 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
REDf: A Renewable Energy Demand Forecasting Model for Smart Grids using Long Short Term Memory Network
Apr 08, 2023
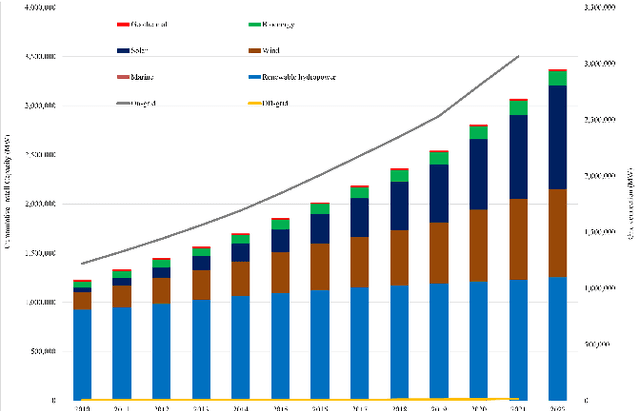
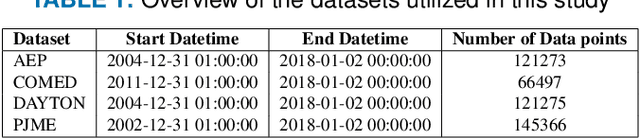
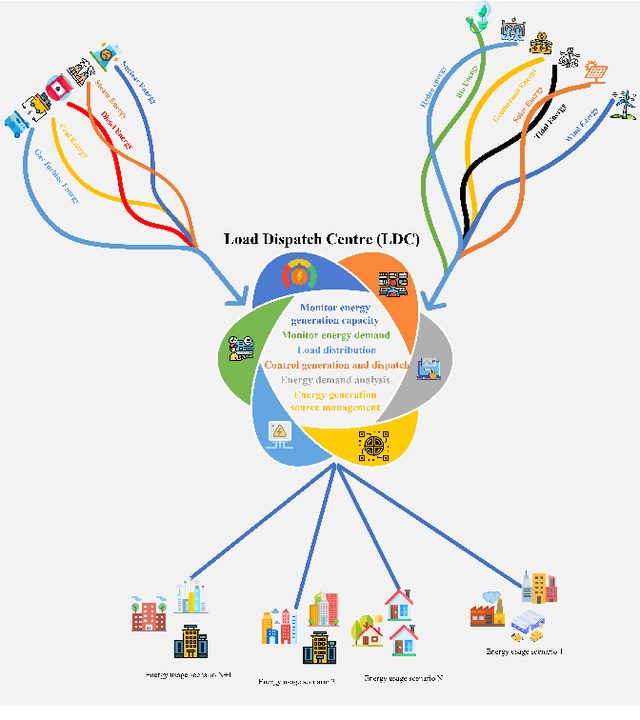
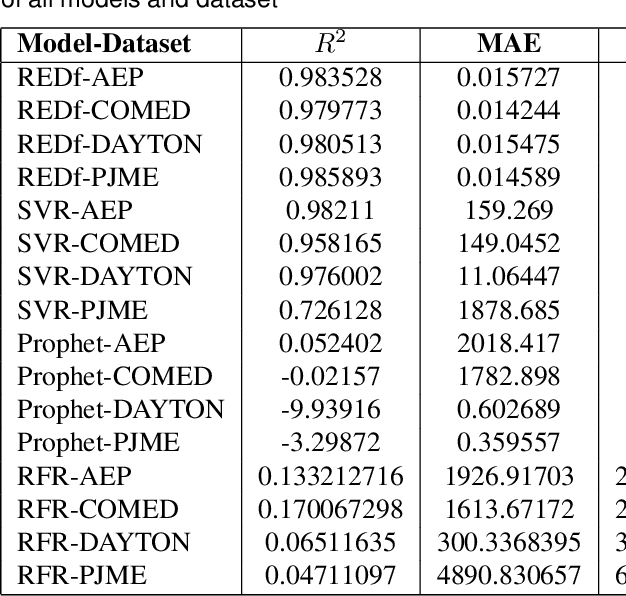
The integration of renewable energy sources into the power grid is becoming increasingly important as the world moves towards a more sustainable energy future. However, the intermittent nature of renewable energy sources can make it challenging to manage the power grid and ensure a stable supply of electricity. In this paper, we propose a deep learning-based approach for predicting energy demand in a smart power grid, which can improve the integration of renewable energy sources by providing accurate predictions of energy demand. We use long short-term memory networks, which are well-suited for time series data, to capture complex patterns and dependencies in energy demand data. The proposed approach is evaluated using four datasets of historical energy demand data from different energy distribution companies including American Electric Power, Commonwealth Edison, Dayton Power and Light, and Pennsylvania-New Jersey-Maryland Interconnection. The proposed model is also compared with two other state of the art forecasting algorithms namely, Facebook Prophet and Support Vector Regressor. The experimental results show that the proposed REDf model can accurately predict energy demand with a mean absolute error of 1.4%. This approach has the potential to improve the efficiency and stability of the power grid by allowing for better management of the integration of renewable energy sources.
A Recommender System Approach for Very Large-scale Multiobjective Optimization
Apr 08, 2023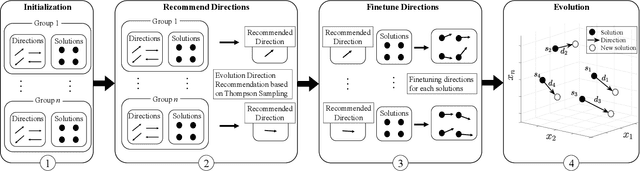
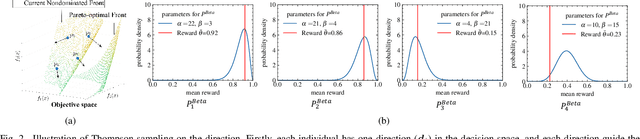
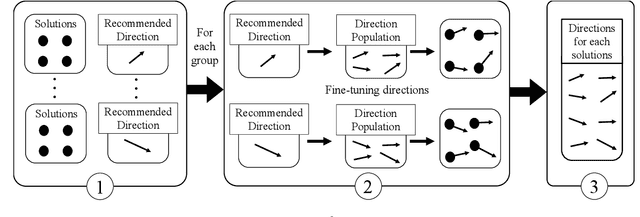
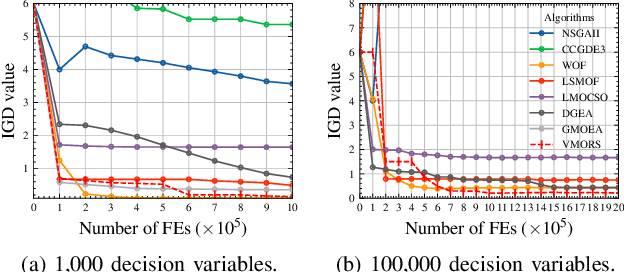
We define very large multi-objective optimization problems to be multiobjective optimization problems in which the number of decision variables is greater than 100,000 dimensions. This is an important class of problems as many real-world problems require optimizing hundreds of thousands of variables. Existing evolutionary optimization methods fall short of such requirements when dealing with problems at this very large scale. Inspired by the success of existing recommender systems to handle very large-scale items with limited historical interactions, in this paper we propose a method termed Very large-scale Multiobjective Optimization through Recommender Systems (VMORS). The idea of the proposed method is to transform the defined such very large-scale problems into a problem that can be tackled by a recommender system. In the framework, the solutions are regarded as users, and the different evolution directions are items waiting for the recommendation. We use Thompson sampling to recommend the most suitable items (evolutionary directions) for different users (solutions), in order to locate the optimal solution to a multiobjective optimization problem in a very large search space within acceptable time. We test our proposed method on different problems from 100,000 to 500,000 dimensions, and experimental results show that our method not only shows good performance but also significant improvement over existing methods.
Evolving Reinforcement Learning Environment to Minimize Learner's Achievable Reward: An Application on Hardening Active Directory Systems
Apr 08, 2023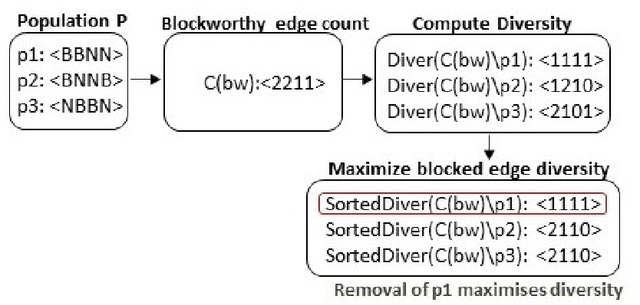
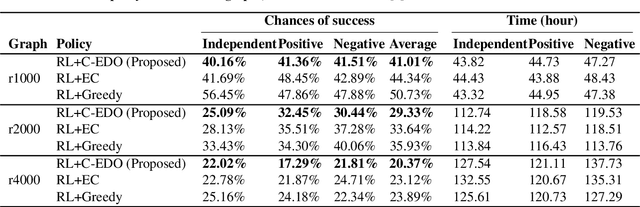
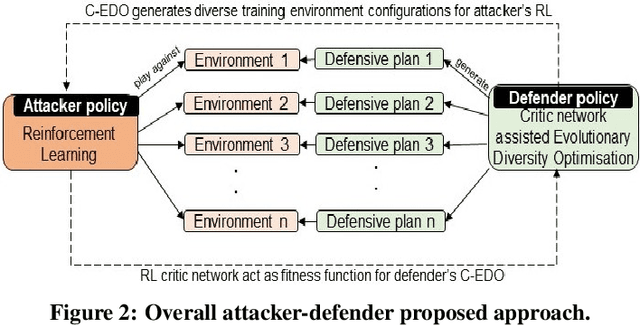
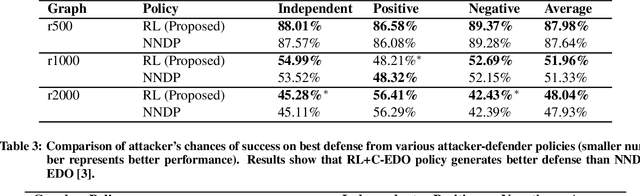
We study a Stackelberg game between one attacker and one defender in a configurable environment. The defender picks a specific environment configuration. The attacker observes the configuration and attacks via Reinforcement Learning (RL trained against the observed environment). The defender's goal is to find the environment with minimum achievable reward for the attacker. We apply Evolutionary Diversity Optimization (EDO) to generate diverse population of environments for training. Environments with clearly high rewards are killed off and replaced by new offsprings to avoid wasting training time. Diversity not only improves training quality but also fits well with our RL scenario: RL agents tend to improve gradually, so a slightly worse environment earlier on may become better later. We demonstrate the effectiveness of our approach by focusing on a specific application, Active Directory (AD). AD is the default security management system for Windows domain networks. AD environment describes an attack graph, where nodes represent computers/accounts/etc., and edges represent accesses. The attacker aims to find the best attack path to reach the highest-privilege node. The defender can change the graph by removing a limited number of edges (revoke accesses). Our approach generates better defensive plans than the existing approach and scales better.
HigeNet: A Highly Efficient Modeling for Long Sequence Time Series Prediction in AIOps
Nov 13, 2022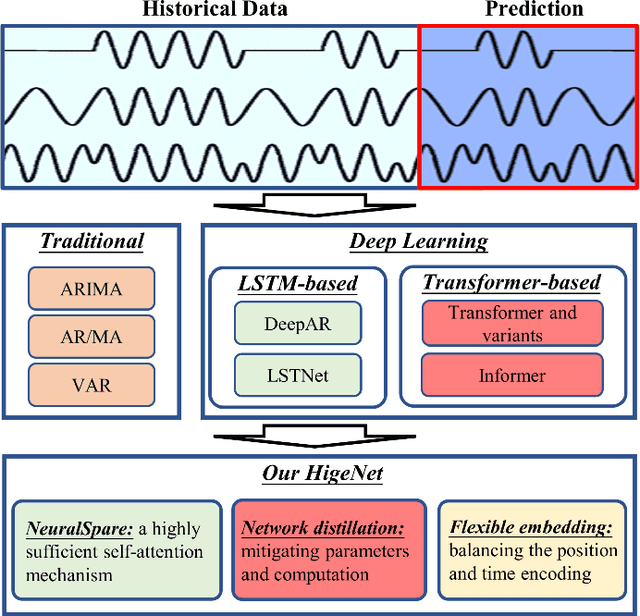
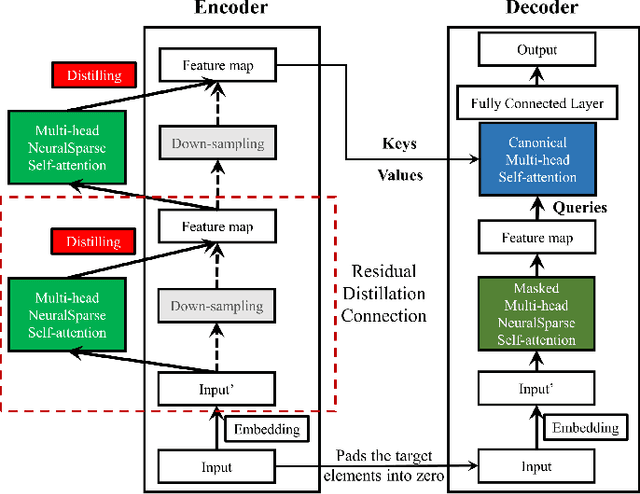
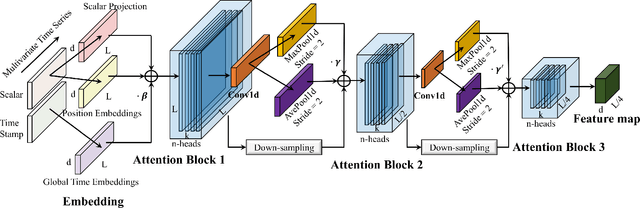
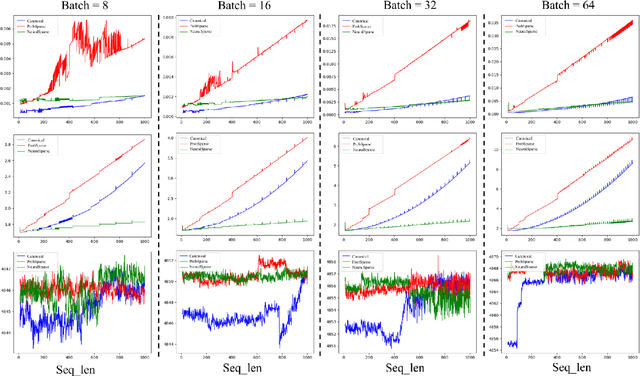
Modern IT system operation demands the integration of system software and hardware metrics. As a result, it generates a massive amount of data, which can be potentially used to make data-driven operational decisions. In the basic form, the decision model needs to monitor a large set of machine data, such as CPU utilization, allocated memory, disk and network latency, and predicts the system metrics to prevent performance degradation. Nevertheless, building an effective prediction model in this scenario is rather challenging as the model has to accurately capture the long-range coupling dependency in the Multivariate Time-Series (MTS). Moreover, this model needs to have low computational complexity and can scale efficiently to the dimension of data available. In this paper, we propose a highly efficient model named HigeNet to predict the long-time sequence time series. We have deployed the HigeNet on production in the D-matrix platform. We also provide offline evaluations on several publicly available datasets as well as one online dataset to demonstrate the model's efficacy. The extensive experiments show that training time, resource usage and accuracy of the model are found to be significantly better than five state-of-the-art competing models.
Depression Diagnosis and Drug Response Prediction via Recurrent Neural Networks and Transformers Utilizing EEG Signals
Mar 09, 2023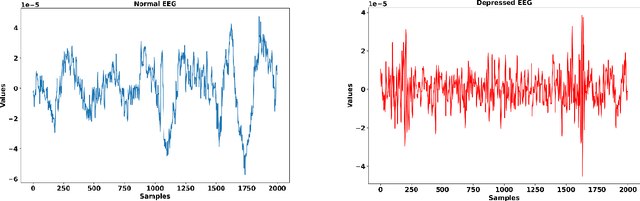

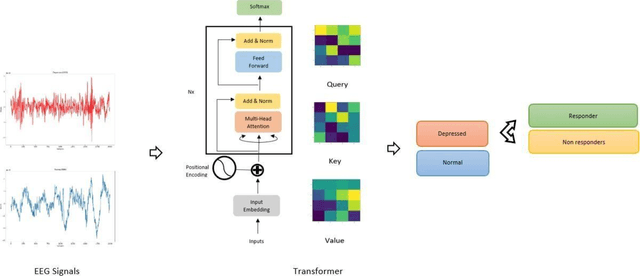

The Early diagnosis and treatment of depression is essential for effective treatment. Depression, while being one of the most common mental illnesses, is still poorly understood in both research and clinical practice. Among different treatments, drug prescription is widely used, however the drug treatment is not effective for many patients. In this work, we propose a method for major depressive disorder (MDD) diagnosis as well as a method for predicting the drug response in patient with MDD using EEG signals. Method: We employ transformers, which are modified recursive neural networks with novel architecture to evaluate the time dependency of time series effectively. We also compare the model to the well-known deep learning schemes such as CNN, LSTM and CNN-LSTM. Results: The transformer achieves an average recall of 99.41% and accuracy of 97.14% for classifying normal and MDD subjects. Furthermore, the transformer also performed well in classifying responders and non-responders to the drug, resulting in 97.01% accuracy and 97.76% Recall. Conclusion: Outperforming other methods on a similar number of parameters, the suggested technique, as a screening tool, seems to have the potential to assist health care professionals in assessing MDD patients for early diagnosis and treatment. Significance: Analyzing EEG signal analysis using transformers, which have replaced the recursive models as a new structure to examine the time dependence of time series, is the main novelty of this research.
Invariant preservation in machine learned PDE solvers via error correction
Mar 29, 2023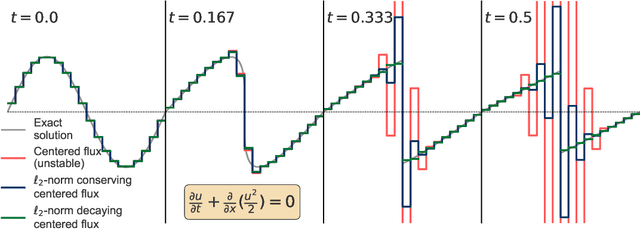
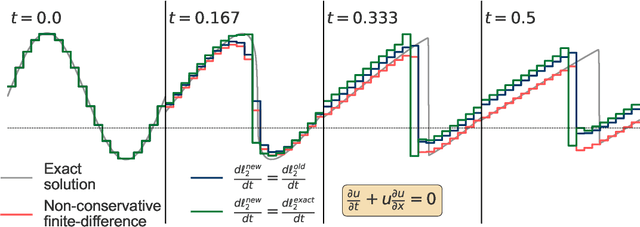
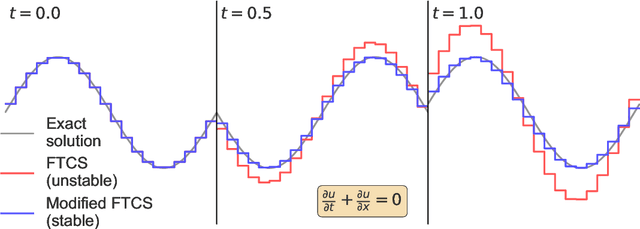
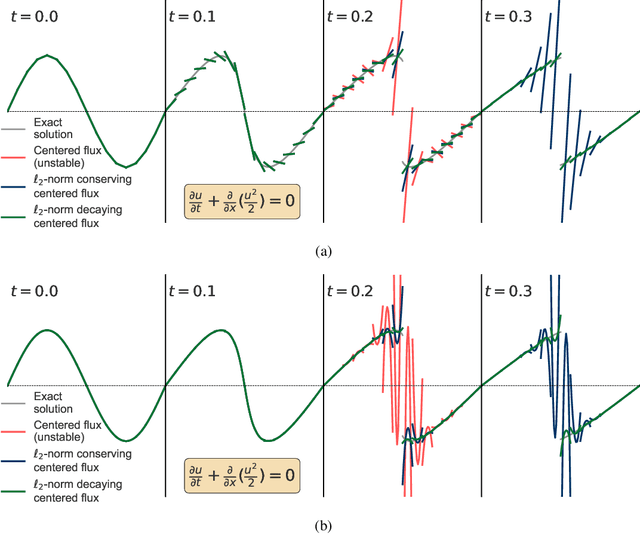
Machine learned partial differential equation (PDE) solvers trade the reliability of standard numerical methods for potential gains in accuracy and/or speed. The only way for a solver to guarantee that it outputs the exact solution is to use a convergent method in the limit that the grid spacing $\Delta x$ and timestep $\Delta t$ approach zero. Machine learned solvers, which learn to update the solution at large $\Delta x$ and/or $\Delta t$, can never guarantee perfect accuracy. Some amount of error is inevitable, so the question becomes: how do we constrain machine learned solvers to give us the sorts of errors that we are willing to tolerate? In this paper, we design more reliable machine learned PDE solvers by preserving discrete analogues of the continuous invariants of the underlying PDE. Examples of such invariants include conservation of mass, conservation of energy, the second law of thermodynamics, and/or non-negative density. Our key insight is simple: to preserve invariants, at each timestep apply an error-correcting algorithm to the update rule. Though this strategy is different from how standard solvers preserve invariants, it is necessary to retain the flexibility that allows machine learned solvers to be accurate at large $\Delta x$ and/or $\Delta t$. This strategy can be applied to any autoregressive solver for any time-dependent PDE in arbitrary geometries with arbitrary boundary conditions. Although this strategy is very general, the specific error-correcting algorithms need to be tailored to the invariants of the underlying equations as well as to the solution representation and time-stepping scheme of the solver. The error-correcting algorithms we introduce have two key properties. First, by preserving the right invariants they guarantee numerical stability. Second, in closed or periodic systems they do so without degrading the accuracy of an already-accurate solver.
The DOPE Distance is SIC: A Stable, Informative, and Computable Metric on Time Series And Ordered Merge Trees
Dec 03, 2022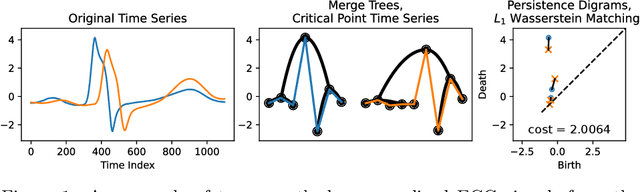
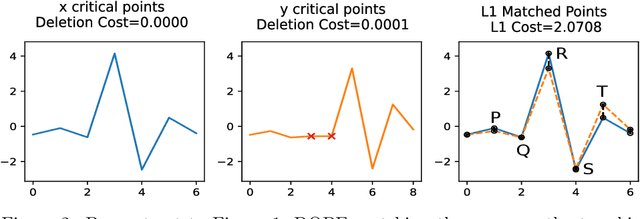
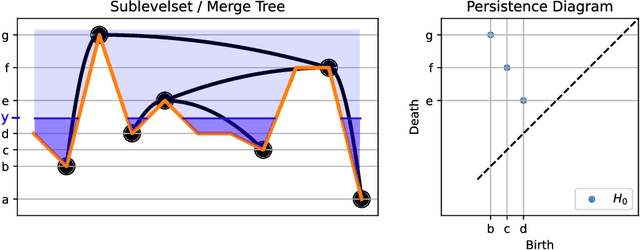
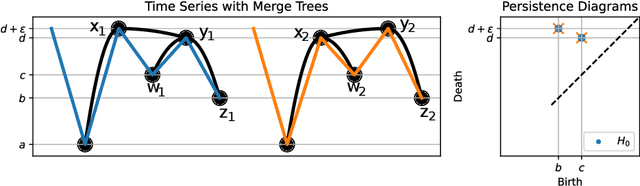
Metrics for merge trees that are simultaneously stable, informative, and efficiently computable have so far eluded researchers. We show in this work that it is possible to devise such a metric when restricting merge trees to ordered domains such as the interval and the circle. We present the ``dynamic ordered persistence editing'' (DOPE) distance, which we prove is stable and informative while satisfying metric properties. We then devise a simple $O(N^2)$ dynamic programming algorithm to compute it on the interval and an $O(N^3)$ algorithm to compute it on the circle. Surprisingly, we accomplish this by ignoring all of the hierarchical information of the merge tree and simply focusing on a sequence of ordered critical points, which can be interpreted as a time series. Thus our algorithm is more similar to string edit distance and dynamic time warping than it is to more conventional merge tree comparison algorithms. In the context of time series with the interval as a domain, we show empirically on the UCR time series classification dataset that DOPE performs better than bottleneck/Wasserstein distances between persistence diagrams.
MusicFace: Music-driven Expressive Singing Face Synthesis
Mar 24, 2023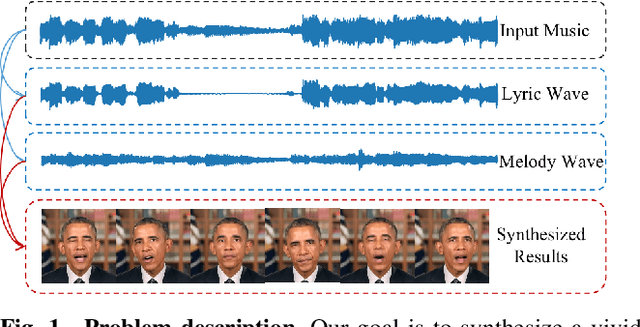
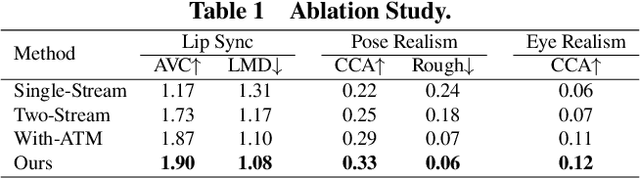
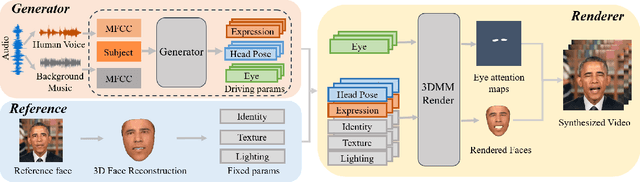

It is still an interesting and challenging problem to synthesize a vivid and realistic singing face driven by music signal. In this paper, we present a method for this task with natural motions of the lip, facial expression, head pose, and eye states. Due to the coupling of the mixed information of human voice and background music in common signals of music audio, we design a decouple-and-fuse strategy to tackle the challenge. We first decompose the input music audio into human voice stream and background music stream. Due to the implicit and complicated correlation between the two-stream input signals and the dynamics of the facial expressions, head motions and eye states, we model their relationship with an attention scheme, where the effects of the two streams are fused seamlessly. Furthermore, to improve the expressiveness of the generated results, we propose to decompose head movements generation into speed generation and direction generation, and decompose eye states generation into the short-time eye blinking generation and the long-time eye closing generation to model them separately. We also build a novel SingingFace Dataset to support the training and evaluation of this task, and to facilitate future works on this topic. Extensive experiments and user study show that our proposed method is capable of synthesizing vivid singing face, which is better than state-of-the-art methods qualitatively and quantitatively.
Hospital Length of Stay Prediction Based on Multi-modal Data towards Trustworthy Human-AI Collaboration in Radiomics
Mar 17, 2023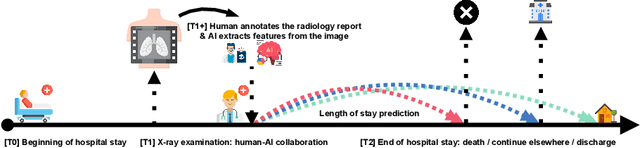
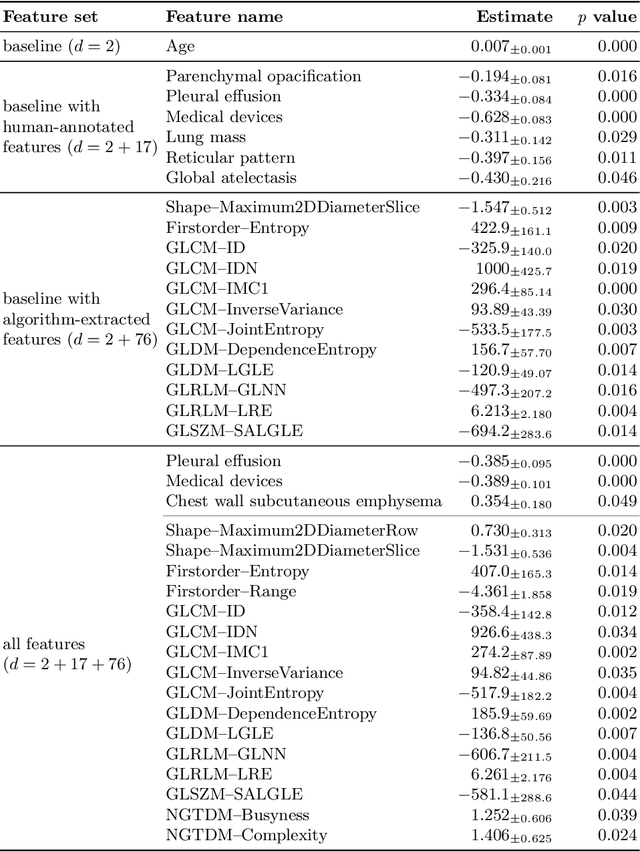
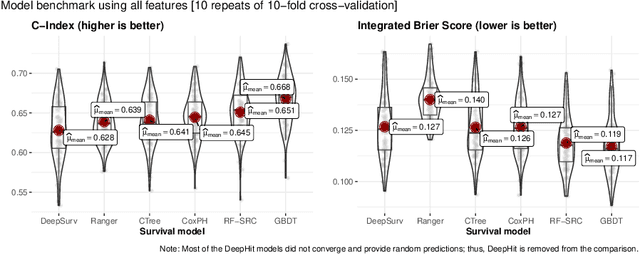
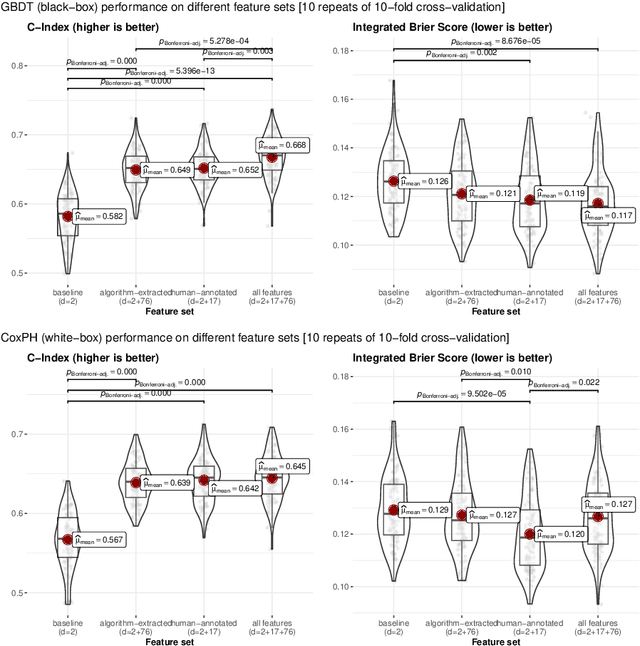
To what extent can the patient's length of stay in a hospital be predicted using only an X-ray image? We answer this question by comparing the performance of machine learning survival models on a novel multi-modal dataset created from 1235 images with textual radiology reports annotated by humans. Although black-box models predict better on average than interpretable ones, like Cox proportional hazards, they are not inherently understandable. To overcome this trust issue, we introduce time-dependent model explanations into the human-AI decision making process. Explaining models built on both: human-annotated and algorithm-extracted radiomics features provides valuable insights for physicians working in a hospital. We believe the presented approach to be general and widely applicable to other time-to-event medical use cases. For reproducibility, we open-source code and the TLOS dataset at https://github.com/mi2datalab/xlungs-trustworthy-los-prediction.
TILDE-Q: A Transformation Invariant Loss Function for Time-Series Forecasting
Oct 26, 2022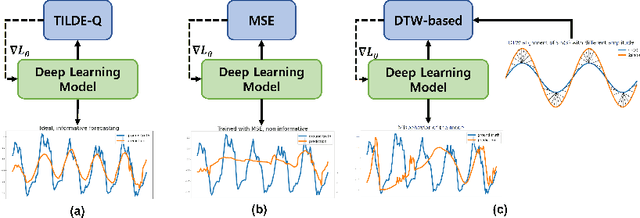

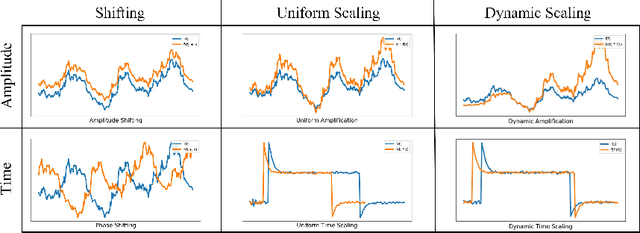
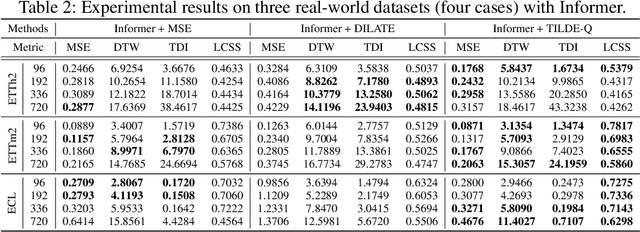
Time-series forecasting has caught increasing attention in the AI research field due to its importance in solving real-world problems across different domains, such as energy, weather, traffic, and economy. As shown in various types of data, it has been a must-see issue to deal with drastic changes, temporal patterns, and shapes in sequential data that previous models are weak in prediction. This is because most cases in time-series forecasting aim to minimize $L_p$ norm distances as loss functions, such as mean absolute error (MAE) or mean square error (MSE). These loss functions are vulnerable to not only considering temporal dynamics modeling but also capturing the shape of signals. In addition, these functions often make models misbehave and return uncorrelated results to the original time-series. To become an effective loss function, it has to be invariant to the set of distortions between two time-series data instead of just comparing exact values. In this paper, we propose a novel loss function, called TILDE-Q (Transformation Invariant Loss function with Distance EQuilibrium), that not only considers the distortions in amplitude and phase but also allows models to capture the shape of time-series sequences. In addition, TILDE-Q supports modeling periodic and non-periodic temporal dynamics at the same time. We evaluate the effectiveness of TILDE-Q by conducting extensive experiments with respect to periodic and non-periodic conditions of data, from naive models to state-of-the-art models. The experiment results indicate that the models trained with TILDE-Q outperform those trained with other training metrics (e.g., MSE, dynamic time warping (DTW), temporal distortion index (TDI), and longest common subsequence (LCSS)).