 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scientific Computing Algorithms to Learn Enhanced Scalable Surrogates for Mesh Physics
Apr 01, 2023
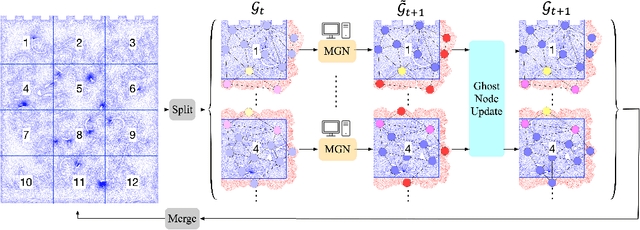

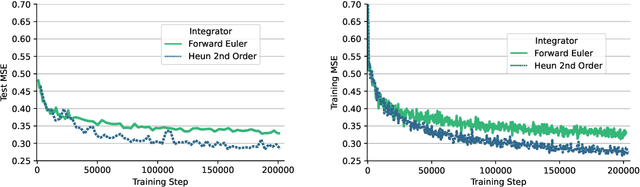
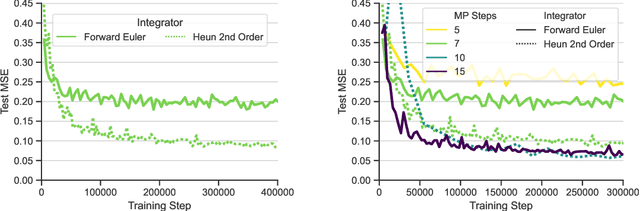
Data-driven modeling approaches can produce fast surrogates to study large-scale physics problems. Among them, graph neural networks (GNNs) that operate on mesh-based data are desirable because they possess inductive biases that promote physical faithfulness, but hardware limitations have precluded their application to large computational domains. We show that it is \textit{possible} to train a class of GNN surrogates on 3D meshes. We scale MeshGraphNets (MGN), a subclass of GNNs for mesh-based physics modeling, via our domain decomposition approach to facilitate training that is mathematically equivalent to training on the whole domain under certain conditions. With this, we were able to train MGN on meshes with \textit{millions} of nodes to generate computational fluid dynamics (CFD) simulations. Furthermore, we show how to enhance MGN via higher-order numerical integration, which can reduce MGN's error and training time. We validated our methods on an accompanying dataset of 3D $\text{CO}_2$-capture CFD simulations on a 3.1M-node mesh. This work presents a practical path to scaling MGN for real-world applications.
Stock Trend Prediction: A Semantic Segmentation Approach
Mar 09, 2023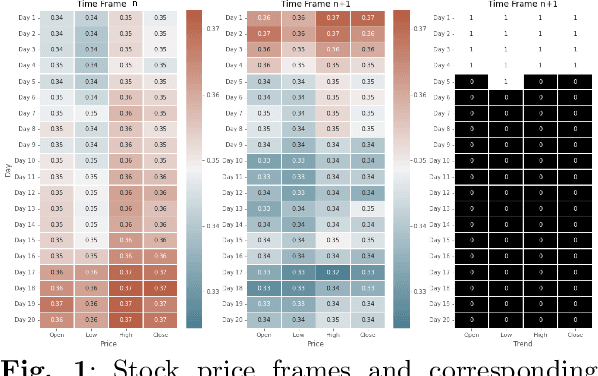
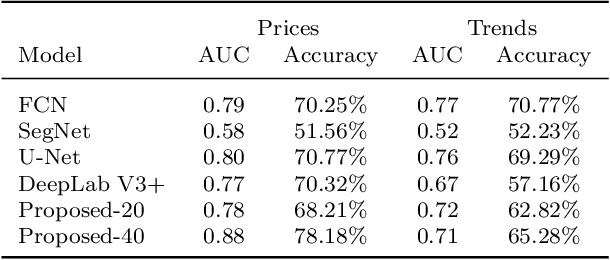
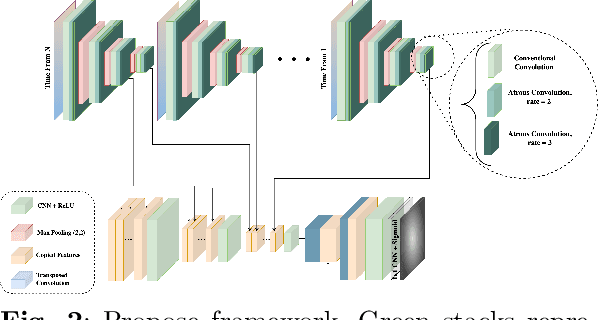
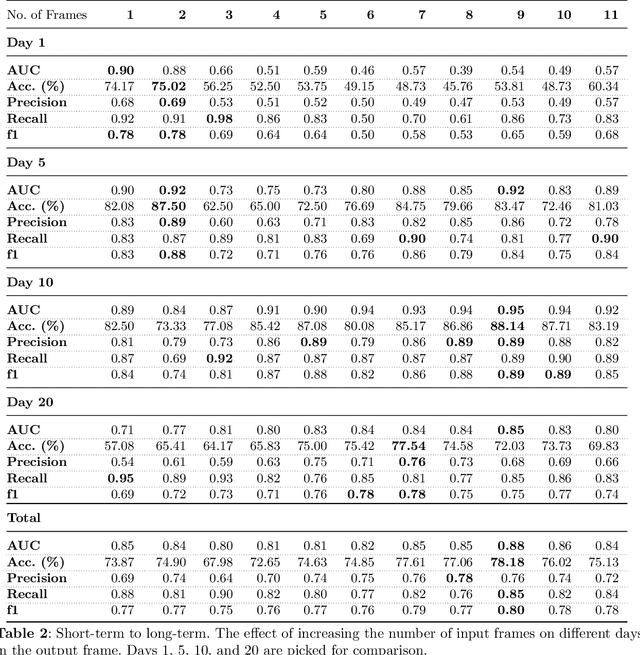
Market financial forecasting is a trending area in deep learning. Deep learning models are capable of tackling the classic challenges in stock market data, such as its extremely complicated dynamics as well as long-term temporal correlation. To capture the temporal relationship among these time series, recurrent neural networks are employed. However, it is difficult for recurrent models to learn to keep track of long-term information. Convolutional Neural Networks have been utilized to better capture the dynamics and extract features for both short- and long-term forecasting. However, semantic segmentation and its well-designed fully convolutional networks have never been studied for time-series dense classification. We present a novel approach to predict long-term daily stock price change trends with fully 2D-convolutional encoder-decoders. We generate input frames with daily prices for a time-frame of T days. The aim is to predict future trends by pixel-wise classification of the current price frame. We propose a hierarchical CNN structure to encode multiple price frames to multiscale latent representation in parallel using Atrous Spatial Pyramid Pooling blocks and take that temporal coarse feature stacks into account in the decoding stages. Our hierarchical structure of CNNs makes it capable of capturing both long and short-term temporal relationships effectively. The effect of increasing the input time horizon via incrementing parallel encoders has been studied with interesting and substantial changes in the output segmentation masks. We achieve overall accuracy and AUC of %78.18 and 0.88 for joint trend prediction over the next 20 days, surpassing other semantic segmentation approaches. We compared our proposed model with several deep models specifically designed for technical analysis and found that for different output horizons, our proposed models outperformed other models.
Decoupling Dynamic Monocular Videos for Dynamic View Synthesis
Apr 04, 2023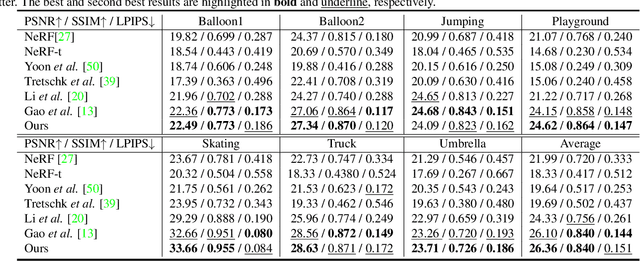

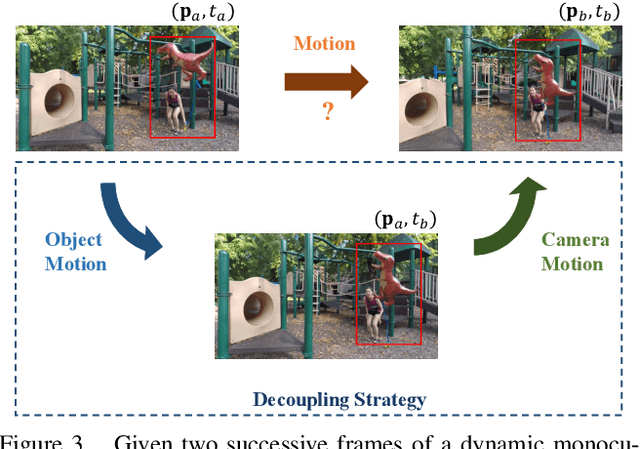
The challenge of dynamic view synthesis from dynamic monocular videos, i.e., synthesizing novel views for free viewpoints given a monocular video of a dynamic scene captured by a moving camera, mainly lies in accurately modeling the dynamic objects of a scene using limited 2D frames, each with a varying timestamp and viewpoint. Existing methods usually require pre-processed 2D optical flow and depth maps by additional methods to supervise the network, making them suffer from the inaccuracy of the pre-processed supervision and the ambiguity when lifting the 2D information to 3D. In this paper, we tackle this challenge in an unsupervised fashion. Specifically, we decouple the motion of the dynamic objects into object motion and camera motion, respectively regularized by proposed unsupervised surface consistency and patch-based multi-view constraints. The former enforces the 3D geometric surfaces of moving objects to be consistent over time, while the latter regularizes their appearances to be consistent across different viewpoints. Such a fine-grained motion formulation can alleviate the learning difficulty for the network, thus enabling it to produce not only novel views with higher quality but also more accurate scene flows and depth than existing methods requiring extra supervision. We will make the code publicly available.
Risk Sensitive Filtering with Randomly Delayed Measurements
Apr 04, 2023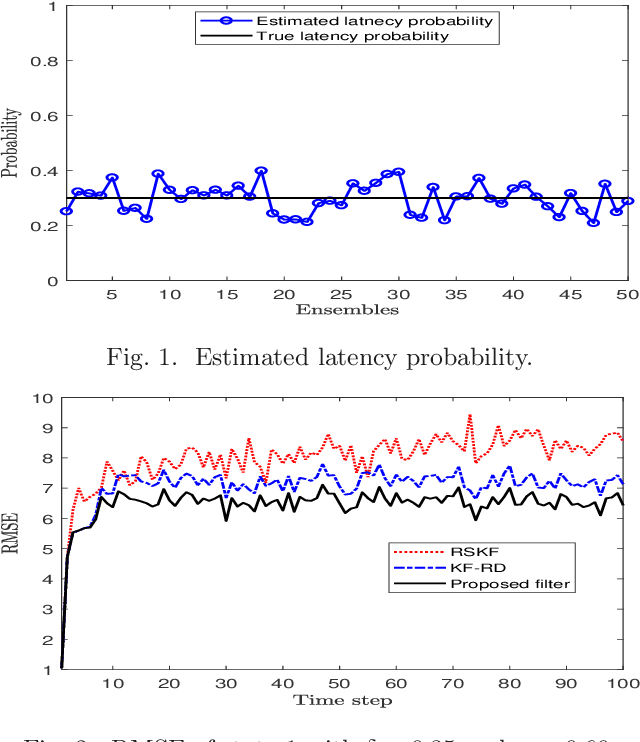
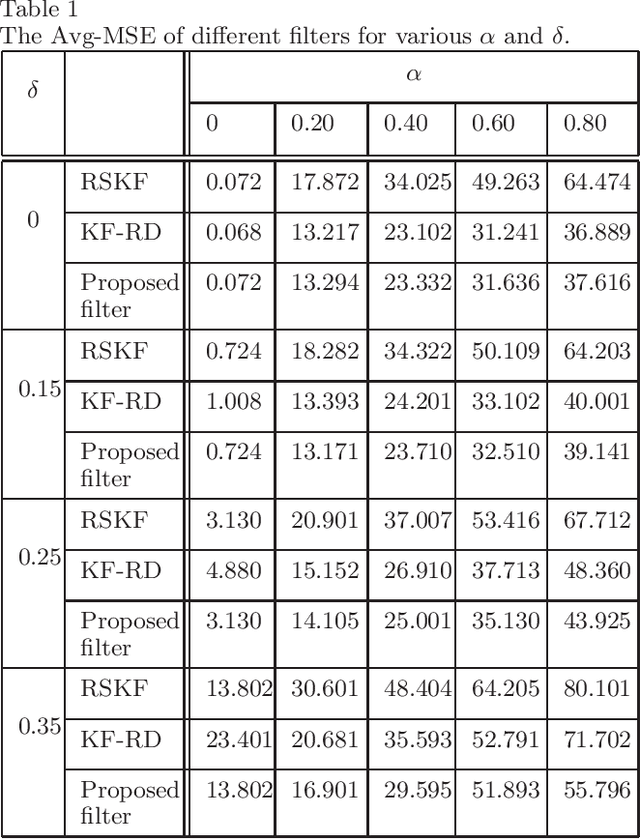

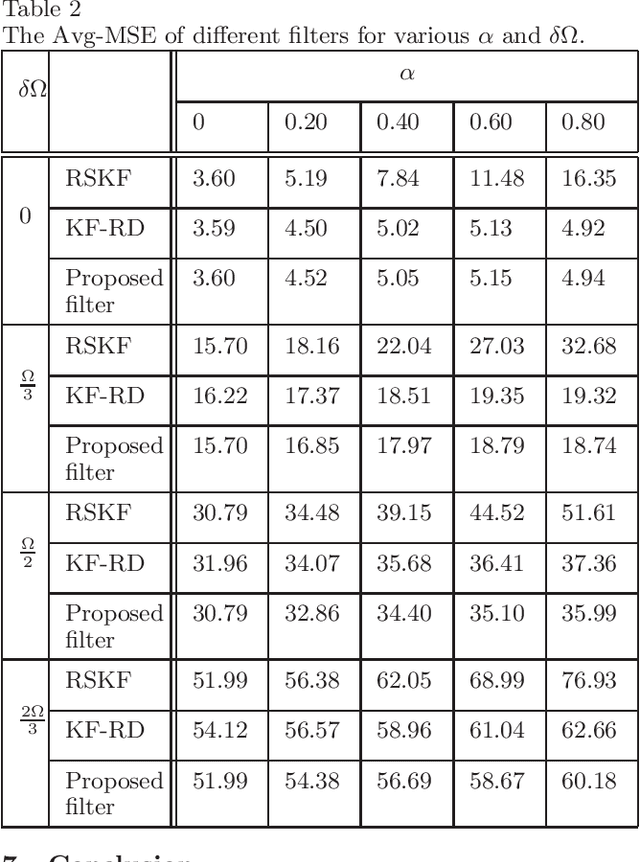
Conventional Bayesian estimation requires an accurate stochastic model of a system. However, this requirement is not always met in many practical cases where the system is not completely known or may differ from the assumed model. For such a system, we consider a scenario where the measurements are transmitted to a remote location using a common communication network and due to which, a delay is introduced while receiving the measurements. The delay that we consider here is random and one step maximum at a given time instant. For such a scenario, this paper develops a robust estimator for a linear Gaussian system by minimizing the risk sensitive error criterion that is defined as an expectation of the accumulated exponential quadratic error. The criteria for the stability of the risk sensitive Kalman filter (RSKF) are derived and the results are used to study the stability of the developed filter. Further, it is assumed that the latency probability related to delay is not known and it is estimated by maximizing the likelihood function. Simulation results suggest that the proposed filter shows acceptable performance under the nominal conditions, and it performs better than the Kalman filter for randomly delayed measurements and the RSKF in presence of both the model uncertainty and random delays.
* 15 pages and 6 Figures. The paper is published in Automatica
Fully Convolutional Networks for Dense Water Flow Intensity Prediction in Swedish Catchment Areas
Apr 04, 2023
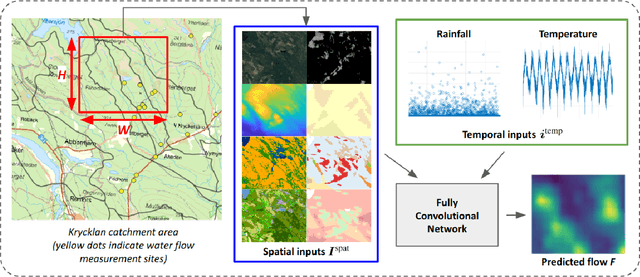
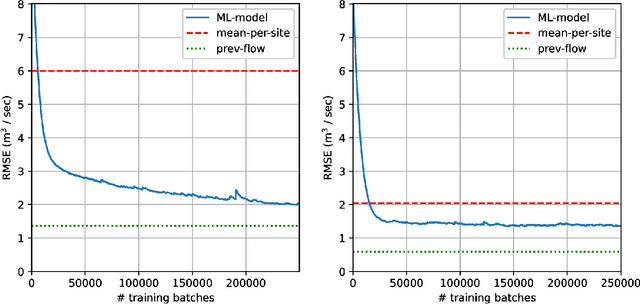
Intensifying climate change will lead to more extreme weather events, including heavy rainfall and drought. Accurate stream flow prediction models which are adaptable and robust to new circumstances in a changing climate will be an important source of information for decisions on climate adaptation efforts, especially regarding mitigation of the risks of and damages associated with flooding. In this work we propose a machine learning-based approach for predicting water flow intensities in inland watercourses based on the physical characteristics of the catchment areas, obtained from geospatial data (including elevation and soil maps, as well as satellite imagery), in addition to temporal information about past rainfall quantities and temperature variations. We target the one-day-ahead regime, where a fully convolutional neural network model receives spatio-temporal inputs and predicts the water flow intensity in every coordinate of the spatial input for the subsequent day. To the best of our knowledge, we are the first to tackle the task of dense water flow intensity prediction; earlier works have considered predicting flow intensities at a sparse set of locations at a time. An extensive set of model evaluations and ablations are performed, which empirically justify our various design choices. Code and preprocessed data have been made publicly available at https://github.com/aleksispi/fcn-water-flow.
Competitive plasticity to reduce the energetic costs of learning
Apr 04, 2023The brain is not only constrained by energy needed to fuel computation, but it is also constrained by energy needed to form memories. Experiments have shown that learning simple conditioning tasks already carries a significant metabolic cost. Yet, learning a task like MNIST to 95% accuracy appears to require at least 10^{8} synaptic updates. Therefore the brain has likely evolved to be able to learn using as little energy as possible. We explored the energy required for learning in feedforward neural networks. Based on a parsimonious energy model, we propose two plasticity restricting algorithms that save energy: 1) only modify synapses with large updates, and 2) restrict plasticity to subsets of synapses that form a path through the network. Combining these two methods leads to substantial energy savings while only incurring a small increase in learning time. In biology networks are often much larger than the task requires. In particular in that case, large savings can be achieved. Thus competitively restricting plasticity helps to save metabolic energy associated to synaptic plasticity. The results might lead to a better understanding of biological plasticity and a better match between artificial and biological learning. Moreover, the algorithms might also benefit hardware because in electronics memory storage is energetically costly as well.
Online augmentation of learned grasp sequence policies for more adaptable and data-efficient in-hand manipulation
Apr 04, 2023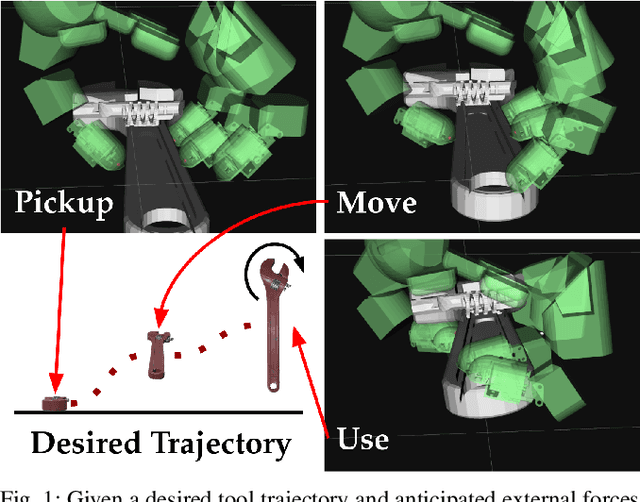
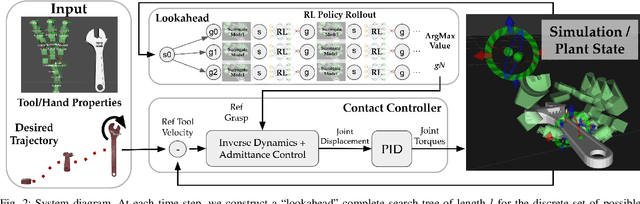
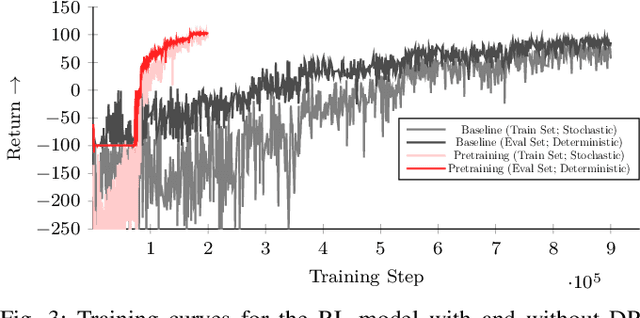
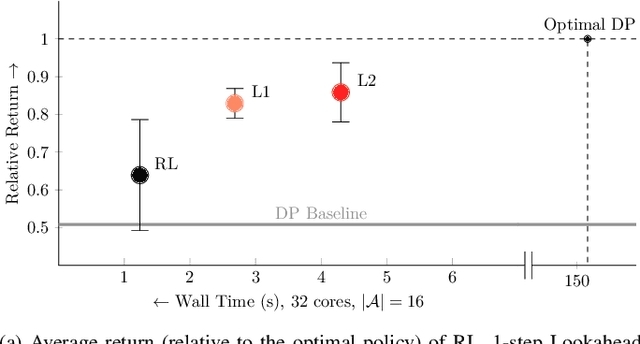
When using a tool, the grasps used for picking it up, reposing, and holding it in a suitable pose for the desired task could be distinct. Therefore, a key challenge for autonomous in-hand tool manipulation is finding a sequence of grasps that facilitates every step of the tool use process while continuously maintaining force closure and stability. Due to the complexity of modeling the contact dynamics, reinforcement learning (RL) techniques can provide a solution in this continuous space subject to highly parameterized physical models. However, these techniques impose a trade-off in adaptability and data efficiency. At test time the tool properties, desired trajectory, and desired application forces could differ substantially from training scenarios. Adapting to this necessitates more data or computationally expensive online policy updates. In this work, we apply the principles of discrete dynamic programming (DP) to augment RL performance with domain knowledge. Specifically, we first design a computationally simple approximation of our environment. We then demonstrate in physical simulation that performing tree searches (i.e., lookaheads) and policy rollouts with this approximation can improve an RL-derived grasp sequence policy with minimal additional online computation. Additionally, we show that pretraining a deep RL network with the DP-derived solution to the discretized problem can speed up policy training.
Online Joint Assortment-Inventory Optimization under MNL Choices
Apr 04, 2023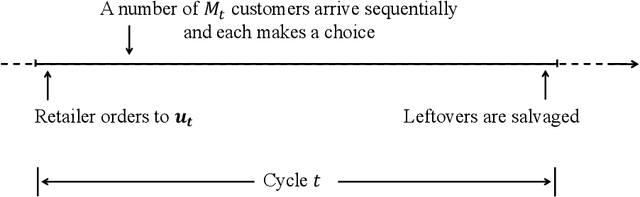

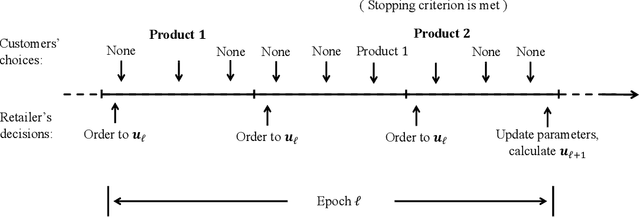
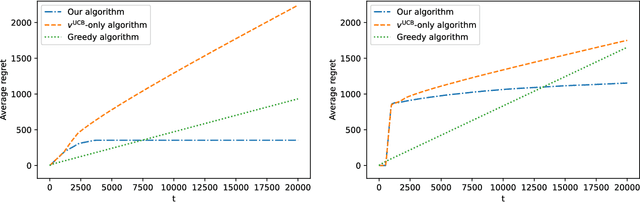
We study an online joint assortment-inventory optimization problem, in which we assume that the choice behavior of each customer follows the Multinomial Logit (MNL) choice model, and the attraction parameters are unknown a priori. The retailer makes periodic assortment and inventory decisions to dynamically learn from the realized demands about the attraction parameters while maximizing the expected total profit over time. In this paper, we propose a novel algorithm that can effectively balance the exploration and exploitation in the online decision-making of assortment and inventory. Our algorithm builds on a new estimator for the MNL attraction parameters, a novel approach to incentivize exploration by adaptively tuning certain known and unknown parameters, and an optimization oracle to static single-cycle assortment-inventory planning problems with given parameters. We establish a regret upper bound for our algorithm and a lower bound for the online joint assortment-inventory optimization problem, suggesting that our algorithm achieves nearly optimal regret rate, provided that the static optimization oracle is exact. Then we incorporate more practical approximate static optimization oracles into our algorithm, and bound from above the impact of static optimization errors on the regret of our algorithm. At last, we perform numerical studies to demonstrate the effectiveness of our proposed algorithm.
Category Query Learning for Human-Object Interaction Classification
Mar 24, 2023
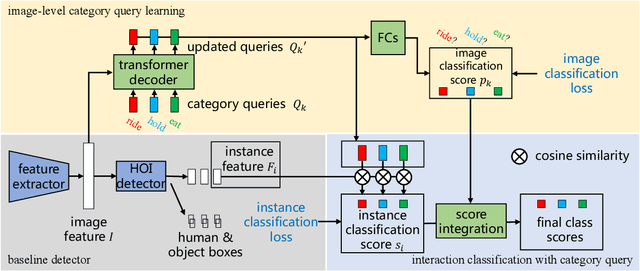
Unlike most previous HOI methods that focus on learning better human-object features, we propose a novel and complementary approach called category query learning. Such queries are explicitly associated to interaction categories, converted to image specific category representation via a transformer decoder, and learnt via an auxiliary image-level classification task. This idea is motivated by an earlier multi-label image classification method, but is for the first time applied for the challenging human-object interaction classification task. Our method is simple, general and effective. It is validated on three representative HOI baselines and achieves new state-of-the-art results on two benchmarks.
A Policy Iteration Approach for Flock Motion Control
Mar 17, 2023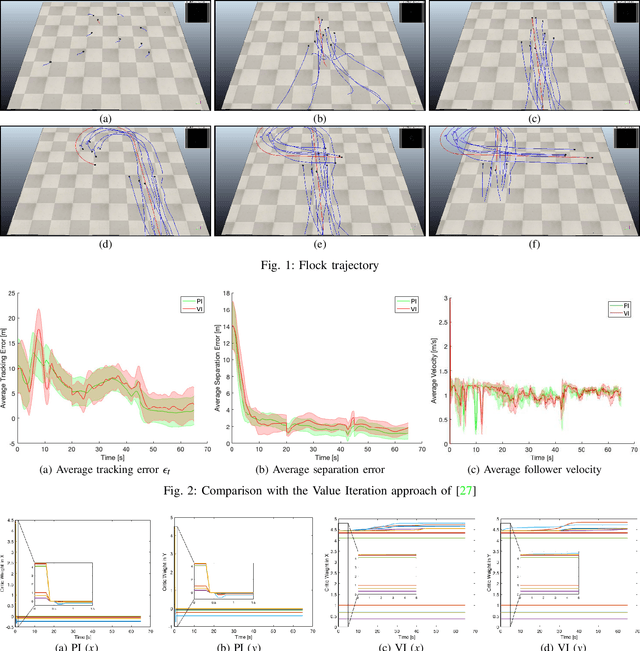
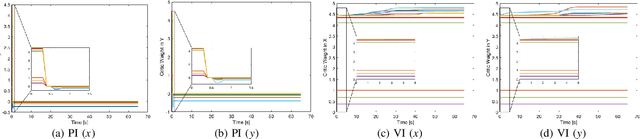
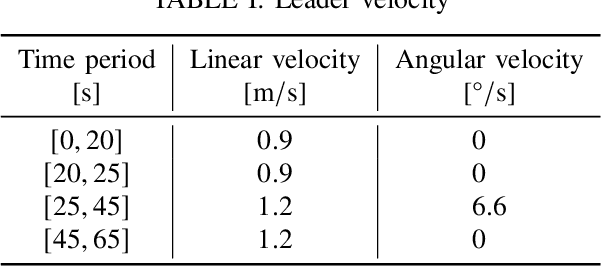
The flocking motion control is concerned with managing the possible conflicts between local and team objectives of multi-agent systems. The overall control process guides the agents while monitoring the flock-cohesiveness and localization. The underlying mechanisms may degrade due to overlooking the unmodeled uncertainties associated with the flock dynamics and formation. On another side, the efficiencies of the various control designs rely on how quickly they can adapt to different dynamic situations in real-time. An online model-free policy iteration mechanism is developed here to guide a flock of agents to follow an independent command generator over a time-varying graph topology. The strength of connectivity between any two agents or the graph edge weight is decided using a position adjacency dependent function. An online recursive least squares approach is adopted to tune the guidance strategies without knowing the dynamics of the agents or those of the command generator. It is compared with another reinforcement learning approach from the literature which is based on a value iteration technique. The simulation results of the policy iteration mechanism revealed fast learning and convergence behaviors with less computational effort.
* 7 pages, 3 figures