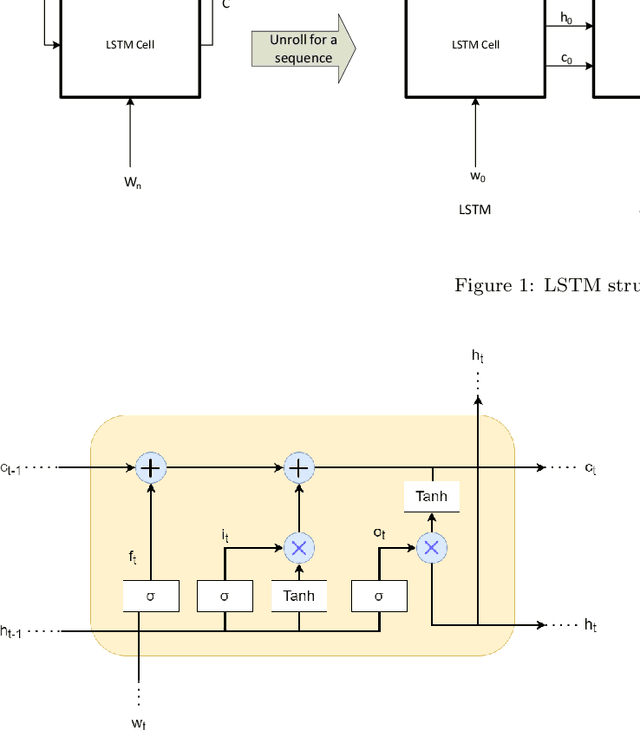
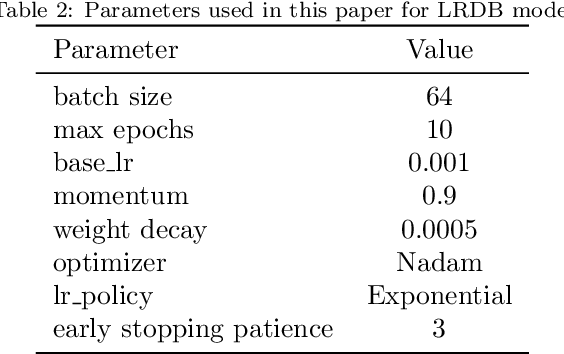
The first important step in extracting DNA characters is using the output data of MinION devices in the form of electrical current signals. Various cutting-edge base callers use this data to detect the DNA characters based on the input. In this paper, we discuss several shortcomings of prior base callers in the case of time-critical applications, privacy-aware design, and the problem of catastrophic forgetting. Next, we propose the LRDB model, a lightweight open-source model for private developments with a better read-identity (0.35% increase) for the target bacterial samples in the paper. We have limited the extent of training data and benefited from the transfer learning algorithm to make the active usage of the LRDB viable in critical applications. Henceforth, less training time for adapting to new DNA samples (in our case, Bacterial samples) is needed. Furthermore, LRDB can be modified concerning the user constraints as the results show a negligible accuracy loss in case of using fewer parameters. We have also assessed the noise-tolerance property, which offers about a 1.439% decline in accuracy for a 15dB noise injection, and the performance metrics show that the model executes in a medium speed range compared with current cutting-edge models.
Online and Predictive Warning System for Forced Lane Changes using Risk Maps
Mar 15, 2023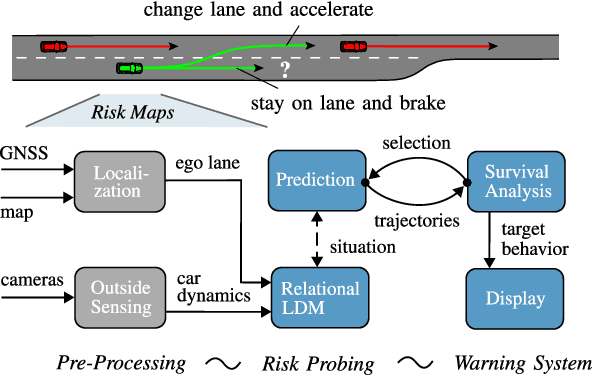
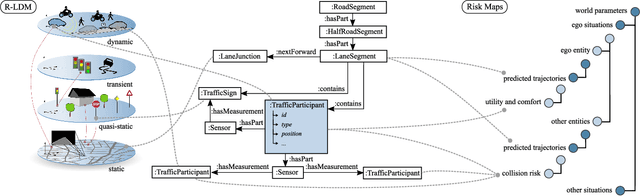
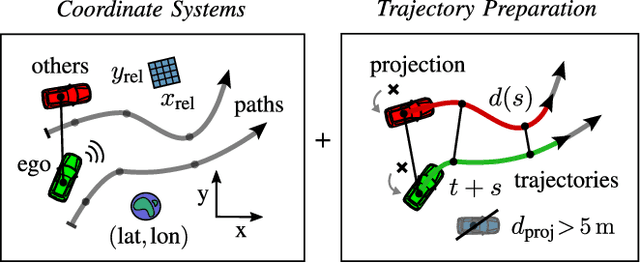
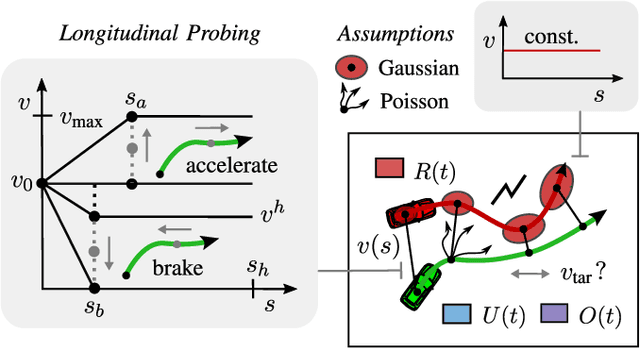
The survival analysis of driving trajectories allows for holistic evaluations of car-related risks caused by collisions or curvy roads. This analysis has advantages over common Time-To-X indicators, such as its predictive and probabilistic nature. However, so far, the theoretical risks have not been demonstrated in real-world environments. In this paper, we therefore present Risk Maps (RM) for online warning support in situations with forced lane changes, due to the end of roads. For this purpose, we first unify sensor data in a Relational Local Dynamic Map (R-LDM). RM is afterwards able to be run in real-time and efficiently probes a range of situations in order to determine risk-minimizing behaviors. Hereby, we focus on the improvement of uncertainty-awareness and transparency of the system. Risk, utility and comfort costs are included in a single formula and are intuitively visualized to the driver. In the conducted experiments, a low-cost sensor setup with a GNSS receiver for localization and multiple cameras for object detection are leveraged. The final system is successfully applied on two-lane roads and recommends lane change advices, which are separated in gap and no-gap indications. These results are promising and present an important step towards interpretable safety.
Efficient Planning of Multi-Robot Collective Transport using Graph Reinforcement Learning with Higher Order Topological Abstraction
Mar 15, 2023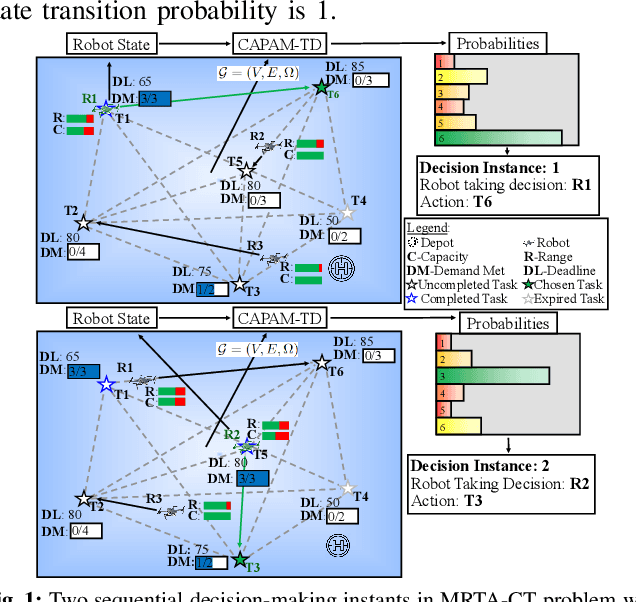
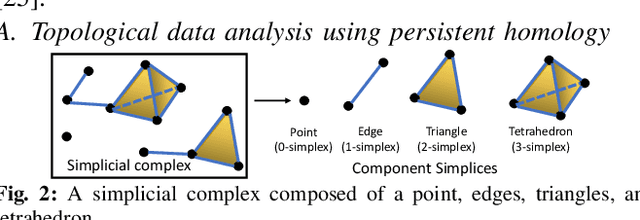
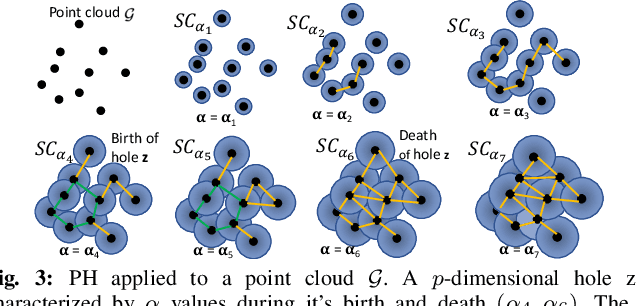
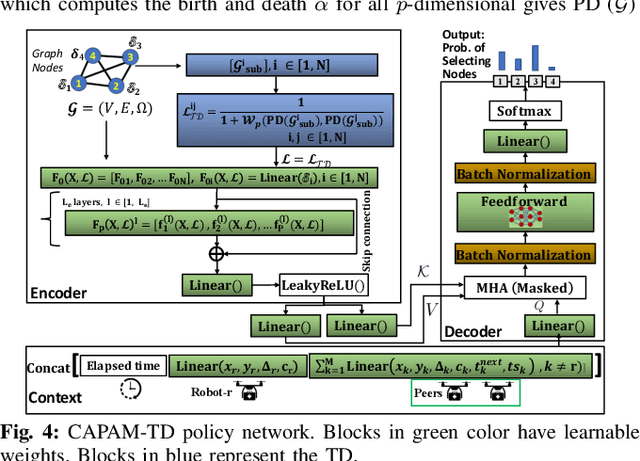
Efficient multi-robot task allocation (MRTA) is fundamental to various time-sensitive applications such as disaster response, warehouse operations, and construction. This paper tackles a particular class of these problems that we call MRTA-collective transport or MRTA-CT -- here tasks present varying workloads and deadlines, and robots are subject to flight range, communication range, and payload constraints. For large instances of these problems involving 100s-1000's of tasks and 10s-100s of robots, traditional non-learning solvers are often time-inefficient, and emerging learning-based policies do not scale well to larger-sized problems without costly retraining. To address this gap, we use a recently proposed encoder-decoder graph neural network involving Capsule networks and multi-head attention mechanism, and innovatively add topological descriptors (TD) as new features to improve transferability to unseen problems of similar and larger size. Persistent homology is used to derive the TD, and proximal policy optimization is used to train our TD-augmented graph neural network. The resulting policy model compares favorably to state-of-the-art non-learning baselines while being much faster. The benefit of using TD is readily evident when scaling to test problems of size larger than those used in training.
Multi-Robot Persistent Monitoring: Minimizing Latency and Number of Robots with Recharging Constraints
Mar 15, 2023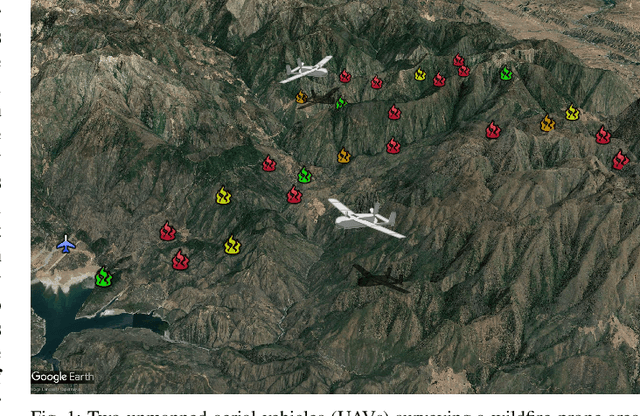

In this paper we study multi-robot path planning for persistent monitoring tasks. We consider the case where robots have a limited battery capacity with a discharge time $D$. We represent the areas to be monitored as the vertices of a weighted graph. For each vertex, there is a constraint on the maximum allowable time between robot visits, called the latency. The objective is to find the minimum number of robots that can satisfy these latency constraints while also ensuring that the robots periodically charge at a recharging depot. The decision version of this problem is known to be PSPACE-complete. We present a $O(\frac{\log D}{\log \log D}\log \rho)$ approximation algorithm for the problem where $\rho$ is the ratio of the maximum and the minimum latency constraints. We also present an orienteering based heuristic to solve the problem and show empirically that it typically provides higher quality solutions than the approximation algorithm. We extend our results to provide an algorithm for the problem of minimizing the maximum weighted latency given a fixed number of robots. We evaluate our algorithms on large problem instances in a patrolling scenario and in a wildfire monitoring application. We also compare the algorithms with an existing solver on benchmark instances.
Few-shot Geometry-Aware Keypoint Localization
Mar 30, 2023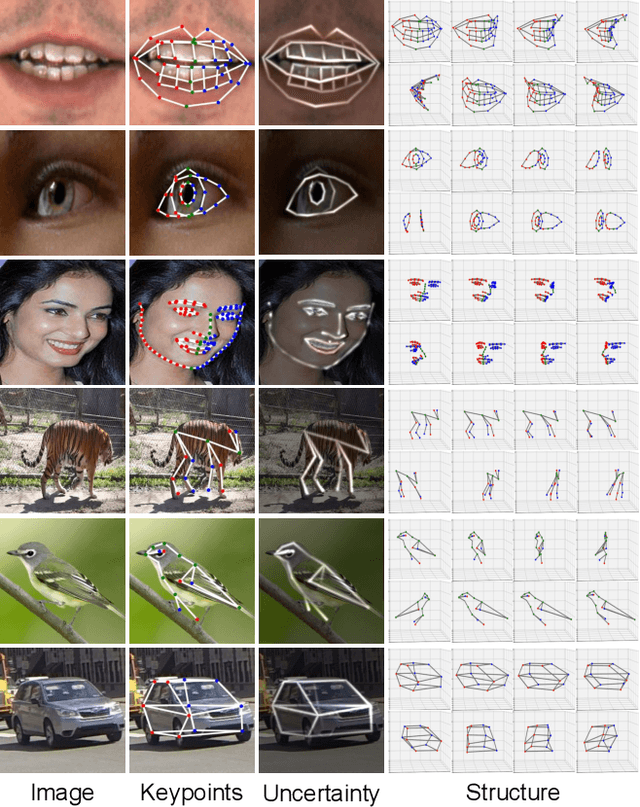
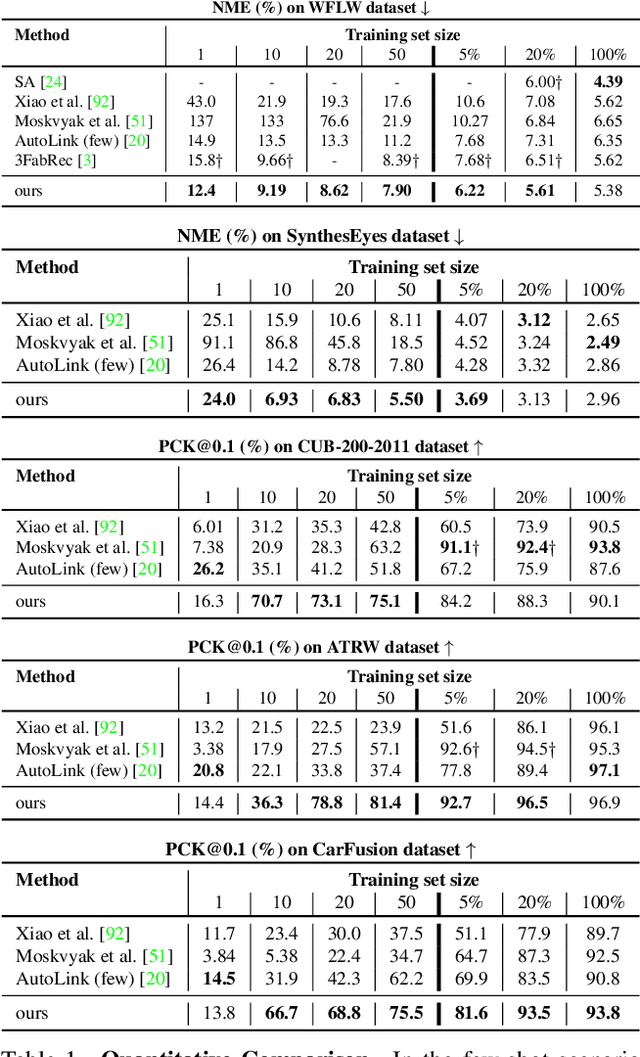
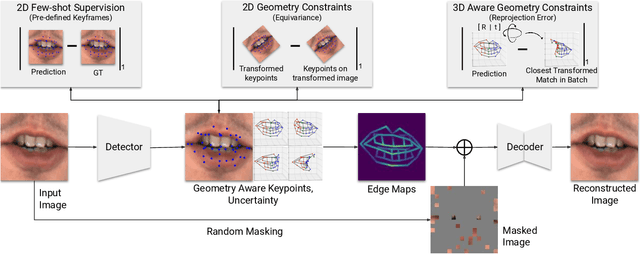
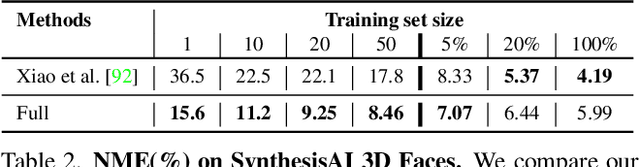
Supervised keypoint localization methods rely on large manually labeled image datasets, where objects can deform, articulate, or occlude. However, creating such large keypoint labels is time-consuming and costly, and is often error-prone due to inconsistent labeling. Thus, we desire an approach that can learn keypoint localization with fewer yet consistently annotated images. To this end, we present a novel formulation that learns to localize semantically consistent keypoint definitions, even for occluded regions, for varying object categories. We use a few user-labeled 2D images as input examples, which are extended via self-supervision using a larger unlabeled dataset. Unlike unsupervised methods, the few-shot images act as semantic shape constraints for object localization. Furthermore, we introduce 3D geometry-aware constraints to uplift keypoints, achieving more accurate 2D localization. Our general-purpose formulation paves the way for semantically conditioned generative modeling and attains competitive or state-of-the-art accuracy on several datasets, including human faces, eyes, animals, cars, and never-before-seen mouth interior (teeth) localization tasks, not attempted by the previous few-shot methods. Project page: https://xingzhehe.github.io/FewShot3DKP/}{https://xingzhehe.github.io/FewShot3DKP/
* CVPR 2023
Event-based Agile Object Catching with a Quadrupedal Robot
Mar 30, 2023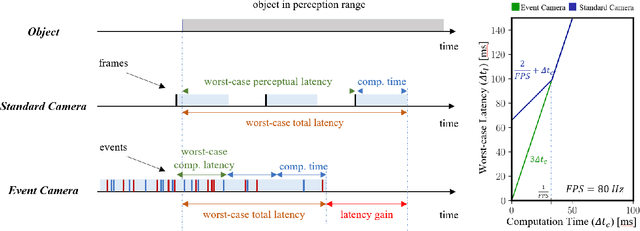
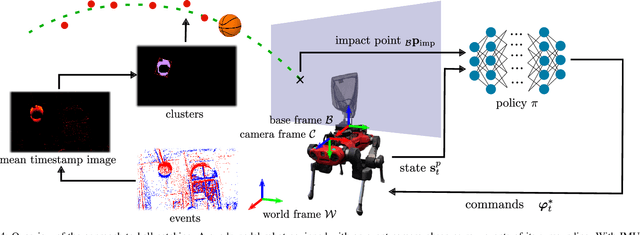


Quadrupedal robots are conquering various indoor and outdoor applications due to their ability to navigate challenging uneven terrains. Exteroceptive information greatly enhances this capability since perceiving their surroundings allows them to adapt their controller and thus achieve higher levels of robustness. However, sensors such as LiDARs and RGB cameras do not provide sufficient information to quickly and precisely react in a highly dynamic environment since they suffer from a bandwidth-latency tradeoff. They require significant bandwidth at high frame rates while featuring significant perceptual latency at lower frame rates, thereby limiting their versatility on resource-constrained platforms. In this work, we tackle this problem by equipping our quadruped with an event camera, which does not suffer from this tradeoff due to its asynchronous and sparse operation. In leveraging the low latency of the events, we push the limits of quadruped agility and demonstrate high-speed ball catching for the first time. We show that our quadruped equipped with an event camera can catch objects with speeds up to 15 m/s from 4 meters, with a success rate of 83%. Using a VGA event camera, our method runs at 100 Hz on an NVIDIA Jetson Orin.
Robust Multi-Agent Pickup and Delivery with Delays
Mar 30, 2023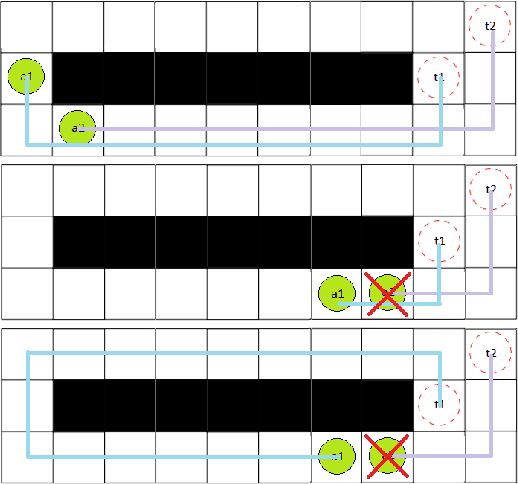
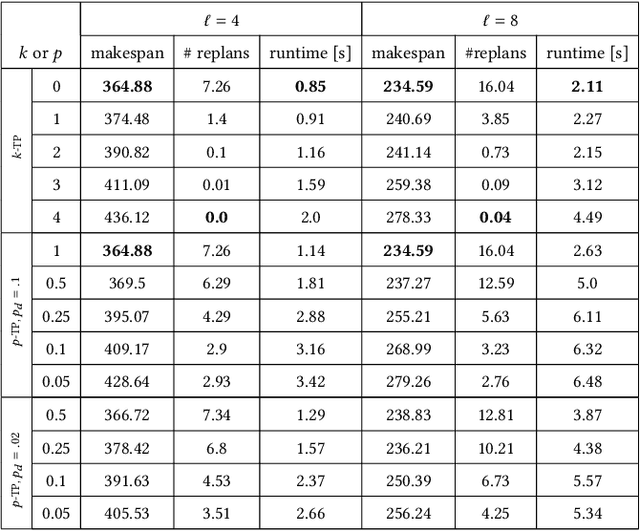
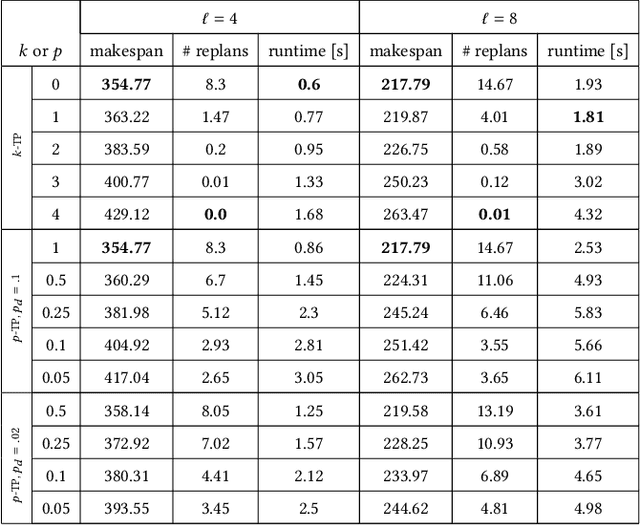
Multi-Agent Pickup and Delivery (MAPD) is the problem of computing collision-free paths for a group of agents such that they can safely reach delivery locations from pickup ones. These locations are provided at runtime, making MAPD a combination between classical Multi-Agent Path Finding (MAPF) and online task assignment. Current algorithms for MAPD do not consider many of the practical issues encountered in real applications: real agents often do not follow the planned paths perfectly, and may be subject to delays and failures. In this paper, we study the problem of MAPD with delays, and we present two solution approaches that provide robustness guarantees by planning paths that limit the effects of imperfect execution. In particular, we introduce two algorithms, k-TP and p-TP, both based on a decentralized algorithm typically used to solve MAPD, Token Passing (TP), which offer deterministic and probabilistic guarantees, respectively. Experimentally, we compare our algorithms against a version of TP enriched with online replanning. k-TP and p-TP provide robust solutions, significantly reducing the number of replans caused by delays, with little or no increase in solution cost and running time.
Lifting uniform learners via distributional decomposition
Mar 30, 2023

We show how any PAC learning algorithm that works under the uniform distribution can be transformed, in a blackbox fashion, into one that works under an arbitrary and unknown distribution $\mathcal{D}$. The efficiency of our transformation scales with the inherent complexity of $\mathcal{D}$, running in $\mathrm{poly}(n, (md)^d)$ time for distributions over $\{\pm 1\}^n$ whose pmfs are computed by depth-$d$ decision trees, where $m$ is the sample complexity of the original algorithm. For monotone distributions our transformation uses only samples from $\mathcal{D}$, and for general ones it uses subcube conditioning samples. A key technical ingredient is an algorithm which, given the aforementioned access to $\mathcal{D}$, produces an optimal decision tree decomposition of $\mathcal{D}$: an approximation of $\mathcal{D}$ as a mixture of uniform distributions over disjoint subcubes. With this decomposition in hand, we run the uniform-distribution learner on each subcube and combine the hypotheses using the decision tree. This algorithmic decomposition lemma also yields new algorithms for learning decision tree distributions with runtimes that exponentially improve on the prior state of the art -- results of independent interest in distribution learning.
Temporal Graph Neural Networks for Irregular Data
Feb 16, 2023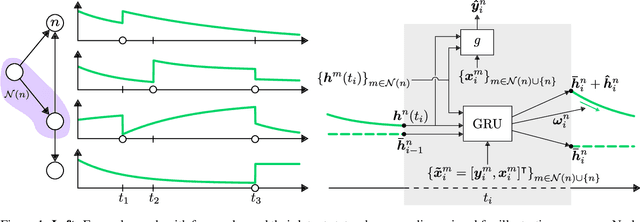
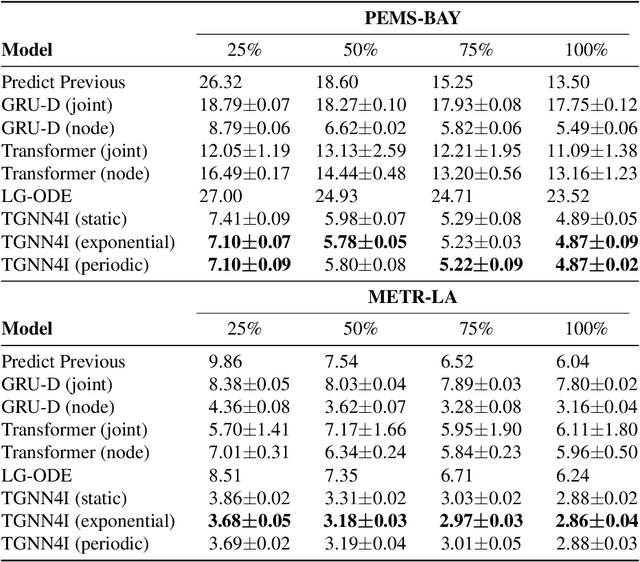
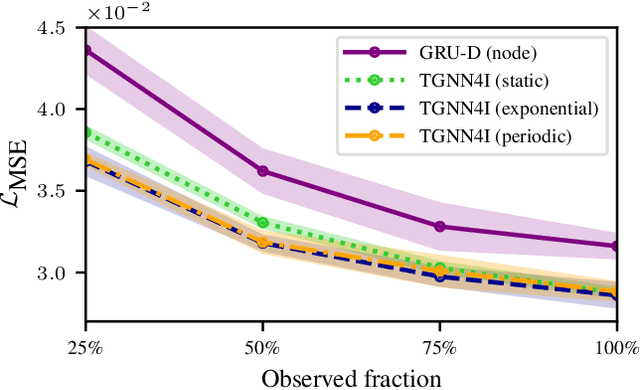
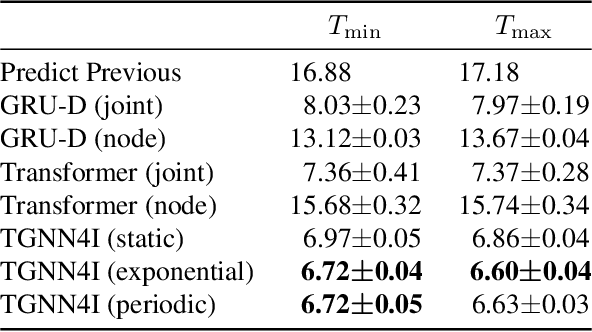
This paper proposes a temporal graph neural network model for forecasting of graph-structured irregularly observed time series. Our TGNN4I model is designed to handle both irregular time steps and partial observations of the graph. This is achieved by introducing a time-continuous latent state in each node, following a linear Ordinary Differential Equation (ODE) defined by the output of a Gated Recurrent Unit (GRU). The ODE has an explicit solution as a combination of exponential decay and periodic dynamics. Observations in the graph neighborhood are taken into account by integrating graph neural network layers in both the GRU state update and predictive model. The time-continuous dynamics additionally enable the model to make predictions at arbitrary time steps. We propose a loss function that leverages this and allows for training the model for forecasting over different time horizons. Experiments on simulated data and real-world data from traffic and climate modeling validate the usefulness of both the graph structure and time-continuous dynamics in settings with irregular observations.
MDAESF: Cine MRI Reconstruction Based on Motion-Guided Deformable Alignment and Efficient Spatiotemporal Self-Attention Fusion
Mar 09, 2023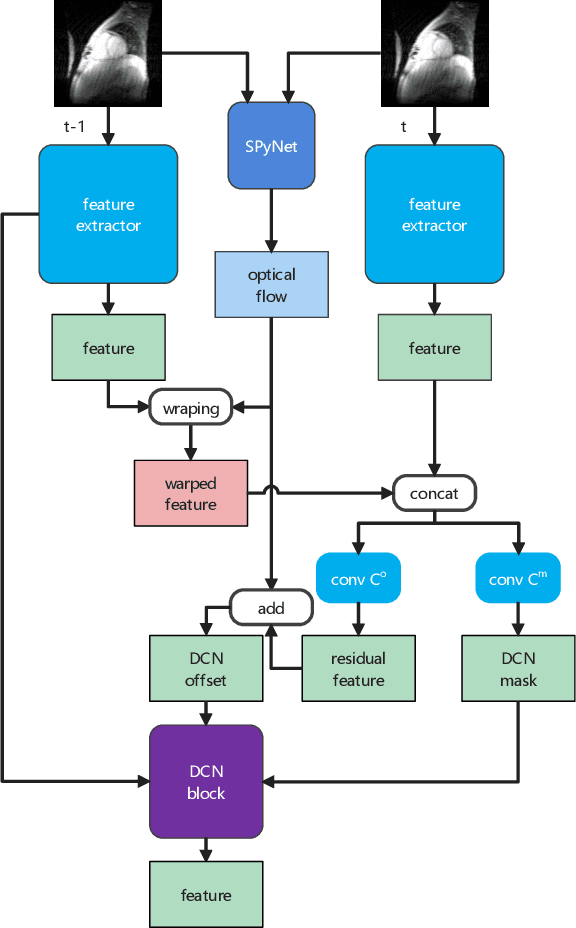

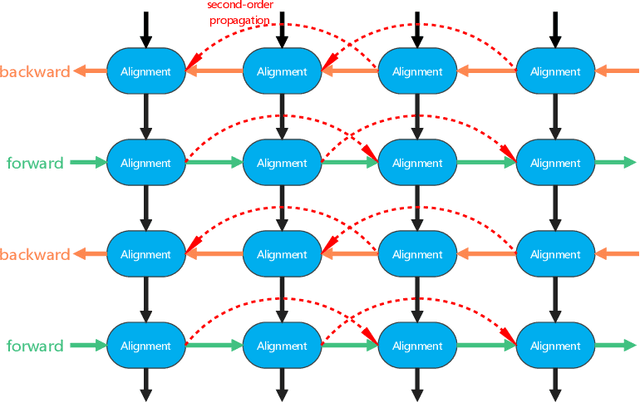

Cine MRI can jointly obtain the continuous influence of the anatomical structure and physiological and pathological mechanisms of organs in the two dimensions of time domain and space domain. Compared with ordinary two-dimensional static MRI images, the information in the time dimension of cine MRI contains many important information. But the information in the temporal dimension is not well utilized in past methods. To make full use of spatiotemporal information and reduce the influence of artifacts, this paper proposes a cine MRI reconstruction model based on second-order bidirectional propagation, motion-guided deformable alignment, and efficient spatiotemporal self-attention fusion. Compared to other advanced methods, our proposed method achieved better image reconstruction quality in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) metrics as well as visual effects. The source code will be made available on https://github.com/GtLinyer/MDAESF.