 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diffusion Bridge Mixture Transports, Schrödinger Bridge Problems and Generative Modeling
Apr 03, 2023
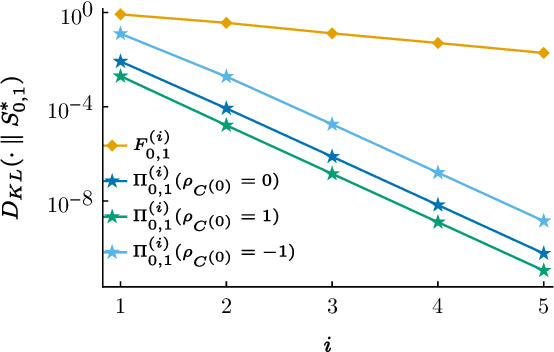

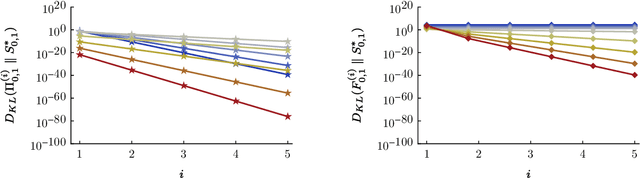

The dynamic Schr\"odinger bridge problem seeks a stochastic process that defines a transport between two target probability measures, while optimally satisfying the criteria of being closest, in terms of Kullback-Leibler divergence, to a reference process. We propose a novel sampling-based iterative algorithm, the iterated diffusion bridge mixture transport (IDBM), aimed at solving the dynamic Schr\"odinger bridge problem. The IDBM procedure exhibits the attractive property of realizing a valid coupling between the target measures at each step. We perform an initial theoretical investigation of the IDBM procedure, establishing its convergence properties. The theoretical findings are complemented by numerous numerical experiments illustrating the competitive performance of the IDBM procedure across various applications. Recent advancements in generative modeling employ the time-reversal of a diffusion process to define a generative process that approximately transports a simple distribution to the data distribution. As an alternative, we propose using the first iteration of the IDBM procedure as an approximation-free method for realizing this transport. This approach offers greater flexibility in selecting the generative process dynamics and exhibits faster training and superior sample quality over longer discretization intervals. In terms of implementation, the necessary modifications are minimally intrusive, being limited to the training loss computation, with no changes necessary for generative sampling.
Tunable Convolutions with Parametric Multi-Loss Optimization
Apr 03, 2023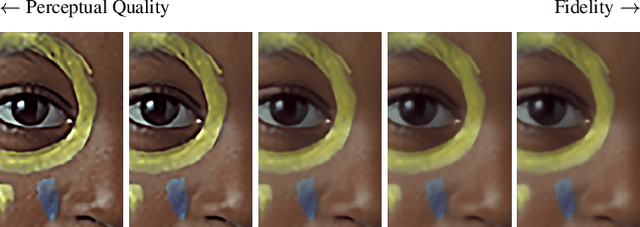
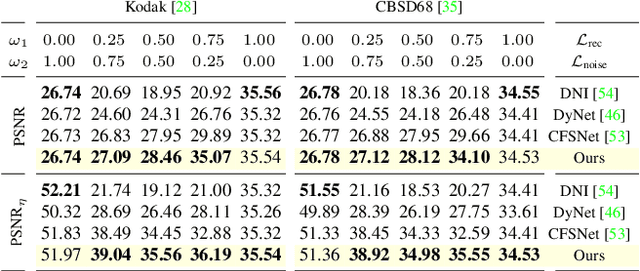
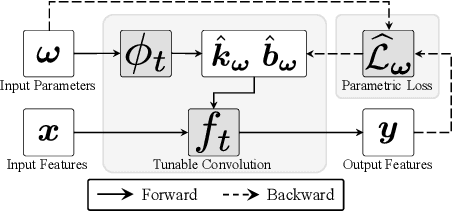
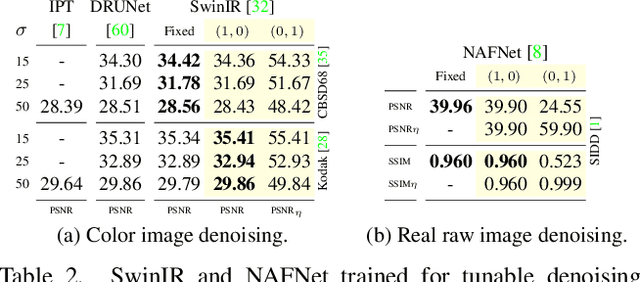
Behavior of neural networks is irremediably determined by the specific loss and data used during training. However it is often desirable to tune the model at inference time based on external factors such as preferences of the user or dynamic characteristics of the data. This is especially important to balance the perception-distortion trade-off of ill-posed image-to-image translation tasks. In this work, we propose to optimize a parametric tunable convolutional layer, which includes a number of different kernels, using a parametric multi-loss, which includes an equal number of objectives. Our key insight is to use a shared set of parameters to dynamically interpolate both the objectives and the kernels. During training, these parameters are sampled at random to explicitly optimize all possible combinations of objectives and consequently disentangle their effect into the corresponding kernels. During inference, these parameters become interactive inputs of the model hence enabling reliable and consistent control over the model behavior. Extensive experimental results demonstrate that our tunable convolutions effectively work as a drop-in replacement for traditional convolutions in existing neural networks at virtually no extra computational cost, outperforming state-of-the-art control strategies in a wide range of applications; including image denoising, deblurring, super-resolution, and style transfer.
Prediction of solar wind speed by applying convolutional neural network to potential field source surface (PFSS) magnetograms
Apr 03, 2023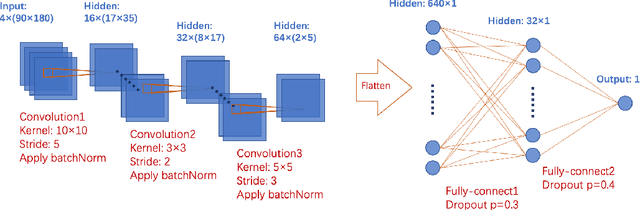
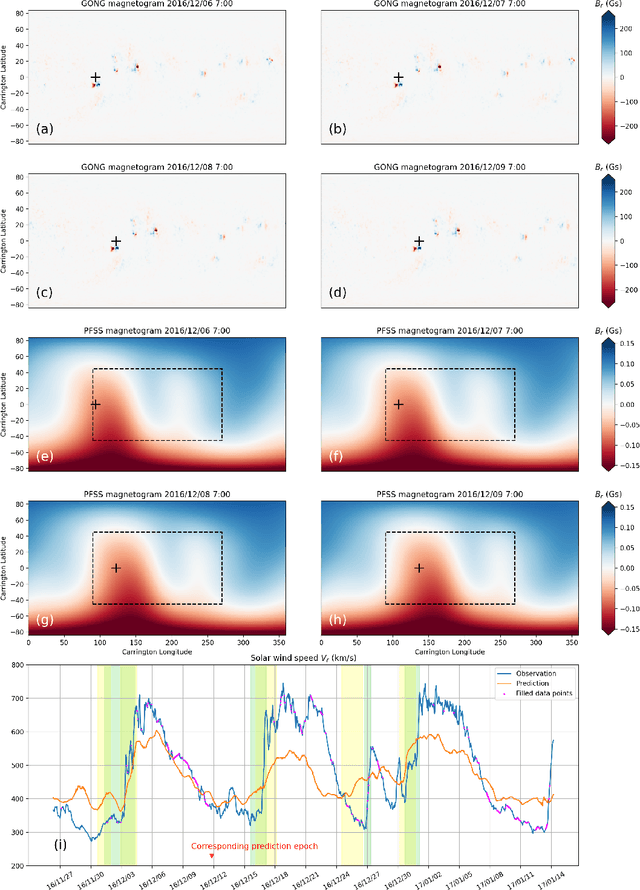
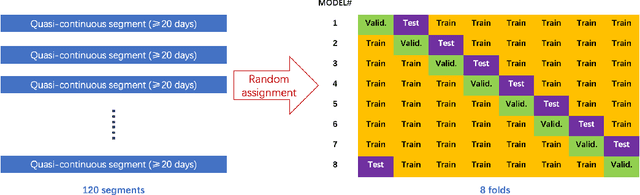
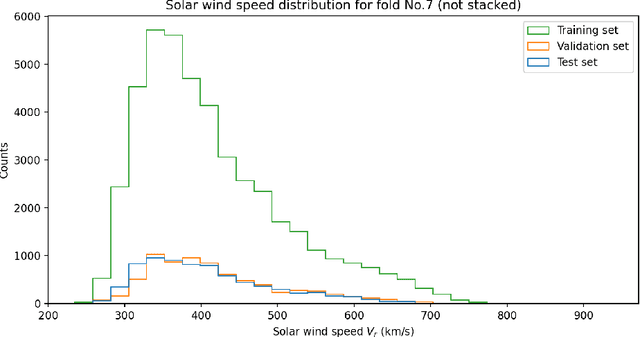
An accurate solar wind speed model is important for space weather predictions, catastrophic event warnings, and other issues concerning solar wind - magnetosphere interaction. In this work, we construct a model based on convolutional neural network (CNN) and Potential Field Source Surface (PFSS) magnetograms, considering a solar wind source surface of $R_{\rm SS}=2.5R_\odot$, aiming to predict the solar wind speed at the Lagrange 1 (L1) point of the Sun-Earth system. The input of our model consists of four Potential Field Source Surface (PFSS) magnetograms at $R_{\rm SS}$, which are 7, 6, 5, and 4 days before the target epoch. Reduced magnetograms are used to promote the model's efficiency. We use the Global Oscillation Network Group (GONG) photospheric magnetograms and the potential field extrapolation model to generate PFSS magnetograms at the source surface. The model provides predictions of the continuous test dataset with an averaged correlation coefficient (CC) of 0.52 and a root mean square error (RMSE) of 80.8 km/s in an eight-fold validation training scheme with the time resolution of the data as small as one hour. The model also has the potential to forecast high speed streams of the solar wind, which can be quantified with a general threat score of 0.39.
Joint Device Activity Detection, Channel Estimation and Signal Detection for Massive Grant-free Access via BiGAMP
Apr 03, 2023
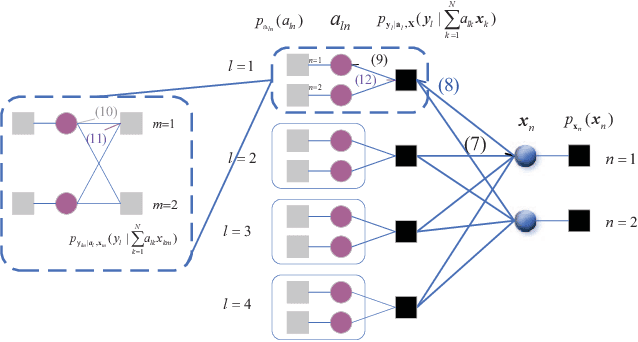
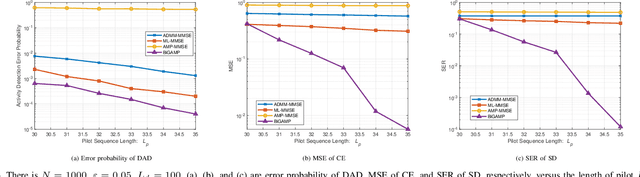
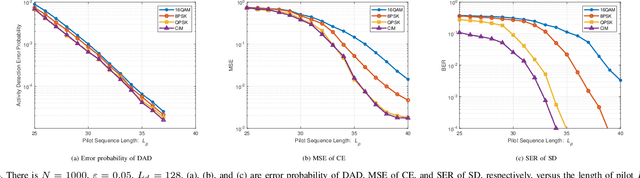
Massive access has been challenging for the fifth generation (5G) and beyond since the abundance of devices causes communication overload to skyrocket. In an uplink massive access scenario, device traffic is sporadic in any given coherence time. Thus, channels across the antennas of each device exhibit correlation, which can be characterized by the row sparse channel matrix structure. In this work, we develop a bilinear generalized approximate message passing (BiGAMP) algorithm based on the row sparse channel matrix structure. This algorithm can jointly detect device activities, estimate channels, and detect signals in massive multiple-input multiple-output (MIMO) systems by alternating updates between channel matrices and signal matrices. The signal observation provides additional information for performance improvement compared to the existing algorithms. We further analyze state evolution (SE) to measure the performance of the proposed algorithm and characterize the convergence condition for SE. Moreover, we perform theoretical analysis on the error probability of device activity detection, the mean square error of channel estimation, and the symbol error rate of signal detection. The numerical results demonstrate the superiority of the proposed algorithm over the state-of-the-art methods in DADCE-SD, and the numerical results are relatively close to the theoretical analysis results.
Learning robotic milling strategies based on passive variable operational space interaction control
Apr 03, 2023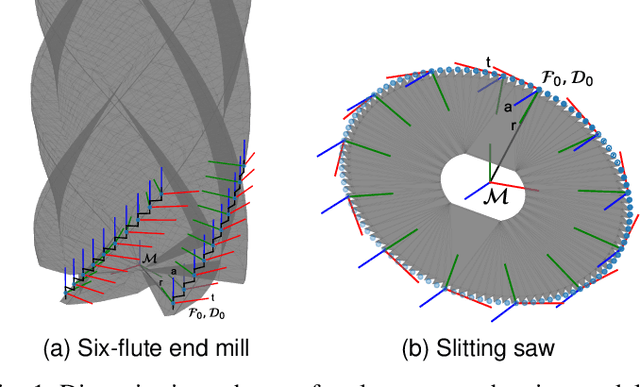
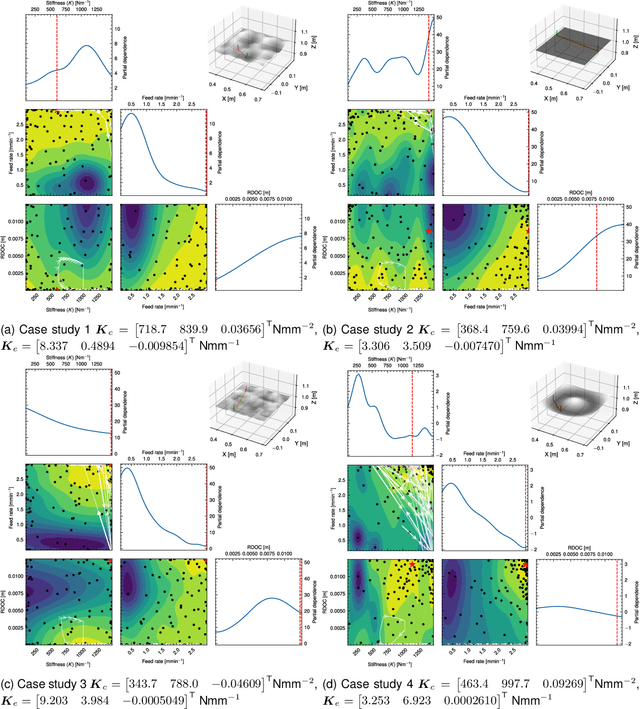
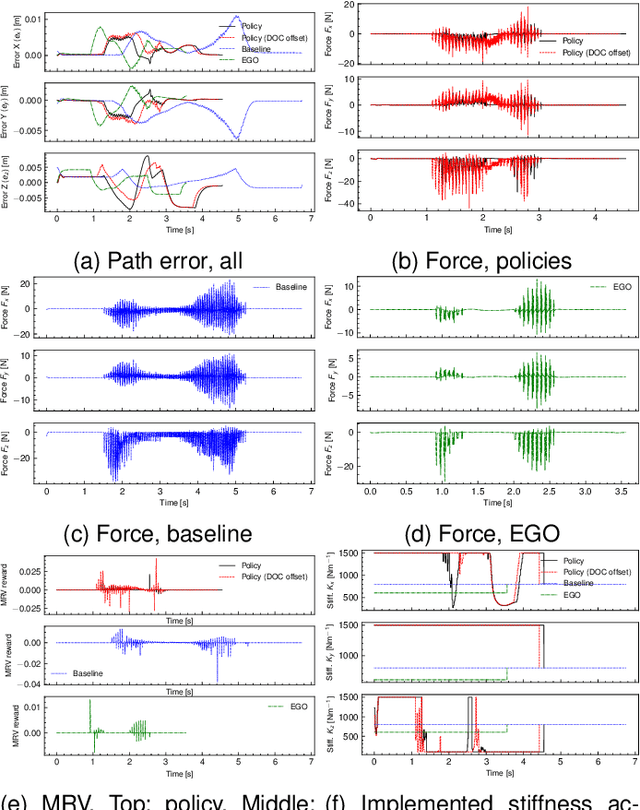
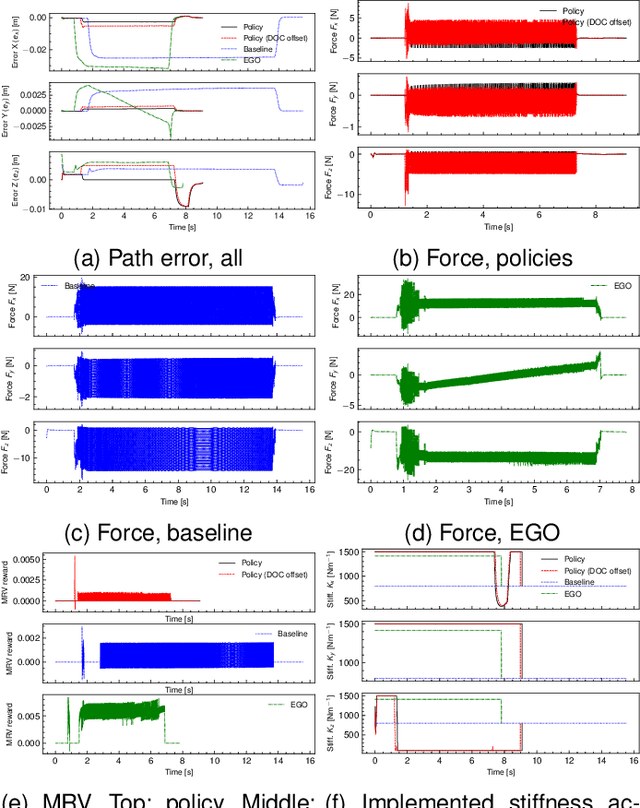
This paper addresses the problem of robotic cutting during disassembly of products for materials separation and recycling. Waste handling applications differ from milling in manufacturing processes, as they engender considerable variety and uncertainty in the parameters (e.g. hardness) of materials which the robot must cut. To address this challenge, we propose a learning-based approach incorporating elements of interaction control, in which the robot can adapt key parameters, such as feed rate, depth of cut, and mechanical compliance during task execution. We show how a mathematical model of cutting mechanics, embedded in a simulation environment, can be used to rapidly train the system without needing large amounts of data from physical cutting trials. The simulation approach was validated on a real robot setup based on four case study materials with varying structural and mechanical properties. We demonstrate the proposed method minimises process force and path deviations to a level similar to offline optimal planning methods, while the average time to complete a cutting task is within 25% of the optimum, at the expense of reduced volume of material removed per pass. A key advantage of our approach over similar works is that no prior knowledge about the material is required.
Lithium-ion Battery Online Knee Onset Detection by Matrix Profile
Apr 03, 2023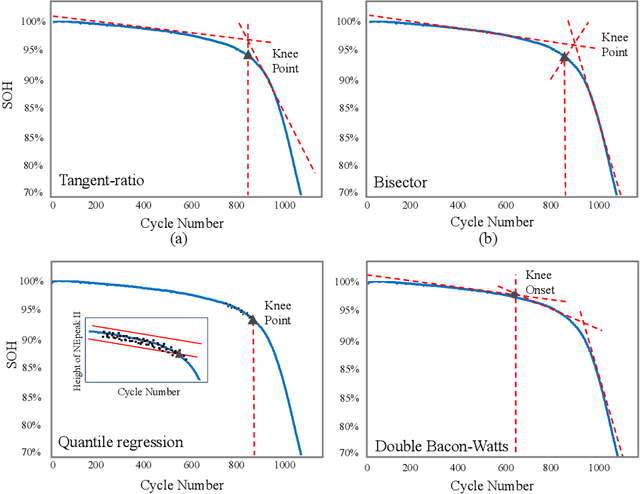
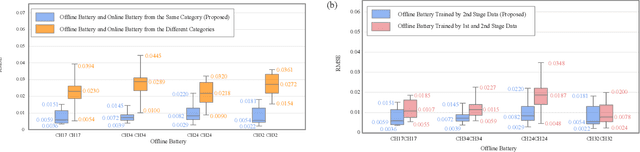
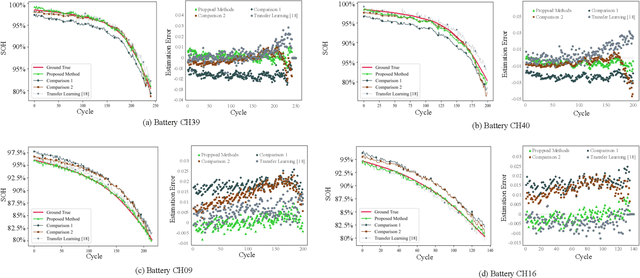

Lithium-ion batteries (LiBs) degrade slightly until the knee onset, after which the deterioration accelerates to end of life (EOL). The knee onset, which marks the initiation of the accelerated degradation rate, is crucial in providing an early warning of the battery's performance changes. However, there is only limited literature on online knee onset identification. Furthermore, it is good to perform such identification using easily collected measurements. To solve these challenges, an online knee onset identification method is developed by exploiting the temporal information within the discharge data. First, the temporal dynamics embedded in the discharge voltage cycles from the slight degradation stage are extracted by the dynamic time warping. Second, the anomaly is exposed by Matrix Profile during subsequence similarity search. The knee onset is detected when the temporal dynamics of the new cycle exceed the control limit and the profile index indicates a change in regime. Finally, the identified knee onset is utilized to categorize the battery into long-range or short-range categories by its strong correlation with the battery's EOL cycles. With the support of the battery categorization and the training data acquired under the same statistic distribution, the proposed SOH estimation model achieves enhanced estimation results with a root mean squared error as low as 0.22%.
Online Camera-to-ground Calibration for Autonomous Driving
Mar 31, 2023
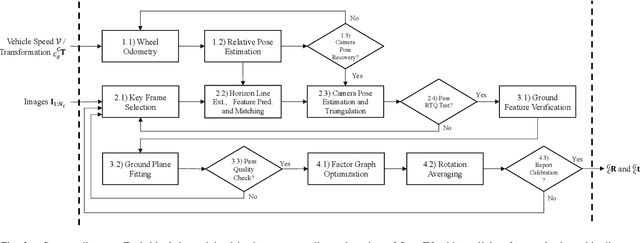
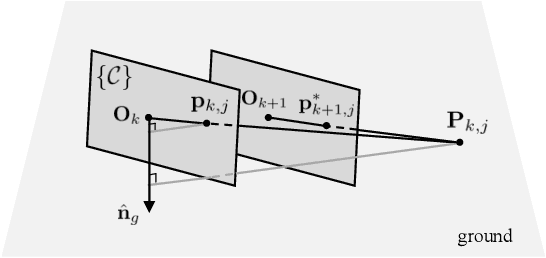
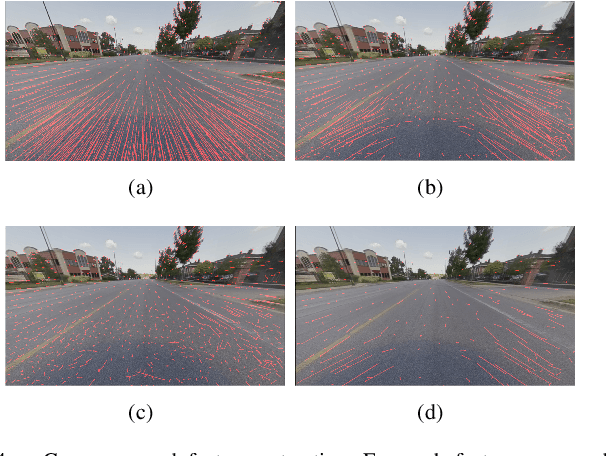
Online camera-to-ground calibration is to generate a non-rigid body transformation between the camera and the road surface in a real-time manner. Existing solutions utilize static calibration, suffering from environmental variations such as tire pressure changes, vehicle loading volume variations, and road surface diversity. Other online solutions exploit the usage of road elements or photometric consistency between overlapping views across images, which require continuous detection of specific targets on the road or assistance with multiple cameras to facilitate calibration. In our work, we propose an online monocular camera-to-ground calibration solution that does not utilize any specific targets while driving. We perform a coarse-to-fine approach for ground feature extraction through wheel odometry and estimate the camera-to-ground calibration parameters through a sliding-window-based factor graph optimization. Considering the non-rigid transformation of camera-to-ground while driving, we provide metrics to quantify calibration performance and stopping criteria to report/broadcast our satisfying calibration results. Extensive experiments using real-world data demonstrate that our algorithm is effective and outperforms state-of-the-art techniques.
CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society
Mar 31, 2023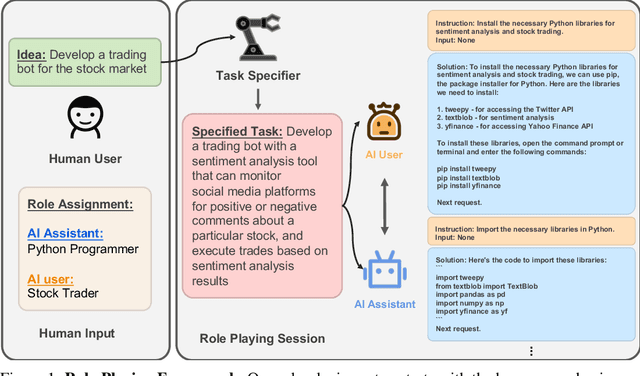


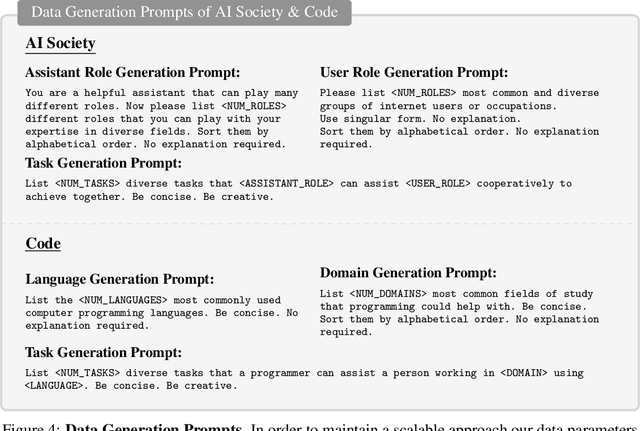
The rapid advancement of conversational and chat-based language models has led to remarkable progress in complex task-solving. However, their success heavily relies on human input to guide the conversation, which can be challenging and time-consuming. This paper explores the potential of building scalable techniques to facilitate autonomous cooperation among communicative agents and provide insight into their "cognitive" processes. To address the challenges of achieving autonomous cooperation, we propose a novel communicative agent framework named role-playing. Our approach involves using inception prompting to guide chat agents toward task completion while maintaining consistency with human intentions. We showcase how role-playing can be used to generate conversational data for studying the behaviors and capabilities of chat agents, providing a valuable resource for investigating conversational language models. Our contributions include introducing a novel communicative agent framework, offering a scalable approach for studying the cooperative behaviors and capabilities of multi-agent systems, and open-sourcing our library to support research on communicative agents and beyond. The GitHub repository of this project is made publicly available on: https://github.com/lightaime/camel.
GVP: Generative Volumetric Primitives
Mar 31, 2023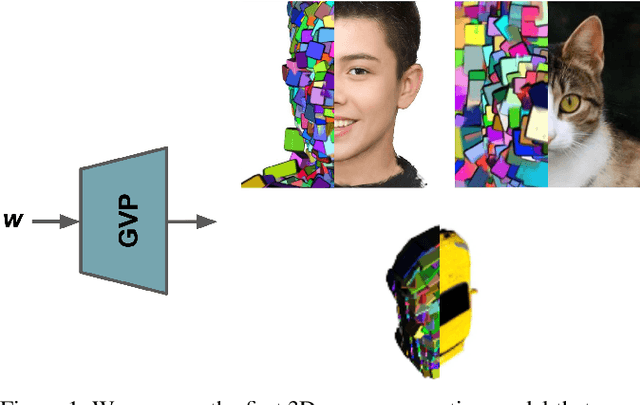
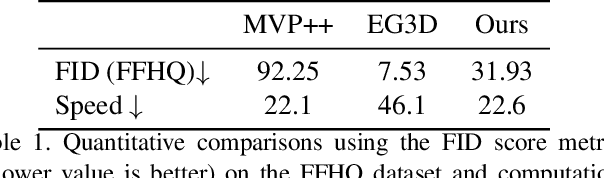
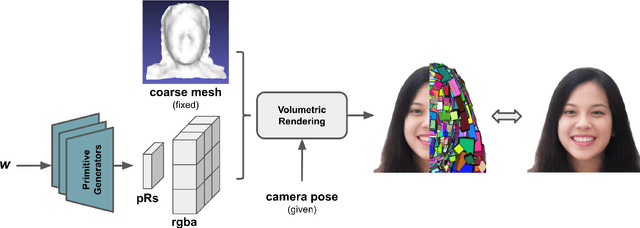

Advances in 3D-aware generative models have pushed the boundary of image synthesis with explicit camera control. To achieve high-resolution image synthesis, several attempts have been made to design efficient generators, such as hybrid architectures with both 3D and 2D components. However, such a design compromises multiview consistency, and the design of a pure 3D generator with high resolution is still an open problem. In this work, we present Generative Volumetric Primitives (GVP), the first pure 3D generative model that can sample and render 512-resolution images in real-time. GVP jointly models a number of volumetric primitives and their spatial information, both of which can be efficiently generated via a 2D convolutional network. The mixture of these primitives naturally captures the sparsity and correspondence in the 3D volume. The training of such a generator with a high degree of freedom is made possible through a knowledge distillation technique. Experiments on several datasets demonstrate superior efficiency and 3D consistency of GVP over the state-of-the-art.
Online Reinforcement Learning in Markov Decision Process Using Linear Programming
Mar 31, 2023We consider online reinforcement learning in episodic Markov decision process (MDP) with an unknown transition matrix and stochastic rewards drawn from a fixed but unknown distribution. The learner aims to learn the optimal policy and minimize their regret over a finite time horizon through interacting with the environment. We devise a simple and efficient model-based algorithm that achieves $\tilde{O}(LX\sqrt{TA})$ regret with high probability, where $L$ is the episode length, $T$ is the number of episodes, and $X$ and $A$ are the cardinalities of the state space and the action space, respectively. The proposed algorithm, which is based on the concept of "optimism in the face of uncertainty", maintains confidence sets of transition and reward functions and uses occupancy measures to connect the online MDP with linear programming. It achieves a tighter regret bound compared to the existing works that use a similar confidence sets framework and improves the computational effort compared to those that use a different framework but with a slightly tighter regret bound.