 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Structured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
Apr 05, 2023
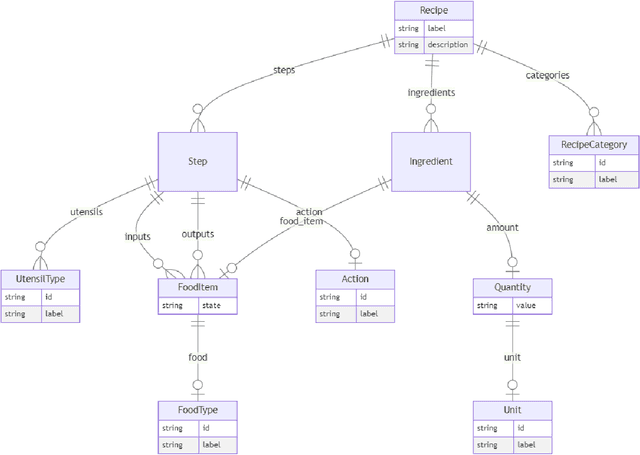
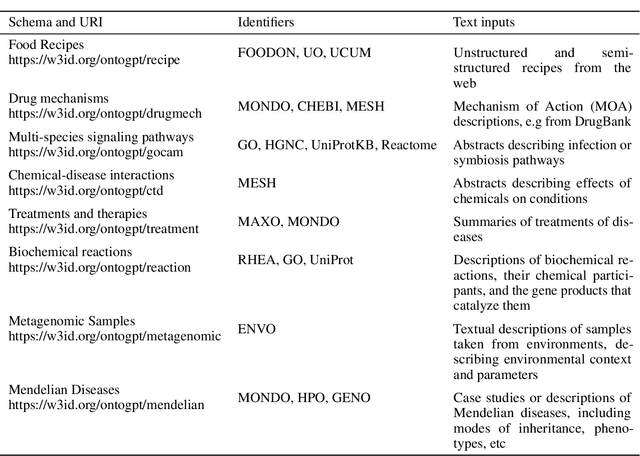
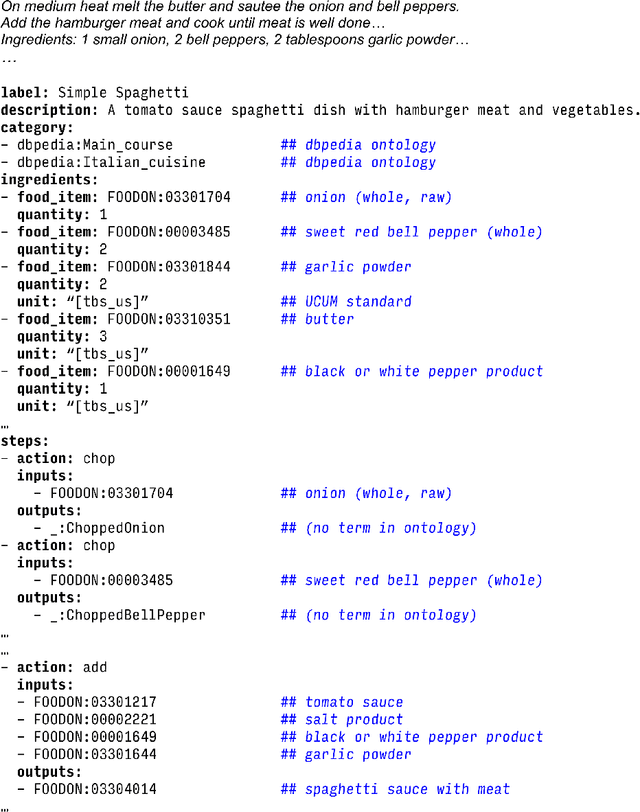

Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.
Direct and indirect evidence of compression of word lengths. Zipf's law of abbreviation revisited
Mar 17, 2023
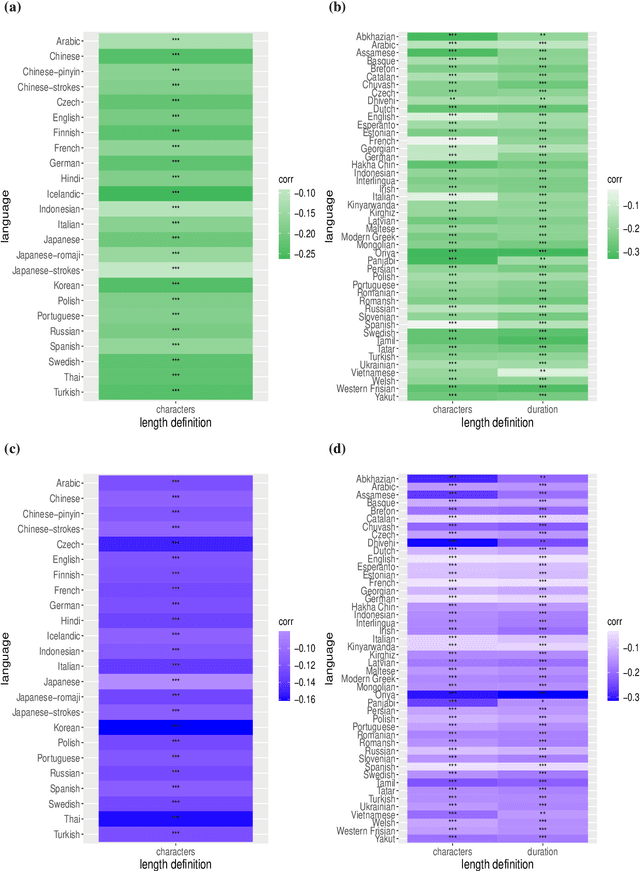
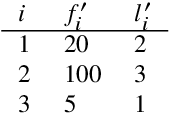
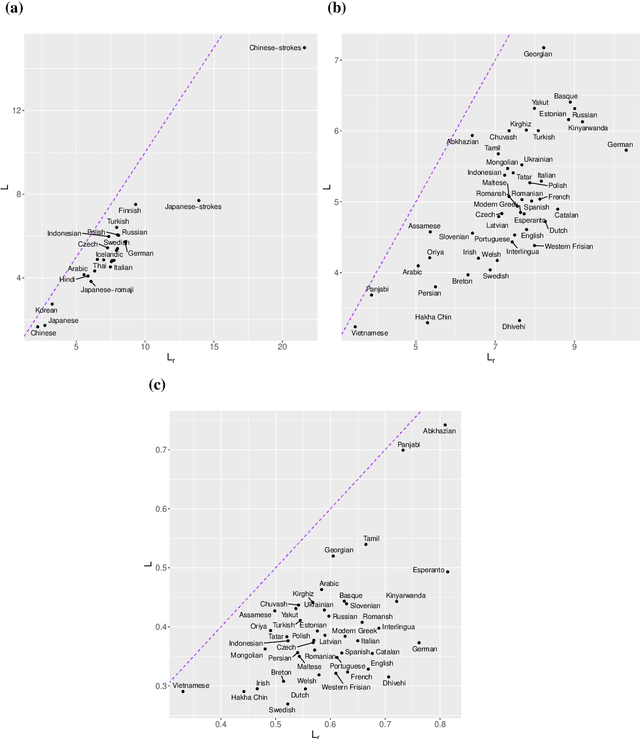
Zipf's law of abbreviation, the tendency of more frequent words to be shorter, is one of the most solid candidates for a linguistic universal, in the sense that it has the potential for being exceptionless or with a number of exceptions that is vanishingly small compared to the number of languages on Earth. Since Zipf's pioneering research, this law has been viewed as a manifestation of a universal principle of communication, i.e. the minimization of word lengths, to reduce the effort of communication. Here we revisit the concordance of written language with the law of abbreviation. Crucially, we provide wider evidence that the law holds also in speech (when word length is measured in time), in particular in 46 languages from 14 linguistic families. Agreement with the law of abbreviation provides indirect evidence of compression of languages via the theoretical argument that the law of abbreviation is a prediction of optimal coding. Motivated by the need of direct evidence of compression, we derive a simple formula for a random baseline indicating that word lengths are systematically below chance, across linguistic families and writing systems, and independently of the unit of measurement (length in characters or duration in time). Our work paves the way to measure and compare the degree of optimality of word lengths in languages.
What, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Mar 29, 2023
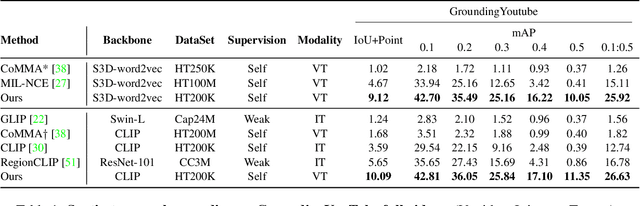
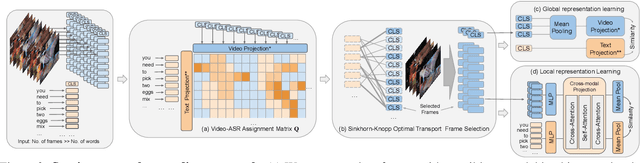
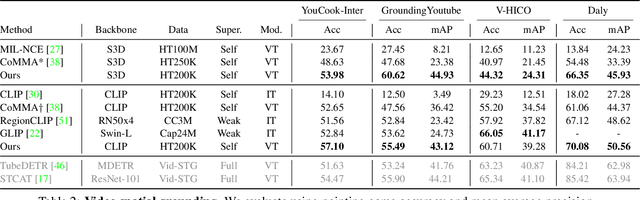
Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
Adaptive Superpixel for Active Learning in Semantic Segmentation
Mar 29, 2023
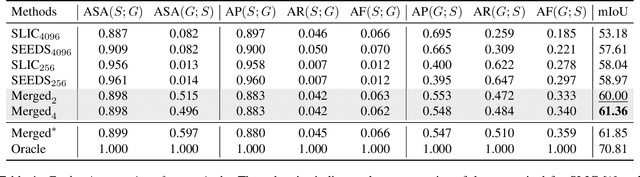
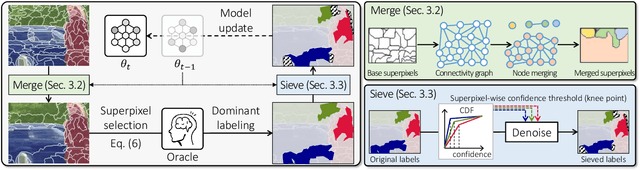
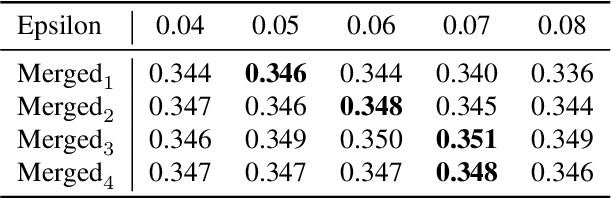
Learning semantic segmentation requires pixel-wise annotations, which can be time-consuming and expensive. To reduce the annotation cost, we propose a superpixel-based active learning (AL) framework, which collects a dominant label per superpixel instead. To be specific, it consists of adaptive superpixel and sieving mechanisms, fully dedicated to AL. At each round of AL, we adaptively merge neighboring pixels of similar learned features into superpixels. We then query a selected subset of these superpixels using an acquisition function assuming no uniform superpixel size. This approach is more efficient than existing methods, which rely only on innate features such as RGB color and assume uniform superpixel sizes. Obtaining a dominant label per superpixel drastically reduces annotators' burden as it requires fewer clicks. However, it inevitably introduces noisy annotations due to mismatches between superpixel and ground truth segmentation. To address this issue, we further devise a sieving mechanism that identifies and excludes potentially noisy annotations from learning. Our experiments on both Cityscapes and PASCAL VOC datasets demonstrate the efficacy of adaptive superpixel and sieving mechanisms.
Infeasible Deterministic, Stochastic, and Variance-Reduction Algorithms for Optimization under Orthogonality Constraints
Mar 29, 2023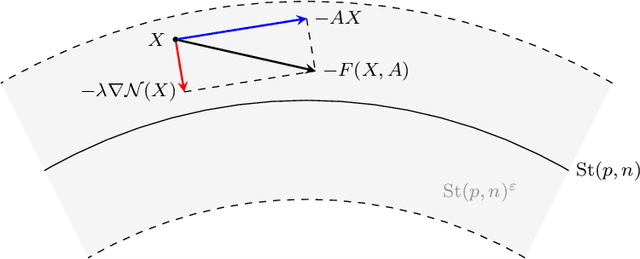
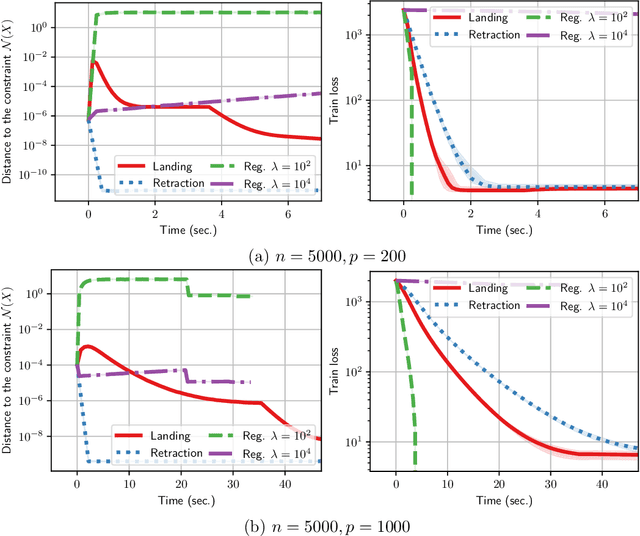
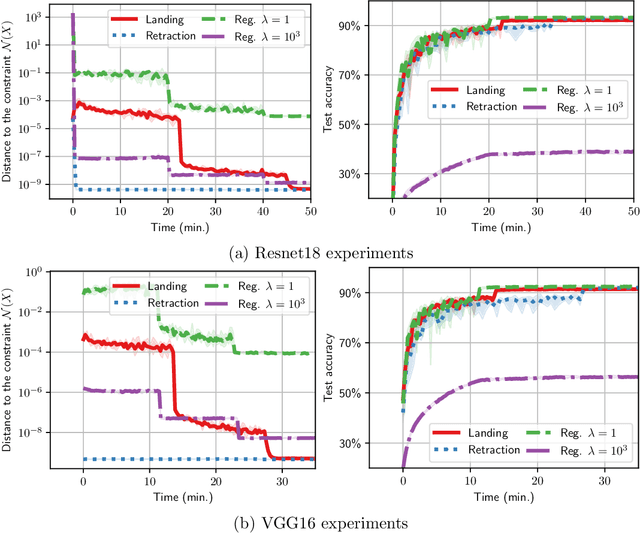

Orthogonality constraints naturally appear in many machine learning problems, from Principal Components Analysis to robust neural network training. They are usually solved using Riemannian optimization algorithms, which minimize the objective function while enforcing the constraint. However, enforcing the orthogonality constraint can be the most time-consuming operation in such algorithms. Recently, Ablin & Peyr\'e (2022) proposed the Landing algorithm, a method with cheap iterations that does not enforce the orthogonality constraint but is attracted towards the manifold in a smooth manner. In this article, we provide new practical and theoretical developments for the landing algorithm. First, the method is extended to the Stiefel manifold, the set of rectangular orthogonal matrices. We also consider stochastic and variance reduction algorithms when the cost function is an average of many functions. We demonstrate that all these methods have the same rate of convergence as their Riemannian counterparts that exactly enforce the constraint. Finally, our experiments demonstrate the promise of our approach to an array of machine-learning problems that involve orthogonality constraints.
Hybrid ACO-CI Algorithm for Beam Design problems
Mar 29, 2023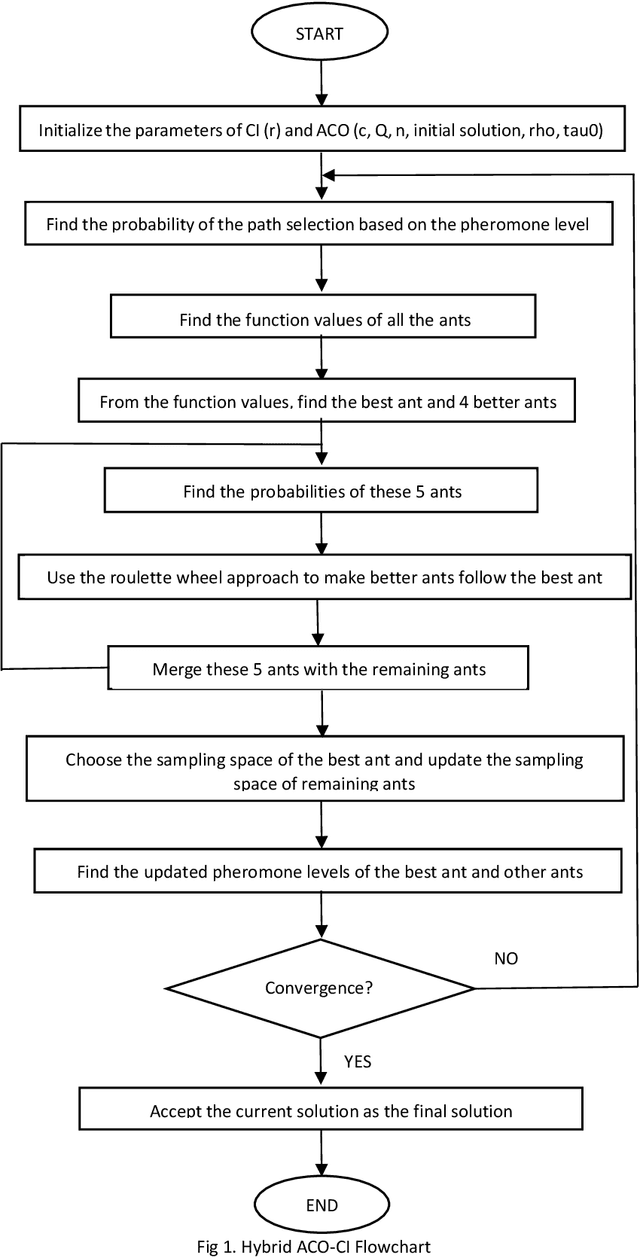
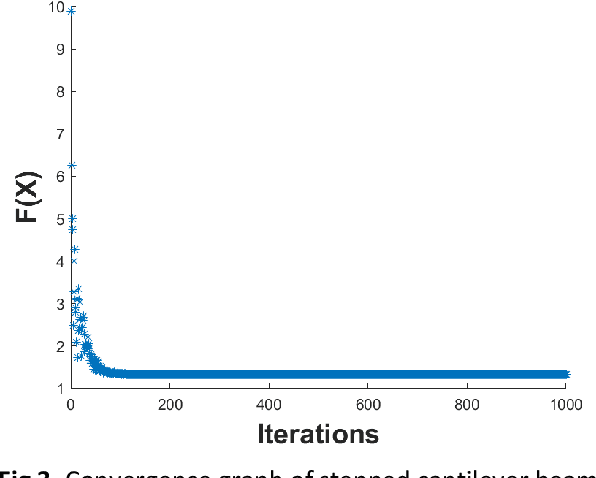
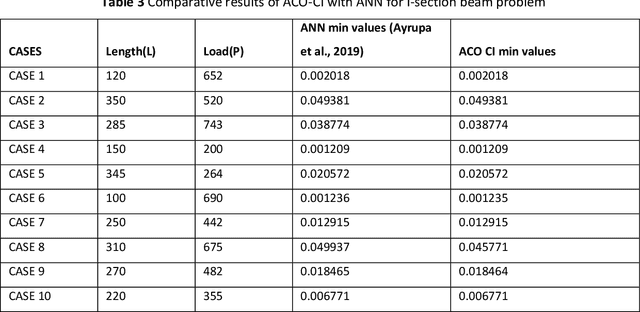
A range of complicated real-world problems have inspired the development of several optimization methods. Here, a novel hybrid version of the Ant colony optimization (ACO) method is developed using the sample space reduction technique of the Cohort Intelligence (CI) Algorithm. The algorithm is developed, and accuracy is tested by solving 35 standard benchmark test functions. Furthermore, the constrained version of the algorithm is used to solve two mechanical design problems involving stepped cantilever beams and I-section beams. The effectiveness of the proposed technique of solution is evaluated relative to contemporary algorithmic approaches that are already in use. The results show that our proposed hybrid ACO-CI algorithm will take lesser number of iterations to produce the desired output which means lesser computational time. For the minimization of weight of stepped cantilever beam and deflection in I-section beam a proposed hybrid ACO-CI algorithm yielded best results when compared to other existing algorithms. The proposed work could be investigate for variegated real world applications encompassing domains of engineering, combinatorial and health care problems.
Hardness of Independent Learning and Sparse Equilibrium Computation in Markov Games
Mar 22, 2023We consider the problem of decentralized multi-agent reinforcement learning in Markov games. A fundamental question is whether there exist algorithms that, when adopted by all agents and run independently in a decentralized fashion, lead to no-regret for each player, analogous to celebrated convergence results in normal-form games. While recent work has shown that such algorithms exist for restricted settings (notably, when regret is defined with respect to deviations to Markovian policies), the question of whether independent no-regret learning can be achieved in the standard Markov game framework was open. We provide a decisive negative resolution this problem, both from a computational and statistical perspective. We show that: - Under the widely-believed assumption that PPAD-hard problems cannot be solved in polynomial time, there is no polynomial-time algorithm that attains no-regret in general-sum Markov games when executed independently by all players, even when the game is known to the algorithm designer and the number of players is a small constant. - When the game is unknown, no algorithm, regardless of computational efficiency, can achieve no-regret without observing a number of episodes that is exponential in the number of players. Perhaps surprisingly, our lower bounds hold even for seemingly easier setting in which all agents are controlled by a a centralized algorithm. They are proven via lower bounds for a simpler problem we refer to as SparseCCE, in which the goal is to compute a coarse correlated equilibrium that is sparse in the sense that it can be represented as a mixture of a small number of product policies. The crux of our approach is a novel application of aggregation techniques from online learning, whereby we show that any algorithm for the SparseCCE problem can be used to compute approximate Nash equilibria for non-zero sum normal-form games.
Wide neural networks: From non-gaussian random fields at initialization to the NTK geometry of training
Apr 06, 2023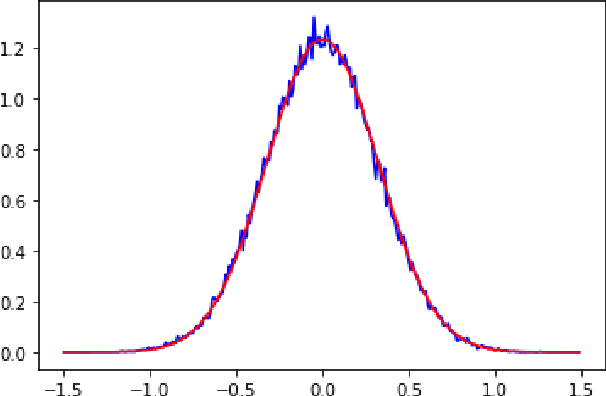
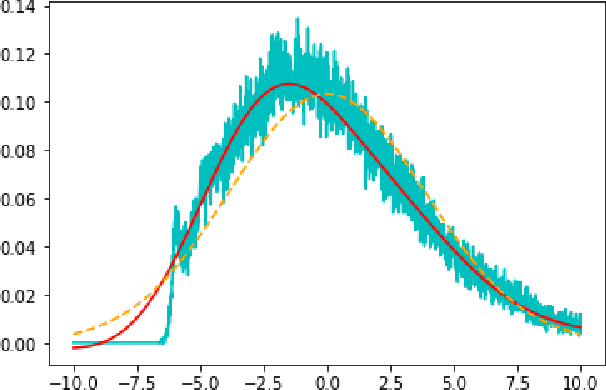
Recent developments in applications of artificial neural networks with over $n=10^{14}$ parameters make it extremely important to study the large $n$ behaviour of such networks. Most works studying wide neural networks have focused on the infinite width $n \to +\infty$ limit of such networks and have shown that, at initialization, they correspond to Gaussian processes. In this work we will study their behavior for large, but finite $n$. Our main contributions are the following: (1) The computation of the corrections to Gaussianity in terms of an asymptotic series in $n^{-\frac{1}{2}}$. The coefficients in this expansion are determined by the statistics of parameter initialization and by the activation function. (2) Controlling the evolution of the outputs of finite width $n$ networks, during training, by computing deviations from the limiting infinite width case (in which the network evolves through a linear flow). This improves previous estimates and yields sharper decay rates for the (finite width) NTK in terms of $n$, valid during the entire training procedure. As a corollary, we also prove that, with arbitrarily high probability, the training of sufficiently wide neural networks converges to a global minimum of the corresponding quadratic loss function. (3) Estimating how the deviations from Gaussianity evolve with training in terms of $n$. In particular, using a certain metric in the space of measures we find that, along training, the resulting measure is within $n^{-\frac{1}{2}}(\log n)^{1+}$ of the time dependent Gaussian process corresponding to the infinite width network (which is explicitly given by precomposing the initial Gaussian process with the linear flow corresponding to training in the infinite width limit).
Conformal Regression in Calorie Prediction for Team Jumbo-Visma
Apr 06, 2023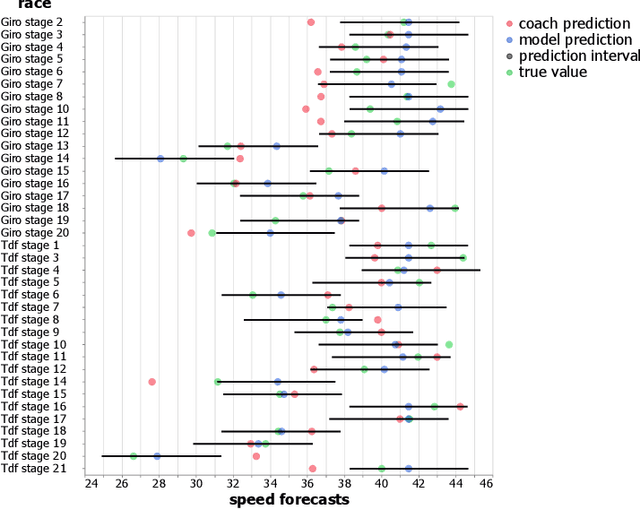
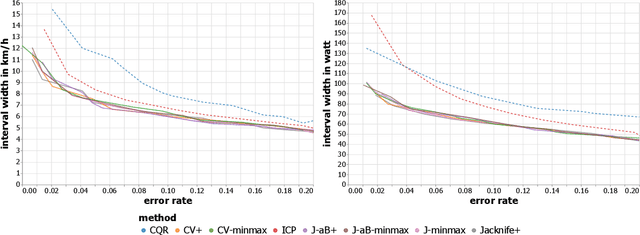
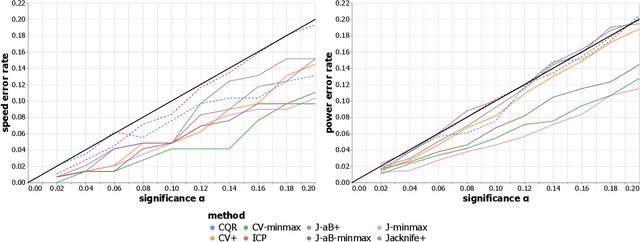
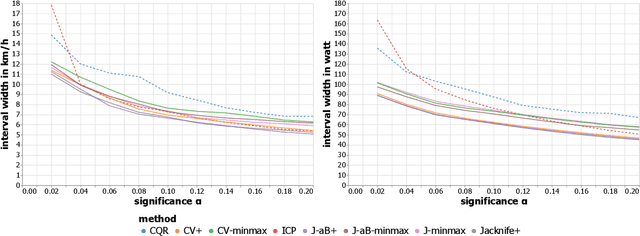
UCI WorldTour races, the premier men's elite road cycling tour, are grueling events that put riders' physical fitness and endurance to the test. The coaches of Team Jumbo-Visma have long been responsible for predicting the energy needs of each rider of the Dutch team for every race on the calendar. Those must be estimated to ensure riders have the energy and resources necessary to maintain a high level of performance throughout a race. This task, however, is both time-consuming and challenging, as it requires precise estimates of race speed and power output. Traditionally, the approach to predicting energy needs has relied on coaches' judgement and experience, but this method has its limitations and often leads to inaccurate predictions. In this paper, we propose a new, more effective approach to predicting energy needs for cycling races. By predicting the speed and power with regression models, we provide the coaches with calorie needs estimate for each individual rider per stage instantly. In addition, we compare methods to quantify uncertainty in estimating the speed and power of Team Jumbo-Visma riders for cycling races. The empirical analysis of the jackknife+, jackknife-minmax, jackknife-minmax-after-bootstrap, CV+, CV-minmax, conformalized quantile regression (CQR) and inductive conformal prediction (ICP) methods in conformal prediction reveals all methods except minmax based methods achieve valid prediction intervals while producing prediction intervals tight enough to be used for decision making. Furthermore, methods computing prediction intervals of fixed size produce significantly tighter intervals for low significance value. Among the methods computing intervals of varying length across the input space, namely the CQR and ICP methods, ICP computes tighter prediction intervals at larger significance level.
RADIFUSION: A multi-radiomics deep learning based breast cancer risk prediction model using sequential mammographic images with image attention and bilateral asymmetry refinement
Apr 01, 2023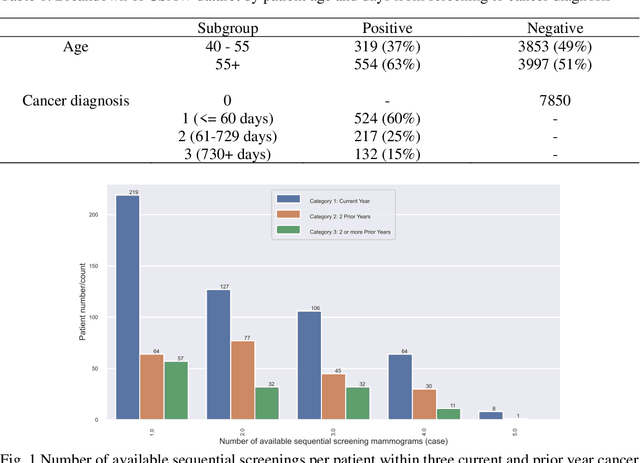
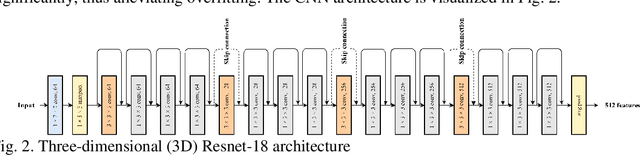

Breast cancer is a significant public health concern and early detection is critical for triaging high risk patients. Sequential screening mammograms can provide important spatiotemporal information about changes in breast tissue over time. In this study, we propose a deep learning architecture called RADIFUSION that utilizes sequential mammograms and incorporates a linear image attention mechanism, radiomic features, a new gating mechanism to combine different mammographic views, and bilateral asymmetry-based finetuning for breast cancer risk assessment. We evaluate our model on a screening dataset called Cohort of Screen-Aged Women (CSAW) dataset. Based on results obtained on the independent testing set consisting of 1,749 women, our approach achieved superior performance compared to other state-of-the-art models with area under the receiver operating characteristic curves (AUCs) of 0.905, 0.872 and 0.866 in the three respective metrics of 1-year AUC, 2-year AUC and > 2-year AUC. Our study highlights the importance of incorporating various deep learning mechanisms, such as image attention, radiomic features, gating mechanism, and bilateral asymmetry-based fine-tuning, to improve the accuracy of breast cancer risk assessment. We also demonstrate that our model's performance was enhanced by leveraging spatiotemporal information from sequential mammograms. Our findings suggest that RADIFUSION can provide clinicians with a powerful tool for breast cancer risk assessment.