 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MTSMAE: Masked Autoencoders for Multivariate Time-Series Forecasting
Oct 04, 2022
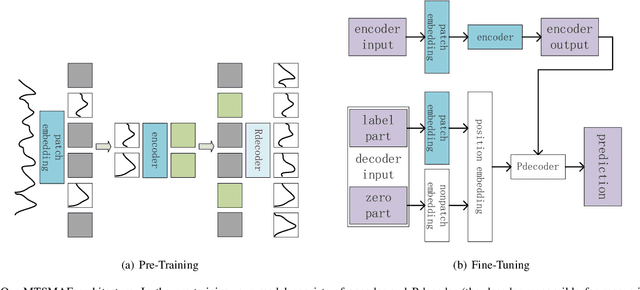
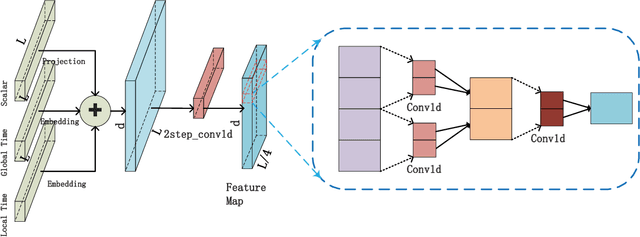
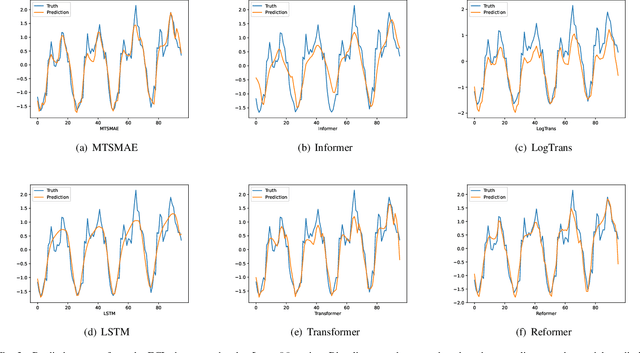
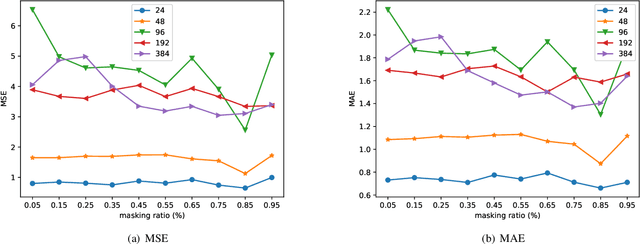
Large-scale self-supervised pre-training Transformer architecture have significantly boosted the performance for various tasks in natural language processing (NLP) and computer vision (CV). However, there is a lack of researches on processing multivariate time-series by pre-trained Transformer, and especially, current study on masking time-series for self-supervised learning is still a gap. Different from language and image processing, the information density of time-series increases the difficulty of research. The challenge goes further with the invalidity of the previous patch embedding and mask methods. In this paper, according to the data characteristics of multivariate time-series, a patch embedding method is proposed, and we present an self-supervised pre-training approach based on Masked Autoencoders (MAE), called MTSMAE, which can improve the performance significantly over supervised learning without pre-training. Evaluating our method on several common multivariate time-series datasets from different fields and with different characteristics, experiment results demonstrate that the performance of our method is significantly better than the best method currently available.
Hospital Length of Stay Prediction Based on Multi-modal Data towards Trustworthy Human-AI Collaboration in Radiomics
Mar 17, 2023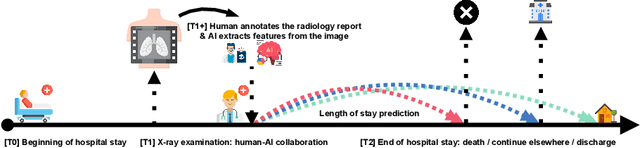
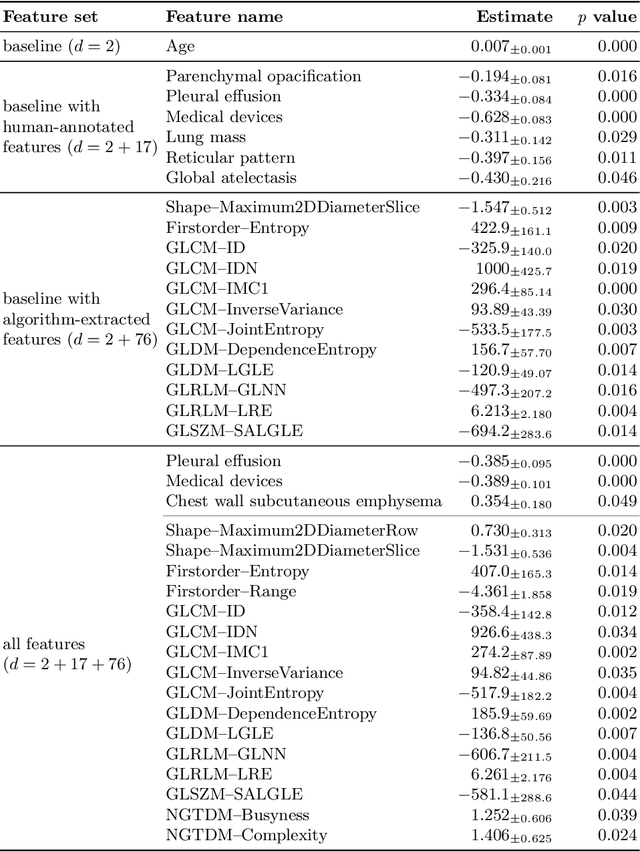
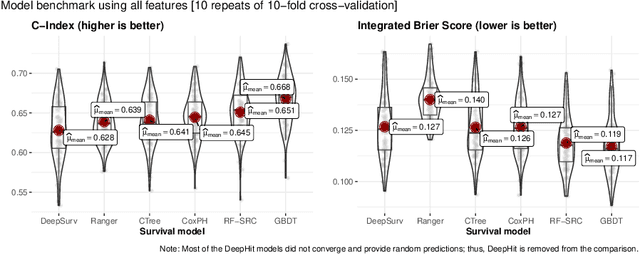
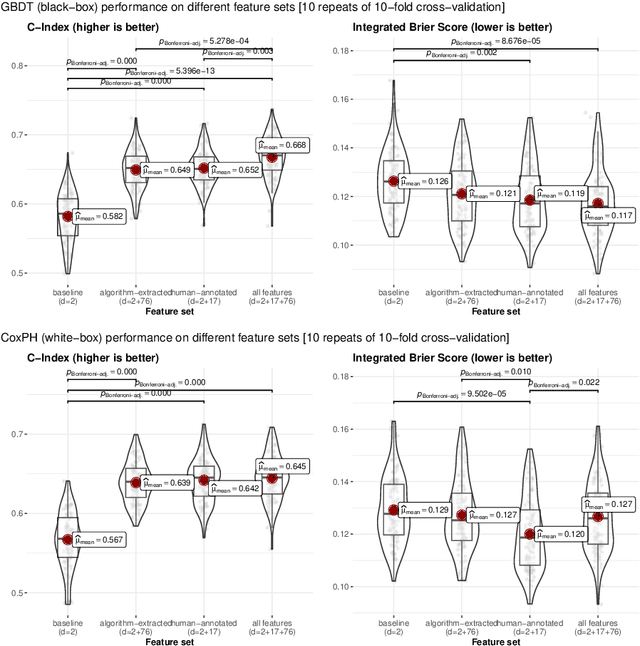
To what extent can the patient's length of stay in a hospital be predicted using only an X-ray image? We answer this question by comparing the performance of machine learning survival models on a novel multi-modal dataset created from 1235 images with textual radiology reports annotated by humans. Although black-box models predict better on average than interpretable ones, like Cox proportional hazards, they are not inherently understandable. To overcome this trust issue, we introduce time-dependent model explanations into the human-AI decision making process. Explaining models built on both: human-annotated and algorithm-extracted radiomics features provides valuable insights for physicians working in a hospital. We believe the presented approach to be general and widely applicable to other time-to-event medical use cases. For reproducibility, we open-source code and the TLOS dataset at https://github.com/mi2datalab/xlungs-trustworthy-los-prediction.
MusicFace: Music-driven Expressive Singing Face Synthesis
Mar 24, 2023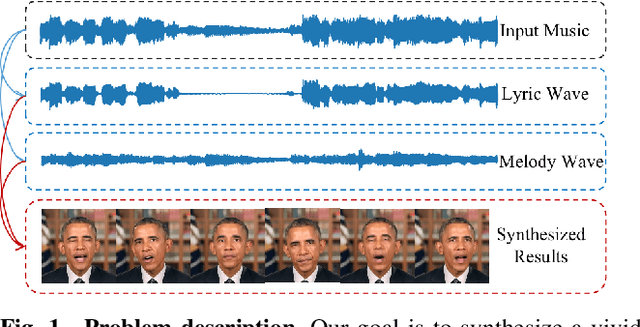
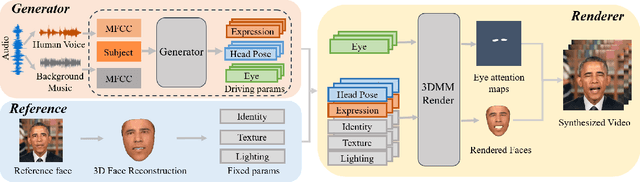

It is still an interesting and challenging problem to synthesize a vivid and realistic singing face driven by music signal. In this paper, we present a method for this task with natural motions of the lip, facial expression, head pose, and eye states. Due to the coupling of the mixed information of human voice and background music in common signals of music audio, we design a decouple-and-fuse strategy to tackle the challenge. We first decompose the input music audio into human voice stream and background music stream. Due to the implicit and complicated correlation between the two-stream input signals and the dynamics of the facial expressions, head motions and eye states, we model their relationship with an attention scheme, where the effects of the two streams are fused seamlessly. Furthermore, to improve the expressiveness of the generated results, we propose to decompose head movements generation into speed generation and direction generation, and decompose eye states generation into the short-time eye blinking generation and the long-time eye closing generation to model them separately. We also build a novel SingingFace Dataset to support the training and evaluation of this task, and to facilitate future works on this topic. Extensive experiments and user study show that our proposed method is capable of synthesizing vivid singing face, which is better than state-of-the-art methods qualitatively and quantitatively.
Koopman Neural Forecaster for Time Series with Temporal Distribution Shifts
Oct 10, 2022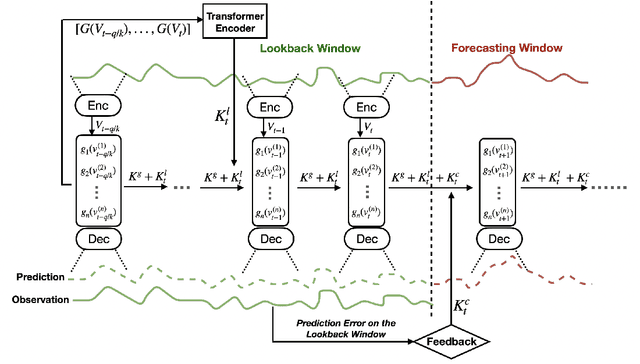

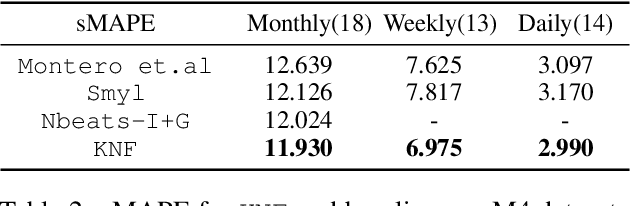
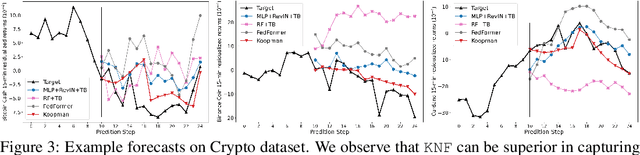
Temporal distributional shifts, with underlying dynamics changing over time, frequently occur in real-world time series, and pose a fundamental challenge for deep neural networks (DNNs). In this paper, we propose a novel deep sequence model based on the Koopman theory for time series forecasting: Koopman Neural Forecaster (KNF) that leverages DNNs to learn the linear Koopman space and the coefficients of chosen measurement functions. KNF imposes appropriate inductive biases for improved robustness against distributional shifts, employing both a global operator to learn shared characteristics, and a local operator to capture changing dynamics, as well as a specially-designed feedback loop to continuously update the learnt operators over time for rapidly varying behaviors. To the best of our knowledge, this is the first time that Koopman theory is applied to real-world chaotic time series without known governing laws. We demonstrate that KNF achieves the superior performance compared to the alternatives, on multiple time series datasets that are shown to suffer from distribution shifts.
Bringing Telepresence to Every Desk
Apr 03, 2023
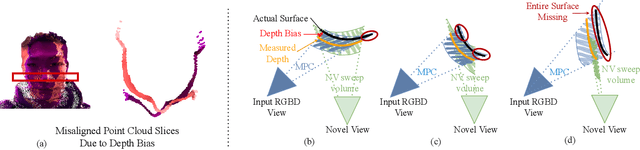

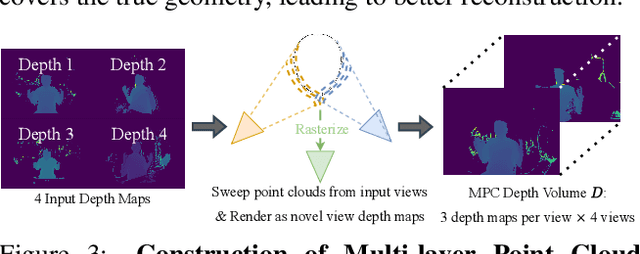
In this paper, we work to bring telepresence to every desktop. Unlike commercial systems, personal 3D video conferencing systems must render high-quality videos while remaining financially and computationally viable for the average consumer. To this end, we introduce a capturing and rendering system that only requires 4 consumer-grade RGBD cameras and synthesizes high-quality free-viewpoint videos of users as well as their environments. Experimental results show that our system renders high-quality free-viewpoint videos without using object templates or heavy pre-processing. While not real-time, our system is fast and does not require per-video optimizations. Moreover, our system is robust to complex hand gestures and clothing, and it can generalize to new users. This work provides a strong basis for further optimization, and it will help bring telepresence to every desk in the near future. The code and dataset will be made available on our website https://mcmvmc.github.io/PersonalTelepresence/.
Imitation Learning from Nonlinear MPC via the Exact Q-Loss and its Gauss-Newton Approximation
Apr 03, 2023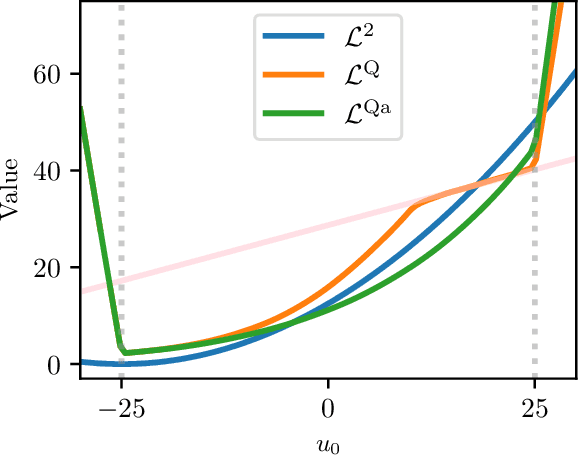
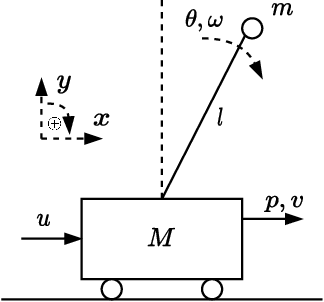
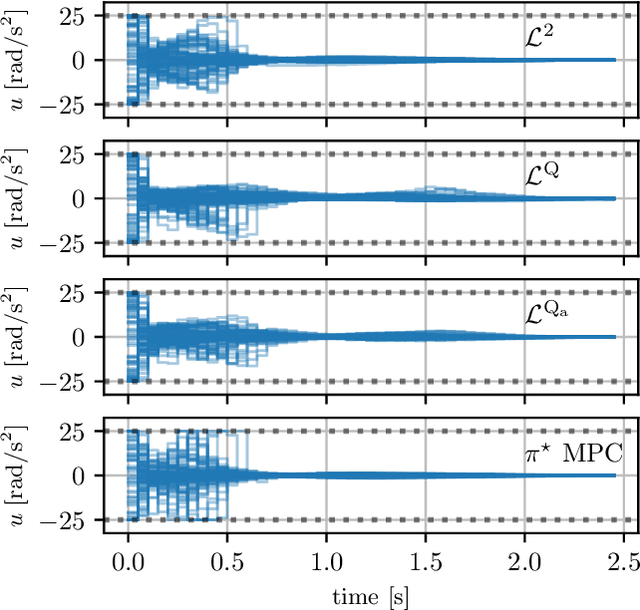
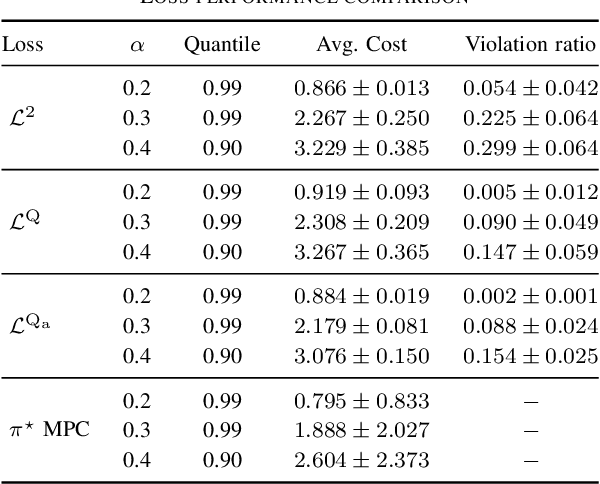
This work presents a novel loss function for learning nonlinear Model Predictive Control policies via Imitation Learning. Standard approaches to Imitation Learning neglect information about the expert and generally adopt a loss function based on the distance between expert and learned controls. In this work, we present a loss based on the Q-function directly embedding the performance objectives and constraint satisfaction of the associated Optimal Control Problem (OCP). However, training a Neural Network with the Q-loss requires solving the associated OCP for each new sample. To alleviate the computational burden, we derive a second Q-loss based on the Gauss-Newton approximation of the OCP resulting in a faster training time. We validate our losses against Behavioral Cloning, the standard approach to Imitation Learning, on the control of a nonlinear system with constraints. The final results show that the Q-function-based losses significantly reduce the amount of constraint violations while achieving comparable or better closed-loop costs.
Bubble Explorer: Fast UAV Exploration in Large-Scale and Cluttered 3D-Environments using Occlusion-Free Spheres
Apr 03, 2023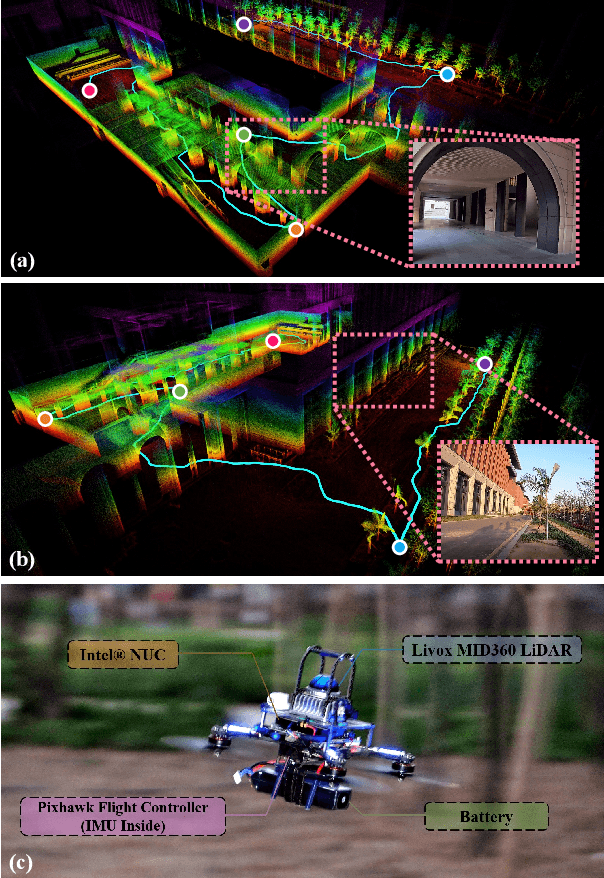
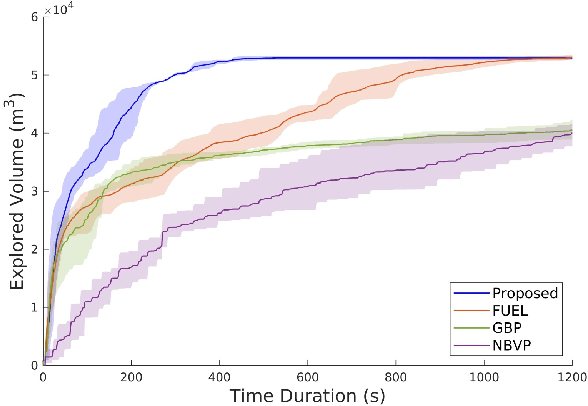

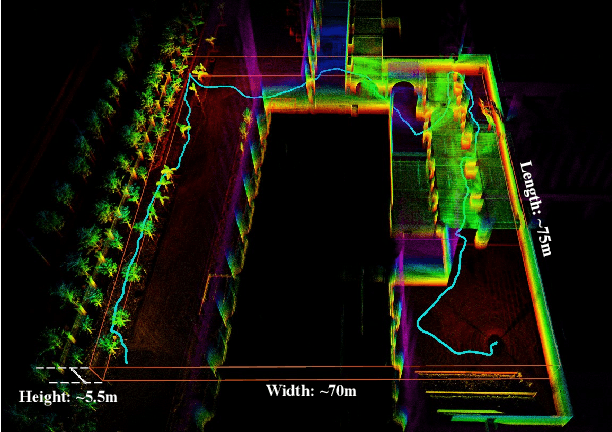
Autonomous exploration is a crucial aspect of robotics that has numerous applications. Most of the existing methods greedily choose goals that maximize immediate reward. This strategy is computationally efficient but insufficient for overall exploration efficiency. In recent years, some state-of-the-art methods are proposed, which generate a global coverage path and significantly improve overall exploration efficiency. However, global optimization produces high computational overhead, leading to low-frequency planner updates and inconsistent planning motion. In this work, we propose a novel method to support fast UAV exploration in large-scale and cluttered 3-D environments. We introduce a computationally low-cost viewpoints generation method using novel occlusion-free spheres. Additionally, we combine greedy strategy with global optimization, which considers both computational and exploration efficiency. We benchmark our method against state-of-the-art methods to showcase its superiority in terms of exploration efficiency and computational time. We conduct various real-world experiments to demonstrate the excellent performance of our method in large-scale and cluttered environments.
Properties and Potential Applications of Random Functional-Linked Types of Neural Networks
Apr 03, 2023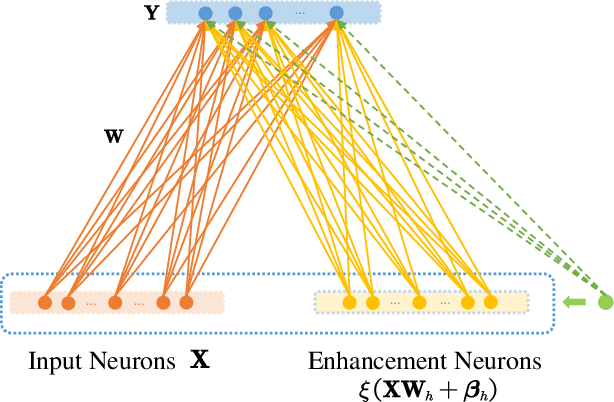
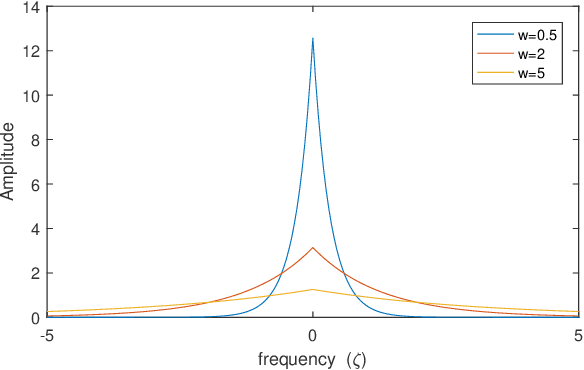
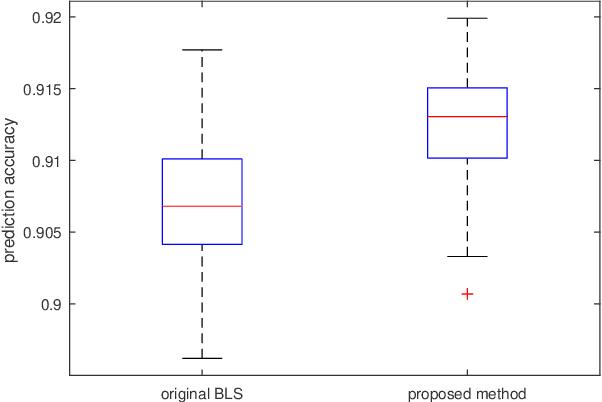
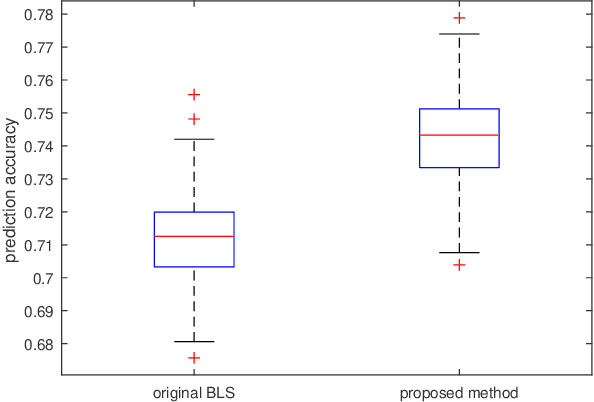
Random functional-linked types of neural networks (RFLNNs), e.g., the extreme learning machine (ELM) and broad learning system (BLS), which avoid suffering from a time-consuming training process, offer an alternative way of learning in deep structure. The RFLNNs have achieved excellent performance in various classification and regression tasks, however, the properties and explanations of these networks are ignored in previous research. This paper gives some insights into the properties of RFLNNs from the viewpoints of frequency domain, and discovers the presence of frequency principle in these networks, that is, they preferentially capture low-frequencies quickly and then fit the high frequency components during the training process. These findings are valuable for understanding the RFLNNs and expanding their applications. Guided by the frequency principle, we propose a method to generate a BLS network with better performance, and design an efficient algorithm for solving Poison's equation in view of the different frequency principle presenting in the Jacobi iterative method and BLS network.
DrBERT: A Robust Pre-trained Model in French for Biomedical and Clinical domains
Apr 03, 2023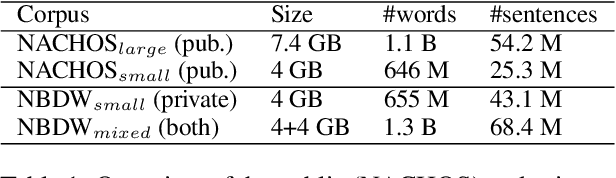
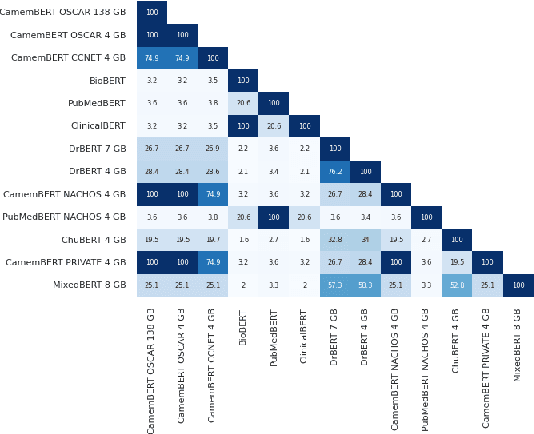

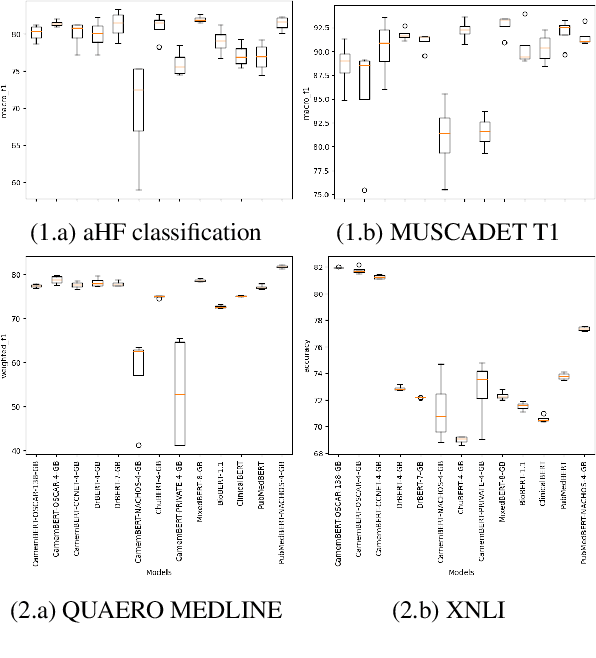
In recent years, pre-trained language models (PLMs) achieve the best performance on a wide range of natural language processing (NLP) tasks. While the first models were trained on general domain data, specialized ones have emerged to more effectively treat specific domains. In this paper, we propose an original study of PLMs in the medical domain on French language. We compare, for the first time, the performance of PLMs trained on both public data from the web and private data from healthcare establishments. We also evaluate different learning strategies on a set of biomedical tasks. In particular, we show that we can take advantage of already existing biomedical PLMs in a foreign language by further pre-train it on our targeted data. Finally, we release the first specialized PLMs for the biomedical field in French, called DrBERT, as well as the largest corpus of medical data under free license on which these models are trained.
Role of Transients in Two-Bounce Non-Line-of-Sight Imaging
Apr 03, 2023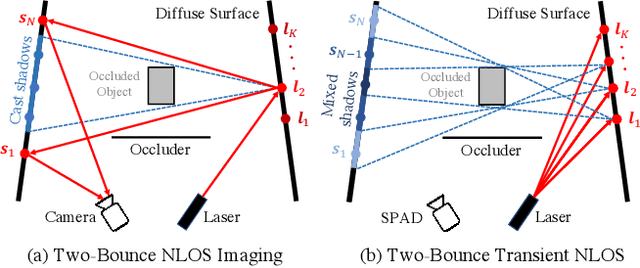
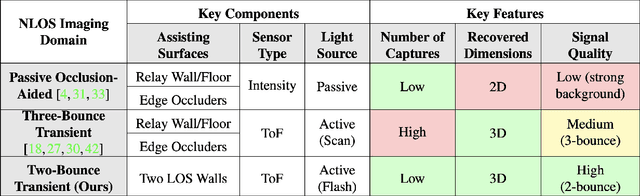
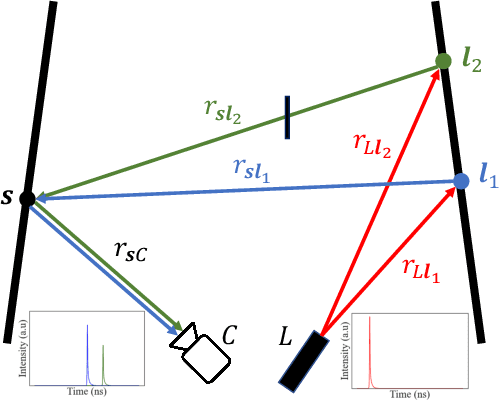
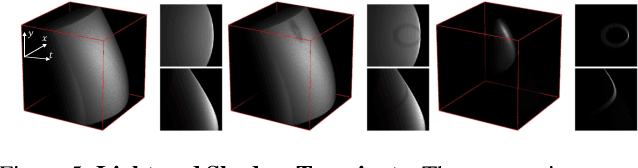
The goal of non-line-of-sight (NLOS) imaging is to image objects occluded from the camera's field of view using multiply scattered light. Recent works have demonstrated the feasibility of two-bounce (2B) NLOS imaging by scanning a laser and measuring cast shadows of occluded objects in scenes with two relay surfaces. In this work, we study the role of time-of-flight (ToF) measurements, \ie transients, in 2B-NLOS under multiplexed illumination. Specifically, we study how ToF information can reduce the number of measurements and spatial resolution needed for shape reconstruction. We present our findings with respect to tradeoffs in (1) temporal resolution, (2) spatial resolution, and (3) number of image captures by studying SNR and recoverability as functions of system parameters. This leads to a formal definition of the mathematical constraints for 2B lidar. We believe that our work lays an analytical groundwork for design of future NLOS imaging systems, especially as ToF sensors become increasingly ubiquitous.