 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Three-dimensional coherent diffraction snapshot imaging using extreme ultraviolet radiation from a free electron laser
Apr 03, 2023
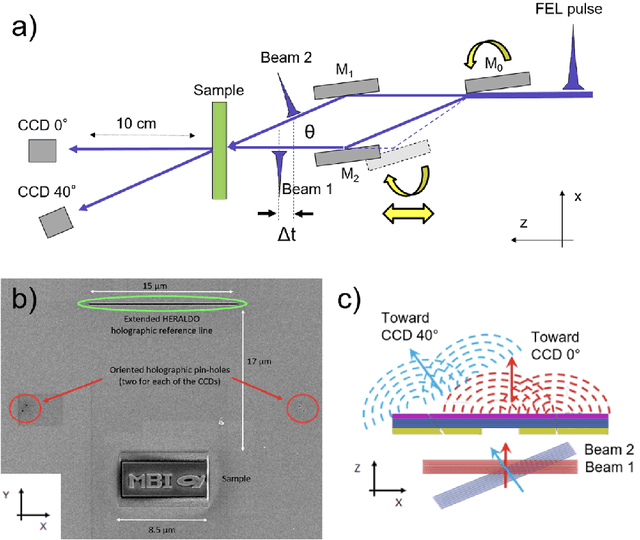
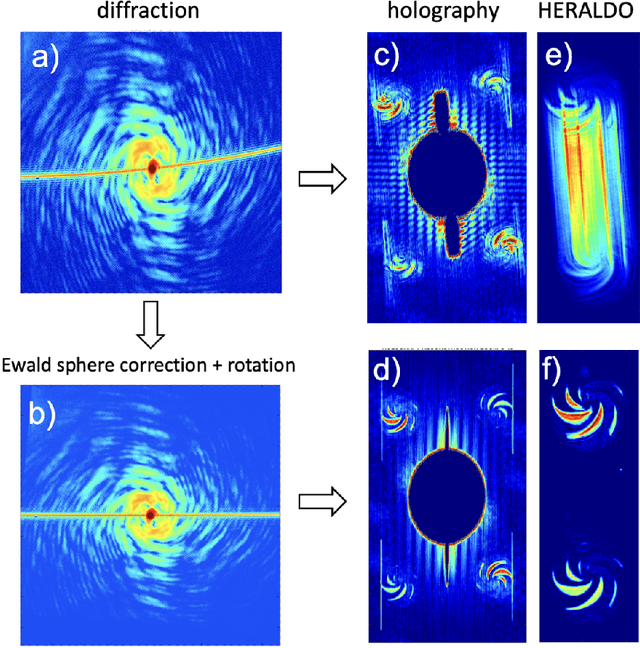
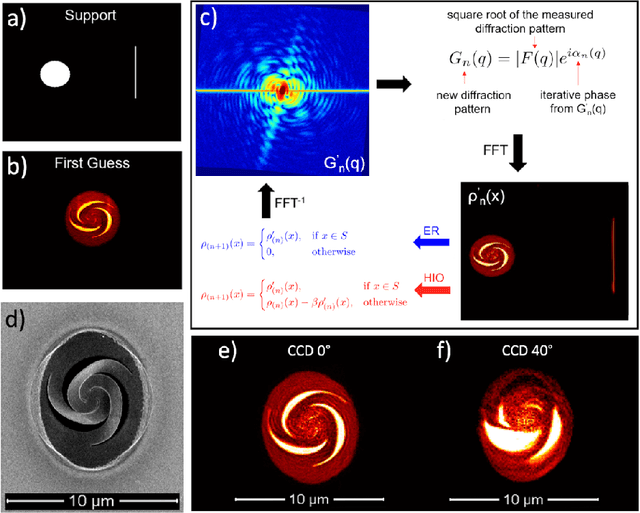

The possibility to obtain a three-dimensional representation of a single object with sub-$\mu$m resolution is crucial in many fields, from material science to clinical diagnostics. This is typically achieved through tomography, which combines multiple two-dimensional images of the same object captured at different orientations. However, this serial imaging method prevents single-shot acquisition in imaging experiments at free electron lasers. In the present experiment, we report on a new approach to 3D imaging using extreme-ultraviolet radiation. In this method, two EUV pulses hit simultaneously an isolated 3D object from different sides, generating independent coherent diffraction patterns, resulting in two distinct bidimensional views obtained via phase retrieval. These views are then used to obtain a 3D reconstruction using a ray tracing algorithm. This EUV stereoscopic imaging approach, similar to the natural process of binocular vision, provides sub-$\mu$m spatial resolution and single shot capability. Moreover, ultrafast time resolution and spectroscopy can be readily implemented, a further extension to X-ray wavelengths can be envisioned as well.
Wearable Sensor-based Multimodal Physiological Responses of Socially Anxious Individuals across Social Contexts
Apr 03, 2023
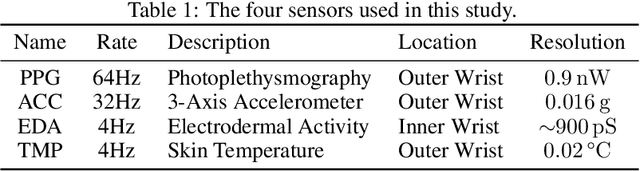
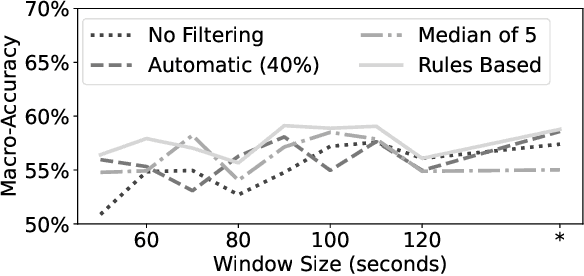
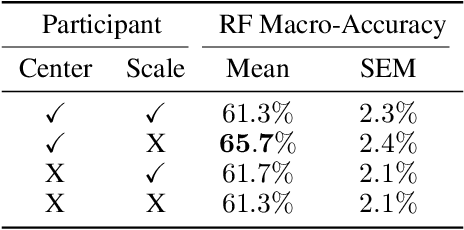
Correctly identifying an individual's social context from passively worn sensors holds promise for delivering just-in-time adaptive interventions (JITAIs) to treat social anxiety disorder. In this study, we present results using passively collected data from a within-subject experiment that assessed physiological response across different social contexts (i.e, alone vs. with others), social phases (i.e., pre- and post-interaction vs. during an interaction), social interaction sizes (i.e., dyadic vs. group interactions), and levels of social threat (i.e., implicit vs. explicit social evaluation). Participants in the study ($N=46$) reported moderate to severe social anxiety symptoms as assessed by the Social Interaction Anxiety Scale ($\geq$34 out of 80). Univariate paired difference tests, multivariate random forest models, and follow-up cluster analyses were used to explore physiological response patterns across different social and non-social contexts. Our results suggest that social context is more reliably distinguishable than social phase, group size, or level of social threat, but that there is considerable variability in physiological response patterns even among these distinguishable contexts. Implications for real-world context detection and deployment of JITAIs are discussed.
A Simple Approach for General Task-Oriented Picking using Placing constraints
Apr 03, 2023
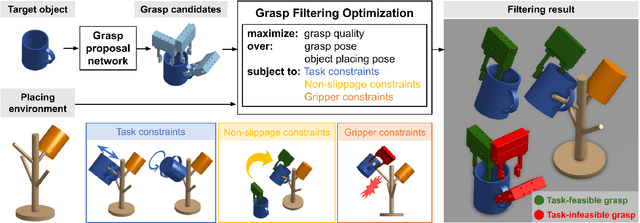

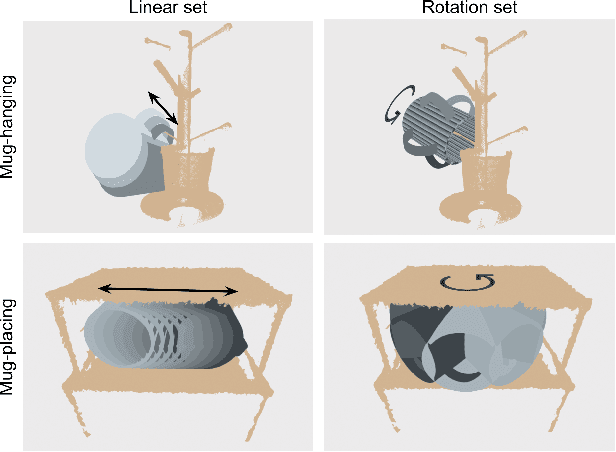
Pick-and-place is an important manipulation task in domestic or manufacturing applications. There exist many works focusing on grasp detection with high picking success rate but lacking consideration of downstream manipulation tasks (e.g., placing). Although some research works proposed methods to incorporate task conditions into grasp selection, most of them are data-driven and are therefore hard to adapt to arbitrary operating environments. Observing this challenge, we propose a general task-oriented pick-place framework that treats the target task and operating environment as placing constraints into grasping optimization. Combined with existing grasp detectors, our framework is able to generate feasible grasps for different downstream tasks and adapt to environmental changes without time-consuming re-training processes. Moreover, the framework can accept different definitions of placing constraints, so it is easy to integrate with other modules. Experiments in the simulator and real-world on multiple pick-place tasks are conducted to evaluate the performance of our framework. The result shows that our framework achieves a high and robust task success rate on a wide variety of the pick-place tasks.
Knowledge Accumulation in Continually Learned Representations and the Issue of Feature Forgetting
Apr 03, 2023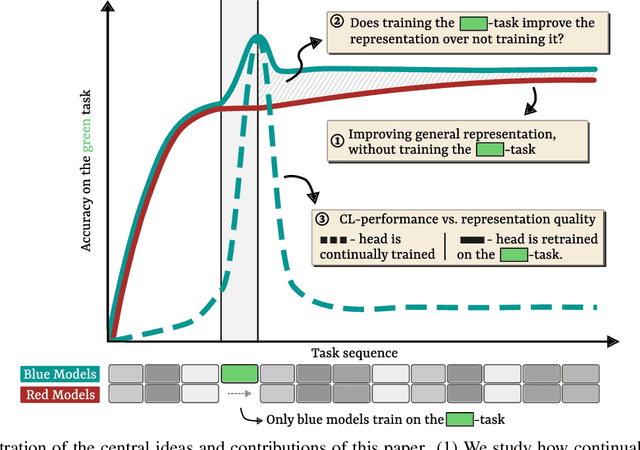

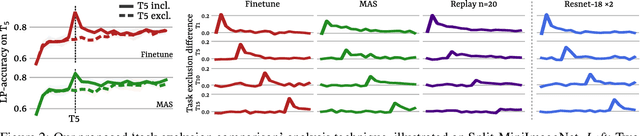
By default, neural networks learn on all training data at once. When such a model is trained on sequential chunks of new data, it tends to catastrophically forget how to handle old data. In this work we investigate how continual learners learn and forget representations. We observe two phenomena: knowledge accumulation, i.e. the improvement of a representation over time, and feature forgetting, i.e. the loss of task-specific representations. To better understand both phenomena, we introduce a new analysis technique called task exclusion comparison. If a model has seen a task and it has not forgotten all the task-specific features, then its representation for that task should be better than that of a model that was trained on similar tasks, but not that exact one. Our image classification experiments show that most task-specific features are quickly forgotten, in contrast to what has been suggested in the past. Further, we demonstrate how some continual learning methods, like replay, and ideas from representation learning affect a continually learned representation. We conclude by observing that representation quality is tightly correlated with continual learning performance.
Learning with augmented target information: An alternative theory of Feedback Alignment
Apr 03, 2023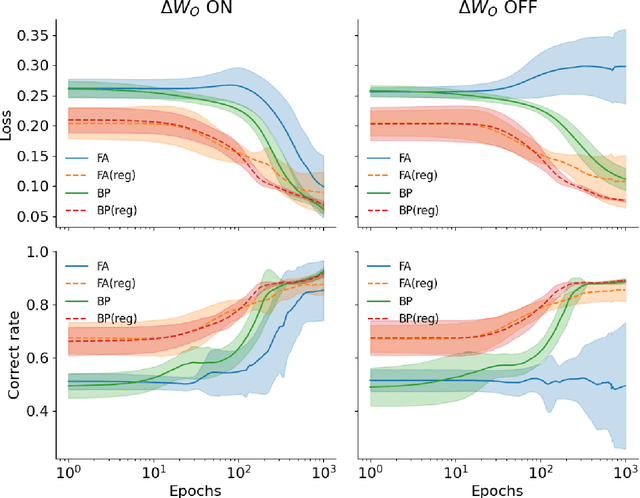
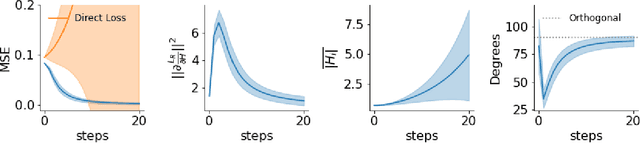
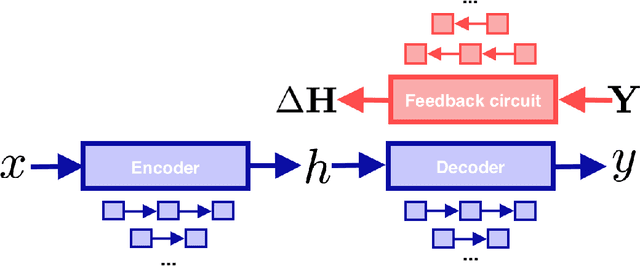
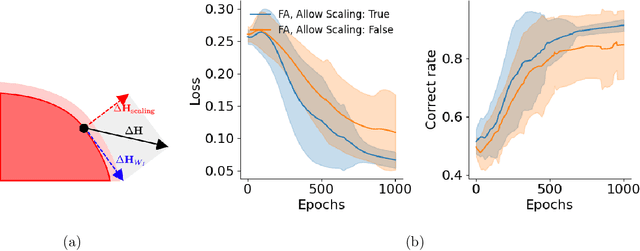
While error backpropagation (BP) has dominated the training of nearly all modern neural networks for a long time, it suffers from several biological plausibility issues such as the symmetric weight requirement and synchronous updates. Feedback Alignment (FA) was proposed as an alternative to BP to address those dilemmas and has been demonstrated to be effective on various tasks and network architectures. Despite its simplicity and effectiveness, a satisfying explanation of how FA works across different architectures is still lacking. Here we propose a novel, architecture-agnostic theory of how FA works through the lens of information theory: Instead of approximating gradients calculated by BP with the same parameter, FA learns effective representations by embedding target information into neural networks to be trained. We show this through the analysis of FA dynamics in idealized settings and then via a series of experiments. Based on the implications of this theory, we designed three variants of FA and show their comparable performance on several tasks. These variants also account for some phenomena and theories in neuroscience such as predictive coding and representational drift.
Action Pick-up in Dynamic Action Space Reinforcement Learning
Apr 03, 2023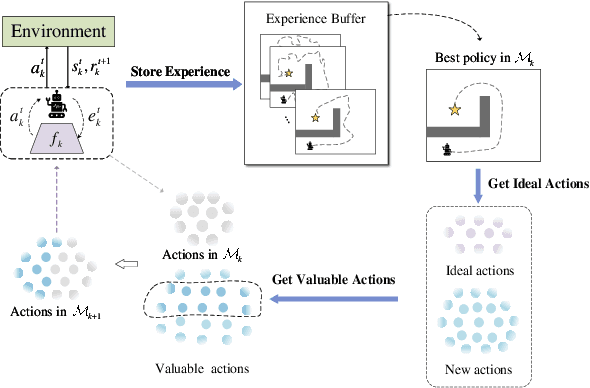

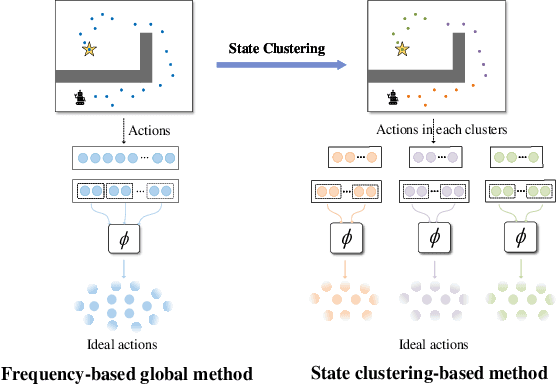
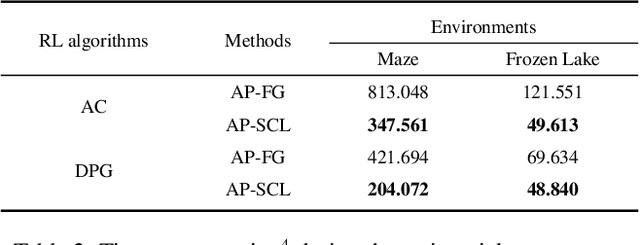
Most reinforcement learning algorithms are based on a key assumption that Markov decision processes (MDPs) are stationary. However, non-stationary MDPs with dynamic action space are omnipresent in real-world scenarios. Yet problems of dynamic action space reinforcement learning have been studied by many previous works, how to choose valuable actions from new and unseen actions to improve learning efficiency remains unaddressed. To tackle this problem, we propose an intelligent Action Pick-up (AP) algorithm to autonomously choose valuable actions that are most likely to boost performance from a set of new actions. In this paper, we first theoretically analyze and find that a prior optimal policy plays an important role in action pick-up by providing useful knowledge and experience. Then, we design two different AP methods: frequency-based global method and state clustering-based local method, based on the prior optimal policy. Finally, we evaluate the AP on two simulated but challenging environments where action spaces vary over time. Experimental results demonstrate that our proposed AP has advantages over baselines in learning efficiency.
Optimizing data-flow in Binary Neural Networks
Apr 03, 2023Binary Neural Networks (BNNs) can significantly accelerate the inference time of a neural network by replacing its expensive floating-point arithmetic with bitwise operations. Most existing solutions, however, do not fully optimize data flow through the BNN layers, and intermediate conversions from 1 to 16/32 bits often further hinder efficiency. We propose a novel training scheme that can increase data flow and parallelism in the BNN pipeline; specifically, we introduce a clipping block that decreases the data-width from 32 bits to 8. Furthermore, we reduce the internal accumulator size of a binary layer, usually kept using 32-bit to prevent data overflow without losing accuracy. Additionally, we provide an optimization of the Batch Normalization layer that both reduces latency and simplifies deployment. Finally, we present an optimized implementation of the Binary Direct Convolution for ARM instruction sets. Our experiments show a consistent improvement of the inference speed (up to 1.91 and 2.73x compared to two state-of-the-art BNNs frameworks) with no drop in accuracy for at least one full-precision model.
MetaHead: An Engine to Create Realistic Digital Head
Apr 03, 2023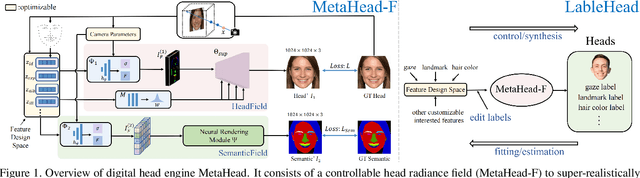
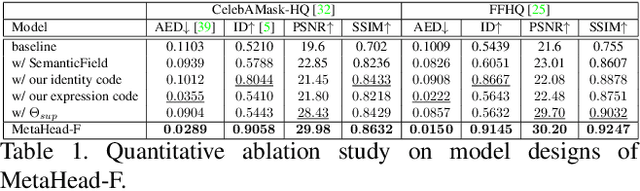
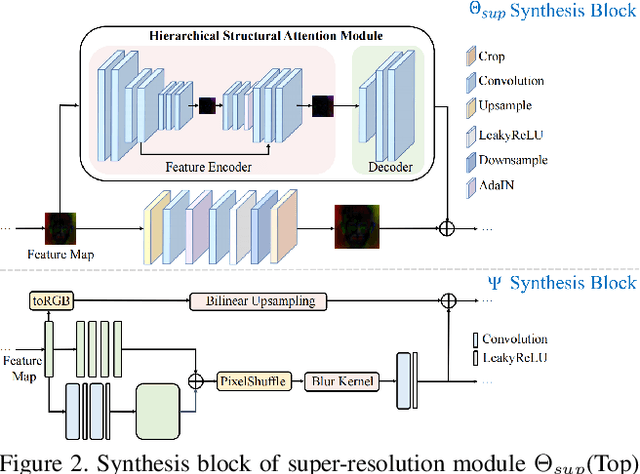
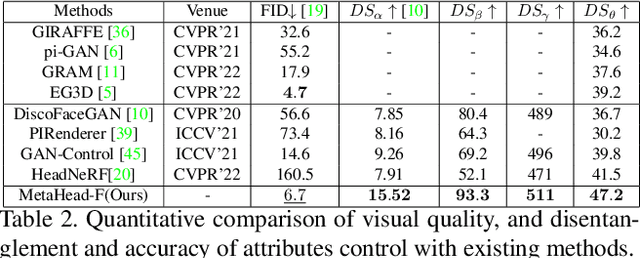
Collecting and labeling training data is one important step for learning-based methods because the process is time-consuming and biased. For face analysis tasks, although some generative models can be used to generate face data, they can only achieve a subset of generation diversity, reconstruction accuracy, 3D consistency, high-fidelity visual quality, and easy editability. One recent related work is the graphics-based generative method, but it can only render low realism head with high computation cost. In this paper, we propose MetaHead, a unified and full-featured controllable digital head engine, which consists of a controllable head radiance field(MetaHead-F) to super-realistically generate or reconstruct view-consistent 3D controllable digital heads and a generic top-down image generation framework LabelHead to generate digital heads consistent with the given customizable feature labels. Experiments validate that our controllable digital head engine achieves the state-of-the-art generation visual quality and reconstruction accuracy. Moreover, the generated labeled data can assist real training data and significantly surpass the labeled data generated by graphics-based methods in terms of training effect.
VPFusion: Towards Robust Vertical Representation Learning for 3D Object Detection
Apr 06, 2023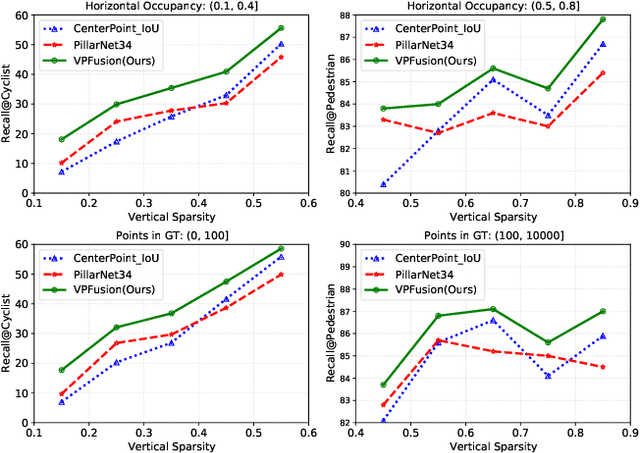
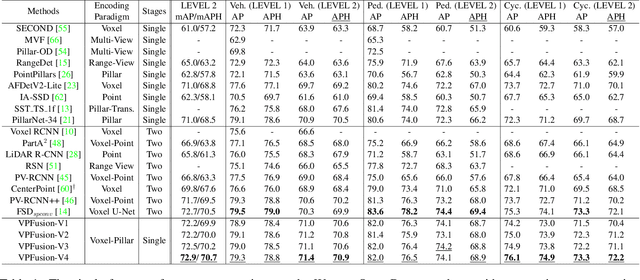
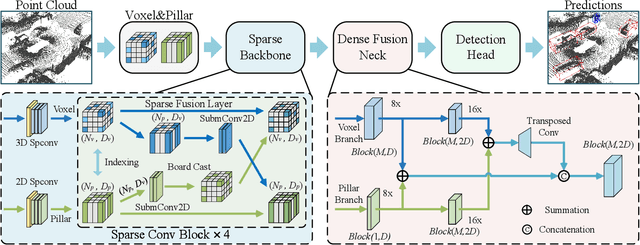
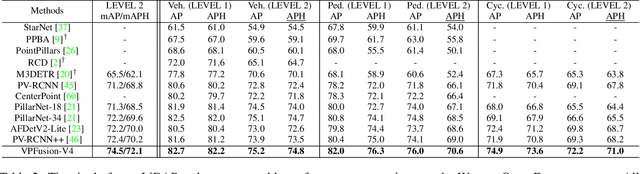
Efficient point cloud representation is a fundamental element of Lidar-based 3D object detection. Recent grid-based detectors usually divide point clouds into voxels or pillars and construct single-stream networks in Bird's Eye View. However, these point cloud encoding paradigms underestimate the point representation in the vertical direction, which cause the loss of semantic or fine-grained information, especially for vertical sensitive objects like pedestrian and cyclists. In this paper, we propose an explicit vertical multi-scale representation learning framework, VPFusion, to combine the complementary information from both voxel and pillar streams. Specifically, VPFusion first builds upon a sparse voxel-pillar-based backbone. The backbone divides point clouds into voxels and pillars, then encodes features with 3D and 2D sparse convolution simultaneously. Next, we introduce the Sparse Fusion Layer (SFL), which establishes a bidirectional pathway for sparse voxel and pillar features to enable the interaction between them. Additionally, we present the Dense Fusion Neck (DFN) to effectively combine the dense feature maps from voxel and pillar branches with multi-scale. Extensive experiments on the large-scale Waymo Open Dataset and nuScenes Dataset demonstrate that VPFusion surpasses the single-stream baselines by a large margin and achieves state-of-the-art performance with real-time inference speed.
Boundary-Denoising for Video Activity Localization
Apr 06, 2023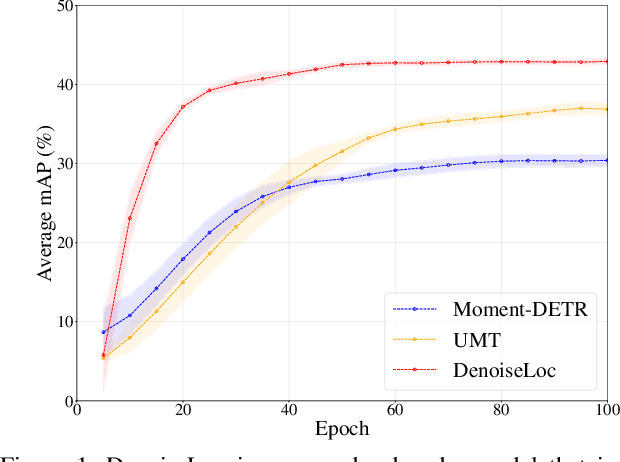
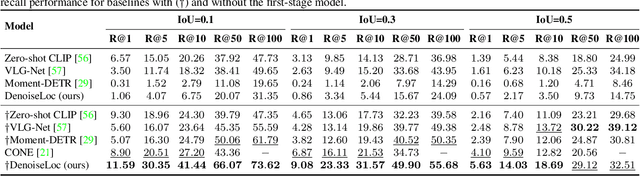
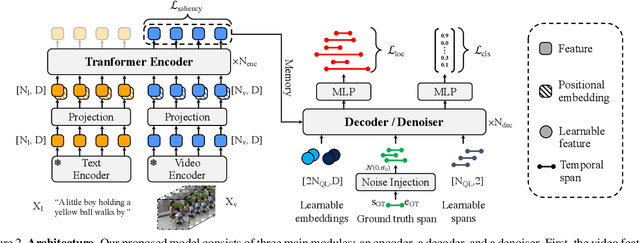
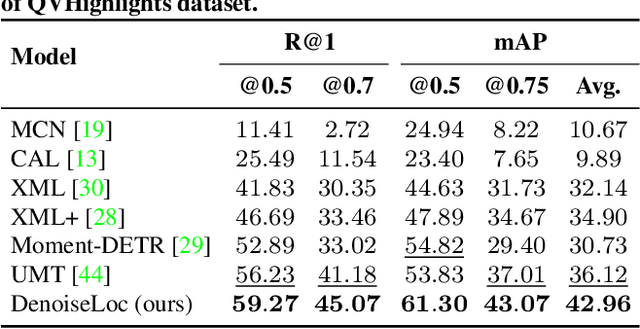
Video activity localization aims at understanding the semantic content in long untrimmed videos and retrieving actions of interest. The retrieved action with its start and end locations can be used for highlight generation, temporal action detection, etc. Unfortunately, learning the exact boundary location of activities is highly challenging because temporal activities are continuous in time, and there are often no clear-cut transitions between actions. Moreover, the definition of the start and end of events is subjective, which may confuse the model. To alleviate the boundary ambiguity, we propose to study the video activity localization problem from a denoising perspective. Specifically, we propose an encoder-decoder model named DenoiseLoc. During training, a set of action spans is randomly generated from the ground truth with a controlled noise scale. Then we attempt to reverse this process by boundary denoising, allowing the localizer to predict activities with precise boundaries and resulting in faster convergence speed. Experiments show that DenoiseLoc advances %in several video activity understanding tasks. For example, we observe a gain of +12.36% average mAP on QV-Highlights dataset and +1.64% mAP@0.5 on THUMOS'14 dataset over the baseline. Moreover, DenoiseLoc achieves state-of-the-art performance on TACoS and MAD datasets, but with much fewer predictions compared to other current methods.