 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Blind Acoustic Room Parameter Estimation Using Phase Features
Mar 13, 2023

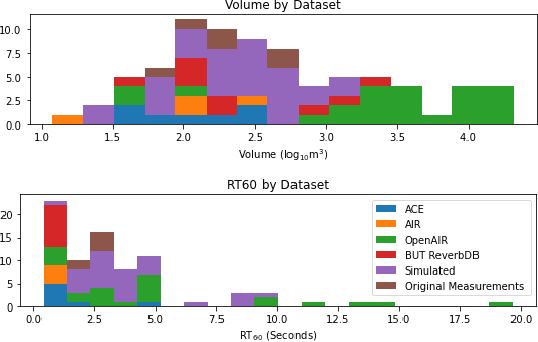
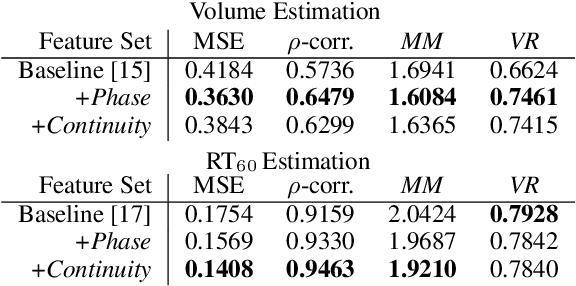

Modeling room acoustics in a field setting involves some degree of blind parameter estimation from noisy and reverberant audio. Modern approaches leverage convolutional neural networks (CNNs) in tandem with time-frequency representation. Using short-time Fourier transforms to develop these spectrogram-like features has shown promising results, but this method implicitly discards a significant amount of audio information in the phase domain. Inspired by recent works in speech enhancement, we propose utilizing novel phase-related features to extend recent approaches to blindly estimate the so-called "reverberation fingerprint" parameters, namely, volume and RT60. The addition of these features is shown to outperform existing methods that rely solely on magnitude-based spectral features across a wide range of acoustics spaces. We evaluate the effectiveness of the deployment of these novel features in both single-parameter and multi-parameter estimation strategies, using a novel dataset that consists of publicly available room impulse responses (RIRs), synthesized RIRs, and in-house measurements of real acoustic spaces.
Gradient-Descent Based Optimization of Constant Envelope OFDM Waveforms
Mar 13, 2023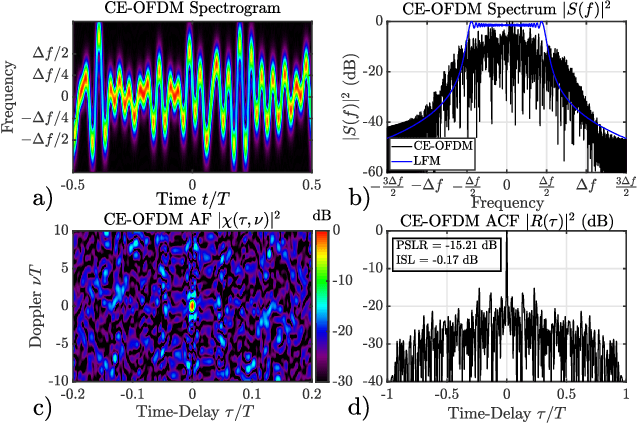
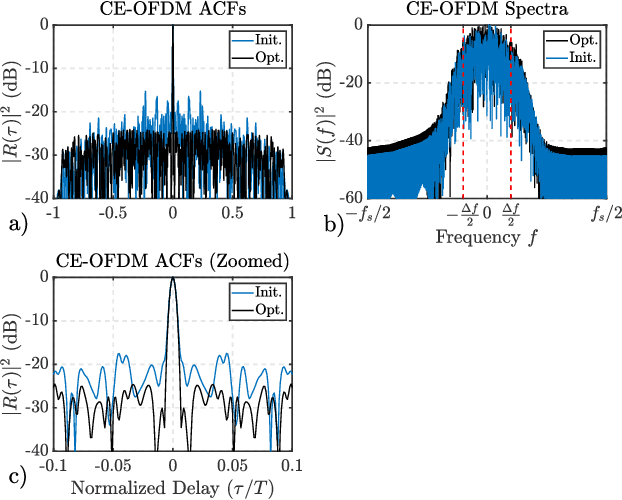
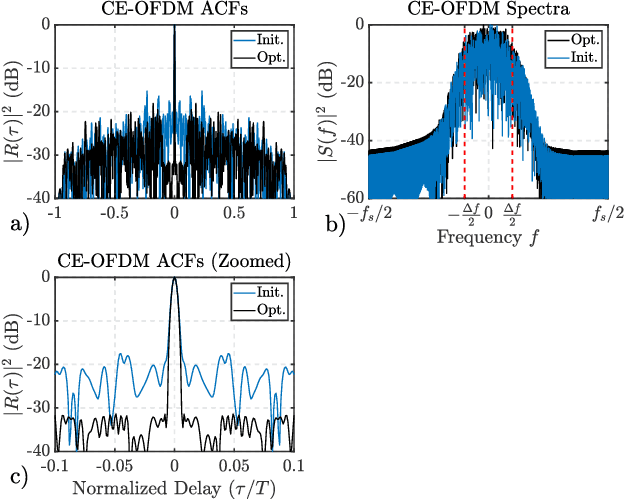
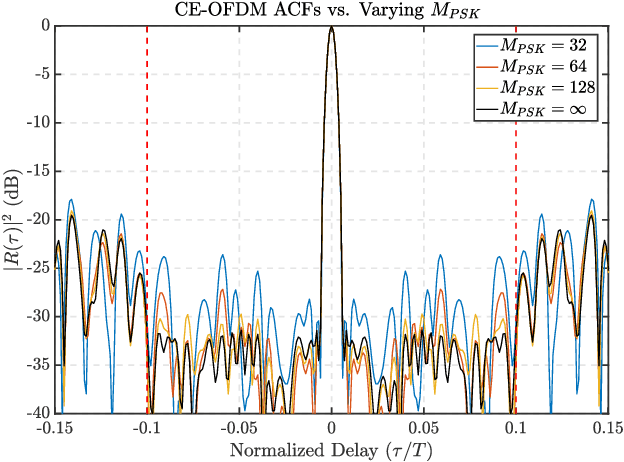
This paper describes a gradient-descent based optimization algorithm for synthesizing Constant Envelope Orthogonal Frequency Division Multiplexing (CE-OFDM) waveforms with low Auto-Correlation Function (ACF) sidelobes in a specified region of time-delays. The algorithm optimizes the Generalized Integrated Sidelobe Level (GISL) which controls the mainlobe and sidelobe structure of the waveform's ACF. The operations of this Gradient-Descent GISL (GD-GISL) algorithm are FFT-based making it computationally efficient. This computational efficiency facilitates the design of large dimensional waveform design problems. Simulations demonstrate the GD-GISL algorithm on CE-OFDM waveforms employing Phase-Shift Keying (PSK) symbols that take on a continuum of values (i.e, $M_{\text{PSK}} = \infty$). Results from these simulations show that the GD-GISL algorithm can indeed reduce ACF sidelobes in a desired region of time-delays. However, truncating the symbols to finite M-ary alphabets introduces perturbations to the waveform's instantaneous phase which increases the waveform's ACF sidelobe levels.
Non-Linear Signal Processing methods for UAV detections from a Multi-function X-band Radar
Mar 13, 2023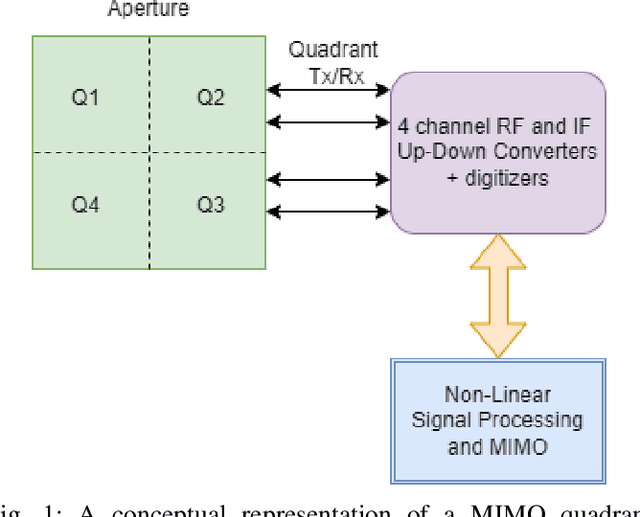
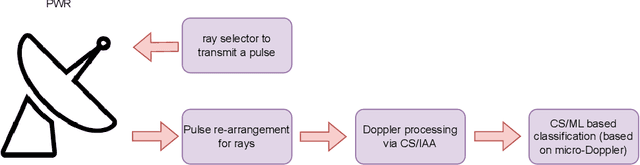
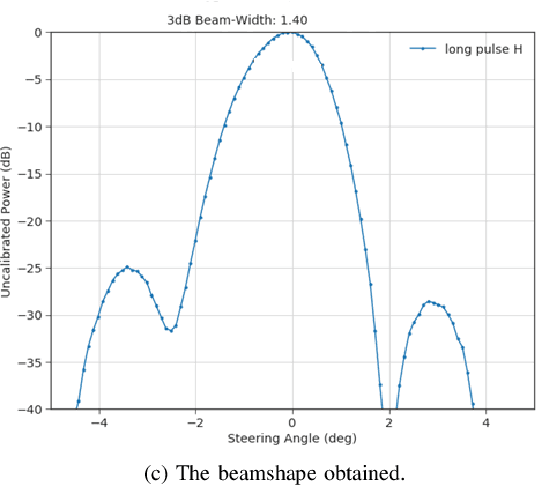
This article develops the applicability of non-linear processing techniques such as Compressed Sensing (CS), Principal Component Analysis (PCA), Iterative Adaptive Approach (IAA) and Multiple-input-multiple-output (MIMO) for the purpose of enhanced UAV detections using portable radar systems. The combined scheme has many advantages and the potential for better detection and classification accuracy. Some of the benefits are discussed here with a phased array platform in mind, the novel portable phased array Radar (PWR) by Agile RF Systems (ARS), which offers quadrant outputs. CS and IAA both show promising results when applied to micro-Doppler processing of radar returns owing to the sparse nature of the target Doppler frequencies. This shows promise in reducing the dwell time and increase the rate at which a volume can be interrogated. Real-time processing of target information with iterative and non-linear solutions is possible now with the advent of GPU-based graphics processing hardware. Simulations show promising results.
Development and Evaluation of a Learning-based Model for Real-time Haptic Texture Rendering
Dec 27, 2022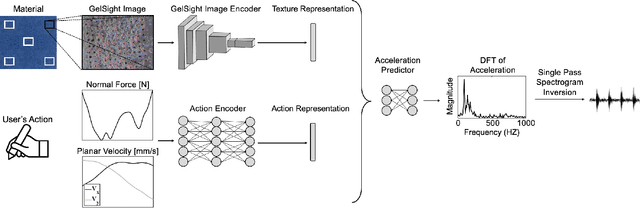

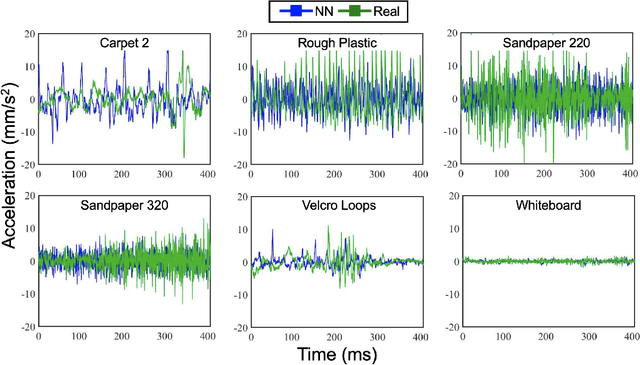

Current Virtual Reality (VR) environments lack the rich haptic signals that humans experience during real-life interactions, such as the sensation of texture during lateral movement on a surface. Adding realistic haptic textures to VR environments requires a model that generalizes to variations of a user's interaction and to the wide variety of existing textures in the world. Current methodologies for haptic texture rendering exist, but they usually develop one model per texture, resulting in low scalability. We present a deep learning-based action-conditional model for haptic texture rendering and evaluate its perceptual performance in rendering realistic texture vibrations through a multi part human user study. This model is unified over all materials and uses data from a vision-based tactile sensor (GelSight) to render the appropriate surface conditioned on the user's action in real time. For rendering texture, we use a high-bandwidth vibrotactile transducer attached to a 3D Systems Touch device. The result of our user study shows that our learning-based method creates high-frequency texture renderings with comparable or better quality than state-of-the-art methods without the need for learning a separate model per texture. Furthermore, we show that the method is capable of rendering previously unseen textures using a single GelSight image of their surface.
AttenFace: A Real Time Attendance System using Face Recognition
Nov 14, 2022
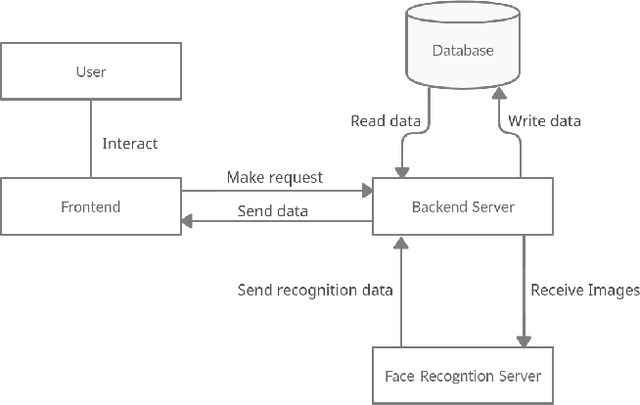
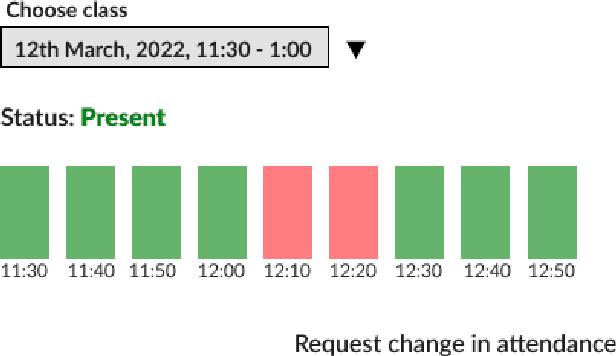
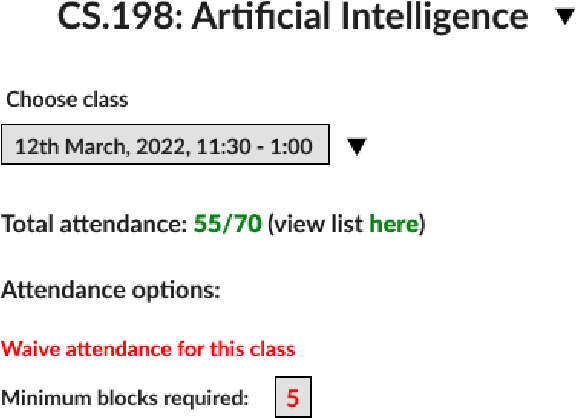
The current approach to marking attendance in colleges is tedious and time consuming. I propose AttenFace, a standalone system to analyze, track and grant attendance in real time using face recognition. Using snapshots of class from live camera feed, the system identifies students and marks them as present in a class based on their presence in multiple snapshots taken throughout the class duration. Face recognition for each class is performed independently and in parallel, ensuring that the system scales with number of concurrent classes. Further, the separation of the face recognition server from the back-end server for attendance calculation allows the face recognition module to be integrated with existing attendance tracking software like Moodle. The face recognition algorithm runs at 10 minute intervals on classroom snapshots, significantly reducing computation compared to direct processing of live camera feed. This method also provides students the flexibility to leave class for a short duration (such as for a phone call) without losing attendance for that class. Attendance is granted to a student if he remains in class for a number of snapshots above a certain threshold. The system is fully automatic and requires no professor intervention or any form of manual attendance or even camera set-up, since the back-end directly interfaces with in-class cameras. AttenFace is a first-of-its-kind one-stop solution for face-recognition-enabled attendance in educational institutions that prevents proxy, handling all aspects from students checking attendance to professors deciding their own attendance policy, to college administration enforcing default attendance rules.
Inflation forecasting with attention based transformer neural networks
Mar 29, 2023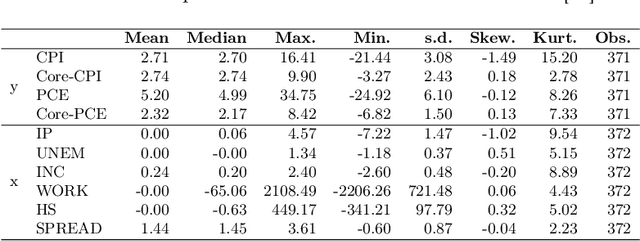
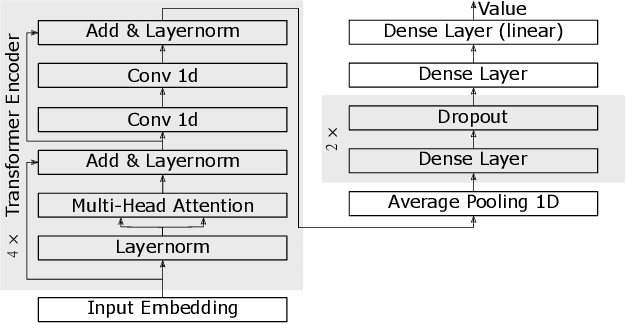
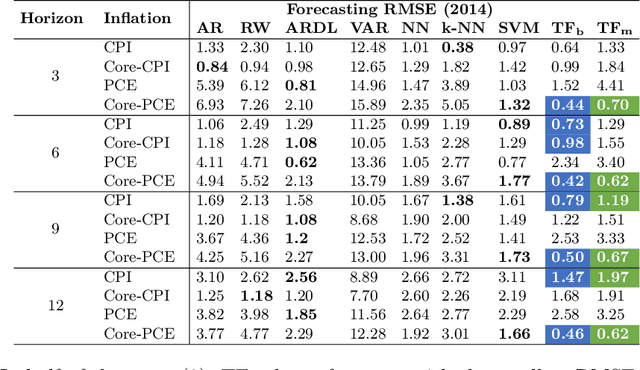
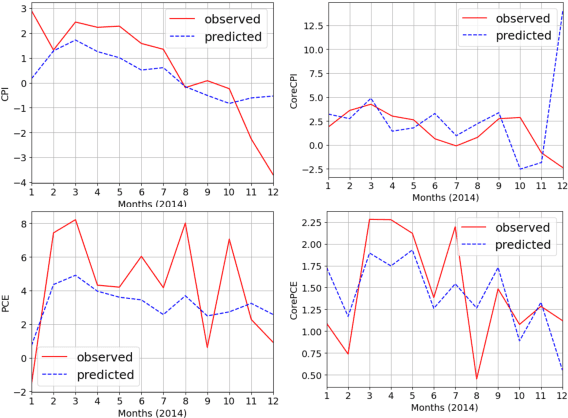
Inflation is a major determinant for allocation decisions and its forecast is a fundamental aim of governments and central banks. However, forecasting inflation is not a trivial task, as its prediction relies on low frequency, highly fluctuating data with unclear explanatory variables. While classical models show some possibility of predicting inflation, reliably beating the random walk benchmark remains difficult. Recently, (deep) neural networks have shown impressive results in a multitude of applications, increasingly setting the new state-of-the-art. This paper investigates the potential of the transformer deep neural network architecture to forecast different inflation rates. The results are compared to a study on classical time series and machine learning models. We show that our adapted transformer, on average, outperforms the baseline in 6 out of 16 experiments, showing best scores in two out of four investigated inflation rates. Our results demonstrate that a transformer based neural network can outperform classical regression and machine learning models in certain inflation rates and forecasting horizons.
Learning Complicated Manipulation Skills via Deterministic Policy with Limited Demonstrations
Mar 29, 2023Combined with demonstrations, deep reinforcement learning can efficiently develop policies for manipulators. However, it takes time to collect sufficient high-quality demonstrations in practice. And human demonstrations may be unsuitable for robots. The non-Markovian process and over-reliance on demonstrations are further challenges. For example, we found that RL agents are sensitive to demonstration quality in manipulation tasks and struggle to adapt to demonstrations directly from humans. Thus it is challenging to leverage low-quality and insufficient demonstrations to assist reinforcement learning in training better policies, and sometimes, limited demonstrations even lead to worse performance. We propose a new algorithm named TD3fG (TD3 learning from a generator) to solve these problems. It forms a smooth transition from learning from experts to learning from experience. This innovation can help agents extract prior knowledge while reducing the detrimental effects of the demonstrations. Our algorithm performs well in Adroit manipulator and MuJoCo tasks with limited demonstrations.
A Compositional Approach to Certifying the Almost Global Asymptotic Stability of Cascade Systems
Mar 29, 2023
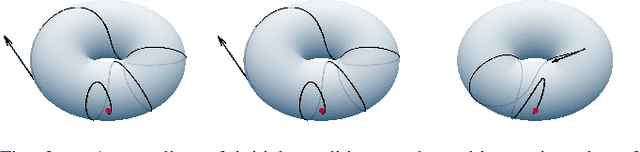
In this work, we give sufficient conditions for the almost global asymptotic stability of a cascade in which the inner loop and the unforced outer loop are each almost globally asymptotically stable. Our qualitative approach relies on the absence of chain recurrence for non-equilibrium points of the unforced outer loop, the hyperbolicity of equilibria, and the precompactness of forward trajectories. We show that the required structure of the chain recurrent set can be readily verified, and describe two important classes of systems with this property. We also show that the precompactness requirement can be verified by growth rate conditions on the interconnection term coupling the subsystems. Our results stand in contrast to prior works that require either global asymptotic stability of the subsystems (impossible for smooth systems evolving on general manifolds), time scale separation between the subsystems, or strong disturbance robustness properties of the outer loop. The approach has clear applications in stability certification of cascaded controllers for systems evolving on manifolds.
Training Neural Networks is NP-Hard in Fixed Dimension
Mar 29, 2023
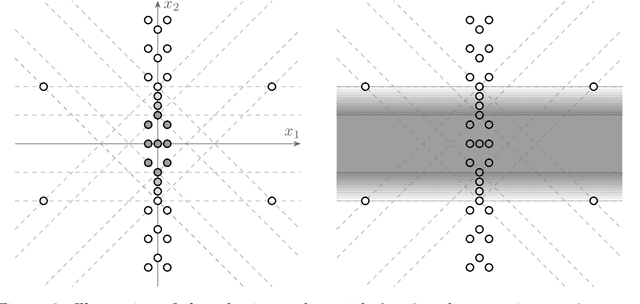
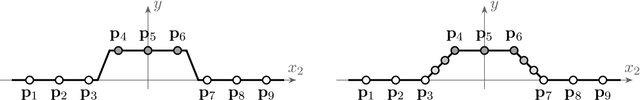
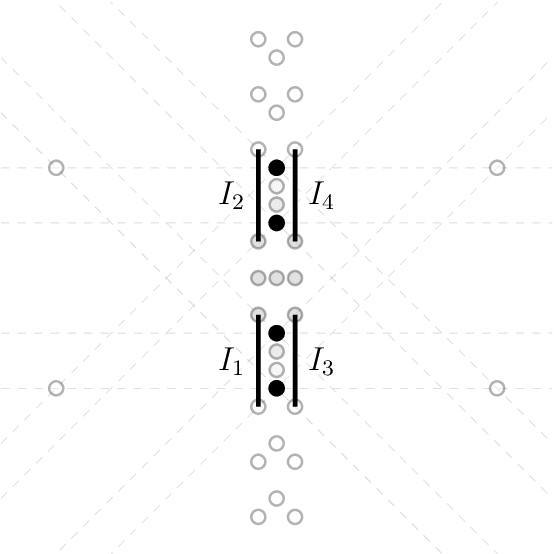
We study the parameterized complexity of training two-layer neural networks with respect to the dimension of the input data and the number of hidden neurons, considering ReLU and linear threshold activation functions. Albeit the computational complexity of these problems has been studied numerous times in recent years, several questions are still open. We answer questions by Arora et al. [ICLR '18] and Khalife and Basu [IPCO '22] showing that both problems are NP-hard for two dimensions, which excludes any polynomial-time algorithm for constant dimension. We also answer a question by Froese et al. [JAIR '22] proving W[1]-hardness for four ReLUs (or two linear threshold neurons) with zero training error. Finally, in the ReLU case, we show fixed-parameter tractability for the combined parameter number of dimensions and number of ReLUs if the network is assumed to compute a convex map. Our results settle the complexity status regarding these parameters almost completely.
Who You Play Affects How You Play: Predicting Sports Performance Using Graph Attention Networks With Temporal Convolution
Mar 29, 2023
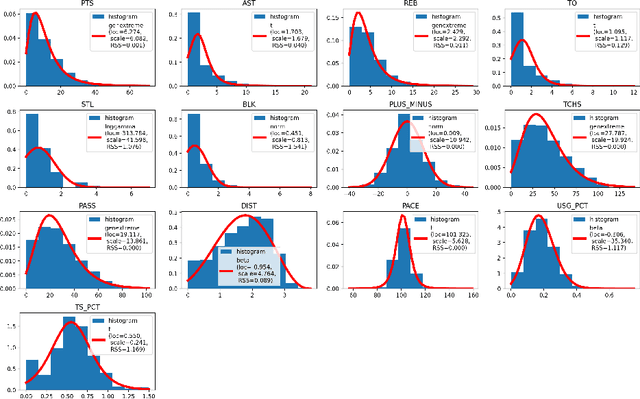
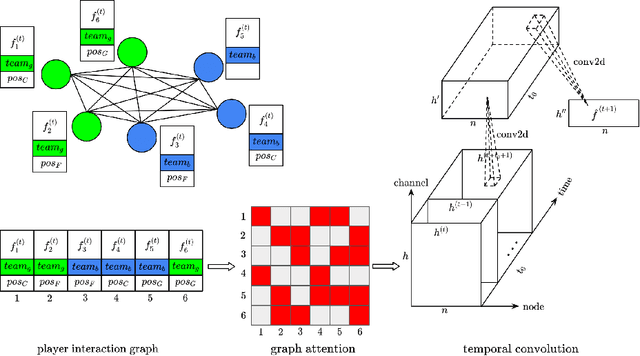
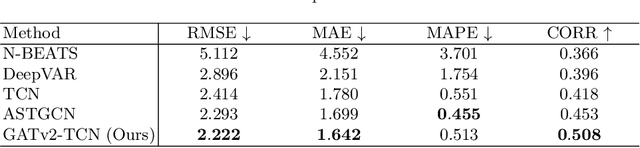
This study presents a novel deep learning method, called GATv2-GCN, for predicting player performance in sports. To construct a dynamic player interaction graph, we leverage player statistics and their interactions during gameplay. We use a graph attention network to capture the attention that each player pays to each other, allowing for more accurate modeling of the dynamic player interactions. To handle the multivariate player statistics time series, we incorporate a temporal convolution layer, which provides the model with temporal predictive power. We evaluate the performance of our model using real-world sports data, demonstrating its effectiveness in predicting player performance. Furthermore, we explore the potential use of our model in a sports betting context, providing insights into profitable strategies that leverage our predictive power. The proposed method has the potential to advance the state-of-the-art in player performance prediction and to provide valuable insights for sports analytics and betting industries.