 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Survey on Task Allocation and Scheduling in Robotic Network Systems
Mar 22, 2023
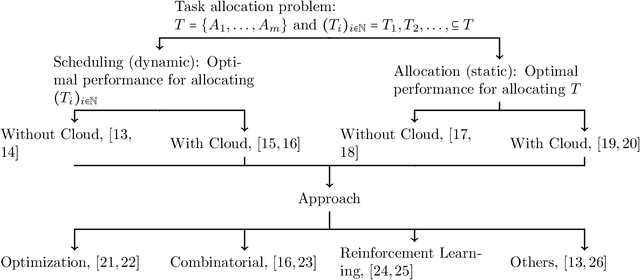
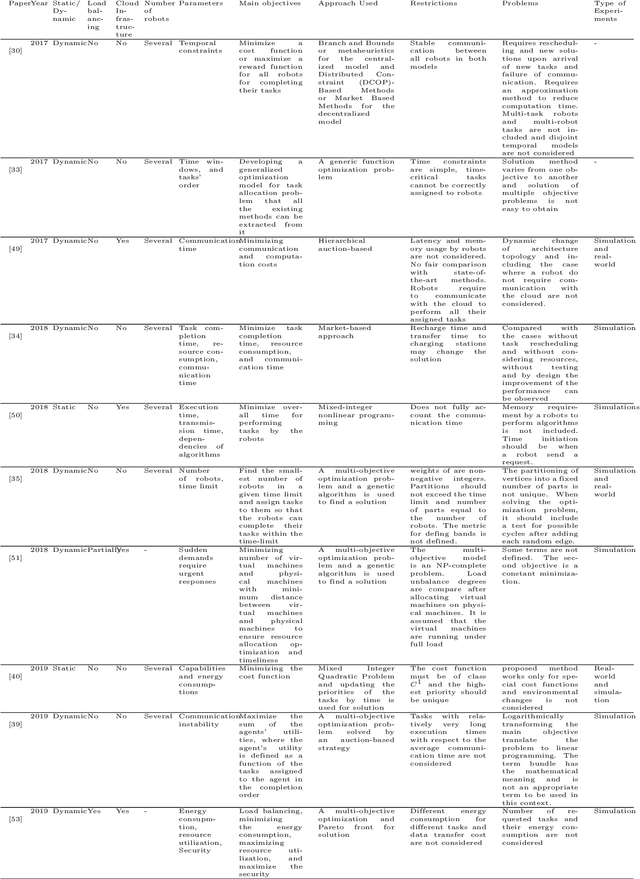
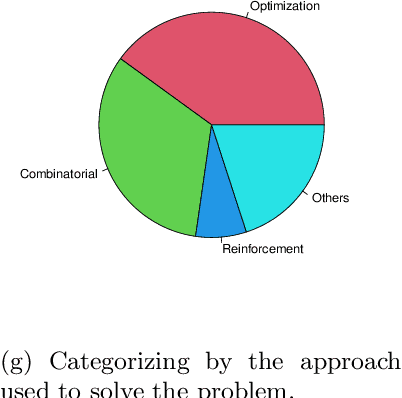
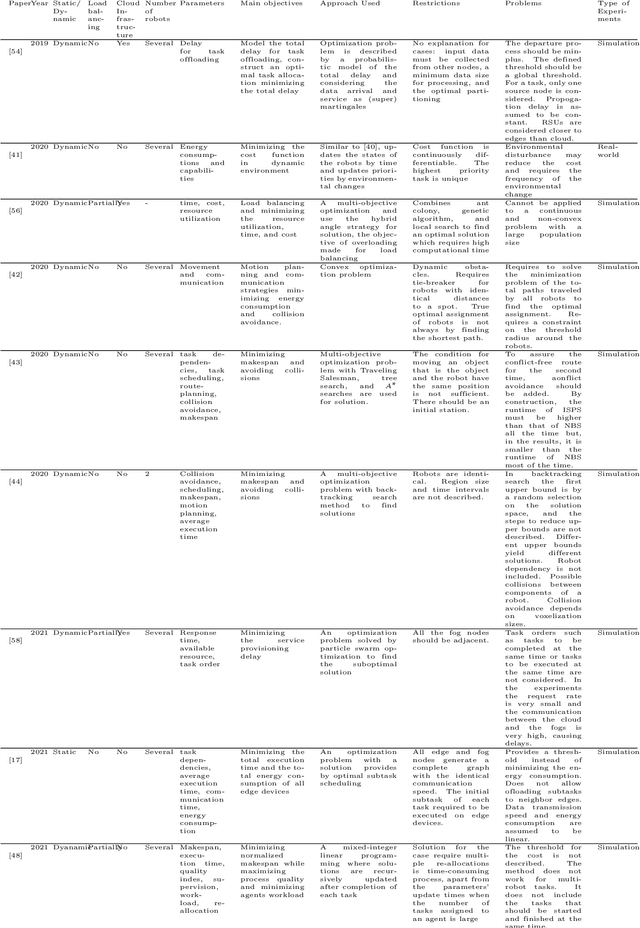
Cloud Robotics is helping to create a new generation of robots that leverage the nearly unlimited resources of large data centers (i.e., the cloud), overcoming the limitations imposed by on-board resources. Different processing power, capabilities, resource sizes, energy consumption, and so forth, make scheduling and task allocation critical components. The basic idea of task allocation and scheduling is to optimize performance by minimizing completion time, energy consumption, delays between two consecutive tasks, along with others, and maximizing resource utilization, number of completed tasks in a given time interval, and suchlike. In the past, several works have addressed various aspects of task allocation and scheduling. In this paper, we provide a comprehensive overview of task allocation and scheduling strategies and related metrics suitable for robotic network cloud systems. We discuss the issues related to allocation and scheduling methods and the limitations that need to be overcome. The literature review is organized according to three different viewpoints: Architectures and Applications, Methods and Parameters. In addition, the limitations of each method are highlighted for future research.
Agent-Time Attention for Sparse Rewards Multi-Agent Reinforcement Learning
Oct 31, 2022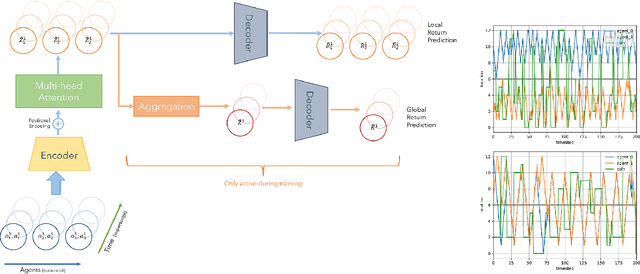
Sparse and delayed rewards pose a challenge to single agent reinforcement learning. This challenge is amplified in multi-agent reinforcement learning (MARL) where credit assignment of these rewards needs to happen not only across time, but also across agents. We propose Agent-Time Attention (ATA), a neural network model with auxiliary losses for redistributing sparse and delayed rewards in collaborative MARL. We provide a simple example that demonstrates how providing agents with their own local redistributed rewards and shared global redistributed rewards motivate different policies. We extend several MiniGrid environments, specifically MultiRoom and DoorKey, to the multi-agent sparse delayed rewards setting. We demonstrate that ATA outperforms various baselines on many instances of these environments. Source code of the experiments is available at https://github.com/jshe/agent-time-attention.
CNN-based real-time 2D-3D deformable registration from a single X-ray projection
Dec 15, 2022
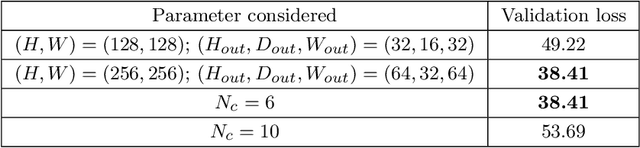
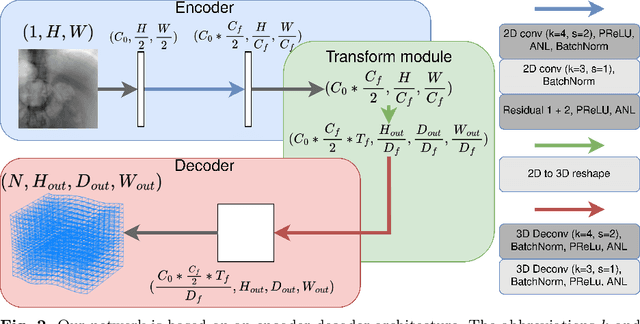
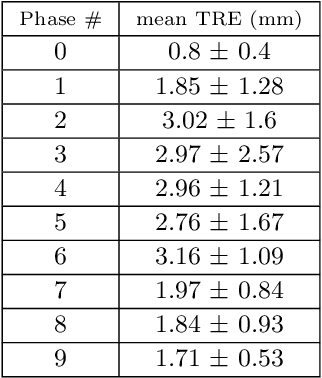
Purpose: The purpose of this paper is to present a method for real-time 2D-3D non-rigid registration using a single fluoroscopic image. Such a method can find applications in surgery, interventional radiology and radiotherapy. By estimating a three-dimensional displacement field from a 2D X-ray image, anatomical structures segmented in the preoperative scan can be projected onto the 2D image, thus providing a mixed reality view. Methods: A dataset composed of displacement fields and 2D projections of the anatomy is generated from the preoperative scan. From this dataset, a neural network is trained to recover the unknown 3D displacement field from a single projection image. Results: Our method is validated on lung 4D CT data at different stages of the lung deformation. The training is performed on a 3D CT using random (non domain-specific) diffeomorphic deformations, to which perturbations mimicking the pose uncertainty are added. The model achieves a mean TRE over a series of landmarks ranging from 2.3 to 5.5 mm depending on the amplitude of deformation. Conclusion: In this paper, a CNN-based method for real-time 2D-3D non-rigid registration is presented. This method is able to cope with pose estimation uncertainties, making it applicable to actual clinical scenarios, such as lung surgery, where the C-arm pose is planned before the intervention.
eCDANs: Efficient Temporal Causal Discovery from Autocorrelated and Non-stationary Data (Student Abstract)
Mar 06, 2023
Conventional temporal causal discovery (CD) methods suffer from high dimensionality, fail to identify lagged causal relationships, and often ignore dynamics in relations. In this study, we present a novel constraint-based CD approach for autocorrelated and non-stationary time series data (eCDANs) capable of detecting lagged and contemporaneous causal relationships along with temporal changes. eCDANs addresses high dimensionality by optimizing the conditioning sets while conducting conditional independence (CI) tests and identifies the changes in causal relations by introducing a surrogate variable to represent time dependency. Experiments on synthetic and real-world data show that eCDANs can identify time influence and outperform the baselines.
CAVL: Learning Contrastive and Adaptive Representations of Vision and Language
Apr 10, 2023
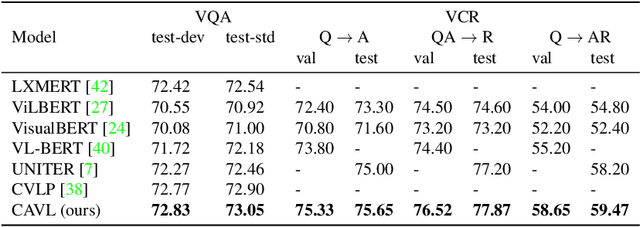
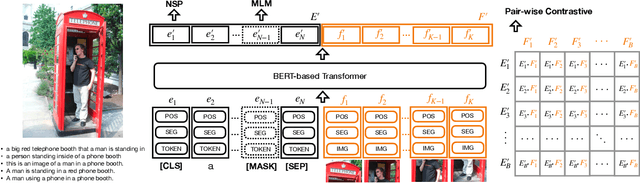
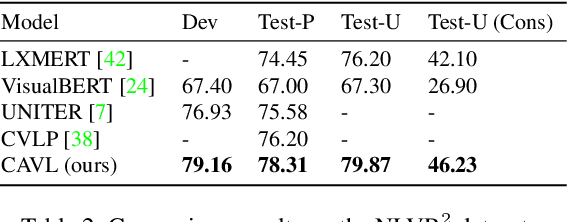
Visual and linguistic pre-training aims to learn vision and language representations together, which can be transferred to visual-linguistic downstream tasks. However, there exists semantic confusion between language and vision during the pre-training stage. Moreover, current pre-trained models tend to take lots of computation resources for fine-tuning when transferred to downstream tasks. In this work, we present a simple but effective approach for learning Contrastive and Adaptive representations of Vision and Language, namely CAVL. Specifically, we introduce a pair-wise contrastive loss to learn alignments between the whole sentence and each image in the same batch during the pre-training process. At the fine-tuning stage, we introduce two lightweight adaptation networks to reduce model parameters and increase training speed for saving computation resources. We evaluate our CAVL on six main downstream tasks, including Visual Question Answering (VQA), Visual Commonsense Reasoning (VCR), Natural Language for Visual Reasoning (NLVR), Region-to-Phrase Grounding (RPG), Text-to-Image Retrieval (TIR), and Zero-shot Text-to-Image Retrieval (ZS-TIR). Compared to baselines, we achieve superior performance and reduce the fine-tuning time by a large margin (in particular, 76.17%). Extensive experiments and ablation studies demonstrate the efficiency of contrastive pre-training and adaptive fine-tuning proposed in our CAVL.
Automated Reading Passage Generation with OpenAI's Large Language Model
Apr 10, 2023
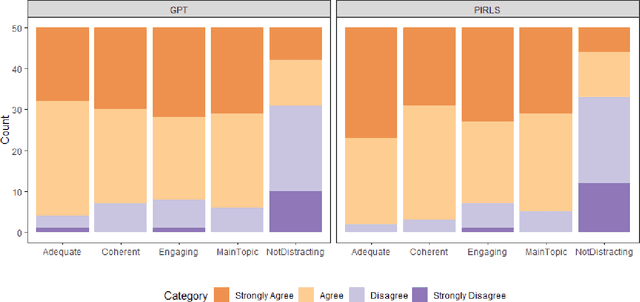
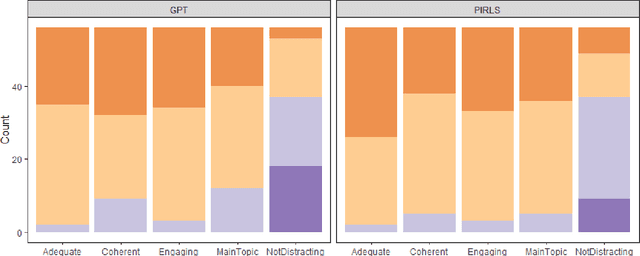
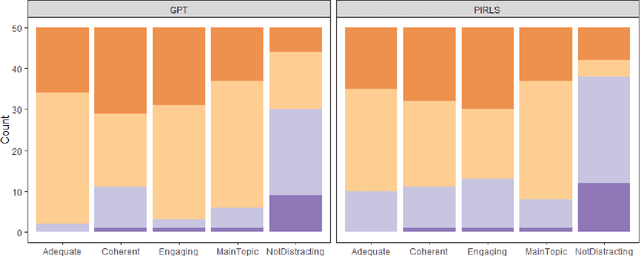
The widespread usage of computer-based assessments and individualized learning platforms has resulted in an increased demand for the rapid production of high-quality items. Automated item generation (AIG), the process of using item models to generate new items with the help of computer technology, was proposed to reduce reliance on human subject experts at each step of the process. AIG has been used in test development for some time. Still, the use of machine learning algorithms has introduced the potential to improve the efficiency and effectiveness of the process greatly. The approach presented in this paper utilizes OpenAI's latest transformer-based language model, GPT-3, to generate reading passages. Existing reading passages were used in carefully engineered prompts to ensure the AI-generated text has similar content and structure to a fourth-grade reading passage. For each prompt, we generated multiple passages, the final passage was selected according to the Lexile score agreement with the original passage. In the final round, the selected passage went through a simple revision by a human editor to ensure the text was free of any grammatical and factual errors. All AI-generated passages, along with original passages were evaluated by human judges according to their coherence, appropriateness to fourth graders, and readability.
Learning Residual Model of Model Predictive Control via Random Forests for Autonomous Driving
Apr 10, 2023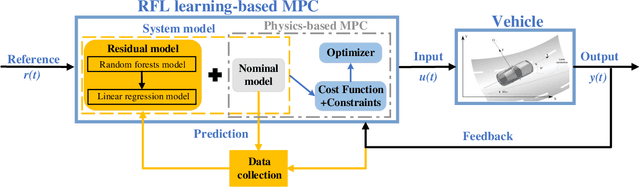
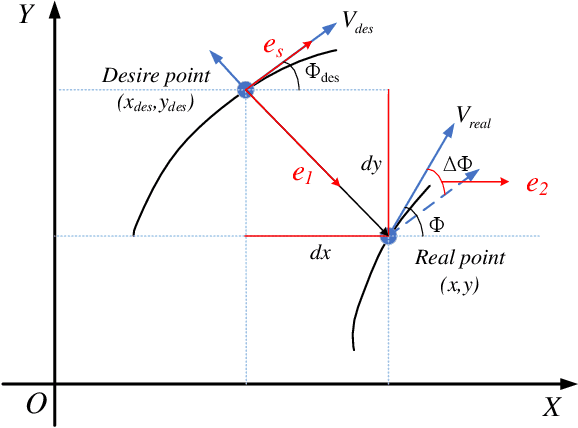
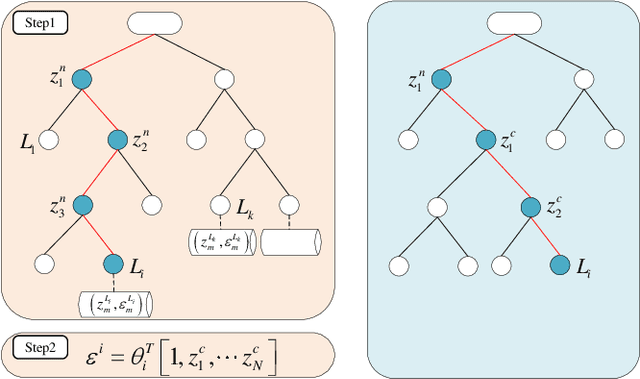
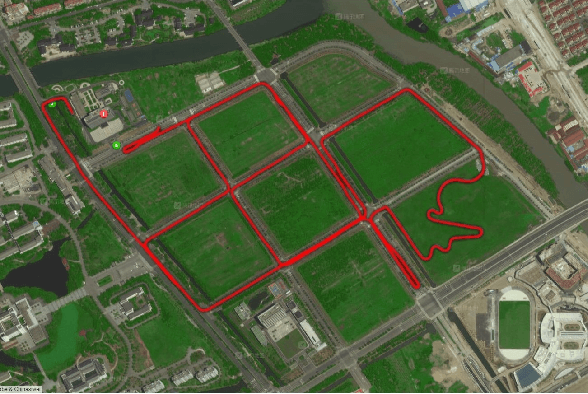
One major issue in learning-based model predictive control (MPC) for autonomous driving is the contradiction between the system model's prediction accuracy and computation efficiency. The more situations a system model covers, the more complex it is, along with highly nonlinear and nonconvex properties. These issues make the optimization too complicated to solve and render real-time control impractical.To address these issues, we propose a hierarchical learning residual model which leverages random forests and linear regression.The learned model consists of two levels. The low level uses linear regression to fit the residues, and the high level uses random forests to switch different linear models. Meanwhile, we adopt the linear dynamic bicycle model with error states as the nominal model.The switched linear regression model is added to the nominal model to form the system model. It reformulates the learning-based MPC as a quadratic program (QP) problem and optimization solvers can effectively solve it. Experimental path tracking results show that the driving vehicle's prediction accuracy and tracking accuracy are significantly improved compared with the nominal MPC.Compared with the state-of-the-art Gaussian process-based nonlinear model predictive control (GP-NMPC), our method gets better performance on tracking accuracy while maintaining a lower computation consumption.
FAN: Fatigue-Aware Network for Click-Through Rate Prediction in E-commerce Recommendation
Apr 10, 2023

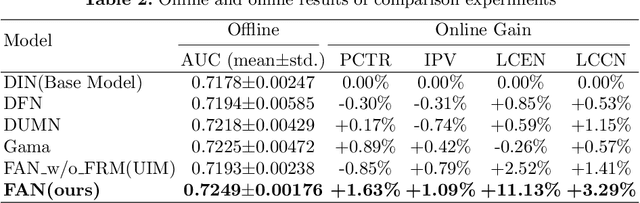
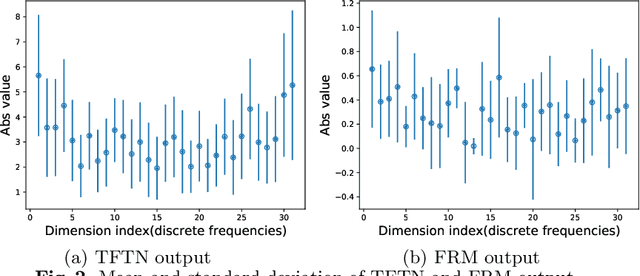
Since clicks usually contain heavy noise, increasing research efforts have been devoted to modeling implicit negative user behaviors (i.e., non-clicks). However, they either rely on explicit negative user behaviors (e.g., dislikes) or simply treat non-clicks as negative feedback, failing to learn negative user interests comprehensively. In such situations, users may experience fatigue because of seeing too many similar recommendations. In this paper, we propose Fatigue-Aware Network (FAN), a novel CTR model that directly perceives user fatigue from non-clicks. Specifically, we first apply Fourier Transformation to the time series generated from non-clicks, obtaining its frequency spectrum which contains comprehensive information about user fatigue. Then the frequency spectrum is modulated by category information of the target item to model the bias that both the upper bound of fatigue and users' patience is different for different categories. Moreover, a gating network is adopted to model the confidence of user fatigue and an auxiliary task is designed to guide the learning of user fatigue, so we can obtain a well-learned fatigue representation and combine it with user interests for the final CTR prediction. Experimental results on real-world datasets validate the superiority of FAN and online A/B tests also show FAN outperforms representative CTR models significantly.
ADS_UNet: A Nested UNet for Histopathology Image Segmentation
Apr 10, 2023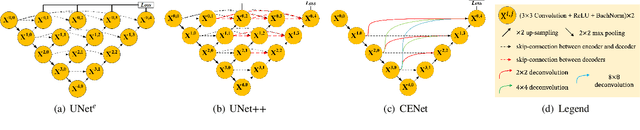
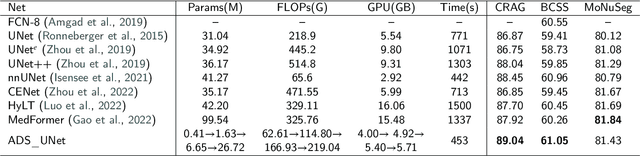
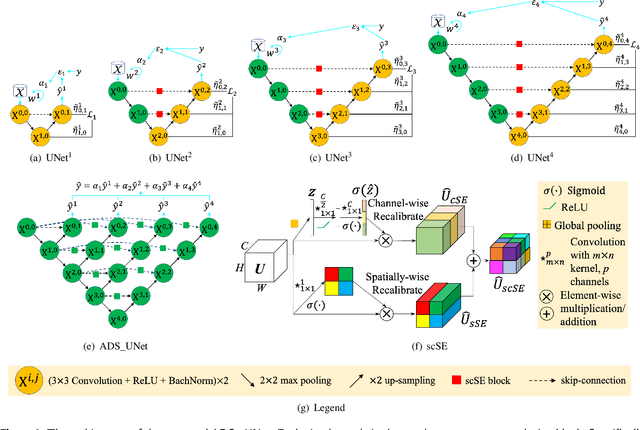

The UNet model consists of fully convolutional network (FCN) layers arranged as contracting encoder and upsampling decoder maps. Nested arrangements of these encoder and decoder maps give rise to extensions of the UNet model, such as UNete and UNet++. Other refinements include constraining the outputs of the convolutional layers to discriminate between segment labels when trained end to end, a property called deep supervision. This reduces feature diversity in these nested UNet models despite their large parameter space. Furthermore, for texture segmentation, pixel correlations at multiple scales contribute to the classification task; hence, explicit deep supervision of shallower layers is likely to enhance performance. In this paper, we propose ADS UNet, a stage-wise additive training algorithm that incorporates resource-efficient deep supervision in shallower layers and takes performance-weighted combinations of the sub-UNets to create the segmentation model. We provide empirical evidence on three histopathology datasets to support the claim that the proposed ADS UNet reduces correlations between constituent features and improves performance while being more resource efficient. We demonstrate that ADS_UNet outperforms state-of-the-art Transformer-based models by 1.08 and 0.6 points on CRAG and BCSS datasets, and yet requires only 37% of GPU consumption and 34% of training time as that required by Transformers.
Simulated Annealing in Early Layers Leads to Better Generalization
Apr 10, 2023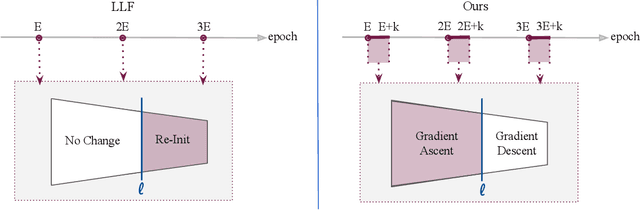
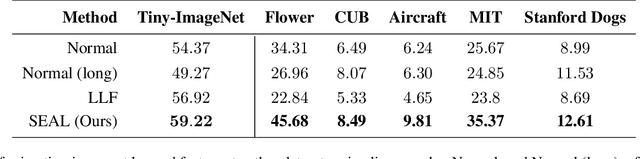
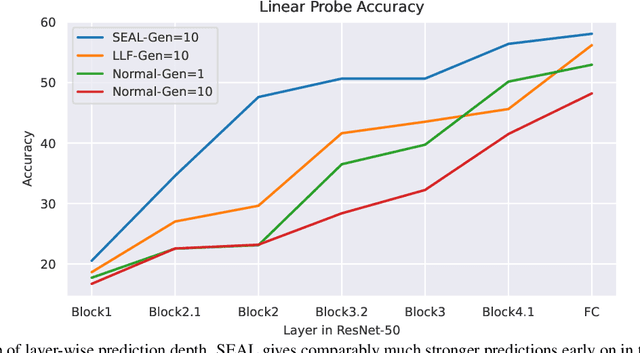
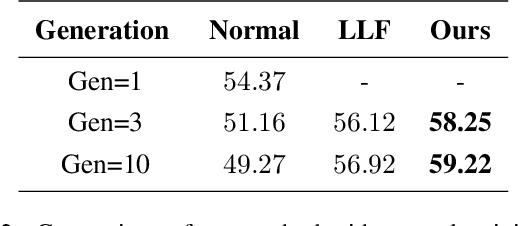
Recently, a number of iterative learning methods have been introduced to improve generalization. These typically rely on training for longer periods of time in exchange for improved generalization. LLF (later-layer-forgetting) is a state-of-the-art method in this category. It strengthens learning in early layers by periodically re-initializing the last few layers of the network. Our principal innovation in this work is to use Simulated annealing in EArly Layers (SEAL) of the network in place of re-initialization of later layers. Essentially, later layers go through the normal gradient descent process, while the early layers go through short stints of gradient ascent followed by gradient descent. Extensive experiments on the popular Tiny-ImageNet dataset benchmark and a series of transfer learning and few-shot learning tasks show that we outperform LLF by a significant margin. We further show that, compared to normal training, LLF features, although improving on the target task, degrade the transfer learning performance across all datasets we explored. In comparison, our method outperforms LLF across the same target datasets by a large margin. We also show that the prediction depth of our method is significantly lower than that of LLF and normal training, indicating on average better prediction performance.