 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DFSNet: A Steerable Neural Beamformer Invariant to Microphone Array Configuration for Real-Time, Low-Latency Speech Enhancement
Feb 26, 2023
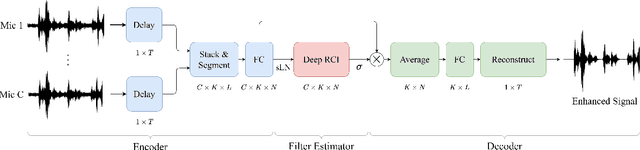
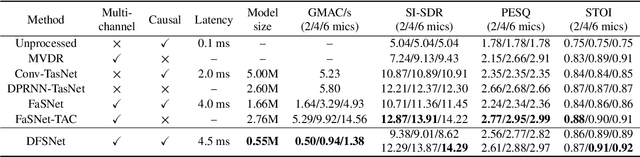
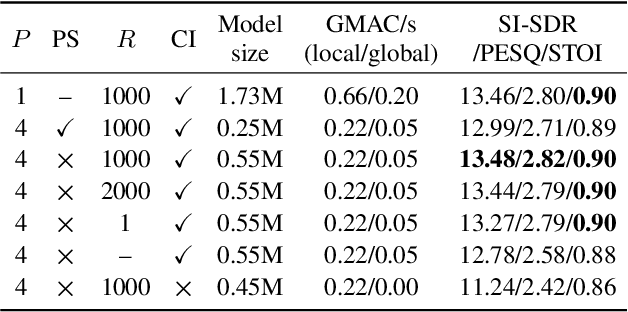
Invariance to microphone array configuration is a rare attribute in neural beamformers. Filter-and-sum (FS) methods in this class define the target signal with respect to a reference channel. However, this not only complicates formulation in reverberant conditions but also the network, which must have a mechanism to infer what the reference channel is. To address these issues, this study presents Delay Filter-and-Sum Network (DFSNet), a steerable neural beamformer invariant to microphone number and array geometry for causal speech enhancement. In DFSNet, acquired signals are first steered toward the speech source direction prior to the FS operation, which simplifies the task into the estimation of delay-and-summed reverberant clean speech. The proposed model is designed to incur low latency, distortion, and memory and computational burden, giving rise to high potential in hearing aid applications. Simulation results reveal comparable performance to noncausal state-of-the-art.
Scavenger: A Cloud Service for Optimizing Cost and Performance of ML Training
Mar 12, 2023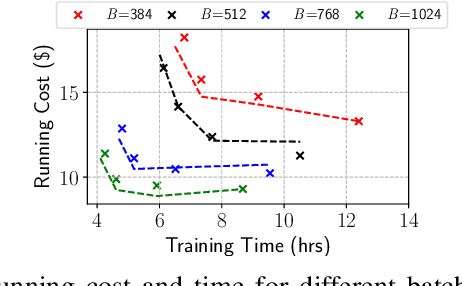
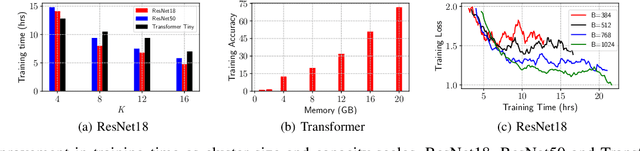
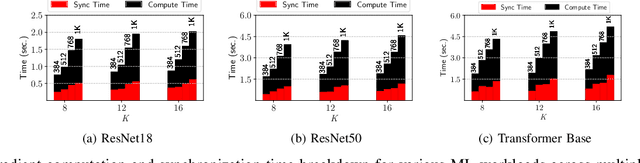
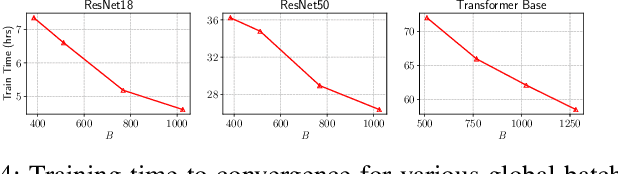
While the pay-as-you-go nature of cloud virtual machines (VMs) makes it easy to spin-up large clusters for training ML models, it can also lead to ballooning costs. The 100s of virtual machine sizes provided by cloud platforms also makes it extremely challenging to select the ``right'' cloud cluster configuration for training. Furthermore, the training time and cost of distributed model training is highly sensitive to the cluster configurations, and presents a large and complex tradeoff-space. In this paper, we develop principled and practical techniques for optimizing the training time and cost of distributed ML model training on the cloud. Our key insight is that both parallel and statistical efficiency must be considered when selecting the optimum job configuration parameters such as the number of workers and the batch size. By combining conventional parallel scaling concepts and new insights into SGD noise, our models accurately estimate the time and cost on different cluster configurations with < 5% error. Using the repetitive nature of training and our models, we can search for optimum cloud configurations in a black-box, online manner. Our approach reduces training times by 2 times and costs more more than 50%. Compared to an oracle-based approach, our performance models are accurate to within 2% such that the search imposes an overhead of just 10%.
Real-time Local Feature with Global Visual Information Enhancement
Nov 20, 2022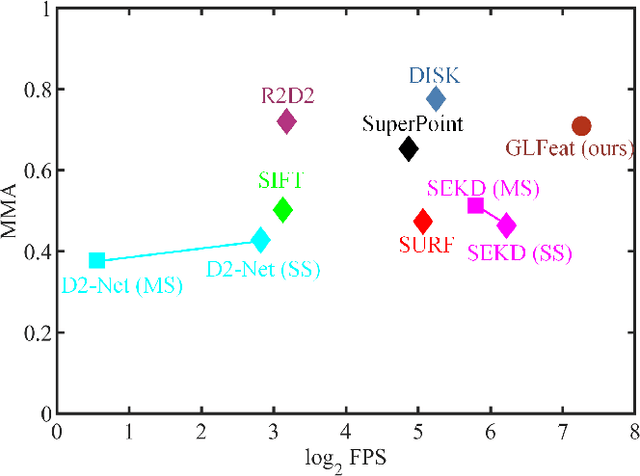
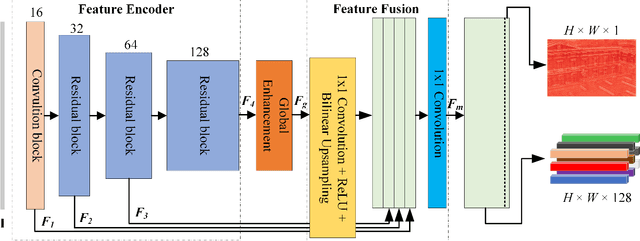

Local feature provides compact and invariant image representation for various visual tasks. Current deep learning-based local feature algorithms always utilize convolution neural network (CNN) architecture with limited receptive field. Besides, even with high-performance GPU devices, the computational efficiency of local features cannot be satisfactory. In this paper, we tackle such problems by proposing a CNN-based local feature algorithm. The proposed method introduces a global enhancement module to fuse global visual clues in a light-weight network, and then optimizes the network by novel deep reinforcement learning scheme from the perspective of local feature matching task. Experiments on the public benchmarks demonstrate that the proposal can achieve considerable robustness against visual interference and meanwhile run in real time.
Timestamps as Prompts for Geography-Aware Location Recommendation
Apr 09, 2023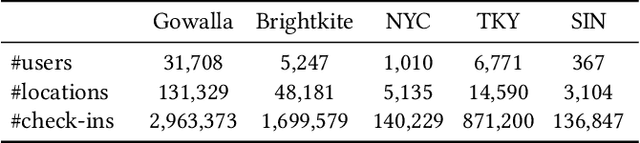
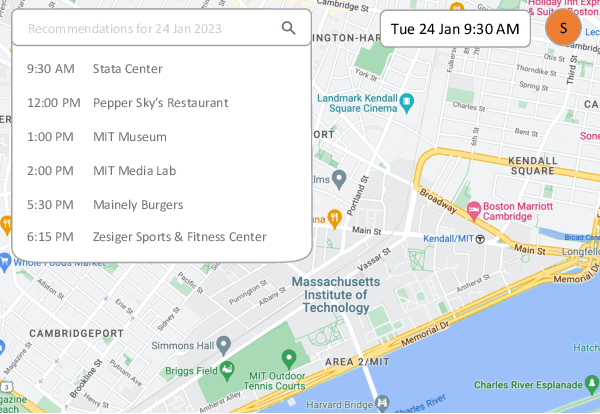
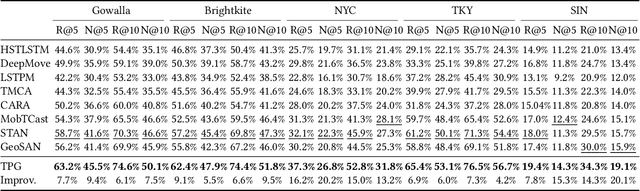
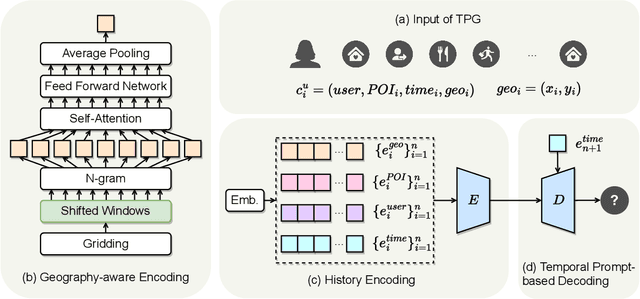
Location recommendation plays a vital role in improving users' travel experience. The timestamp of the POI to be predicted is of great significance, since a user will go to different places at different times. However, most existing methods either do not use this kind of temporal information, or just implicitly fuse it with other contextual information. In this paper, we revisit the problem of location recommendation and point out that explicitly modeling temporal information is a great help when the model needs to predict not only the next location but also further locations. In addition, state-of-the-art methods do not make effective use of geographic information and suffer from the hard boundary problem when encoding geographic information by gridding. To this end, a Temporal Prompt-based and Geography-aware (TPG) framework is proposed. The temporal prompt is firstly designed to incorporate temporal information of any further check-in. A shifted window mechanism is then devised to augment geographic data for addressing the hard boundary problem. Via extensive comparisons with existing methods and ablation studies on five real-world datasets, we demonstrate the effectiveness and superiority of the proposed method under various settings. Most importantly, our proposed model has the superior ability of interval prediction. In particular, the model can predict the location that a user wants to go to at a certain time while the most recent check-in behavioral data is masked, or it can predict specific future check-in (not just the next one) at a given timestamp.
Descriptor Distillation for Efficient Multi-Robot SLAM
Mar 15, 2023
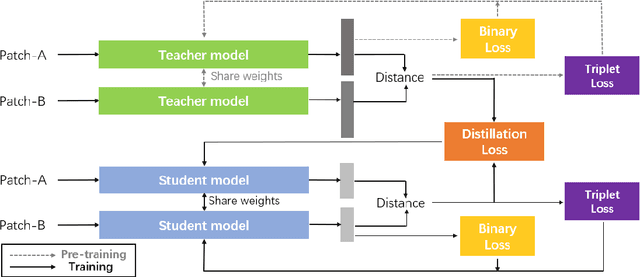
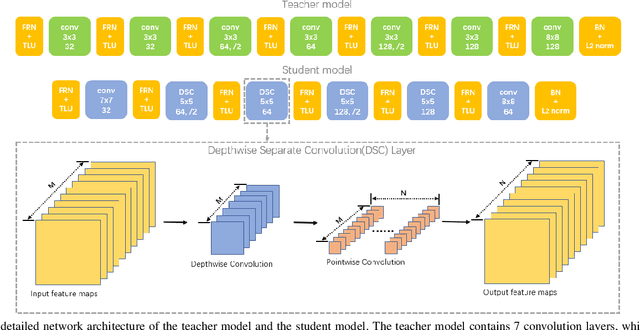
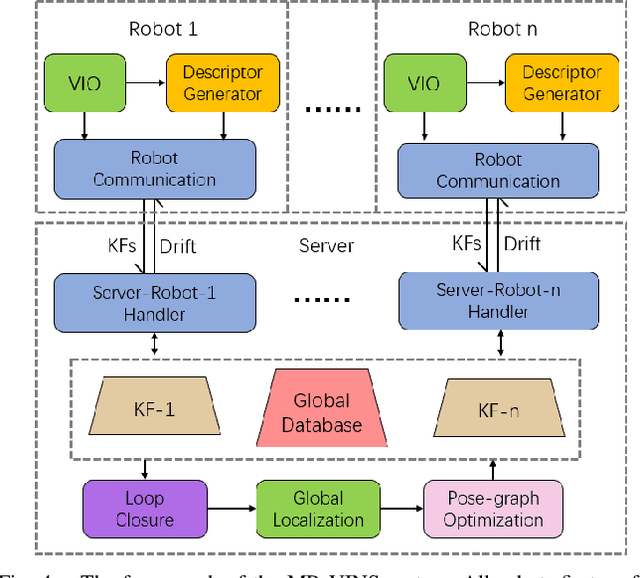
Performing accurate localization while maintaining the low-level communication bandwidth is an essential challenge of multi-robot simultaneous localization and mapping (MR-SLAM). In this paper, we tackle this problem by generating a compact yet discriminative feature descriptor with minimum inference time. We propose descriptor distillation that formulates the descriptor generation into a learning problem under the teacher-student framework. To achieve real-time descriptor generation, we design a compact student network and learn it by transferring the knowledge from a pre-trained large teacher model. To reduce the descriptor dimensions from the teacher to the student, we propose a novel loss function that enables the knowledge transfer between two different dimensional descriptors. The experimental results demonstrate that our model is 30% lighter than the state-of-the-art model and produces better descriptors in patch matching. Moreover, we build a MR-SLAM system based on the proposed method and show that our descriptor distillation can achieve higher localization performance for MR-SLAM with lower bandwidth.
Comparative Evaluation of Data Decoupling Techniques for Federated Machine Learning with Database as a Service
Mar 15, 2023
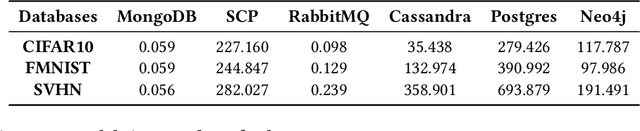
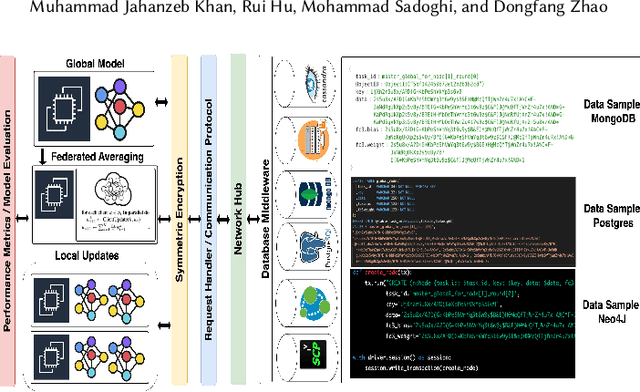

Federated Learning (FL) is a machine learning approach that allows multiple clients to collaboratively learn a shared model without sharing raw data. However, current FL systems provide an all-in-one solution, which can hinder the wide adoption of FL in certain domains such as scientific applications. To overcome this limitation, this paper proposes a decoupling approach that enables clients to customize FL applications with specific data subsystems. To evaluate this approach, the authors develop a framework called Data-Decoupling Federated Learning (DDFL) and compare it with state-of-the-art FL systems that tightly couple data management and computation. Extensive experiments on various datasets and data management subsystems show that DDFL achieves comparable or better performance in terms of training time, inference accuracy, and database query time. Moreover, DDFL provides clients with more options to tune their FL applications regarding data-related metrics. The authors also provide a detailed qualitative analysis of DDFL when integrated with mainstream database systems.
Multi-Sample Consensus Driven Unsupervised Normal Estimation for 3D Point Clouds
Apr 10, 2023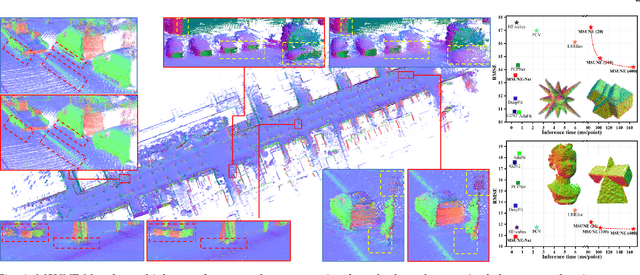
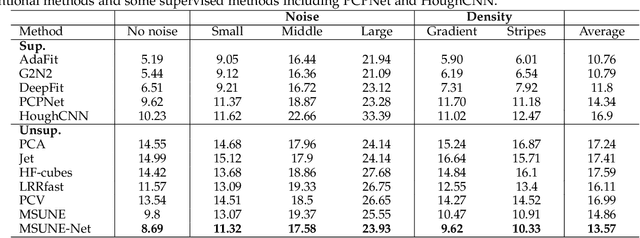
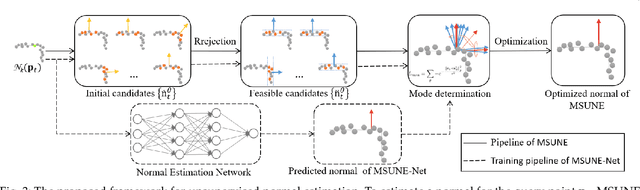
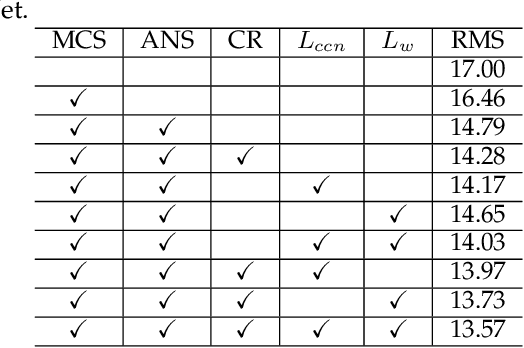
Deep normal estimators have made great strides on synthetic benchmarks. Unfortunately, their performance dramatically drops on the real scan data since they are supervised only on synthetic datasets. The point-wise annotation of ground truth normals is vulnerable to inefficiency and inaccuracies, which totally makes it impossible to build perfect real datasets for supervised deep learning. To overcome the challenge, we propose a multi-sample consensus paradigm for unsupervised normal estimation. The paradigm consists of multi-candidate sampling, candidate rejection, and mode determination. The latter two are driven by neighbor point consensus and candidate consensus respectively. Two primary implementations of the paradigm, MSUNE and MSUNE-Net, are proposed. MSUNE minimizes a candidate consensus loss in mode determination. As a robust optimization method, it outperforms the cutting-edge supervised deep learning methods on real data at the cost of longer runtime for sampling enough candidate normals for each query point. MSUNE-Net, the first unsupervised deep normal estimator as far as we know, significantly promotes the multi-sample consensus further. It transfers the three online stages of MSUNE to offline training. Thereby its inference time is 100 times faster. Besides that, more accurate inference is achieved, since the candidates of query points from similar patches can form a sufficiently large candidate set implicitly in MSUNE-Net. Comprehensive experiments demonstrate that the two proposed unsupervised methods are noticeably superior to some supervised deep normal estimators on the most common synthetic dataset. More importantly, they show better generalization ability and outperform all the SOTA conventional and deep methods on three real datasets: NYUV2, KITTI, and a dataset from PCV [1].
Detecting Anomalous Microflows in IoT Volumetric Attacks via Dynamic Monitoring of MUD Activity
Apr 11, 2023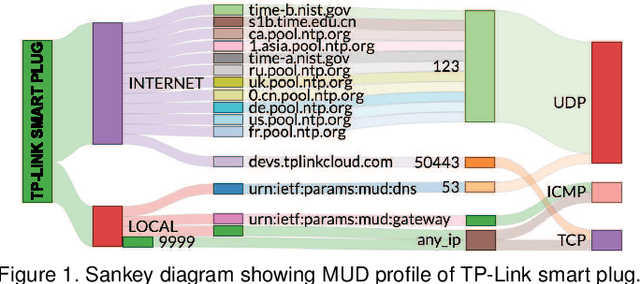
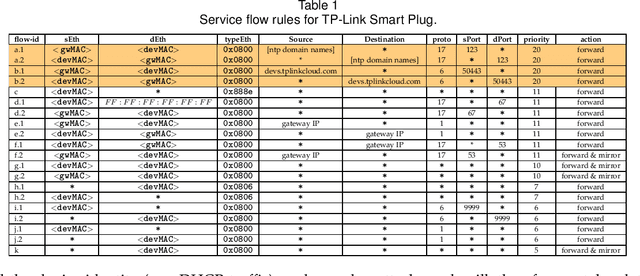
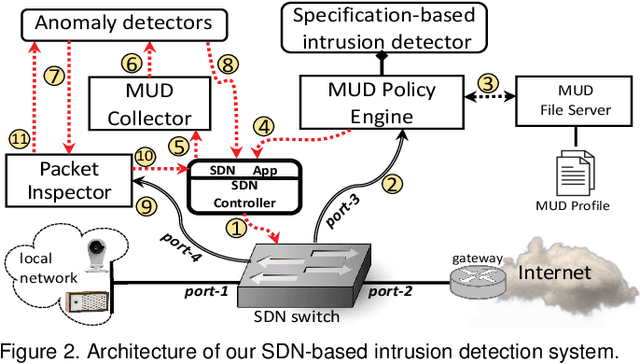
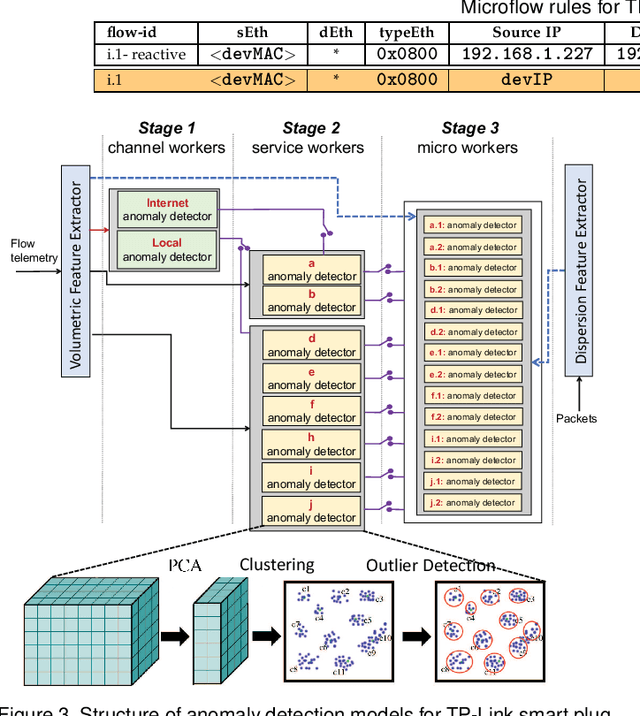
IoT networks are increasingly becoming target of sophisticated new cyber-attacks. Anomaly-based detection methods are promising in finding new attacks, but there are certain practical challenges like false-positive alarms, hard to explain, and difficult to scale cost-effectively. The IETF recent standard called Manufacturer Usage Description (MUD) seems promising to limit the attack surface on IoT devices by formally specifying their intended network behavior. In this paper, we use SDN to enforce and monitor the expected behaviors of each IoT device, and train one-class classifier models to detect volumetric attacks. Our specific contributions are fourfold. (1) We develop a multi-level inferencing model to dynamically detect anomalous patterns in network activity of MUD-compliant traffic flows via SDN telemetry, followed by packet inspection of anomalous flows. This provides enhanced fine-grained visibility into distributed and direct attacks, allowing us to precisely isolate volumetric attacks with microflow (5-tuple) resolution. (2) We collect traffic traces (benign and a variety of volumetric attacks) from network behavior of IoT devices in our lab, generate labeled datasets, and make them available to the public. (3) We prototype a full working system (modules are released as open-source), demonstrates its efficacy in detecting volumetric attacks on several consumer IoT devices with high accuracy while maintaining low false positives, and provides insights into cost and performance of our system. (4) We demonstrate how our models scale in environments with a large number of connected IoTs (with datasets collected from a network of IP cameras in our university campus) by considering various training strategies (per device unit versus per device type), and balancing the accuracy of prediction against the cost of models in terms of size and training time.
Robust Multiview Point Cloud Registration with Reliable Pose Graph Initialization and History Reweighting
Apr 02, 2023

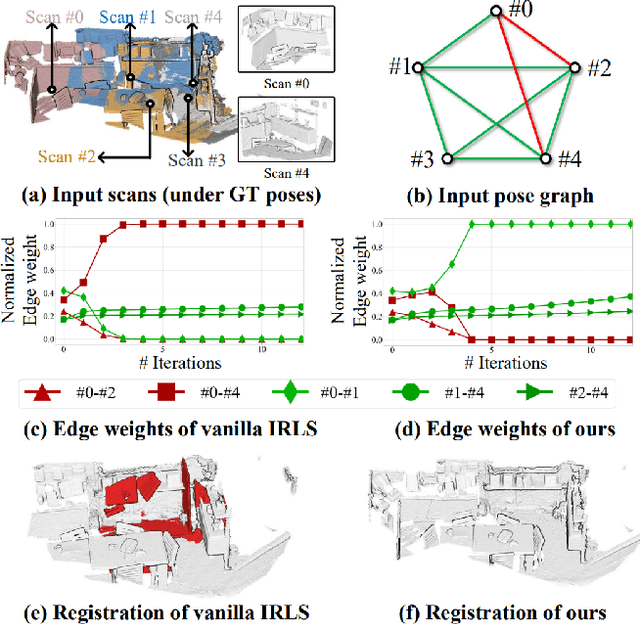
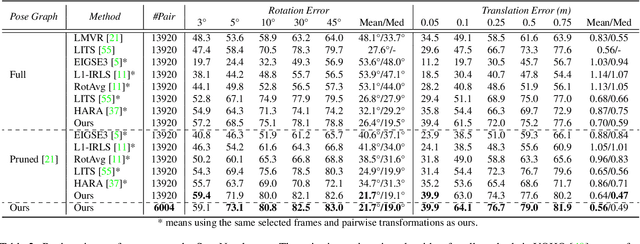
In this paper, we present a new method for the multiview registration of point cloud. Previous multiview registration methods rely on exhaustive pairwise registration to construct a densely-connected pose graph and apply Iteratively Reweighted Least Square (IRLS) on the pose graph to compute the scan poses. However, constructing a densely-connected graph is time-consuming and contains lots of outlier edges, which makes the subsequent IRLS struggle to find correct poses. To address the above problems, we first propose to use a neural network to estimate the overlap between scan pairs, which enables us to construct a sparse but reliable pose graph. Then, we design a novel history reweighting function in the IRLS scheme, which has strong robustness to outlier edges on the graph. In comparison with existing multiview registration methods, our method achieves 11% higher registration recall on the 3DMatch dataset and ~13% lower registration errors on the ScanNet dataset while reducing ~70% required pairwise registrations. Comprehensive ablation studies are conducted to demonstrate the effectiveness of our designs.
altiro3D: Scene representation from single image and novel view synthesis
Apr 02, 2023


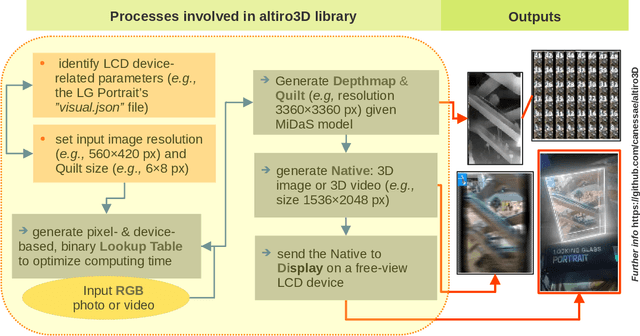
We introduce altiro3D, a free extended library developed to represent reality starting from a given original RGB image or flat video. It allows to generate a light-field (or Native) image or video and get a realistic 3D experience. To synthesize N-number of virtual images and add them sequentially into a Quilt collage, we apply MiDaS models for the monocular depth estimation, simple OpenCV and Telea inpainting techniques to map all pixels, and implement a 'Fast' algorithm to handle 3D projection camera and scene transformations along N-viewpoints. We use the degree of depth to move proportionally the pixels, assuming the original image to be at the center of all the viewpoints. altiro3D can also be used with DIBR algorithm to compute intermediate snapshots from a equivalent 'Real (slower)' camera with N-geometric viewpoints, which requires to calibrate a priori several intrinsic and extrinsic camera parameters. We adopt a pixel- and device-based Lookup Table to optimize computing time. The multiple viewpoints and video generated from a single image or frame can be displayed in a free-view LCD display.