 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Few-Shot Domain Adaptation for Low Light RAW Image Enhancement
Mar 27, 2023

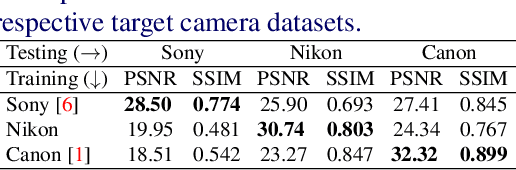
Enhancing practical low light raw images is a difficult task due to severe noise and color distortions from short exposure time and limited illumination. Despite the success of existing Convolutional Neural Network (CNN) based methods, their performance is not adaptable to different camera domains. In addition, such methods also require large datasets with short-exposure and corresponding long-exposure ground truth raw images for each camera domain, which is tedious to compile. To address this issue, we present a novel few-shot domain adaptation method to utilize the existing source camera labeled data with few labeled samples from the target camera to improve the target domain's enhancement quality in extreme low-light imaging. Our experiments show that only ten or fewer labeled samples from the target camera domain are sufficient to achieve similar or better enhancement performance than training a model with a large labeled target camera dataset. To support research in this direction, we also present a new low-light raw image dataset captured with a Nikon camera, comprising short-exposure and their corresponding long-exposure ground truth images.
* BMVC 2021 Best Student Paper Award (Runner-Up). Project Page: https://val.cds.iisc.ac.in/HDR/BMVC21/index.html
Prompting Multilingual Large Language Models to Generate Code-Mixed Texts: The Case of South East Asian Languages
Mar 30, 2023
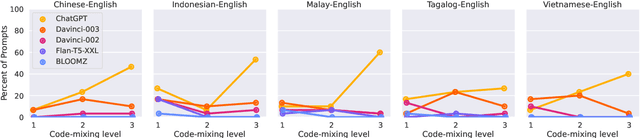
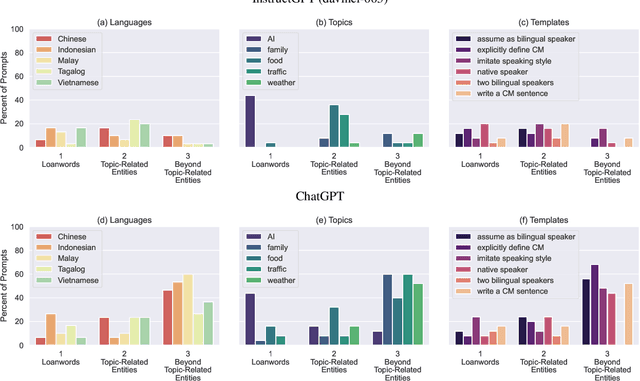
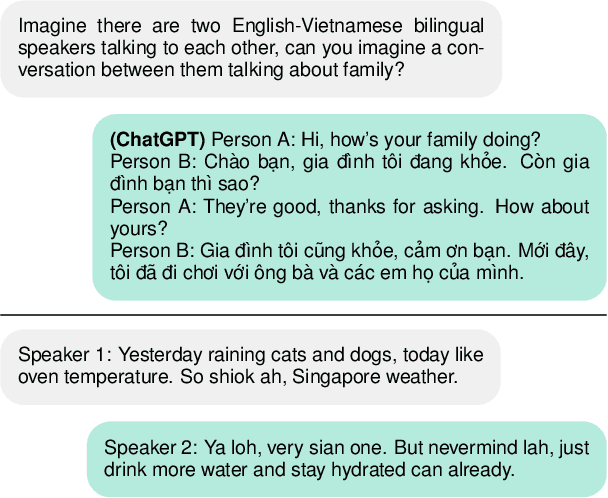
While code-mixing is a common linguistic practice in many parts of the world, collecting high-quality and low-cost code-mixed data remains a challenge for natural language processing (NLP) research. The proliferation of Large Language Models (LLMs) in recent times compels one to ask: can these systems be used for data generation? In this article, we explore prompting multilingual LLMs in a zero-shot manner to create code-mixed data for five languages in South East Asia (SEA) -- Indonesian, Malay, Chinese, Tagalog, Vietnamese, as well as the creole language Singlish. We find that ChatGPT shows the most potential, capable of producing code-mixed text 68% of the time when the term "code-mixing" is explicitly defined. Moreover, both ChatGPT's and InstructGPT's (davinci-003) performances in generating Singlish texts are noteworthy, averaging a 96% success rate across a variety of prompts. Their code-mixing proficiency, however, is dampened by word choice errors that lead to semantic inaccuracies. Other multilingual models such as BLOOMZ and Flan-T5-XXL are unable to produce code-mixed texts altogether. By highlighting the limited promises of LLMs in a specific form of low-resource data generation, we call for a measured approach when applying similar techniques to other data-scarce NLP contexts.
TraffNet: Learning Causality of Traffic Generation for Road Network Digital Twins
Mar 30, 2023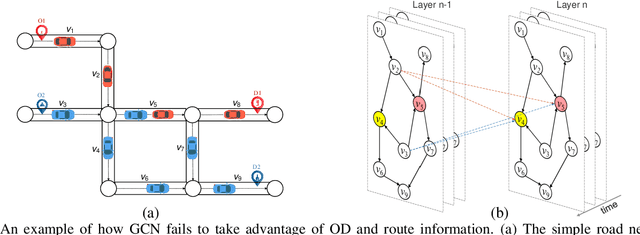
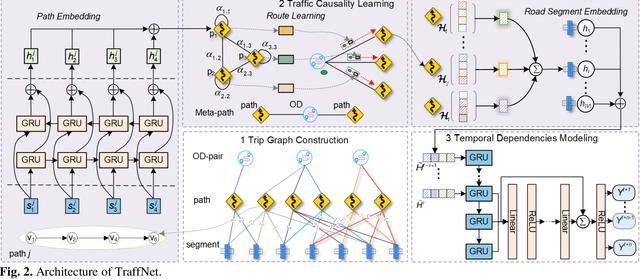
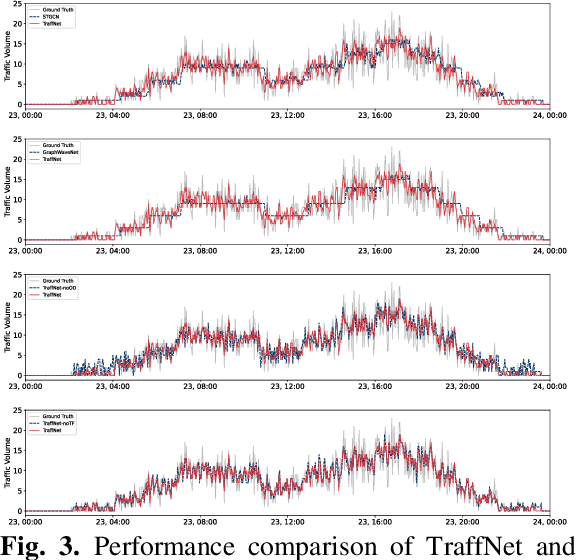
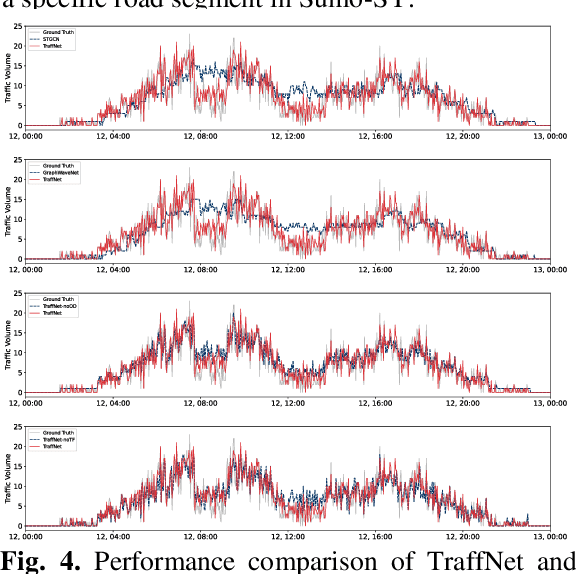
Road network digital twins (RNDTs) play a critical role in the development of next-generation intelligent transportation systems, enabling more precise traffic planning and control. To support just-in-time (JIT) decision making, RNDTs require a model that dynamically learns the traffic patterns from online sensor data and generates high-fidelity simulation results. Although current traffic prediction techniques based on graph neural networks have achieved state-of-the-art performance, these techniques only predict future traffic by mining correlations in historical traffic data, disregarding the causes of traffic generation, such as traffic demands and route selection. Therefore, their performance is unreliable for JIT decision making. To fill this gap, we introduce a novel deep learning framework called TraffNet that learns the causality of traffic volume from vehicle trajectory data. First, we use a heterogeneous graph to represent the road network, allowing the model to incorporate causal features of traffic volumes. Next, motivated by the traffic domain knowledge, we propose a traffic causality learning method to learn an embedding vector that encodes travel demands and path-level dependencies for each road segment. Then, we model temporal dependencies to match the underlying process of traffic generation. Finally, the experiments verify the utility of TraffNet. The code of TraffNet is available at https://github.com/mayunyi-1999/TraffNet_code.git.
Can I Trust My Simulation Model? Measuring the Quality of Business Process Simulation Models
Mar 30, 2023
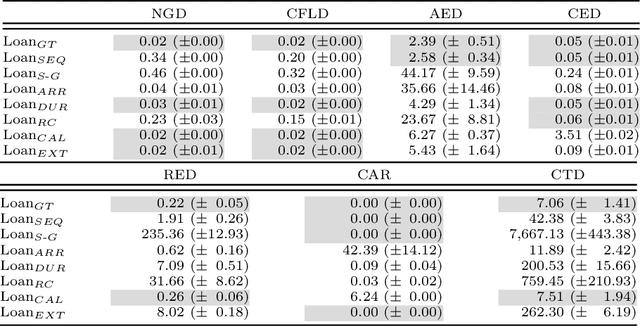
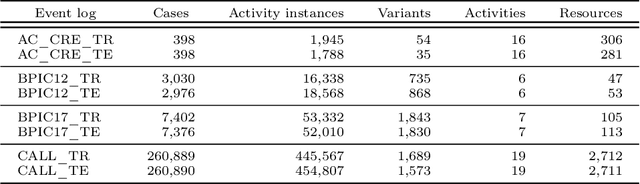
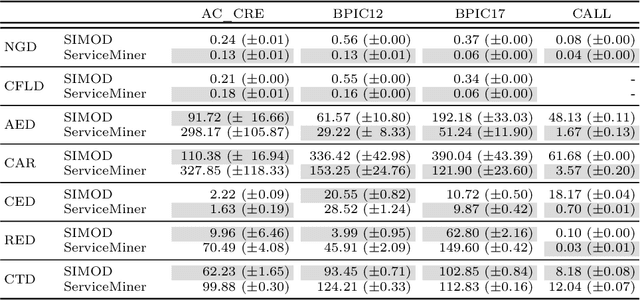
Business Process Simulation (BPS) is an approach to analyze the performance of business processes under different scenarios. For example, BPS allows us to estimate what would be the cycle time of a process if one or more resources became unavailable. The starting point of BPS is a process model annotated with simulation parameters (a BPS model). BPS models may be manually designed, based on information collected from stakeholders and empirical observations, or automatically discovered from execution data. Regardless of its origin, a key question when using a BPS model is how to assess its quality. In this paper, we propose a collection of measures to evaluate the quality of a BPS model w.r.t. its ability to replicate the observed behavior of the process. We advocate an approach whereby different measures tackle different process perspectives. We evaluate the ability of the proposed measures to discern the impact of modifications to a BPS model, and their ability to uncover the relative strengths and weaknesses of two approaches for automated discovery of BPS models. The evaluation shows that the measures not only capture how close a BPS model is to the observed behavior, but they also help us to identify sources of discrepancies.
Analysis of Failures and Risks in Deep Learning Model Converters: A Case Study in the ONNX Ecosystem
Mar 30, 2023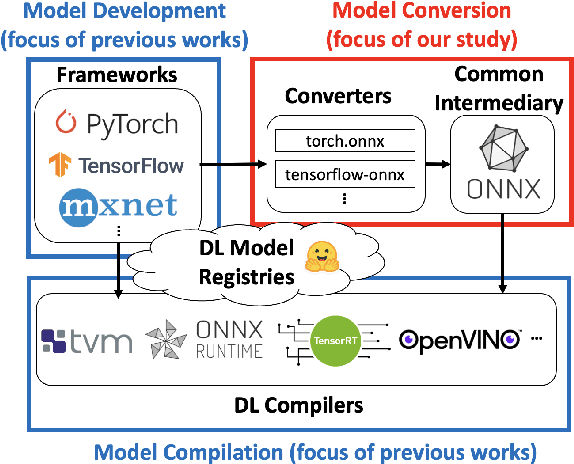

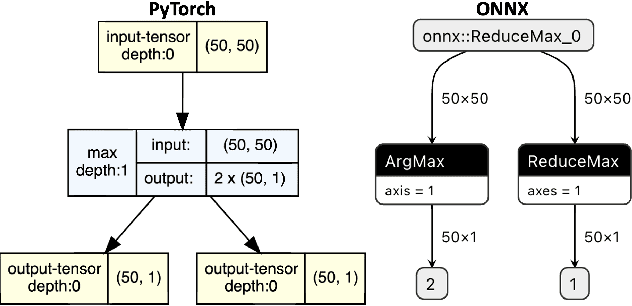
Software engineers develop, fine-tune, and deploy deep learning (DL) models. They use and re-use models in a variety of development frameworks and deploy them on a range of runtime environments. In this diverse ecosystem, engineers use DL model converters to move models from frameworks to runtime environments. However, errors in converters can compromise model quality and disrupt deployment. The failure frequency and failure modes of DL model converters are unknown. In this paper, we conduct the first failure analysis on DL model converters. Specifically, we characterize failures in model converters associated with ONNX (Open Neural Network eXchange). We analyze past failures in the ONNX converters in two major DL frameworks, PyTorch and TensorFlow. The symptoms, causes, and locations of failures (for N=200 issues), and trends over time are also reported. We also evaluate present-day failures by converting 8,797 models, both real-world and synthetically generated instances. The consistent result from both parts of the study is that DL model converters commonly fail by producing models that exhibit incorrect behavior: 33% of past failures and 8% of converted models fell into this category. Our results motivate future research on making DL software simpler to maintain, extend, and validate.
Building Floorspace in China: A Dataset and Learning Pipeline
Mar 03, 2023
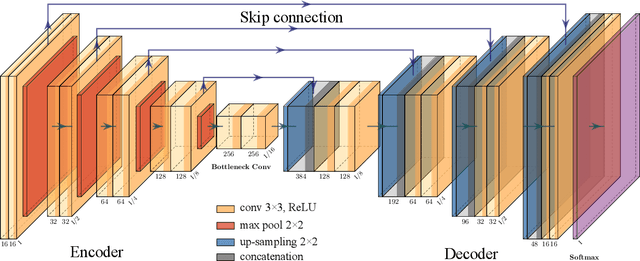
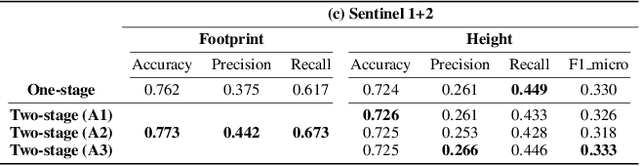
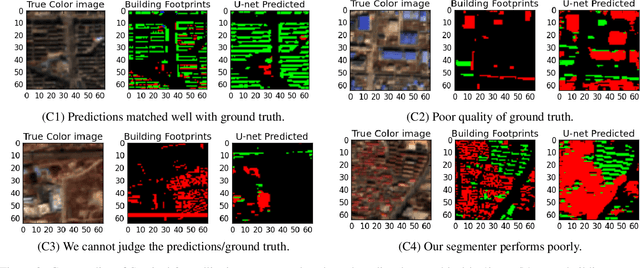
This paper provides the first milestone in measuring the floor space of buildings (that is, building footprint and height) and its evolution over time for China. Doing so requires building on imagery that is of a medium-fine-grained granularity, as longer cross-sections and time series data across many cities are only available in such format. We use a multi-class object segmenter approach to gauge the floor space of buildings in the same framework: first, we determine whether a surface area is covered by buildings (the square footage of occupied land); second, we need to determine the height of buildings from their imagery. We then use Sentinel-1 and -2 satellite images as our main data source. The benefits of these data are their large cross-sectional and longitudinal scope plus their unrestricted accessibility. We provide a detailed description of the algorithms used to generate the data and the results. We analyze the preprocessing steps of reference data (if not ground truth data) and their consequences for measuring the building floor space. We also discuss the future steps in building a time series on urban development based on our preliminary experimental results.
Study on the Data Storage Technology of Mini-Airborne Radar Based on Machine Learning
Mar 03, 2023

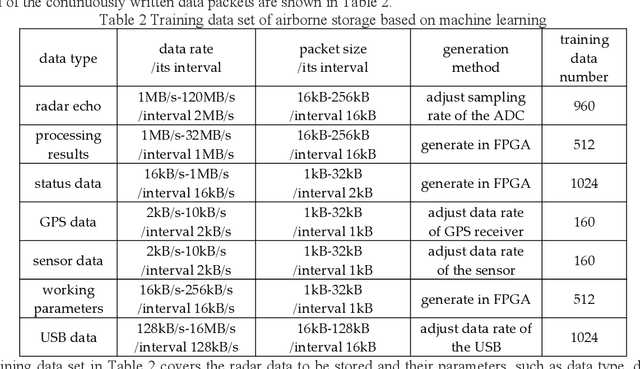

The data rate of airborne radar is much higher than the wireless data transfer rate in many detection applications, so the onboard data storage systems are usually used to store the radar data. Data storage systems with good seismic performance usually use NAND Flash as storage medium, and there is a widespread problem of long file management time, which seriously affects the data storage speed, especially under the limitation of platform miniaturization. To solve this problem, a data storage method based on machine learning is proposed for mini-airborne radar. The storage training model is established based on machine learning, and could process various kinds of radar data. The file management methods are classified and determined using the model, and then are applied to the storage of radar data. To verify the performance of the proposed method, a test was carried out on the data storage system of a mini-airborne radar. The experimental results show that the method based on machine learning can form various data storage methods adapted to different data rates and application scenarios. The ratio of the file management time to the actual data writing time is extremely low.
Robot Navigation in Risky, Crowded Environments: Understanding Human Preferences
Mar 15, 2023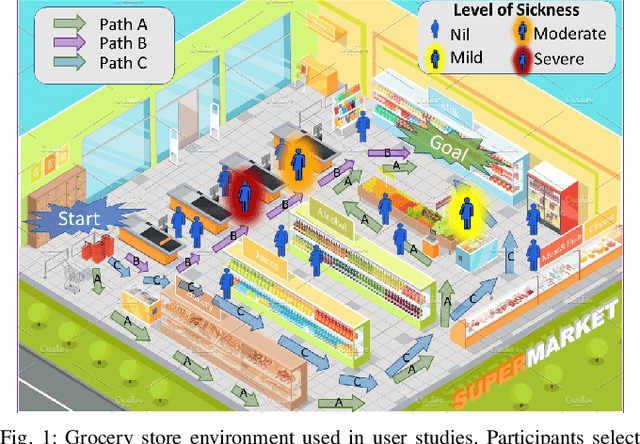
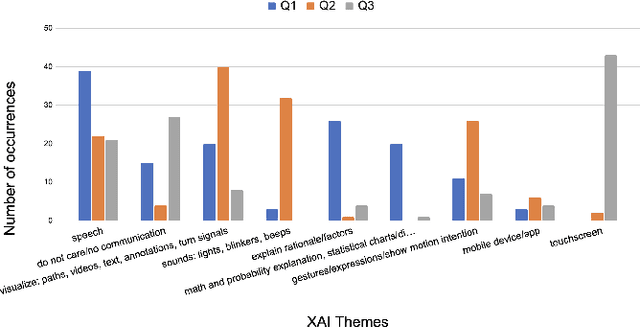
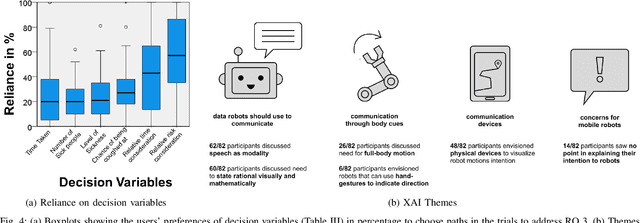
Risky and crowded environments (RCE) contain abstract sources of risk and uncertainty, which are perceived differently by humans, leading to a variety of behaviors. Thus, robots deployed in RCEs, need to exhibit diverse perception and planning capabilities in order to interpret other human agents' behavior and act accordingly in such environments. To understand this problem domain, we conducted a study to explore human path choices in RCEs, enabling better robotic navigational explainable AI (XAI) designs. We created a novel COVID-19 pandemic grocery shopping scenario which had time-risk tradeoffs, and acquired users' path preferences. We found that participants showcase a variety of path preferences: from risky and urgent to safe and relaxed. To model users' decision making, we evaluated three popular risk models (Cumulative Prospect Theory (CPT), Conditional Value at Risk (CVAR), and Expected Risk (ER). We found that CPT captured people's decision making more accurately than CVaR and ER, corroborating theoretical results that CPT is more expressive and inclusive than CVaR and ER. We also found that people's self assessments of risk and time-urgency do not correlate with their path preferences in RCEs. Finally, we conducted thematic analysis of open-ended questions, providing crucial design insights for robots is RCE. Thus, through this study, we provide novel and critical insights about human behavior and perception to help design better navigational explainable AI (XAI) in RCEs.
Digital Twins for Trust Building in Autonomous Drones through Dynamic Safety Evaluation
Mar 15, 2023The adoption process of innovative software-intensive technologies leverages complex trust concerns in different forms and shapes. Perceived safety plays a fundamental role in technology adoption, being especially crucial in the case of those innovative software-driven technologies characterized by a high degree of dynamism and unpredictability, like collaborating autonomous systems. These systems need to synchronize their maneuvers in order to collaboratively engage in reactions to unpredictable incoming hazardous situations. That is however only possible in the presence of mutual trust. In this paper, we propose an approach for machine-to-machine dynamic trust assessment for collaborating autonomous systems that supports trust-building based on the concept of dynamic safety assurance within the collaborative process among the software-intensive autonomous systems. In our approach, we leverage the concept of digital twins which are abstract models fed with real-time data used in the run-time dynamic exchange of information. The information exchange is performed through the execution of specialized models that embed the necessary safety properties. More particularly, we examine the possible role of the Digital Twins in machine-to-machine trust building and present their design in supporting dynamic trust assessment of autonomous drones. Ultimately, we present a proof of concept of direct and indirect trust assessment by employing the Digital Twin in a use case involving two autonomous collaborating drones.
Panoptic Mapping with Fruit Completion and Pose Estimation for Horticultural Robots
Mar 15, 2023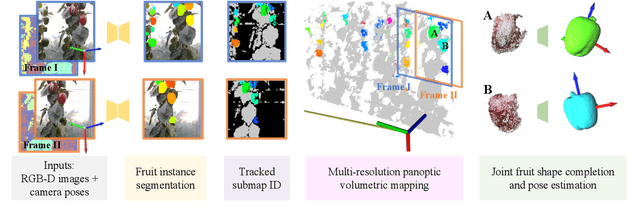

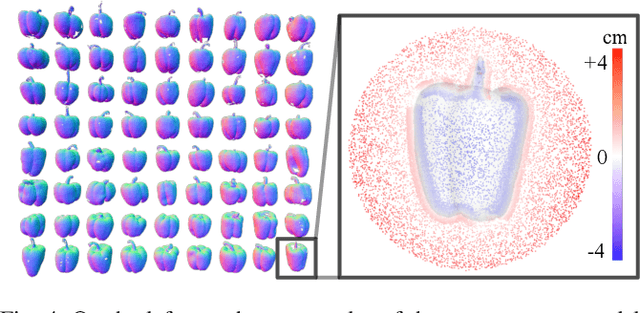
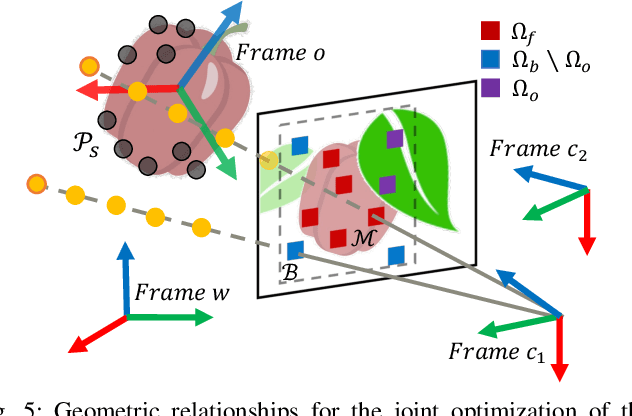
Monitoring plants and fruits at high resolution play a key role in the future of agriculture. Accurate 3D information can pave the way to a diverse number of robotic applications in agriculture ranging from autonomous harvesting to precise yield estimation. Obtaining such 3D information is non-trivial as agricultural environments are often repetitive and cluttered, and one has to account for the partial observability of fruit and plants. In this paper, we address the problem of jointly estimating complete 3D shapes of fruit and their pose in a 3D multi-resolution map built by a mobile robot. To this end, we propose an online multi-resolution panoptic mapping system where regions of interest are represented with a higher resolution. We exploit data to learn a general fruit shape representation that we use at inference time together with an occlusion-aware differentiable rendering pipeline to complete partial fruit observations and estimate the 7 DoF pose of each fruit in the map. The experiments presented in this paper, evaluated both in the controlled environment and in a commercial greenhouse, show that our novel algorithm yields higher completion and pose estimation accuracy than existing methods, with an improvement of 41% in completion accuracy and 52% in pose estimation accuracy while keeping a low inference time of 0.6s in average.