 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantic Prompting with Image-Token for Continual Learning
Mar 18, 2024
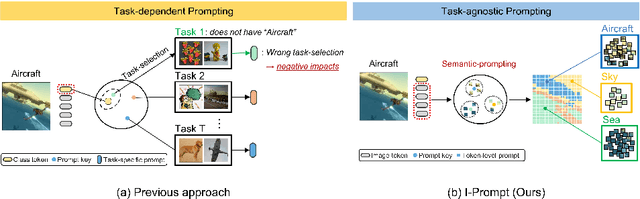
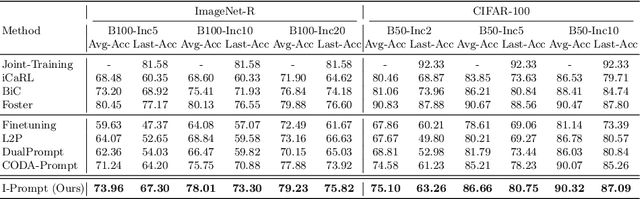
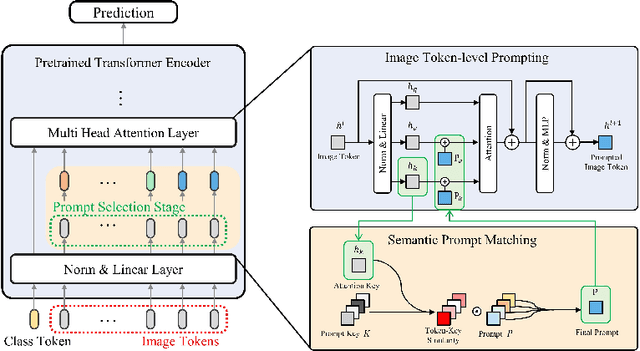
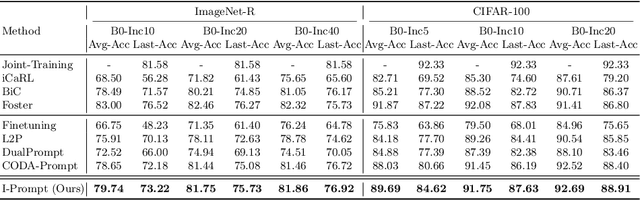
Continual learning aims to refine model parameters for new tasks while retaining knowledge from previous tasks. Recently, prompt-based learning has emerged to leverage pre-trained models to be prompted to learn subsequent tasks without the reliance on the rehearsal buffer. Although this approach has demonstrated outstanding results, existing methods depend on preceding task-selection process to choose appropriate prompts. However, imperfectness in task-selection may lead to negative impacts on the performance particularly in the scenarios where the number of tasks is large or task distributions are imbalanced. To address this issue, we introduce I-Prompt, a task-agnostic approach focuses on the visual semantic information of image tokens to eliminate task prediction. Our method consists of semantic prompt matching, which determines prompts based on similarities between tokens, and image token-level prompting, which applies prompts directly to image tokens in the intermediate layers. Consequently, our method achieves competitive performance on four benchmarks while significantly reducing training time compared to state-of-the-art methods. Moreover, we demonstrate the superiority of our method across various scenarios through extensive experiments.
TCNet: Continuous Sign Language Recognition from Trajectories and Correlated Regions
Mar 18, 2024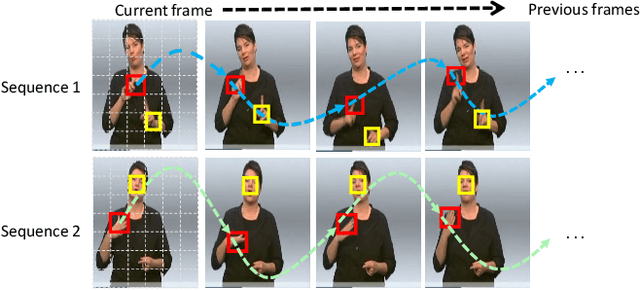
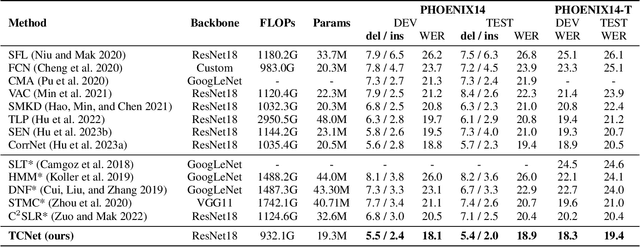
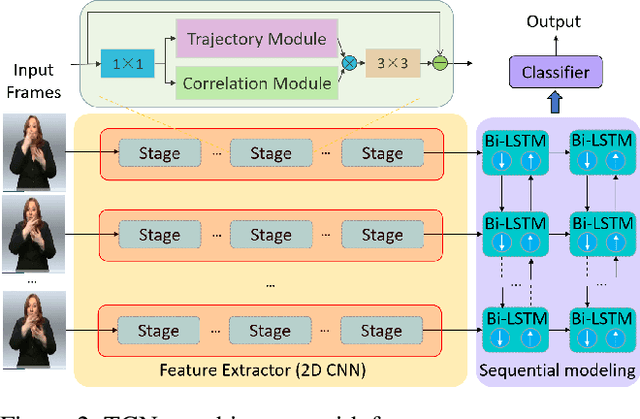
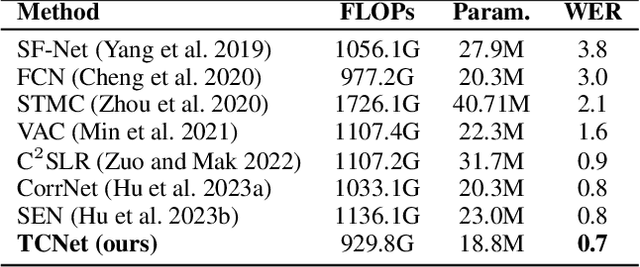
A key challenge in continuous sign language recognition (CSLR) is to efficiently capture long-range spatial interactions over time from the video input. To address this challenge, we propose TCNet, a hybrid network that effectively models spatio-temporal information from Trajectories and Correlated regions. TCNet's trajectory module transforms frames into aligned trajectories composed of continuous visual tokens. In addition, for a query token, self-attention is learned along the trajectory. As such, our network can also focus on fine-grained spatio-temporal patterns, such as finger movements, of a specific region in motion. TCNet's correlation module uses a novel dynamic attention mechanism that filters out irrelevant frame regions. Additionally, it assigns dynamic key-value tokens from correlated regions to each query. Both innovations significantly reduce the computation cost and memory. We perform experiments on four large-scale datasets: PHOENIX14, PHOENIX14-T, CSL, and CSL-Daily, respectively. Our results demonstrate that TCNet consistently achieves state-of-the-art performance. For example, we improve over the previous state-of-the-art by 1.5% and 1.0% word error rate on PHOENIX14 and PHOENIX14-T, respectively.
Yell At Your Robot: Improving On-the-Fly from Language Corrections
Mar 19, 2024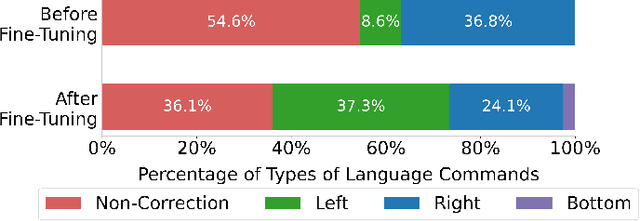



Hierarchical policies that combine language and low-level control have been shown to perform impressively long-horizon robotic tasks, by leveraging either zero-shot high-level planners like pretrained language and vision-language models (LLMs/VLMs) or models trained on annotated robotic demonstrations. However, for complex and dexterous skills, attaining high success rates on long-horizon tasks still represents a major challenge -- the longer the task is, the more likely it is that some stage will fail. Can humans help the robot to continuously improve its long-horizon task performance through intuitive and natural feedback? In this paper, we make the following observation: high-level policies that index into sufficiently rich and expressive low-level language-conditioned skills can be readily supervised with human feedback in the form of language corrections. We show that even fine-grained corrections, such as small movements ("move a bit to the left"), can be effectively incorporated into high-level policies, and that such corrections can be readily obtained from humans observing the robot and making occasional suggestions. This framework enables robots not only to rapidly adapt to real-time language feedback, but also incorporate this feedback into an iterative training scheme that improves the high-level policy's ability to correct errors in both low-level execution and high-level decision-making purely from verbal feedback. Our evaluation on real hardware shows that this leads to significant performance improvement in long-horizon, dexterous manipulation tasks without the need for any additional teleoperation. Videos and code are available at https://yay-robot.github.io/.
A Parallel Workflow for Polar Sea-Ice Classification using Auto-labeling of Sentinel-2 Imagery
Mar 19, 2024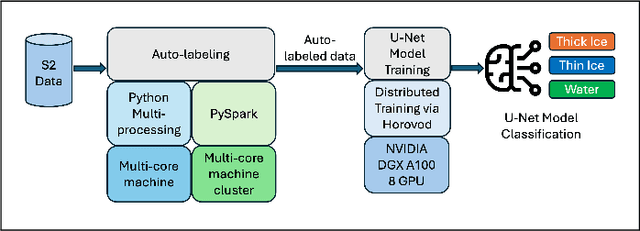
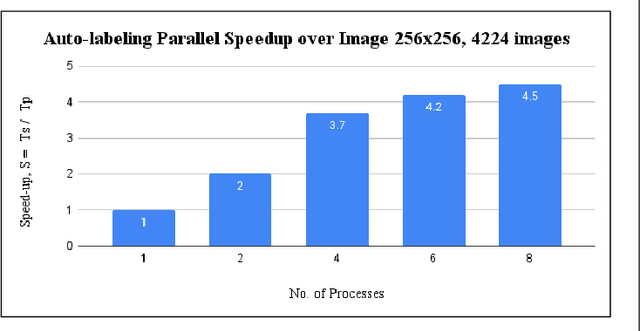
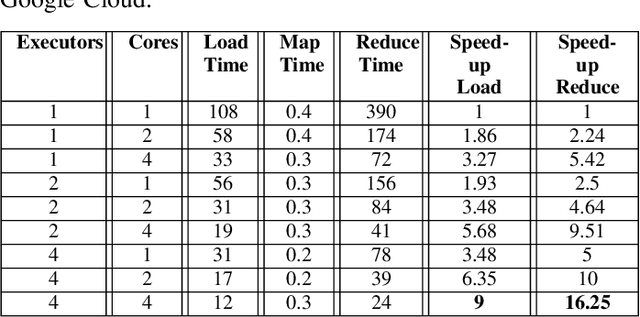
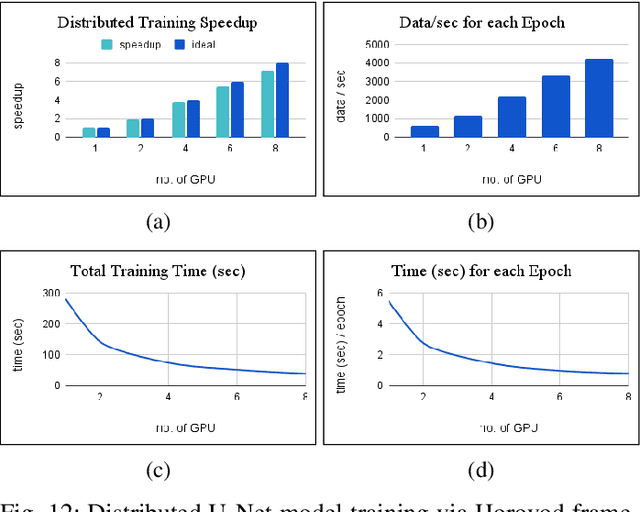
The observation of the advancing and retreating pattern of polar sea ice cover stands as a vital indicator of global warming. This research aims to develop a robust, effective, and scalable system for classifying polar sea ice as thick/snow-covered, young/thin, or open water using Sentinel-2 (S2) images. Since the S2 satellite is actively capturing high-resolution imagery over the earth's surface, there are lots of images that need to be classified. One major obstacle is the absence of labeled S2 training data (images) to act as the ground truth. We demonstrate a scalable and accurate method for segmenting and automatically labeling S2 images using carefully determined color thresholds. We employ a parallel workflow using PySpark to scale and achieve 9-fold data loading and 16-fold map-reduce speedup on auto-labeling S2 images based on thin cloud and shadow-filtered color-based segmentation to generate label data. The auto-labeled data generated from this process are then employed to train a U-Net machine learning model, resulting in good classification accuracy. As training the U-Net classification model is computationally heavy and time-consuming, we distribute the U-Net model training to scale it over 8 GPUs using the Horovod framework over a DGX cluster with a 7.21x speedup without affecting the accuracy of the model. Using the Antarctic's Ross Sea region as an example, the U-Net model trained on auto-labeled data achieves a classification accuracy of 98.97% for auto-labeled training datasets when the thin clouds and shadows from the S2 images are filtered out.
FAGH: Accelerating Federated Learning with Approximated Global Hessian
Mar 16, 2024
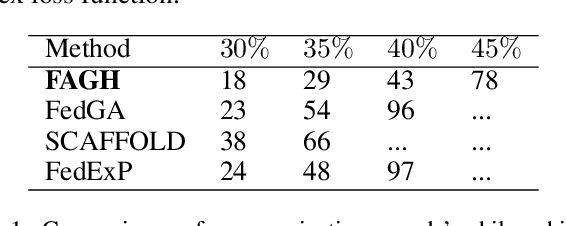
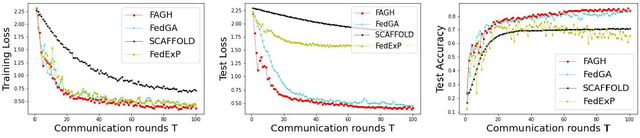

In federated learning (FL), the significant communication overhead due to the slow convergence speed of training the global model poses a great challenge. Specifically, a large number of communication rounds are required to achieve the convergence in FL. One potential solution is to employ the Newton-based optimization method for training, known for its quadratic convergence rate. However, the existing Newton-based FL training methods suffer from either memory inefficiency or high computational costs for local clients or the server. To address this issue, we propose an FL with approximated global Hessian (FAGH) method to accelerate FL training. FAGH leverages the first moment of the approximated global Hessian and the first moment of the global gradient to train the global model. By harnessing the approximated global Hessian curvature, FAGH accelerates the convergence of global model training, leading to the reduced number of communication rounds and thus the shortened training time. Experimental results verify FAGH's effectiveness in decreasing the number of communication rounds and the time required to achieve the pre-specified objectives of the global model performance in terms of training and test losses as well as test accuracy. Notably, FAGH outperforms several state-of-the-art FL training methods.
K-Link: Knowledge-Link Graph from LLMs for Enhanced Representation Learning in Multivariate Time-Series Data
Mar 06, 2024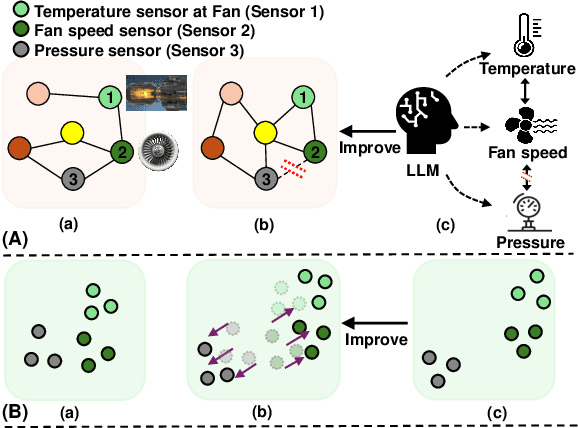
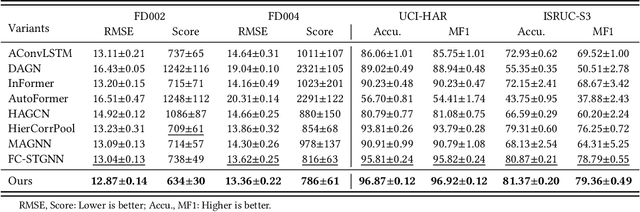
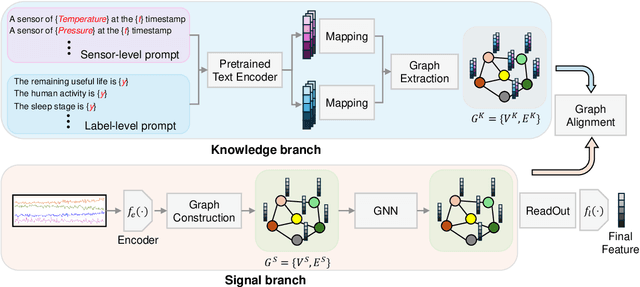
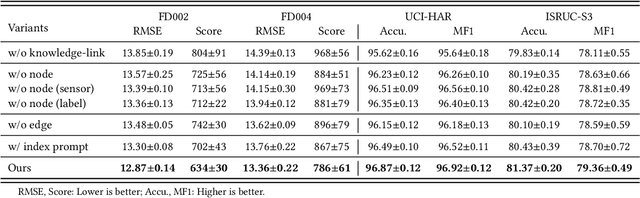
Sourced from various sensors and organized chronologically, Multivariate Time-Series (MTS) data involves crucial spatial-temporal dependencies, e.g., correlations among sensors. To capture these dependencies, Graph Neural Networks (GNNs) have emerged as powerful tools, yet their effectiveness is restricted by the quality of graph construction from MTS data. Typically, existing approaches construct graphs solely from MTS signals, which may introduce bias due to a small training dataset and may not accurately represent underlying dependencies. To address this challenge, we propose a novel framework named K-Link, leveraging Large Language Models (LLMs) to encode extensive general knowledge and thereby providing effective solutions to reduce the bias. Leveraging the knowledge embedded in LLMs, such as physical principles, we extract a \textit{Knowledge-Link graph}, capturing vast semantic knowledge of sensors and the linkage of the sensor-level knowledge. To harness the potential of the knowledge-link graph in enhancing the graph derived from MTS data, we propose a graph alignment module, facilitating the transfer of semantic knowledge within the knowledge-link graph into the MTS-derived graph. By doing so, we can improve the graph quality, ensuring effective representation learning with GNNs for MTS data. Extensive experiments demonstrate the efficacy of our approach for superior performance across various MTS-related downstream tasks.
MKF-ADS: Multi-Knowledge Fusion Based Self-supervised Anomaly Detection System for Control Area Network
Mar 15, 2024
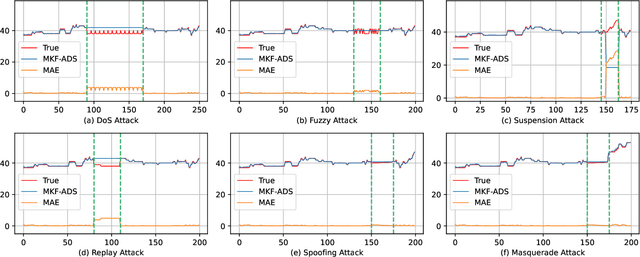
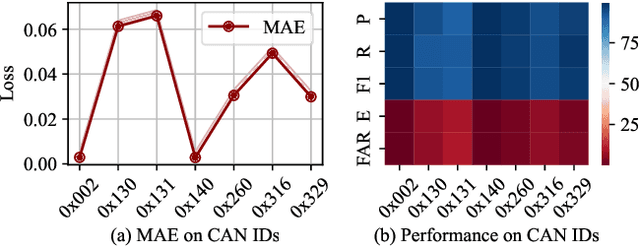
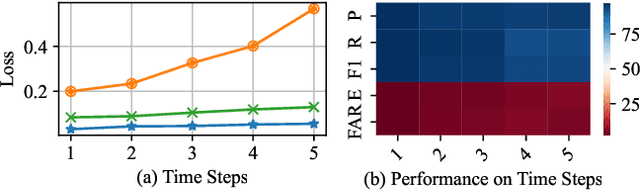
Control Area Network (CAN) is an essential communication protocol that interacts between Electronic Control Units (ECUs) in the vehicular network. However, CAN is facing stringent security challenges due to innate security risks. Intrusion detection systems (IDSs) are a crucial safety component in remediating Vehicular Electronics and Systems vulnerabilities. However, existing IDSs fail to identify complexity attacks and have higher false alarms owing to capability bottleneck. In this paper, we propose a self-supervised multi-knowledge fused anomaly detection model, called MKF-ADS. Specifically, the method designs an integration framework, including spatial-temporal correlation with an attention mechanism (STcAM) module and patch sparse-transformer module (PatchST). The STcAM with fine-pruning uses one-dimensional convolution (Conv1D) to extract spatial features and subsequently utilizes the Bidirectional Long Short Term Memory (Bi-LSTM) to extract the temporal features, where the attention mechanism will focus on the important time steps. Meanwhile, the PatchST captures the combined contextual features from independent univariate time series. Finally, the proposed method is based on knowledge distillation to STcAM as a student model for learning intrinsic knowledge and cross the ability to mimic PatchST. We conduct extensive experiments on six simulation attack scenarios across various CAN IDs and time steps, and two real attack scenarios, which present a competitive prediction and detection performance. Compared with the baseline in the same paradigm, the error rate and FAR are 2.62\% and 2.41\% and achieve a promising F1-score of 97.3\%.
Enhancing LLM Factual Accuracy with RAG to Counter Hallucinations: A Case Study on Domain-Specific Queries in Private Knowledge-Bases
Mar 15, 2024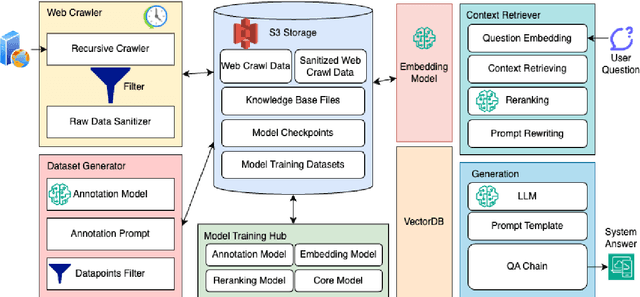
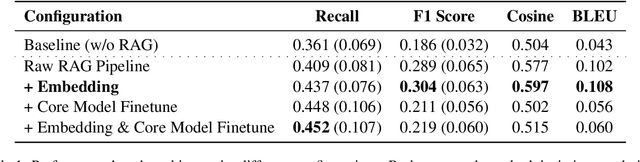
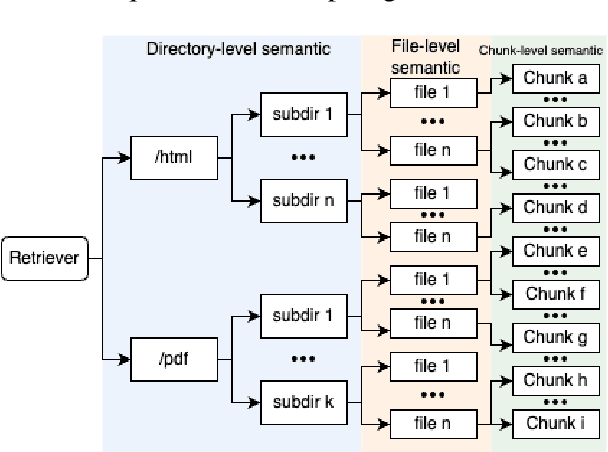
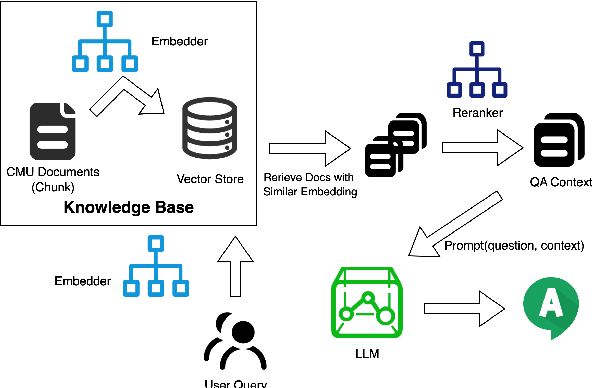
We proposed an end-to-end system design towards utilizing Retrieval Augmented Generation (RAG) to improve the factual accuracy of Large Language Models (LLMs) for domain-specific and time-sensitive queries related to private knowledge-bases. Our system integrates RAG pipeline with upstream datasets processing and downstream performance evaluation. Addressing the challenge of LLM hallucinations, we finetune models with a curated dataset which originates from CMU's extensive resources and annotated with the teacher model. Our experiments demonstrate the system's effectiveness in generating more accurate answers to domain-specific and time-sensitive inquiries. The results also revealed the limitations of fine-tuning LLMs with small-scale and skewed datasets. This research highlights the potential of RAG systems in augmenting LLMs with external datasets for improved performance in knowledge-intensive tasks. Our code and models are available on Github.
Time-Efficient and Identity-Consistent Virtual Try-On Using A Variant of Altered Diffusion Models
Mar 12, 2024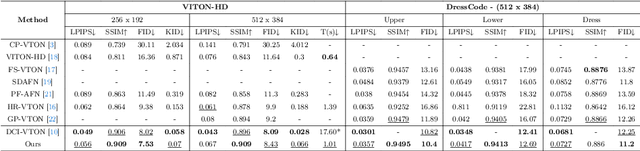
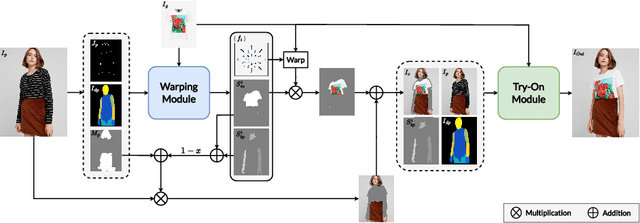
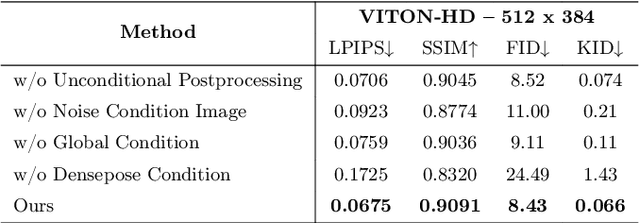
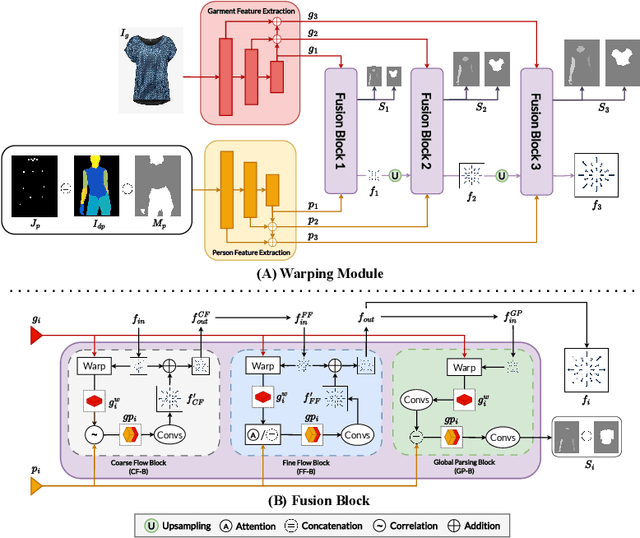
This study discusses the critical issues of Virtual Try-On in contemporary e-commerce and the prospective metaverse, emphasizing the challenges of preserving intricate texture details and distinctive features of the target person and the clothes in various scenarios, such as clothing texture and identity characteristics like tattoos or accessories. In addition to the fidelity of the synthesized images, the efficiency of the synthesis process presents a significant hurdle. Various existing approaches are explored, highlighting the limitations and unresolved aspects, e.g., identity information omission, uncontrollable artifacts, and low synthesis speed. It then proposes a novel diffusion-based solution that addresses garment texture preservation and user identity retention during virtual try-on. The proposed network comprises two primary modules - a warping module aligning clothing with individual features and a try-on module refining the attire and generating missing parts integrated with a mask-aware post-processing technique ensuring the integrity of the individual's identity. It demonstrates impressive results, surpassing the state-of-the-art in speed by nearly 20 times during inference, with superior fidelity in qualitative assessments. Quantitative evaluations confirm comparable performance with the recent SOTA method on the VITON-HD and Dresscode datasets.
Primal-Dual iLQR
Mar 13, 2024We introduce a new algorithm for solving unconstrained discrete-time optimal control problems. Our method follows a direct multiple shooting approach, and consists of applying the SQP method together with an $\ell_2$ augmented Lagrangian primal-dual merit function. We use the LQR algorithm to efficiently solve the primal component of the Newton-KKT system, and use a dual LQR backward pass to solve its dual component. We also present a new parallel algorithm for solving the dual component of the Newton-KKT system in $O(\log(N))$ parallel time, where $N$ is the number of stages. Combining it with (S\"{a}rkk\"{a} and Garc\'{i}a-Fern\'{a}ndez, 2023), we are able to solve the full Newton-KKT system in $O(\log(N))$ parallel time. The remaining parts of our method have constant parallel time complexity per iteration. Therefore, this paper provides, for the first time, a practical, highly parallelizable (for example, with a GPU) method for solving nonlinear discrete-time optimal control problems. As our algorithm is a specialization of NPSQP (Gill et al. 1992), it inherits its generic properties, including global convergence, fast local convergence, and the lack of need for second order corrections or dimension expansions, improving on existing direct multiple shooting approaches such as acados (Verschueren et al. 2022), ALTRO (Howell et al. 2019), GNMS (Giftthaler et al. 2018), FATROP (Vanroye et al. 2023), and FDDP (Mastalli et al. 2020).