 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Effective black box adversarial attack with handcrafted kernels
Mar 24, 2023
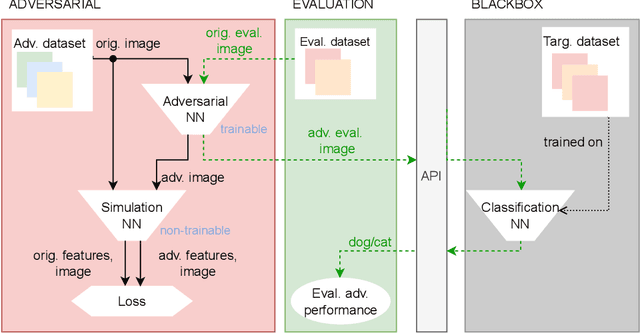
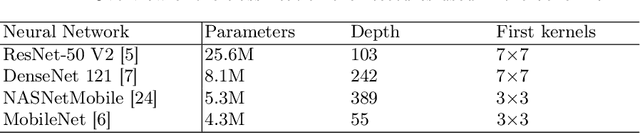


We propose a new, simple framework for crafting adversarial examples for black box attacks. The idea is to simulate the substitution model with a non-trainable model compounded of just one layer of handcrafted convolutional kernels and then train the generator neural network to maximize the distance of the outputs for the original and generated adversarial image. We show that fooling the prediction of the first layer causes the whole network to be fooled and decreases its accuracy on adversarial inputs. Moreover, we do not train the neural network to obtain the first convolutional layer kernels, but we create them using the technique of F-transform. Therefore, our method is very time and resource effective.
VMesh: Hybrid Volume-Mesh Representation for Efficient View Synthesis
Mar 28, 2023
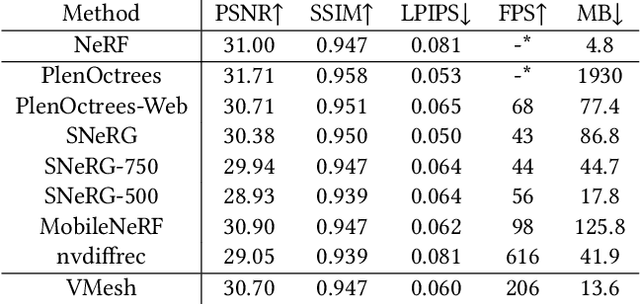
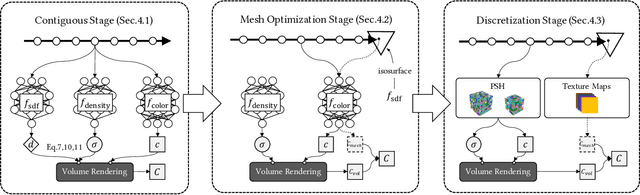
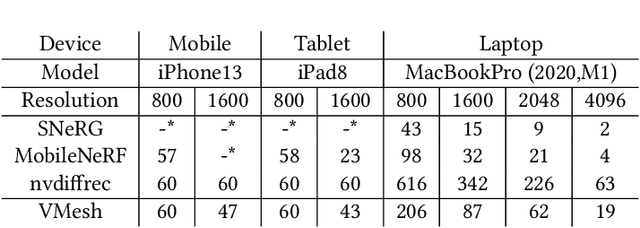
With the emergence of neural radiance fields (NeRFs), view synthesis quality has reached an unprecedented level. Compared to traditional mesh-based assets, this volumetric representation is more powerful in expressing scene geometry but inevitably suffers from high rendering costs and can hardly be involved in further processes like editing, posing significant difficulties in combination with the existing graphics pipeline. In this paper, we present a hybrid volume-mesh representation, VMesh, which depicts an object with a textured mesh along with an auxiliary sparse volume. VMesh retains the advantages of mesh-based assets, such as efficient rendering, compact storage, and easy editing, while also incorporating the ability to represent subtle geometric structures provided by the volumetric counterpart. VMesh can be obtained from multi-view images of an object and renders at 2K 60FPS on common consumer devices with high fidelity, unleashing new opportunities for real-time immersive applications.
Real-time Local Feature with Global Visual Information Enhancement
Nov 20, 2022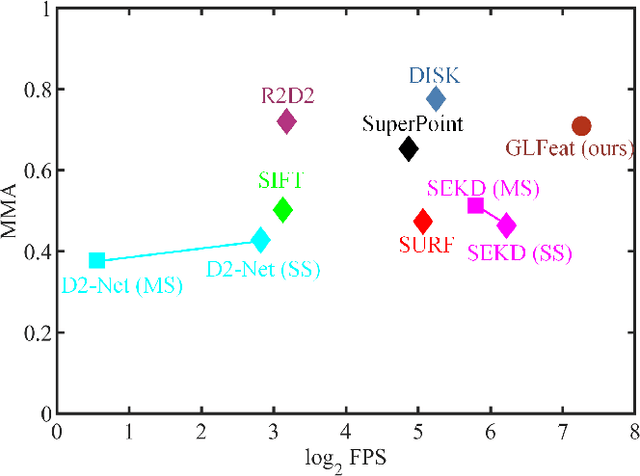
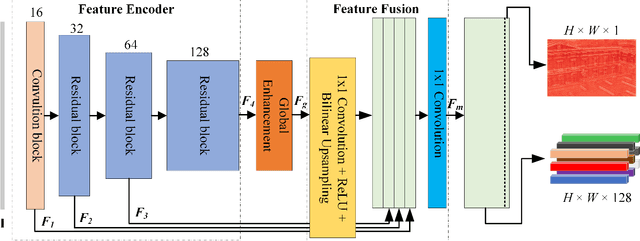

Local feature provides compact and invariant image representation for various visual tasks. Current deep learning-based local feature algorithms always utilize convolution neural network (CNN) architecture with limited receptive field. Besides, even with high-performance GPU devices, the computational efficiency of local features cannot be satisfactory. In this paper, we tackle such problems by proposing a CNN-based local feature algorithm. The proposed method introduces a global enhancement module to fuse global visual clues in a light-weight network, and then optimizes the network by novel deep reinforcement learning scheme from the perspective of local feature matching task. Experiments on the public benchmarks demonstrate that the proposal can achieve considerable robustness against visual interference and meanwhile run in real time.
Prompt-Guided Transformers for End-to-End Open-Vocabulary Object Detection
Mar 25, 2023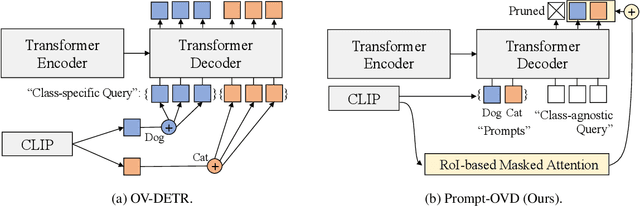
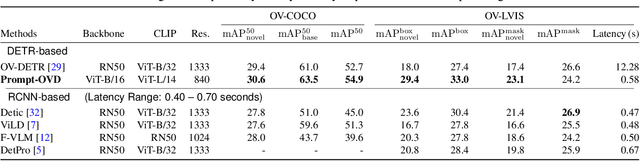
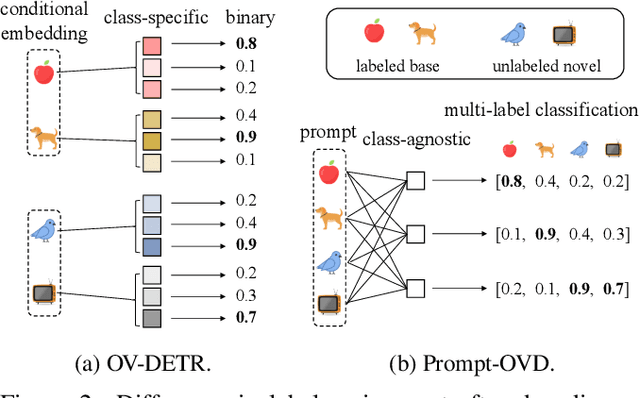
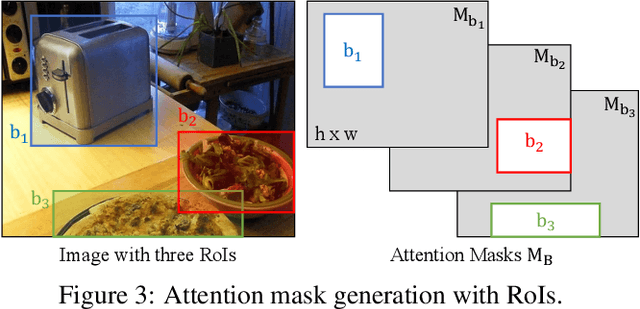
Prompt-OVD is an efficient and effective framework for open-vocabulary object detection that utilizes class embeddings from CLIP as prompts, guiding the Transformer decoder to detect objects in both base and novel classes. Additionally, our novel RoI-based masked attention and RoI pruning techniques help leverage the zero-shot classification ability of the Vision Transformer-based CLIP, resulting in improved detection performance at minimal computational cost. Our experiments on the OV-COCO and OVLVIS datasets demonstrate that Prompt-OVD achieves an impressive 21.2 times faster inference speed than the first end-to-end open-vocabulary detection method (OV-DETR), while also achieving higher APs than four two-stage-based methods operating within similar inference time ranges. Code will be made available soon.
Heat flux for semi-local machine-learning potentials
Mar 25, 2023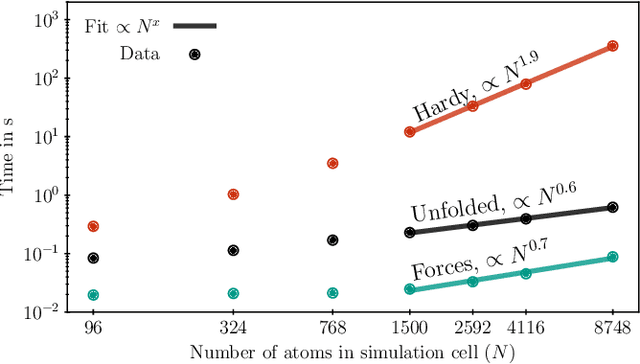
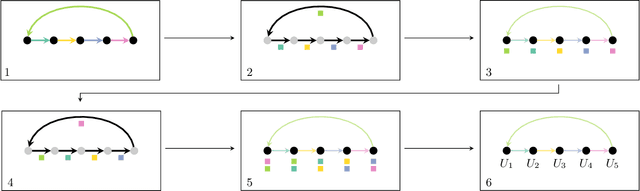
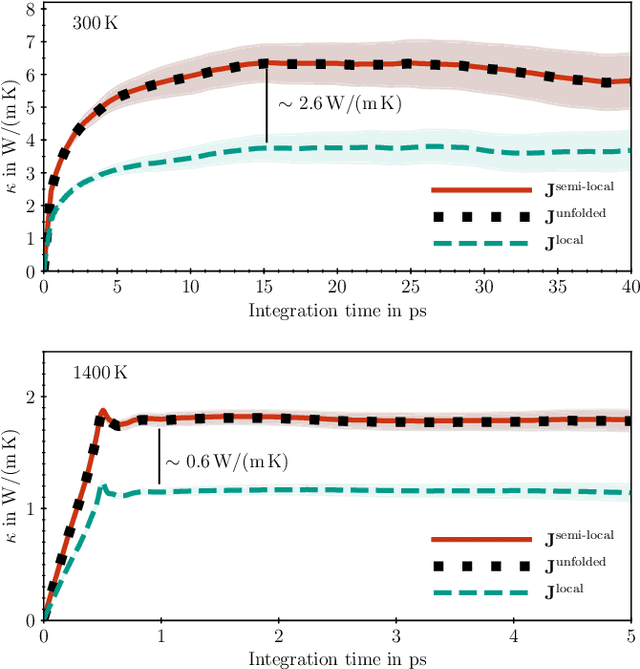
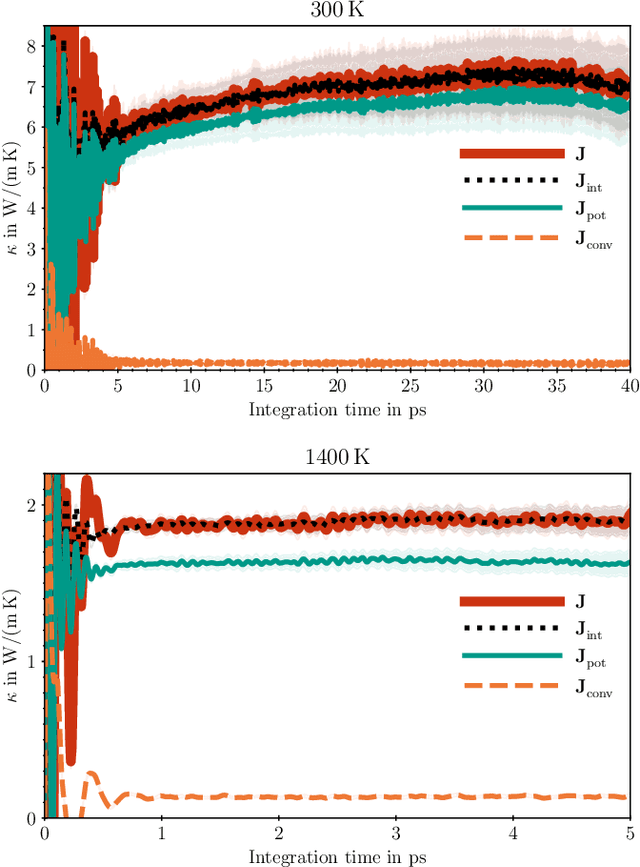
The Green-Kubo (GK) method is a rigorous framework for heat transport simulations in materials. However, it requires an accurate description of the potential-energy surface and carefully converged statistics. Machine-learning potentials can achieve the accuracy of first-principles simulations while allowing to reach well beyond their simulation time and length scales at a fraction of the cost. In this paper, we explain how to apply the GK approach to the recent class of message-passing machine-learning potentials, which iteratively consider semi-local interactions beyond the initial interaction cutoff. We derive an adapted heat flux formulation that can be implemented using automatic differentiation without compromising computational efficiency. The approach is demonstrated and validated by calculating the thermal conductivity of zirconium dioxide across temperatures.
Optimal Mixed-ADC arrangement for DOA Estimation via CRB using ULA
Mar 27, 2023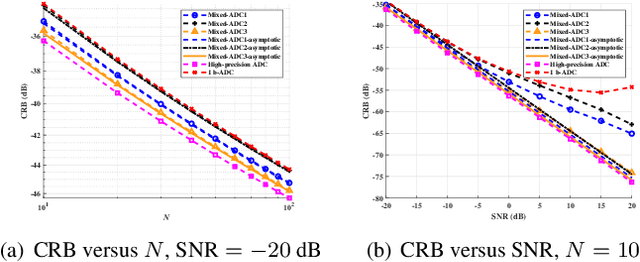
We consider a mixed analog-to-digital converter (ADC) based architecture for direction of arrival (DOA) estimation using a uniform linear array (ULA). We derive the Cram{\'e}r-Rao bound (CRB) of the DOA under the optimal time-varying threshold, and find that the asymptotic CRB is related to the arrangement of high-precision and one-bit ADCs for a fixed number of ADCs. Then, a new concept called ``mixed-precision arrangement" is proposed. It is proven that better performance for DOA estimation is achieved when high-precision ADCs are distributed evenly around the edges of the ULA. This result can be extended to a more general case where the ULA is equipped with various precision ADCs. Simulation results show the validity of the asymptotic CRB and better performance under the optimal mixed-precision arrangement.
A Comprehensive Survey of Regression Based Loss Functions for Time Series Forecasting
Nov 05, 2022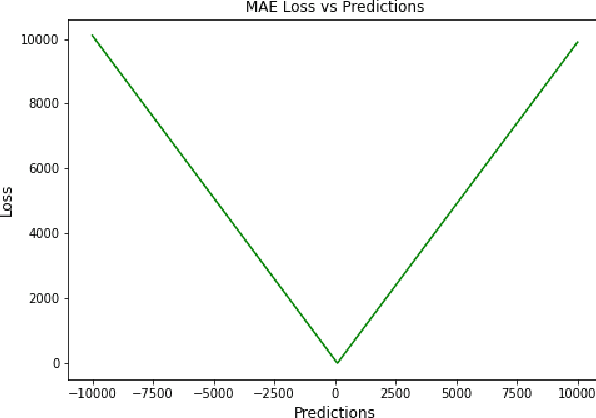
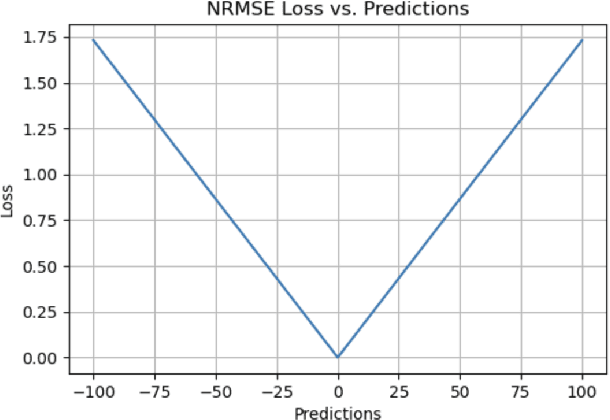
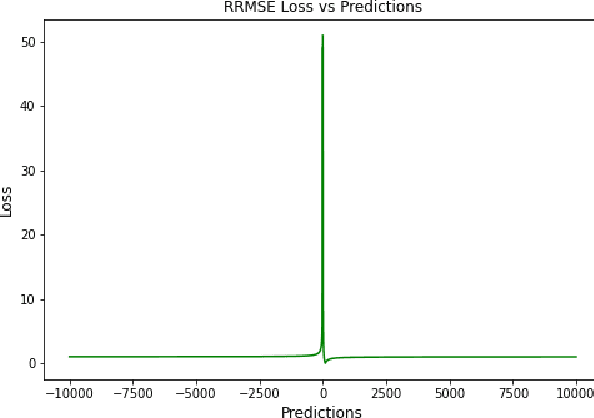
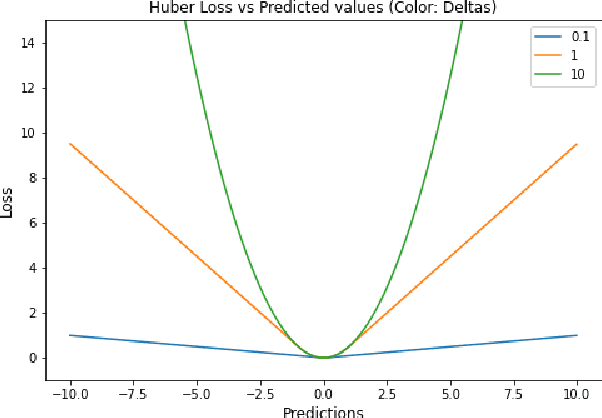
Time Series Forecasting has been an active area of research due to its many applications ranging from network usage prediction, resource allocation, anomaly detection, and predictive maintenance. Numerous publications published in the last five years have proposed diverse sets of objective loss functions to address cases such as biased data, long-term forecasting, multicollinear features, etc. In this paper, we have summarized 14 well-known regression loss functions commonly used for time series forecasting and listed out the circumstances where their application can aid in faster and better model convergence. We have also demonstrated how certain categories of loss functions perform well across all data sets and can be considered as a baseline objective function in circumstances where the distribution of the data is unknown. Our code is available at GitHub: https://github.com/aryan-jadon/Regression-Loss-Functions-in-Time-Series-Forecasting-Tensorflow.
Development of A Real-time POCUS Image Quality Assessment and Acquisition Guidance System
Dec 19, 2022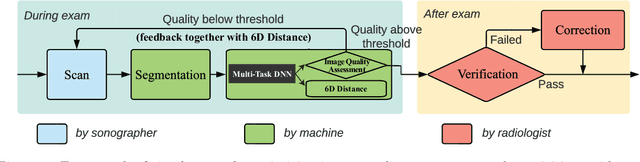
Point-of-care ultrasound (POCUS) is one of the most commonly applied tools for cardiac function imaging in the clinical routine of the emergency department and pediatric intensive care unit. The prior studies demonstrate that AI-assisted software can guide nurses or novices without prior sonography experience to acquire POCUS by recognizing the interest region, assessing image quality, and providing instructions. However, these AI algorithms cannot simply replace the role of skilled sonographers in acquiring diagnostic-quality POCUS. Unlike chest X-ray, CT, and MRI, which have standardized imaging protocols, POCUS can be acquired with high inter-observer variability. Though being with variability, they are usually all clinically acceptable and interpretable. In challenging clinical environments, sonographers employ novel heuristics to acquire POCUS in complex scenarios. To help novice learners to expedite the training process while reducing the dependency on experienced sonographers in the curriculum implementation, We will develop a framework to perform real-time AI-assisted quality assessment and probe position guidance to provide training process for novice learners with less manual intervention.
Safe Perception-Based Control under Stochastic Sensor Uncertainty using Conformal Prediction
Apr 01, 2023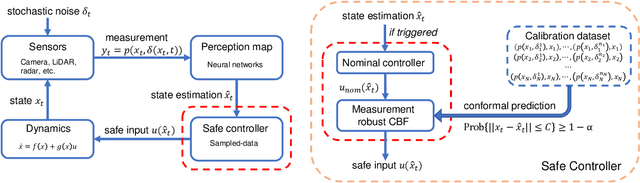
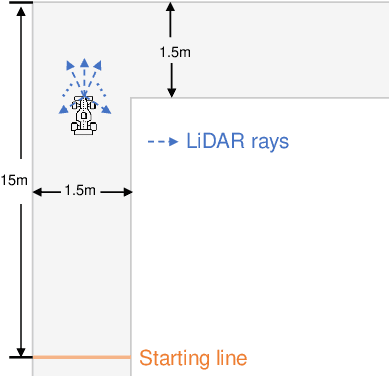
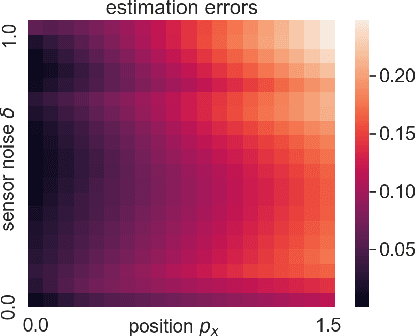
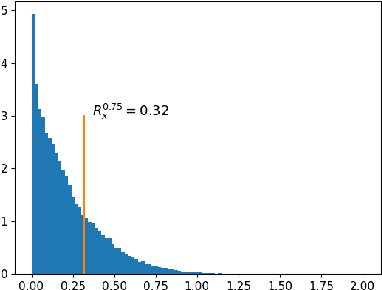
We consider perception-based control using state estimates that are obtained from high-dimensional sensor measurements via learning-enabled perception maps. However, these perception maps are not perfect and result in state estimation errors that can lead to unsafe system behavior. Stochastic sensor noise can make matters worse and result in estimation errors that follow unknown distributions. We propose a perception-based control framework that i) quantifies estimation uncertainty of perception maps, and ii) integrates these uncertainty representations into the control design. To do so, we use conformal prediction to compute valid state estimation regions, which are sets that contain the unknown state with high probability. We then devise a sampled-data controller for continuous-time systems based on the notion of measurement robust control barrier functions. Our controller uses idea from self-triggered control and enables us to avoid using stochastic calculus. Our framework is agnostic to the choice of the perception map, independent of the noise distribution, and to the best of our knowledge the first to provide probabilistic safety guarantees in such a setting. We demonstrate the effectiveness of our proposed perception-based controller for a LiDAR-enabled F1/10th car.
Leveraging Neo4j and deep learning for traffic congestion simulation & optimization
Apr 01, 2023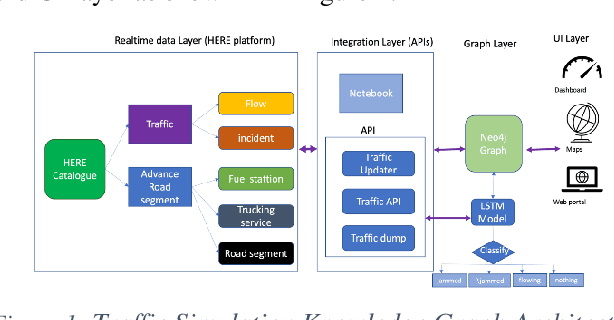
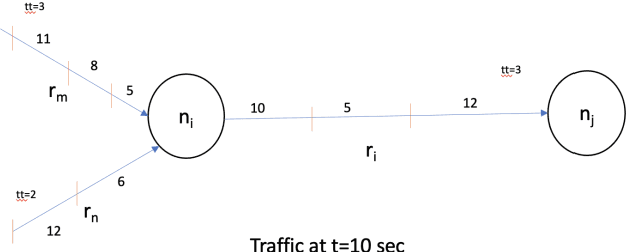

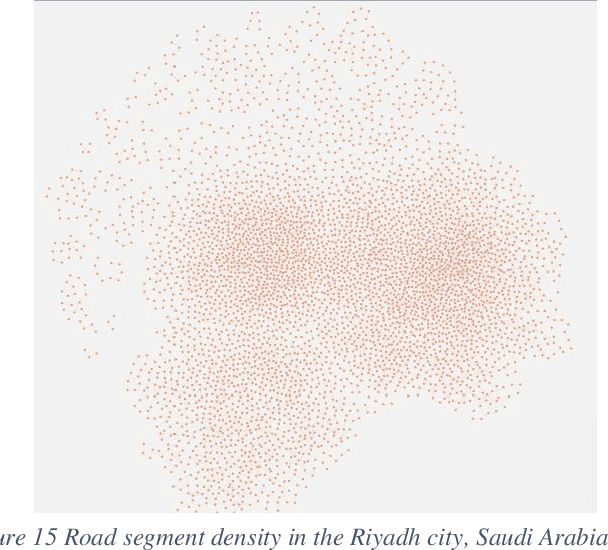
Traffic congestion has been a major challenge in many urban road networks. Extensive research studies have been conducted to highlight traffic-related congestion and address the issue using data-driven approaches. Currently, most traffic congestion analyses are done using simulation software that offers limited insight due to the limitations in the tools and utilities being used to render various traffic congestion scenarios. All that impacts the formulation of custom business problems which vary from place to place and country to country. By exploiting the power of the knowledge graph, we model a traffic congestion problem into the Neo4j graph and then use the load balancing, optimization algorithm to identify congestion-free road networks. We also show how traffic propagates backward in case of congestion or accident scenarios and its overall impact on other segments of the roads. We also train a sequential RNN-LSTM (Long Short-Term Memory) deep learning model on the real-time traffic data to assess the accuracy of simulation results based on a road-specific congestion. Our results show that graph-based traffic simulation, supplemented by AI ML-based traffic prediction can be more effective in estimating the congestion level in a road network.