 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Viewpoint: A Theoretical Computer Science Perspective on Consciousness and Artificial General Intelligence
Mar 30, 2023
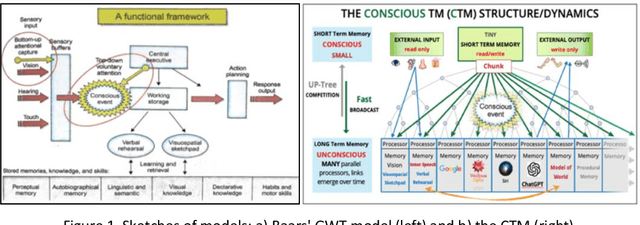
We have defined the Conscious Turing Machine (CTM) for the purpose of investigating a Theoretical Computer Science (TCS) approach to consciousness. For this, we have hewn to the TCS demand for simplicity and understandability. The CTM is consequently and intentionally a simple machine. It is not a model of the brain, though its design has greatly benefited - and continues to benefit - from neuroscience and psychology. The CTM is a model of and for consciousness. Although it is developed to understand consciousness, the CTM offers a thoughtful and novel guide to the creation of an Artificial General Intelligence (AGI). For example, the CTM has an enormous number of powerful processors, some with specialized expertise, others unspecialized but poised to develop an expertise. For whatever problem must be dealt with, the CTM has an excellent way to utilize those processors that have the required knowledge, ability, and time to work on the problem, even if it is not aware of which ones these may be.
Zero-Shot Video Editing Using Off-The-Shelf Image Diffusion Models
Mar 30, 2023
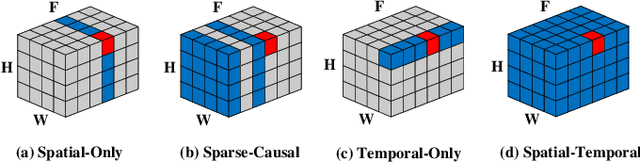

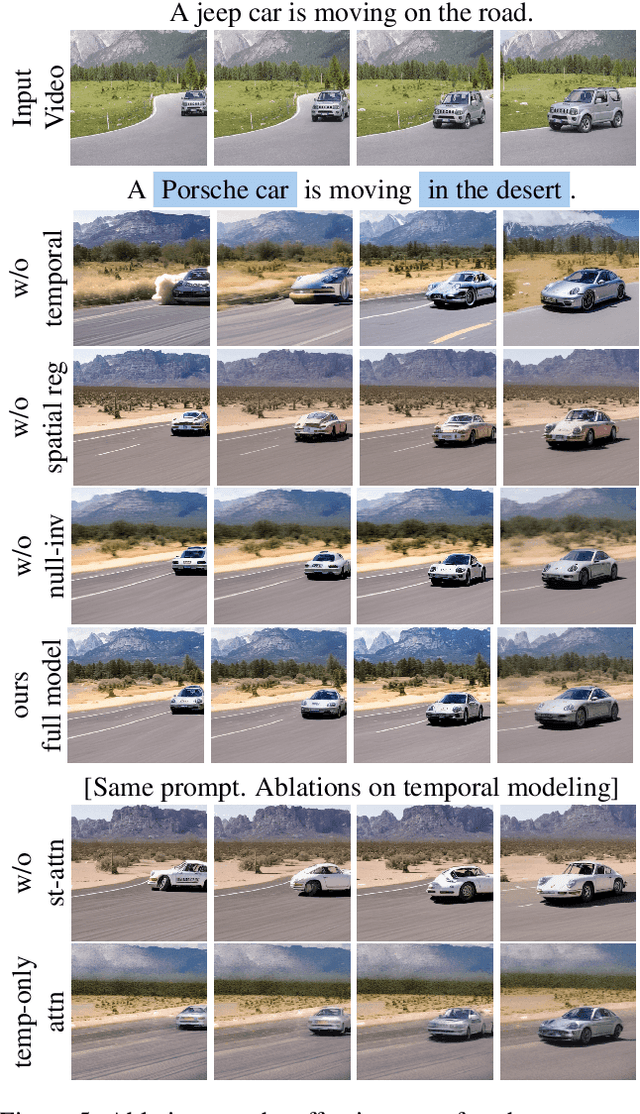
Large-scale text-to-image diffusion models achieve unprecedented success in image generation and editing. However, how to extend such success to video editing is unclear. Recent initial attempts at video editing require significant text-to-video data and computation resources for training, which is often not accessible. In this work, we propose vid2vid-zero, a simple yet effective method for zero-shot video editing. Our vid2vid-zero leverages off-the-shelf image diffusion models, and doesn't require training on any video. At the core of our method is a null-text inversion module for text-to-video alignment, a cross-frame modeling module for temporal consistency, and a spatial regularization module for fidelity to the original video. Without any training, we leverage the dynamic nature of the attention mechanism to enable bi-directional temporal modeling at test time. Experiments and analyses show promising results in editing attributes, subjects, places, etc., in real-world videos. Code will be made available at \url{https://github.com/baaivision/vid2vid-zero}.
Torque Control with Joints Position and Velocity Limits Avoidance
Mar 30, 2023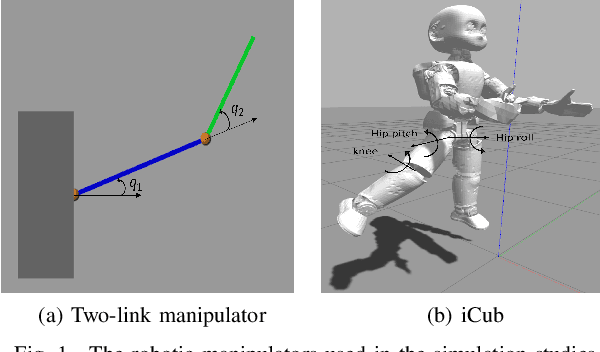
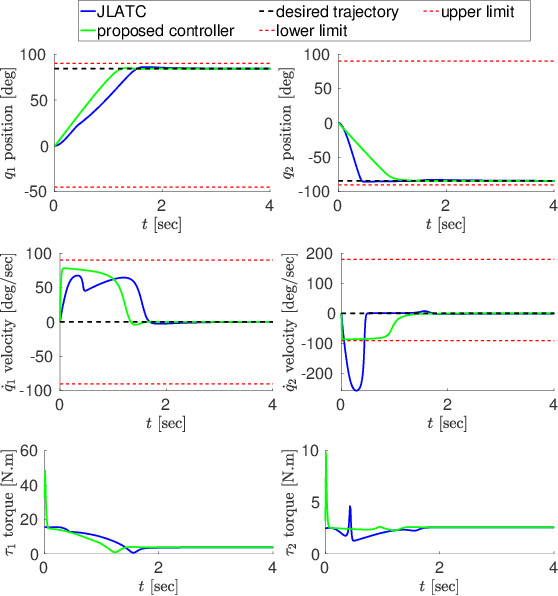
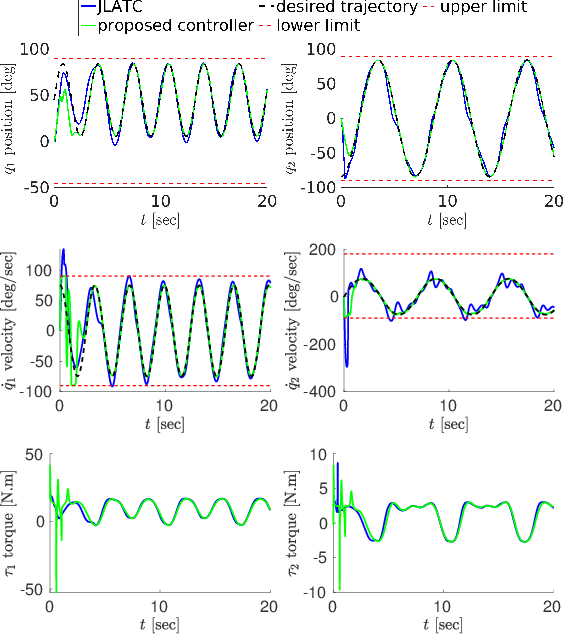
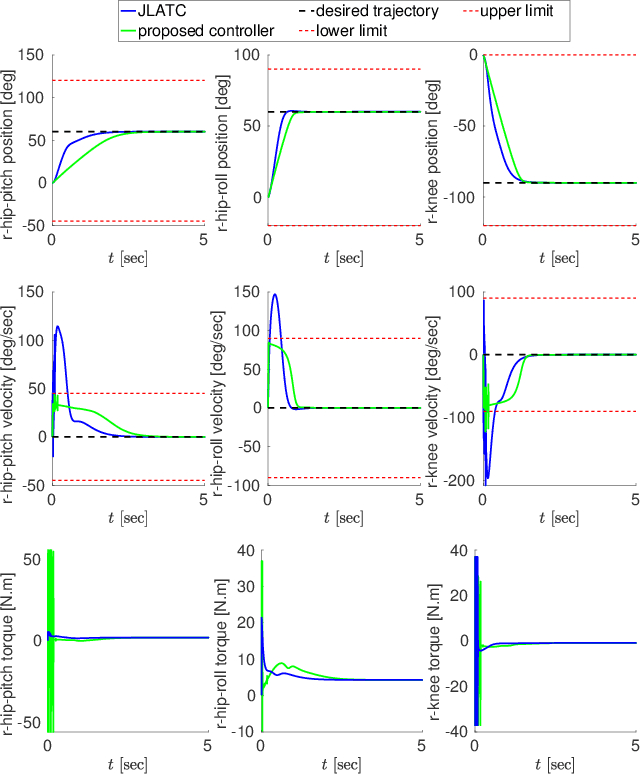
The design of a control architecture for providing the desired motion along with the realization of the joint limitation of a robotic system is still an open challenge in control and robotics. This paper presents a torque control architecture for fully actuated manipulators for tracking the desired time-varying trajectory while ensuring the joints position and velocity limits. The presented architecture stems from the parametrization of the feasible joints position and velocity space by exogenous states. The proposed parametrization transforms the control problem with constrained states to an un-constrained one by replacing the joints position and velocity with the exogenous states. With the help of Lyapunov-based arguments, we prove that the proposed control architecture ensures the stability and convergence of the desired joint trajectory along with the joints position and velocity limits avoidance. We validate the performance of proposed architecture through various simulations on a simple two-degree-of-freedom manipulator and the humanoid robot iCub.
Learning Spiking Neural Systems with the Event-Driven Forward-Forward Process
Mar 30, 2023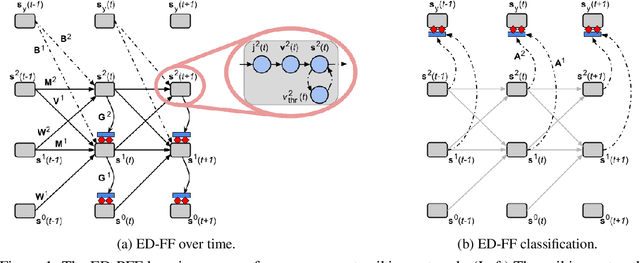
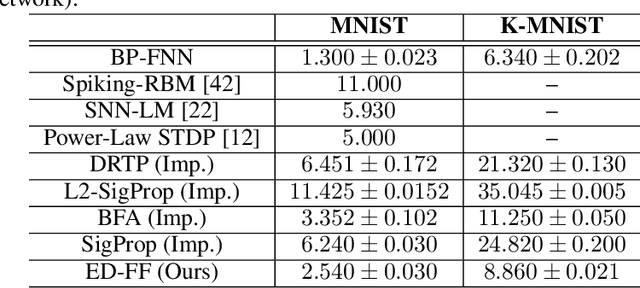
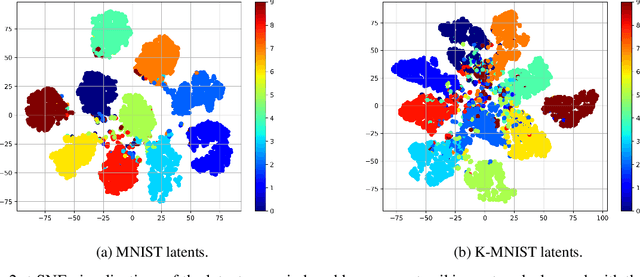

We develop a novel credit assignment algorithm for information processing with spiking neurons without requiring feedback synapses. Specifically, we propose an event-driven generalization of the forward-forward and the predictive forward-forward learning processes for a spiking neural system that iteratively processes sensory input over a stimulus window. As a result, the recurrent circuit computes the membrane potential of each neuron in each layer as a function of local bottom-up, top-down, and lateral signals, facilitating a dynamic, layer-wise parallel form of neural computation. Unlike spiking neural coding, which relies on feedback synapses to adjust neural electrical activity, our model operates purely online and forward in time, offering a promising way to learn distributed representations of sensory data patterns with temporal spike signals. Notably, our experimental results on several pattern datasets demonstrate that the even-driven forward-forward (ED-FF) framework works well for training a dynamic recurrent spiking system capable of both classification and reconstruction.
Taming Encoder for Zero Fine-tuning Image Customization with Text-to-Image Diffusion Models
Apr 05, 2023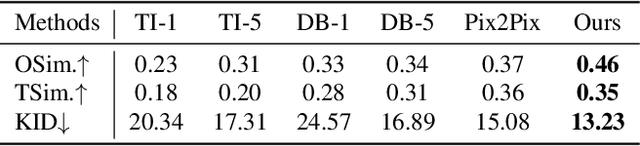
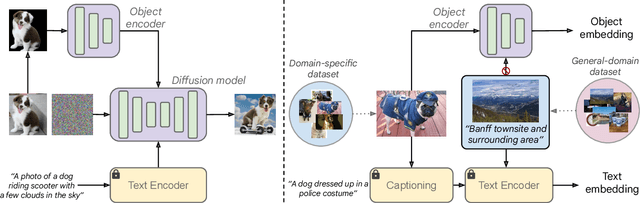
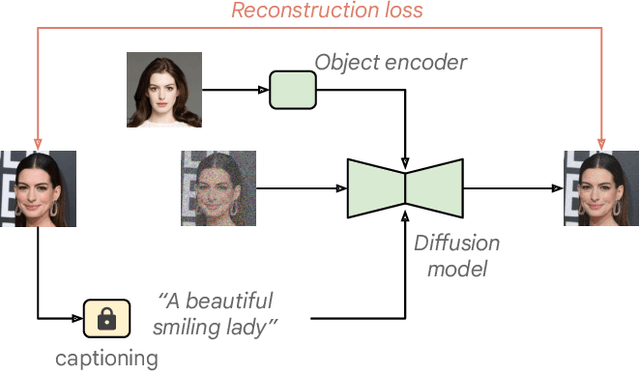

This paper proposes a method for generating images of customized objects specified by users. The method is based on a general framework that bypasses the lengthy optimization required by previous approaches, which often employ a per-object optimization paradigm. Our framework adopts an encoder to capture high-level identifiable semantics of objects, producing an object-specific embedding with only a single feed-forward pass. The acquired object embedding is then passed to a text-to-image synthesis model for subsequent generation. To effectively blend a object-aware embedding space into a well developed text-to-image model under the same generation context, we investigate different network designs and training strategies, and propose a simple yet effective regularized joint training scheme with an object identity preservation loss. Additionally, we propose a caption generation scheme that become a critical piece in fostering object specific embedding faithfully reflected into the generation process, while keeping control and editing abilities. Once trained, the network is able to produce diverse content and styles, conditioned on both texts and objects. We demonstrate through experiments that our proposed method is able to synthesize images with compelling output quality, appearance diversity, and object fidelity, without the need of test-time optimization. Systematic studies are also conducted to analyze our models, providing insights for future work.
Inferring Population Dynamics in Macaque Cortex
Apr 05, 2023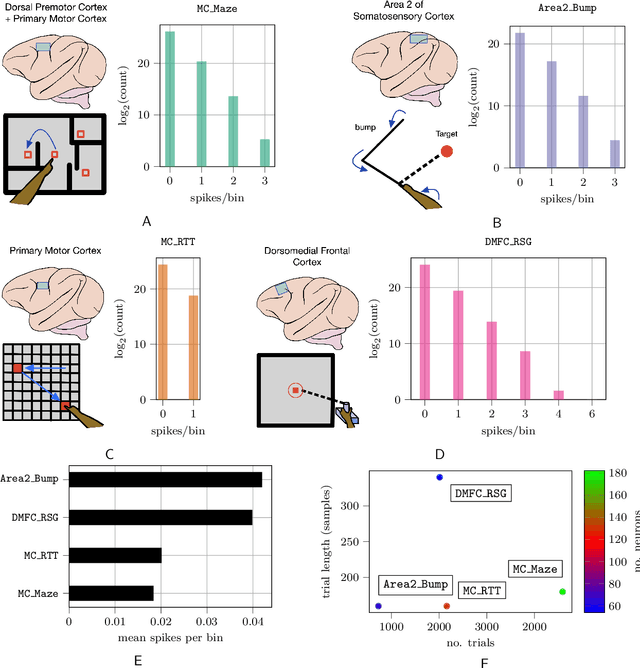
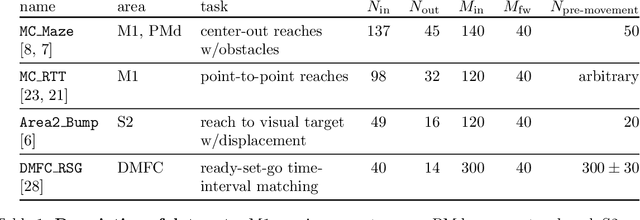
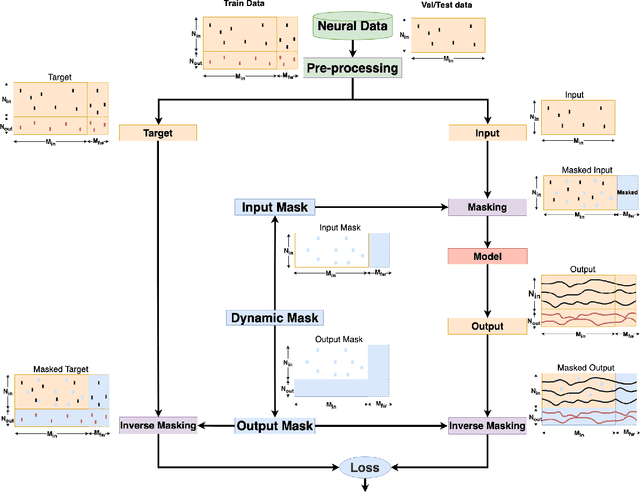
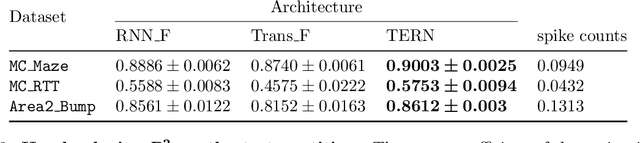
The proliferation of multi-unit cortical recordings over the last two decades, especially in macaques and during motor-control tasks, has generated interest in neural "population dynamics": the time evolution of neural activity across a group of neurons working together. A good model of these dynamics should be able to infer the activity of unobserved neurons within the same population and of the observed neurons at future times. Accordingly, Pandarinath and colleagues have introduced a benchmark to evaluate models on these two (and related) criteria: four data sets, each consisting of firing rates from a population of neurons, recorded from macaque cortex during movement-related tasks. Here we show that simple, general-purpose architectures based on recurrent neural networks (RNNs) outperform more "bespoke" models, and indeed outperform all published models on all four data sets in the benchmark. Performance can be improved further still with a novel, hybrid architecture that augments the RNN with self-attention, as in transformer networks. But pure transformer models fail to achieve this level of performance, either in our work or that of other groups. We argue that the autoregressive bias imposed by RNNs is critical for achieving the highest levels of performance. We conclude, however, by proposing that the benchmark be augmented with an alternative evaluation of latent dynamics that favors generative over discriminative models like the ones we propose in this report.
Solar Power Time Series Forecasting Utilising Wavelet Coefficients
Oct 01, 2022

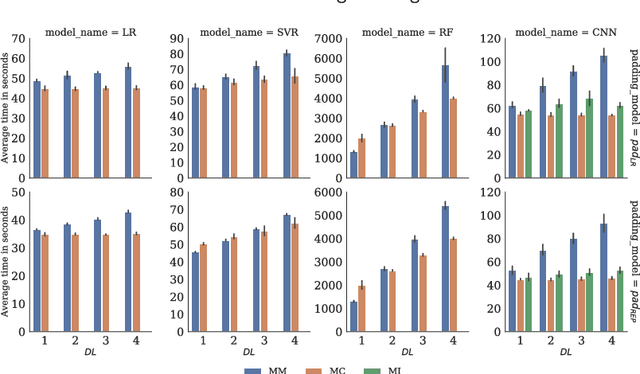
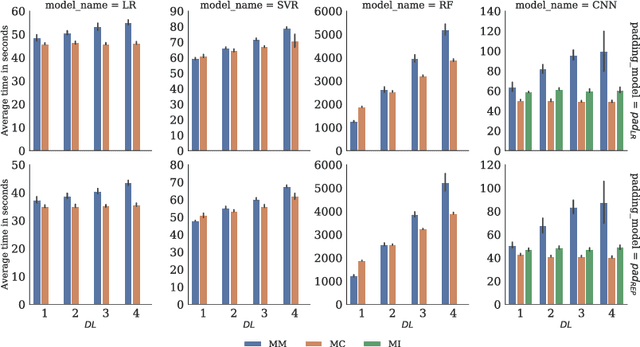
Accurate and reliable prediction of Photovoltaic (PV) power output is critical to electricity grid stability and power dispatching capabilities. However, Photovoltaic (PV) power generation is highly volatile and unstable due to different reasons. The Wavelet Transform (WT) has been utilised in time series applications, such as Photovoltaic (PV) power prediction, to model the stochastic volatility and reduce prediction errors. Yet the existing Wavelet Transform (WT) approach has a limitation in terms of time complexity. It requires reconstructing the decomposed components and modelling them separately and thus needs more time for reconstruction, model configuration and training. The aim of this study is to improve the efficiency of applying Wavelet Transform (WT) by proposing a new method that uses a single simplified model. Given a time series and its Wavelet Transform (WT) coefficients, it trains one model with the coefficients as features and the original time series as labels. This eliminates the need for component reconstruction and training numerous models. This work contributes to the day-ahead aggregated solar Photovoltaic (PV) power time series prediction problem by proposing and comprehensively evaluating a new approach of employing WT. The proposed approach is evaluated using 17 months of aggregated solar Photovoltaic (PV) power data from two real-world datasets. The evaluation includes the use of a variety of prediction models, including Linear Regression, Random Forest, Support Vector Regression, and Convolutional Neural Networks. The results indicate that using a coefficients-based strategy can give predictions that are comparable to those obtained using the components-based approach while requiring fewer models and less computational time.
VADER: Video Alignment Differencing and Retrieval
Mar 25, 2023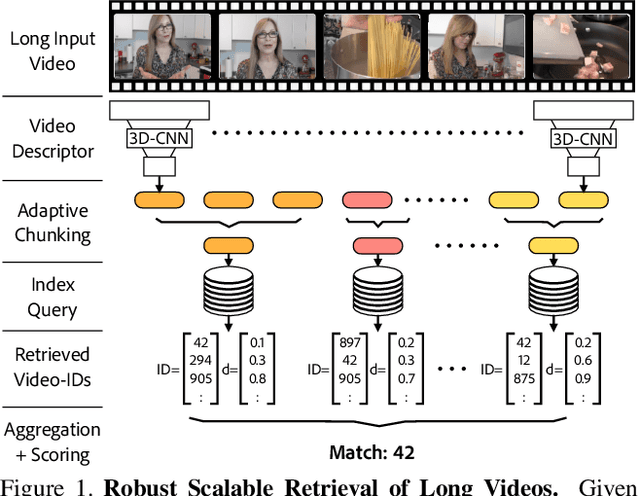
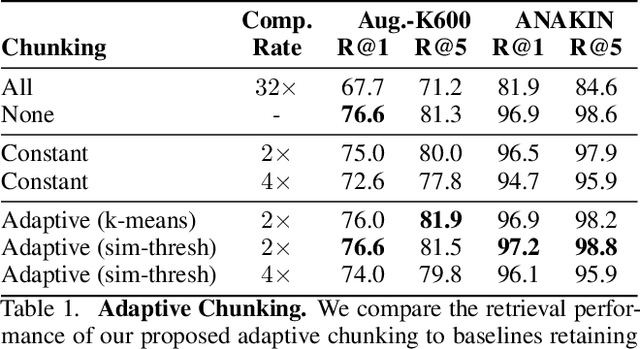

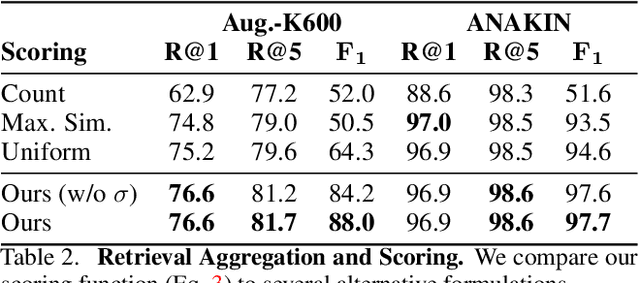
We propose VADER, a spatio-temporal matching, alignment, and change summarization method to help fight misinformation spread via manipulated videos. VADER matches and coarsely aligns partial video fragments to candidate videos using a robust visual descriptor and scalable search over adaptively chunked video content. A transformer-based alignment module then refines the temporal localization of the query fragment within the matched video. A space-time comparator module identifies regions of manipulation between aligned content, invariant to any changes due to any residual temporal misalignments or artifacts arising from non-editorial changes of the content. Robustly matching video to a trusted source enables conclusions to be drawn on video provenance, enabling informed trust decisions on content encountered.
How Efficient Are Today's Continual Learning Algorithms?
Mar 29, 2023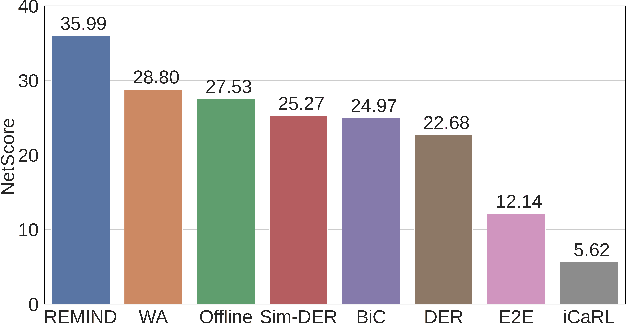
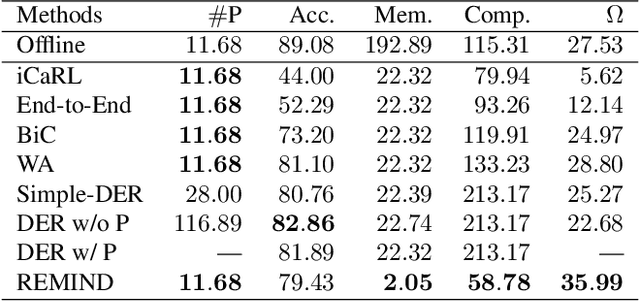
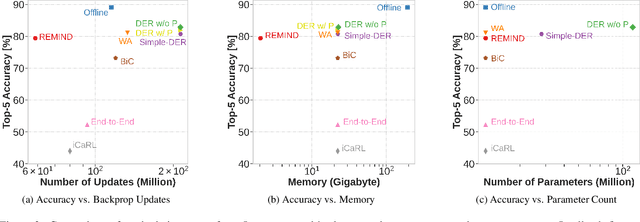
Supervised Continual learning involves updating a deep neural network (DNN) from an ever-growing stream of labeled data. While most work has focused on overcoming catastrophic forgetting, one of the major motivations behind continual learning is being able to efficiently update a network with new information, rather than retraining from scratch on the training dataset as it grows over time. Despite recent continual learning methods largely solving the catastrophic forgetting problem, there has been little attention paid to the efficiency of these algorithms. Here, we study recent methods for incremental class learning and illustrate that many are highly inefficient in terms of compute, memory, and storage. Some methods even require more compute than training from scratch! We argue that for continual learning to have real-world applicability, the research community cannot ignore the resources used by these algorithms. There is more to continual learning than mitigating catastrophic forgetting.
FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model
Mar 17, 2023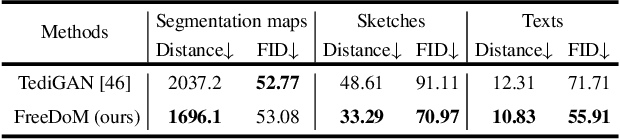



Recently, conditional diffusion models have gained popularity in numerous applications due to their exceptional generation ability. However, many existing methods are training-required. They need to train a time-dependent classifier or a condition-dependent score estimator, which increases the cost of constructing conditional diffusion models and is inconvenient to transfer across different conditions. Some current works aim to overcome this limitation by proposing training-free solutions, but most can only be applied to a specific category of tasks and not to more general conditions. In this work, we propose a training-Free conditional Diffusion Model (FreeDoM) used for various conditions. Specifically, we leverage off-the-shelf pre-trained networks, such as a face detection model, to construct time-independent energy functions, which guide the generation process without requiring training. Furthermore, because the construction of the energy function is very flexible and adaptable to various conditions, our proposed FreeDoM has a broader range of applications than existing training-free methods. FreeDoM is advantageous in its simplicity, effectiveness, and low cost. Experiments demonstrate that FreeDoM is effective for various conditions and suitable for diffusion models of diverse data domains, including image and latent code domains.