 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
When does Metropolized Hamiltonian Monte Carlo provably outperform Metropolis-adjusted Langevin algorithm?
Apr 10, 2023
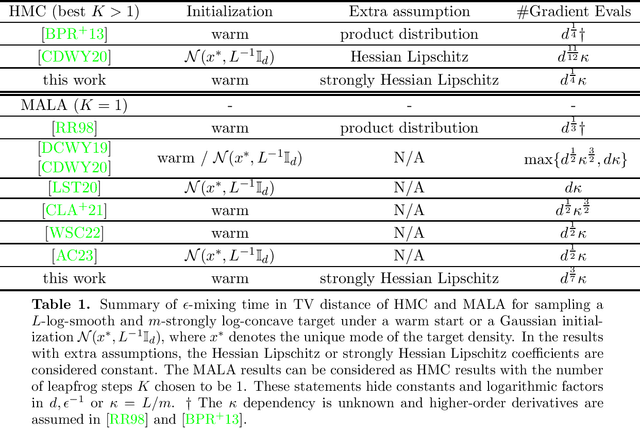
We analyze the mixing time of Metropolized Hamiltonian Monte Carlo (HMC) with the leapfrog integrator to sample from a distribution on $\mathbb{R}^d$ whose log-density is smooth, has Lipschitz Hessian in Frobenius norm and satisfies isoperimetry. We bound the gradient complexity to reach $\epsilon$ error in total variation distance from a warm start by $\tilde O(d^{1/4}\text{polylog}(1/\epsilon))$ and demonstrate the benefit of choosing the number of leapfrog steps to be larger than 1. To surpass previous analysis on Metropolis-adjusted Langevin algorithm (MALA) that has $\tilde{O}(d^{1/2}\text{polylog}(1/\epsilon))$ dimension dependency in Wu et al. (2022), we reveal a key feature in our proof that the joint distribution of the location and velocity variables of the discretization of the continuous HMC dynamics stays approximately invariant. This key feature, when shown via induction over the number of leapfrog steps, enables us to obtain estimates on moments of various quantities that appear in the acceptance rate control of Metropolized HMC. Moreover, to deal with another bottleneck on the HMC proposal distribution overlap control in the literature, we provide a new approach to upper bound the Kullback-Leibler divergence between push-forwards of the Gaussian distribution through HMC dynamics initialized at two different points. Notably, our analysis does not require log-concavity or independence of the marginals, and only relies on an isoperimetric inequality. To illustrate the applicability of our result, several examples of natural functions that fall into our framework are discussed.
Another Vertical View: A Hierarchical Network for Heterogeneous Trajectory Prediction via Spectrums
Apr 11, 2023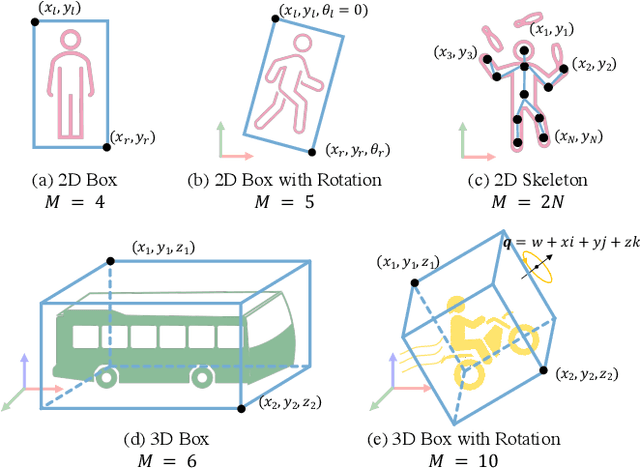

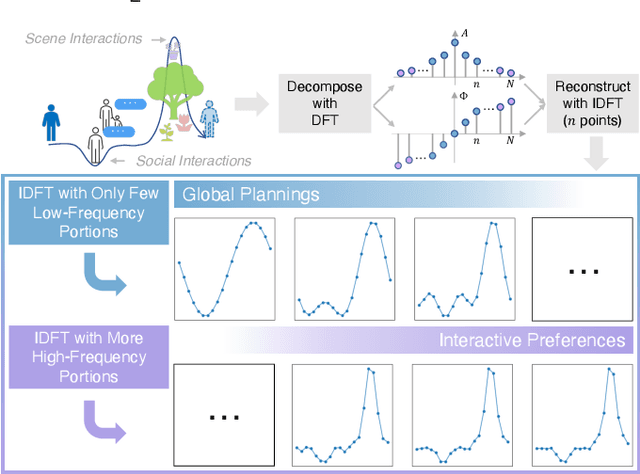
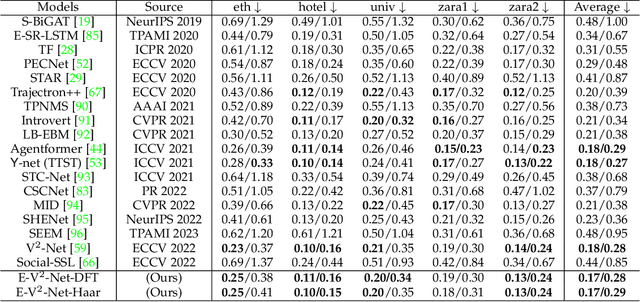
With the fast development of AI-related techniques, the applications of trajectory prediction are no longer limited to easier scenes and trajectories. More and more heterogeneous trajectories with different representation forms, such as 2D or 3D coordinates, 2D or 3D bounding boxes, and even high-dimensional human skeletons, need to be analyzed and forecasted. Among these heterogeneous trajectories, interactions between different elements within a frame of trajectory, which we call the ``Dimension-Wise Interactions'', would be more complex and challenging. However, most previous approaches focus mainly on a specific form of trajectories, which means these methods could not be used to forecast heterogeneous trajectories, not to mention the dimension-wise interaction. Besides, previous methods mostly treat trajectory prediction as a normal time sequence generation task, indicating that these methods may require more work to directly analyze agents' behaviors and social interactions at different temporal scales. In this paper, we bring a new ``view'' for trajectory prediction to model and forecast trajectories hierarchically according to different frequency portions from the spectral domain to learn to forecast trajectories by considering their frequency responses. Moreover, we try to expand the current trajectory prediction task by introducing the dimension $M$ from ``another view'', thus extending its application scenarios to heterogeneous trajectories vertically. Finally, we adopt the bilinear structure to fuse two factors, including the frequency response and the dimension-wise interaction, to forecast heterogeneous trajectories via spectrums hierarchically in a generic way. Experiments show that the proposed model outperforms most state-of-the-art methods on ETH-UCY, Stanford Drone Dataset and nuScenes with heterogeneous trajectories, including 2D coordinates, 2D and 3D bounding boxes.
Automaton-Guided Curriculum Generation for Reinforcement Learning Agents
Apr 11, 2023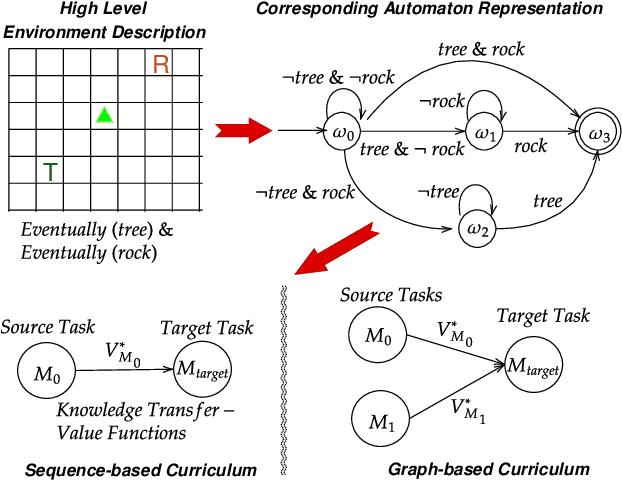
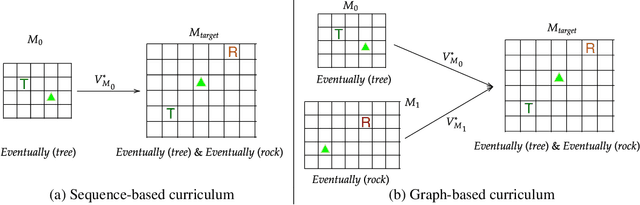
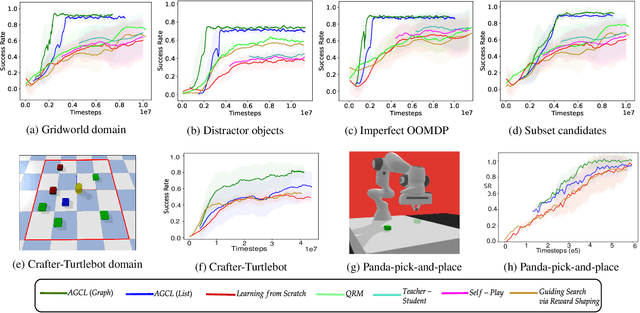
Despite advances in Reinforcement Learning, many sequential decision making tasks remain prohibitively expensive and impractical to learn. Recently, approaches that automatically generate reward functions from logical task specifications have been proposed to mitigate this issue; however, they scale poorly on long-horizon tasks (i.e., tasks where the agent needs to perform a series of correct actions to reach the goal state, considering future transitions while choosing an action). Employing a curriculum (a sequence of increasingly complex tasks) further improves the learning speed of the agent by sequencing intermediate tasks suited to the learning capacity of the agent. However, generating curricula from the logical specification still remains an unsolved problem. To this end, we propose AGCL, Automaton-guided Curriculum Learning, a novel method for automatically generating curricula for the target task in the form of Directed Acyclic Graphs (DAGs). AGCL encodes the specification in the form of a deterministic finite automaton (DFA), and then uses the DFA along with the Object-Oriented MDP (OOMDP) representation to generate a curriculum as a DAG, where the vertices correspond to tasks, and edges correspond to the direction of knowledge transfer. Experiments in gridworld and physics-based simulated robotics domains show that the curricula produced by AGCL achieve improved time-to-threshold performance on a complex sequential decision-making problem relative to state-of-the-art curriculum learning (e.g, teacher-student, self-play) and automaton-guided reinforcement learning baselines (e.g, Q-Learning for Reward Machines). Further, we demonstrate that AGCL performs well even in the presence of noise in the task's OOMDP description, and also when distractor objects are present that are not modeled in the logical specification of the tasks' objectives.
LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images
Apr 11, 2023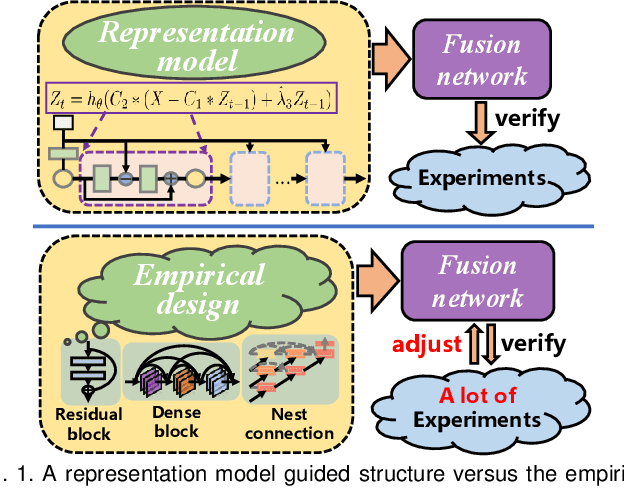
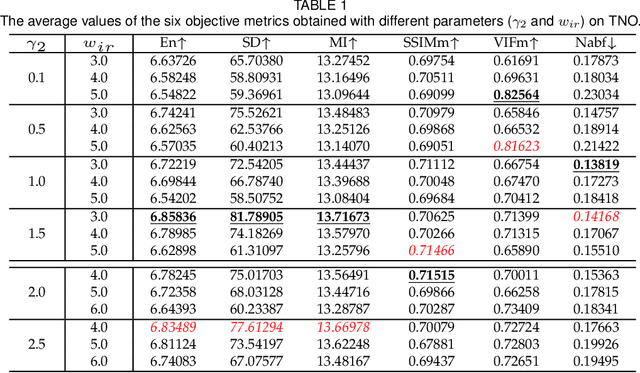

Deep learning based fusion methods have been achieving promising performance in image fusion tasks. This is attributed to the network architecture that plays a very important role in the fusion process. However, in general, it is hard to specify a good fusion architecture, and consequently, the design of fusion networks is still a black art, rather than science. To address this problem, we formulate the fusion task mathematically, and establish a connection between its optimal solution and the network architecture that can implement it. This approach leads to a novel method proposed in the paper of constructing a lightweight fusion network. It avoids the time-consuming empirical network design by a trial-and-test strategy. In particular we adopt a learnable representation approach to the fusion task, in which the construction of the fusion network architecture is guided by the optimisation algorithm producing the learnable model. The low-rank representation (LRR) objective is the foundation of our learnable model. The matrix multiplications, which are at the heart of the solution are transformed into convolutional operations, and the iterative process of optimisation is replaced by a special feed-forward network. Based on this novel network architecture, an end-to-end lightweight fusion network is constructed to fuse infrared and visible light images. Its successful training is facilitated by a detail-to-semantic information loss function proposed to preserve the image details and to enhance the salient features of the source images. Our experiments show that the proposed fusion network exhibits better fusion performance than the state-of-the-art fusion methods on public datasets. Interestingly, our network requires a fewer training parameters than other existing methods.
Gradient-Descent Based Optimization of Constant Envelope OFDM Waveforms
Mar 16, 2023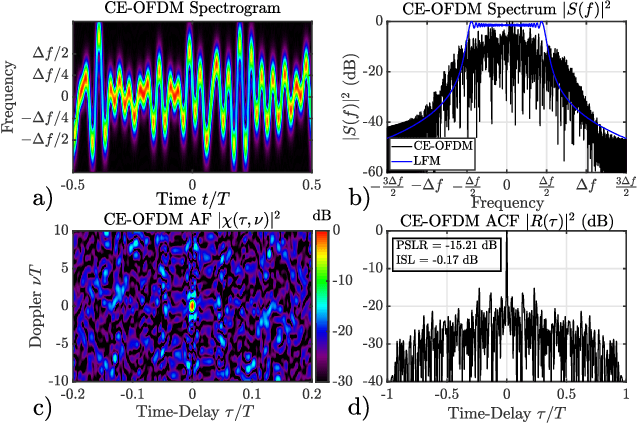
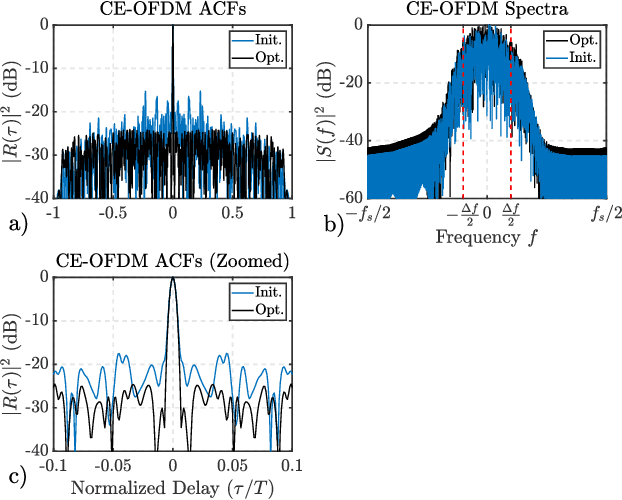
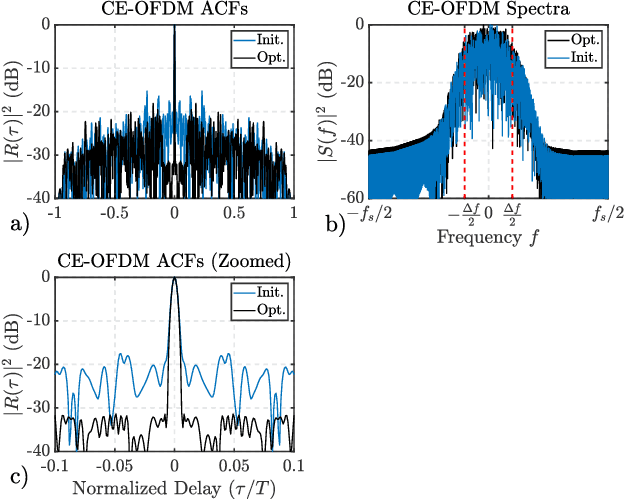
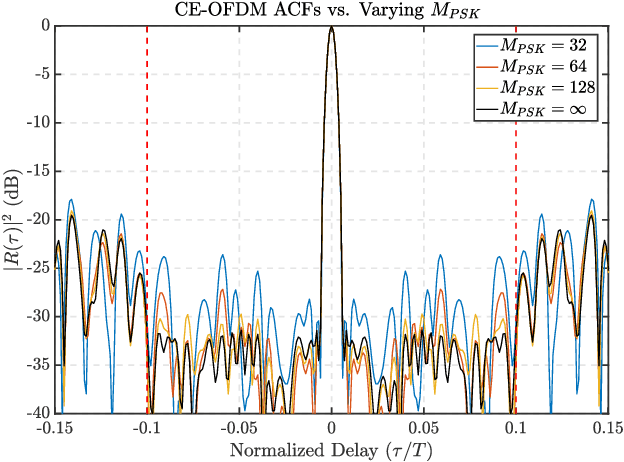
This paper describes a gradient-descent based optimization algorithm for synthesizing Constant Envelope Orthogonal Frequency Division Multiplexing (CE-OFDM) waveforms with low Auto-Correlation Function (ACF) sidelobes in a specified region of time-delays. The algorithm optimizes the Generalized Integrated Sidelobe Level (GISL) which controls the mainlobe and sidelobe structure of the waveform's ACF. The operations of this Gradient-Descent GISL (GD-GISL) algorithm are FFT-based making it computationally efficient. This computational efficiency facilitates the design of large dimensional waveform design problems. Simulations demonstrate the GD-GISL algorithm on CE-OFDM waveforms employing Phase-Shift Keying (PSK) symbols that take on a continuum of values (i.e, $M_{\text{PSK}} = \infty$). Results from these simulations show that the GD-GISL algorithm can indeed reduce ACF sidelobes in a desired region of time-delays. However, truncating the symbols to finite M-ary alphabets introduces perturbations to the waveform's instantaneous phase which increases the waveform's ACF sidelobe levels.
Anomaly Search Over Many Sequences With Switching Costs
Mar 16, 2023
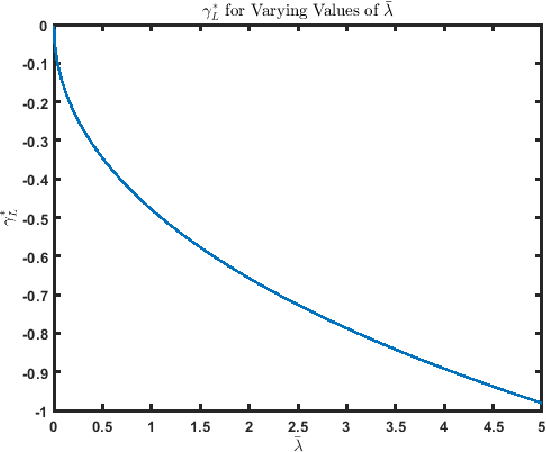
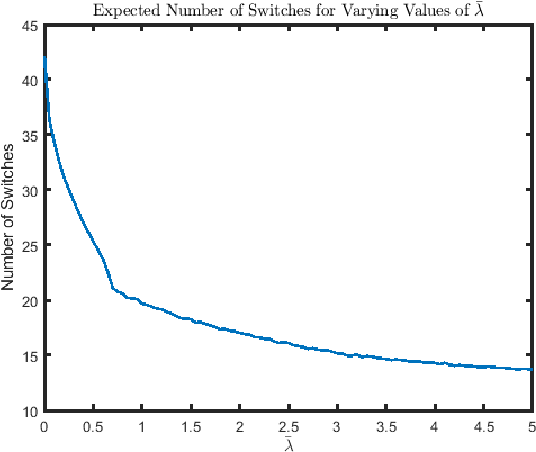
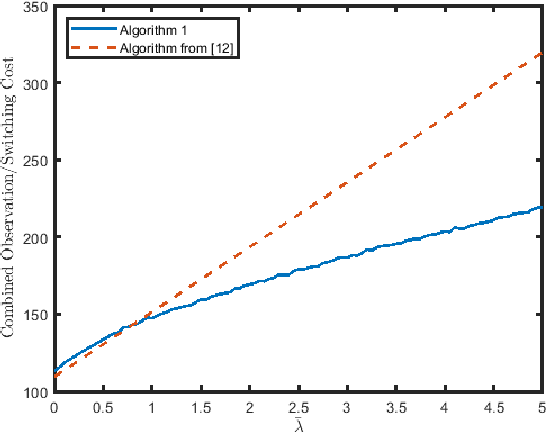
This paper considers the quickest search problem to identify anomalies among large numbers of data streams. These streams can model, for example, disjoint regions monitored by a mobile robot. A particular challenge is a version of the problem in which the experimenter must suffer a cost each time the data stream being sampled changes, such as the time the robot must spend moving between regions. In this paper, we propose an algorithm which accounts for switching costs by varying a confidence threshold that governs when the algorithm switches to a new data stream. Our main contributions are easily computable approximations for both the optimal value of this threshold and the optimal value of the parameter that determines when a stream must be re-sampled. Further, we empirically show (i) a uniform improvement for switching costs of interest and (ii) roughly equivalent performance for small switching costs when comparing to the closest available algorithm.
Green Federated Learning
Mar 26, 2023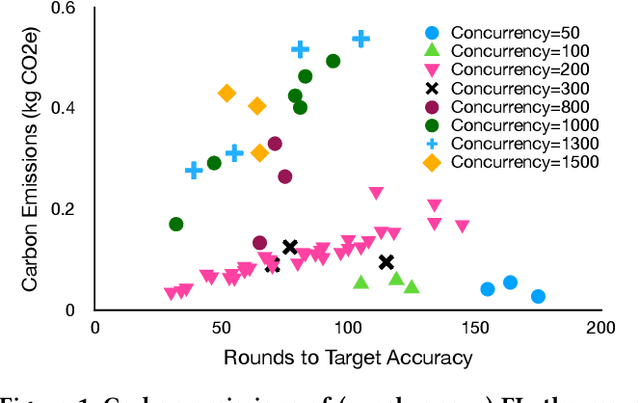
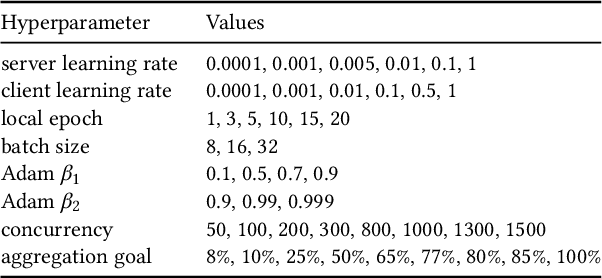
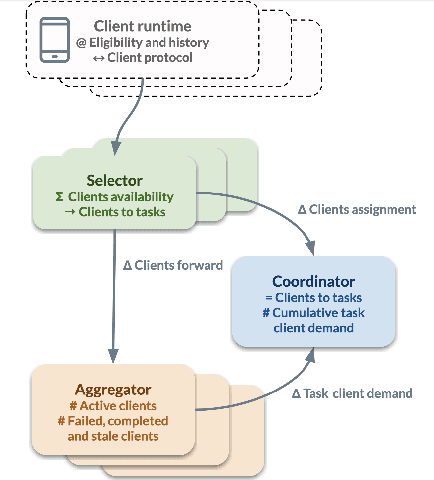
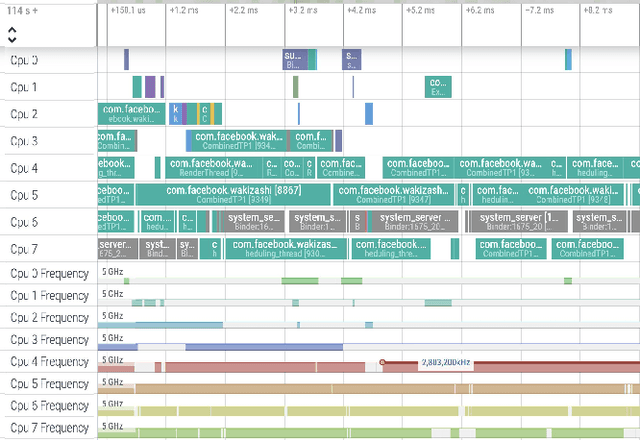
The rapid progress of AI is fueled by increasingly large and computationally intensive machine learning models and datasets. As a consequence, the amount of compute used in training state-of-the-art models is exponentially increasing (doubling every 10 months between 2015 and 2022), resulting in a large carbon footprint. Federated Learning (FL) - a collaborative machine learning technique for training a centralized model using data of decentralized entities - can also be resource-intensive and have a significant carbon footprint, particularly when deployed at scale. Unlike centralized AI that can reliably tap into renewables at strategically placed data centers, cross-device FL may leverage as many as hundreds of millions of globally distributed end-user devices with diverse energy sources. Green AI is a novel and important research area where carbon footprint is regarded as an evaluation criterion for AI, alongside accuracy, convergence speed, and other metrics. In this paper, we propose the concept of Green FL, which involves optimizing FL parameters and making design choices to minimize carbon emissions consistent with competitive performance and training time. The contributions of this work are two-fold. First, we adopt a data-driven approach to quantify the carbon emissions of FL by directly measuring real-world at-scale FL tasks running on millions of phones. Second, we present challenges, guidelines, and lessons learned from studying the trade-off between energy efficiency, performance, and time-to-train in a production FL system. Our findings offer valuable insights into how FL can reduce its carbon footprint, and they provide a foundation for future research in the area of Green AI.
LIGHT: Joint Individual Building Extraction and Height Estimation from Satellite Images through a Unified Multitask Learning Network
Apr 03, 2023
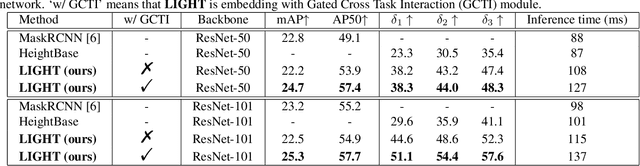
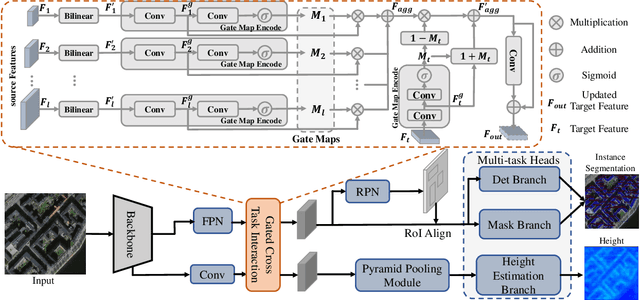

Building extraction and height estimation are two important basic tasks in remote sensing image interpretation, which are widely used in urban planning, real-world 3D construction, and other fields. Most of the existing research regards the two tasks as independent studies. Therefore the height information cannot be fully used to improve the accuracy of building extraction and vice versa. In this work, we combine the individuaL buIlding extraction and heiGHt estimation through a unified multiTask learning network (LIGHT) for the first time, which simultaneously outputs a height map, bounding boxes, and a segmentation mask map of buildings. Specifically, LIGHT consists of an instance segmentation branch and a height estimation branch. In particular, so as to effectively unify multi-scale feature branches and alleviate feature spans between branches, we propose a Gated Cross Task Interaction (GCTI) module that can efficiently perform feature interaction between branches. Experiments on the DFC2023 dataset show that our LIGHT can achieve superior performance, and our GCTI module with ResNet101 as the backbone can significantly improve the performance of multitask learning by 2.8% AP50 and 6.5% delta1, respectively.
Analysis and Comparison of Two-Level KFAC Methods for Training Deep Neural Networks
Apr 03, 2023As a second-order method, the Natural Gradient Descent (NGD) has the ability to accelerate training of neural networks. However, due to the prohibitive computational and memory costs of computing and inverting the Fisher Information Matrix (FIM), efficient approximations are necessary to make NGD scalable to Deep Neural Networks (DNNs). Many such approximations have been attempted. The most sophisticated of these is KFAC, which approximates the FIM as a block-diagonal matrix, where each block corresponds to a layer of the neural network. By doing so, KFAC ignores the interactions between different layers. In this work, we investigate the interest of restoring some low-frequency interactions between the layers by means of two-level methods. Inspired from domain decomposition, several two-level corrections to KFAC using different coarse spaces are proposed and assessed. The obtained results show that incorporating the layer interactions in this fashion does not really improve the performance of KFAC. This suggests that it is safe to discard the off-diagonal blocks of the FIM, since the block-diagonal approach is sufficiently robust, accurate and economical in computation time.
Unified Emulation-Simulation Training Environment for Autonomous Cyber Agents
Apr 03, 2023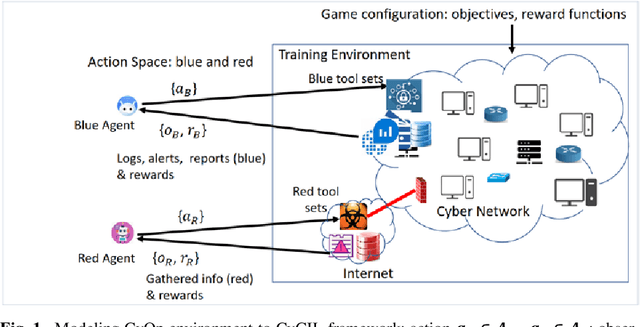
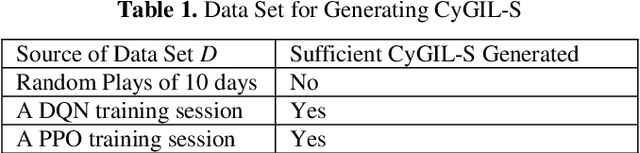
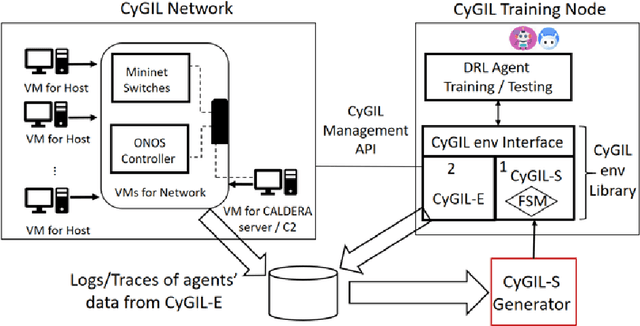
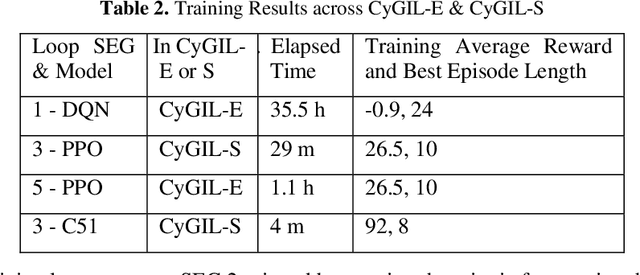
Autonomous cyber agents may be developed by applying reinforcement and deep reinforcement learning (RL/DRL), where agents are trained in a representative environment. The training environment must simulate with high-fidelity the network Cyber Operations (CyOp) that the agent aims to explore. Given the complexity of net-work CyOps, a good simulator is difficult to achieve. This work presents a systematic solution to automatically generate a high-fidelity simulator in the Cyber Gym for Intelligent Learning (CyGIL). Through representation learning and continuous learning, CyGIL provides a unified CyOp training environment where an emulated CyGIL-E automatically generates a simulated CyGIL-S. The simulator generation is integrated with the agent training process to further reduce the required agent training time. The agent trained in CyGIL-S is transferrable directly to CyGIL-E showing full transferability to the emulated "real" network. Experimental results are presented to demonstrate the CyGIL training performance. Enabling offline RL, the CyGIL solution presents a promising direction towards sim-to-real for leveraging RL agents in real-world cyber networks.