 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint Device Activity Detection, Channel Estimation and Signal Detection for Massive Grant-free Access via BiGAMP
Apr 03, 2023
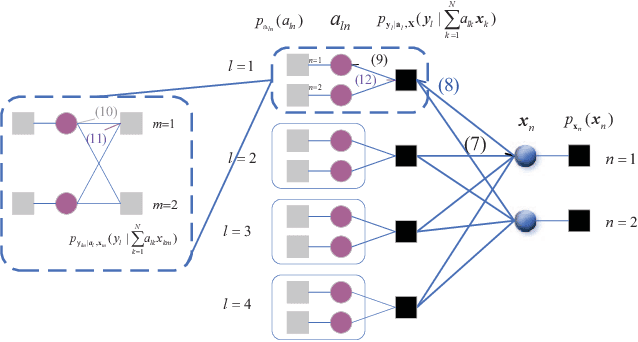
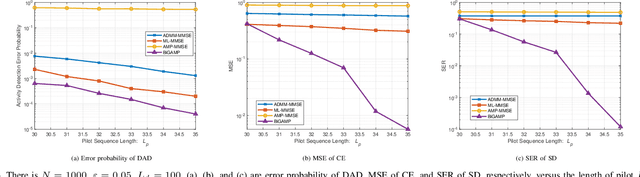
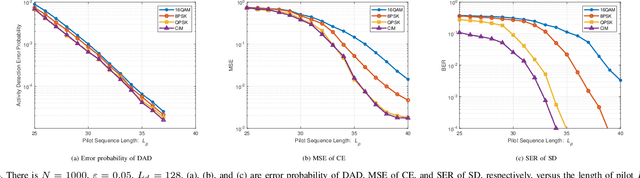
Massive access has been challenging for the fifth generation (5G) and beyond since the abundance of devices causes communication overload to skyrocket. In an uplink massive access scenario, device traffic is sporadic in any given coherence time. Thus, channels across the antennas of each device exhibit correlation, which can be characterized by the row sparse channel matrix structure. In this work, we develop a bilinear generalized approximate message passing (BiGAMP) algorithm based on the row sparse channel matrix structure. This algorithm can jointly detect device activities, estimate channels, and detect signals in massive multiple-input multiple-output (MIMO) systems by alternating updates between channel matrices and signal matrices. The signal observation provides additional information for performance improvement compared to the existing algorithms. We further analyze state evolution (SE) to measure the performance of the proposed algorithm and characterize the convergence condition for SE. Moreover, we perform theoretical analysis on the error probability of device activity detection, the mean square error of channel estimation, and the symbol error rate of signal detection. The numerical results demonstrate the superiority of the proposed algorithm over the state-of-the-art methods in DADCE-SD, and the numerical results are relatively close to the theoretical analysis results.
Learning robotic milling strategies based on passive variable operational space interaction control
Apr 03, 2023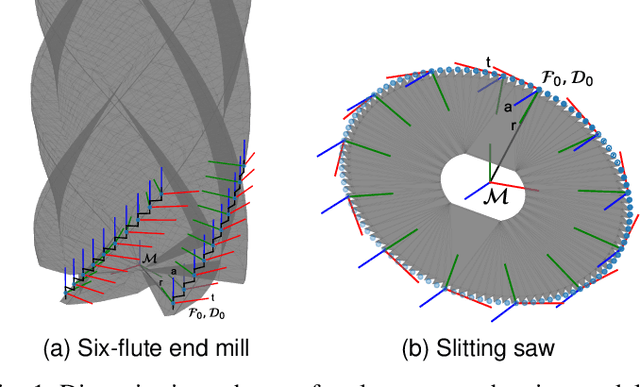
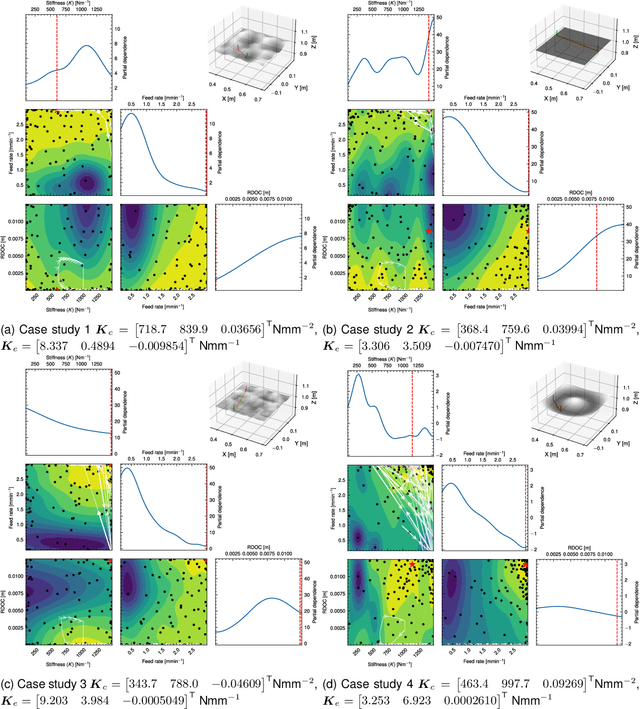
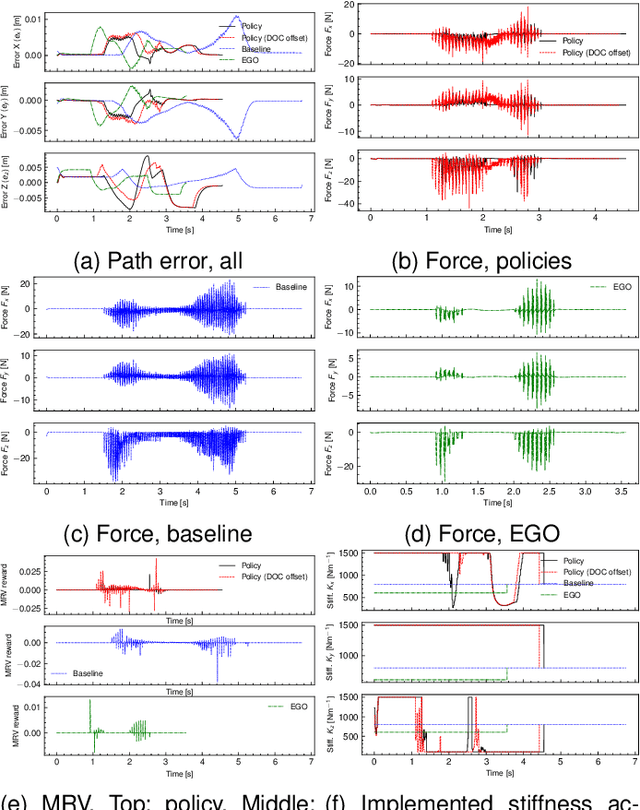
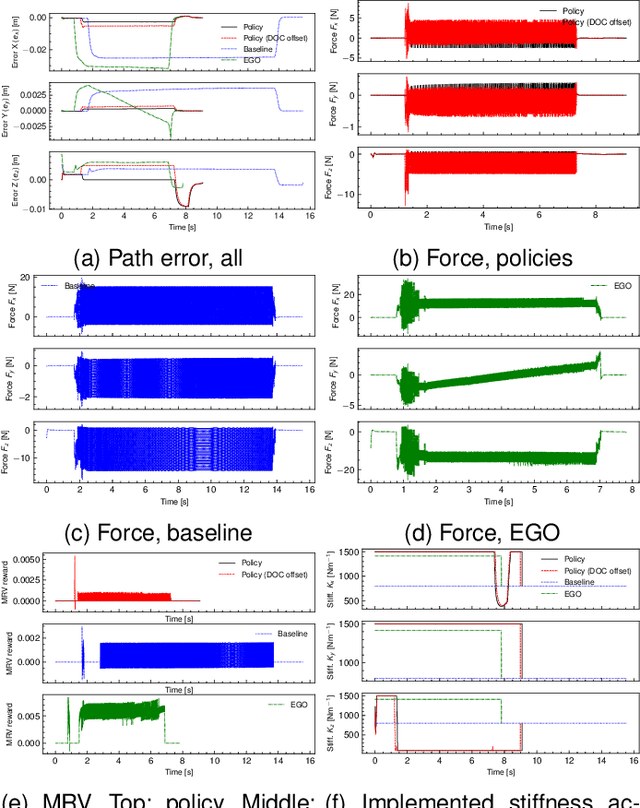
This paper addresses the problem of robotic cutting during disassembly of products for materials separation and recycling. Waste handling applications differ from milling in manufacturing processes, as they engender considerable variety and uncertainty in the parameters (e.g. hardness) of materials which the robot must cut. To address this challenge, we propose a learning-based approach incorporating elements of interaction control, in which the robot can adapt key parameters, such as feed rate, depth of cut, and mechanical compliance during task execution. We show how a mathematical model of cutting mechanics, embedded in a simulation environment, can be used to rapidly train the system without needing large amounts of data from physical cutting trials. The simulation approach was validated on a real robot setup based on four case study materials with varying structural and mechanical properties. We demonstrate the proposed method minimises process force and path deviations to a level similar to offline optimal planning methods, while the average time to complete a cutting task is within 25% of the optimum, at the expense of reduced volume of material removed per pass. A key advantage of our approach over similar works is that no prior knowledge about the material is required.
Lithium-ion Battery Online Knee Onset Detection by Matrix Profile
Apr 03, 2023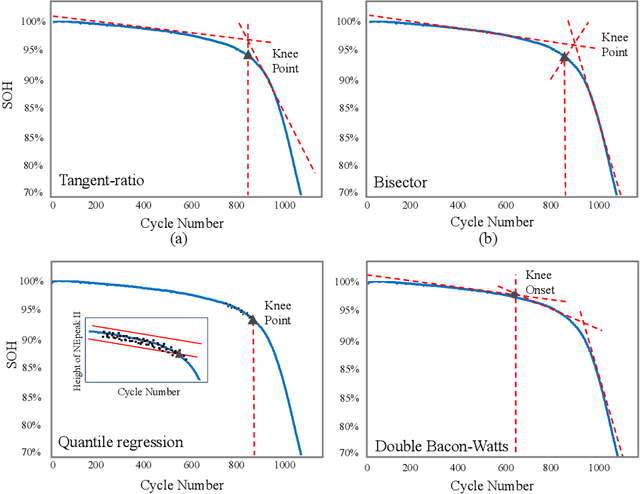
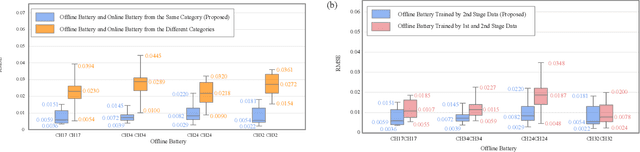
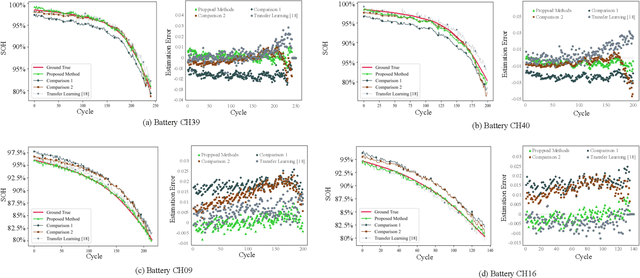

Lithium-ion batteries (LiBs) degrade slightly until the knee onset, after which the deterioration accelerates to end of life (EOL). The knee onset, which marks the initiation of the accelerated degradation rate, is crucial in providing an early warning of the battery's performance changes. However, there is only limited literature on online knee onset identification. Furthermore, it is good to perform such identification using easily collected measurements. To solve these challenges, an online knee onset identification method is developed by exploiting the temporal information within the discharge data. First, the temporal dynamics embedded in the discharge voltage cycles from the slight degradation stage are extracted by the dynamic time warping. Second, the anomaly is exposed by Matrix Profile during subsequence similarity search. The knee onset is detected when the temporal dynamics of the new cycle exceed the control limit and the profile index indicates a change in regime. Finally, the identified knee onset is utilized to categorize the battery into long-range or short-range categories by its strong correlation with the battery's EOL cycles. With the support of the battery categorization and the training data acquired under the same statistic distribution, the proposed SOH estimation model achieves enhanced estimation results with a root mean squared error as low as 0.22%.
Development of A Real-time POCUS Image Quality Assessment and Acquisition Guidance System
Dec 19, 2022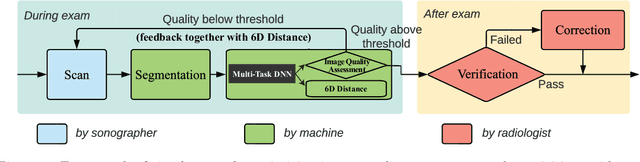
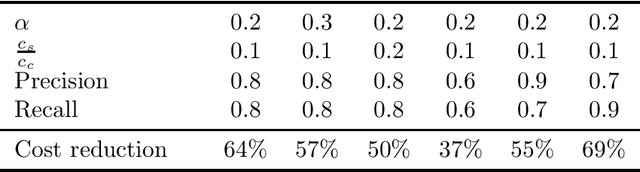
Point-of-care ultrasound (POCUS) is one of the most commonly applied tools for cardiac function imaging in the clinical routine of the emergency department and pediatric intensive care unit. The prior studies demonstrate that AI-assisted software can guide nurses or novices without prior sonography experience to acquire POCUS by recognizing the interest region, assessing image quality, and providing instructions. However, these AI algorithms cannot simply replace the role of skilled sonographers in acquiring diagnostic-quality POCUS. Unlike chest X-ray, CT, and MRI, which have standardized imaging protocols, POCUS can be acquired with high inter-observer variability. Though being with variability, they are usually all clinically acceptable and interpretable. In challenging clinical environments, sonographers employ novel heuristics to acquire POCUS in complex scenarios. To help novice learners to expedite the training process while reducing the dependency on experienced sonographers in the curriculum implementation, We will develop a framework to perform real-time AI-assisted quality assessment and probe position guidance to provide training process for novice learners with less manual intervention.
Predicting the Initial Conditions of the Universe using Deep Learning
Mar 23, 2023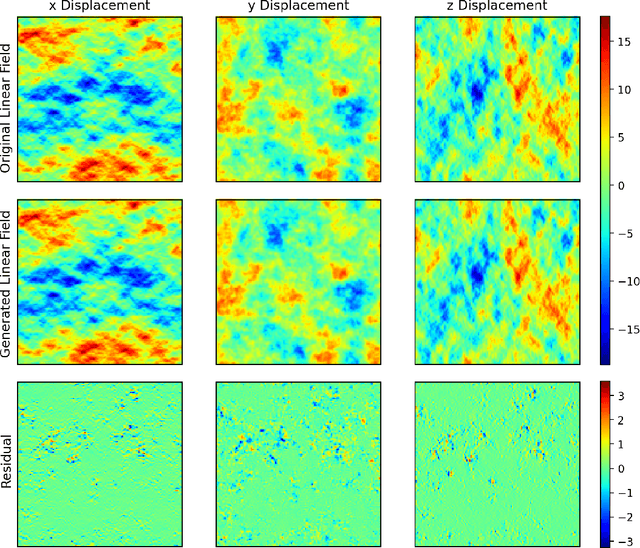
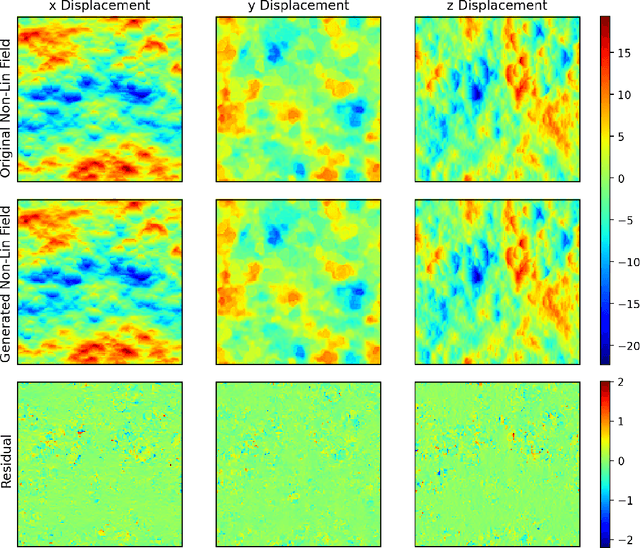
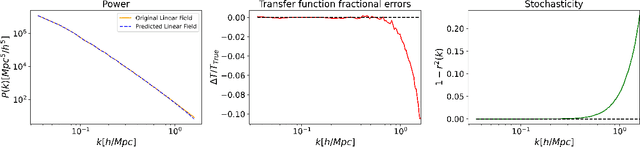
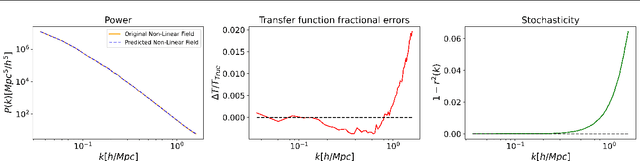
Finding the initial conditions that led to the current state of the universe is challenging because it involves searching over a vast input space of initial conditions, along with modeling their evolution via tools such as N-body simulations which are computationally expensive. Deep learning has emerged as an alternate modeling tool that can learn the mapping between the linear input of an N-body simulation and the final nonlinear displacements at redshift zero, which can significantly accelerate the forward modeling. However, this does not help reduce the search space for initial conditions. In this paper, we demonstrate for the first time that a deep learning model can be trained for the reverse mapping. We train a V-Net based convolutional neural network, which outputs the linear displacement of an N-body system, given the current time nonlinear displacement and the cosmological parameters of the system. We demonstrate that this neural network accurately recovers the initial linear displacement field over a wide range of scales ($<1$-$2\%$ error up to nearly $k = 1\ \mathrm{Mpc}^{-1}\,h$), despite the ill-defined nature of the inverse problem at smaller scales. Specifically, smaller scales are dominated by nonlinear effects which makes the backward dynamics much more susceptible to numerical and computational errors leading to highly divergent backward trajectories and a one-to-many backward mapping. The results of our method motivate that neural network based models can act as good approximators of the initial linear states and their predictions can serve as good starting points for sampling-based methods to infer the initial states of the universe.
Real-Time Marker Localization Learning for GelStereo Tactile Sensing
Nov 24, 2022
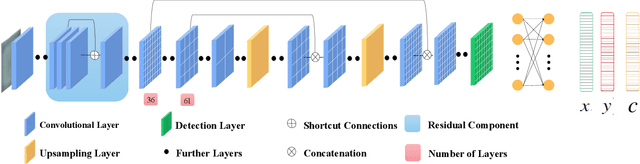
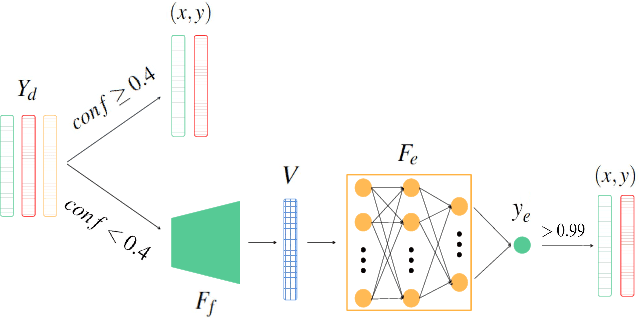
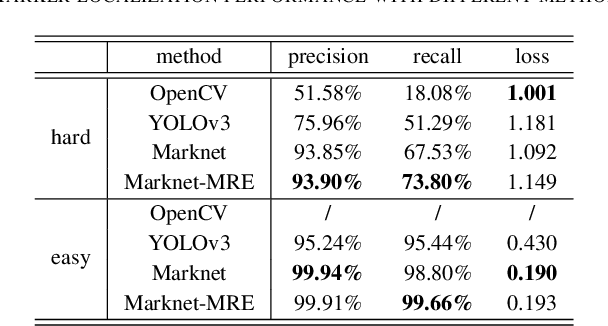
Visuotactile sensing technology is becoming more popular in tactile sensing, but the effectiveness of the existing marker detection localization methods remains to be further explored. Instead of contour-based blob detection, this paper presents a learning-based marker localization network for GelStereo visuotactile sensing called Marknet. Specifically, the Marknet presents a grid regression architecture to incorporate the distribution of the GelStereo markers. Furthermore, a marker rationality evaluator (MRE) is modelled to screen suitable prediction results. The experimental results show that the Marknet combined with MRE achieves 93.90% precision for irregular markers in contact areas, which outperforms the traditional contour-based blob detection method by a large margin of 42.32%. Meanwhile, the proposed learning-based marker localization method can achieve better real-time performance beyond the blob detection interface provided by the OpenCV library through GPU acceleration, which we believe will lead to considerable perceptual sensitivity gains in various robotic manipulation tasks.
Forecasting Solar Irradiance without Direct Observation: An Empirical Analysis
Mar 10, 2023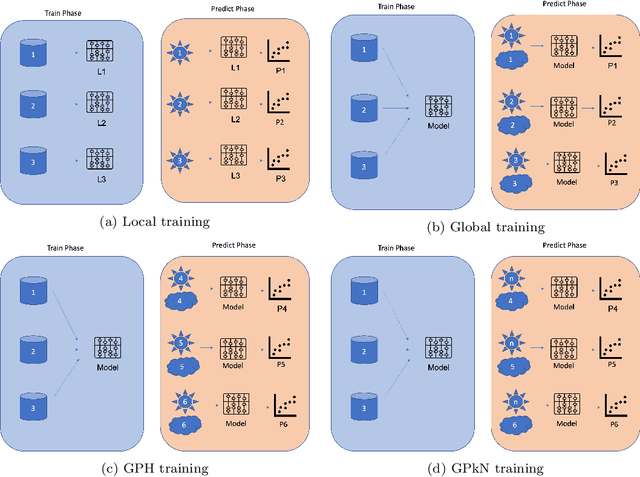
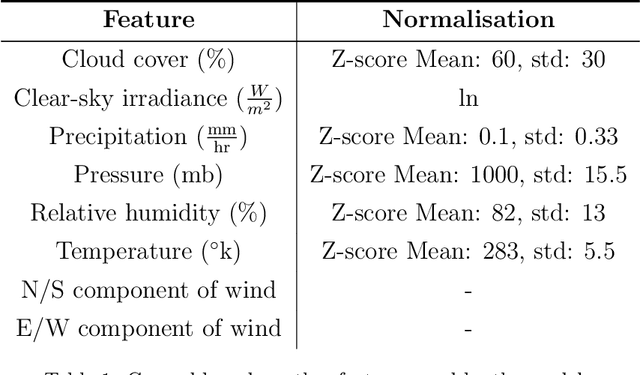
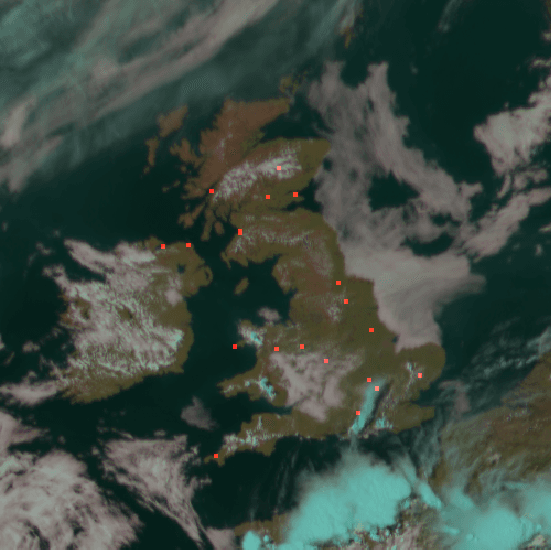
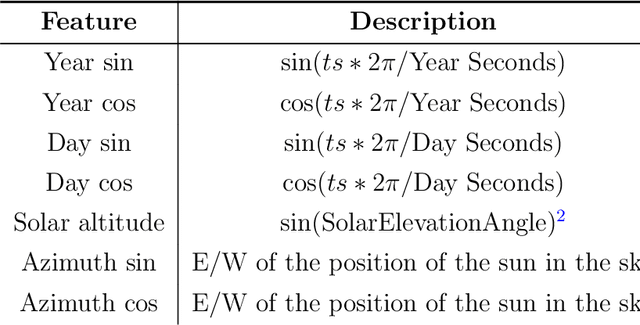
As the use of solar power increases, having accurate and timely forecasters will be essential for smooth grid operators. There are many proposed methods for forecasting solar irradiance / solar power production. However, many of these methods formulate the problem as a time-series, relying on near real-time access to observations at the location of interest to generate forecasts. This requires both access to a real-time stream of data and enough historical observations for these methods to be deployed. In this paper, we conduct a thorough analysis of effective ways to formulate the forecasting problem comparing classical machine learning approaches to state-of-the-art deep learning. Using data from 20 locations distributed throughout the UK and commercially available weather data, we show that it is possible to build systems that do not require access to this data. Leveraging weather observations and measurements from other locations we show it is possible to create models capable of accurately forecasting solar irradiance at new locations. We utilise compare both satellite and ground observations (e.g. temperature, pressure) of weather data. This could facilitate use planning and optimisation for both newly deployed solar farms and domestic installations from the moment they come online. Additionally, we show that training a single global model for multiple locations can produce a more robust model with more consistent and accurate results across locations.
Do we need entire training data for adversarial training?
Mar 10, 2023
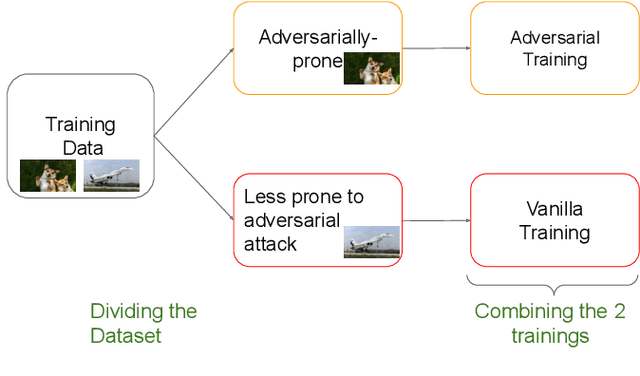

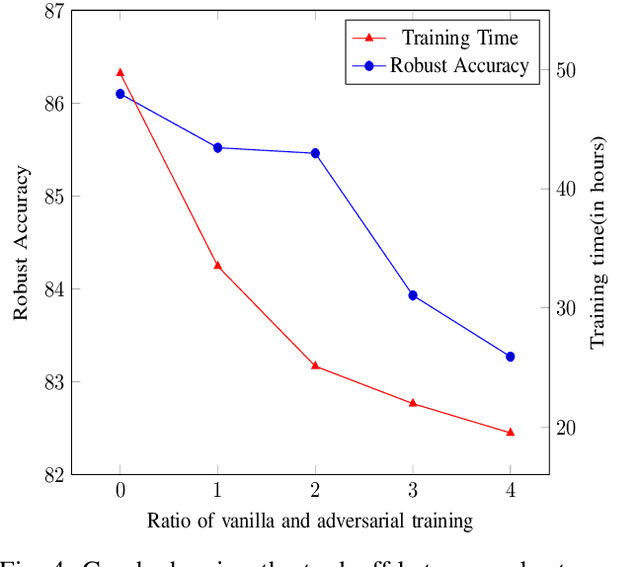
Deep Neural Networks (DNNs) are being used to solve a wide range of problems in many domains including safety-critical domains like self-driving cars and medical imagery. DNNs suffer from vulnerability against adversarial attacks. In the past few years, numerous approaches have been proposed to tackle this problem by training networks using adversarial training. Almost all the approaches generate adversarial examples for the entire training dataset, thus increasing the training time drastically. We show that we can decrease the training time for any adversarial training algorithm by using only a subset of training data for adversarial training. To select the subset, we filter the adversarially-prone samples from the training data. We perform a simple adversarial attack on all training examples to filter this subset. In this attack, we add a small perturbation to each pixel and a few grid lines to the input image. We perform adversarial training on the adversarially-prone subset and mix it with vanilla training performed on the entire dataset. Our results show that when our method-agnostic approach is plugged into FGSM, we achieve a speedup of 3.52x on MNIST and 1.98x on the CIFAR-10 dataset with comparable robust accuracy. We also test our approach on state-of-the-art Free adversarial training and achieve a speedup of 1.2x in training time with a marginal drop in robust accuracy on the ImageNet dataset.
A hybrid deep-learning-metaheuristic framework to approximate discrete road network design problems
Mar 10, 2023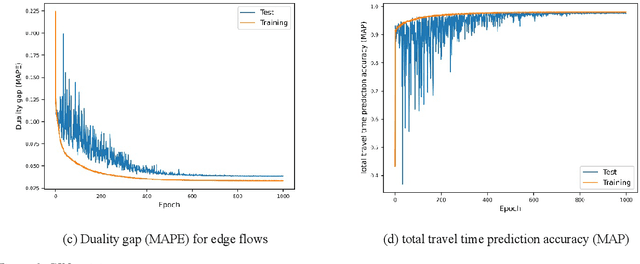

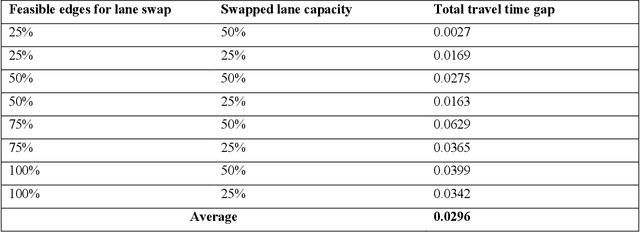
This study proposes a hybrid deep-learning-metaheuristic framework with a bi-level architecture to solve road network design problems (NDPs). We train a graph neural network (GNN) to approximate the solution of the user equilibrium (UE) traffic assignment problem, and use inferences made by the trained model to calculate fitness function evaluations of a genetic algorithm (GA) to approximate solutions for NDPs. Using two NDP variants and an exact solver as benchmark, we show that our proposed framework can provide solutions within 5% gap of the global optimum results given less than 1% of the time required for finding the optimal results. Moreover, we observe many interesting future directions, thus we propose a brief research agenda for this topic. The key observation inspiring influential future research was that fitness function evaluation time using the inferences made by the GNN model for the genetic algorithm was in the order of milliseconds, which points to an opportunity and a need for novel heuristics that 1) can cope well with noisy fitness function values provided by neural networks, and 2) can use the significantly higher computation time provided to them to explore the search space effectively (rather than efficiently). This opens a new avenue for a modern class of metaheuristics that are crafted for use with AI-powered predictors.
Locally Regularized Neural Differential Equations: Some Black Boxes Were Meant to Remain Closed!
Mar 10, 2023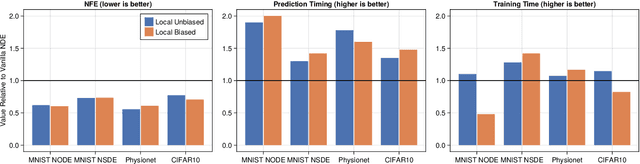
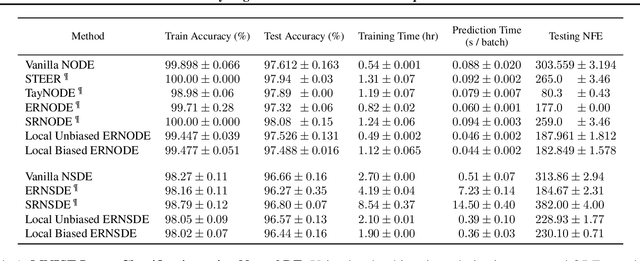
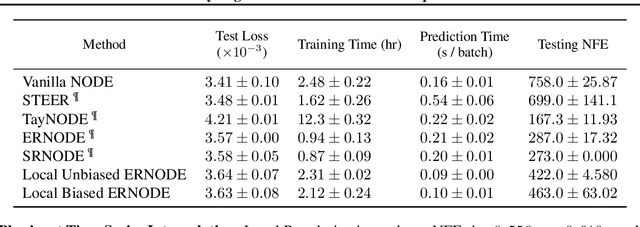
Implicit layer deep learning techniques, like Neural Differential Equations, have become an important modeling framework due to their ability to adapt to new problems automatically. Training a neural differential equation is effectively a search over a space of plausible dynamical systems. However, controlling the computational cost for these models is difficult since it relies on the number of steps the adaptive solver takes. Most prior works have used higher-order methods to reduce prediction timings while greatly increasing training time or reducing both training and prediction timings by relying on specific training algorithms, which are harder to use as a drop-in replacement due to strict requirements on automatic differentiation. In this manuscript, we use internal cost heuristics of adaptive differential equation solvers at stochastic time points to guide the training toward learning a dynamical system that is easier to integrate. We "close the black-box" and allow the use of our method with any adjoint technique for gradient calculations of the differential equation solution. We perform experimental studies to compare our method to global regularization to show that we attain similar performance numbers without compromising the flexibility of implementation on ordinary differential equations (ODEs) and stochastic differential equations (SDEs). We develop two sampling strategies to trade off between performance and training time. Our method reduces the number of function evaluations to 0.556-0.733x and accelerates predictions by 1.3-2x.