 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards an Hybrid Hodgkin-Huxley Action Potential Generation Model
Mar 15, 2023

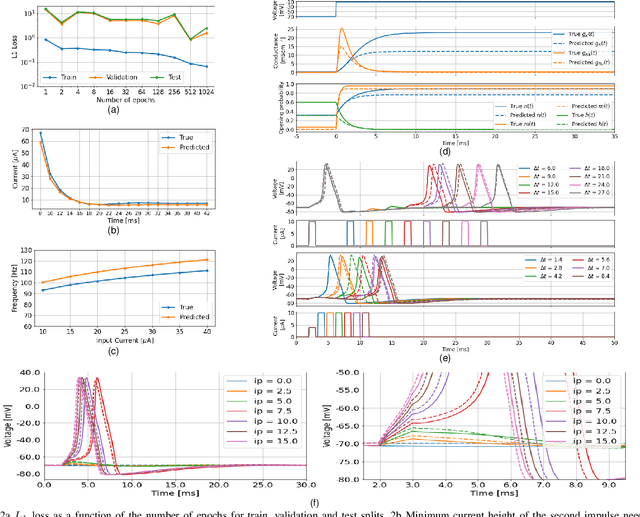

Mathematical models for the generation of the action potential can improve the understanding of physiological mechanisms that are consequence of the electrical activity in neurons. In such models, some equations involving empirically obtained functions of the membrane potential are usually defined. The best known of these models, the Hodgkin-Huxley model, is an example of this paradigm since it defines the conductances of ion channels in terms of the opening and closing rates of each type of gate present in the channels. These functions need to be derived from laboratory measurements that are often very expensive and produce little data because they involve a time-space-independent measurement of the voltage in a single channel of the cell membrane. In this work, we investigate the possibility of finding the Hodgkin-Huxley model's parametric functions using only two simple measurements (the membrane voltage as a function of time and the injected current that triggered that voltage) and applying Deep Learning methods to estimate these functions. This would result in an hybrid model of the action potential generation composed by the original Hodgkin-Huxley equations and an Artificial Neural Network that requires a small set of easy-to-perform measurements to be trained. Experiments were carried out using data generated from the original Hodgkin-Huxley model, and results show that a simple two-layer artificial neural network (ANN) architecture trained on a minimal amount of data can learn to model some of the fundamental proprieties of the action potential generation by estimating the model's rate functions.
$β^{4}$-IRT: A New $β^{3}$-IRT with Enhanced Discrimination Estimation
Mar 30, 2023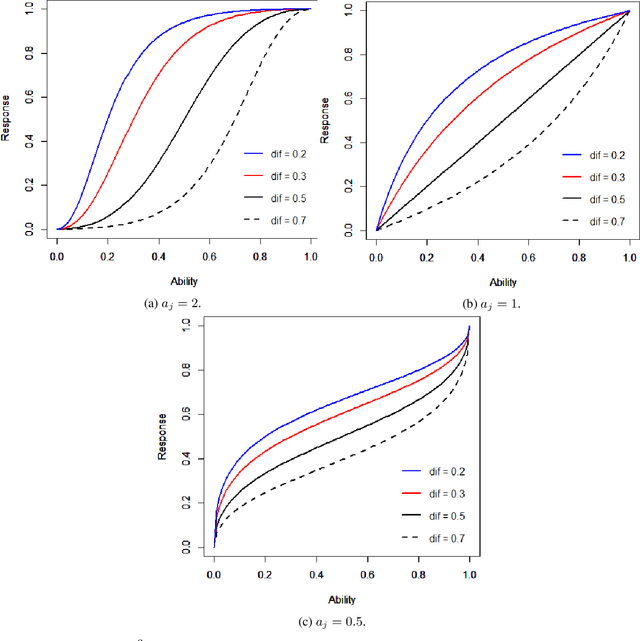
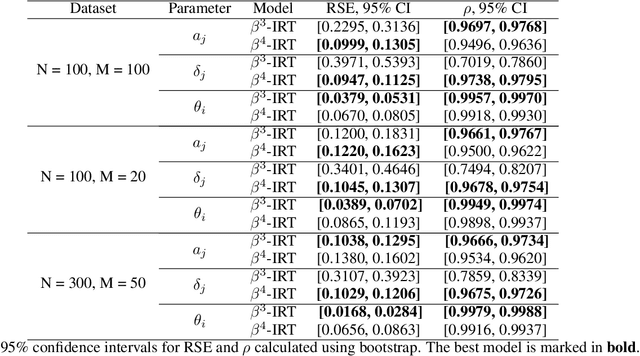
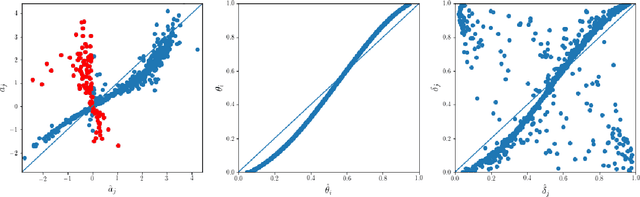

Item response theory aims to estimate respondent's latent skills from their responses in tests composed of items with different levels of difficulty. Several models of item response theory have been proposed for different types of tasks, such as binary or probabilistic responses, response time, multiple responses, among others. In this paper, we propose a new version of $\beta^3$-IRT, called $\beta^{4}$-IRT, which uses the gradient descent method to estimate the model parameters. In $\beta^3$-IRT, abilities and difficulties are bounded, thus we employ link functions in order to turn $\beta^{4}$-IRT into an unconstrained gradient descent process. The original $\beta^3$-IRT had a symmetry problem, meaning that, if an item was initialised with a discrimination value with the wrong sign, e.g. negative when the actual discrimination should be positive, the fitting process could be unable to recover the correct discrimination and difficulty values for the item. In order to tackle this limitation, we modelled the discrimination parameter as the product of two new parameters, one corresponding to the sign and the second associated to the magnitude. We also proposed sensible priors for all parameters. We performed experiments to compare $\beta^{4}$-IRT and $\beta^3$-IRT regarding parameter recovery and our new version outperformed the original $\beta^3$-IRT. Finally, we made $\beta^{4}$-IRT publicly available as a Python package, along with the implementation of $\beta^3$-IRT used in our experiments.
Automatic detection of aerial survey ground control points based on Yolov5-OBB
Mar 06, 2023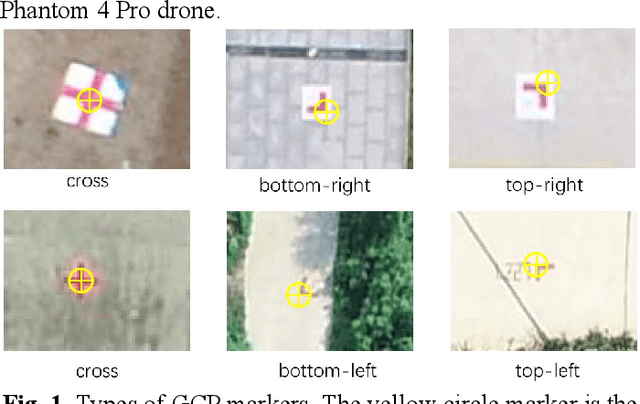
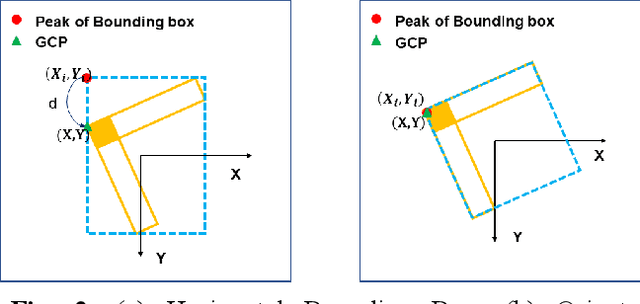
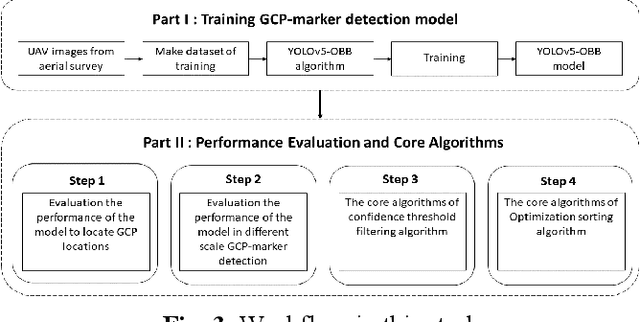
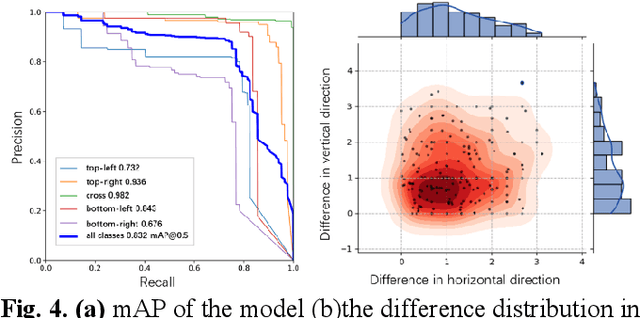
The use of ground control points (GCPs) for georeferencing is the most common strategy in unmanned aerial vehicle (UAV) photogrammetry, but at the same time their collection represents the most time-consuming and expensive part of UAV campaigns. Recently, deep learning has been rapidly developed in the field of small object detection. In this letter, to automatically extract coordinates information of ground control points (GCPs) by detecting GCP-markers in UAV images, we propose a solution that uses a deep learning-based architecture, YOLOv5-OBB, combined with a confidence threshold filtering algorithm and an optimal ranking algorithm. We applied our proposed method to a dataset collected by DJI Phantom 4 Pro drone and obtained good detection performance with the mean Average Precision (AP) of 0.832 and the highest AP of 0.982 for the cross-type GCP-markers. The proposed method can be a promising tool for future implementation of the end-to-end aerial triangulation process.
Learning Object Manipulation With Under-Actuated Impulse Generator Arrays
Mar 06, 2023

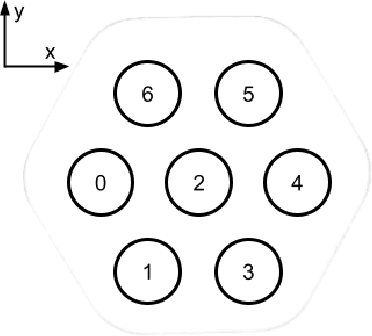
For more than half a century, vibratory bowl feeders have been the standard in automated assembly for singulation, orientation, and manipulation of small parts. Unfortunately, these feeders are expensive, noisy, and highly specialized on a single part design bases. We consider an alternative device and learning control method for singulation, orientation, and manipulation by means of seven fixed-position variable-energy solenoid impulse actuators located beneath a semi-rigid part supporting surface. Using computer vision to provide part pose information, we tested various machine learning (ML) algorithms to generate a control policy that selects the optimal actuator and actuation energy. Our manipulation test object is a 6-sided craps-style die. Using the most suitable ML algorithm, we were able to flip the die to any desired face 30.4\% of the time with a single impulse, and 51.3\% with two chosen impulses, versus a random policy succeeding 5.1\% of the time (that is, a randomly chosen impulse delivered by a randomly chosen solenoid).
Spatiotemporal Capsule Neural Network for Vehicle Trajectory Prediction
Mar 06, 2023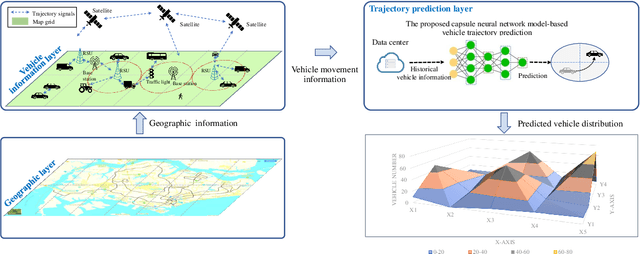
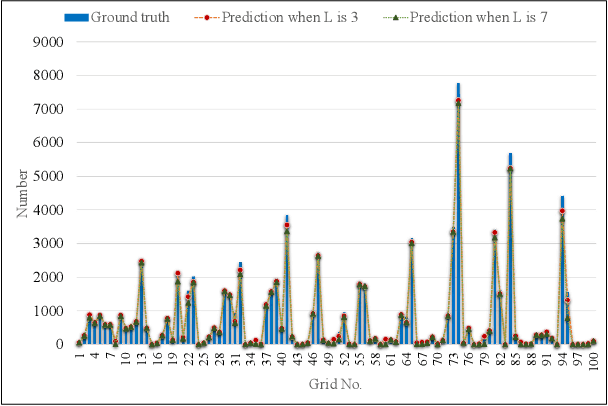

Through advancement of the Vehicle-to-Everything (V2X) network, road safety, energy consumption, and traffic efficiency can be significantly improved. An accurate vehicle trajectory prediction benefits communication traffic management and network resource allocation for the real-time application of the V2X network. Recurrent neural networks and their variants have been reported in recent research to predict vehicle mobility. However, the spatial attribute of vehicle movement behavior has been overlooked, resulting in incomplete information utilization. To bridge this gap, we put forward for the first time a hierarchical trajectory prediction structure using the capsule neural network (CapsNet) with three sequential components. First, the geographic information is transformed into a grid map presentation, describing vehicle mobility distribution spatially and temporally. Second, CapsNet serves as the core model to embed local temporal and global spatial correlation through hierarchical capsules. Finally, extensive experiments conducted on actual taxi mobility data collected in Porto city (Portugal) and Singapore show that the proposed method outperforms the state-of-the-art methods.
Understanding Time Variations of DNN Inference in Autonomous Driving
Sep 12, 2022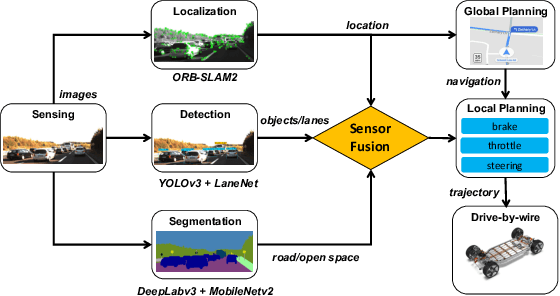
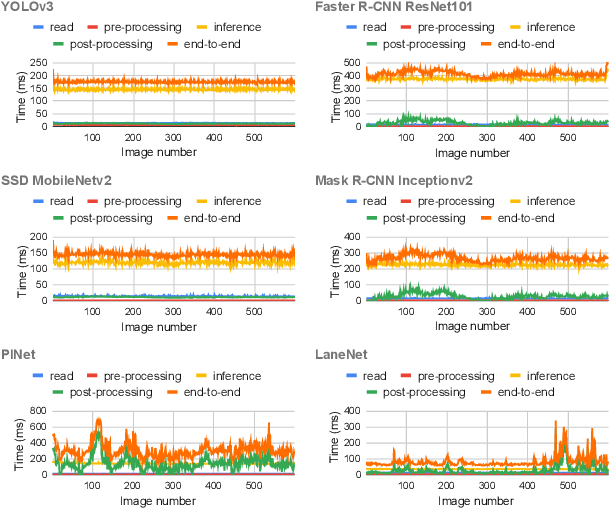
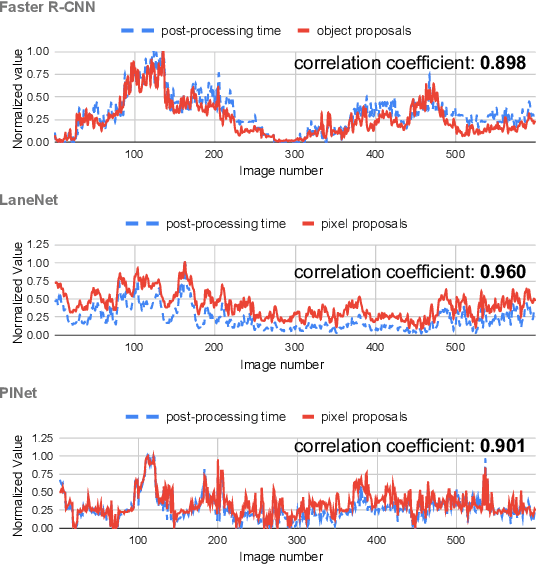
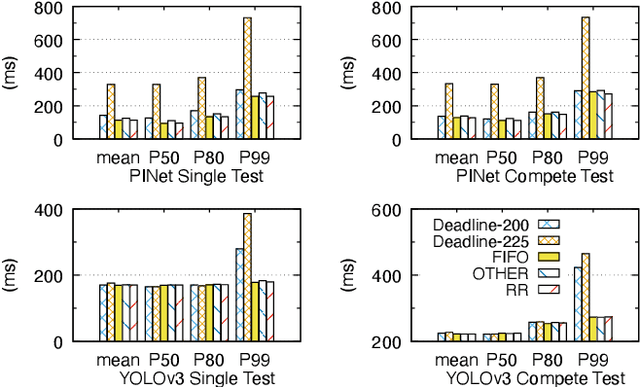
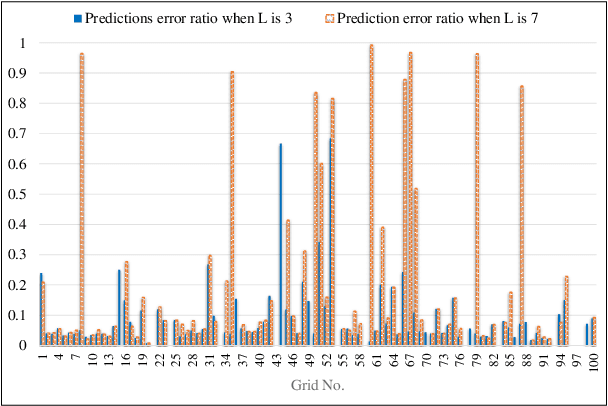
Deep neural networks (DNNs) are widely used in autonomous driving due to their high accuracy for perception, decision, and control. In safety-critical systems like autonomous driving, executing tasks like sensing and perception in real-time is vital to the vehicle's safety, which requires the application's execution time to be predictable. However, non-negligible time variations are observed in DNN inference. Current DNN inference studies either ignore the time variation issue or rely on the scheduler to handle it. None of the current work explains the root causes of DNN inference time variations. Understanding the time variations of the DNN inference becomes a fundamental challenge in real-time scheduling for autonomous driving. In this work, we analyze the time variation in DNN inference in fine granularity from six perspectives: data, I/O, model, runtime, hardware, and end-to-end perception system. Six insights are derived in understanding the time variations for DNN inference.
Low Latency Video Denoising for Online Conferencing Using CNN Architectures
Feb 17, 2023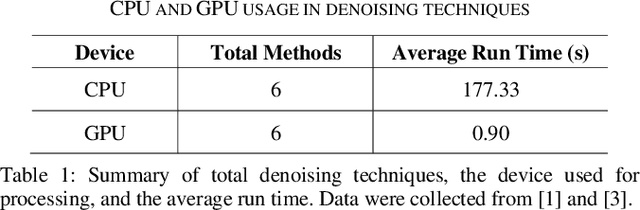
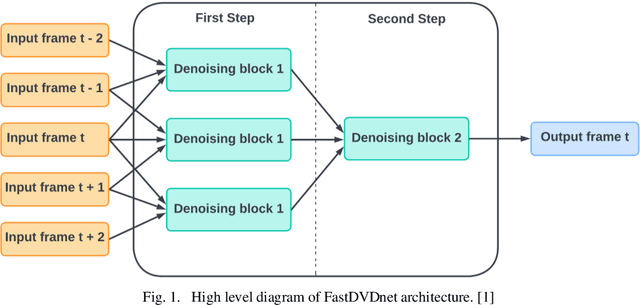
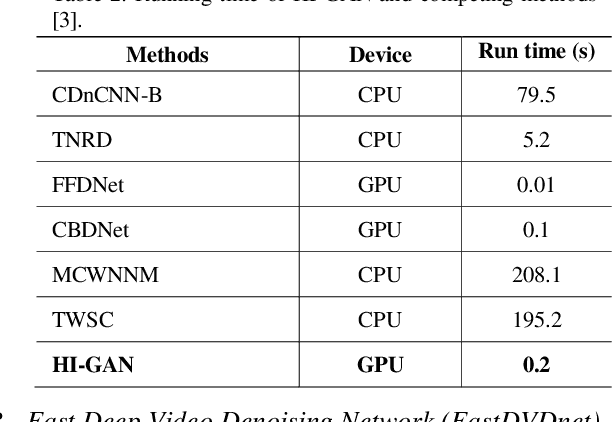
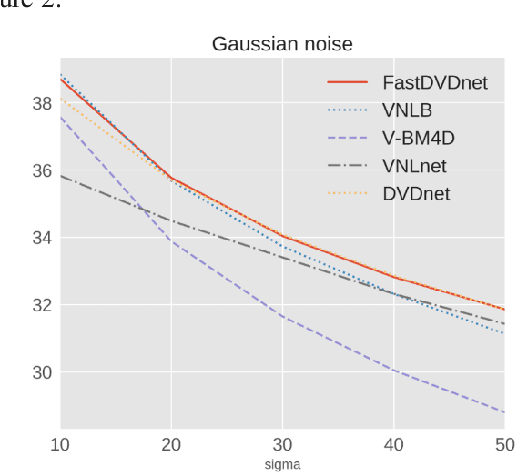
In this paper, we propose a pipeline for real-time video denoising with low runtime cost and high perceptual quality. The vast majority of denoising studies focus on image denoising. However, a minority of research works focusing on video denoising do so with higher performance costs to obtain higher quality while maintaining temporal coherence. The approach we introduce in this paper leverages the advantages of both image and video-denoising architectures. Our pipeline first denoises the keyframes or one-fifth of the frames using HI-GAN blind image denoising architecture. Then, the remaining four-fifths of the noisy frames and the denoised keyframe data are fed into the FastDVDnet video denoising model. The final output is rendered in the user's display in real-time. The combination of these low-latency neural network architectures produces real-time denoising with high perceptual quality with applications in video conferencing and other real-time media streaming systems. A custom noise detector analyzer provides real-time feedback to adapt the weights and improve the models' output.
Test-Time Adaptation with Principal Component Analysis
Sep 13, 2022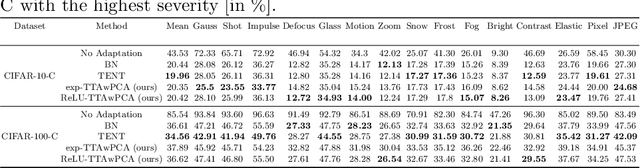
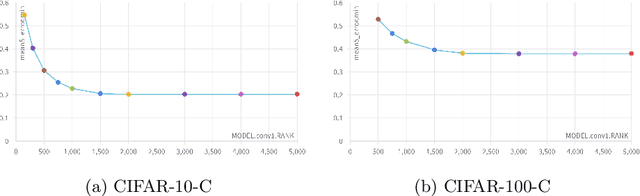

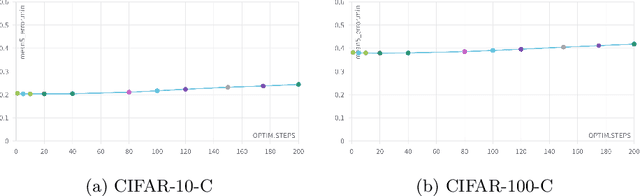
Machine Learning models are prone to fail when test data are different from training data, a situation often encountered in real applications known as distribution shift. While still valid, the training-time knowledge becomes less effective, requiring a test-time adaptation to maintain high performance. Following approaches that assume batch-norm layer and use their statistics for adaptation, we propose a Test-Time Adaptation with Principal Component Analysis (TTAwPCA), which presumes a fitted PCA and adapts at test time a spectral filter based on the singular values of the PCA for robustness to corruptions. TTAwPCA combines three components: the output of a given layer is decomposed using a Principal Component Analysis (PCA), filtered by a penalization of its singular values, and reconstructed with the PCA inverse transform. This generic enhancement adds fewer parameters than current methods. Experiments on CIFAR-10-C and CIFAR- 100-C demonstrate the effectiveness and limits of our method using a unique filter of 2000 parameters.
Data drift correction via time-varying importance weight estimator
Oct 04, 2022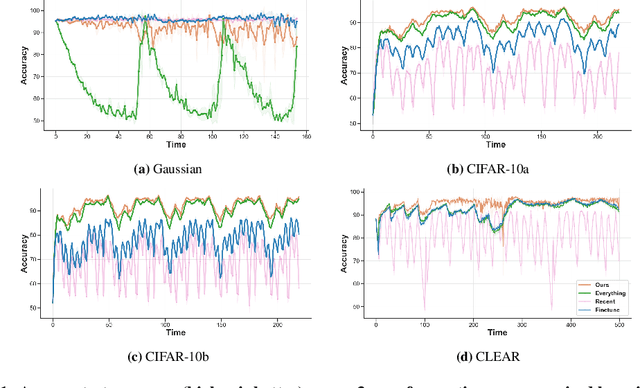

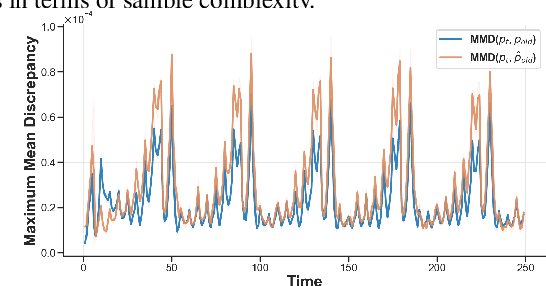
Real-world deployment of machine learning models is challenging when data evolves over time. And data does evolve over time. While no model can work when data evolves in an arbitrary fashion, if there is some pattern to these changes, we might be able to design methods to address it. This paper addresses situations when data evolves gradually. We introduce a novel time-varying importance weight estimator that can detect gradual shifts in the distribution of data. Such an importance weight estimator allows the training method to selectively sample past data -- not just similar data from the past like a standard importance weight estimator would but also data that evolved in a similar fashion in the past. Our time-varying importance weight is quite general. We demonstrate different ways of implementing it that exploit some known structure in the evolution of data. We demonstrate and evaluate this approach on a variety of problems ranging from supervised learning tasks (multiple image classification datasets) where the data undergoes a sequence of gradual shifts of our design to reinforcement learning tasks (robotic manipulation and continuous control) where data undergoes a shift organically as the policy or the task changes.
Learning Spatio-Temporal Aggregations for Large-Scale Capacity Expansion Problems
Mar 16, 2023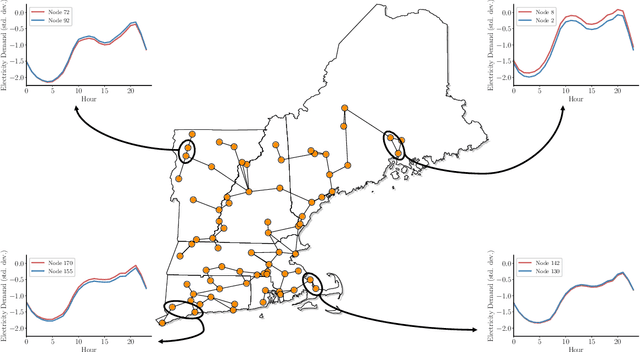
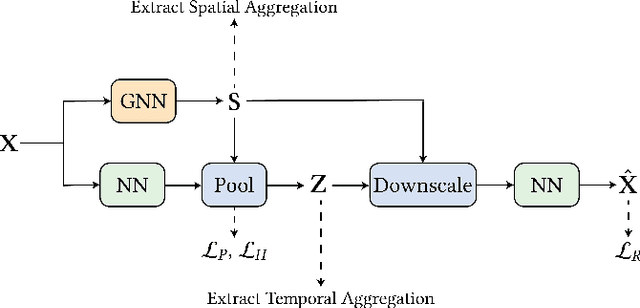
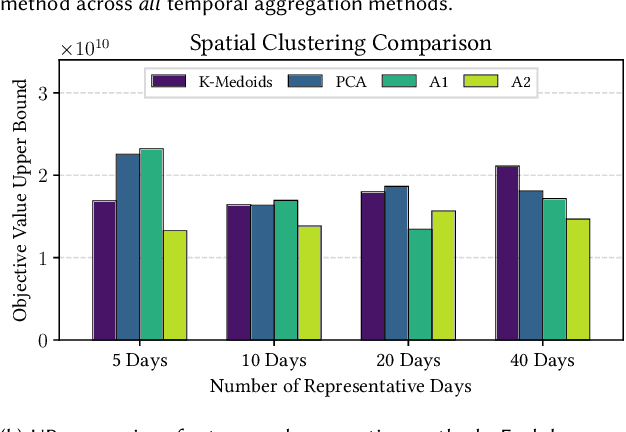
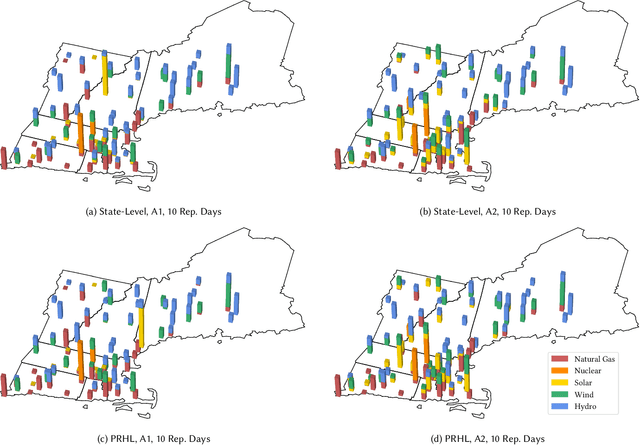
Effective investment planning decisions are crucial to ensure cyber-physical infrastructures satisfy performance requirements over an extended time horizon. Computing these decisions often requires solving Capacity Expansion Problems (CEPs). In the context of regional-scale energy systems, these problems are prohibitively expensive to solve due to large network sizes, heterogeneous node characteristics, and a large number of operational periods. To maintain tractability, traditional approaches aggregate network nodes and/or select a set of representative time periods. Often, these reductions do not capture supply-demand variations that crucially impact CEP costs and constraints, leading to suboptimal decisions. Here, we propose a novel graph convolutional autoencoder approach for spatio-temporal aggregation of a generic CEP with heterogeneous nodes (CEPHN). Our architecture leverages graph pooling to identify nodes with similar characteristics and minimizes a multi-objective loss function. This loss function is tailored to induce desirable spatial and temporal aggregations with regard to tractability and optimality. In particular, the output of the graph pooling provides a spatial aggregation while clustering the low-dimensional encoded representations yields a temporal aggregation. We apply our approach to generation expansion planning of a coupled 88-node power and natural gas system in New England. The resulting aggregation leads to a simpler CEPHN with 6 nodes and a small set of representative days selected from one year. We evaluate aggregation outcomes over a range of hyperparameters governing the loss function and compare resulting upper bounds on the original problem with those obtained using benchmark methods. We show that our approach provides upper bounds that are 33% (resp. 10%) lower those than obtained from benchmark spatial (resp. temporal) aggregation approaches.