 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model Stitching and Visualization How GAN Generators can Invert Networks in Real-Time
Feb 04, 2023
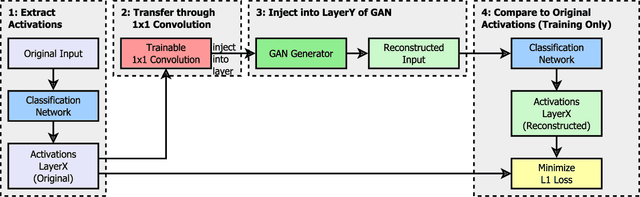
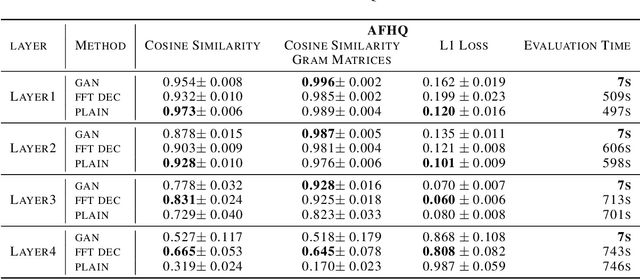
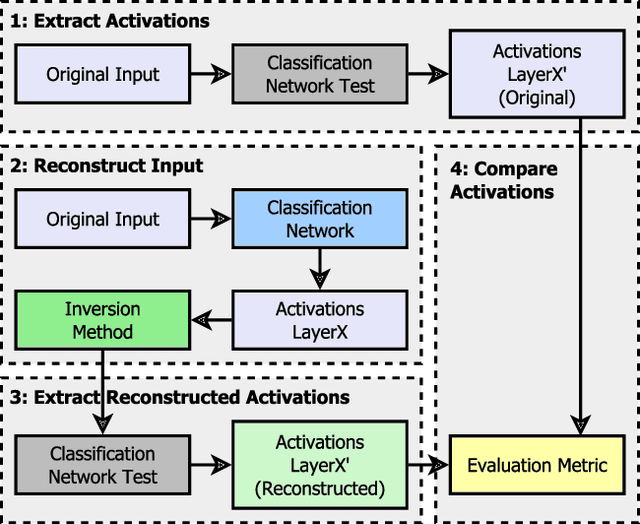

Critical applications, such as in the medical field, require the rapid provision of additional information to interpret decisions made by deep learning methods. In this work, we propose a fast and accurate method to visualize activations of classification and semantic segmentation networks by stitching them with a GAN generator utilizing convolutions. We test our approach on images of animals from the AFHQ wild dataset and real-world digital pathology scans of stained tissue samples. Our method provides comparable results to established gradient descent methods on these datasets while running about two orders of magnitude faster.
Two-stage Neural Network for ICASSP 2023 Speech Signal Improvement Challenge
Mar 14, 2023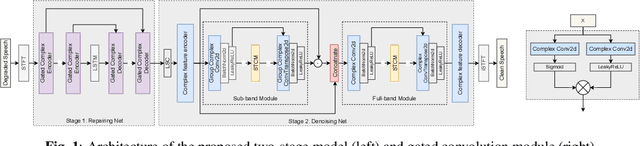
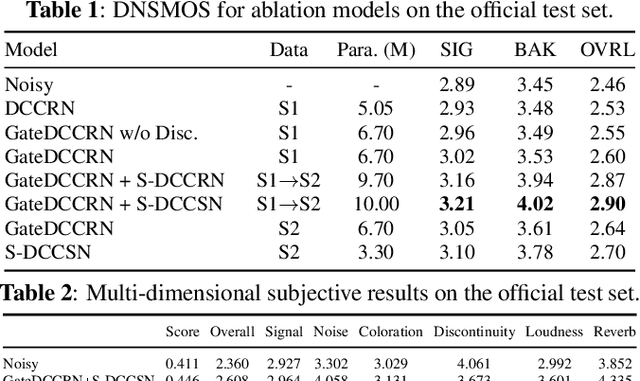
In ICASSP 2023 speech signal improvement challenge, we developed a dual-stage neural model which improves speech signal quality induced by different distortions in a stage-wise divide-and-conquer fashion. Specifically, in the first stage, the speech improvement network focuses on recovering the missing components of the spectrum, while in the second stage, our model aims to further suppress noise, reverberation, and artifacts introduced by the first-stage model. Achieving 0.446 in the final score and 0.517 in the P.835 score, our system ranks 4th in the non-real-time track.
What is the State of Memory Saving for Model Training?
Mar 26, 2023
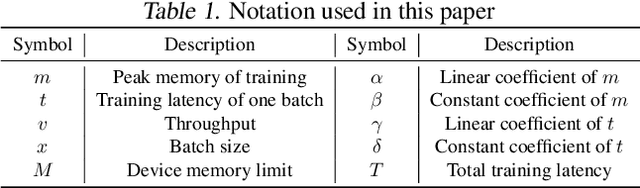
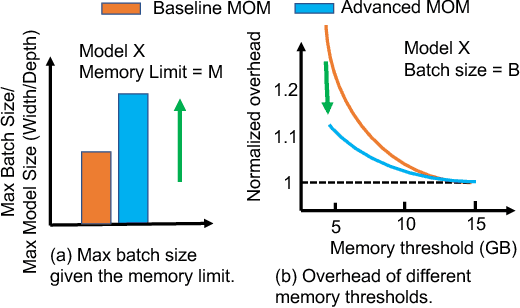
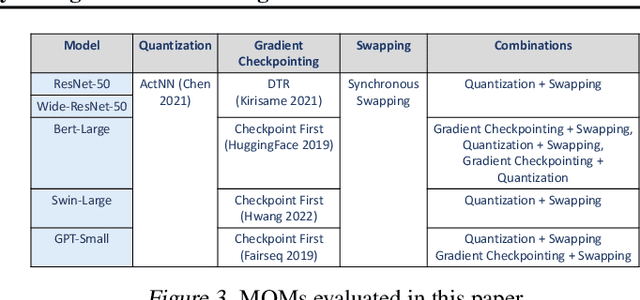
Large neural networks can improve the accuracy and generalization on tasks across many domains. However, this trend cannot continue indefinitely due to limited hardware memory. As a result, researchers have devised a number of memory optimization methods (MOMs) to alleviate the memory bottleneck, such as gradient checkpointing, quantization, and swapping. In this work, we study memory optimization methods and show that, although these strategies indeed lower peak memory usage, they can actually decrease training throughput by up to 9.3x. To provide practical guidelines for practitioners, we propose a simple but effective performance model PAPAYA to quantitatively explain the memory and training time trade-off. PAPAYA can be used to determine when to apply the various memory optimization methods in training different models. We outline the circumstances in which memory optimization techniques are more advantageous based on derived implications from PAPAYA. We assess the accuracy of PAPAYA and the derived implications on a variety of machine models, showing that it achieves over 0.97 R score on predicting the peak memory/throughput, and accurately predicts the effectiveness of MOMs across five evaluated models on vision and NLP tasks.
Common Subexpression-based Compression and Multiplication of Sparse Constant Matrices
Mar 26, 2023
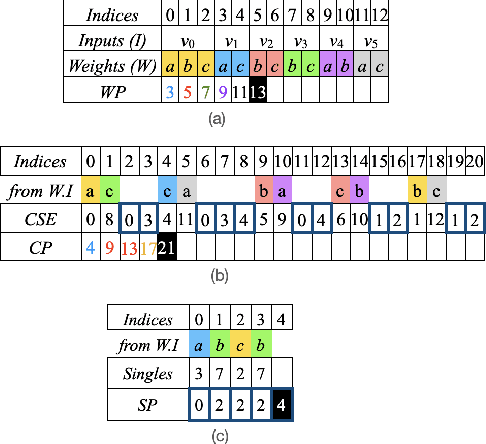
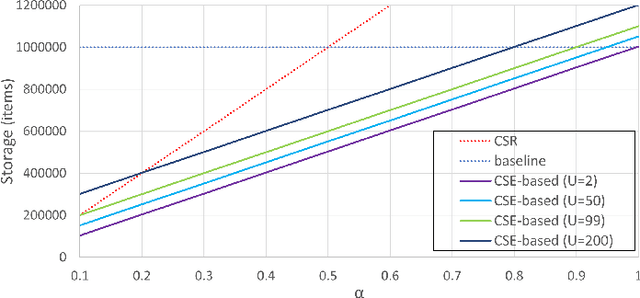
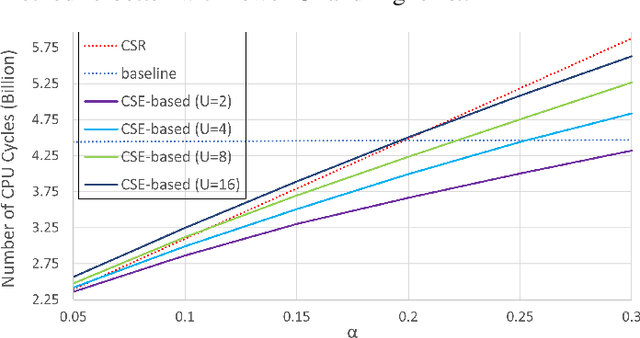
In deep learning inference, model parameters are pruned and quantized to reduce the model size. Compression methods and common subexpression (CSE) elimination algorithms are applied on sparse constant matrices to deploy the models on low-cost embedded devices. However, the state-of-the-art CSE elimination methods do not scale well for handling large matrices. They reach hours for extracting CSEs in a $200 \times 200$ matrix while their matrix multiplication algorithms execute longer than the conventional matrix multiplication methods. Besides, there exist no compression methods for matrices utilizing CSEs. As a remedy to this problem, a random search-based algorithm is proposed in this paper to extract CSEs in the column pairs of a constant matrix. It produces an adder tree for a $1000 \times 1000$ matrix in a minute. To compress the adder tree, this paper presents a compression format by extending the Compressed Sparse Row (CSR) to include CSEs. While compression rates of more than $50\%$ can be achieved compared to the original CSR format, simulations for a single-core embedded system show that the matrix multiplication execution time can be reduced by $20\%$.
Need for Speed: Fast Correspondence-Free Lidar Odometry Using Doppler Velocity
Mar 11, 2023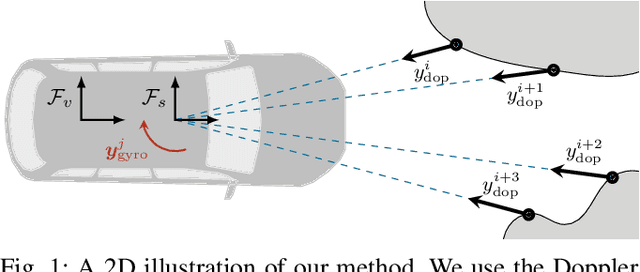
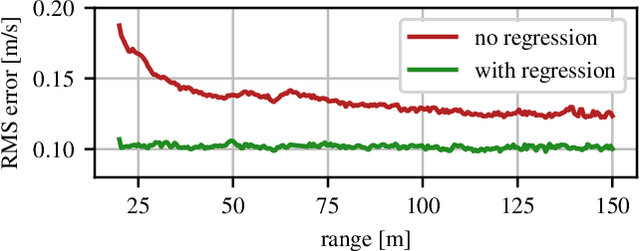
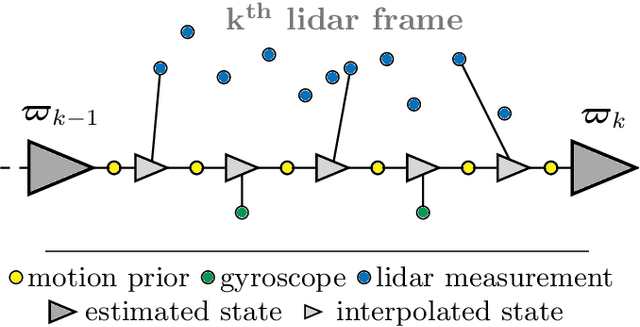

In this paper, we present a fast, lightweight odometry method that uses the Doppler velocity measurements from a Frequency-Modulated Continuous-Wave (FMCW) lidar without data association. FMCW lidar is a recently emerging technology that enables per-return relative radial velocity measurements via the Doppler effect. Since the Doppler measurement model is linear with respect to the 6-degrees-of-freedom (DOF) vehicle velocity, we can formulate a linear continuous-time estimation problem for the velocity and numerically integrate for the 6-DOF pose estimate afterward. The caveat is that angular velocity is not observable with a single FMCW lidar. We address this limitation by also incorporating the angular velocity measurements from a gyroscope. This results in an extremely efficient odometry method that processes lidar frames at an average wall-clock time of 5.8ms on a single thread, well below the 10Hz operating rate of the lidar we tested. We show experimental results on real-world driving sequences and compare against state-of-the-art Iterative Closest Point (ICP)-based odometry methods, presenting a compelling trade-off between accuracy and computation. We also present an algebraic observability study, where we demonstrate in theory that the Doppler measurements from multiple FMCW lidars are capable of observing all 6 degrees of freedom (translational and angular velocity).
Accurate Prediction of Global Mean Temperature through Data Transformation Techniques
Mar 11, 2023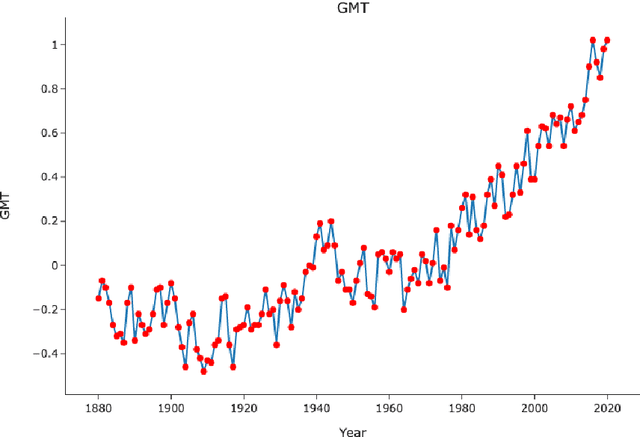
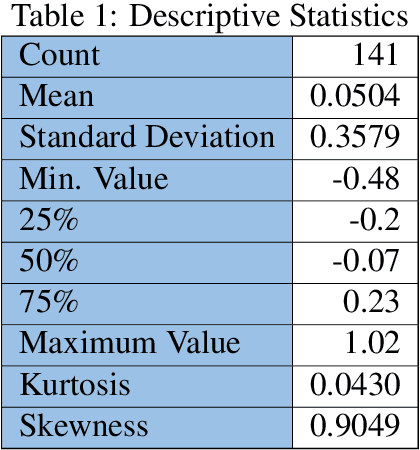
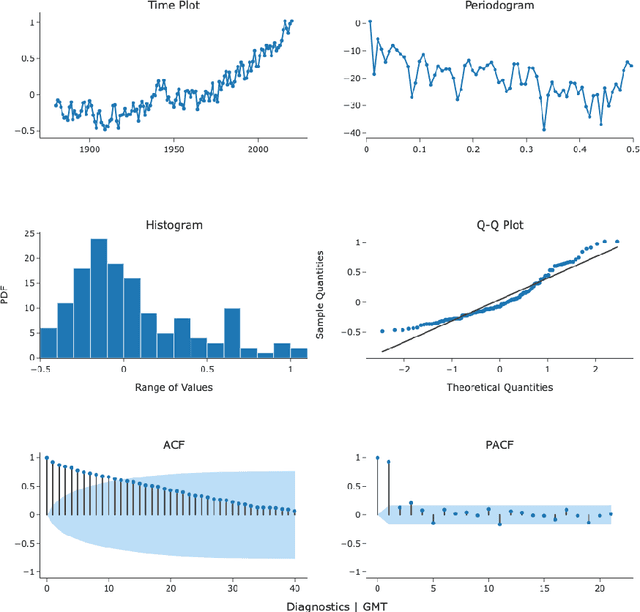
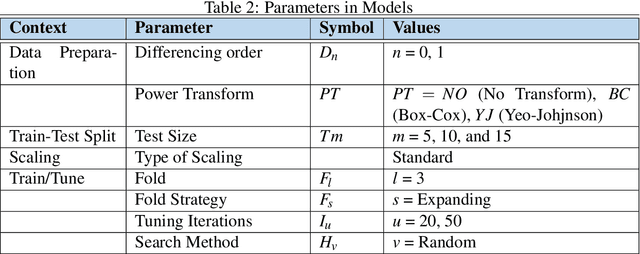
It is important to predict how the Global Mean Temperature (GMT) will evolve in the next few decades. The ability to predict historical data is a necessary first step toward the actual goal of making long-range forecasts. This paper examines the advantage of statistical and simpler Machine Learning (ML) methods instead of directly using complex ML algorithms and Deep Learning Neural Networks (DNN). Often neglected data transformation methods prior to applying different algorithms have been used as a means of improving predictive accuracy. The GMT time series is treated both as a univariate time series and also cast as a regression problem. Some steps of data transformations were found to be effective. Various simple ML methods did as well or better than the more well-known ones showing merit in trying a large bouquet of algorithms as a first step. Fifty-six algorithms were subject to Box-Cox, Yeo-Johnson, and first-order differencing and compared with the absence of them. Predictions for the annual GMT testing data were better than that published so far, with the lowest RMSE value of 0.02 $^\circ$C. RMSE for five-year mean GMT values for the test data ranged from 0.00002 to 0.00036 $^\circ$C.
Learning a Meta-Controller for Dynamic Grasping
Feb 16, 2023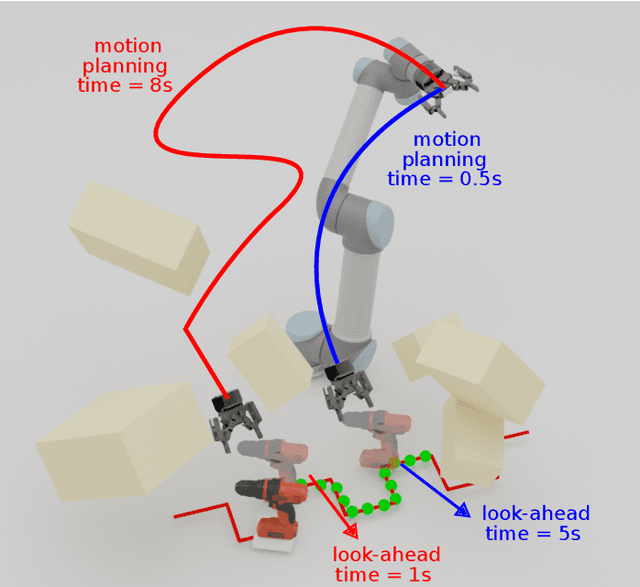
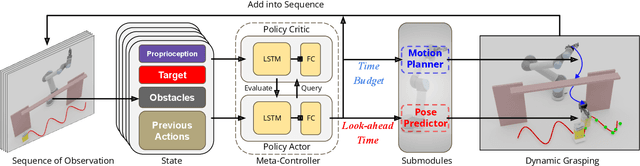
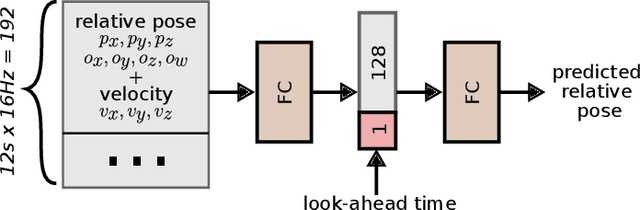
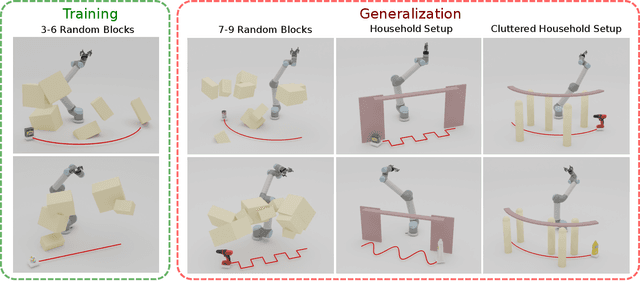
Grasping moving objects is a challenging task that combines multiple submodules such as object pose predictor, arm motion planner, etc. Each submodule operates under its own set of meta-parameters. For example, how far the pose predictor should look into the future (i.e., look-ahead time) and the maximum amount of time the motion planner can spend planning a motion (i.e., time budget). Many previous works assign fixed values to these parameters either heuristically or through grid search; however, at different moments within a single episode of dynamic grasping, the optimal values should vary depending on the current scene. In this work, we learn a meta-controller through reinforcement learning to control the look-ahead time and time budget dynamically. Our extensive experiments show that the meta-controller improves the grasping success rate (up to 12% in the most cluttered environment) and reduces grasping time, compared to the strongest baseline. Our meta-controller learns to reason about the reachable workspace and maintain the predicted pose within the reachable region. In addition, it assigns a small but sufficient time budget for the motion planner. Our method can handle different target objects, trajectories, and obstacles. Despite being trained only with 3-6 randomly generated cuboidal obstacles, our meta-controller generalizes well to 7-9 obstacles and more realistic out-of-domain household setups with unseen obstacle shapes. Video is available at https://youtu.be/CwHq77wFQqI.
Improving Surgical Situational Awareness with Signed Distance Field: A Pilot Study in Virtual Reality
Mar 03, 2023
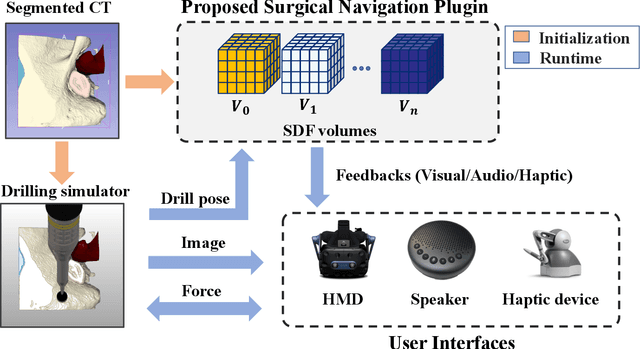
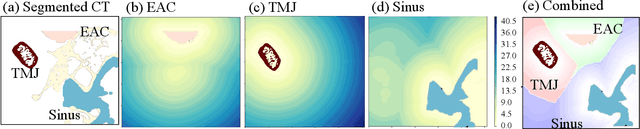
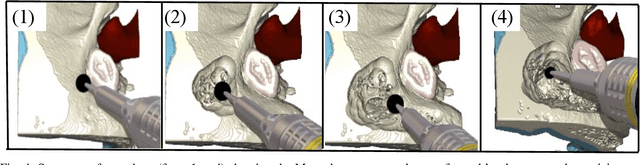
The introduction of image-guided surgical navigation (IGSN) has greatly benefited technically demanding surgical procedures by providing real-time support and guidance to the surgeon during surgery. To develop effective IGSN, a careful selection of the information provided to the surgeon is needed. However, identifying optimal feedback modalities is challenging due to the broad array of available options. To address this problem, we have developed an open-source library that facilitates the development of multimodal navigation systems in a wide range of surgical procedures relying on medical imaging data. To provide guidance, our system calculates the minimum distance between the surgical instrument and the anatomy and then presents this information to the user through different mechanisms. The real-time performance of our approach is achieved by calculating Signed Distance Fields at initialization from segmented anatomical volumes. Using this framework, we developed a multimodal surgical navigation system to help surgeons navigate anatomical variability in a skull-base surgery simulation environment. Three different feedback modalities were explored: visual, auditory, and haptic. To evaluate the proposed system, a pilot user study was conducted in which four clinicians performed mastoidectomy procedures with and without guidance. Each condition was assessed using objective performance and subjective workload metrics. This pilot user study showed improvements in procedural safety without additional time or workload. These results demonstrate our pipeline's successful use case in the context of mastoidectomy.
CS-TGN: Community Search via Temporal Graph Neural Networks
Mar 15, 2023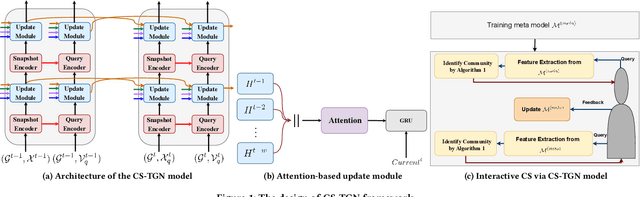
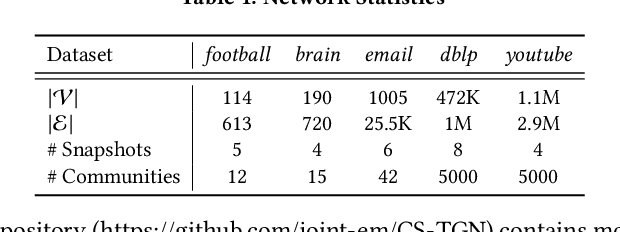
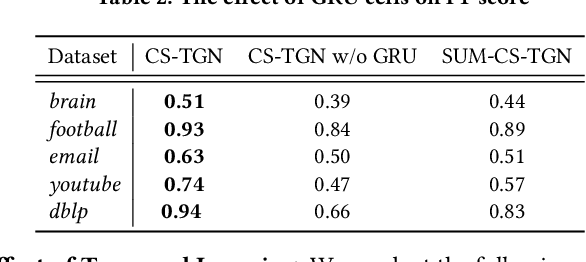
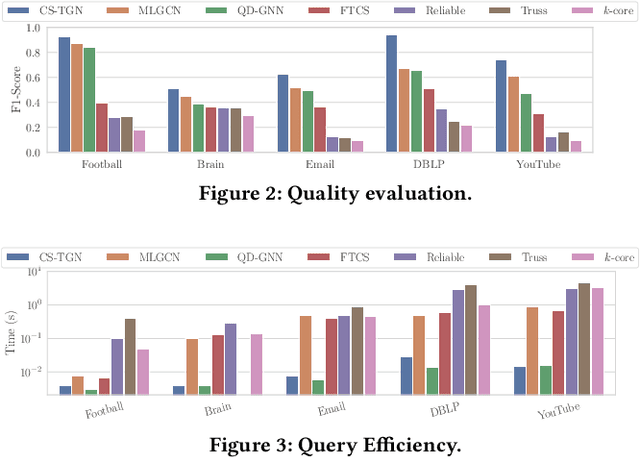
Searching for local communities is an important research challenge that allows for personalized community discovery and supports advanced data analysis in various complex networks, such as the World Wide Web, social networks, and brain networks. The evolution of these networks over time has motivated several recent studies to identify local communities in temporal networks. Given any query nodes, Community Search aims to find a densely connected subgraph containing query nodes. However, existing community search approaches in temporal networks have two main limitations: (1) they adopt pre-defined subgraph patterns to model communities, which cannot find communities that do not conform to these patterns in real-world networks, and (2) they only use the aggregation of disjoint structural information to measure quality, missing the dynamic of connections and temporal properties. In this paper, we propose a query-driven Temporal Graph Convolutional Network (CS-TGN) that can capture flexible community structures by learning from the ground-truth communities in a data-driven manner. CS-TGN first combines the local query-dependent structure and the global graph embedding in each snapshot of the network and then uses a GRU cell with contextual attention to learn the dynamics of interactions and update node embeddings over time. We demonstrate how this model can be used for interactive community search in an online setting, allowing users to evaluate the found communities and provide feedback. Experiments on real-world temporal graphs with ground-truth communities validate the superior quality of the solutions obtained and the efficiency of our model in both temporal and interactive static settings.
Towards an Hybrid Hodgkin-Huxley Action Potential Generation Model
Mar 15, 2023
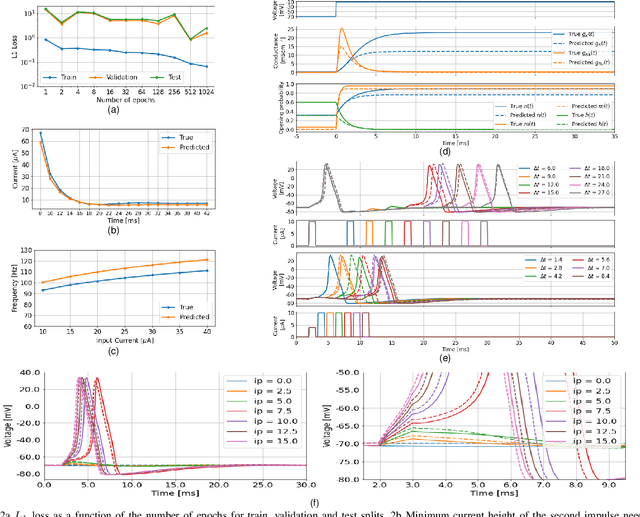

Mathematical models for the generation of the action potential can improve the understanding of physiological mechanisms that are consequence of the electrical activity in neurons. In such models, some equations involving empirically obtained functions of the membrane potential are usually defined. The best known of these models, the Hodgkin-Huxley model, is an example of this paradigm since it defines the conductances of ion channels in terms of the opening and closing rates of each type of gate present in the channels. These functions need to be derived from laboratory measurements that are often very expensive and produce little data because they involve a time-space-independent measurement of the voltage in a single channel of the cell membrane. In this work, we investigate the possibility of finding the Hodgkin-Huxley model's parametric functions using only two simple measurements (the membrane voltage as a function of time and the injected current that triggered that voltage) and applying Deep Learning methods to estimate these functions. This would result in an hybrid model of the action potential generation composed by the original Hodgkin-Huxley equations and an Artificial Neural Network that requires a small set of easy-to-perform measurements to be trained. Experiments were carried out using data generated from the original Hodgkin-Huxley model, and results show that a simple two-layer artificial neural network (ANN) architecture trained on a minimal amount of data can learn to model some of the fundamental proprieties of the action potential generation by estimating the model's rate functions.