 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NVAutoNet: Fast and Accurate 360$^{\circ}$ 3D Perception For Self Driving
Mar 23, 2023
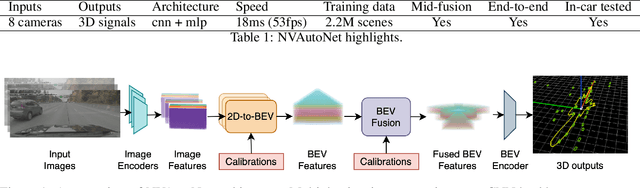

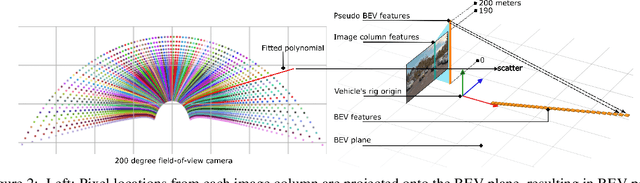
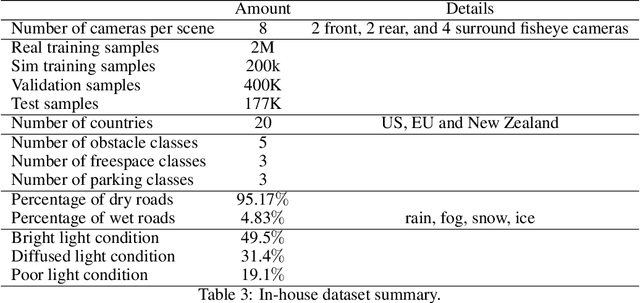
Robust real-time perception of 3D world is essential to the autonomous vehicle. We introduce an end-to-end surround camera perception system for self-driving. Our perception system is a novel multi-task, multi-camera network which takes a variable set of time-synced camera images as input and produces a rich collection of 3D signals such as sizes, orientations, locations of obstacles, parking spaces and free-spaces, etc. Our perception network is modular and end-to-end: 1) the outputs can be consumed directly by downstream modules without any post-processing such as clustering and fusion -- improving speed of model deployment and in-car testing 2) the whole network training is done in one single stage -- improving speed of model improvement and iterations. The network is well designed to have high accuracy while running at 53 fps on NVIDIA Orin SoC (system-on-a-chip). The network is robust to sensor mounting variations (within some tolerances) and can be quickly customized for different vehicle types via efficient model fine-tuning thanks of its capability of taking calibration parameters as additional inputs during training and testing. Most importantly, our network has been successfully deployed and being tested on real roads.
Automated Federated Learning in Mobile Edge Networks -- Fast Adaptation and Convergence
Mar 23, 2023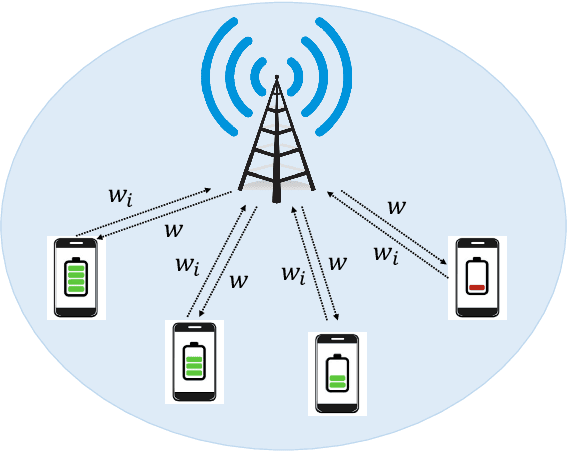
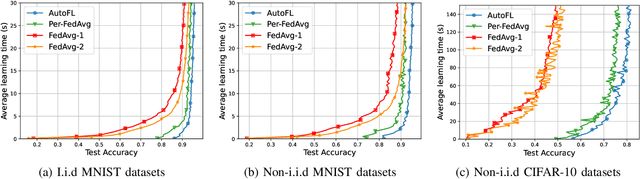
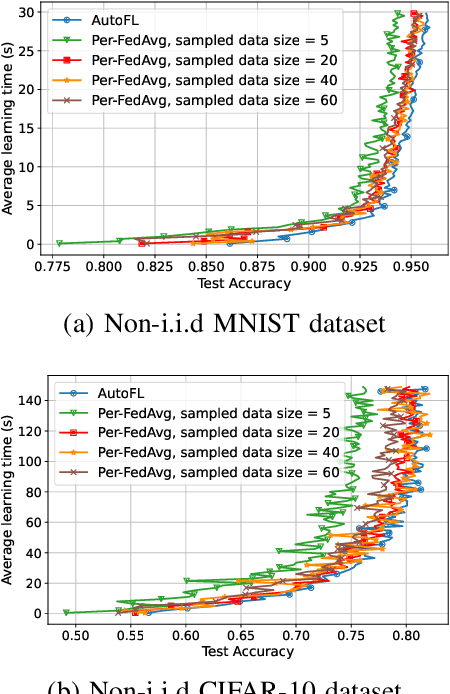
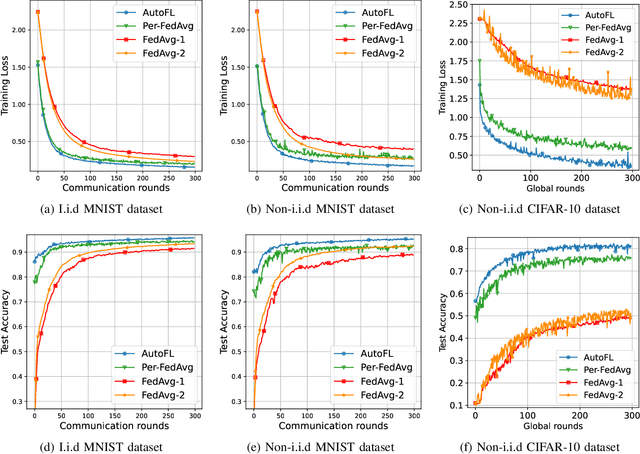
Federated Learning (FL) can be used in mobile edge networks to train machine learning models in a distributed manner. Recently, FL has been interpreted within a Model-Agnostic Meta-Learning (MAML) framework, which brings FL significant advantages in fast adaptation and convergence over heterogeneous datasets. However, existing research simply combines MAML and FL without explicitly addressing how much benefit MAML brings to FL and how to maximize such benefit over mobile edge networks. In this paper, we quantify the benefit from two aspects: optimizing FL hyperparameters (i.e., sampled data size and the number of communication rounds) and resource allocation (i.e., transmit power) in mobile edge networks. Specifically, we formulate the MAML-based FL design as an overall learning time minimization problem, under the constraints of model accuracy and energy consumption. Facilitated by the convergence analysis of MAML-based FL, we decompose the formulated problem and then solve it using analytical solutions and the coordinate descent method. With the obtained FL hyperparameters and resource allocation, we design a MAML-based FL algorithm, called Automated Federated Learning (AutoFL), that is able to conduct fast adaptation and convergence. Extensive experimental results verify that AutoFL outperforms other benchmark algorithms regarding the learning time and convergence performance.
RFAConv: Innovating Spatital Attention and Standard Convolutional Operation
Apr 13, 2023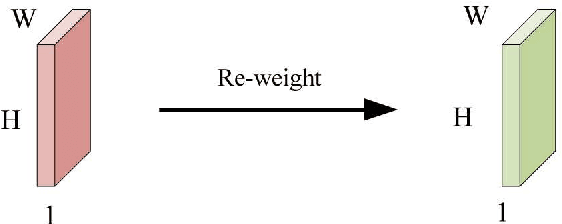
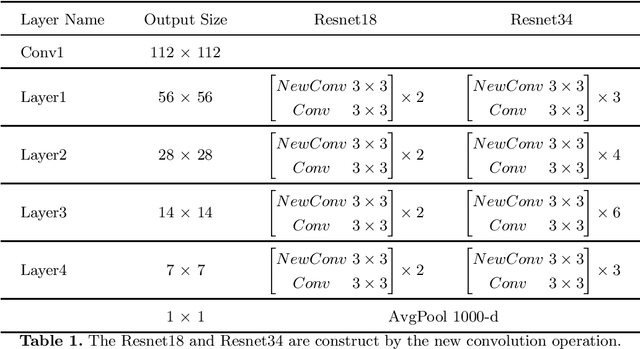
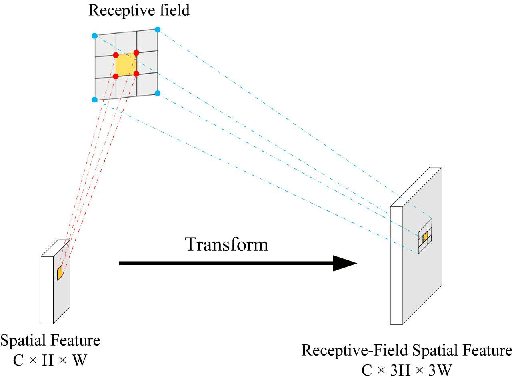
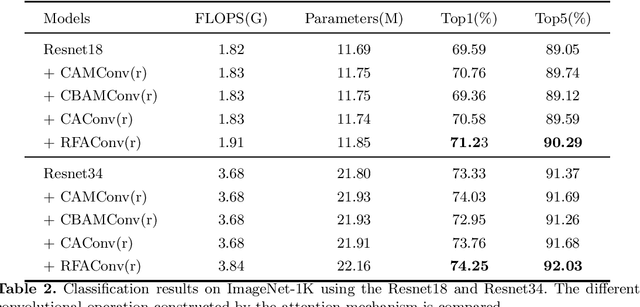
Spatial attention has been widely used to improve the performance of convolutional neural networks by allowing them to focus on important information. However, it has certain limitations. In this paper, we propose a new perspective on the effectiveness of spatial attention, which is that it can solve the problem of convolutional kernel parameter sharing. Despite this, the information contained in the attention map generated by spatial attention is not sufficient for large-size convolutional kernels. Therefore, we introduce a new attention mechanism called Receptive-Field Attention (RFA). While previous attention mechanisms such as the Convolutional Block Attention Module (CBAM) and Coordinate Attention (CA) only focus on spatial features, they cannot fully address the issue of convolutional kernel parameter sharing. In contrast, RFA not only focuses on the receptive-field spatial feature but also provides effective attention weights for large-size convolutional kernels. The Receptive-Field Attention convolutional operation (RFAConv), developed by RFA, represents a new approach to replace the standard convolution operation. It offers nearly negligible increment of computational cost and parameters, while significantly improving network performance. We conducted a series of experiments on ImageNet-1k, MS COCO, and VOC datasets, which demonstrated the superiority of our approach in various tasks including classification, object detection, and semantic segmentation. Of particular importance, we believe that it is time to shift focus from spatial features to receptive-field spatial features for current spatial attention mechanisms. By doing so, we can further improve network performance and achieve even better results. The code and pre-trained models for the relevant tasks can be found at https://github.com/Liuchen1997/RFAConv.
Active Cost-aware Labeling of Streaming Data
Apr 13, 2023

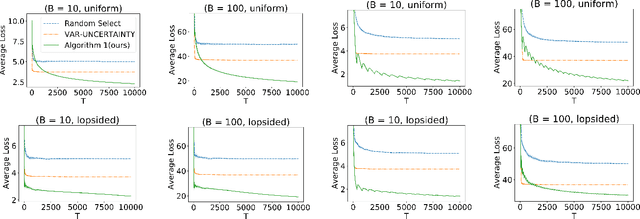

We study actively labeling streaming data, where an active learner is faced with a stream of data points and must carefully choose which of these points to label via an expensive experiment. Such problems frequently arise in applications such as healthcare and astronomy. We first study a setting when the data's inputs belong to one of $K$ discrete distributions and formalize this problem via a loss that captures the labeling cost and the prediction error. When the labeling cost is $B$, our algorithm, which chooses to label a point if the uncertainty is larger than a time and cost dependent threshold, achieves a worst-case upper bound of $O(B^{\frac{1}{3}} K^{\frac{1}{3}} T^{\frac{2}{3}})$ on the loss after $T$ rounds. We also provide a more nuanced upper bound which demonstrates that the algorithm can adapt to the arrival pattern, and achieves better performance when the arrival pattern is more favorable. We complement both upper bounds with matching lower bounds. We next study this problem when the inputs belong to a continuous domain and the output of the experiment is a smooth function with bounded RKHS norm. After $T$ rounds in $d$ dimensions, we show that the loss is bounded by $O(B^{\frac{1}{d+3}} T^{\frac{d+2}{d+3}})$ in an RKHS with a squared exponential kernel and by $O(B^{\frac{1}{2d+3}} T^{\frac{2d+2}{2d+3}})$ in an RKHS with a Mat\'ern kernel. Our empirical evaluation demonstrates that our method outperforms other baselines in several synthetic experiments and two real experiments in medicine and astronomy.
On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence
Apr 13, 2023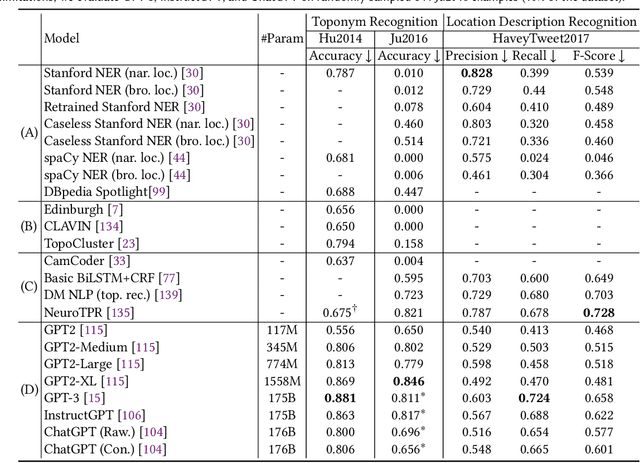
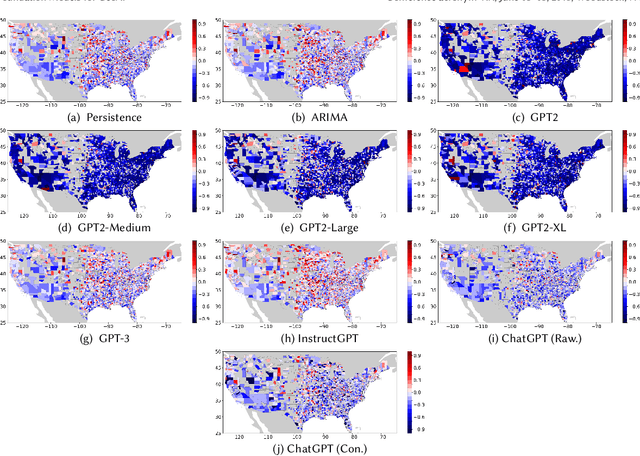
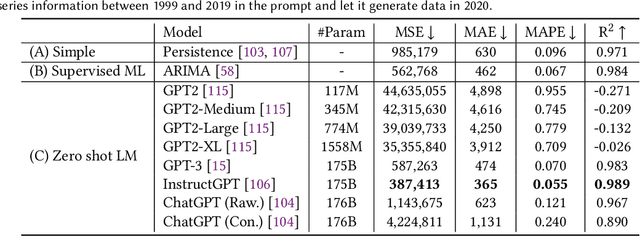
Large pre-trained models, also known as foundation models (FMs), are trained in a task-agnostic manner on large-scale data and can be adapted to a wide range of downstream tasks by fine-tuning, few-shot, or even zero-shot learning. Despite their successes in language and vision tasks, we have yet seen an attempt to develop foundation models for geospatial artificial intelligence (GeoAI). In this work, we explore the promises and challenges of developing multimodal foundation models for GeoAI. We first investigate the potential of many existing FMs by testing their performances on seven tasks across multiple geospatial subdomains including Geospatial Semantics, Health Geography, Urban Geography, and Remote Sensing. Our results indicate that on several geospatial tasks that only involve text modality such as toponym recognition, location description recognition, and US state-level/county-level dementia time series forecasting, these task-agnostic LLMs can outperform task-specific fully-supervised models in a zero-shot or few-shot learning setting. However, on other geospatial tasks, especially tasks that involve multiple data modalities (e.g., POI-based urban function classification, street view image-based urban noise intensity classification, and remote sensing image scene classification), existing foundation models still underperform task-specific models. Based on these observations, we propose that one of the major challenges of developing a FM for GeoAI is to address the multimodality nature of geospatial tasks. After discussing the distinct challenges of each geospatial data modality, we suggest the possibility of a multimodal foundation model which can reason over various types of geospatial data through geospatial alignments. We conclude this paper by discussing the unique risks and challenges to develop such a model for GeoAI.
Distributed detection of ARMA signals
Apr 14, 2023
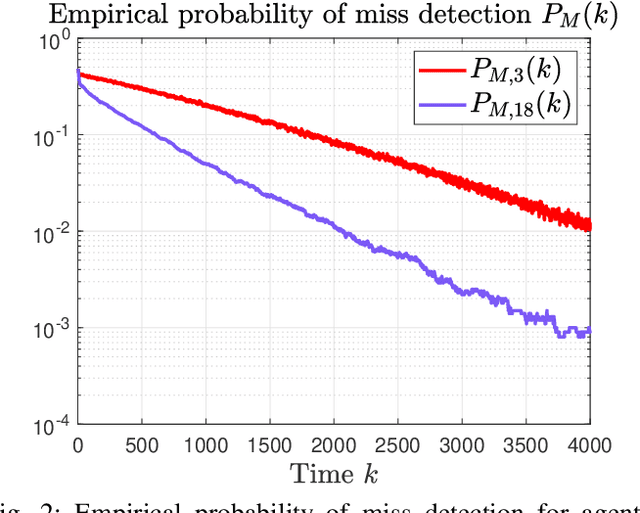
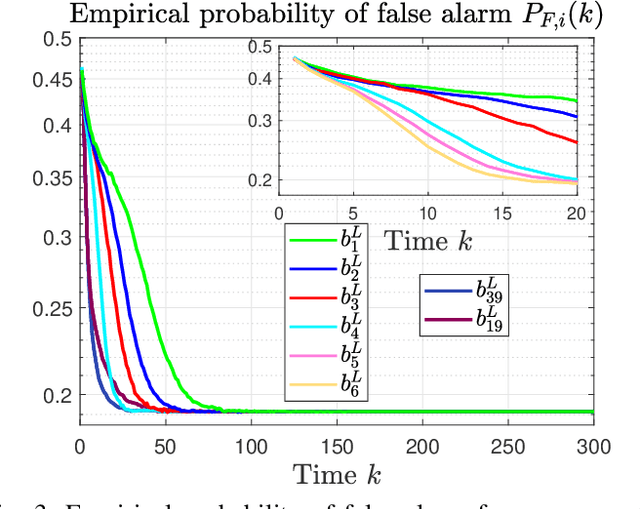
This paper considers a distributed detection setup where agents in a network want to detect a time-varying signal embedded in temporally correlated noise. The signal of interest is the impulse response of an ARMA (auto-regressive moving average) filter, and the noise is the output of yet another ARMA filter which is fed white Gaussian noise. For this extended problem setup, which can prompt novel behaviour, we propose a comprehensive solution. First, we extend the well-known running consensus detector (RCD) to this correlated setup; then, we design an efficient implementation of the RCD by exploiting the underlying ARMA structures; and, finally, we derive the theoretical asymptotic performance of the RCD in this ARMA setup. It turns out that the error probability at each agent exhibits one of two regimes: either (a) the error probability decays exponentially fast to zero or (b) it converges to a strictly positive error floor. While regime (a) spans staple results in large deviation theory, regime (b) is new in distributed detection and is elicited by the ARMA setup. We fully characterize these two scenarios: we give necessary and sufficient conditions, phrased in terms of the zero and poles of the underlying ARMA models, for the emergence of each regime, and provide closed-form expressions for both the decay rates of regime (a) and the positive error floors of regime (b). Our analysis also shows that the ARMA setup leads to two novel features: (1) the threshold level used in RCD can influence the asymptotics of the error probabilities and (2) some agents might be weakly informative, in the sense that their observations do not improve the asymptotic performance of RCD and, as such, can be safely muted to save sensing resources. Numerical simulations illustrate and confirm the theoretical findings.
Revenue Management without Demand Forecasting: A Data-Driven Approach for Bid Price Generation
Apr 14, 2023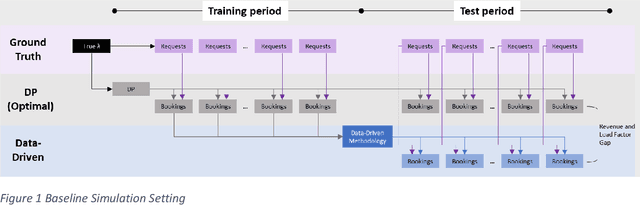
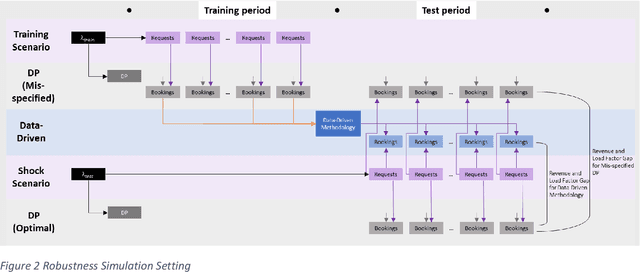
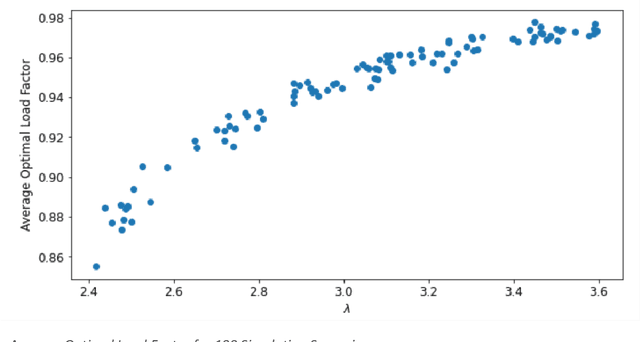
Traditional revenue management relies on long and stable historical data and predictable demand patterns. However, meeting those requirements is not always possible. Many industries face demand volatility on an ongoing basis, an example would be air cargo which has much shorter booking horizon with highly variable batch arrivals. Even for passenger airlines where revenue management (RM) is well-established, reacting to external shocks is a well-known challenge that requires user monitoring and manual intervention. Moreover, traditional RM comes with strict data requirements including historical bookings and pricing even in the absence of any bookings, spanning multiple years. For companies that have not established a practice in RM, that type of extensive data is usually not available. We present a data-driven approach to RM which eliminates the need for demand forecasting and optimization techniques. We develop a methodology to generate bid prices using historical booking data only. Our approach is an ex-post greedy heuristic to estimate proxies for marginal opportunity costs as a function of remaining capacity and time-to-departure solely based on historical booking data. We utilize a neural network algorithm to project bid price estimations into the future. We conduct an extensive simulation study where we measure performance of our methodology compared to that of an optimally generated bid price using dynamic programming (DP). We also extend our simulations to measure performance of both data-driven and DP generated bid prices under the presence of demand misspecification. Our results show that our data-driven methodology stays near a theoretical optimum (<1% revenue gap) for a wide-range of settings, whereas DP deviates more significantly from the optimal as the magnitude of misspecification is increased. This highlights the robustness of our data-driven approach.
TILDE-Q: A Transformation Invariant Loss Function for Time-Series Forecasting
Oct 26, 2022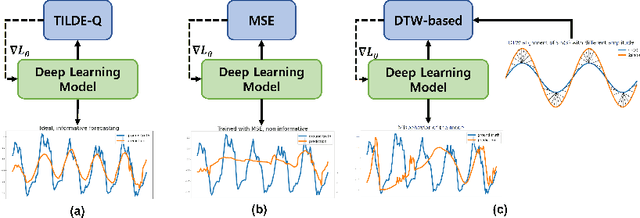

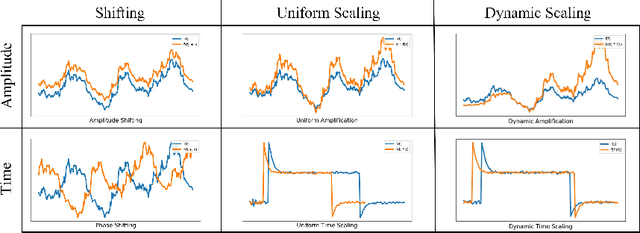
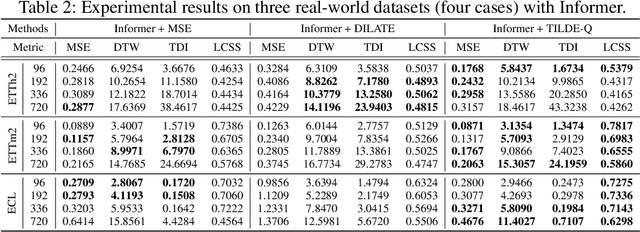
Time-series forecasting has caught increasing attention in the AI research field due to its importance in solving real-world problems across different domains, such as energy, weather, traffic, and economy. As shown in various types of data, it has been a must-see issue to deal with drastic changes, temporal patterns, and shapes in sequential data that previous models are weak in prediction. This is because most cases in time-series forecasting aim to minimize $L_p$ norm distances as loss functions, such as mean absolute error (MAE) or mean square error (MSE). These loss functions are vulnerable to not only considering temporal dynamics modeling but also capturing the shape of signals. In addition, these functions often make models misbehave and return uncorrelated results to the original time-series. To become an effective loss function, it has to be invariant to the set of distortions between two time-series data instead of just comparing exact values. In this paper, we propose a novel loss function, called TILDE-Q (Transformation Invariant Loss function with Distance EQuilibrium), that not only considers the distortions in amplitude and phase but also allows models to capture the shape of time-series sequences. In addition, TILDE-Q supports modeling periodic and non-periodic temporal dynamics at the same time. We evaluate the effectiveness of TILDE-Q by conducting extensive experiments with respect to periodic and non-periodic conditions of data, from naive models to state-of-the-art models. The experiment results indicate that the models trained with TILDE-Q outperform those trained with other training metrics (e.g., MSE, dynamic time warping (DTW), temporal distortion index (TDI), and longest common subsequence (LCSS)).
The DOPE Distance is SIC: A Stable, Informative, and Computable Metric on Time Series And Ordered Merge Trees
Dec 03, 2022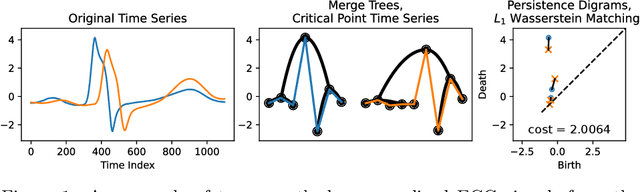
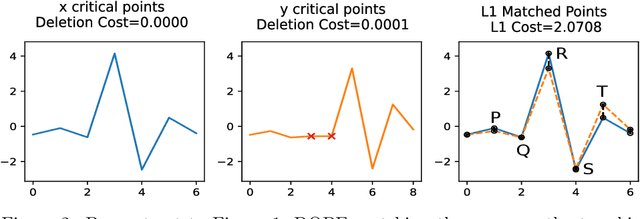
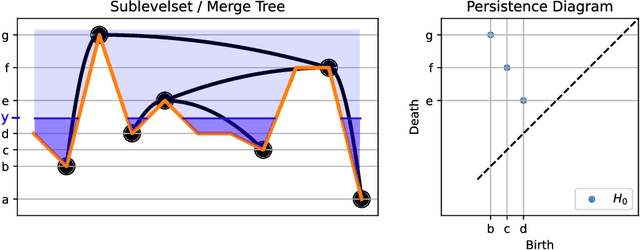
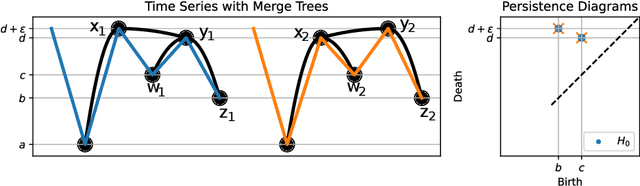
Metrics for merge trees that are simultaneously stable, informative, and efficiently computable have so far eluded researchers. We show in this work that it is possible to devise such a metric when restricting merge trees to ordered domains such as the interval and the circle. We present the ``dynamic ordered persistence editing'' (DOPE) distance, which we prove is stable and informative while satisfying metric properties. We then devise a simple $O(N^2)$ dynamic programming algorithm to compute it on the interval and an $O(N^3)$ algorithm to compute it on the circle. Surprisingly, we accomplish this by ignoring all of the hierarchical information of the merge tree and simply focusing on a sequence of ordered critical points, which can be interpreted as a time series. Thus our algorithm is more similar to string edit distance and dynamic time warping than it is to more conventional merge tree comparison algorithms. In the context of time series with the interval as a domain, we show empirically on the UCR time series classification dataset that DOPE performs better than bottleneck/Wasserstein distances between persistence diagrams.
A Survey on Causal Discovery Methods for Temporal and Non-Temporal Data
Apr 05, 2023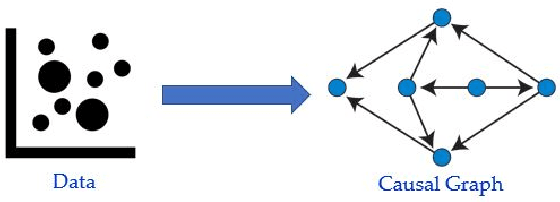
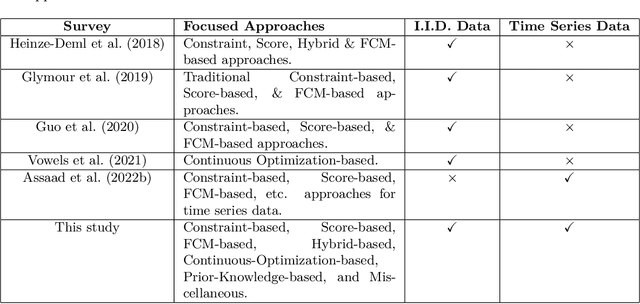
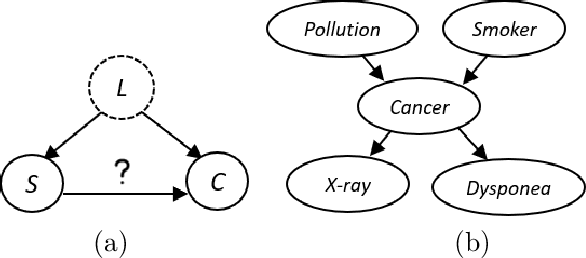
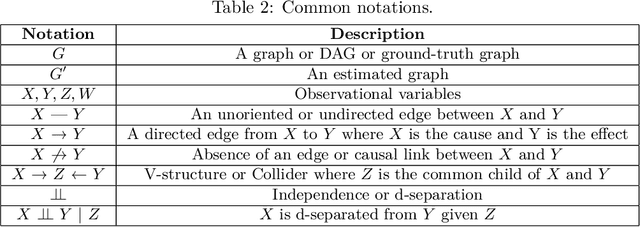
Causal Discovery (CD) is the process of identifying the cause-effect relationships among the variables of a system from data. Over the years, several methods have been developed primarily based on the statistical properties of data to uncover the underlying causal mechanism. In this study, we present an extensive discussion on the methods designed to perform causal discovery from both independent and identically distributed (i.i.d.) data and time series data. For this purpose, we first introduce the common terminologies in causal discovery, and then provide a comprehensive discussion of the algorithms designed to identify the causal edges in different settings. We further discuss some of the benchmark datasets available for evaluating the performance of the causal discovery methods, available tools or software packages to perform causal discovery readily, and the common metrics used to evaluate these methods. We also test some common causal discovery algorithms on different benchmark datasets, and compare their performances. Finally, we conclude by presenting the common challenges involved in causal discovery, and also, discuss the applications of causal discovery in multiple areas of interest.