 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conjunction Data Messages for Space Collision Behave as a Poisson Process
Mar 27, 2023

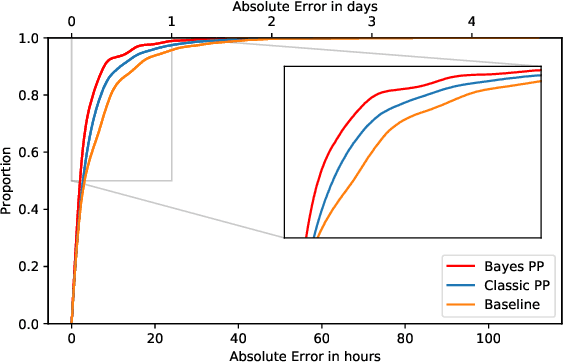
Space debris is a major problem in space exploration. International bodies continuously monitor a large database of orbiting objects and emit warnings in the form of conjunction data messages. An important question for satellite operators is to estimate when fresh information will arrive so that they can react timely but sparingly with satellite maneuvers. We propose a statistical learning model of the message arrival process, allowing us to answer two important questions: (1) Will there be any new message in the next specified time interval? (2) When exactly and with what uncertainty will the next message arrive? The average prediction error for question (2) of our Bayesian Poisson process model is smaller than the baseline in more than 4 hours in a test set of 50k close encounter events.
Learning Dynamic Style Kernels for Artistic Style Transfer
Apr 02, 2023
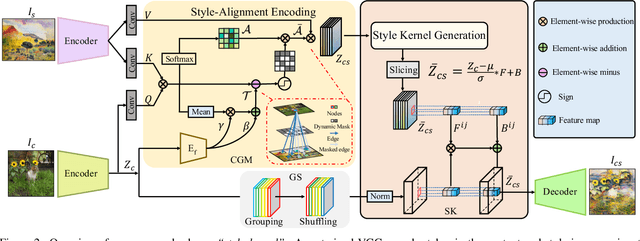


Arbitrary style transfer has been demonstrated to be efficient in artistic image generation. Previous methods either globally modulate the content feature ignoring local details, or overly focus on the local structure details leading to style leakage. In contrast to the literature, we propose a new scheme \textit{``style kernel"} that learns {\em spatially adaptive kernels} for per-pixel stylization, where the convolutional kernels are dynamically generated from the global style-content aligned feature and then the learned kernels are applied to modulate the content feature at each spatial position. This new scheme allows flexible both global and local interactions between the content and style features such that the wanted styles can be easily transferred to the content image while at the same time the content structure can be easily preserved. To further enhance the flexibility of our style transfer method, we propose a Style Alignment Encoding (SAE) module complemented with a Content-based Gating Modulation (CGM) module for learning the dynamic style kernels in focusing regions. Extensive experiments strongly demonstrate that our proposed method outperforms state-of-the-art methods and exhibits superior performance in terms of visual quality and efficiency.
Demonstration of InsightPilot: An LLM-Empowered Automated Data Exploration System
Apr 02, 2023
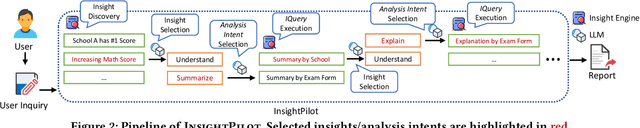

Exploring data is crucial in data analysis, as it helps users understand and interpret the data more effectively. However, performing effective data exploration requires in-depth knowledge of the dataset and expertise in data analysis techniques. Not being familiar with either can create obstacles that make the process time-consuming and overwhelming for data analysts. To address this issue, we introduce InsightPilot, an LLM (Large Language Model)-based, automated data exploration system designed to simplify the data exploration process. InsightPilot automatically selects appropriate analysis intents, such as understanding, summarizing, and explaining. Then, these analysis intents are concretized by issuing corresponding intentional queries (IQueries) to create a meaningful and coherent exploration sequence. In brief, an IQuery is an abstraction and automation of data analysis operations, which mimics the approach of data analysts and simplifies the exploration process for users. By employing an LLM to iteratively collaborate with a state-of-the-art insight engine via IQueries, InsightPilot is effective in analyzing real-world datasets, enabling users to gain valuable insights through natural language inquiries. We demonstrate the effectiveness of InsightPilot in a case study, showing how it can help users gain valuable insights from their datasets.
Predictive Context-Awareness for Full-Immersive Multiuser Virtual Reality with Redirected Walking
Apr 06, 2023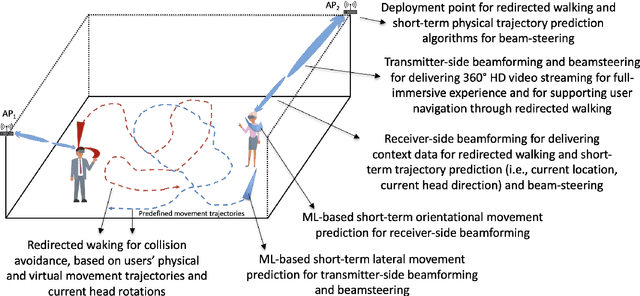
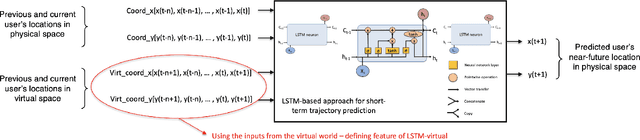
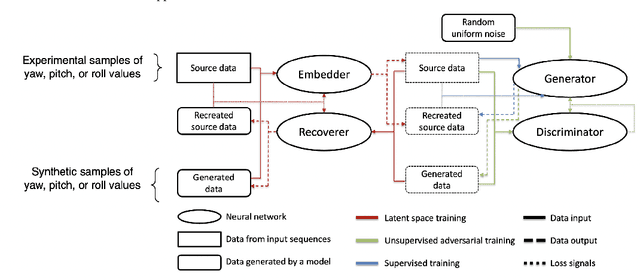
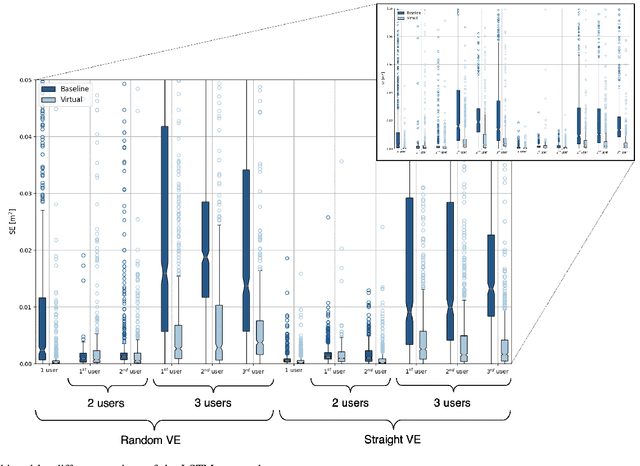
The advancement of Virtual Reality (VR) technology is focused on improving its immersiveness, supporting multiuser Virtual Experiences (VEs), and enabling the users to move freely within their VEs while still being confined within specialized VR setups through Redirected Walking (RDW). To meet their extreme data-rate and latency requirements, future VR systems will require supporting wireless networking infrastructures operating in millimeter Wave (mmWave) frequencies that leverage highly directional communication in both transmission and reception through beamforming and beamsteering. We propose the use of predictive context-awareness to optimize transmitter and receiver-side beamforming and beamsteering. By predicting users' short-term lateral movements in multiuser VR setups with Redirected Walking (RDW), transmitter-side beamforming and beamsteering can be optimized through Line-of-Sight (LoS) "tracking" in the users' directions. At the same time, predictions of short-term orientational movements can be utilized for receiver-side beamforming for coverage flexibility enhancements. We target two open problems in predicting these two context information instances: i) predicting lateral movements in multiuser VR settings with RDW, and ii) generating synthetic head rotation datasets for training orientational movements predictors. Our experimental results demonstrate that Long Short-Term Memory (LSTM) networks feature promising accuracy in predicting lateral movements, and context-awareness stemming from VEs further enhances this accuracy. Additionally, we show that a TimeGAN-based approach for orientational data generation can create synthetic samples that closely match experimentally obtained ones.
FengWu: Pushing the Skillful Global Medium-range Weather Forecast beyond 10 Days Lead
Apr 06, 2023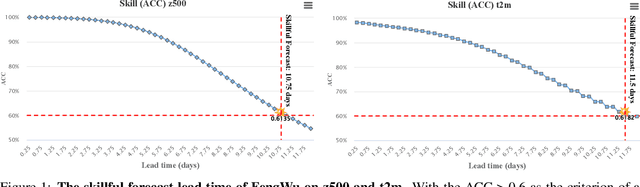
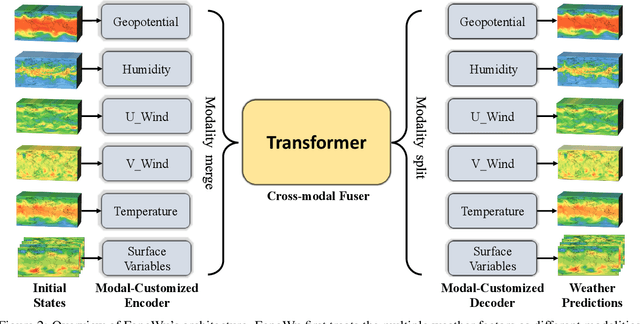
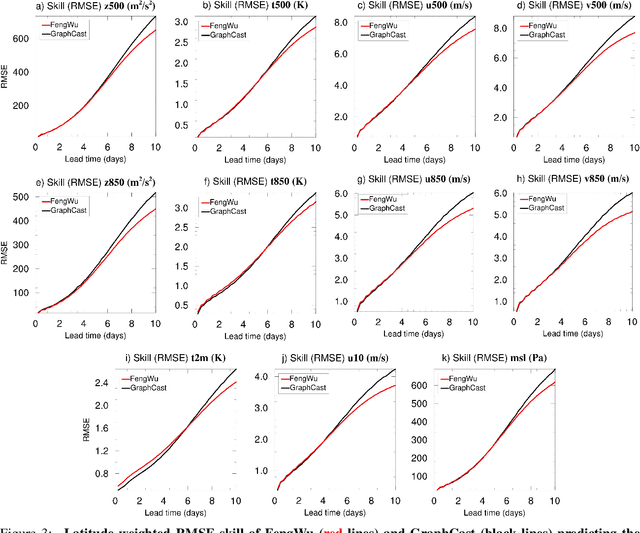
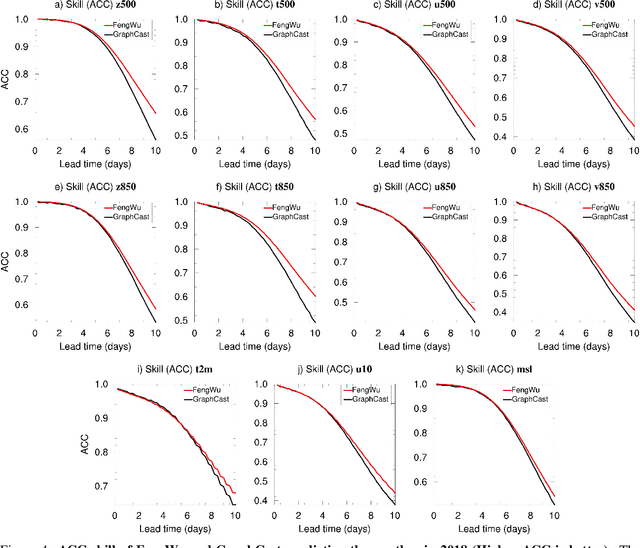
We present FengWu, an advanced data-driven global medium-range weather forecast system based on Artificial Intelligence (AI). Different from existing data-driven weather forecast methods, FengWu solves the medium-range forecast problem from a multi-modal and multi-task perspective. Specifically, a deep learning architecture equipped with model-specific encoder-decoders and cross-modal fusion Transformer is elaborately designed, which is learned under the supervision of an uncertainty loss to balance the optimization of different predictors in a region-adaptive manner. Besides this, a replay buffer mechanism is introduced to improve medium-range forecast performance. With 39-year data training based on the ERA5 reanalysis, FengWu is able to accurately reproduce the atmospheric dynamics and predict the future land and atmosphere states at 37 vertical levels on a 0.25{\deg} latitude-longitude resolution. Hindcasts of 6-hourly weather in 2018 based on ERA5 demonstrate that FengWu performs better than GraphCast in predicting 80\% of the 880 reported predictands, e.g., reducing the root mean square error (RMSE) of 10-day lead global z500 prediction from 733 to 651 $m^{2}/s^2$. In addition, the inference cost of each iteration is merely 600ms on NVIDIA Tesla A100 hardware. The results suggest that FengWu can significantly improve the forecast skill and extend the skillful global medium-range weather forecast out to 10.75 days lead (with ACC of z500 > 0.6) for the first time.
When approximate design for fast homomorphic computation provides differential privacy guarantees
Apr 06, 2023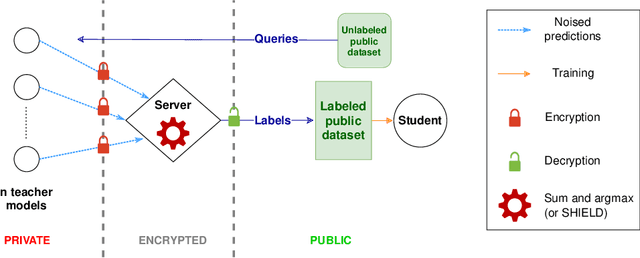
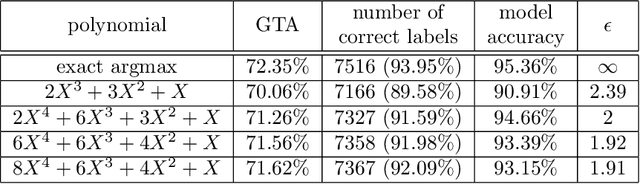
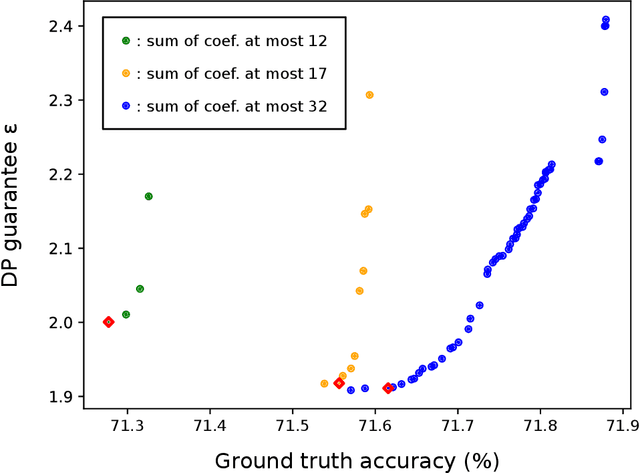
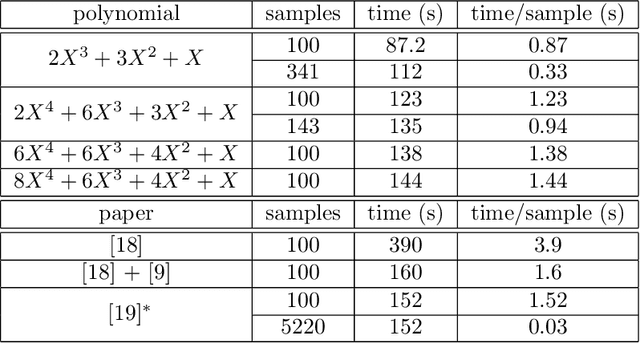
While machine learning has become pervasive in as diversified fields as industry, healthcare, social networks, privacy concerns regarding the training data have gained a critical importance. In settings where several parties wish to collaboratively train a common model without jeopardizing their sensitive data, the need for a private training protocol is particularly stringent and implies to protect the data against both the model's end-users and the actors of the training phase. Differential privacy (DP) and cryptographic primitives are complementary popular countermeasures against privacy attacks. Among these cryptographic primitives, fully homomorphic encryption (FHE) offers ciphertext malleability at the cost of time-consuming operations in the homomorphic domain. In this paper, we design SHIELD, a probabilistic approximation algorithm for the argmax operator which is both fast when homomorphically executed and whose inaccuracy is used as a feature to ensure DP guarantees. Even if SHIELD could have other applications, we here focus on one setting and seamlessly integrate it in the SPEED collaborative training framework from "SPEED: Secure, PrivatE, and Efficient Deep learning" (Grivet S\'ebert et al., 2021) to improve its computational efficiency. After thoroughly describing the FHE implementation of our algorithm and its DP analysis, we present experimental results. To the best of our knowledge, it is the first work in which relaxing the accuracy of an homomorphic calculation is constructively usable as a degree of freedom to achieve better FHE performances.
Tag that issue: Applying API-domain labels in issue tracking systems
Apr 06, 2023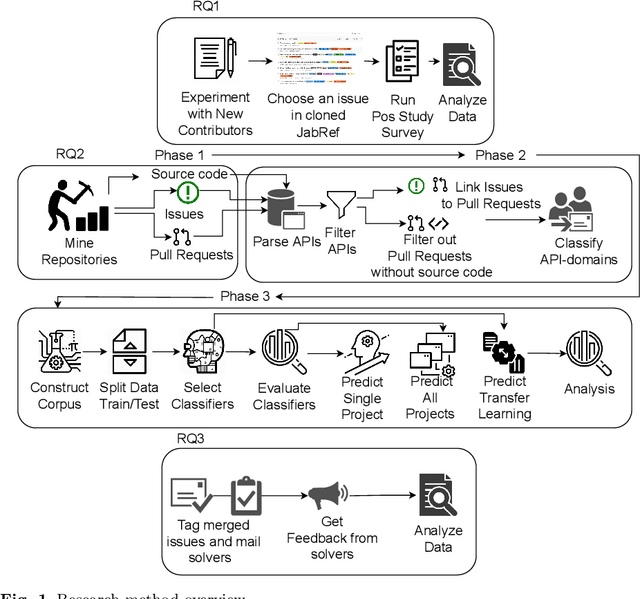
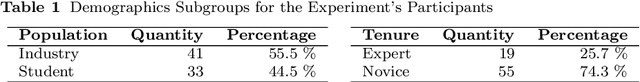
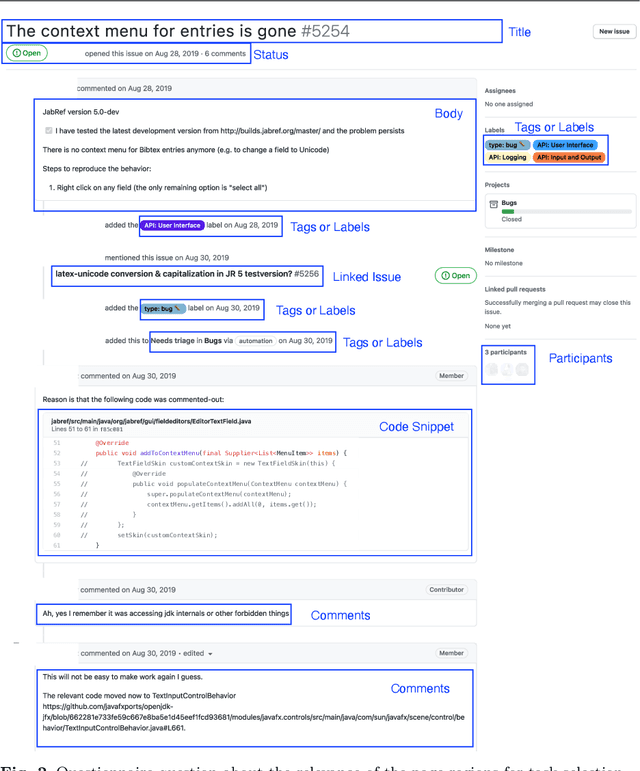
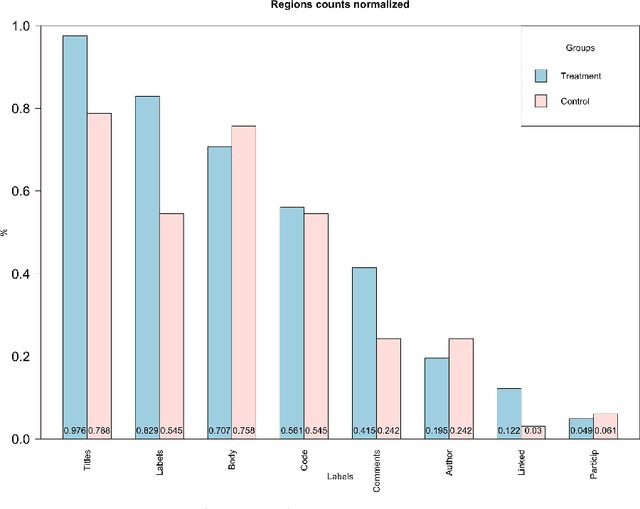
Labeling issues with the skills required to complete them can help contributors to choose tasks in Open Source Software projects. However, manually labeling issues is time-consuming and error-prone, and current automated approaches are mostly limited to classifying issues as bugs/non-bugs. We investigate the feasibility and relevance of automatically labeling issues with what we call "API-domains," which are high-level categories of APIs. Therefore, we posit that the APIs used in the source code affected by an issue can be a proxy for the type of skills (e.g., DB, security, UI) needed to work on the issue. We ran a user study (n=74) to assess API-domain labels' relevancy to potential contributors, leveraged the issues' descriptions and the project history to build prediction models, and validated the predictions with contributors (n=20) of the projects. Our results show that (i) newcomers to the project consider API-domain labels useful in choosing tasks, (ii) labels can be predicted with a precision of 84% and a recall of 78.6% on average, (iii) the results of the predictions reached up to 71.3% in precision and 52.5% in recall when training with a project and testing in another (transfer learning), and (iv) project contributors consider most of the predictions helpful in identifying needed skills. These findings suggest our approach can be applied in practice to automatically label issues, assisting developers in finding tasks that better match their skills.
DITTO-NeRF: Diffusion-based Iterative Text To Omni-directional 3D Model
Apr 06, 2023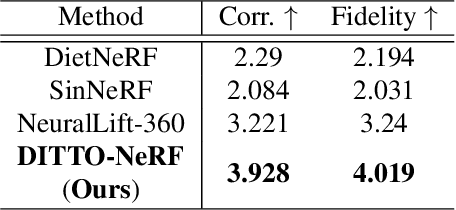
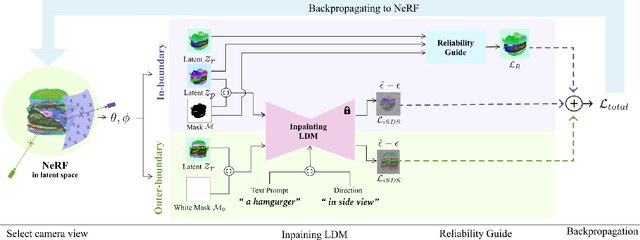
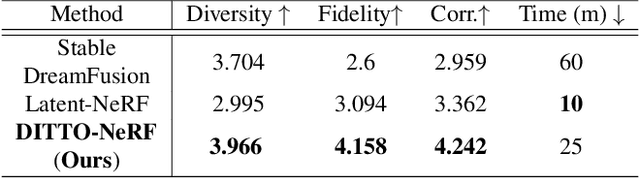
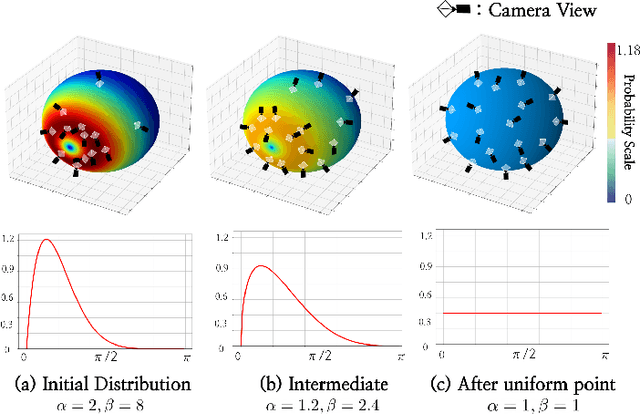
The increasing demand for high-quality 3D content creation has motivated the development of automated methods for creating 3D object models from a single image and/or from a text prompt. However, the reconstructed 3D objects using state-of-the-art image-to-3D methods still exhibit low correspondence to the given image and low multi-view consistency. Recent state-of-the-art text-to-3D methods are also limited, yielding 3D samples with low diversity per prompt with long synthesis time. To address these challenges, we propose DITTO-NeRF, a novel pipeline to generate a high-quality 3D NeRF model from a text prompt or a single image. Our DITTO-NeRF consists of constructing high-quality partial 3D object for limited in-boundary (IB) angles using the given or text-generated 2D image from the frontal view and then iteratively reconstructing the remaining 3D NeRF using inpainting latent diffusion model. We propose progressive 3D object reconstruction schemes in terms of scales (low to high resolution), angles (IB angles initially to outer-boundary (OB) later), and masks (object to background boundary) in our DITTO-NeRF so that high-quality information on IB can be propagated into OB. Our DITTO-NeRF outperforms state-of-the-art methods in terms of fidelity and diversity qualitatively and quantitatively with much faster training times than prior arts on image/text-to-3D such as DreamFusion, and NeuralLift-360.
Continuous tuning & thermally induced frequency drift stabilisation of time delay oscillators such as the optoelectronic oscillator
Jan 12, 2023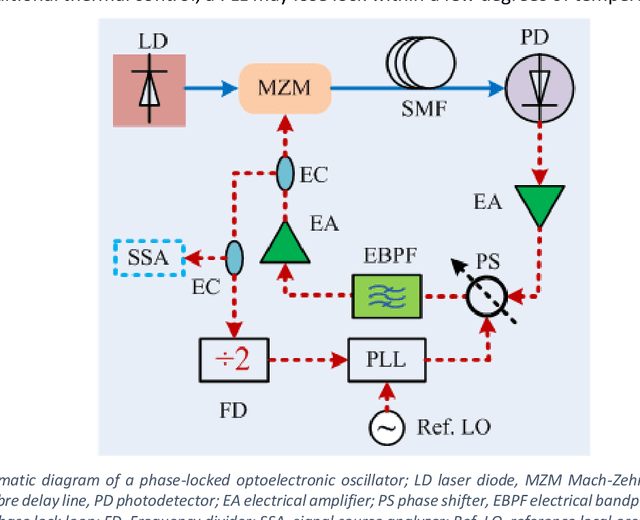

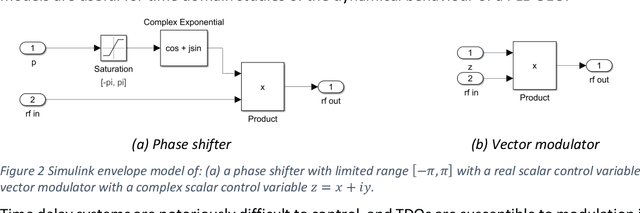
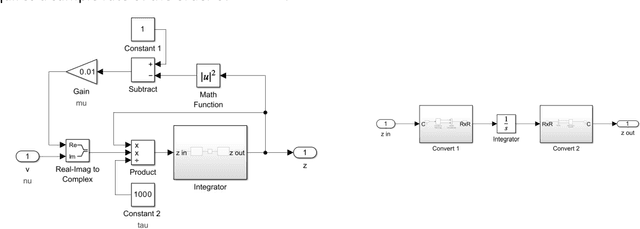
Delay line oscillators based on photonic components, such as the optoelectronic oscillator (OEO), offer the potential for realization of phase noise levels orders of magnitude lower than achievable by conventional microwave sources. Fibre optic-based delay lines can realize the large delay required for low phase noise systems whilst simultaneously achieving insertion loss levels that can be compensated by available microwave and photonic amplification technologies. However, the long fibre is vulnerable to environmental perturbations such as mechanical vibrations and variations in ambient temperature, which result in short term fluctuations and thermally induced drift of the oscillation frequency. The phase shifter used conventionally to adjust the frequency of an OEO to enable phase lock has a finite range that is insufficient to compensate the delay change resulting from operational temperature ranges. A solution to continuous tuning without mode-hopping and to compensation of thermally induced frequency drift without loss of lock of a time delay oscillator is proposed. The basic concept is to introduce a tuning mechanism that works with Cartesian co-ordinates on the complex plane and to avoid explicit use of polar co-ordinates. Consequently, the transmission of the tuning component may traverse the unit circle in either direction multiple times without range limitation to the phase. Thereby tuning by mode-hopping is avoided and expedients to stabilisation, such as the use of tunable lasers within a control loop or precision temperature stabilisation measures are not required. The concept is verified by Simulink simulations. The method has been experimentally tested successfully using a prototype OEO phase locked to a system reference. Solid lock was maintained even when the OEO was placed in an oven and cycled over a temperature range from ambient to 80 {\deg}C.
Efficient Testable Learning of Halfspaces with Adversarial Label Noise
Mar 09, 2023
We give the first polynomial-time algorithm for the testable learning of halfspaces in the presence of adversarial label noise under the Gaussian distribution. In the recently introduced testable learning model, one is required to produce a tester-learner such that if the data passes the tester, then one can trust the output of the robust learner on the data. Our tester-learner runs in time $\poly(d/\eps)$ and outputs a halfspace with misclassification error $O(\opt)+\eps$, where $\opt$ is the 0-1 error of the best fitting halfspace. At a technical level, our algorithm employs an iterative soft localization technique enhanced with appropriate testers to ensure that the data distribution is sufficiently similar to a Gaussian.