 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mapping historical forest biomass for stock-change assessments at parcel to landscape scales
Apr 05, 2023
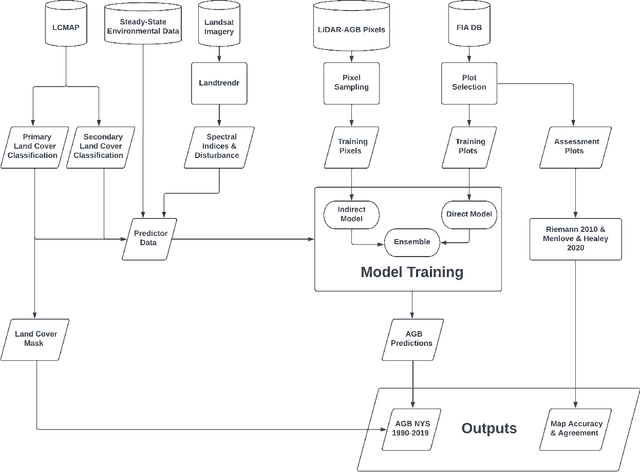

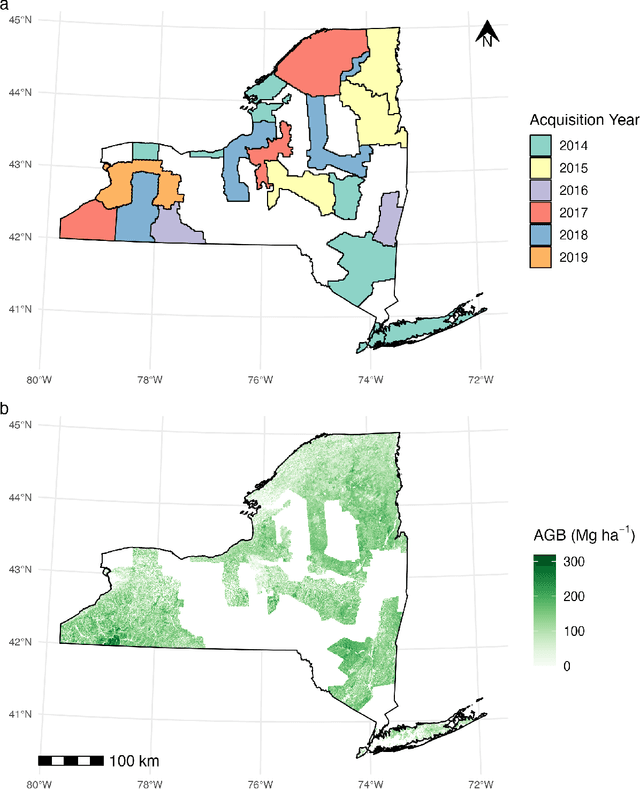
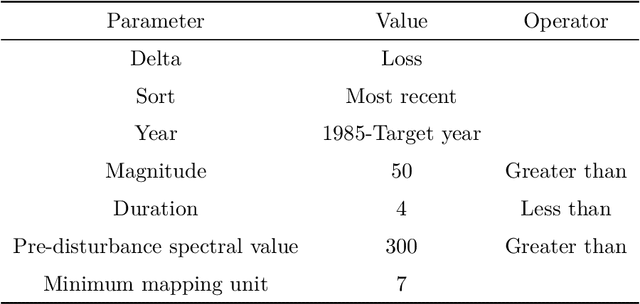
Understanding historical forest dynamics, specifically changes in forest biomass and carbon stocks, has become critical for assessing current forest climate benefits and projecting future benefits under various policy, regulatory, and stewardship scenarios. Carbon accounting frameworks based exclusively on national forest inventories are limited to broad-scale estimates, but model-based approaches that combine these inventories with remotely sensed data can yield contiguous fine-resolution maps of forest biomass and carbon stocks across landscapes over time. Here we describe a fundamental step in building a map-based stock-change framework: mapping historical forest biomass at fine temporal and spatial resolution (annual, 30m) across all of New York State (USA) from 1990 to 2019, using freely available data and open-source tools. Using Landsat imagery, US Forest Service Forest Inventory and Analysis (FIA) data, and off-the-shelf LiDAR collections we developed three modeling approaches for mapping historical forest aboveground biomass (AGB): training on FIA plot-level AGB estimates (direct), training on LiDAR-derived AGB maps (indirect), and an ensemble averaging predictions from the direct and indirect models. Model prediction surfaces (maps) were tested against FIA estimates at multiple scales. All three approaches produced viable outputs, yet tradeoffs were evident in terms of model complexity, map accuracy, saturation, and fine-scale pattern representation. The resulting map products can help identify where, when, and how forest carbon stocks are changing as a result of both anthropogenic and natural drivers alike. These products can thus serve as inputs to a wide range of applications including stock-change assessments, monitoring reporting and verification frameworks, and prioritizing parcels for protection or enrollment in improved management programs.
Parameterized Approximation Schemes for Clustering with General Norm Objectives
Apr 06, 2023
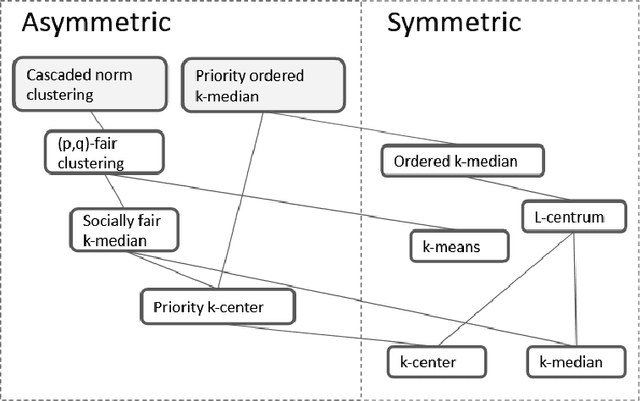
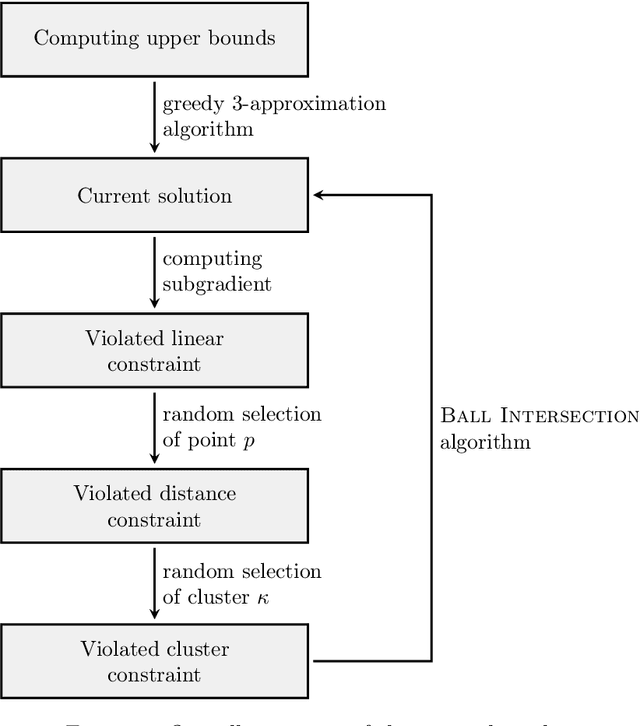
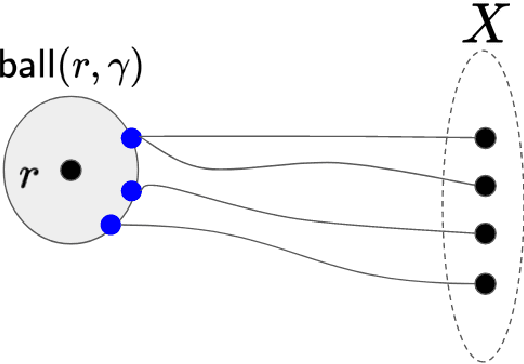
This paper considers the well-studied algorithmic regime of designing a $(1+\epsilon)$-approximation algorithm for a $k$-clustering problem that runs in time $f(k,\epsilon)poly(n)$ (sometimes called an efficient parameterized approximation scheme or EPAS for short). Notable results of this kind include EPASes in the high-dimensional Euclidean setting for $k$-center [Bad\u{o}iu, Har-Peled, Indyk; STOC'02] as well as $k$-median, and $k$-means [Kumar, Sabharwal, Sen; J. ACM 2010]. However, existing EPASes handle only basic objectives (such as $k$-center, $k$-median, and $k$-means) and are tailored to the specific objective and metric space. Our main contribution is a clean and simple EPAS that settles more than ten clustering problems (across multiple well-studied objectives as well as metric spaces) and unifies well-known EPASes. Our algorithm gives EPASes for a large variety of clustering objectives (for example, $k$-means, $k$-center, $k$-median, priority $k$-center, $\ell$-centrum, ordered $k$-median, socially fair $k$-median aka robust $k$-median, or more generally monotone norm $k$-clustering) and metric spaces (for example, continuous high-dimensional Euclidean spaces, metrics of bounded doubling dimension, bounded treewidth metrics, and planar metrics). Key to our approach is a new concept that we call bounded $\epsilon$-scatter dimension--an intrinsic complexity measure of a metric space that is a relaxation of the standard notion of bounded doubling dimension. Our main technical result shows that two conditions are essentially sufficient for our algorithm to yield an EPAS on the input metric $M$ for any clustering objective: (i) The objective is described by a monotone (not necessarily symmetric!) norm, and (ii) the $\epsilon$-scatter dimension of $M$ is upper bounded by a function of $\epsilon$.
Deep Reinforcement Learning Based Vehicle Selection for Asynchronous Federated Learning Enabled Vehicular Edge Computing
Apr 06, 2023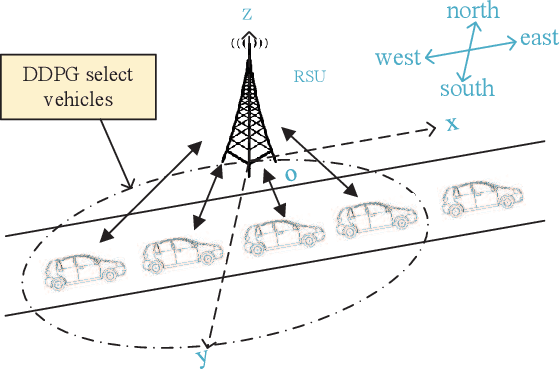
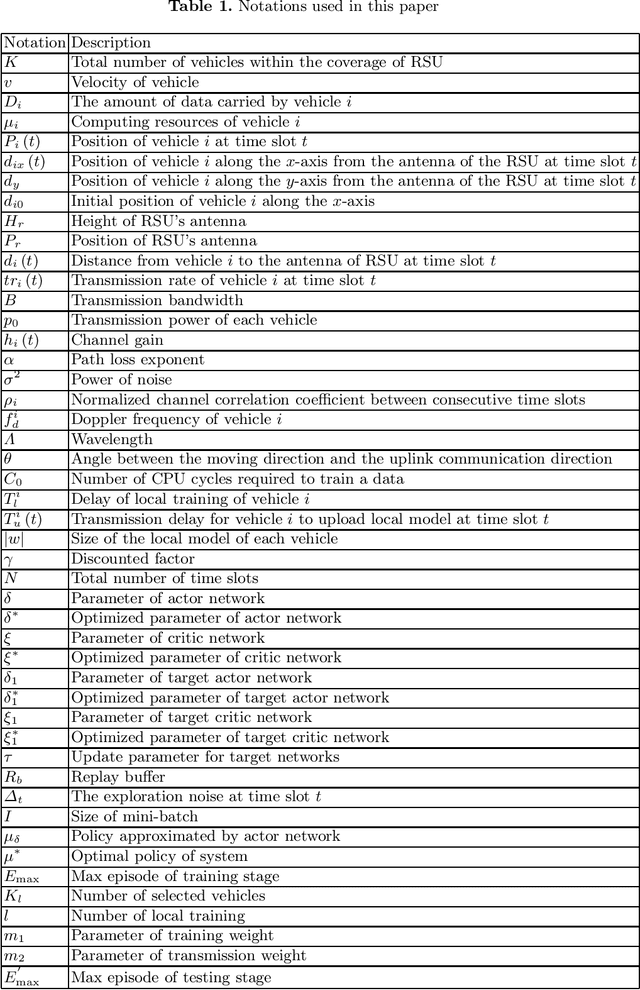
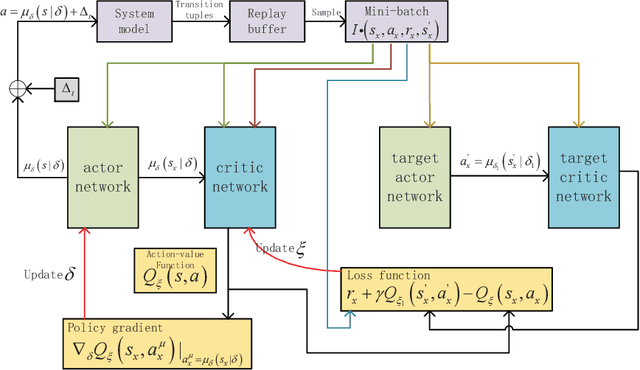
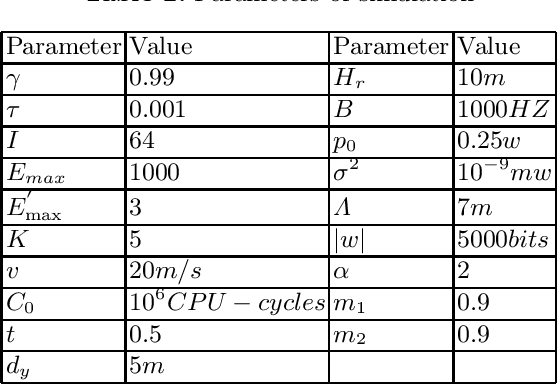
In the traditional vehicular network, computing tasks generated by the vehicles are usually uploaded to the cloud for processing. However, since task offloading toward the cloud will cause a large delay, vehicular edge computing (VEC) is introduced to avoid such a problem and improve the whole system performance, where a roadside unit (RSU) with certain computing capability is used to process the data of vehicles as an edge entity. Owing to the privacy and security issues, vehicles are reluctant to upload local data directly to the RSU, and thus federated learning (FL) becomes a promising technology for some machine learning tasks in VEC, where vehicles only need to upload the local model hyperparameters instead of transferring their local data to the nearby RSU. Furthermore, as vehicles have different local training time due to various sizes of local data and their different computing capabilities, asynchronous federated learning (AFL) is employed to facilitate the RSU to update the global model immediately after receiving a local model to reduce the aggregation delay. However, in AFL of VEC, different vehicles may have different impact on the global model updating because of their various local training delay, transmission delay and local data sizes. Also, if there are bad nodes among the vehicles, it will affect the global aggregation quality at the RSU. To solve the above problem, we shall propose a deep reinforcement learning (DRL) based vehicle selection scheme to improve the accuracy of the global model in AFL of vehicular network. In the scheme, we present the model including the state, action and reward in the DRL based to the specific problem. Simulation results demonstrate our scheme can effectively remove the bad nodes and improve the aggregation accuracy of the global model.
Deep trip generation with graph neural networks for bike sharing system expansion
Mar 20, 2023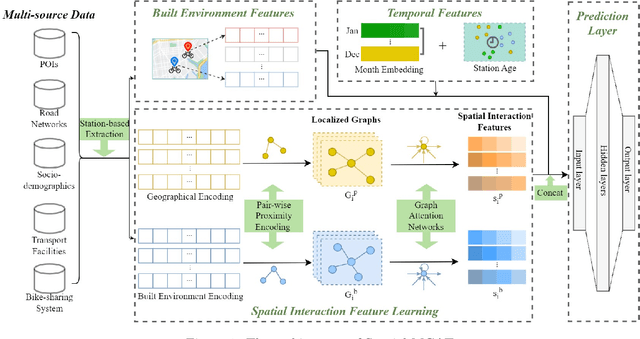
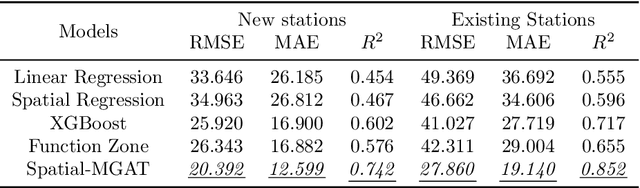
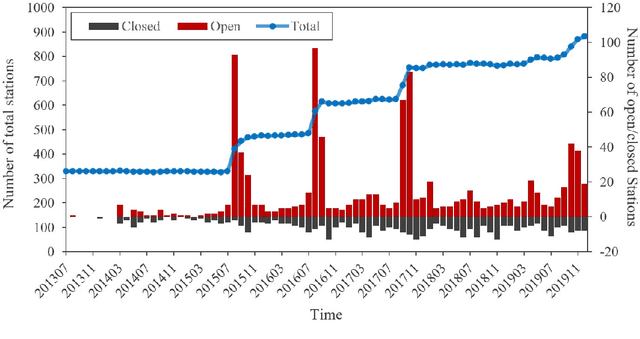
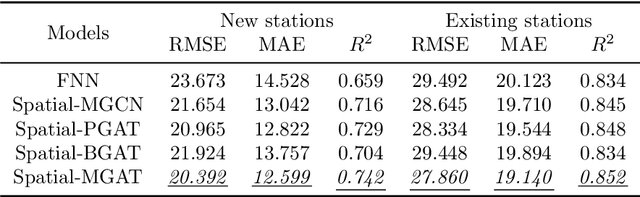
Bike sharing is emerging globally as an active, convenient, and sustainable mode of transportation. To plan successful bike-sharing systems (BSSs), many cities start from a small-scale pilot and gradually expand the system to cover more areas. For station-based BSSs, this means planning new stations based on existing ones over time, which requires prediction of the number of trips generated by these new stations across the whole system. Previous studies typically rely on relatively simple regression or machine learning models, which are limited in capturing complex spatial relationships. Despite the growing literature in deep learning methods for travel demand prediction, they are mostly developed for short-term prediction based on time series data, assuming no structural changes to the system. In this study, we focus on the trip generation problem for BSS expansion, and propose a graph neural network (GNN) approach to predicting the station-level demand based on multi-source urban built environment data. Specifically, it constructs multiple localized graphs centered on each target station and uses attention mechanisms to learn the correlation weights between stations. We further illustrate that the proposed approach can be regarded as a generalized spatial regression model, indicating the commonalities between spatial regression and GNNs. The model is evaluated based on realistic experiments using multi-year BSS data from New York City, and the results validate the superior performance of our approach compared to existing methods. We also demonstrate the interpretability of the model for uncovering the effects of built environment features and spatial interactions between stations, which can provide strategic guidance for BSS station location selection and capacity planning.
4D Panoptic Segmentation as Invariant and Equivariant Field Prediction
Mar 28, 2023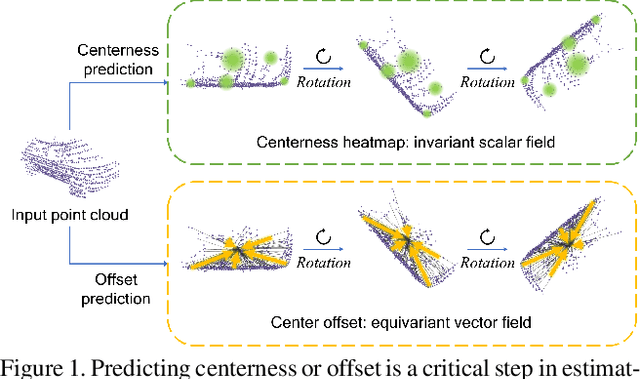
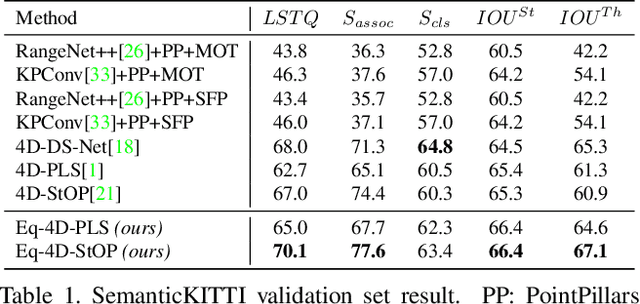
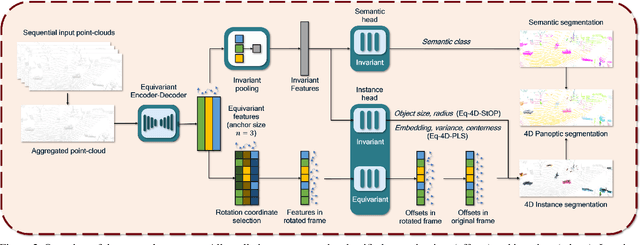
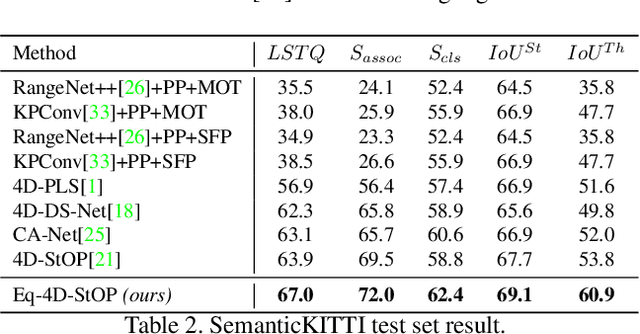
In this paper, we develop rotation-equivariant neural networks for 4D panoptic segmentation. 4D panoptic segmentation is a recently established benchmark task for autonomous driving, which requires recognizing semantic classes and object instances on the road based on LiDAR scans, as well as assigning temporally consistent IDs to instances across time. We observe that the driving scenario is symmetric to rotations on the ground plane. Therefore, rotation-equivariance could provide better generalization and more robust feature learning. Specifically, we review the object instance clustering strategies, and restate the centerness-based approach and the offset-based approach as the prediction of invariant scalar fields and equivariant vector fields. Other sub-tasks are also unified from this perspective, and different invariant and equivariant layers are designed to facilitate their predictions. Through evaluation on the standard 4D panoptic segmentation benchmark of SemanticKITTI, we show that our equivariant models achieve higher accuracy with lower computational costs compared to their non-equivariant counterparts. Moreover, our method sets the new state-of-the-art performance and achieves 1st place on the SemanticKITTI 4D Panoptic Segmentation leaderboard.
Deep Selection: A Fully Supervised Camera Selection Network for Surgery Recordings
Mar 28, 2023Recording surgery in operating rooms is an essential task for education and evaluation of medical treatment. However, recording the desired targets, such as the surgery field, surgical tools, or doctor's hands, is difficult because the targets are heavily occluded during surgery. We use a recording system in which multiple cameras are embedded in the surgical lamp, and we assume that at least one camera is recording the target without occlusion at any given time. As the embedded cameras obtain multiple video sequences, we address the task of selecting the camera with the best view of the surgery. Unlike the conventional method, which selects the camera based on the area size of the surgery field, we propose a deep neural network that predicts the camera selection probability from multiple video sequences by learning the supervision of the expert annotation. We created a dataset in which six different types of plastic surgery are recorded, and we provided the annotation of camera switching. Our experiments show that our approach successfully switched between cameras and outperformed three baseline methods.
Planning with Sequence Models through Iterative Energy Minimization
Mar 28, 2023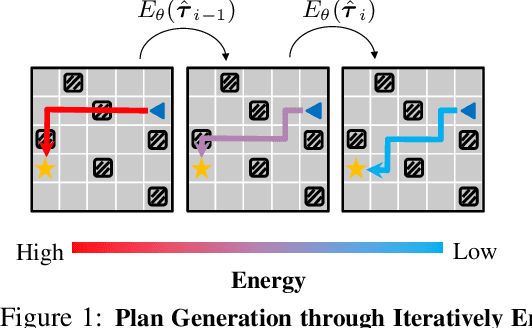
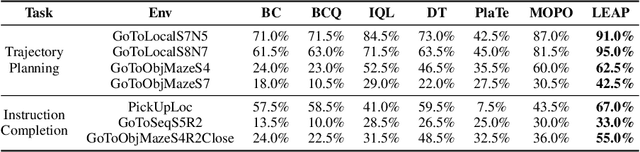
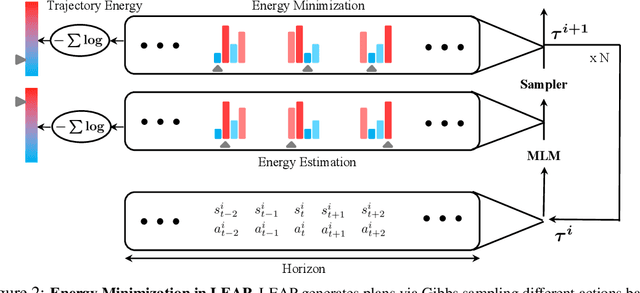
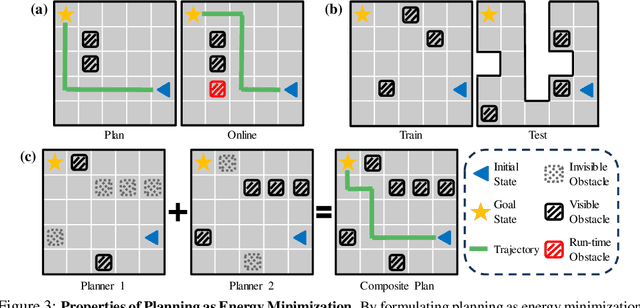
Recent works have shown that sequence modeling can be effectively used to train reinforcement learning (RL) policies. However, the success of applying existing sequence models to planning, in which we wish to obtain a trajectory of actions to reach some goal, is less straightforward. The typical autoregressive generation procedures of sequence models preclude sequential refinement of earlier steps, which limits the effectiveness of a predicted plan. In this paper, we suggest an approach towards integrating planning with sequence models based on the idea of iterative energy minimization, and illustrate how such a procedure leads to improved RL performance across different tasks. We train a masked language model to capture an implicit energy function over trajectories of actions, and formulate planning as finding a trajectory of actions with minimum energy. We illustrate how this procedure enables improved performance over recent approaches across BabyAI and Atari environments. We further demonstrate unique benefits of our iterative optimization procedure, involving new task generalization, test-time constraints adaptation, and the ability to compose plans together. Project website: https://hychen-naza.github.io/projects/LEAP
The Topology-Overlap Trade-Off in Retinal Arteriole-Venule Segmentation
Mar 31, 2023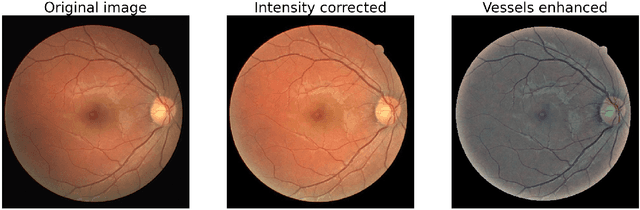
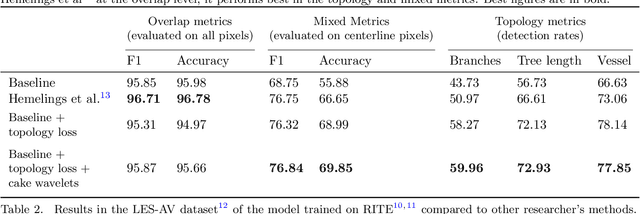
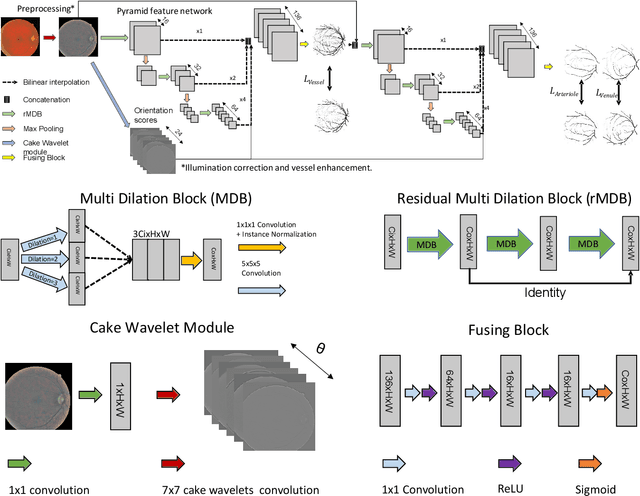

Retinal fundus images can be an invaluable diagnosis tool for screening epidemic diseases like hypertension or diabetes. And they become especially useful when the arterioles and venules they depict are clearly identified and annotated. However, manual annotation of these vessels is extremely time demanding and taxing, which calls for automatic segmentation. Although convolutional neural networks can achieve high overlap between predictions and expert annotations, they often fail to produce topologically correct predictions of tubular structures. This situation is exacerbated by the bifurcation versus crossing ambiguity which causes classification mistakes. This paper shows that including a topology preserving term in the loss function improves the continuity of the segmented vessels, although at the expense of artery-vein misclassification and overall lower overlap metrics. However, we show that by including an orientation score guided convolutional module, based on the anisotropic single sided cake wavelet, we reduce such misclassification and further increase the topology correctness of the results. We evaluate our model on public datasets with conveniently chosen metrics to assess both overlap and topology correctness, showing that our model is able to produce results on par with state-of-the-art from the point of view of overlap, while increasing topological accuracy.
A Benchmark Generative Probabilistic Model for Weak Supervised Learning
Mar 31, 2023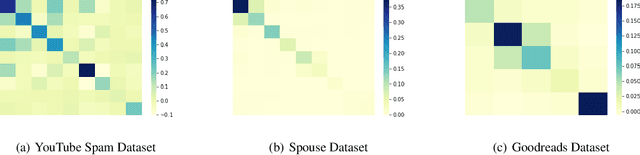
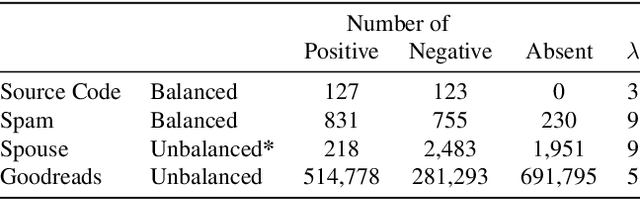
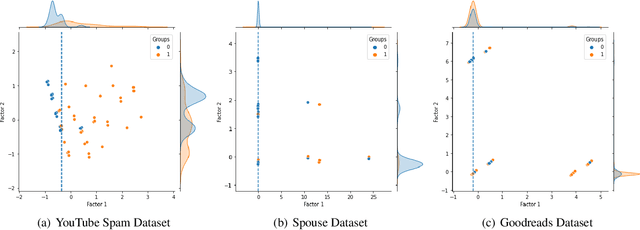
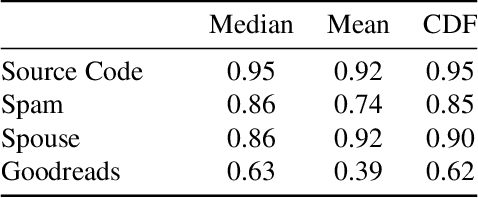
Finding relevant and high-quality datasets to train machine learning models is a major bottleneck for practitioners. Furthermore, to address ambitious real-world use-cases there is usually the requirement that the data come labelled with high-quality annotations that can facilitate the training of a supervised model. Manually labelling data with high-quality labels is generally a time-consuming and challenging task and often this turns out to be the bottleneck in a machine learning project. Weak Supervised Learning (WSL) approaches have been developed to alleviate the annotation burden by offering an automatic way of assigning approximate labels (pseudo-labels) to unlabelled data based on heuristics, distant supervision and knowledge bases. We apply probabilistic generative latent variable models (PLVMs), trained on heuristic labelling representations of the original dataset, as an accurate, fast and cost-effective way to generate pseudo-labels. We show that the PLVMs achieve state-of-the-art performance across four datasets. For example, they achieve 22% points higher F1 score than Snorkel in the class-imbalanced Spouse dataset. PLVMs are plug-and-playable and are a drop-in replacement to existing WSL frameworks (e.g. Snorkel) or they can be used as benchmark models for more complicated algorithms, giving practitioners a compelling accuracy boost.
Almost Linear Constant-Factor Sketching for $\ell_1$ and Logistic Regression
Mar 31, 2023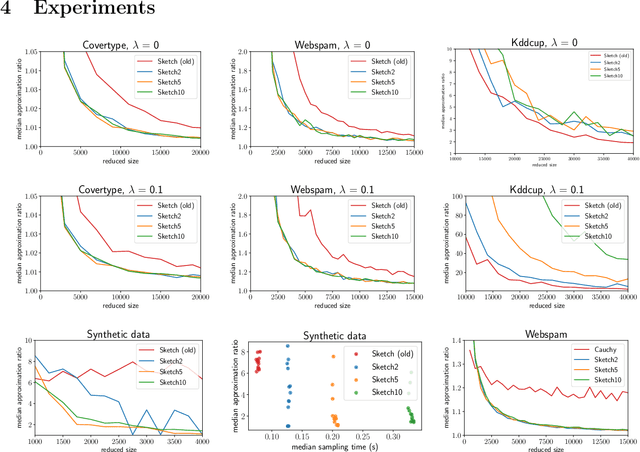

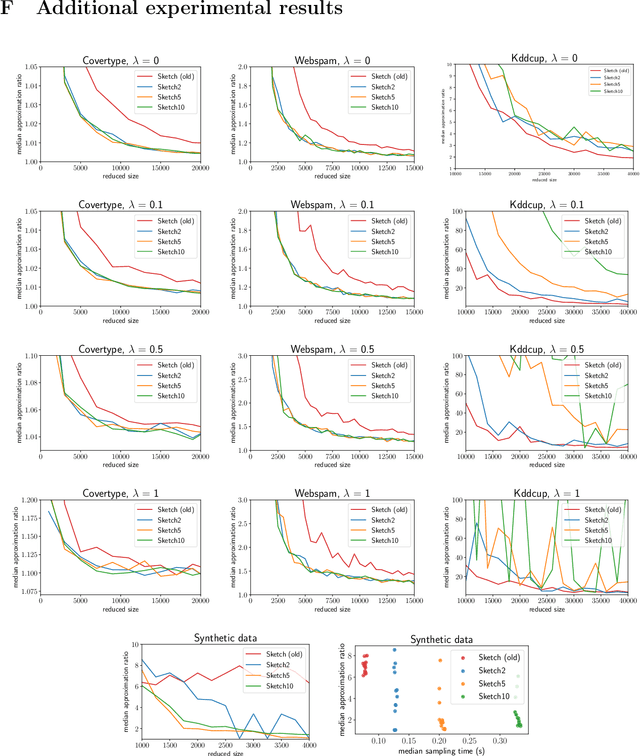
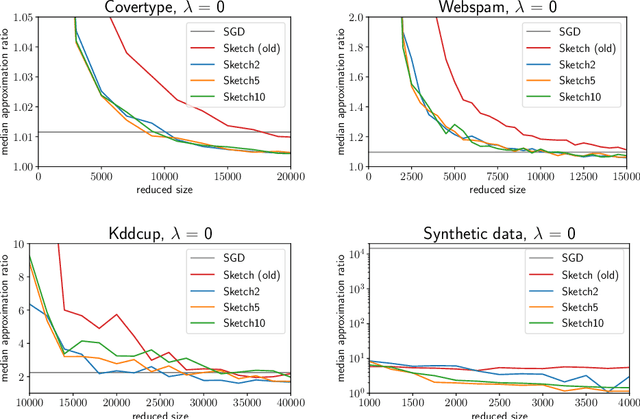
We improve upon previous oblivious sketching and turnstile streaming results for $\ell_1$ and logistic regression, giving a much smaller sketching dimension achieving $O(1)$-approximation and yielding an efficient optimization problem in the sketch space. Namely, we achieve for any constant $c>0$ a sketching dimension of $\tilde{O}(d^{1+c})$ for $\ell_1$ regression and $\tilde{O}(\mu d^{1+c})$ for logistic regression, where $\mu$ is a standard measure that captures the complexity of compressing the data. For $\ell_1$-regression our sketching dimension is near-linear and improves previous work which either required $\Omega(\log d)$-approximation with this sketching dimension, or required a larger $\operatorname{poly}(d)$ number of rows. Similarly, for logistic regression previous work had worse $\operatorname{poly}(\mu d)$ factors in its sketching dimension. We also give a tradeoff that yields a $1+\varepsilon$ approximation in input sparsity time by increasing the total size to $(d\log(n)/\varepsilon)^{O(1/\varepsilon)}$ for $\ell_1$ and to $(\mu d\log(n)/\varepsilon)^{O(1/\varepsilon)}$ for logistic regression. Finally, we show that our sketch can be extended to approximate a regularized version of logistic regression where the data-dependent regularizer corresponds to the variance of the individual logistic losses.