 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Augmented Reality Remote Operation of Dual Arm Manipulators in Hot Boxes
Mar 28, 2023


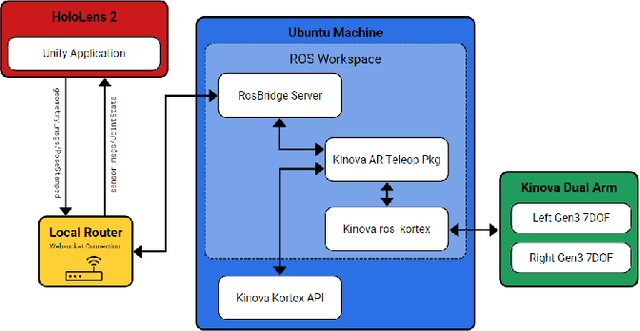
In nuclear isotope and chemistry laboratories, hot cells and gloveboxes provide scientists with a controlled and safe environment to perform experiments. Working on experiments in these isolated containment cells requires scientists to be physically present. For hot cell work today, scientists manipulate equipment and radioactive material inside through a bilateral mechanical control mechanism. Motions produced outside the cell with the master control levers are mechanically transferred to the internal grippers inside the shielded containment cell. There is a growing need to have the capability to conduct experiments within these cells remotely. A simple method to enable remote manipulations within hot cell and glovebox cells is to mount two robotic arms inside a box to mimic the motions of human hands. An AR application was built in this work to allow a user wearing a Microsoft HoloLens 2 headset to teleoperate dual arm manipulators by grasping robotic end-effector digital replicas in AR from a remote location. In addition to the real-time replica of the physical robotic arms in AR, the application enables users to view a live video stream attached to the robotic arms and parse a 3D point cloud of 3D objects in their remote AR environment for better situational awareness. This work also provides users with virtual fixture to assist in manipulation and other teleoperation tasks.
Fast Diffusion Sampler for Inverse Problems by Geometric Decomposition
Mar 10, 2023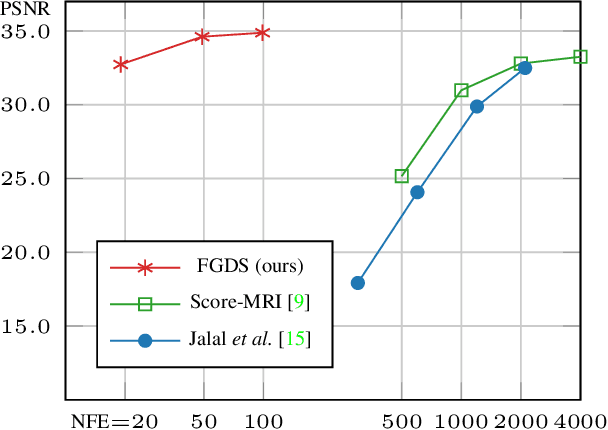
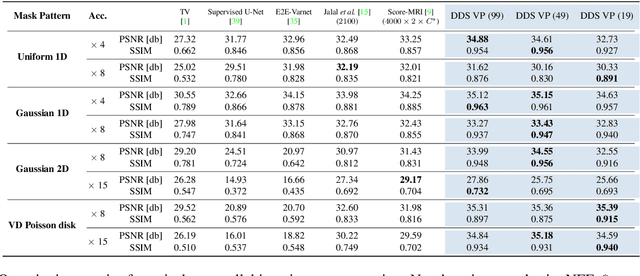
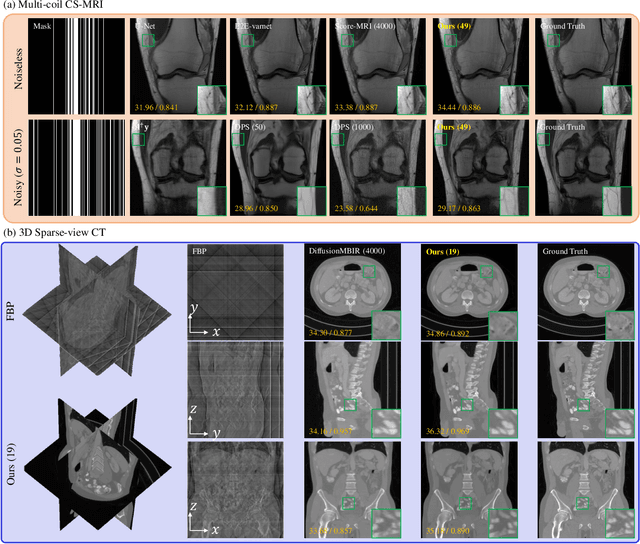

Diffusion models have shown exceptional performance in solving inverse problems. However, one major limitation is the slow inference time. While faster diffusion samplers have been developed for unconditional sampling, there has been limited research on conditional sampling in the context of inverse problems. In this study, we propose a novel and efficient diffusion sampling strategy that employs the geometric decomposition of diffusion sampling. Specifically, we discover that the samples generated from diffusion models can be decomposed into two orthogonal components: a ``denoised" component obtained by projecting the sample onto the clean data manifold, and a ``noise" component that induces a transition to the next lower-level noisy manifold with the addition of stochastic noise. Furthermore, we prove that, under some conditions on the clean data manifold, the conjugate gradient update for imposing conditioning from the denoised signal belongs to the clean manifold, resulting in a much faster and more accurate diffusion sampling. Our method is applicable regardless of the parameterization and setting (i.e., VE, VP). Notably, we achieve state-of-the-art reconstruction quality on challenging real-world medical inverse imaging problems, including multi-coil MRI reconstruction and 3D CT reconstruction. Moreover, our proposed method achieves more than 80 times faster inference time than the previous state-of-the-art method.
Dual Arm Impact-Aware Grasping through Time-Invariant Reference Spreading Control
Dec 01, 2022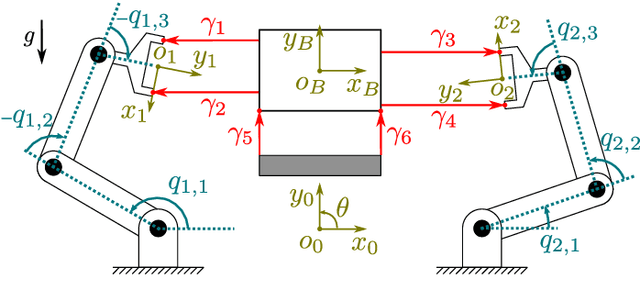
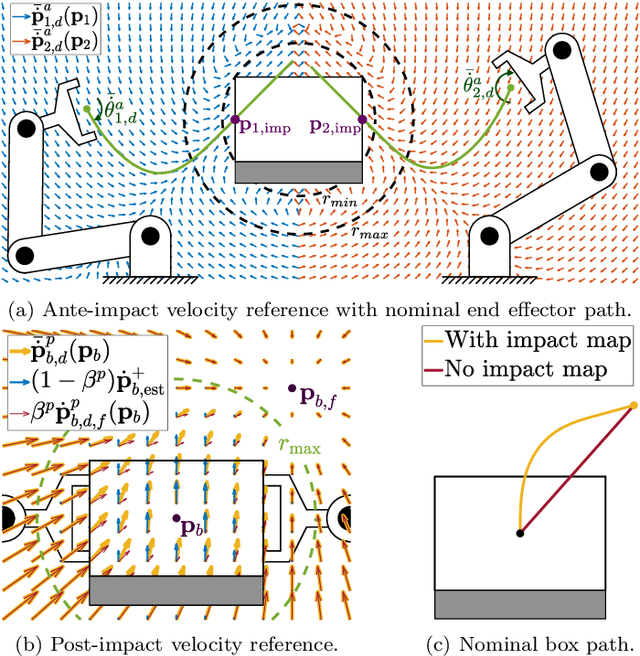
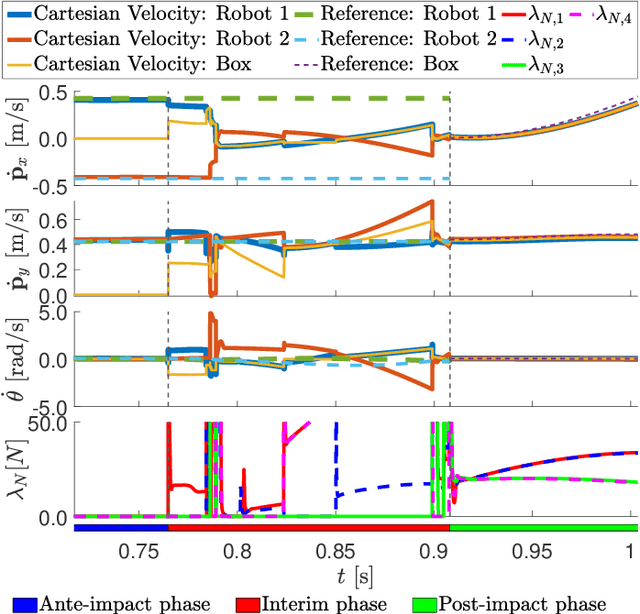
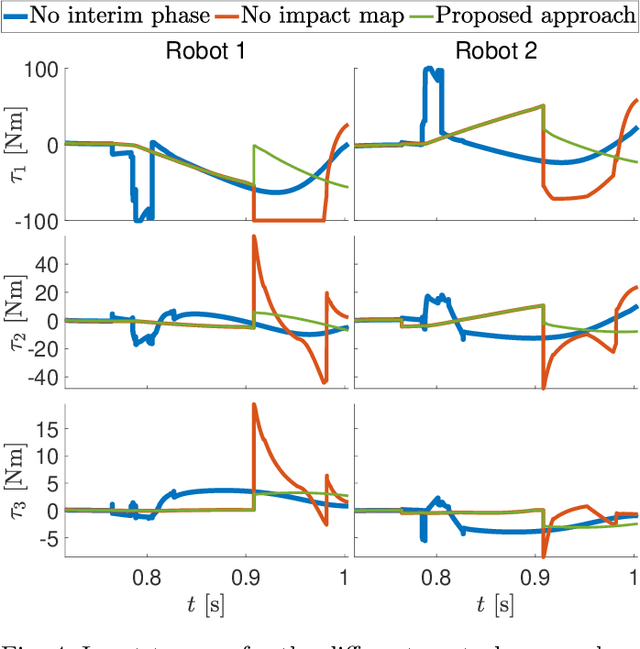
With the goal of increasing the speed and efficiency in robotic dual-arm manipulation, a novel control approach is presented that utilizes intentional simultaneous impacts to rapidly grasp objects. This approach uses the time-invariant reference spreading framework, in which partly-overlapping ante- and post-impact reference vector fields are used. These vector fields are coupled via the impact dynamics in proximity of the expected impact area, minimizing the otherwise large velocity errors after the impact and the corresponding large control efforts. A purely spatial task is introduced to strongly encourage the synchronization of impact times of the two arms. An interim-impact control phase provides robustness in the execution against the inevitable lack of exact impact simultaneity and the corresponding unreliable velocity error. In this interim phase, a position feedback signal is derived from the ante-impact velocity reference, which is used to enforce sustained contact in all contact points without using velocity error feedback. With an eye towards real-life implementation, the approach is formulated using a QP control framework, and is validated using numerical simulations on a realistic robot model with flexible joints and low-level torque control.
Complexity-calibrated Benchmarks for Machine Learning Reveal When Next-Generation Reservoir Computer Predictions Succeed and Mislead
Mar 25, 2023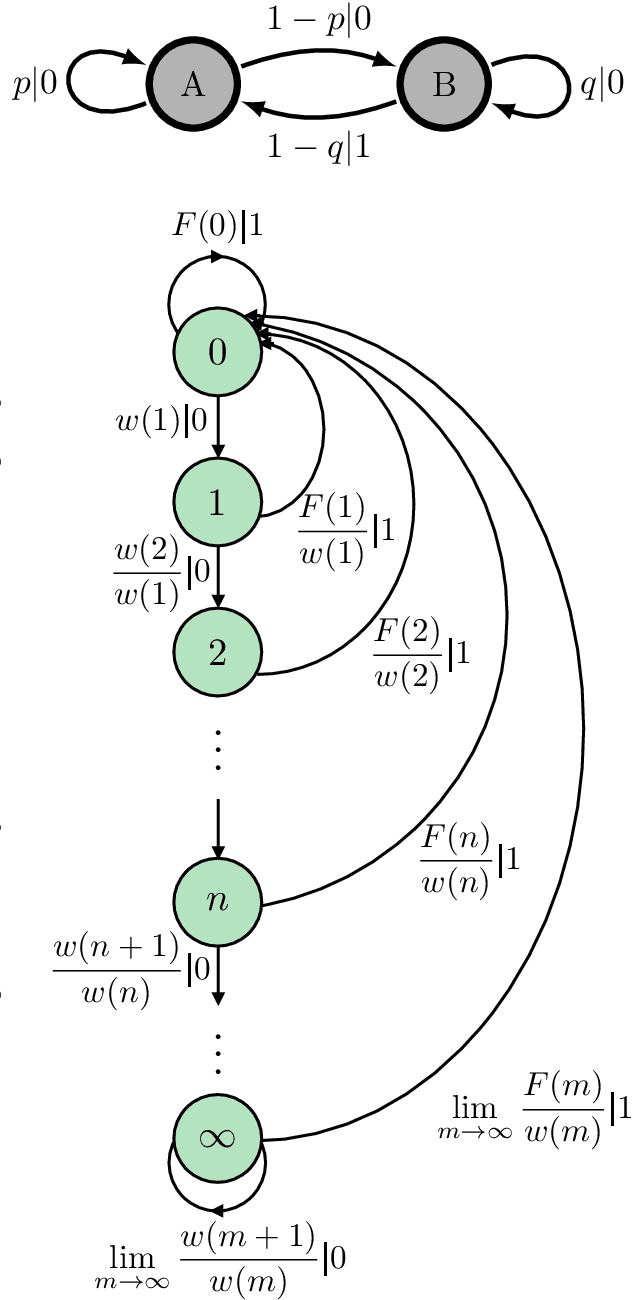
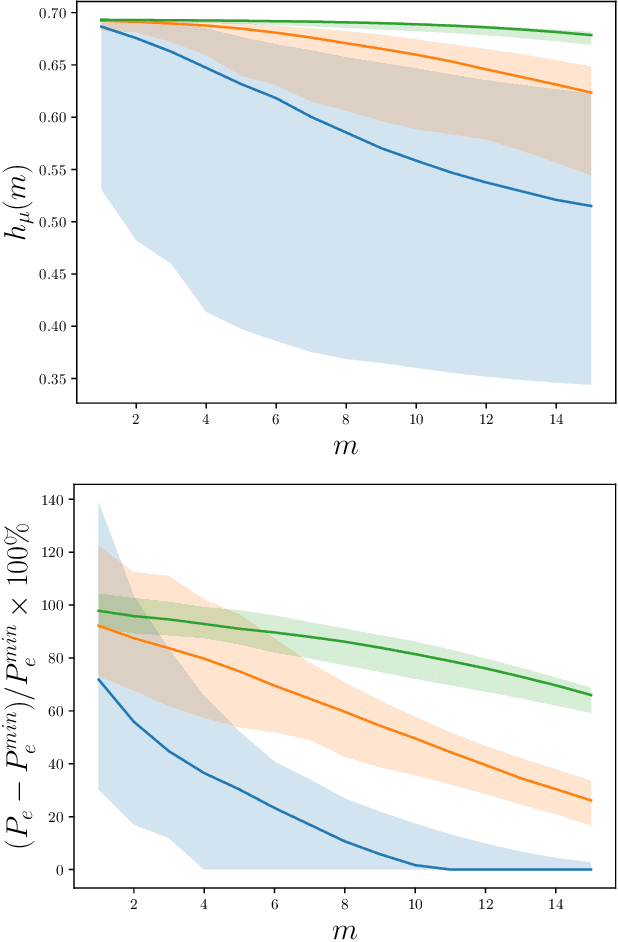
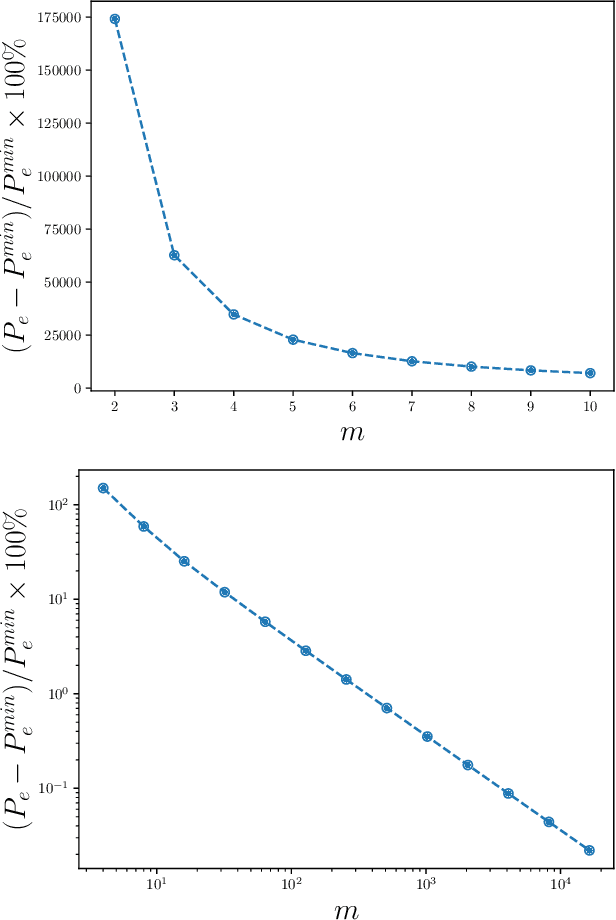
Recurrent neural networks are used to forecast time series in finance, climate, language, and from many other domains. Reservoir computers are a particularly easily trainable form of recurrent neural network. Recently, a "next-generation" reservoir computer was introduced in which the memory trace involves only a finite number of previous symbols. We explore the inherent limitations of finite-past memory traces in this intriguing proposal. A lower bound from Fano's inequality shows that, on highly non-Markovian processes generated by large probabilistic state machines, next-generation reservoir computers with reasonably long memory traces have an error probability that is at least ~ 60% higher than the minimal attainable error probability in predicting the next observation. More generally, it appears that popular recurrent neural networks fall far short of optimally predicting such complex processes. These results highlight the need for a new generation of optimized recurrent neural network architectures. Alongside this finding, we present concentration-of-measure results for randomly-generated but complex processes. One conclusion is that large probabilistic state machines -- specifically, large $\epsilon$-machines -- are key to generating challenging and structurally-unbiased stimuli for ground-truthing recurrent neural network architectures.
Image Moment Invariants to Rotational Motion Blur
Mar 25, 2023
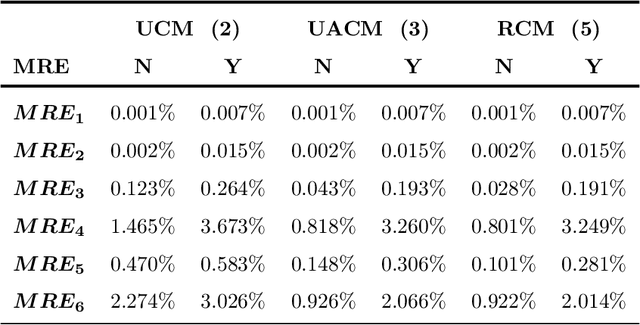
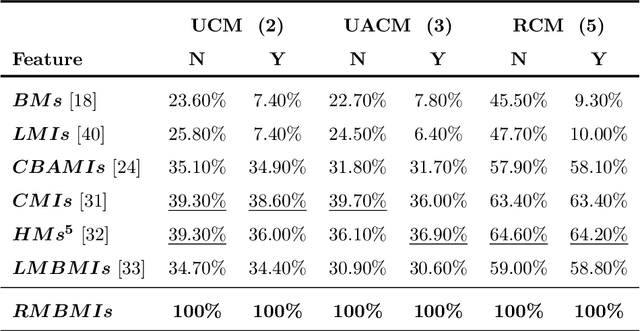

Rotational motion blur caused by the circular motion of the camera or/and object is common in life. Identifying objects from images affected by rotational motion blur is challenging because this image degradation severely impacts image quality. Therefore, it is meaningful to develop image invariant features under rotational motion blur and then use them in practical tasks, such as object classification and template matching. This paper proposes a novel method to generate image moment invariants under general rotational motion blur and provides some instances. Further, we achieve their invariance to similarity transform. To the best of our knowledge, this is the first time that moment invariants for rotational motion blur have been proposed in the literature. We conduct extensive experiments on various image datasets disturbed by similarity transform and rotational motion blur to test these invariants' numerical stability and robustness to image noise. We also demonstrate their performance in image classification and handwritten digit recognition. Current state-of-the-art blur moment invariants and deep neural networks are chosen for comparison. Our results show that the moment invariants proposed in this paper significantly outperform other features in various tasks.
Body-UAV Near-Ground LoRa Links through a Mediterranean Forest
Mar 25, 2023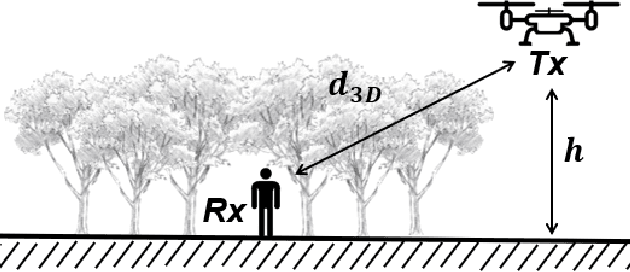
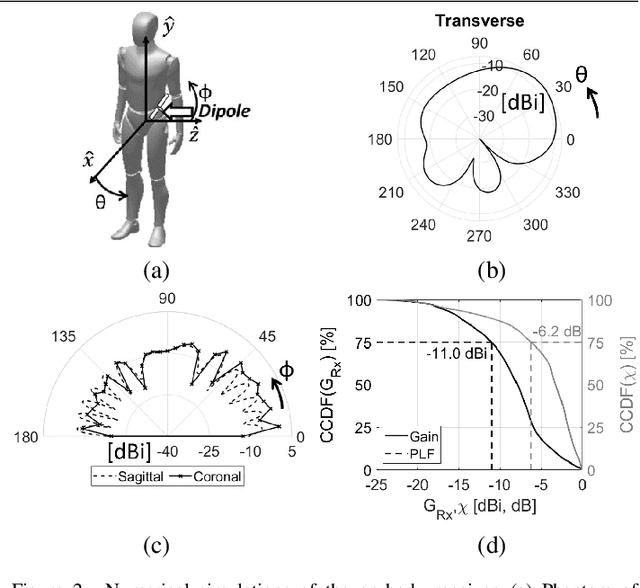
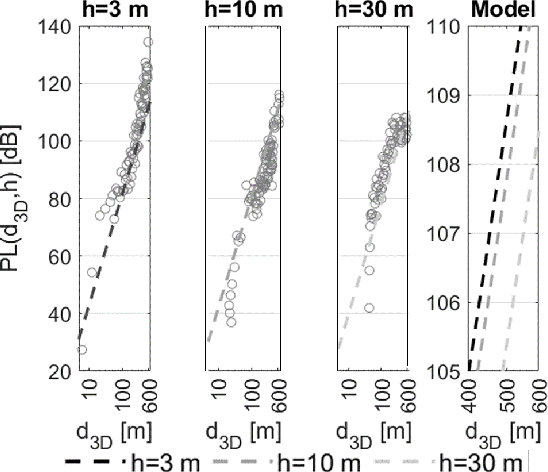
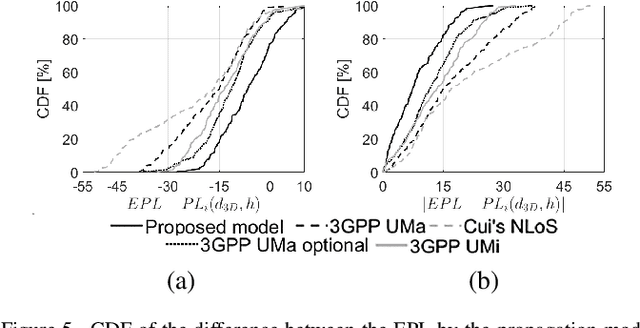
LoRa low-power wide-area network protocol has recently gained attention for deploying ad-hoc search and rescue (SaR) systems. They could be empowered by exploiting body-UAV links that enable communications between a body-worn radio and a UAV-mounted one. However, to employ UAVs effectively, knowledge of the signal's propagation in the environment is required. Otherwise, communications and localization could be hindered. The radio range, the packet delivery ratio (PDR), and the large- and small-scale fading of body-UAV LoRa links at 868 MHz when the radio wearer is in a Mediterranean forest are here characterized for the first time with a near-ground UAV having a maximum flying height of 30 m. A log-distance model accounting for the body shadowing and the wearer's movements is derived. Over the full LoRa radio range of about 600 m, the new model predicts the path loss (PL) better than the state-of-the-art ones, with a reduction of the median error even by 10 dB. The observed small-scale fading is severe and follows a Nakagami-m distribution. Extensions of the model for similar scenarios can be drawn through appropriate corrective factors.
Hard Nominal Example-aware Template Mutual Matching for Industrial Anomaly Detection
Mar 29, 2023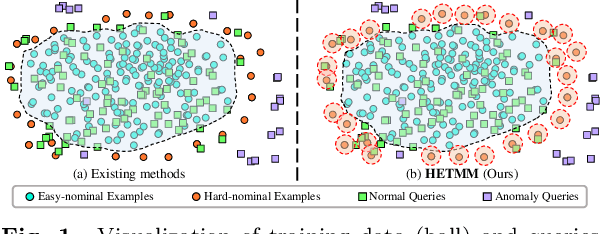
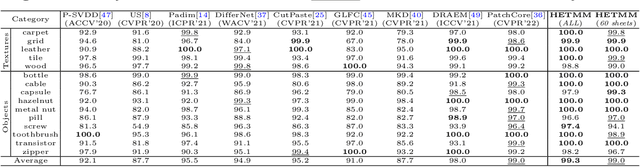
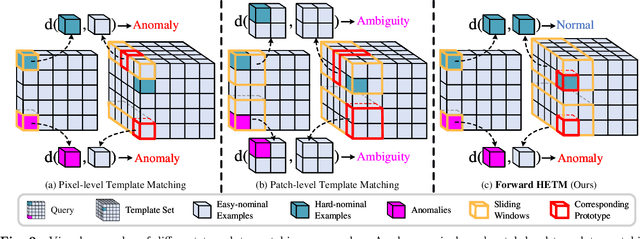
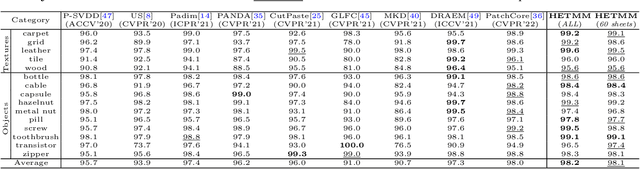
Anomaly detectors are widely used in industrial production to detect and localize unknown defects in query images. These detectors are trained on nominal images and have shown success in distinguishing anomalies from most normal samples. However, hard-nominal examples are scattered and far apart from most normalities, they are often mistaken for anomalies by existing anomaly detectors. To address this problem, we propose a simple yet efficient method: \textbf{H}ard Nominal \textbf{E}xample-aware \textbf{T}emplate \textbf{M}utual \textbf{M}atching (HETMM). Specifically, \textit{HETMM} aims to construct a robust prototype-based decision boundary, which can precisely distinguish between hard-nominal examples and anomalies, yielding fewer false-positive and missed-detection rates. Moreover, \textit{HETMM} mutually explores the anomalies in two directions between queries and the template set, and thus it is capable to capture the logical anomalies. This is a significant advantage over most anomaly detectors that frequently fail to detect logical anomalies. Additionally, to meet the speed-accuracy demands, we further propose \textbf{P}ixel-level \textbf{T}emplate \textbf{S}election (PTS) to streamline the original template set. \textit{PTS} selects cluster centres and hard-nominal examples to form a tiny set, maintaining the original decision boundaries. Comprehensive experiments on five real-world datasets demonstrate that our methods yield outperformance than existing advances under the real-time inference speed. Furthermore, \textit{HETMM} can be hot-updated by inserting novel samples, which may promptly address some incremental learning issues.
Using Connected Vehicle Trajectory Data to Evaluate the Effects of Speeding
Mar 29, 2023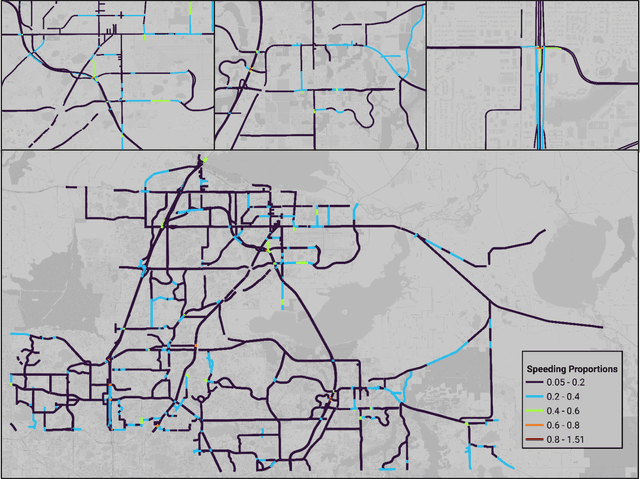
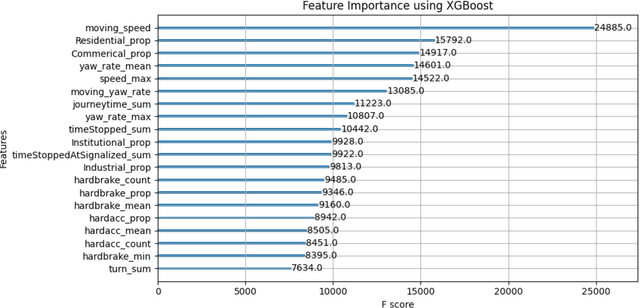
Speeding has been and continues to be a major contributing factor to traffic fatalities. Various transportation agencies have proposed speed management strategies to reduce the amount of speeding on arterials. While there have been various studies done on the analysis of speeding proportions above the speed limit, few studies have considered the effect on the individual's journey. Many studies utilized speed data from detectors, which is limited in that there is no information of the route that the driver took. This study aims to explore the effects of various roadway features an individual experiences for a given journey on speeding proportions. Connected vehicle trajectory data was utilized to identify the path that a driver took, along with the vehicle related variables. The level of speeding proportion is predicted using multiple learning models. The model with the best performance, Extreme Gradient Boosting, achieved an accuracy of 0.756. The proposed model can be used to understand how the environment and vehicle's path effects the drivers' speeding behavior, as well as predict the areas with high levels of speeding proportions. The results suggested that features related to an individual driver's trip, i.e., total travel time, has a significant contribution towards speeding. Features that are related to the environment of the individual driver's trip, i.e., proportion of residential area, also had a significant effect on reducing speeding proportions. It is expected that the findings could help inform transportation agencies more on the factors related to speeding for an individual driver's trip.
CoordFill: Efficient High-Resolution Image Inpainting via Parameterized Coordinate Querying
Mar 15, 2023
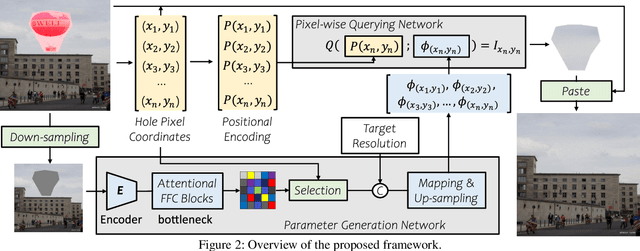
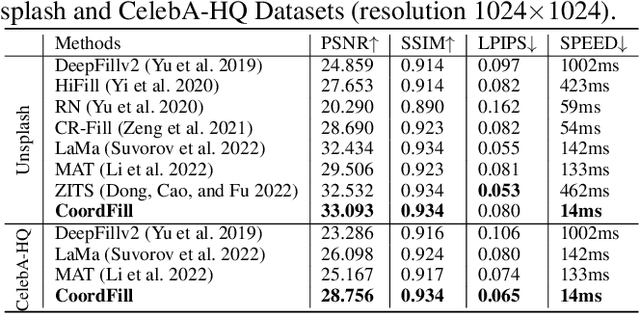
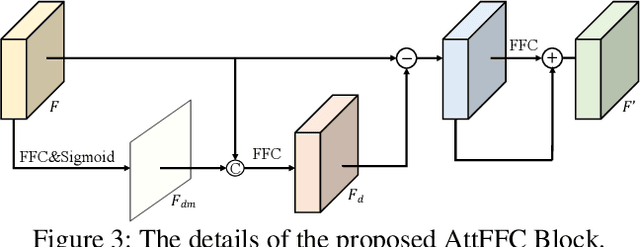
Image inpainting aims to fill the missing hole of the input. It is hard to solve this task efficiently when facing high-resolution images due to two reasons: (1) Large reception field needs to be handled for high-resolution image inpainting. (2) The general encoder and decoder network synthesizes many background pixels synchronously due to the form of the image matrix. In this paper, we try to break the above limitations for the first time thanks to the recent development of continuous implicit representation. In detail, we down-sample and encode the degraded image to produce the spatial-adaptive parameters for each spatial patch via an attentional Fast Fourier Convolution(FFC)-based parameter generation network. Then, we take these parameters as the weights and biases of a series of multi-layer perceptron(MLP), where the input is the encoded continuous coordinates and the output is the synthesized color value. Thanks to the proposed structure, we only encode the high-resolution image in a relatively low resolution for larger reception field capturing. Then, the continuous position encoding will be helpful to synthesize the photo-realistic high-frequency textures by re-sampling the coordinate in a higher resolution. Also, our framework enables us to query the coordinates of missing pixels only in parallel, yielding a more efficient solution than the previous methods. Experiments show that the proposed method achieves real-time performance on the 2048$\times$2048 images using a single GTX 2080 Ti GPU and can handle 4096$\times$4096 images, with much better performance than existing state-of-the-art methods visually and numerically. The code is available at: https://github.com/NiFangBaAGe/CoordFill.
Dynamic Graph Convolution Network with Spatio-Temporal Attention Fusion for Traffic Flow Prediction
Feb 24, 2023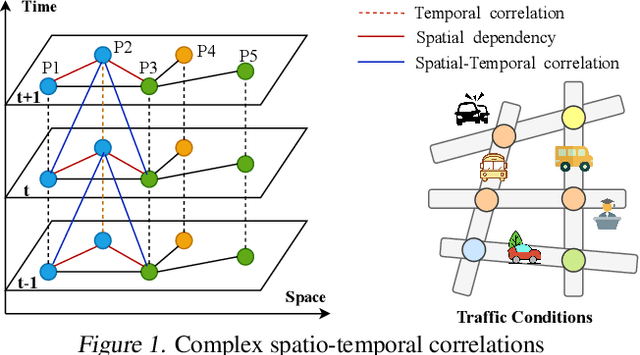
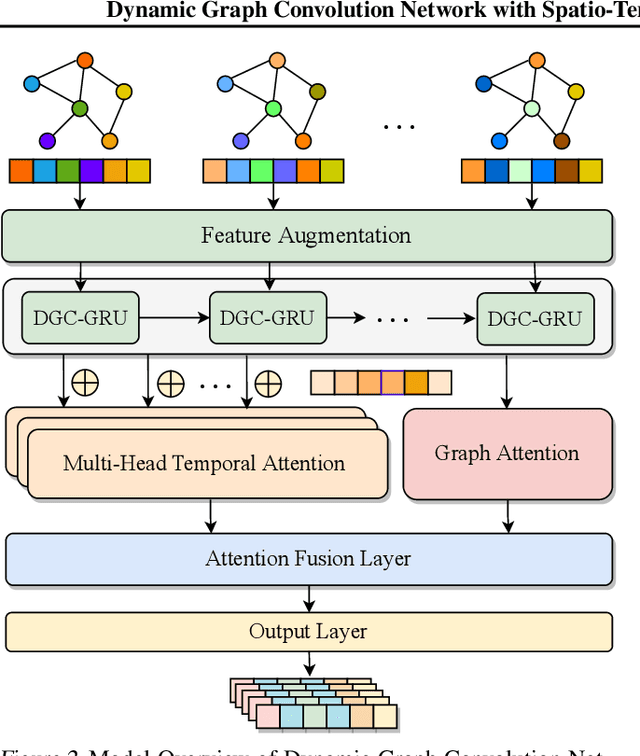
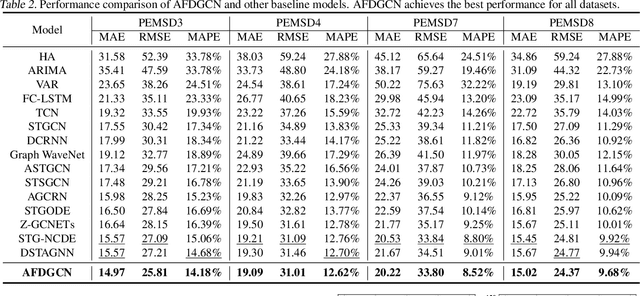
Accurate and real-time traffic state prediction is of great practical importance for urban traffic control and web mapping services (e.g. Google Maps). With the support of massive data, deep learning methods have shown their powerful capability in capturing the complex spatio-temporal patterns of road networks. However, existing approaches use independent components to model temporal and spatial dependencies and thus ignore the heterogeneous characteristics of traffic flow that vary with time and space. In this paper, we propose a novel dynamic graph convolution network with spatio-temporal attention fusion. The method not only captures local spatio-temporal information that changes over time, but also comprehensively models long-distance and multi-scale spatio-temporal patterns based on the fusion mechanism of temporal and spatial attention. This design idea can greatly improve the spatio-temporal perception of the model. We conduct extensive experiments in 4 real-world datasets to demonstrate that our model achieves state-of-the-art performance compared to 22 baseline models.