 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Object Motion Sensitivity: A Bio-inspired Solution to the Ego-motion Problem for Event-based Cameras
Mar 27, 2023
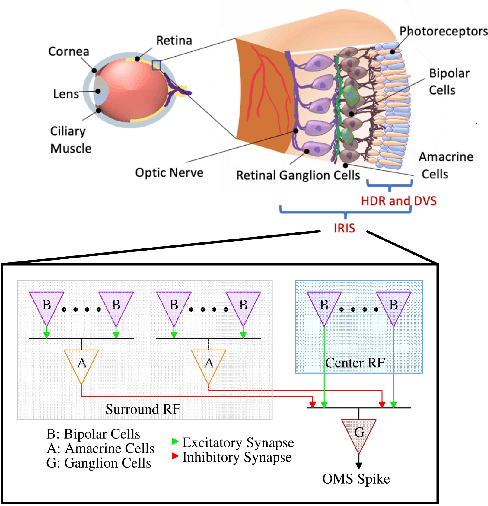
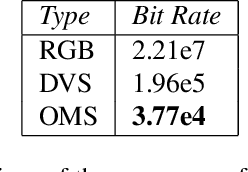
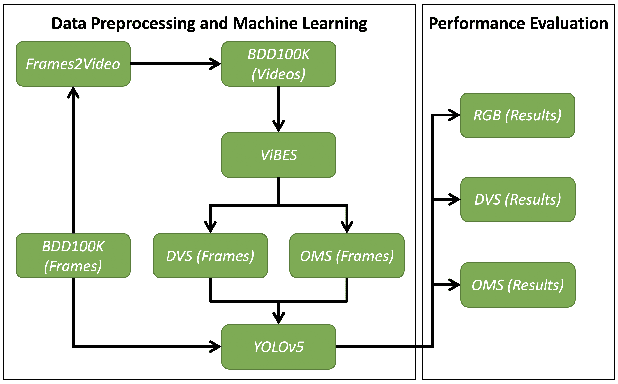
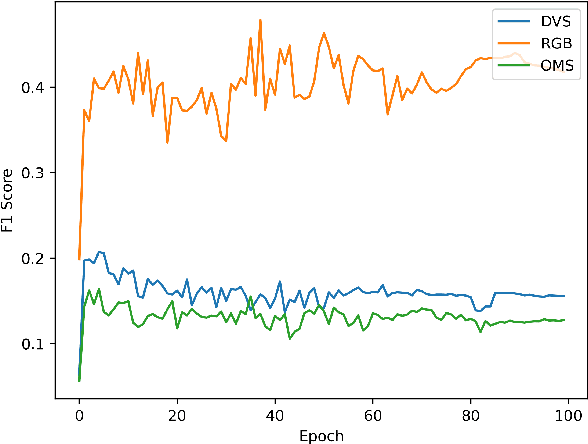
Neuromorphic (event-based) image sensors draw inspiration from the human-retina to create an electronic device that can process visual stimuli in a way that closely resembles its biological counterpart. These sensors process information significantly different than the traditional RGB sensors. Specifically, the sensory information generated by event-based image sensors are orders of magnitude sparser compared to that of RGB sensors. The first generation of neuromorphic image sensors, Dynamic Vision Sensor (DVS), are inspired by the computations confined to the photoreceptors and the first retinal synapse. In this work, we highlight the capability of the second generation of neuromorphic image sensors, Integrated Retinal Functionality in CMOS Image Sensors (IRIS), which aims to mimic full retinal computations from photoreceptors to output of the retina (retinal ganglion cells) for targeted feature-extraction. The feature of choice in this work is Object Motion Sensitivity (OMS) that is processed locally in the IRIS sensor. We study the capability of OMS in solving the ego-motion problem of the event-based cameras. Our results show that OMS can accomplish standard computer vision tasks with similar efficiency to conventional RGB and DVS solutions but offers drastic bandwidth reduction. This cuts the wireless and computing power budgets and opens up vast opportunities in high-speed, robust, energy-efficient, and low-bandwidth real-time decision making.
Intensity-based dynamic speckle method using JPEG and JPEG2000 compression
Mar 13, 2023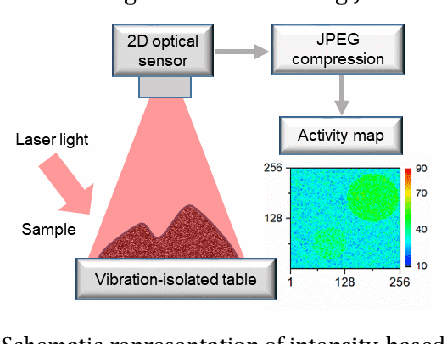
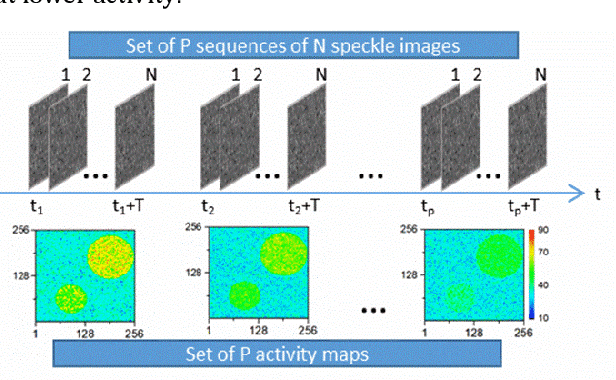
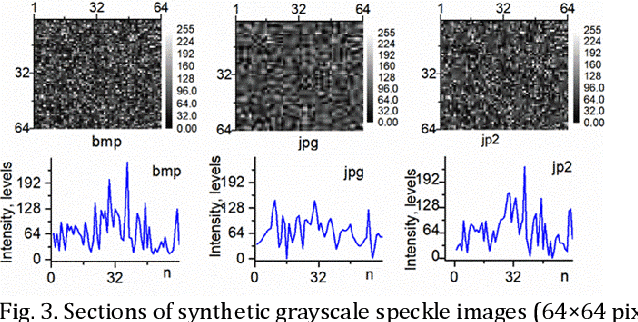
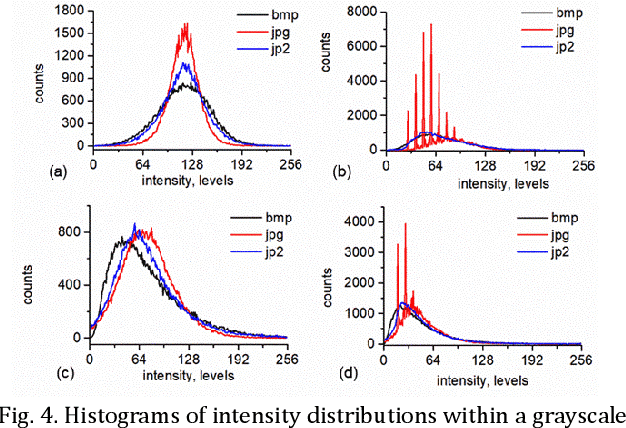
Statistical processing of speckle data enables observation of speed of processes. In intensity-based pointwise dynamic speckle analysis, a map related to speed's spatial distribution is extracted from a sequence of speckle patterns formed on an object under coherent light. Monitoring of time evolution of a process needs storage, transfer and processing of a large number of images. We have proposed lossy compression of these images using JPEG and JPEG2000 formats. We have compared the maps computed from non-compressed and decompressed synthetic and experimental images, and we have proven that both compression formats can be applied in the dynamic speckle analysis.
Neural Preset for Color Style Transfer
Mar 24, 2023
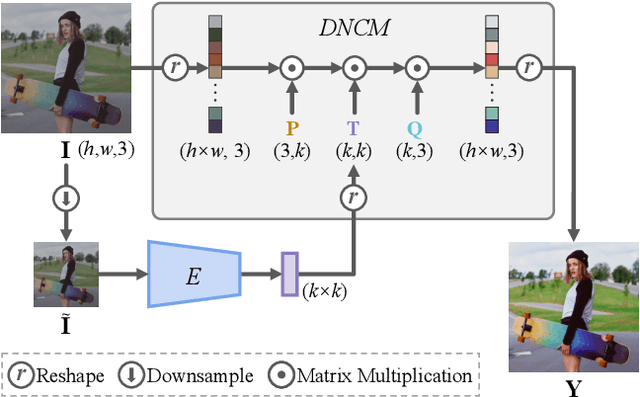
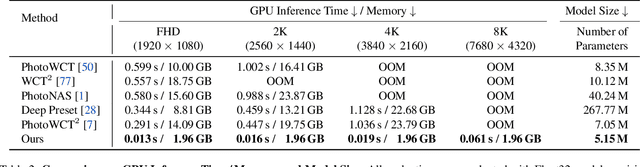
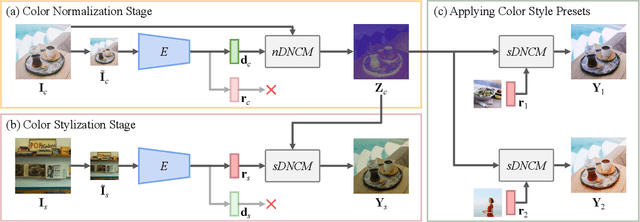
In this paper, we present a Neural Preset technique to address the limitations of existing color style transfer methods, including visual artifacts, vast memory requirement, and slow style switching speed. Our method is based on two core designs. First, we propose Deterministic Neural Color Mapping (DNCM) to consistently operate on each pixel via an image-adaptive color mapping matrix, avoiding artifacts and supporting high-resolution inputs with a small memory footprint. Second, we develop a two-stage pipeline by dividing the task into color normalization and stylization, which allows efficient style switching by extracting color styles as presets and reusing them on normalized input images. Due to the unavailability of pairwise datasets, we describe how to train Neural Preset via a self-supervised strategy. Various advantages of Neural Preset over existing methods are demonstrated through comprehensive evaluations. Notably, Neural Preset enables stable 4K color style transfer in real-time without artifacts. Besides, we show that our trained model can naturally support multiple applications without fine-tuning, including low-light image enhancement, underwater image correction, image dehazing, and image harmonization. Project page with demos: https://zhkkke.github.io/NeuralPreset .
Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
Mar 24, 2023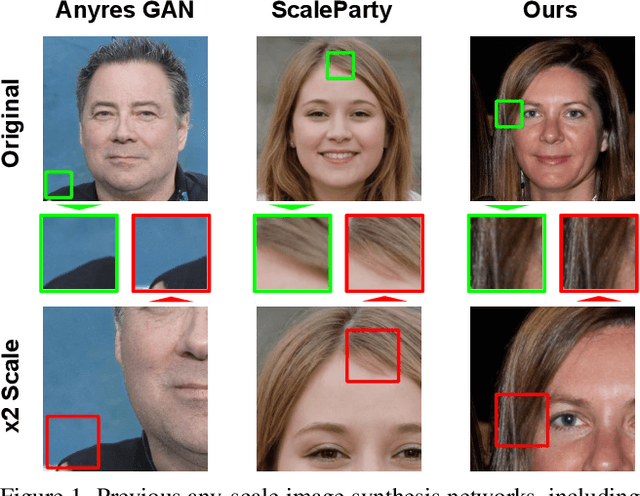
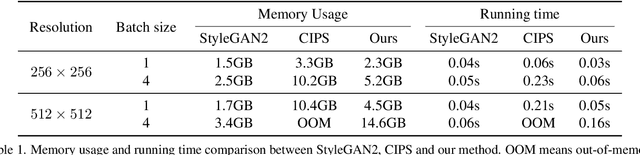
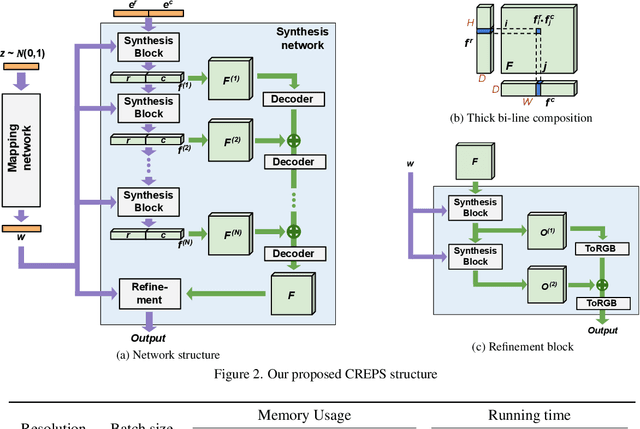

Any-scale image synthesis offers an efficient and scalable solution to synthesize photo-realistic images at any scale, even going beyond 2K resolution. However, existing GAN-based solutions depend excessively on convolutions and a hierarchical architecture, which introduce inconsistency and the $``$texture sticking$"$ issue when scaling the output resolution. From another perspective, INR-based generators are scale-equivariant by design, but their huge memory footprint and slow inference hinder these networks from being adopted in large-scale or real-time systems. In this work, we propose $\textbf{C}$olumn-$\textbf{R}$ow $\textbf{E}$ntangled $\textbf{P}$ixel $\textbf{S}$ynthesis ($\textbf{CREPS}$), a new generative model that is both efficient and scale-equivariant without using any spatial convolutions or coarse-to-fine design. To save memory footprint and make the system scalable, we employ a novel bi-line representation that decomposes layer-wise feature maps into separate $``$thick$"$ column and row encodings. Experiments on various datasets, including FFHQ, LSUN-Church, MetFaces, and Flickr-Scenery, confirm CREPS' ability to synthesize scale-consistent and alias-free images at any arbitrary resolution with proper training and inference speed. Code is available at https://github.com/VinAIResearch/CREPS.
Sequential Knockoffs for Variable Selection in Reinforcement Learning
Mar 24, 2023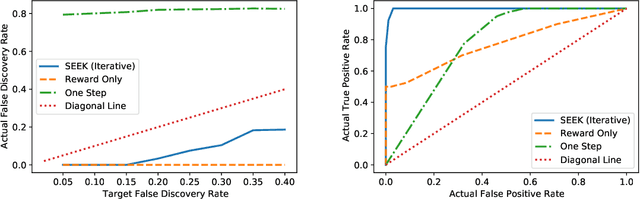


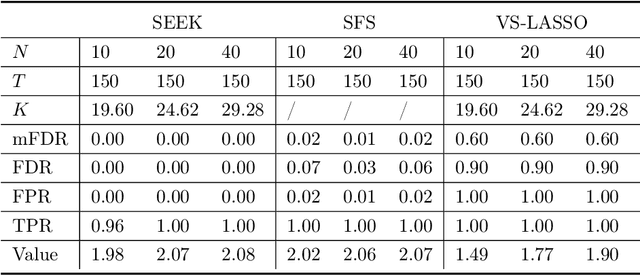
In real-world applications of reinforcement learning, it is often challenging to obtain a state representation that is parsimonious and satisfies the Markov property without prior knowledge. Consequently, it is common practice to construct a state which is larger than necessary, e.g., by concatenating measurements over contiguous time points. However, needlessly increasing the dimension of the state can slow learning and obfuscate the learned policy. We introduce the notion of a minimal sufficient state in a Markov decision process (MDP) as the smallest subvector of the original state under which the process remains an MDP and shares the same optimal policy as the original process. We propose a novel sequential knockoffs (SEEK) algorithm that estimates the minimal sufficient state in a system with high-dimensional complex nonlinear dynamics. In large samples, the proposed method controls the false discovery rate, and selects all sufficient variables with probability approaching one. As the method is agnostic to the reinforcement learning algorithm being applied, it benefits downstream tasks such as policy optimization. Empirical experiments verify theoretical results and show the proposed approach outperforms several competing methods in terms of variable selection accuracy and regret.
Differentially Private Synthetic Control
Mar 24, 2023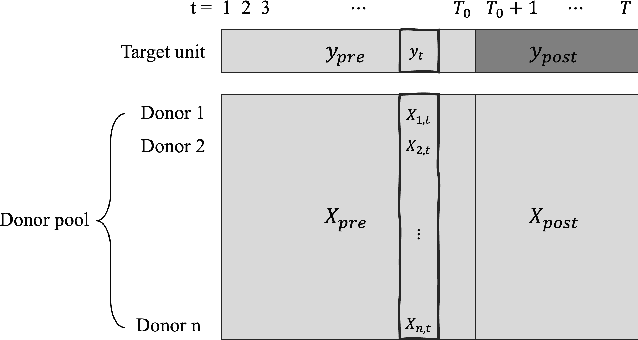

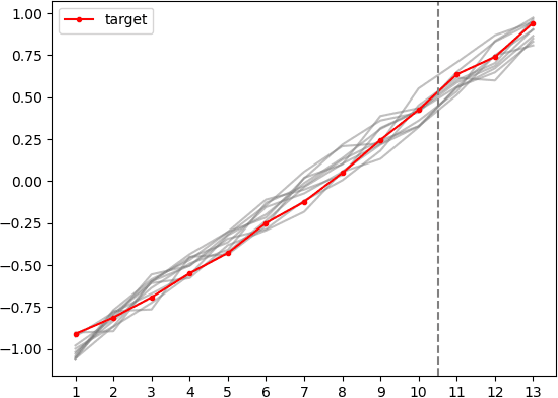

Synthetic control is a causal inference tool used to estimate the treatment effects of an intervention by creating synthetic counterfactual data. This approach combines measurements from other similar observations (i.e., donor pool ) to predict a counterfactual time series of interest (i.e., target unit) by analyzing the relationship between the target and the donor pool before the intervention. As synthetic control tools are increasingly applied to sensitive or proprietary data, formal privacy protections are often required. In this work, we provide the first algorithms for differentially private synthetic control with explicit error bounds. Our approach builds upon tools from non-private synthetic control and differentially private empirical risk minimization. We provide upper and lower bounds on the sensitivity of the synthetic control query and provide explicit error bounds on the accuracy of our private synthetic control algorithms. We show that our algorithms produce accurate predictions for the target unit, and that the cost of privacy is small. Finally, we empirically evaluate the performance of our algorithm, and show favorable performance in a variety of parameter regimes, as well as providing guidance to practitioners for hyperparameter tuning.
Spatiotemporal modeling of grip forces captures proficiency in manual robot control
Mar 03, 2023

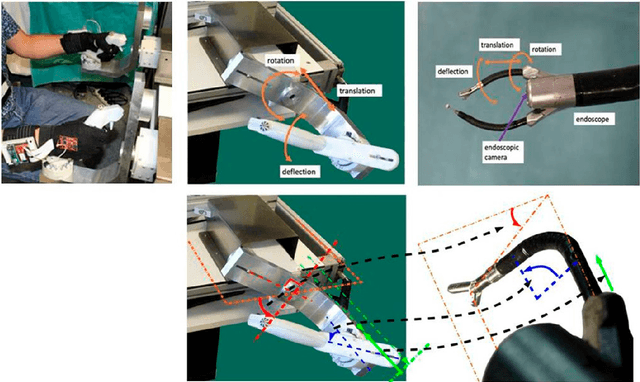

This paper builds on our previous work by exploiting Artificial Intelligence to predict individual grip force variability in manual robot control. Grip forces were recorded from various loci in the dominant and non dominant hands of individuals by means of wearable wireless sensor technology. Statistical analyses bring to the fore skill specific temporal variations in thousands of grip forces of a complete novice and a highly proficient expert in manual robot control. A brain inspired neural network model that uses the output metric of a Self Organizing Map with unsupervised winner take all learning was run on the sensor output from both hands of each user. The neural network metric expresses the difference between an input representation and its model representation at any given moment in time t and reliably captures the differences between novice and expert performance in terms of grip force variability.Functionally motivated spatiotemporal analysis of individual average grip forces, computed for time windows of constant size in the output of a restricted amount of task-relevant sensors in the dominant (preferred) hand, reveal finger-specific synergies reflecting robotic task skill. The analyses lead the way towards grip force monitoring in real time to permit tracking task skill evolution in trainees, or identify individual proficiency levels in human robot interaction in environmental contexts of high sensory uncertainty. Parsimonious Artificial Intelligence (AI) assistance will contribute to the outcome of new types of surgery, in particular single-port approaches such as NOTES (Natural Orifice Transluminal Endoscopic Surgery) and SILS (Single Incision Laparoscopic Surgery).
Allegro-Legato: Scalable, Fast, and Robust Neural-Network Quantum Molecular Dynamics via Sharpness-Aware Minimization
Mar 14, 2023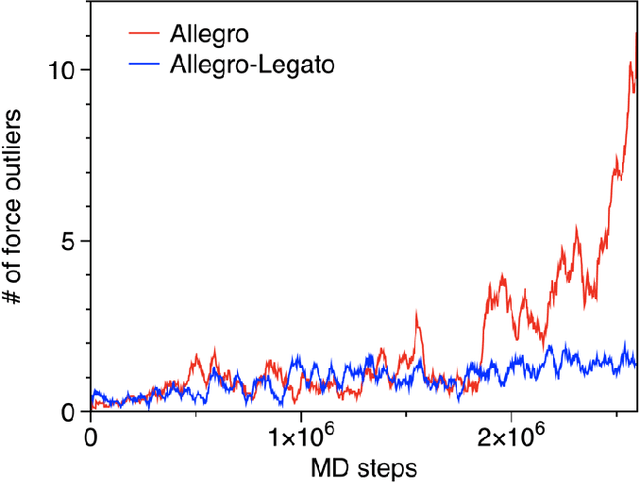

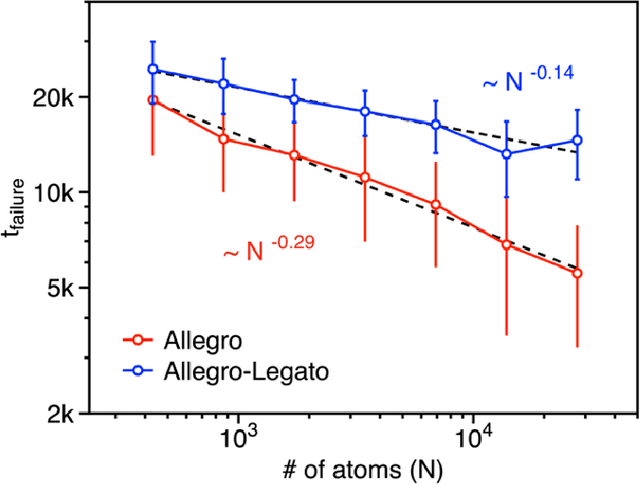
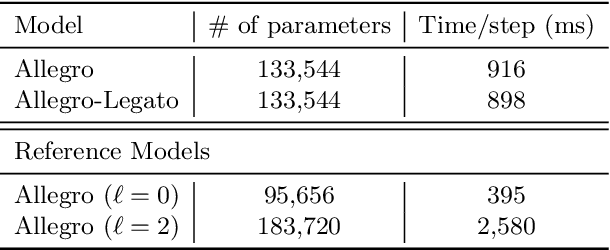
Neural-network quantum molecular dynamics (NNQMD) simulations based on machine learning are revolutionizing atomistic simulations of materials by providing quantum-mechanical accuracy but orders-of-magnitude faster, illustrated by ACM Gordon Bell prize (2020) and finalist (2021). State-of-the-art (SOTA) NNQMD model founded on group theory featuring rotational equivariance and local descriptors has provided much higher accuracy and speed than those models, thus named Allegro (meaning fast). On massively parallel supercomputers, however, it suffers a fidelity-scaling problem, where growing number of unphysical predictions of interatomic forces prohibits simulations involving larger numbers of atoms for longer times. Here, we solve this problem by combining the Allegro model with sharpness aware minimization (SAM) for enhancing the robustness of model through improved smoothness of the loss landscape. The resulting Allegro-Legato (meaning fast and "smooth") model was shown to elongate the time-to-failure $t_\textrm{failure}$, without sacrificing computational speed or accuracy. Specifically, Allegro-Legato exhibits much weaker dependence of timei-to-failure on the problem size, $t_{\textrm{failure}} \propto N^{-0.14}$ ($N$ is the number of atoms) compared to the SOTA Allegro model $\left(t_{\textrm{failure}} \propto N^{-0.29}\right)$, i.e., systematically delayed time-to-failure, thus allowing much larger and longer NNQMD simulations without failure. The model also exhibits excellent computational scalability and GPU acceleration on the Polaris supercomputer at Argonne Leadership Computing Facility. Such scalable, accurate, fast and robust NNQMD models will likely find broad applications in NNQMD simulations on emerging exaflop/s computers, with a specific example of accounting for nuclear quantum effects in the dynamics of ammonia.
Variational Quantum Neural Networks (VQNNS) in Image Classification
Mar 10, 2023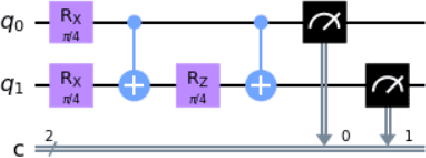

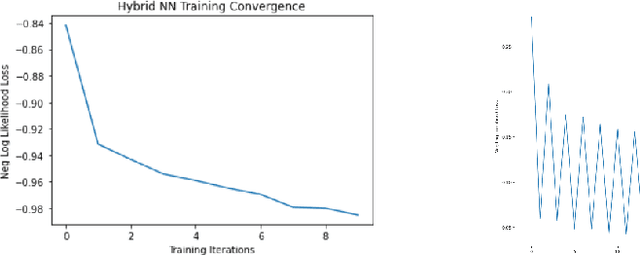
Quantum machine learning has established as an interdisciplinary field to overcome limitations of classical machine learning and neural networks. This is a field of research which can prove that quantum computers are able to solve problems with complex correlations between inputs that can be hard for classical computers. This suggests that learning models made on quantum computers may be more powerful for applications, potentially faster computation and better generalization on less data. The objective of this paper is to investigate how training of quantum neural network (QNNs) can be done using quantum optimization algorithms for improving the performance and time complexity of QNNs. A classical neural network can be partially quantized to create a hybrid quantum-classical neural network which is used mainly in classification and image recognition. In this paper, a QNN structure is made where a variational parameterized circuit is incorporated as an input layer named as Variational Quantum Neural Network (VQNNs). We encode the cost function of QNNs onto relative phases of a superposition state in the Hilbert space of the network parameters. The parameters are tuned with an iterative quantum approximate optimisation (QAOA) mixer and problem hamiltonians. VQNNs is experimented with MNIST digit recognition (less complex) and crack image classification datasets (more complex) which converges the computation in lesser time than QNN with decent training accuracy.
Generating Query Focused Summaries without Fine-tuning the Transformer-based Pre-trained Models
Mar 10, 2023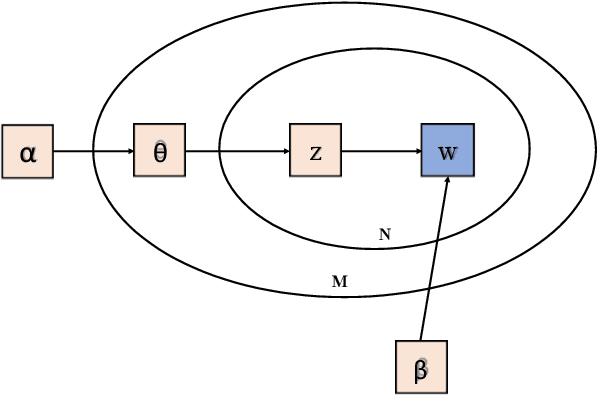
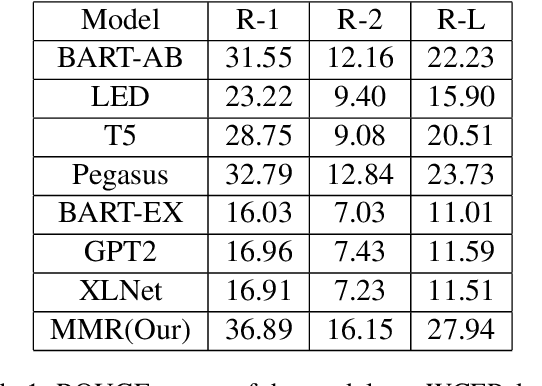
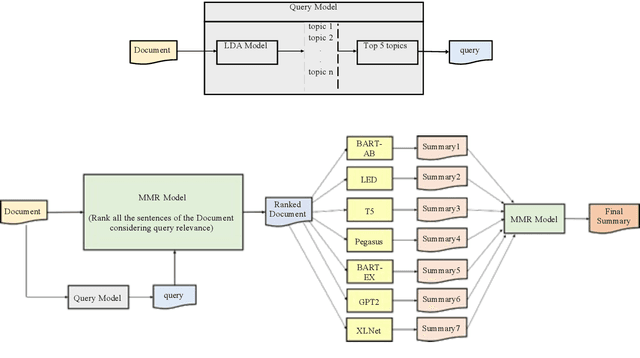
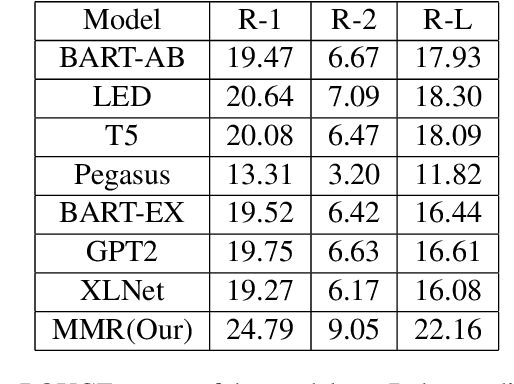
Fine-tuning the Natural Language Processing (NLP) models for each new data set requires higher computational time associated with increased carbon footprint and cost. However, fine-tuning helps the pre-trained models adapt to the latest data sets; what if we avoid the fine-tuning steps and attempt to generate summaries using just the pre-trained models to reduce computational time and cost. In this paper, we tried to omit the fine-tuning steps and investigate whether the Marginal Maximum Relevance (MMR)-based approach can help the pre-trained models to obtain query-focused summaries directly from a new data set that was not used to pre-train the models. First, we used topic modelling on Wikipedia Current Events Portal (WCEP) and Debatepedia datasets to generate queries for summarization tasks. Then, using MMR, we ranked the sentences of the documents according to the queries. Next, we passed the ranked sentences to seven transformer-based pre-trained models to perform the summarization tasks. Finally, we used the MMR approach again to select the query relevant sentences from the generated summaries of individual pre-trained models and constructed the final summary. As indicated by the experimental results, our MMR-based approach successfully ranked and selected the most relevant sentences as summaries and showed better performance than the individual pre-trained models.