 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Complexity in Non-Convex Decentralized Learning over Time-Varying Networks
Nov 01, 2022


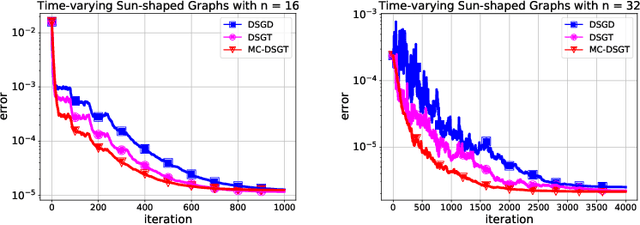
Decentralized optimization with time-varying networks is an emerging paradigm in machine learning. It saves remarkable communication overhead in large-scale deep training and is more robust in wireless scenarios especially when nodes are moving. Federated learning can also be regarded as decentralized optimization with time-varying communication patterns alternating between global averaging and local updates. While numerous studies exist to clarify its theoretical limits and develop efficient algorithms, it remains unclear what the optimal complexity is for non-convex decentralized stochastic optimization over time-varying networks. The main difficulties lie in how to gauge the effectiveness when transmitting messages between two nodes via time-varying communications, and how to establish the lower bound when the network size is fixed (which is a prerequisite in stochastic optimization). This paper resolves these challenges and establish the first lower bound complexity. We also develop a new decentralized algorithm to nearly attain the lower bound, showing the tightness of the lower bound and the optimality of our algorithm.
Modeling and Quickest Detection of a Rapidly Approaching Object
Mar 04, 2023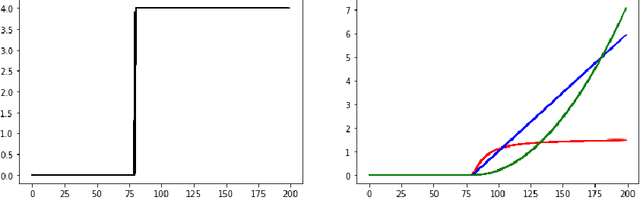

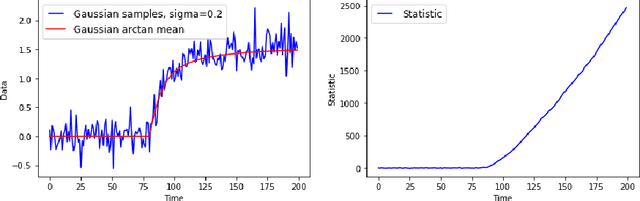
The problem of detecting the presence of a signal that can lead to a disaster is studied. A decision-maker collects data sequentially over time. At some point in time, called the change point, the distribution of data changes. This change in distribution could be due to an event or a sudden arrival of an enemy object. If not detected quickly, this change has the potential to cause a major disaster. In space and military applications, the values of the measurements can stochastically grow with time as the enemy object moves closer to the target. A new class of stochastic processes, called exploding processes, is introduced to model stochastically growing data. An algorithm is proposed and shown to be asymptotically optimal as the mean time to a false alarm goes to infinity.
Modeling Inter-Dependence Between Time and Mark in Multivariate Temporal Point Processes
Oct 27, 2022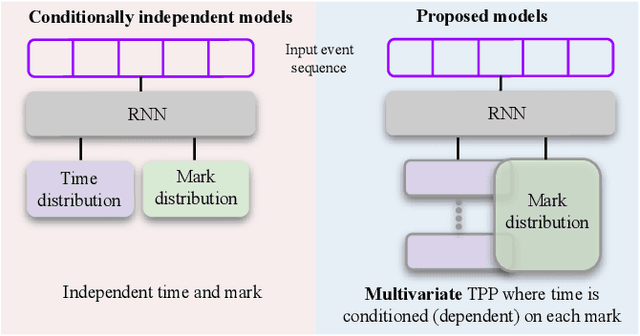

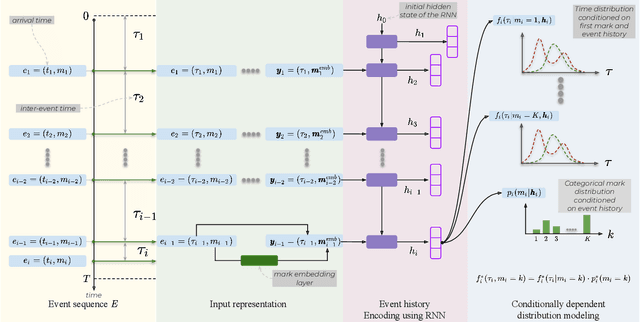
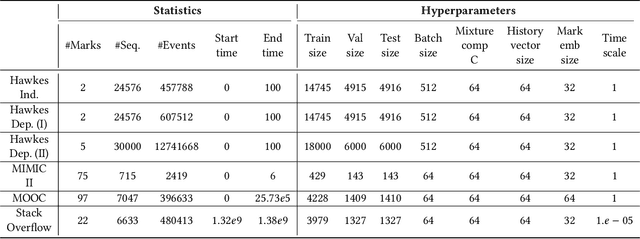
Temporal Point Processes (TPP) are probabilistic generative frameworks. They model discrete event sequences localized in continuous time. Generally, real-life events reveal descriptive information, known as marks. Marked TPPs model time and marks of the event together for practical relevance. Conditioned on past events, marked TPPs aim to learn the joint distribution of the time and the mark of the next event. For simplicity, conditionally independent TPP models assume time and marks are independent given event history. They factorize the conditional joint distribution of time and mark into the product of individual conditional distributions. This structural limitation in the design of TPP models hurt the predictive performance on entangled time and mark interactions. In this work, we model the conditional inter-dependence of time and mark to overcome the limitations of conditionally independent models. We construct a multivariate TPP conditioning the time distribution on the current event mark in addition to past events. Besides the conventional intensity-based models for conditional joint distribution, we also draw on flexible intensity-free TPP models from the literature. The proposed TPP models outperform conditionally independent and dependent models in standard prediction tasks. Our experimentation on various datasets with multiple evaluation metrics highlights the merit of the proposed approach.
Waving Goodbye to Low-Res: A Diffusion-Wavelet Approach for Image Super-Resolution
Apr 05, 2023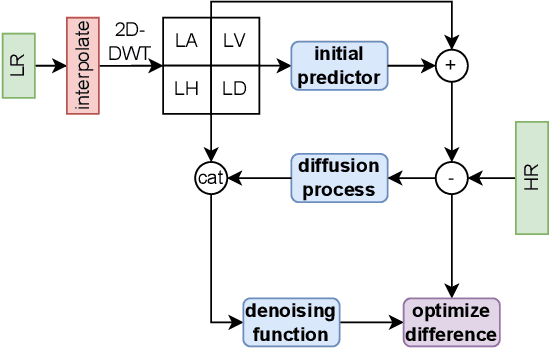
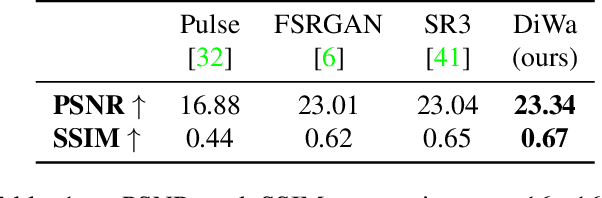
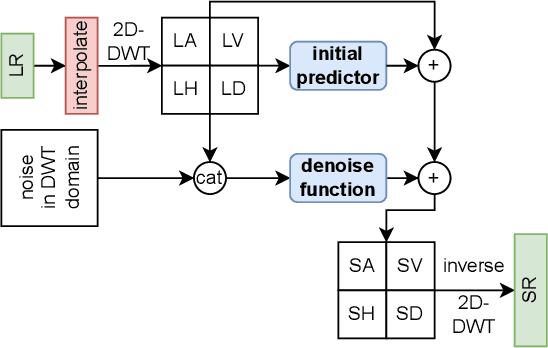
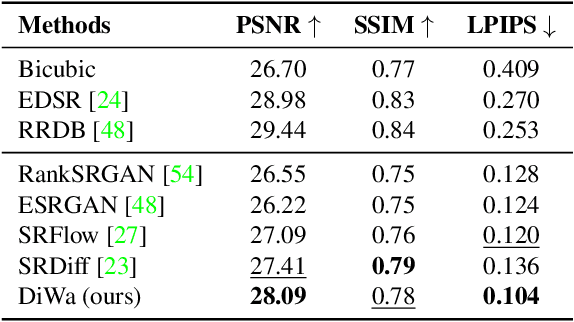
This paper presents a novel Diffusion-Wavelet (DiWa) approach for Single-Image Super-Resolution (SISR). It leverages the strengths of Denoising Diffusion Probabilistic Models (DDPMs) and Discrete Wavelet Transformation (DWT). By enabling DDPMs to operate in the DWT domain, our DDPM models effectively hallucinate high-frequency information for super-resolved images on the wavelet spectrum, resulting in high-quality and detailed reconstructions in image space. Quantitatively, we outperform state-of-the-art diffusion-based SISR methods, namely SR3 and SRDiff, regarding PSNR, SSIM, and LPIPS on both face (8x scaling) and general (4x scaling) SR benchmarks. Meanwhile, using DWT enabled us to use fewer parameters than the compared models: 92M parameters instead of 550M compared to SR3 and 9.3M instead of 12M compared to SRDiff. Additionally, our method outperforms other state-of-the-art generative methods on classical general SR datasets while saving inference time. Finally, our work highlights its potential for various applications.
High Accuracy Uncertainty-Aware Interatomic Force Modeling with Equivariant Bayesian Neural Networks
Apr 05, 2023Even though Bayesian neural networks offer a promising framework for modeling uncertainty, active learning and incorporating prior physical knowledge, few applications of them can be found in the context of interatomic force modeling. One of the main challenges in their application to learning interatomic forces is the lack of suitable Monte Carlo Markov chain sampling algorithms for the posterior density, as the commonly used algorithms do not converge in a practical amount of time for many of the state-of-the-art architectures. As a response to this challenge, we introduce a new Monte Carlo Markov chain sampling algorithm in this paper which can circumvent the problems of the existing sampling methods. In addition, we introduce a new stochastic neural network model based on the NequIP architecture and demonstrate that, when combined with our novel sampling algorithm, we obtain predictions with state-of-the-art accuracy as well as a good measure of uncertainty.
Online Training Through Time for Spiking Neural Networks
Oct 09, 2022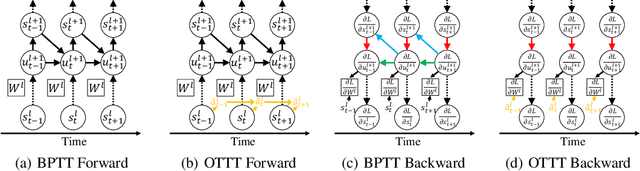
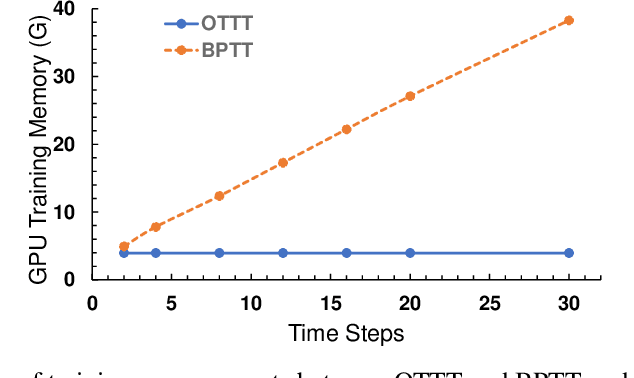
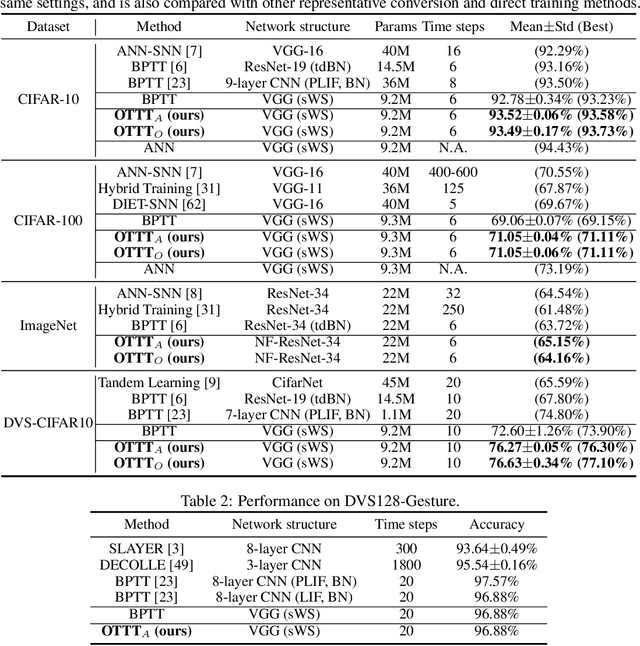
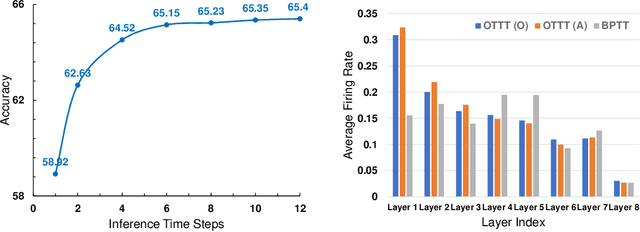
Spiking neural networks (SNNs) are promising brain-inspired energy-efficient models. Recent progress in training methods has enabled successful deep SNNs on large-scale tasks with low latency. Particularly, backpropagation through time (BPTT) with surrogate gradients (SG) is popularly used to achieve high performance in a very small number of time steps. However, it is at the cost of large memory consumption for training, lack of theoretical clarity for optimization, and inconsistency with the online property of biological learning and rules on neuromorphic hardware. Other works connect spike representations of SNNs with equivalent artificial neural network formulation and train SNNs by gradients from equivalent mappings to ensure descent directions. But they fail to achieve low latency and are also not online. In this work, we propose online training through time (OTTT) for SNNs, which is derived from BPTT to enable forward-in-time learning by tracking presynaptic activities and leveraging instantaneous loss and gradients. Meanwhile, we theoretically analyze and prove that gradients of OTTT can provide a similar descent direction for optimization as gradients based on spike representations under both feedforward and recurrent conditions. OTTT only requires constant training memory costs agnostic to time steps, avoiding the significant memory costs of BPTT for GPU training. Furthermore, the update rule of OTTT is in the form of three-factor Hebbian learning, which could pave a path for online on-chip learning. With OTTT, it is the first time that two mainstream supervised SNN training methods, BPTT with SG and spike representation-based training, are connected, and meanwhile in a biologically plausible form. Experiments on CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS demonstrate the superior performance of our method on large-scale static and neuromorphic datasets in small time steps.
L3MVN: Leveraging Large Language Models for Visual Target Navigation
Apr 11, 2023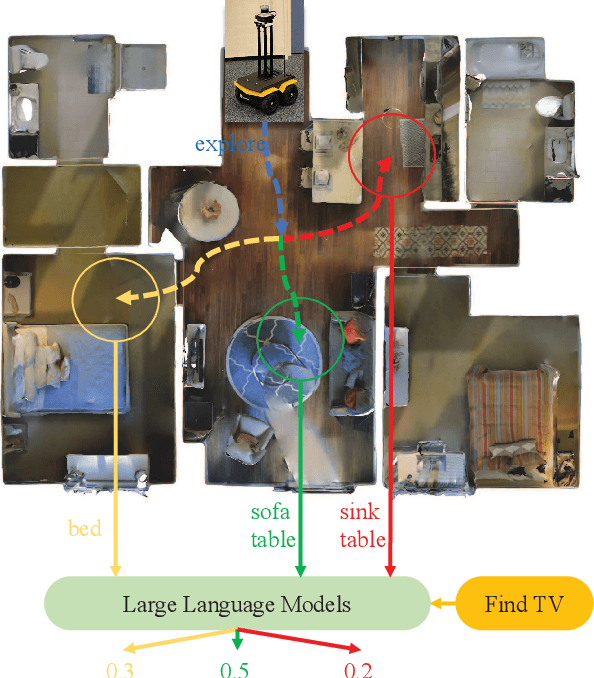
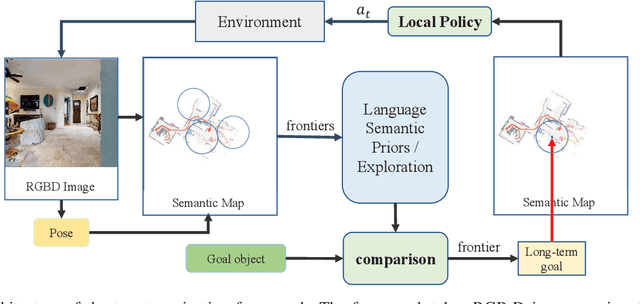
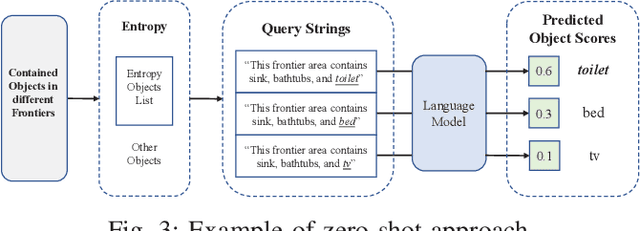
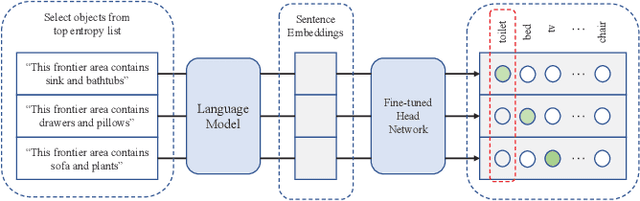
Visual target navigation in unknown environments is a crucial problem in robotics. Despite extensive investigation of classical and learning-based approaches in the past, robots lack common-sense knowledge about household objects and layouts. Prior state-of-the-art approaches to this task rely on learning the priors during the training and typically require significant expensive resources and time for learning. To address this, we propose a new framework for visual target navigation that leverages Large Language Models (LLM) to impart common sense for object searching. Specifically, we introduce two paradigms: (i) zero-shot and (ii) feed-forward approaches that use language to find the relevant frontier from the semantic map as a long-term goal and explore the environment efficiently. Our analysis demonstrates the notable zero-shot generalization and transfer capabilities from the use of language. Experiments on Gibson and Habitat-Matterport 3D (HM3D) demonstrate that the proposed framework significantly outperforms existing map-based methods in terms of success rate and generalization. Ablation analysis also indicates that the common-sense knowledge from the language model leads to more efficient semantic exploration. Finally, we provide a real robot experiment to verify the applicability of our framework in real-world scenarios. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/l3mvn.
Unsupervised out-of-distribution detection for safer robotically-guided retinal microsurgery
Apr 11, 2023Purpose: A fundamental problem in designing safe machine learning systems is identifying when samples presented to a deployed model differ from those observed at training time. Detecting so-called out-of-distribution (OoD) samples is crucial in safety-critical applications such as robotically-guided retinal microsurgery, where distances between the instrument and the retina are derived from sequences of 1D images that are acquired by an instrument-integrated optical coherence tomography (iiOCT) probe. Methods: This work investigates the feasibility of using an OoD detector to identify when images from the iiOCT probe are inappropriate for subsequent machine learning-based distance estimation. We show how a simple OoD detector based on the Mahalanobis distance can successfully reject corrupted samples coming from real-world ex-vivo porcine eyes. Results: Our results demonstrate that the proposed approach can successfully detect OoD samples and help maintain the performance of the downstream task within reasonable levels. MahaAD outperformed a supervised approach trained on the same kind of corruptions and achieved the best performance in detecting OoD cases from a collection of iiOCT samples with real-world corruptions. Conclusion: The results indicate that detecting corrupted iiOCT data through OoD detection is feasible and does not need prior knowledge of possible corruptions. Consequently, MahaAD could aid in ensuring patient safety during robotically-guided microsurgery by preventing deployed prediction models from estimating distances that put the patient at risk.
SamurAI: A Versatile IoT Node With Event-Driven Wake-Up and Embedded ML Acceleration
Apr 11, 2023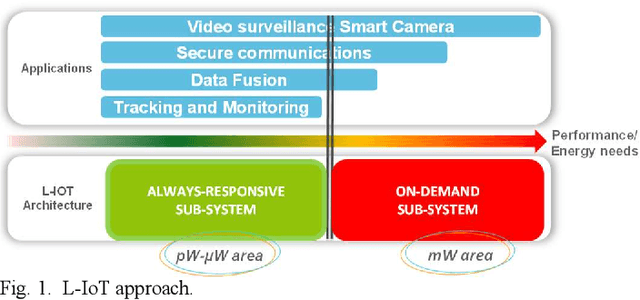
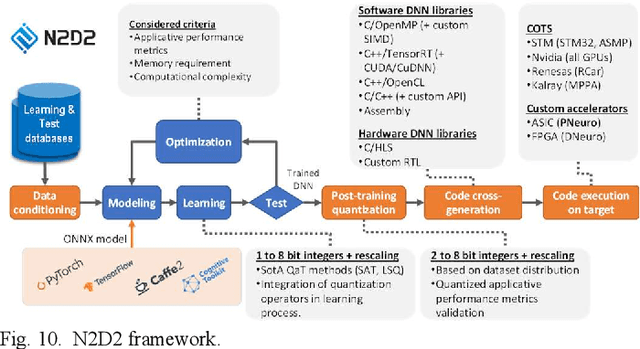
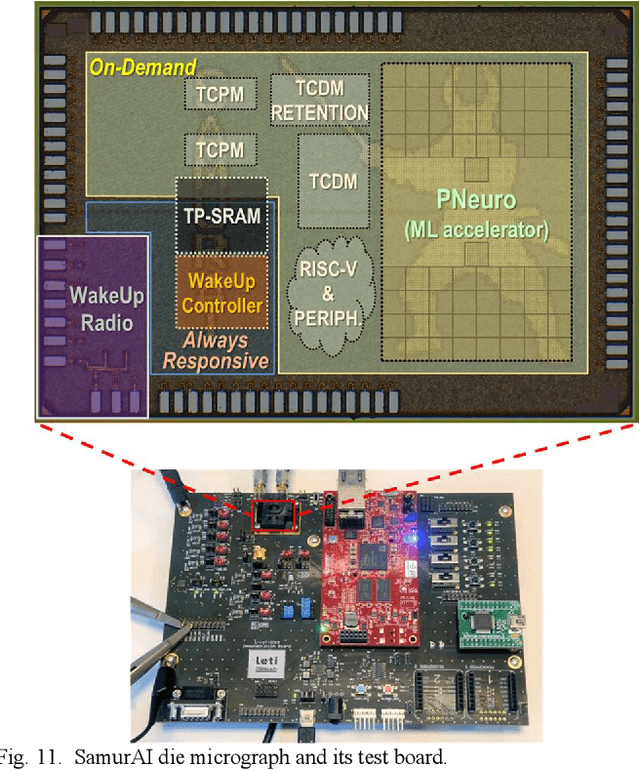
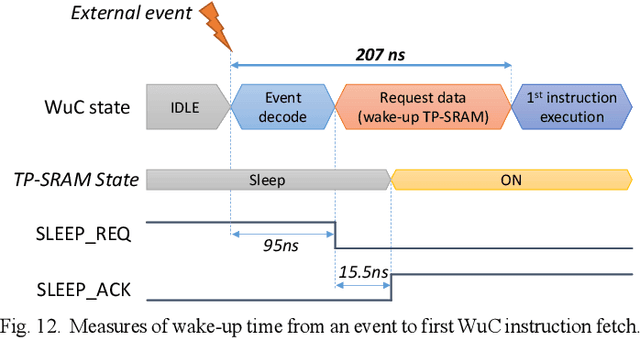
Increased capabilities such as recognition and self-adaptability are now required from IoT applications. While IoT node power consumption is a major concern for these applications, cloud-based processing is becoming unsustainable due to continuous sensor or image data transmission over the wireless network. Thus optimized ML capabilities and data transfers should be integrated in the IoT node. Moreover, IoT applications are torn between sporadic data-logging and energy-hungry data processing (e.g. image classification). Thus, the versatility of the node is key in addressing this wide diversity of energy and processing needs. This paper presents SamurAI, a versatile IoT node bridging this gap in processing and in energy by leveraging two on-chip sub-systems: a low power, clock-less, event-driven Always-Responsive (AR) part and an energy-efficient On-Demand (OD) part. AR contains a 1.7MOPS event-driven, asynchronous Wake-up Controller (WuC) with a 207ns wake-up time optimized for sporadic computing, while OD combines a deep-sleep RISC-V CPU and 1.3TOPS/W Machine Learning (ML) for more complex tasks up to 36GOPS. This architecture partitioning achieves best in class versatility metrics such as peak performance to idle power ratio. On an applicative classification scenario, it demonstrates system power gains, up to 3.5x compared to cloud-based processing, and thus extended battery lifetime.
Linking Representations with Multimodal Contrastive Learning
Apr 11, 2023
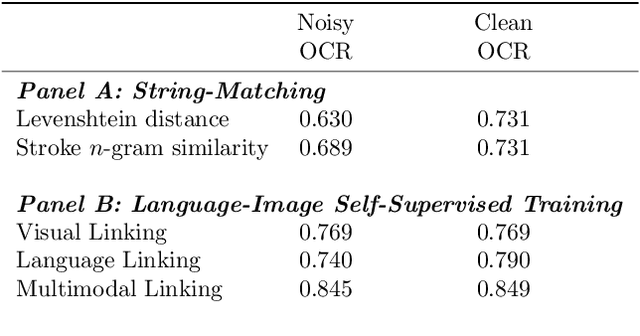
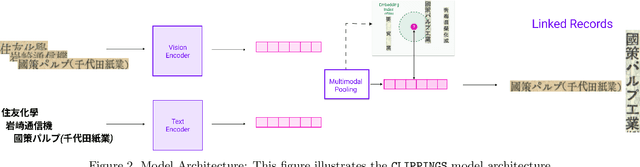
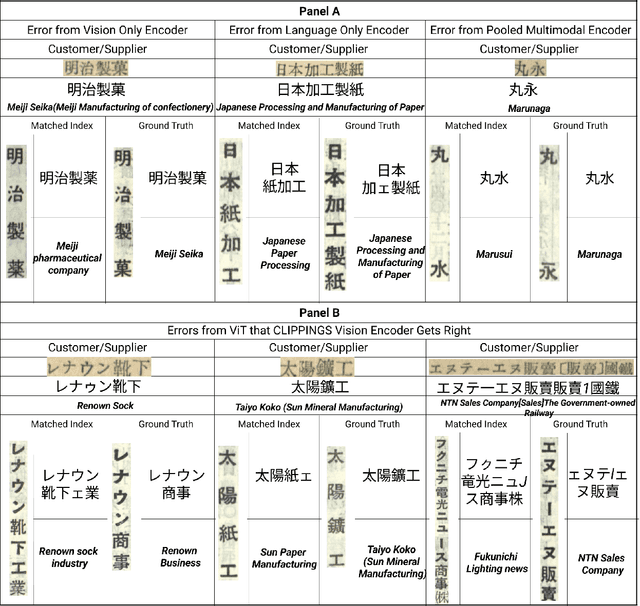
Many applications require grouping instances contained in diverse document datasets into classes. Most widely used methods do not employ deep learning and do not exploit the inherently multimodal nature of documents. Notably, record linkage is typically conceptualized as a string-matching problem. This study develops CLIPPINGS, (Contrastively Linking Pooled Pre-trained Embeddings), a multimodal framework for record linkage. CLIPPINGS employs end-to-end training of symmetric vision and language bi-encoders, aligned through contrastive language-image pre-training, to learn a metric space where the pooled image-text representation for a given instance is close to representations in the same class and distant from representations in different classes. At inference time, instances can be linked by retrieving their nearest neighbor from an offline exemplar embedding index or by clustering their representations. The study examines two challenging applications: constructing comprehensive supply chains for mid-20th century Japan through linking firm level financial records - with each firm name represented by its crop in the document image and the corresponding OCR - and detecting which image-caption pairs in a massive corpus of historical U.S. newspapers came from the same underlying photo wire source. CLIPPINGS outperforms widely used string matching methods by a wide margin and also outperforms unimodal methods. Moreover, a purely self-supervised model trained on only image-OCR pairs also outperforms popular string-matching methods without requiring any labels.