 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ATM Fraud Detection using Streaming Data Analytics
Mar 08, 2023
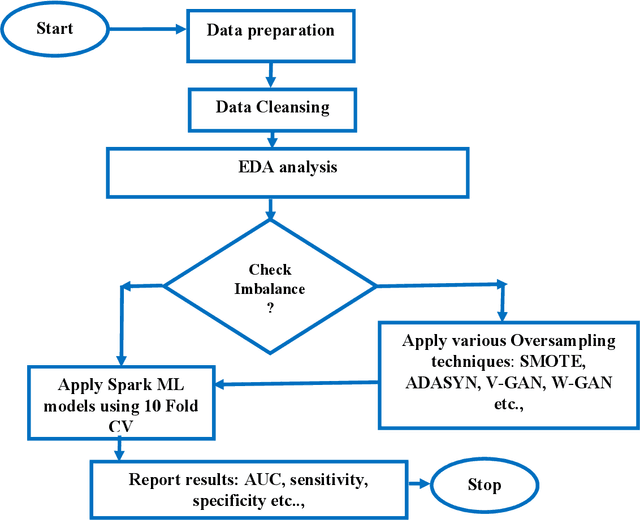
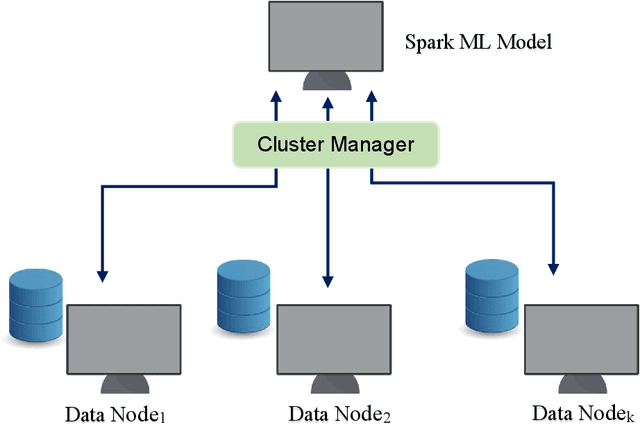

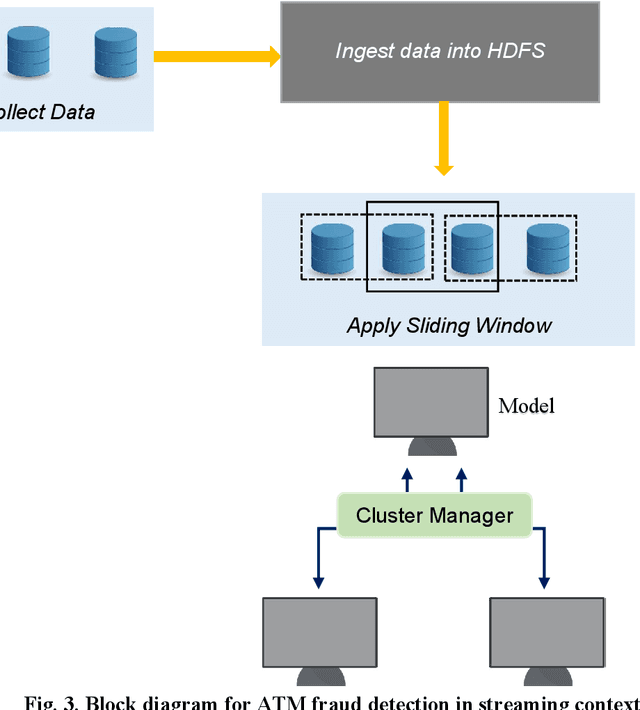
Gaining the trust and confidence of customers is the essence of the growth and success of financial institutions and organizations. Of late, the financial industry is significantly impacted by numerous instances of fraudulent activities. Further, owing to the generation of large voluminous datasets, it is highly essential that underlying framework is scalable and meet real time needs. To address this issue, in the study, we proposed ATM fraud detection in static and streaming contexts respectively. In the static context, we investigated a parallel and scalable machine learning algorithms for ATM fraud detection that is built on Spark and trained with a variety of machine learning (ML) models including Naive Bayes (NB), Logistic Regression (LR), Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), Gradient Boosting Tree (GBT), and Multi-layer perceptron (MLP). We also employed several balancing techniques like Synthetic Minority Oversampling Technique (SMOTE) and its variants, Generative Adversarial Networks (GAN), to address the rarity in the dataset. In addition, we proposed a streaming based ATM fraud detection in the streaming context. Our sliding window based method collects ATM transactions that are performed within a specified time interval and then utilizes to train several ML models, including NB, RF, DT, and K-Nearest Neighbour (KNN). We selected these models based on their less model complexity and quicker response time. In both contexts, RF turned out to be the best model. RF obtained the best mean AUC of 0.975 in the static context and mean AUC of 0.910 in the streaming context. RF is also empirically proven to be statistically significant than the next-best performing models.
Bluetooth and WiFi Dataset for Real World RF Fingerprinting of Commercial Devices
Mar 15, 2023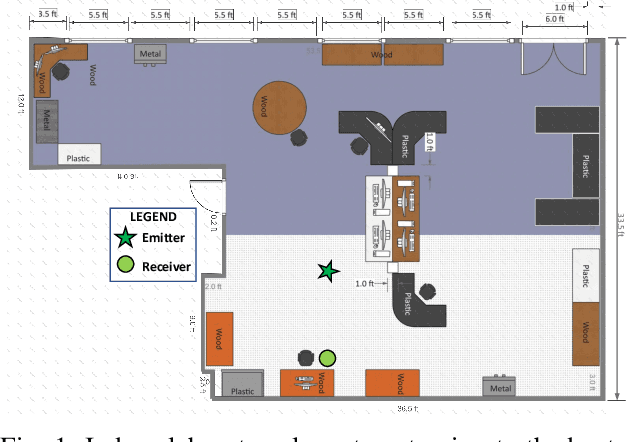
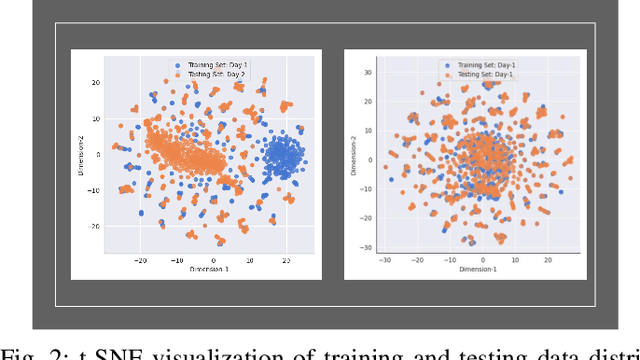
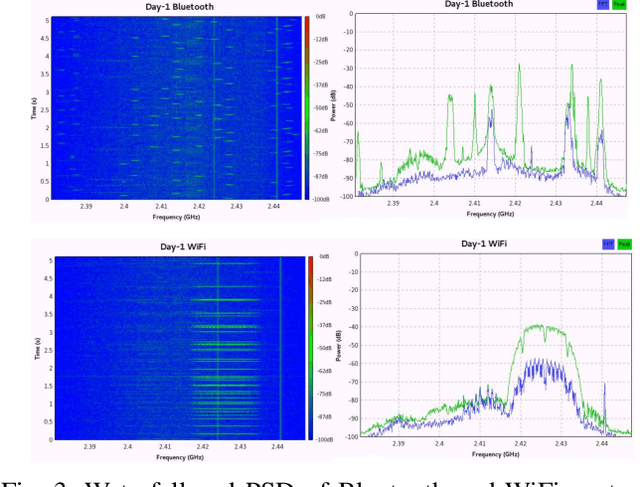
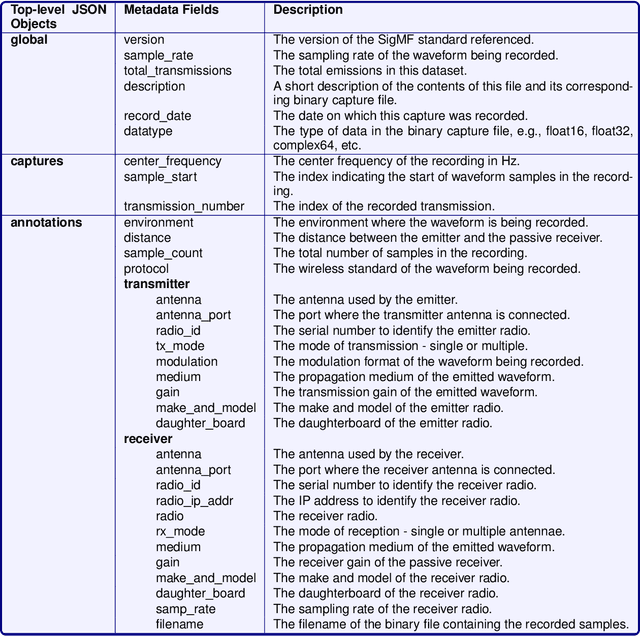
RF fingerprinting is emerging as a physical layer security scheme to identify illegitimate and/or unauthorized emitters sharing the RF spectrum. However, due to the lack of publicly accessible real-world datasets, most research focuses on generating synthetic waveforms with software-defined radios (SDRs) which are not suited for practical deployment settings. On other hand, the limited datasets that are available focus only on chipsets that generate only one kind of waveform. Commercial off-the-shelf (COTS) combo chipsets that support two wireless standards (for example WiFi and Bluetooth) over a shared dual-band antenna such as those found in laptops, adapters, wireless chargers, Raspberry Pis, among others are becoming ubiquitous in the IoT realm. Hence, to keep up with the modern IoT environment, there is a pressing need for real-world open datasets capturing emissions from these combo chipsets transmitting heterogeneous communication protocols. To this end, we capture the first known emissions from the COTS IoT chipsets transmitting WiFi and Bluetooth under two different time frames. The different time frames are essential to rigorously evaluate the generalization capability of the models. To ensure widespread use, each capture within the comprehensive 72 GB dataset is long enough (40 MSamples) to support diverse input tensor lengths and formats. Finally, the dataset also comprises emissions at varying signal powers to account for the feeble to high signal strength emissions as encountered in a real-world setting.
Graph-based Simultaneous Coverage and Exploration Planning for Fast Multi-robot Search
Mar 03, 2023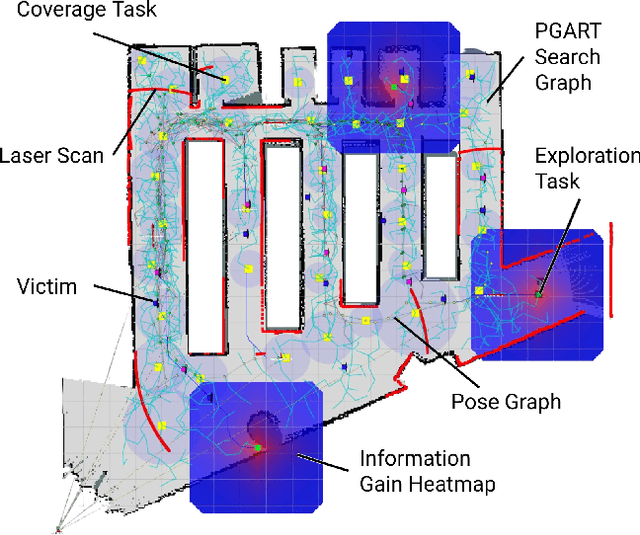
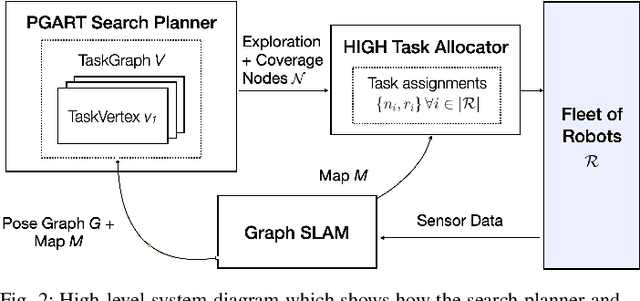
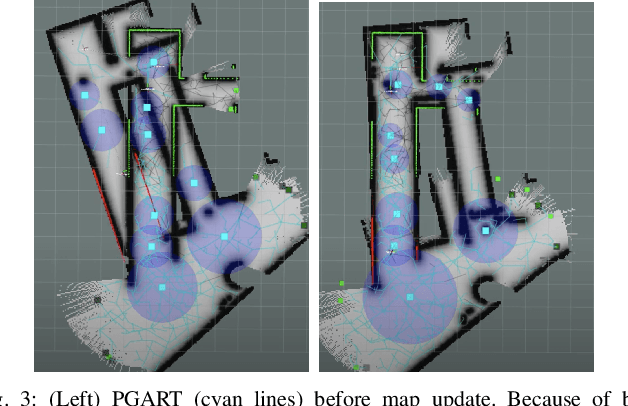
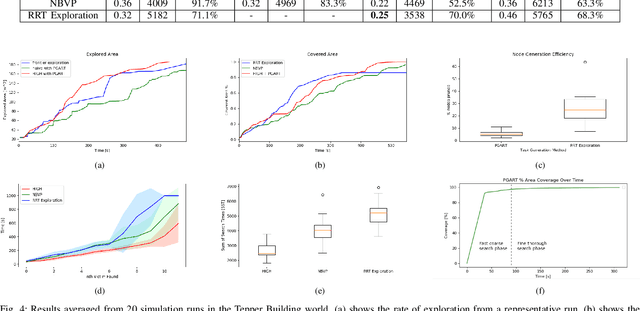
In large unknown environments, search operations can be much more time-efficient with the use of multi-robot fleets by parallelizing efforts. This means robots must efficiently perform collaborative mapping (exploration) while simultaneously searching an area for victims (coverage). Previous simultaneous mapping and planning techniques treat these problems as separate and do not take advantage of the possibility for a unified approach. We propose a novel exploration-coverage planner which bridges the mapping and search domains by growing sets of random trees rooted upon a pose graph produced through mapping to generate points of interest, or tasks. Furthermore, it is important for the robots to first prioritize high information tasks to locate the greatest number of victims in minimum time by balancing coverage and exploration, which current methods do not address. Towards this goal, we also present a new multi-robot task allocator that formulates a notion of a hierarchical information heuristic for time-critical collaborative search. Our results show that our algorithm produces 20% more coverage efficiency, defined as average covered area per second, compared to the existing state-of-the-art. Our algorithms and the rest of our multi-robot search stack is based in ROS and made open source
(1,1)-Cluster Editing is Polynomial-time Solvable
Oct 14, 2022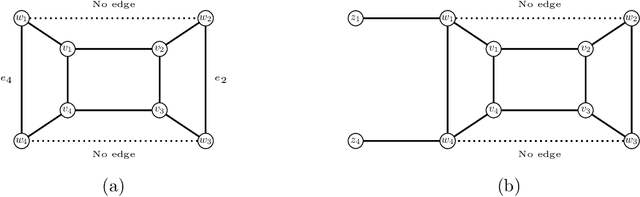
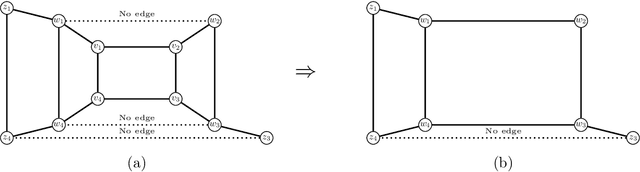
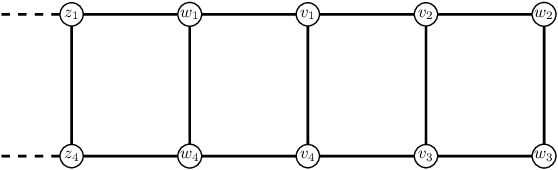
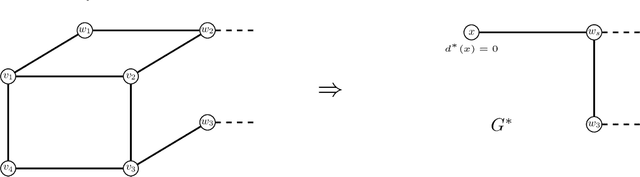
A graph $H$ is a clique graph if $H$ is a vertex-disjoin union of cliques. Abu-Khzam (2017) introduced the $(a,d)$-{Cluster Editing} problem, where for fixed natural numbers $a,d$, given a graph $G$ and vertex-weights $a^*:\ V(G)\rightarrow \{0,1,\dots, a\}$ and $d^*{}:\ V(G)\rightarrow \{0,1,\dots, d\}$, we are to decide whether $G$ can be turned into a cluster graph by deleting at most $d^*(v)$ edges incident to every $v\in V(G)$ and adding at most $a^*(v)$ edges incident to every $v\in V(G)$. Results by Komusiewicz and Uhlmann (2012) and Abu-Khzam (2017) provided a dichotomy of complexity (in P or NP-complete) of $(a,d)$-{Cluster Editing} for all pairs $a,d$ apart from $a=d=1.$ Abu-Khzam (2017) conjectured that $(1,1)$-{Cluster Editing} is in P. We resolve Abu-Khzam's conjecture in affirmative by (i) providing a serious of five polynomial-time reductions to $C_3$-free and $C_4$-free graphs of maximum degree at most 3, and (ii) designing a polynomial-time algorithm for solving $(1,1)$-{Cluster Editing} on $C_3$-free and $C_4$-free graphs of maximum degree at most 3.
Adaptive Finite-Time Model Estimation and Control for Manipulator Visual Servoing using Sliding Mode Control and Neural Networks
Nov 21, 2022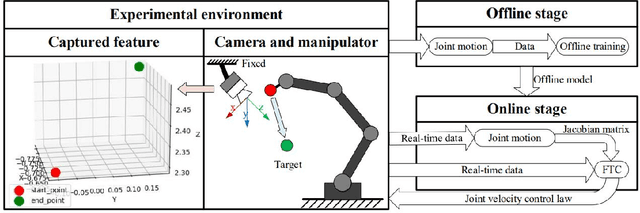
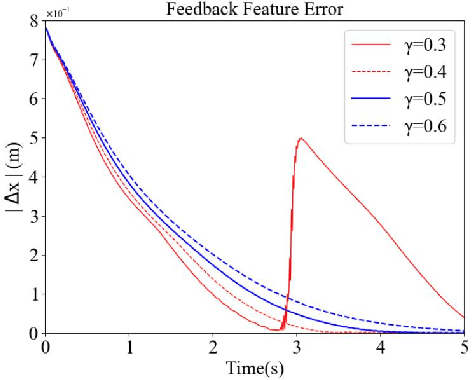
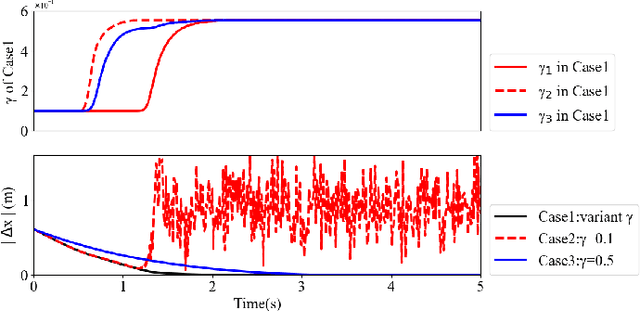
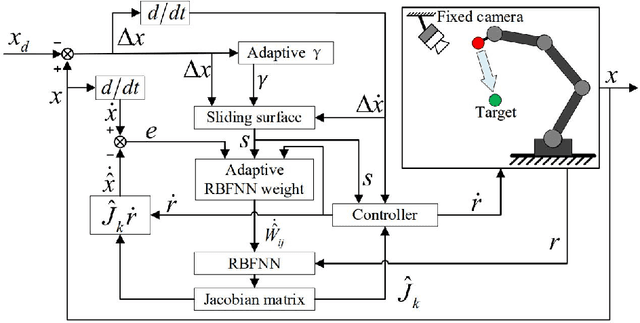
The image-based visual servoing without models of system is challenging since it is hard to fetch an accurate estimation of hand-eye relationship via merely visual measurement. Whereas, the accuracy of estimated hand-eye relationship expressed in local linear format with Jacobian matrix is important to whole system's performance. In this article, we proposed a finite-time controller as well as a Jacobian matrix estimator in a combination of online and offline way. The local linear formulation is formulated first. Then, we use a combination of online and offline method to boost the estimation of the highly coupled and nonlinear hand-eye relationship with data collected via depth camera. A neural network (NN) is pre-trained to give a relative reasonable initial estimation of Jacobian matrix. Then, an online updating method is carried out to modify the offline trained NN for a more accurate estimation. Moreover, sliding mode control algorithm is introduced to realize a finite-time controller. Compared with previous methods, our algorithm possesses better convergence speed. The proposed estimator possesses excellent performance in the accuracy of initial estimation and powerful tracking capabilities for time-varying estimation for Jacobian matrix compared with other data-driven estimators. The proposed scheme acquires the combination of neural network and finite-time control effect which drives a faster convergence speed compared with the exponentially converge ones. Another main feature of our algorithm is that the state signals in system is proved to be semi-global practical finite-time stable. Several experiments are carried out to validate proposed algorithm's performance.
Forecasting with Deep Learning
Feb 17, 2023
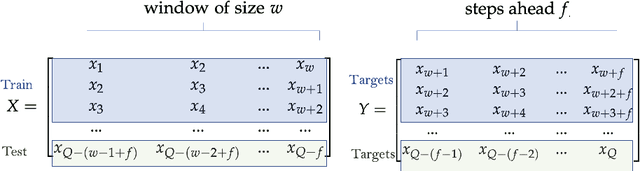
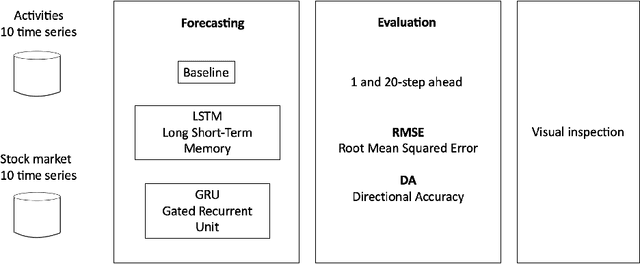
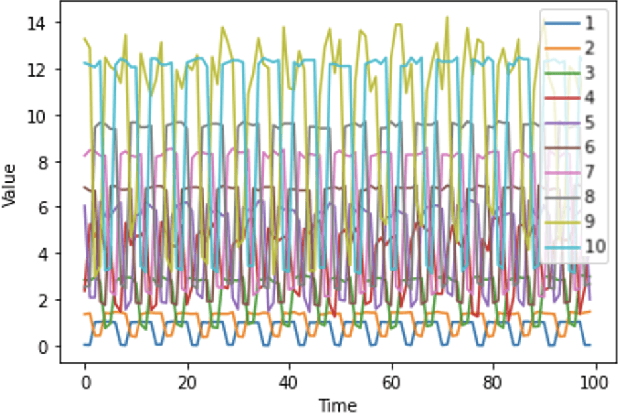
This paper presents a method for time series forecasting with deep learning and its assessment on two datasets. The method starts with data preparation, followed by model training and evaluation. The final step is a visual inspection. Experimental work demonstrates that a single time series can be used to train deep learning networks if time series in a dataset contain patterns that repeat even with a certain variation. However, for less structured time series such as stock market closing prices, the networks perform just like a baseline that repeats the last observed value. The implementation of the method as well as the experiments are open-source.
TiAda: A Time-scale Adaptive Algorithm for Nonconvex Minimax Optimization
Oct 31, 2022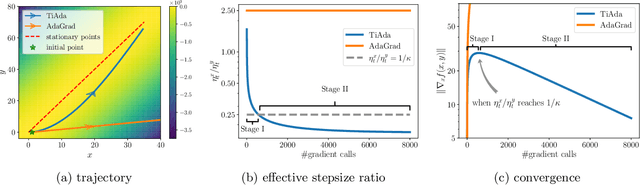

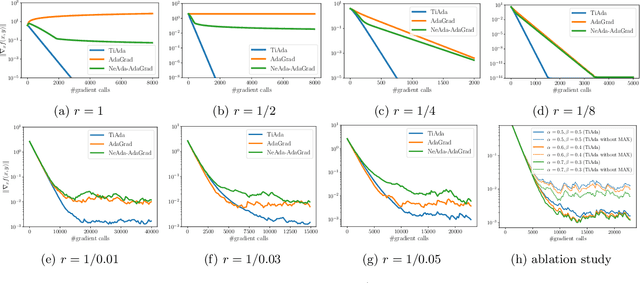
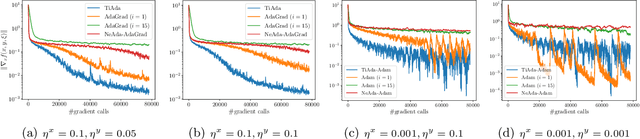
Adaptive gradient methods have shown their ability to adjust the stepsizes on the fly in a parameter-agnostic manner, and empirically achieve faster convergence for solving minimization problems. When it comes to nonconvex minimax optimization, however, current convergence analyses of gradient descent ascent (GDA) combined with adaptive stepsizes require careful tuning of hyper-parameters and the knowledge of problem-dependent parameters. Such a discrepancy arises from the primal-dual nature of minimax problems and the necessity of delicate time-scale separation between the primal and dual updates in attaining convergence. In this work, we propose a single-loop adaptive GDA algorithm called TiAda for nonconvex minimax optimization that automatically adapts to the time-scale separation. Our algorithm is fully parameter-agnostic and can achieve near-optimal complexities simultaneously in deterministic and stochastic settings of nonconvex-strongly-concave minimax problems. The effectiveness of the proposed method is further justified numerically for a number of machine learning applications.
Rotating without Seeing: Towards In-hand Dexterity through Touch
Mar 27, 2023


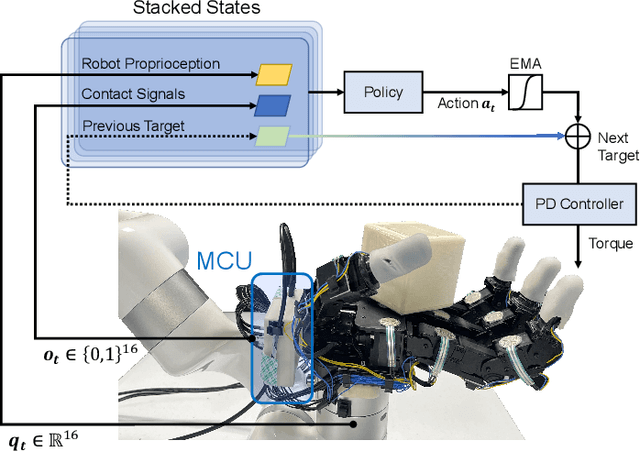
Tactile information plays a critical role in human dexterity. It reveals useful contact information that may not be inferred directly from vision. In fact, humans can even perform in-hand dexterous manipulation without using vision. Can we enable the same ability for the multi-finger robot hand? In this paper, we present Touch Dexterity, a new system that can perform in-hand object rotation using only touching without seeing the object. Instead of relying on precise tactile sensing in a small region, we introduce a new system design using dense binary force sensors (touch or no touch) overlaying one side of the whole robot hand (palm, finger links, fingertips). Such a design is low-cost, giving a larger coverage of the object, and minimizing the Sim2Real gap at the same time. We train an in-hand rotation policy using Reinforcement Learning on diverse objects in simulation. Relying on touch-only sensing, we can directly deploy the policy in a real robot hand and rotate novel objects that are not presented in training. Extensive ablations are performed on how tactile information help in-hand manipulation.Our project is available at https://touchdexterity.github.io.
The Resource Problem of Using Linear Layer Leakage Attack in Federated Learning
Mar 27, 2023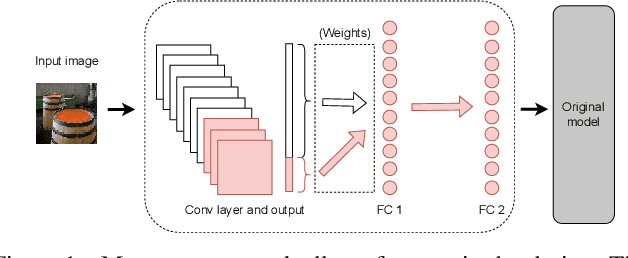
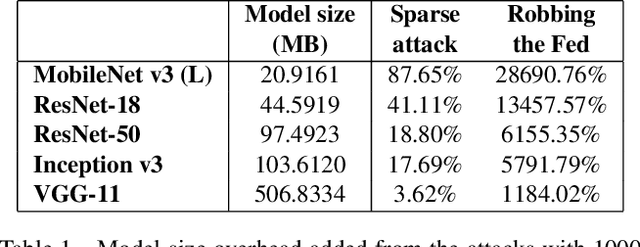
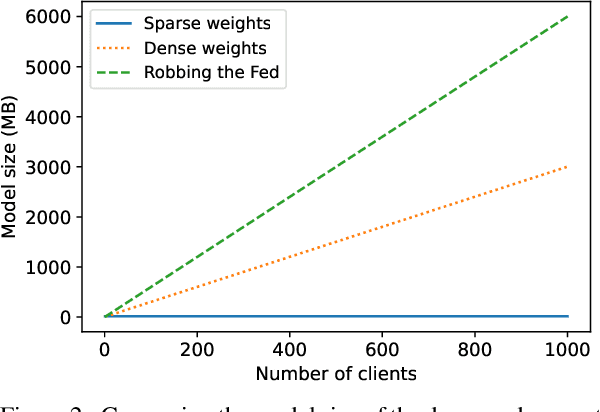
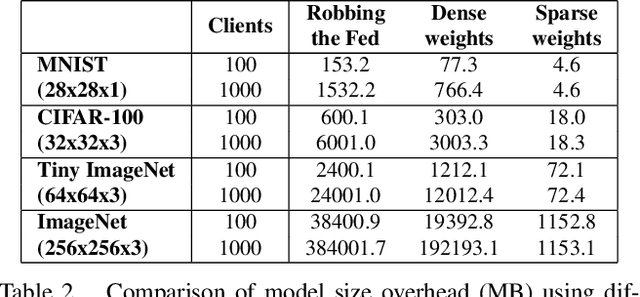
Secure aggregation promises a heightened level of privacy in federated learning, maintaining that a server only has access to a decrypted aggregate update. Within this setting, linear layer leakage methods are the only data reconstruction attacks able to scale and achieve a high leakage rate regardless of the number of clients or batch size. This is done through increasing the size of an injected fully-connected (FC) layer. However, this results in a resource overhead which grows larger with an increasing number of clients. We show that this resource overhead is caused by an incorrect perspective in all prior work that treats an attack on an aggregate update in the same way as an individual update with a larger batch size. Instead, by attacking the update from the perspective that aggregation is combining multiple individual updates, this allows the application of sparsity to alleviate resource overhead. We show that the use of sparsity can decrease the model size overhead by over 327$\times$ and the computation time by 3.34$\times$ compared to SOTA while maintaining equivalent total leakage rate, 77% even with $1000$ clients in aggregation.
Multi-Granularity Archaeological Dating of Chinese Bronze Dings Based on a Knowledge-Guided Relation Graph
Mar 27, 2023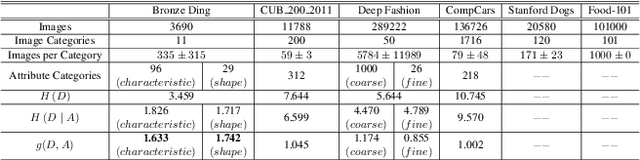

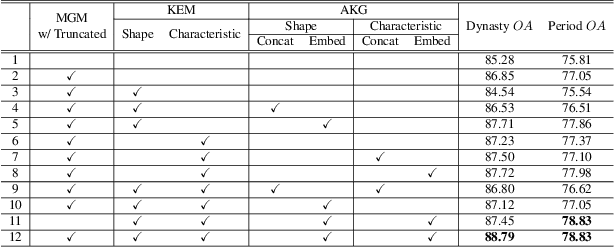
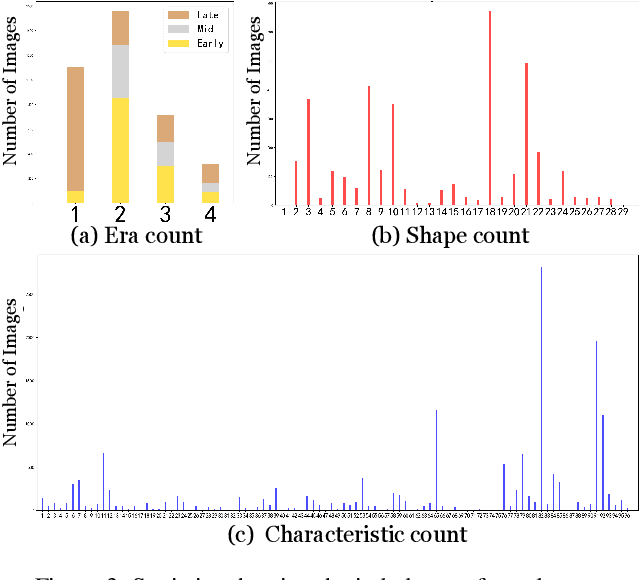
The archaeological dating of bronze dings has played a critical role in the study of ancient Chinese history. Current archaeology depends on trained experts to carry out bronze dating, which is time-consuming and labor-intensive. For such dating, in this study, we propose a learning-based approach to integrate advanced deep learning techniques and archaeological knowledge. To achieve this, we first collect a large-scale image dataset of bronze dings, which contains richer attribute information than other existing fine-grained datasets. Second, we introduce a multihead classifier and a knowledge-guided relation graph to mine the relationship between attributes and the ding era. Third, we conduct comparison experiments with various existing methods, the results of which show that our dating method achieves a state-of-the-art performance. We hope that our data and applied networks will enrich fine-grained classification research relevant to other interdisciplinary areas of expertise. The dataset and source code used are included in our supplementary materials, and will be open after submission owing to the anonymity policy. Source codes and data are available at: https://github.com/zhourixin/bronze-Ding.