 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Context-aware Classifier for Semantic Segmentation
Mar 21, 2023

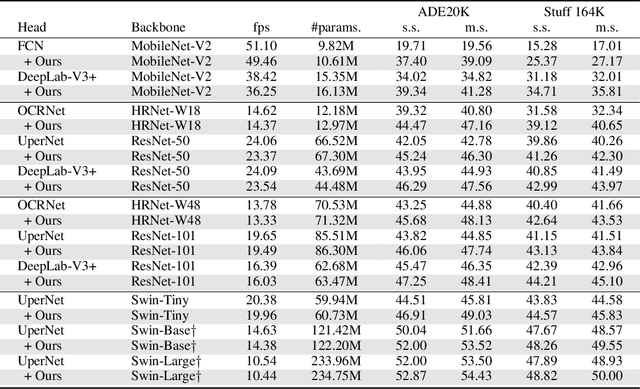


Semantic segmentation is still a challenging task for parsing diverse contexts in different scenes, thus the fixed classifier might not be able to well address varying feature distributions during testing. Different from the mainstream literature where the efficacy of strong backbones and effective decoder heads has been well studied, in this paper, additional contextual hints are instead exploited via learning a context-aware classifier whose content is data-conditioned, decently adapting to different latent distributions. Since only the classifier is dynamically altered, our method is model-agnostic and can be easily applied to generic segmentation models. Notably, with only negligible additional parameters and +2\% inference time, decent performance gain has been achieved on both small and large models with challenging benchmarks, manifesting substantial practical merits brought by our simple yet effective method. The implementation is available at \url{https://github.com/tianzhuotao/CAC}.
Baldur: Whole-Proof Generation and Repair with Large Language Models
Mar 08, 2023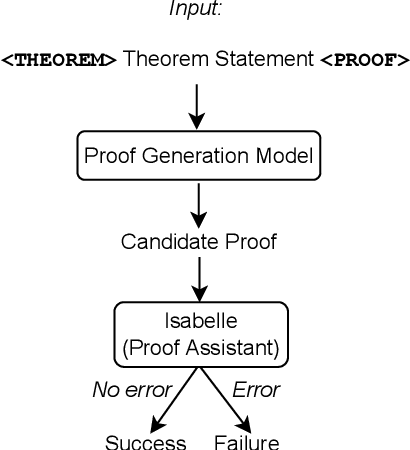
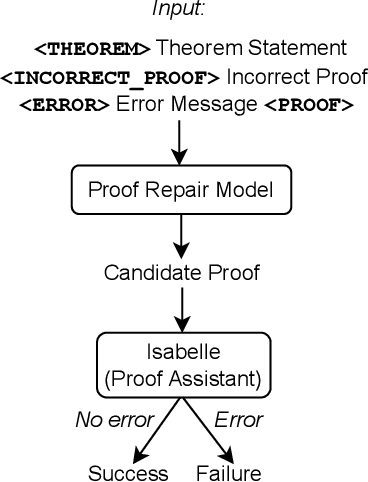
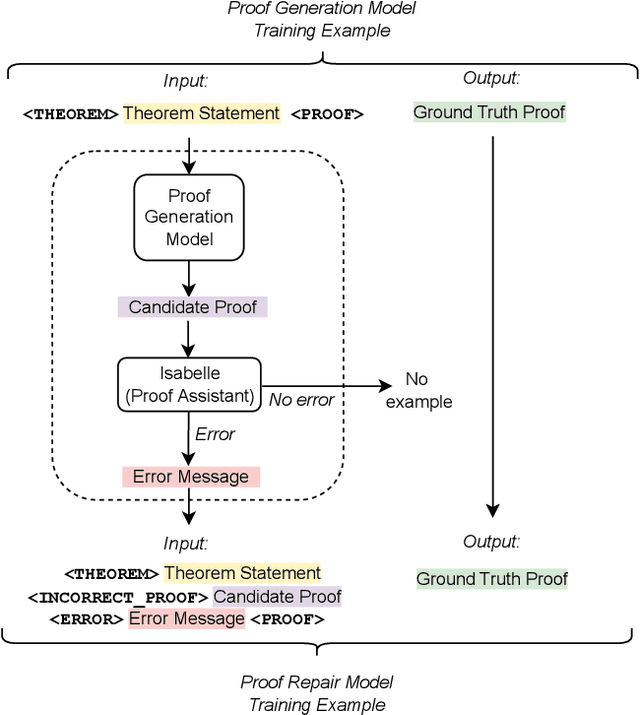
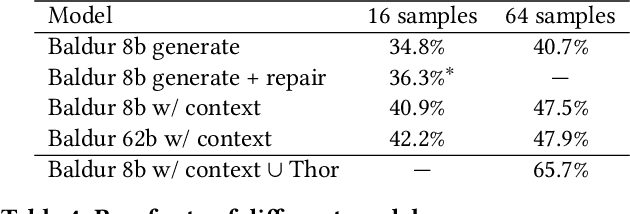
Formally verifying software properties is a highly desirable but labor-intensive task. Recent work has developed methods to automate formal verification using proof assistants, such as Coq and Isabelle/HOL, e.g., by training a model to predict one proof step at a time, and using that model to search through the space of possible proofs. This paper introduces a new method to automate formal verification: We use large language models, trained on natural language text and code and fine-tuned on proofs, to generate whole proofs for theorems at once, rather than one step at a time. We combine this proof generation model with a fine-tuned repair model to repair generated proofs, further increasing proving power. As its main contributions, this paper demonstrates for the first time that: (1) Whole-proof generation using transformers is possible and is as effective as search-based techniques without requiring costly search. (2) Giving the learned model additional context, such as a prior failed proof attempt and the ensuing error message, results in proof repair and further improves automated proof generation. (3) We establish a new state of the art for fully automated proof synthesis. We reify our method in a prototype, Baldur, and evaluate it on a benchmark of 6,336 Isabelle/HOL theorems and their proofs. In addition to empirically showing the effectiveness of whole-proof generation, repair, and added context, we show that Baldur improves on the state-of-the-art tool, Thor, by automatically generating proofs for an additional 8.7% of the theorems. Together, Baldur and Thor can prove 65.7% of the theorems fully automatically. This paper paves the way for new research into using large language models for automating formal verification.
Real-time Trajectory Optimization and Control for Ball Bumping with Quadruped Robots
Oct 11, 2022
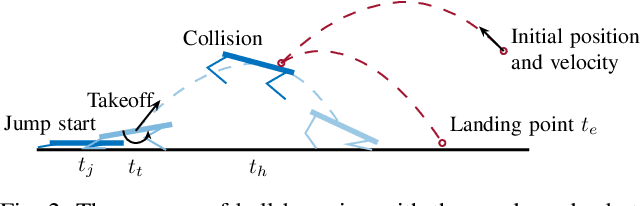

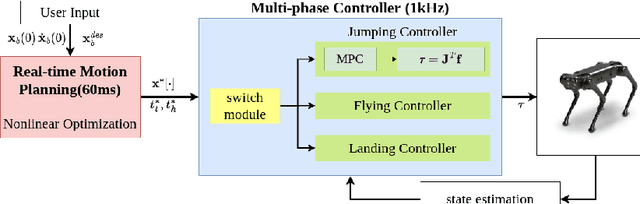
This paper studies real-time motion planning and control for ball bumping motion with quadruped robots. To enable the quadruped to bump the flying ball with different initializations, we develop a nonlinear trajectory optimization-based planning scheme that jointly identifies the take-off time and state to achieve accurate ball hitting during the flight phase. Such a planning scheme employs a two-dimensional single rigid body model that achieves a satisfactory balance between accuracy and efficiency for the highly time-sensitive task. To precisely execute the planned motion, the tracking controller needs to incorporate the strict time-state constraint imposed on the take-off and ball-hitting events. To this end, we develop an improved model predictive controller that respects the critical time-state constraints. The proposed planning and control framework is validated with a real Aliengo robot. Experiments show that the problem planning approach can be computed in approximately 60ms on average, enabling successful accomplishment of the ball bumping motion with various initializations in real time.
TextMI: Textualize Multimodal Information for Integrating Non-verbal Cues in Pre-trained Language Models
Mar 29, 2023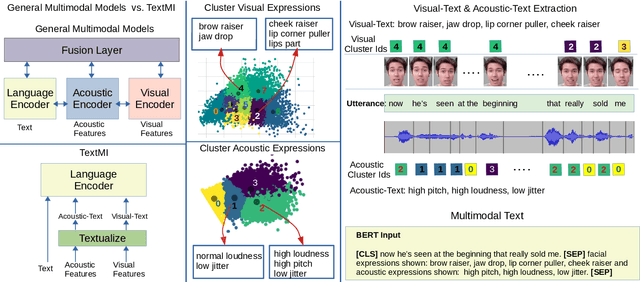
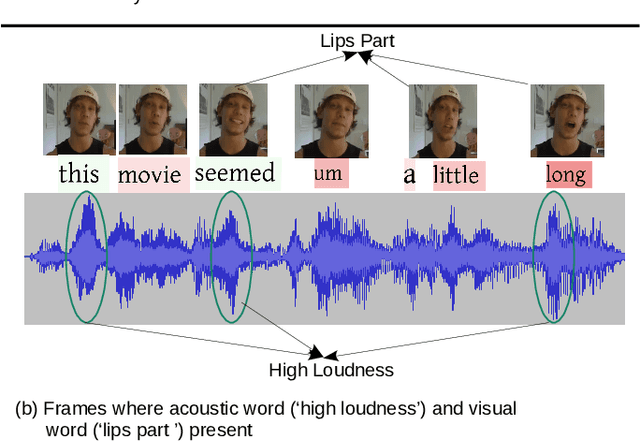

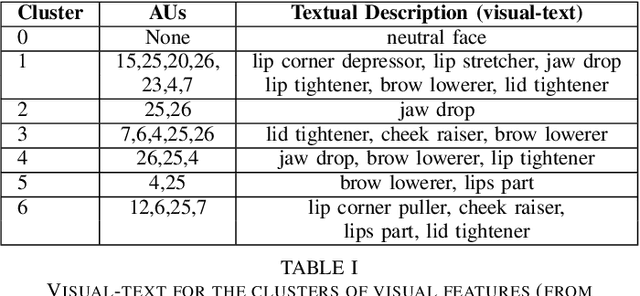
Pre-trained large language models have recently achieved ground-breaking performance in a wide variety of language understanding tasks. However, the same model can not be applied to multimodal behavior understanding tasks (e.g., video sentiment/humor detection) unless non-verbal features (e.g., acoustic and visual) can be integrated with language. Jointly modeling multiple modalities significantly increases the model complexity, and makes the training process data-hungry. While an enormous amount of text data is available via the web, collecting large-scale multimodal behavioral video datasets is extremely expensive, both in terms of time and money. In this paper, we investigate whether large language models alone can successfully incorporate non-verbal information when they are presented in textual form. We present a way to convert the acoustic and visual information into corresponding textual descriptions and concatenate them with the spoken text. We feed this augmented input to a pre-trained BERT model and fine-tune it on three downstream multimodal tasks: sentiment, humor, and sarcasm detection. Our approach, TextMI, significantly reduces model complexity, adds interpretability to the model's decision, and can be applied for a diverse set of tasks while achieving superior (multimodal sarcasm detection) or near SOTA (multimodal sentiment analysis and multimodal humor detection) performance. We propose TextMI as a general, competitive baseline for multimodal behavioral analysis tasks, particularly in a low-resource setting.
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Mar 29, 2023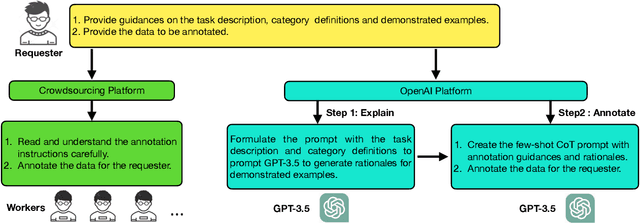
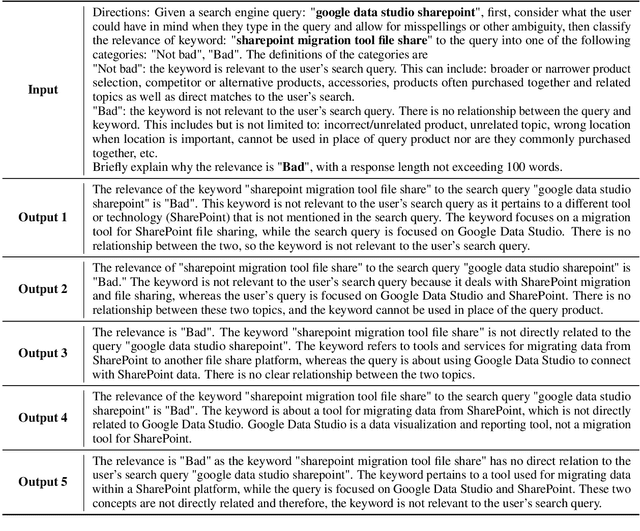

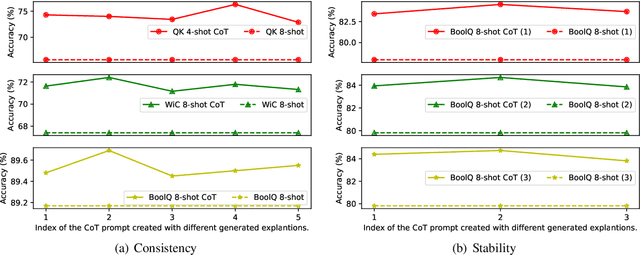
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models to achieve high performance. However, data annotation can be a time-consuming and expensive process, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator by providing them with sufficient guidance and demonstrated examples. To make LLMs to be better annotators, we propose a two-step approach, 'explain-then-annotate'. To be more precise, we begin by creating prompts for every demonstrated example, which we subsequently utilize to prompt a LLM to provide an explanation for why the specific ground truth answer/label was chosen for that particular example. Following this, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data. We conduct experiments on three tasks, including user input and keyword relevance assessment, BoolQ and WiC. The annotation results from GPT-3.5 surpasses those from crowdsourced annotation for user input and keyword relevance assessment. Additionally, for the other two tasks, GPT-3.5 achieves results that are comparable to those obtained through crowdsourced annotation.
FATROP : A Fast Constrained Optimal Control Problem Solver for Robot Trajectory Optimization and Control
Mar 29, 2023
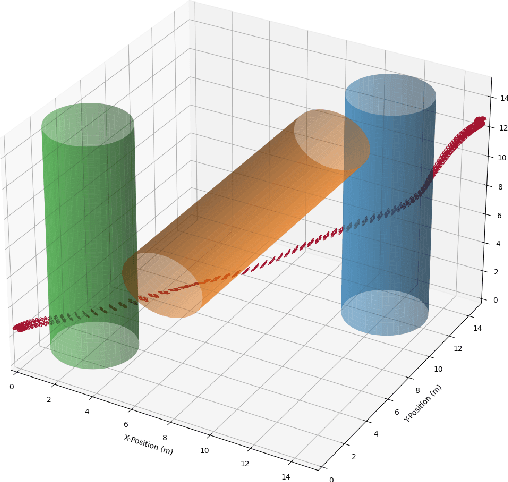

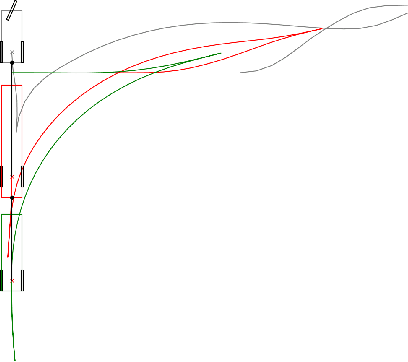
Trajectory optimization is a powerful tool for robot motion planning and control. State-of-the-art general-purpose nonlinear programming solvers are versatile, handle constraints in an effective way and provide a high numerical robustness, but they are slow because they do not fully exploit the optimal control problem structure at hand. Existing structure-exploiting solvers are fast but they often lack techniques to deal with nonlinearity or rely on penalty methods to enforce (equality or inequality) path constraints. This works presents FATROP: a trajectory optimization solver that is fast and benefits from the salient features of general-purpose nonlinear optimization solvers. The speed-up is mainly achieved through the use of a specialized linear solver, based on a Riccati recursion that is generalized to also support stagewise equality constraints. To demonstrate the algorithm's potential, it is benchmarked on a set of robot problems that are challenging from a numerical perspective, including problems with a minimum-time objective and no-collision constraints. The solver is shown to solve problems for trajectory generation of a quadrotor, a robot manipulator and a truck-trailer problem in a few tens of milliseconds. The algorithm's C++-code implementation accompanies this work as open source software, released under the GNU Lesser General Public License (LGPL). This software framework may encourage and enable the robotics community to use trajectory optimization in more challenging applications.
Material-agnostic Shaping of Granular Materials with Optimal Transport
Mar 29, 2023


From construction materials, such as sand or asphalt, to kitchen ingredients, like rice, sugar, or salt; the world is full of granular materials. Despite impressive progress in robotic manipulation, manipulating and interacting with granular material remains a challenge due to difficulties in perceiving, representing, modelling, and planning for these variable materials that have complex internal dynamics. While some prior work has looked into estimating or learning accurate dynamics models for granular materials, the literature is still missing a more abstract planning method that can be used for planning manipulation actions for granular materials with unknown material properties. In this work, we leverage tools from optimal transport and connect them to robot motion planning. We propose a heuristics-based sweep planner that does not require knowledge of the material's properties and directly uses a height map representation to generate promising sweeps. These sweeps transform granular material from arbitrary start shapes into arbitrary target shapes. We apply the sweep planner in a fast and reactive feedback loop and avoid the need for model-based planning over multiple time steps. We validate our approach with a large set of simulation and hardware experiments where we show that our method is capable of efficiently solving several complex tasks, including gathering, separating, and shaping of several types of granular materials into different target shapes.
Understanding and Improving Features Learned in Deep Functional Maps
Mar 29, 2023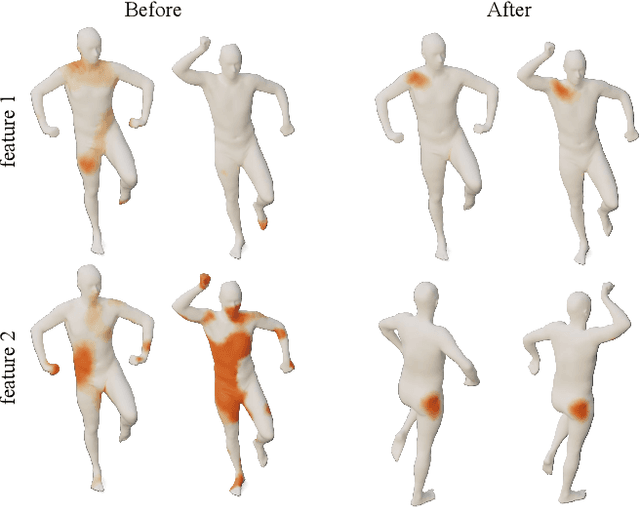
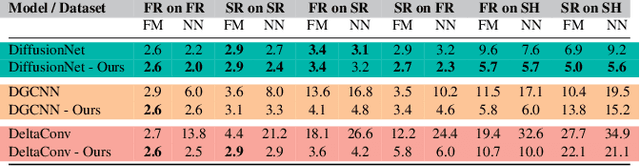
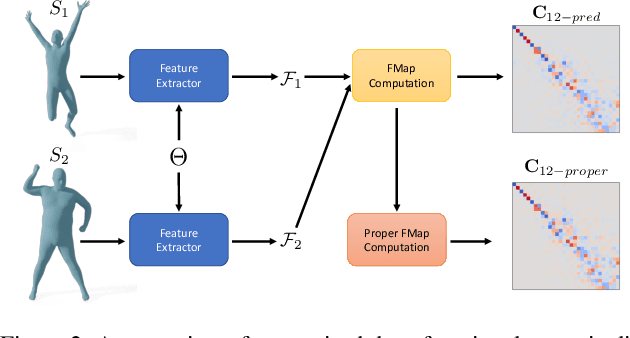
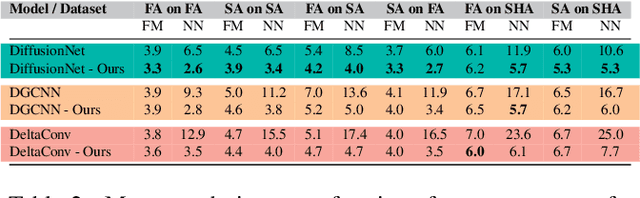
Deep functional maps have recently emerged as a successful paradigm for non-rigid 3D shape correspondence tasks. An essential step in this pipeline consists in learning feature functions that are used as constraints to solve for a functional map inside the network. However, the precise nature of the information learned and stored in these functions is not yet well understood. Specifically, a major question is whether these features can be used for any other objective, apart from their purely algebraic role in solving for functional map matrices. In this paper, we show that under some mild conditions, the features learned within deep functional map approaches can be used as point-wise descriptors and thus are directly comparable across different shapes, even without the necessity of solving for a functional map at test time. Furthermore, informed by our analysis, we propose effective modifications to the standard deep functional map pipeline, which promote structural properties of learned features, significantly improving the matching results. Finally, we demonstrate that previously unsuccessful attempts at using extrinsic architectures for deep functional map feature extraction can be remedied via simple architectural changes, which encourage the theoretical properties suggested by our analysis. We thus bridge the gap between intrinsic and extrinsic surface-based learning, suggesting the necessary and sufficient conditions for successful shape matching. Our code is available at https://github.com/pvnieo/clover.
* 16 pages, 8 figures, 8 tables, to be published in 2023 The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Self-contained Beta-with-Spikes Approximation for Inference Under a Wright-Fisher Model
Mar 08, 2023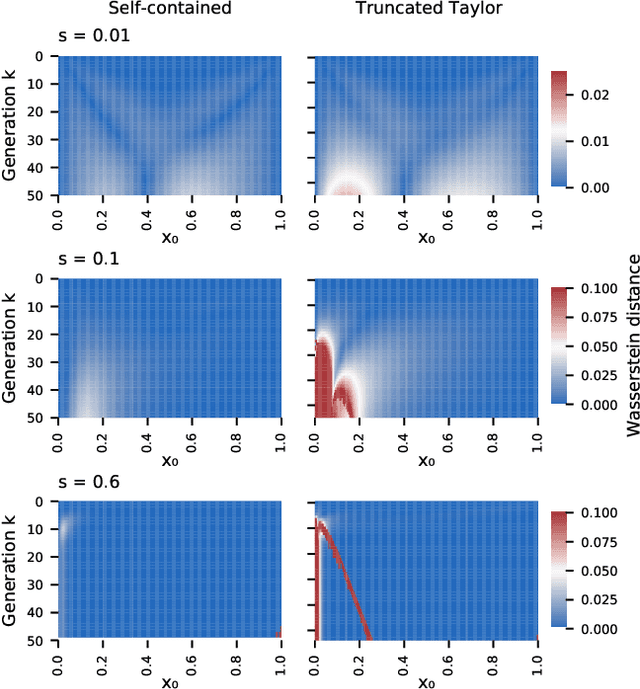
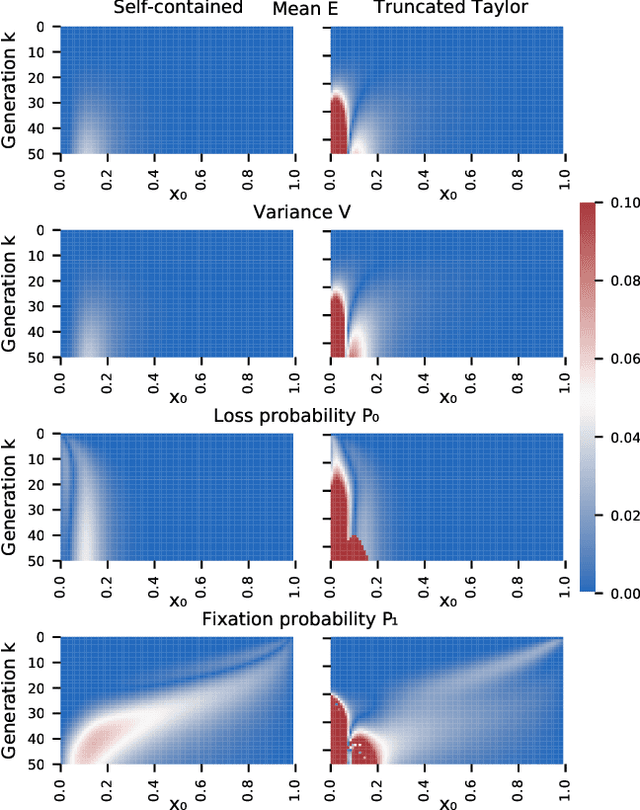
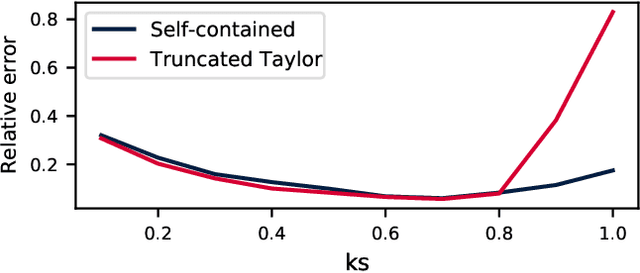
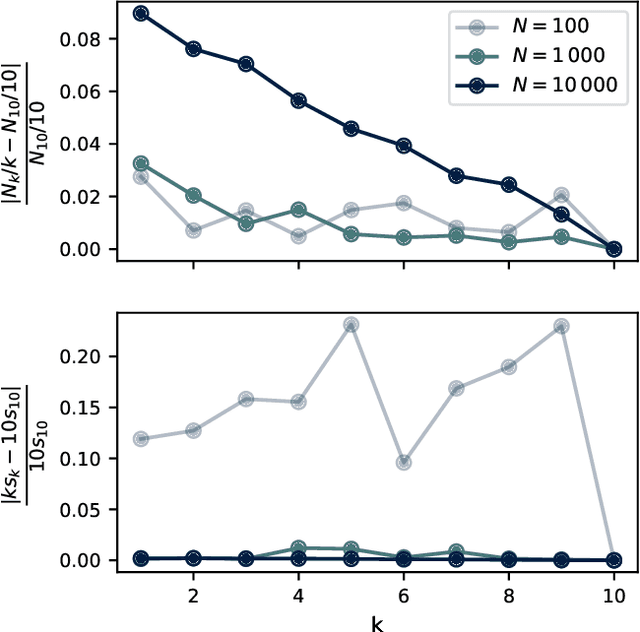
We construct a reliable estimation of evolutionary parameters within the Wright-Fisher model, which describes changes in allele frequencies due to selection and genetic drift, from time-series data. Such data exists for biological populations, for example via artificial evolution experiments, and for the cultural evolution of behavior, such as linguistic corpora that document historical usage of different words with similar meanings. Our method of analysis builds on a Beta-with-Spikes approximation to the distribution of allele frequencies predicted by the Wright-Fisher model. We introduce a self-contained scheme for estimating the parameters in the approximation, and demonstrate its robustness with synthetic data, especially in the strong-selection and near-extinction regimes where previous approaches fail. We further apply to allele frequency data for baker's yeast (Saccharomyces cerevisiae), finding a significant signal of selection in cases where independent evidence supports such a conclusion. We further demonstrate the possibility of detecting time-points at which evolutionary parameters change in the context of a historical spelling reform in the Spanish language.
Denoising Diffusion Samplers
Feb 27, 2023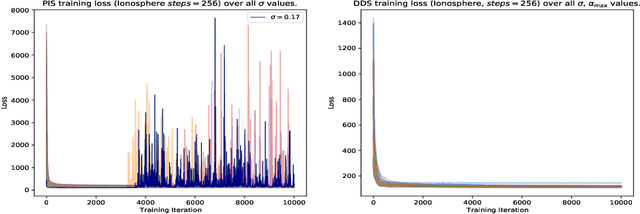

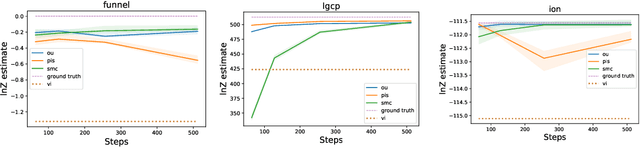

Denoising diffusion models are a popular class of generative models providing state-of-the-art results in many domains. One adds gradually noise to data using a diffusion to transform the data distribution into a Gaussian distribution. Samples from the generative model are then obtained by simulating an approximation of the time-reversal of this diffusion initialized by Gaussian samples. Practically, the intractable score terms appearing in the time-reversed process are approximated using score matching techniques. We explore here a similar idea to sample approximately from unnormalized probability density functions and estimate their normalizing constants. We consider a process where the target density diffuses towards a Gaussian. Denoising Diffusion Samplers (DDS) are obtained by approximating the corresponding time-reversal. While score matching is not applicable in this context, we can leverage many of the ideas introduced in generative modeling for Monte Carlo sampling. Existing theoretical results from denoising diffusion models also provide theoretical guarantees for DDS. We discuss the connections between DDS, optimal control and Schr\"odinger bridges and finally demonstrate DDS experimentally on a variety of challenging sampling tasks.
* In The Eleventh International Conference on Learning Representations, 2023