 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Dynamic Synchronous Functional Brain Network for Schizophrenia Diagnosis and Lateralization Analysis
Apr 06, 2023

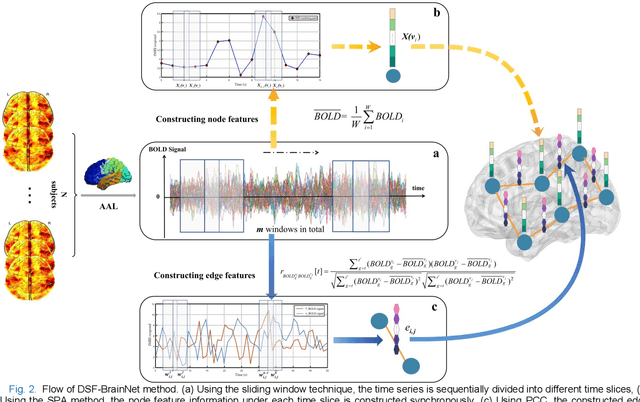
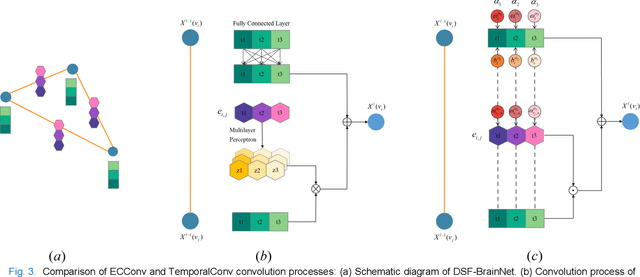
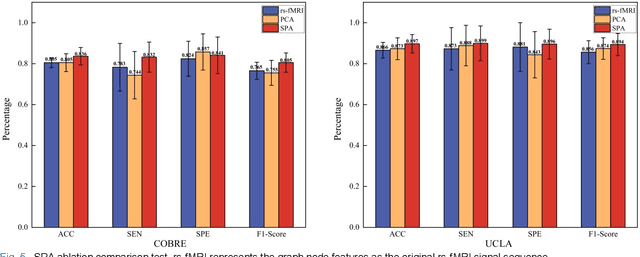
The available evidence suggests that dynamic functional connectivity (dFC) can capture time-varying abnormalities in brain activity in resting-state cerebral functional magnetic resonance imaging (rs-fMRI) data and has a natural advantage in uncovering mechanisms of abnormal brain activity in schizophrenia(SZ) patients. Hence, an advanced dynamic brain network analysis model called the temporal brain category graph convolutional network (Temporal-BCGCN) was employed. Firstly, a unique dynamic brain network analysis module, DSF-BrainNet, was designed to construct dynamic synchronization features. Subsequently, a revolutionary graph convolution method, TemporalConv, was proposed, based on the synchronous temporal properties of feature. Finally, the first modular abnormal hemispherical lateralization test tool in deep learning based on rs-fMRI data, named CategoryPool, was proposed. This study was validated on COBRE and UCLA datasets and achieved 83.62% and 89.71% average accuracies, respectively, outperforming the baseline model and other state-of-the-art methods. The ablation results also demonstrate the advantages of TemporalConv over the traditional edge feature graph convolution approach and the improvement of CategoryPool over the classical graph pooling approach. Interestingly, this study showed that the lower order perceptual system and higher order network regions in the left hemisphere are more severely dysfunctional than in the right hemisphere in SZ and reaffirms the importance of the left medial superior frontal gyrus in SZ. Our core code is available at: https://github.com/swfen/Temporal-BCGCN.
NTK-SAP: Improving neural network pruning by aligning training dynamics
Apr 06, 2023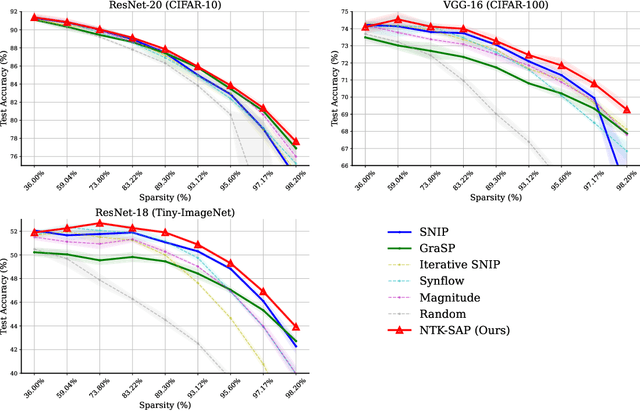
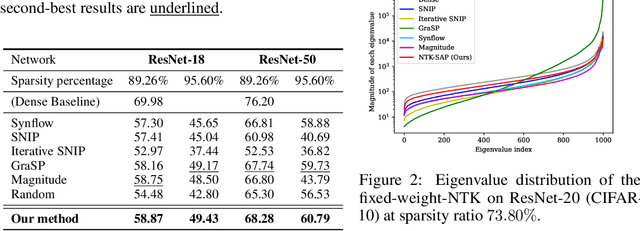

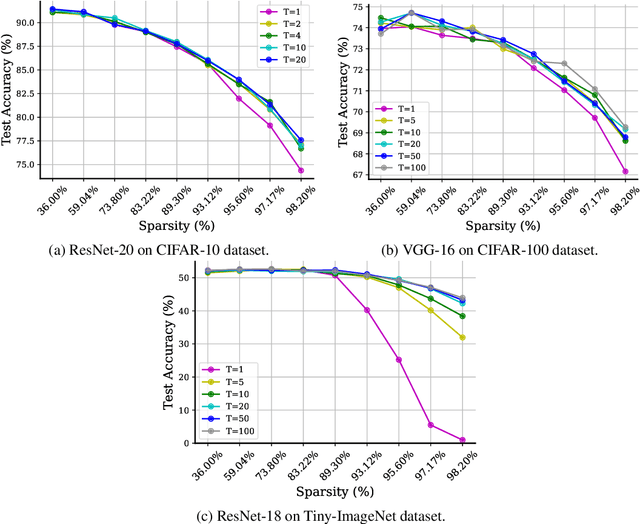
Pruning neural networks before training has received increasing interest due to its potential to reduce training time and memory. One popular method is to prune the connections based on a certain metric, but it is not entirely clear what metric is the best choice. Recent advances in neural tangent kernel (NTK) theory suggest that the training dynamics of large enough neural networks is closely related to the spectrum of the NTK. Motivated by this finding, we propose to prune the connections that have the least influence on the spectrum of the NTK. This method can help maintain the NTK spectrum, which may help align the training dynamics to that of its dense counterpart. However, one possible issue is that the fixed-weight-NTK corresponding to a given initial point can be very different from the NTK corresponding to later iterates during the training phase. We further propose to sample multiple realizations of random weights to estimate the NTK spectrum. Note that our approach is weight-agnostic, which is different from most existing methods that are weight-dependent. In addition, we use random inputs to compute the fixed-weight-NTK, making our method data-agnostic as well. We name our foresight pruning algorithm Neural Tangent Kernel Spectrum-Aware Pruning (NTK-SAP). Empirically, our method achieves better performance than all baselines on multiple datasets.
DiffMimic: Efficient Motion Mimicking with Differentiable Physics
Apr 06, 2023
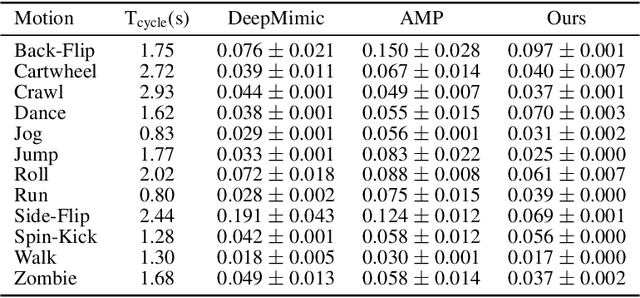
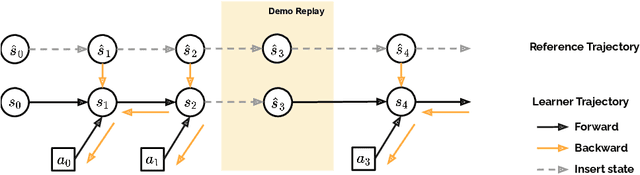
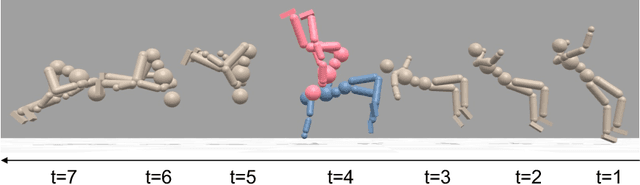
Motion mimicking is a foundational task in physics-based character animation. However, most existing motion mimicking methods are built upon reinforcement learning (RL) and suffer from heavy reward engineering, high variance, and slow convergence with hard explorations. Specifically, they usually take tens of hours or even days of training to mimic a simple motion sequence, resulting in poor scalability. In this work, we leverage differentiable physics simulators (DPS) and propose an efficient motion mimicking method dubbed DiffMimic. Our key insight is that DPS casts a complex policy learning task to a much simpler state matching problem. In particular, DPS learns a stable policy by analytical gradients with ground-truth physical priors hence leading to significantly faster and stabler convergence than RL-based methods. Moreover, to escape from local optima, we utilize a Demonstration Replay mechanism to enable stable gradient backpropagation in a long horizon. Extensive experiments on standard benchmarks show that DiffMimic has a better sample efficiency and time efficiency than existing methods (e.g., DeepMimic). Notably, DiffMimic allows a physically simulated character to learn Backflip after 10 minutes of training and be able to cycle it after 3 hours of training, while the existing approach may require about a day of training to cycle Backflip. More importantly, we hope DiffMimic can benefit more differentiable animation systems with techniques like differentiable clothes simulation in future research.
EZClone: Improving DNN Model Extraction Attack via Shape Distillation from GPU Execution Profiles
Apr 06, 2023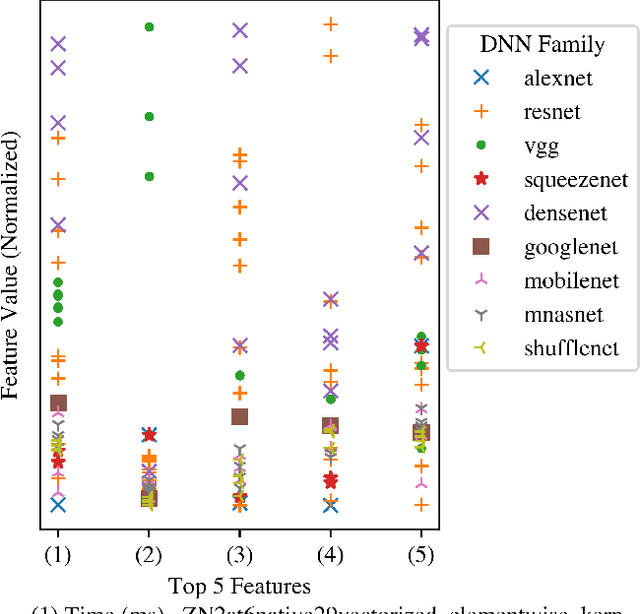
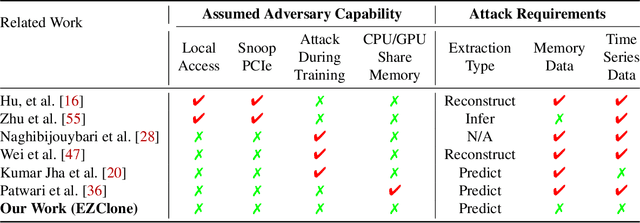
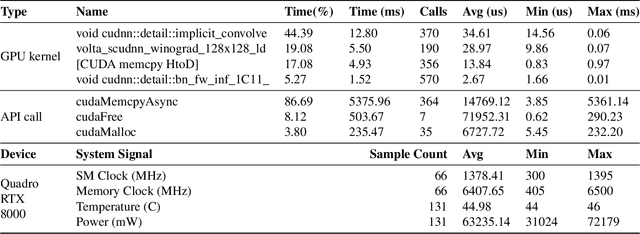
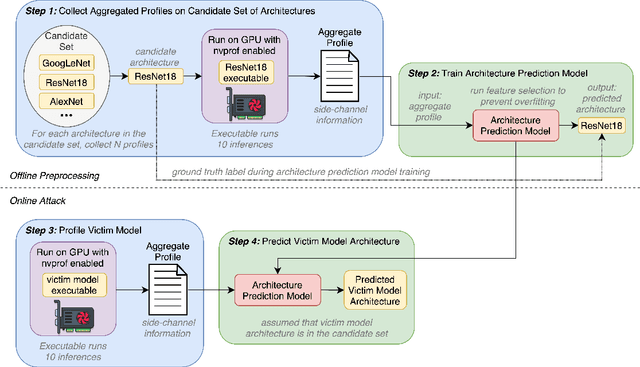
Deep Neural Networks (DNNs) have become ubiquitous due to their performance on prediction and classification problems. However, they face a variety of threats as their usage spreads. Model extraction attacks, which steal DNNs, endanger intellectual property, data privacy, and security. Previous research has shown that system-level side-channels can be used to leak the architecture of a victim DNN, exacerbating these risks. We propose two DNN architecture extraction techniques catering to various threat models. The first technique uses a malicious, dynamically linked version of PyTorch to expose a victim DNN architecture through the PyTorch profiler. The second, called EZClone, exploits aggregate (rather than time-series) GPU profiles as a side-channel to predict DNN architecture, employing a simple approach and assuming little adversary capability as compared to previous work. We investigate the effectiveness of EZClone when minimizing the complexity of the attack, when applied to pruned models, and when applied across GPUs. We find that EZClone correctly predicts DNN architectures for the entire set of PyTorch vision architectures with 100% accuracy. No other work has shown this degree of architecture prediction accuracy with the same adversarial constraints or using aggregate side-channel information. Prior work has shown that, once a DNN has been successfully cloned, further attacks such as model evasion or model inversion can be accelerated significantly.
$R^{2}$Former: Unified $R$etrieval and $R$eranking Transformer for Place Recognition
Apr 06, 2023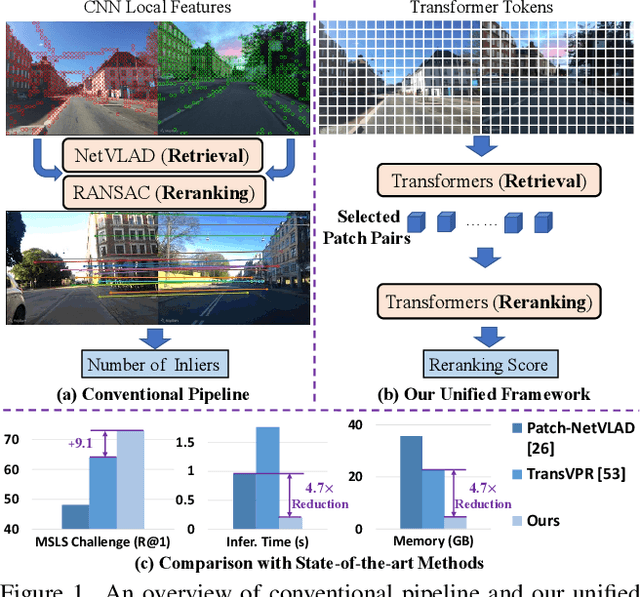
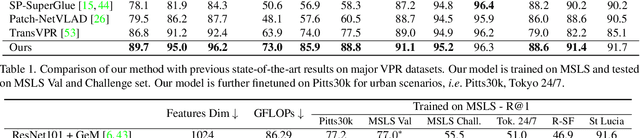
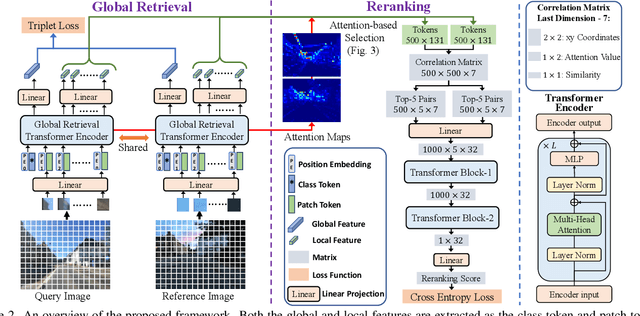

Visual Place Recognition (VPR) estimates the location of query images by matching them with images in a reference database. Conventional methods generally adopt aggregated CNN features for global retrieval and RANSAC-based geometric verification for reranking. However, RANSAC only employs geometric information but ignores other possible information that could be useful for reranking, e.g. local feature correlations, and attention values. In this paper, we propose a unified place recognition framework that handles both retrieval and reranking with a novel transformer model, named $R^{2}$Former. The proposed reranking module takes feature correlation, attention value, and xy coordinates into account, and learns to determine whether the image pair is from the same location. The whole pipeline is end-to-end trainable and the reranking module alone can also be adopted on other CNN or transformer backbones as a generic component. Remarkably, $R^{2}$Former significantly outperforms state-of-the-art methods on major VPR datasets with much less inference time and memory consumption. It also achieves the state-of-the-art on the hold-out MSLS challenge set and could serve as a simple yet strong solution for real-world large-scale applications. Experiments also show vision transformer tokens are comparable and sometimes better than CNN local features on local matching. The code is released at https://github.com/Jeff-Zilence/R2Former.
Development of A Real-time POCUS Image Quality Assessment and Acquisition Guidance System
Dec 19, 2022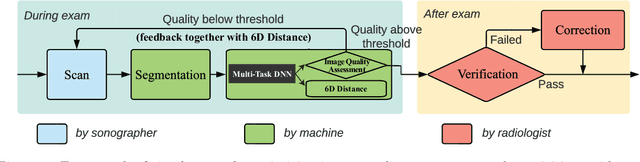
Point-of-care ultrasound (POCUS) is one of the most commonly applied tools for cardiac function imaging in the clinical routine of the emergency department and pediatric intensive care unit. The prior studies demonstrate that AI-assisted software can guide nurses or novices without prior sonography experience to acquire POCUS by recognizing the interest region, assessing image quality, and providing instructions. However, these AI algorithms cannot simply replace the role of skilled sonographers in acquiring diagnostic-quality POCUS. Unlike chest X-ray, CT, and MRI, which have standardized imaging protocols, POCUS can be acquired with high inter-observer variability. Though being with variability, they are usually all clinically acceptable and interpretable. In challenging clinical environments, sonographers employ novel heuristics to acquire POCUS in complex scenarios. To help novice learners to expedite the training process while reducing the dependency on experienced sonographers in the curriculum implementation, We will develop a framework to perform real-time AI-assisted quality assessment and probe position guidance to provide training process for novice learners with less manual intervention.
Baldur: Whole-Proof Generation and Repair with Large Language Models
Mar 16, 2023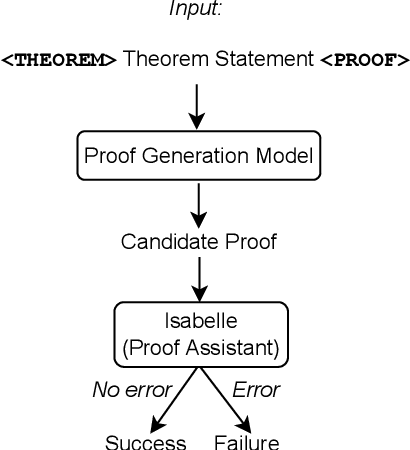
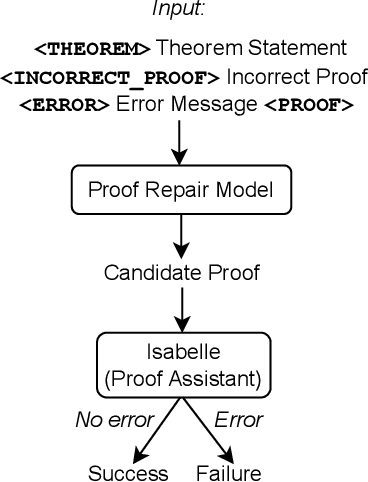
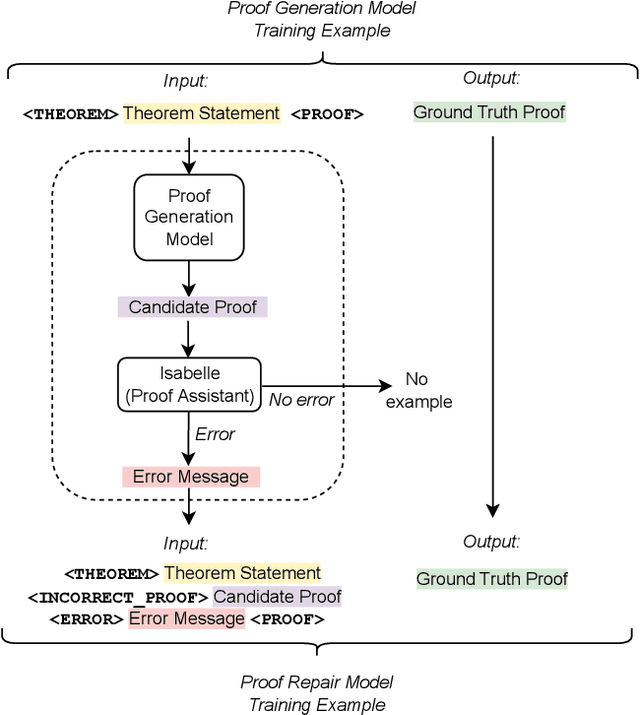
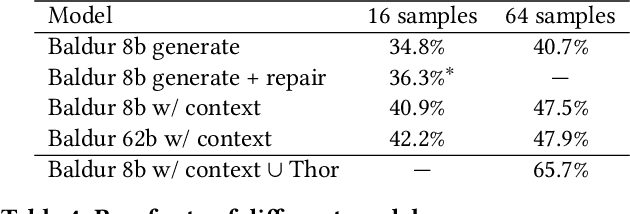
Formally verifying software properties is a highly desirable but labor-intensive task. Recent work has developed methods to automate formal verification using proof assistants, such as Coq and Isabelle/HOL, e.g., by training a model to predict one proof step at a time, and using that model to search through the space of possible proofs. This paper introduces a new method to automate formal verification: We use large language models, trained on natural language text and code and fine-tuned on proofs, to generate whole proofs for theorems at once, rather than one step at a time. We combine this proof generation model with a fine-tuned repair model to repair generated proofs, further increasing proving power. As its main contributions, this paper demonstrates for the first time that: (1) Whole-proof generation using transformers is possible and is as effective as search-based techniques without requiring costly search. (2) Giving the learned model additional context, such as a prior failed proof attempt and the ensuing error message, results in proof repair and further improves automated proof generation. (3) We establish a new state of the art for fully automated proof synthesis. We reify our method in a prototype, Baldur, and evaluate it on a benchmark of 6,336 Isabelle/HOL theorems and their proofs. In addition to empirically showing the effectiveness of whole-proof generation, repair, and added context, we show that Baldur improves on the state-of-the-art tool, Thor, by automatically generating proofs for an additional 8.7% of the theorems. Together, Baldur and Thor can prove 65.7% of the theorems fully automatically. This paper paves the way for new research into using large language models for automating formal verification.
ExoplANNET: A deep learning algorithm to detect and identify planetary signals in radial velocity data
Mar 16, 2023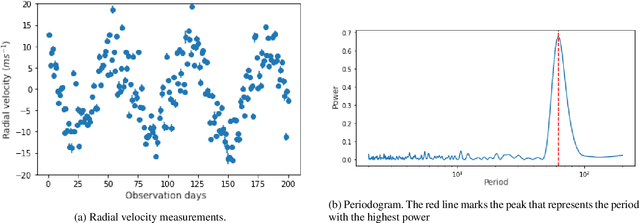
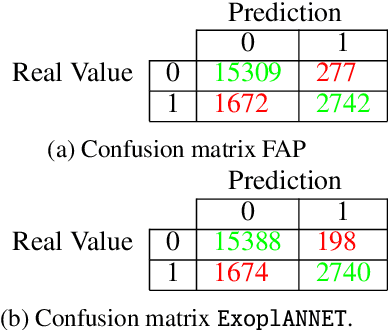
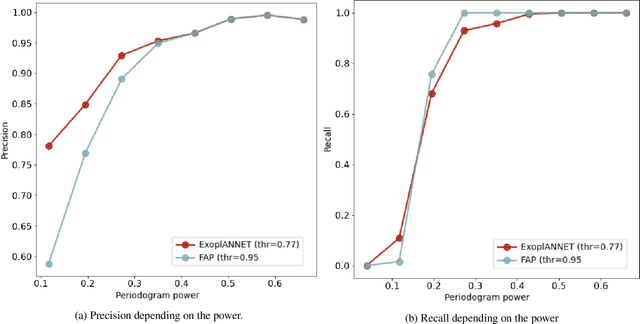
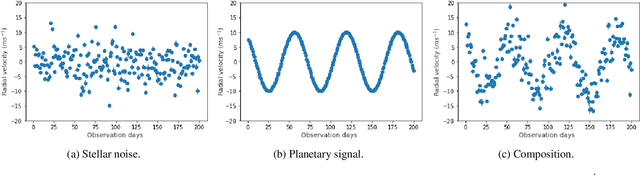
The detection of exoplanets with the radial velocity method consists in detecting variations of the stellar velocity caused by an unseen sub-stellar companion. Instrumental errors, irregular time sampling, and different noise sources originating in the intrinsic variability of the star can hinder the interpretation of the data, and even lead to spurious detections. In recent times, work began to emerge in the field of extrasolar planets that use Machine Learning algorithms, some with results that exceed those obtained with the traditional techniques in the field. We seek to explore the scope of the neural networks in the radial velocity method, in particular for exoplanet detection in the presence of correlated noise of stellar origin. In this work, a neural network is proposed to replace the computation of the significance of the signal detected with the radial velocity method and to classify it as of planetary origin or not. The algorithm is trained using synthetic data of systems with and without planetary companions. We injected realistic correlated noise in the simulations, based on previous studies of the behaviour of stellar activity. The performance of the network is compared to the traditional method based on null hypothesis significance testing. The network achieves 28 % fewer false positives. The improvement is observed mainly in the detection of small-amplitude signals associated with low-mass planets. In addition, its execution time is five orders of magnitude faster than the traditional method. The superior performance exhibited by the algorithm has only been tested on simulated radial velocity data so far. Although in principle it should be straightforward to adapt it for use in real time series, its performance has to be tested thoroughly. Future work should permit evaluating its potential for adoption as a valuable tool for exoplanet detection.
NeRFMeshing: Distilling Neural Radiance Fields into Geometrically-Accurate 3D Meshes
Mar 16, 2023
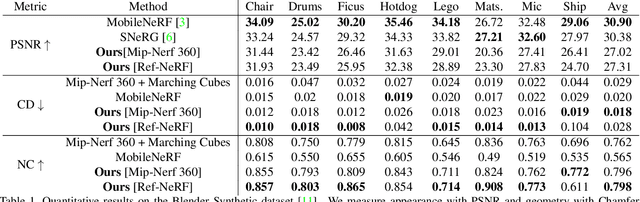


With the introduction of Neural Radiance Fields (NeRFs), novel view synthesis has recently made a big leap forward. At the core, NeRF proposes that each 3D point can emit radiance, allowing to conduct view synthesis using differentiable volumetric rendering. While neural radiance fields can accurately represent 3D scenes for computing the image rendering, 3D meshes are still the main scene representation supported by most computer graphics and simulation pipelines, enabling tasks such as real time rendering and physics-based simulations. Obtaining 3D meshes from neural radiance fields still remains an open challenge since NeRFs are optimized for view synthesis, not enforcing an accurate underlying geometry on the radiance field. We thus propose a novel compact and flexible architecture that enables easy 3D surface reconstruction from any NeRF-driven approach. Upon having trained the radiance field, we distill the volumetric 3D representation into a Signed Surface Approximation Network, allowing easy extraction of the 3D mesh and appearance. Our final 3D mesh is physically accurate and can be rendered in real time on an array of devices.
Complex-Valued Time-Frequency Self-Attention for Speech Dereverberation
Nov 22, 2022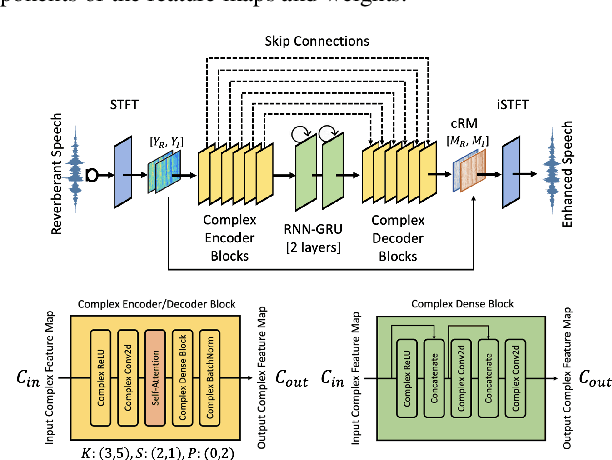
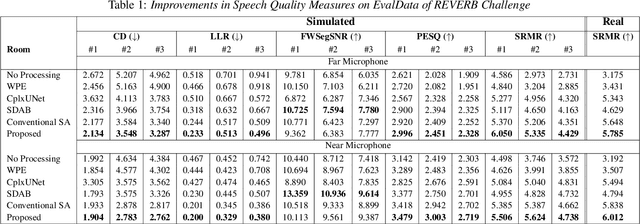
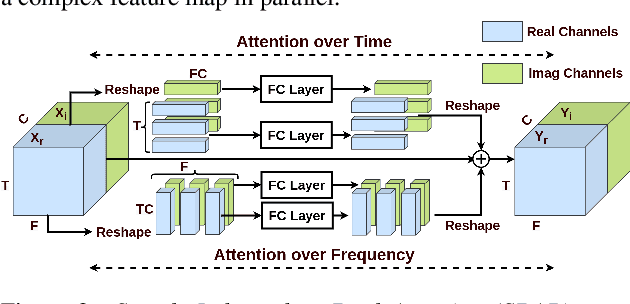
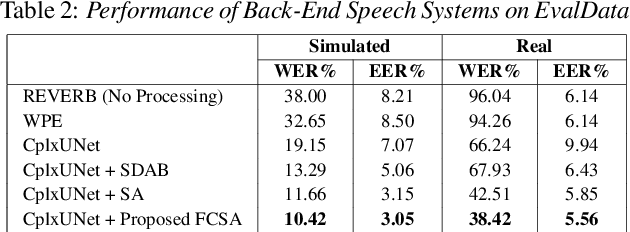
Several speech processing systems have demonstrated considerable performance improvements when deep complex neural networks (DCNN) are coupled with self-attention (SA) networks. However, the majority of DCNN-based studies on speech dereverberation that employ self-attention do not explicitly account for the inter-dependencies between real and imaginary features when computing attention. In this study, we propose a complex-valued T-F attention (TFA) module that models spectral and temporal dependencies by computing two-dimensional attention maps across time and frequency dimensions. We validate the effectiveness of our proposed complex-valued TFA module with the deep complex convolutional recurrent network (DCCRN) using the REVERB challenge corpus. Experimental findings indicate that integrating our complex-TFA module with DCCRN improves overall speech quality and performance of back-end speech applications, such as automatic speech recognition, compared to earlier approaches for self-attention.