 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Panoptic Mapping with Fruit Completion and Pose Estimation for Horticultural Robots
Mar 15, 2023
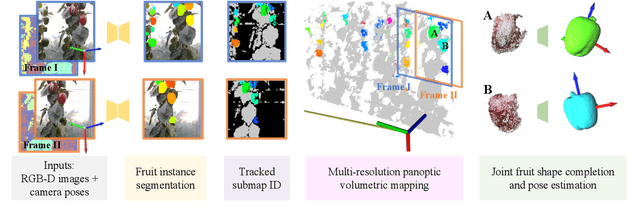

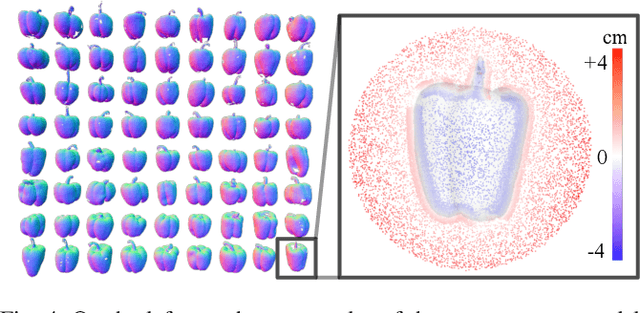
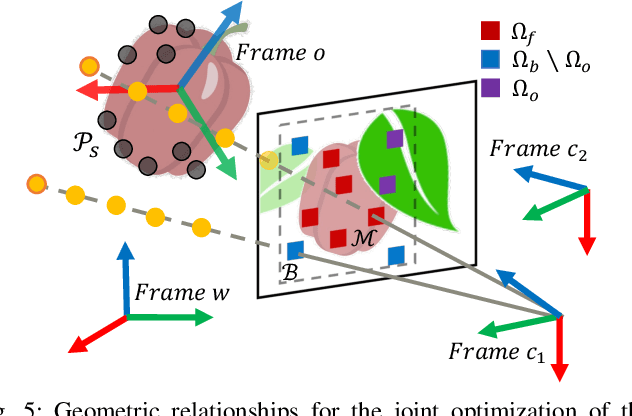
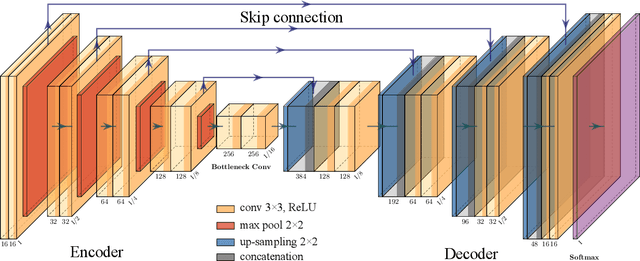
Monitoring plants and fruits at high resolution play a key role in the future of agriculture. Accurate 3D information can pave the way to a diverse number of robotic applications in agriculture ranging from autonomous harvesting to precise yield estimation. Obtaining such 3D information is non-trivial as agricultural environments are often repetitive and cluttered, and one has to account for the partial observability of fruit and plants. In this paper, we address the problem of jointly estimating complete 3D shapes of fruit and their pose in a 3D multi-resolution map built by a mobile robot. To this end, we propose an online multi-resolution panoptic mapping system where regions of interest are represented with a higher resolution. We exploit data to learn a general fruit shape representation that we use at inference time together with an occlusion-aware differentiable rendering pipeline to complete partial fruit observations and estimate the 7 DoF pose of each fruit in the map. The experiments presented in this paper, evaluated both in the controlled environment and in a commercial greenhouse, show that our novel algorithm yields higher completion and pose estimation accuracy than existing methods, with an improvement of 41% in completion accuracy and 52% in pose estimation accuracy while keeping a low inference time of 0.6s in average.
Building Floorspace in China: A Dataset and Learning Pipeline
Mar 03, 2023
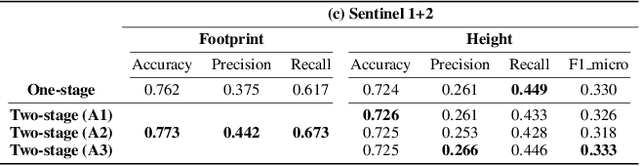
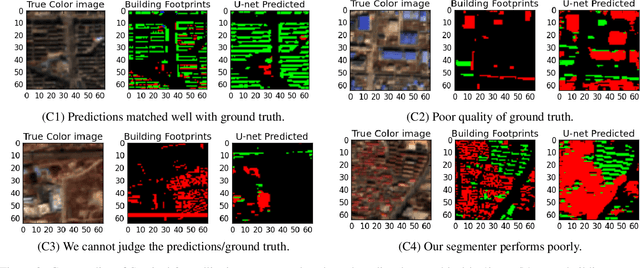
This paper provides the first milestone in measuring the floor space of buildings (that is, building footprint and height) and its evolution over time for China. Doing so requires building on imagery that is of a medium-fine-grained granularity, as longer cross-sections and time series data across many cities are only available in such format. We use a multi-class object segmenter approach to gauge the floor space of buildings in the same framework: first, we determine whether a surface area is covered by buildings (the square footage of occupied land); second, we need to determine the height of buildings from their imagery. We then use Sentinel-1 and -2 satellite images as our main data source. The benefits of these data are their large cross-sectional and longitudinal scope plus their unrestricted accessibility. We provide a detailed description of the algorithms used to generate the data and the results. We analyze the preprocessing steps of reference data (if not ground truth data) and their consequences for measuring the building floor space. We also discuss the future steps in building a time series on urban development based on our preliminary experimental results.
Study on the Data Storage Technology of Mini-Airborne Radar Based on Machine Learning
Mar 03, 2023

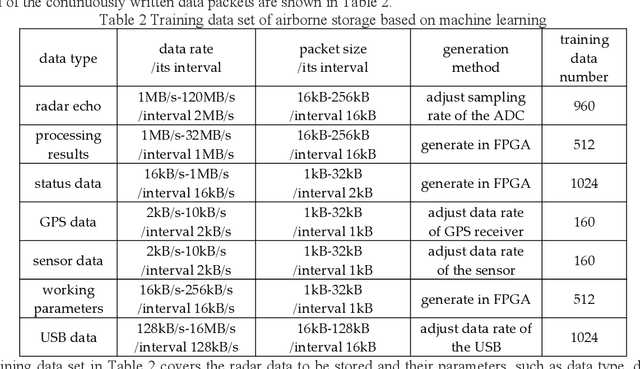

The data rate of airborne radar is much higher than the wireless data transfer rate in many detection applications, so the onboard data storage systems are usually used to store the radar data. Data storage systems with good seismic performance usually use NAND Flash as storage medium, and there is a widespread problem of long file management time, which seriously affects the data storage speed, especially under the limitation of platform miniaturization. To solve this problem, a data storage method based on machine learning is proposed for mini-airborne radar. The storage training model is established based on machine learning, and could process various kinds of radar data. The file management methods are classified and determined using the model, and then are applied to the storage of radar data. To verify the performance of the proposed method, a test was carried out on the data storage system of a mini-airborne radar. The experimental results show that the method based on machine learning can form various data storage methods adapted to different data rates and application scenarios. The ratio of the file management time to the actual data writing time is extremely low.
Large-scale End-of-Life Prediction of Hard Disks in Distributed Datacenters
Mar 20, 2023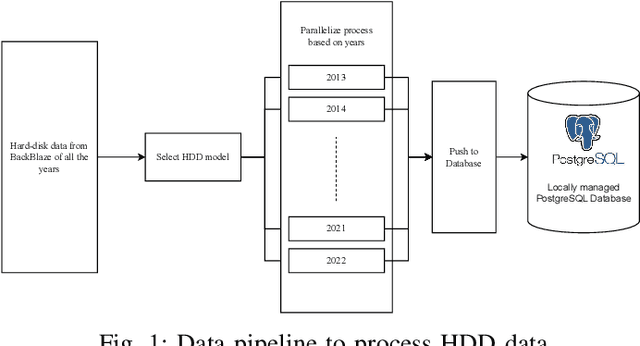
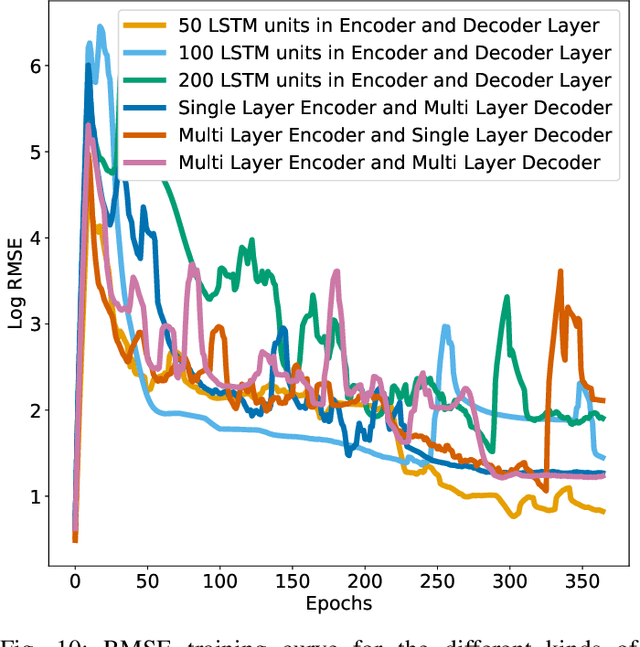
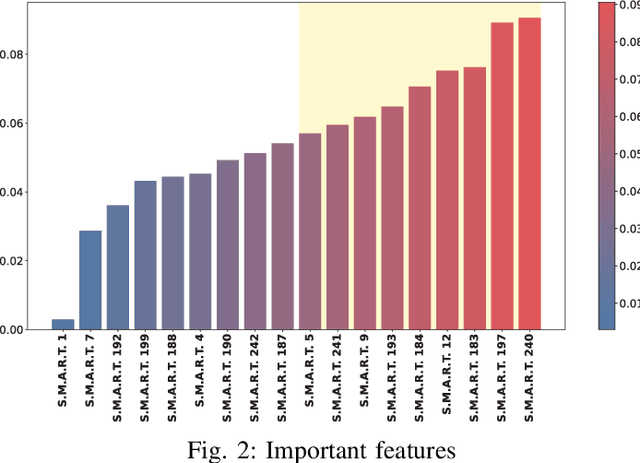
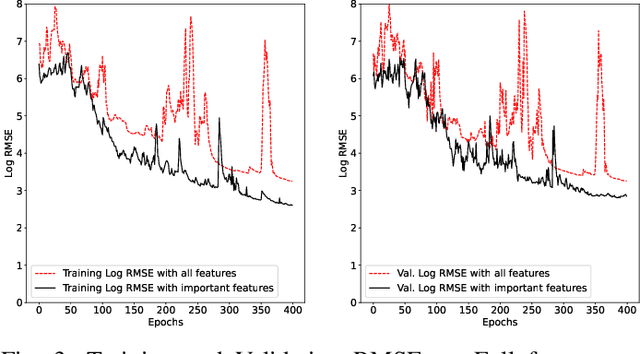
On a daily basis, data centers process huge volumes of data backed by the proliferation of inexpensive hard disks. Data stored in these disks serve a range of critical functional needs from financial, and healthcare to aerospace. As such, premature disk failure and consequent loss of data can be catastrophic. To mitigate the risk of failures, cloud storage providers perform condition-based monitoring and replace hard disks before they fail. By estimating the remaining useful life of hard disk drives, one can predict the time-to-failure of a particular device and replace it at the right time, ensuring maximum utilization whilst reducing operational costs. In this work, large-scale predictive analyses are performed using severely skewed health statistics data by incorporating customized feature engineering and a suite of sequence learners. Past work suggests using LSTMs as an excellent approach to predicting remaining useful life. To this end, we present an encoder-decoder LSTM model where the context gained from understanding health statistics sequences aid in predicting an output sequence of the number of days remaining before a disk potentially fails. The models developed in this work are trained and tested across an exhaustive set of all of the 10 years of S.M.A.R.T. health data in circulation from Backblaze and on a wide variety of disk instances. It closes the knowledge gap on what full-scale training achieves on thousands of devices and advances the state-of-the-art by providing tangible metrics for evaluation and generalization for practitioners looking to extend their workflow to all years of health data in circulation across disk manufacturers. The encoder-decoder LSTM posted an RMSE of 0.83 during training and 0.86 during testing over the exhaustive 10 year data while being able to generalize competitively over other drives from the Seagate family.
CH-Go: Online Go System Based on Chunk Data Storage
Mar 22, 2023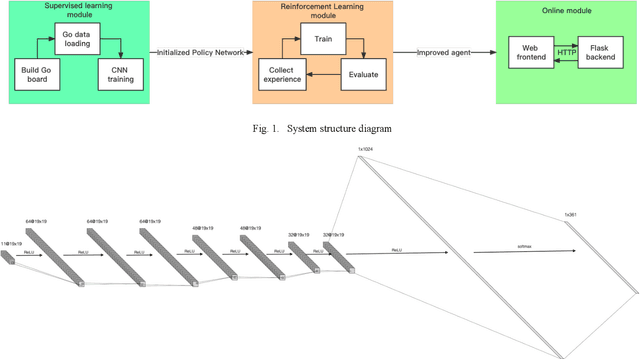

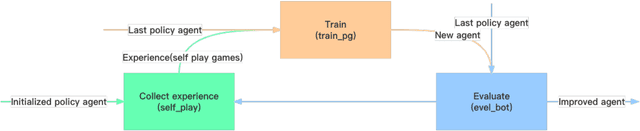
The training and running of an online Go system require the support of effective data management systems to deal with vast data, such as the initial Go game records, the feature data set obtained by representation learning, the experience data set of self-play, the randomly sampled Monte Carlo tree, and so on. Previous work has rarely mentioned this problem, but the ability and efficiency of data management systems determine the accuracy and speed of the Go system. To tackle this issue, we propose an online Go game system based on the chunk data storage method (CH-Go), which processes the format of 160k Go game data released by Kiseido Go Server (KGS) and designs a Go encoder with 11 planes, a parallel processor and generator for better memory performance. Specifically, we store the data in chunks, take the chunk size of 1024 as a batch, and save the features and labels of each chunk as binary files. Then a small set of data is randomly sampled each time for the neural network training, which is accessed by batch through yield method. The training part of the prototype includes three modules: supervised learning module, reinforcement learning module, and an online module. Firstly, we apply Zobrist-guided hash coding to speed up the Go board construction. Then we train a supervised learning policy network to initialize the self-play for generation of experience data with 160k Go game data released by KGS. Finally, we conduct reinforcement learning based on REINFORCE algorithm. Experiments show that the training accuracy of CH- Go in the sampled 150 games is 99.14%, and the accuracy in the test set is as high as 98.82%. Under the condition of limited local computing power and time, we have achieved a better level of intelligence. Given the current situation that classical systems such as GOLAXY are not free and open, CH-Go has realized and maintained complete Internet openness.
Instant Domain Augmentation for LiDAR Semantic Segmentation
Mar 25, 2023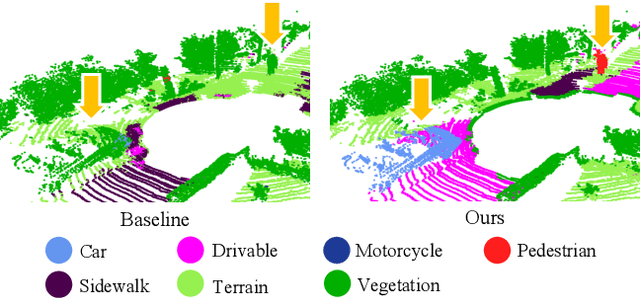
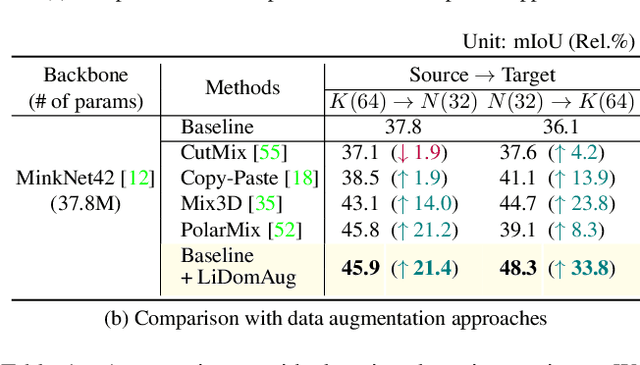
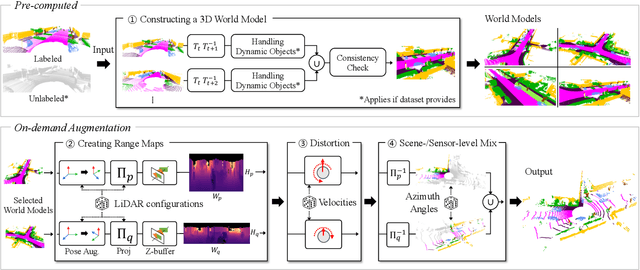

Despite the increasing popularity of LiDAR sensors, perception algorithms using 3D LiDAR data struggle with the 'sensor-bias problem'. Specifically, the performance of perception algorithms significantly drops when an unseen specification of LiDAR sensor is applied at test time due to the domain discrepancy. This paper presents a fast and flexible LiDAR augmentation method for the semantic segmentation task, called 'LiDomAug'. It aggregates raw LiDAR scans and creates a LiDAR scan of any configurations with the consideration of dynamic distortion and occlusion, resulting in instant domain augmentation. Our on-demand augmentation module runs at 330 FPS, so it can be seamlessly integrated into the data loader in the learning framework. In our experiments, learning-based approaches aided with the proposed LiDomAug are less affected by the sensor-bias issue and achieve new state-of-the-art domain adaptation performances on SemanticKITTI and nuScenes dataset without the use of the target domain data. We also present a sensor-agnostic model that faithfully works on the various LiDAR configurations.
Task-Attentive Transformer Architecture for Continual Learning of Vision-and-Language Tasks Using Knowledge Distillation
Mar 25, 2023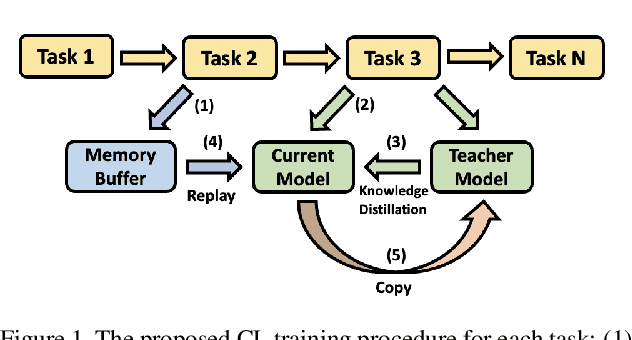
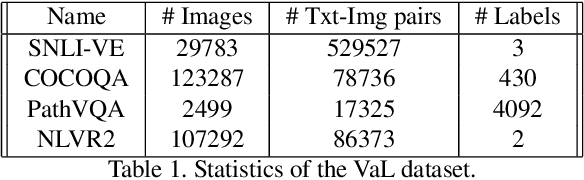
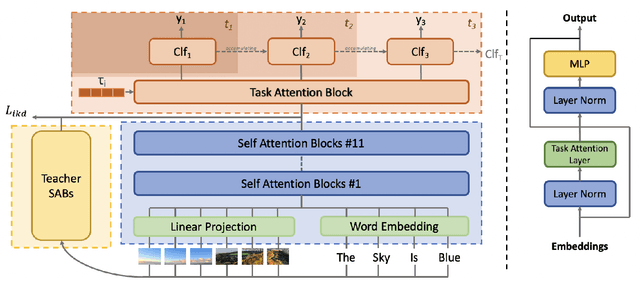
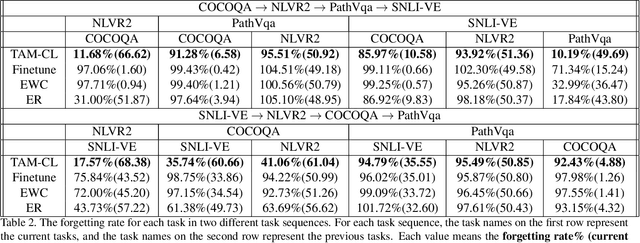
The size and the computational load of fine-tuning large-scale pre-trained neural network are becoming two major obstacles in adopting machine learning in many applications. Continual learning (CL) can serve as a remedy through enabling knowledge-transfer across sequentially arriving tasks which relaxes the need to fine-tune all network weights from scratch. However, existing CL algorithms primarily consider learning unimodal vision-only or language-only tasks. We develop a transformer-based CL architecture for learning bimodal vision-and-language tasks based on increasing the number of the learnable parameters dynamically and using knowledge distillation. The new additional parameters are used to specialize the network for each task. Our approach enables sharing information between the tasks while addressing the challenge of catastrophic forgetting. Our approach is scalable learning to a large number of tasks because it requires little memory and time overhead. Our model reaches state-of-the-art performance on challenging vision-and-language tasks.
Actor-Critic or Critic-Actor? A Tale of Two Time Scales
Oct 10, 2022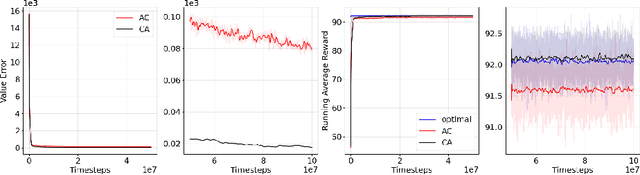
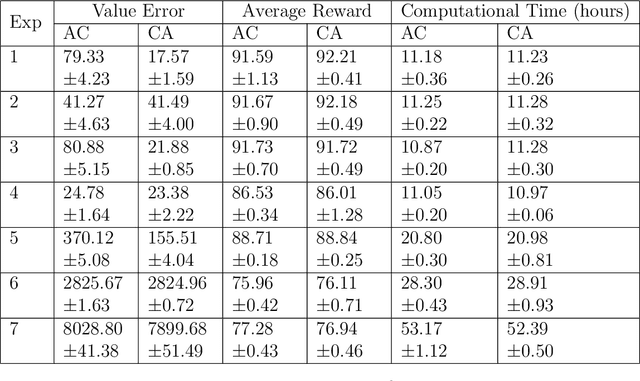
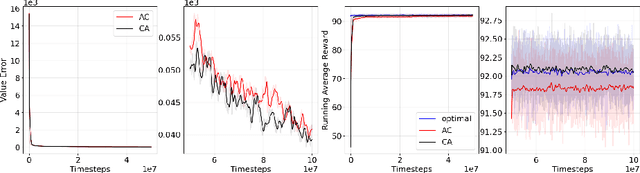
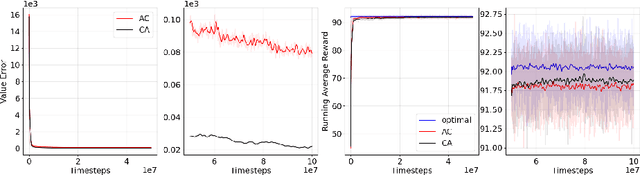
We revisit the standard formulation of tabular actor-critic algorithm as a two time-scale stochastic approximation with value function computed on a faster time-scale and policy computed on a slower time-scale. This emulates policy iteration. We begin by observing that reversal of the time scales will in fact emulate value iteration and is a legitimate algorithm. We compare the two empirically with and without function approximation (with both linear and nonlinear function approximators) and observe that our proposed critic-actor algorithm performs better empirically though with a marginal increase in the computational cost.
Object Permanence in Object Detection Leveraging Temporal Priors at Inference Time
Nov 28, 2022
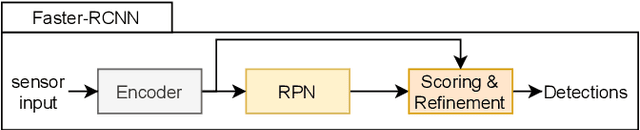
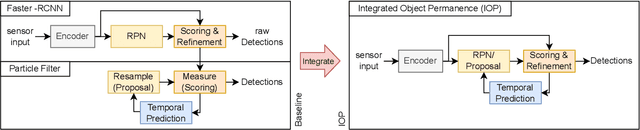
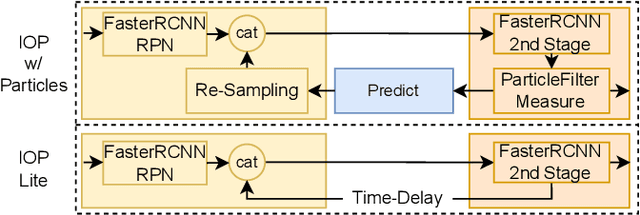
Object permanence is the concept that objects do not suddenly disappear in the physical world. Humans understand this concept at young ages and know that another person is still there, even though it is temporarily occluded. Neural networks currently often struggle with this challenge. Thus, we introduce explicit object permanence into two stage detection approaches drawing inspiration from particle filters. At the core, our detector uses the predictions of previous frames as additional proposals for the current one at inference time. Experiments confirm the feedback loop improving detection performance by a up to 10.3 mAP with little computational overhead. Our approach is suited to extend two-stage detectors for stabilized and reliable detections even under heavy occlusion. Additionally, the ability to apply our method without retraining an existing model promises wide application in real-world tasks.
Simulating Malaria Detection in Laboratories using Deep Learning
Mar 21, 2023
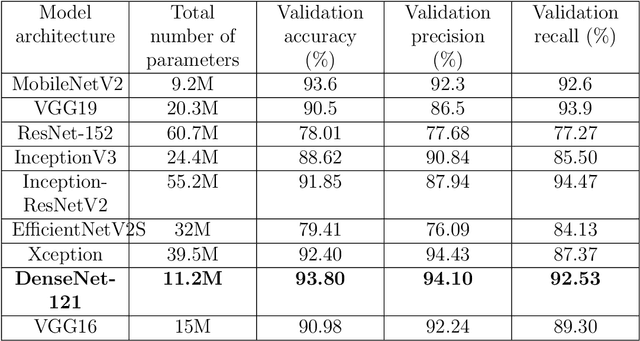
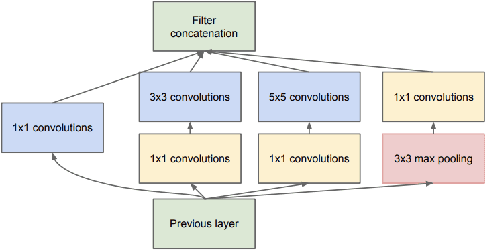
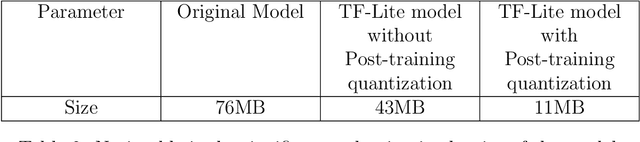
Malaria is usually diagnosed by a microbiologist by examining a small sample of blood smear. Reducing mortality from malaria infection is possible if it is diagnosed early and followed with appropriate treatment. While the WHO has set audacious goals of reducing malaria incidence and mortality rates by 90% in 2030 and eliminating malaria in 35 countries by that time, it still remains a difficult challenge. Computer-assisted diagnostics are on the rise these days as they can be used effectively as a primary test in the absence of or providing assistance to a physician or pathologist. The purpose of this paper is to describe an approach to detecting, localizing and counting parasitic cells in blood sample images towards easing the burden on healthcare workers.