 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Joint Assortment-Inventory Optimization under MNL Choices
Apr 04, 2023
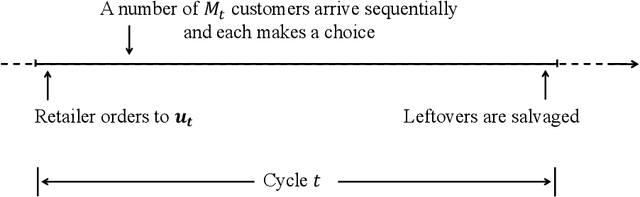

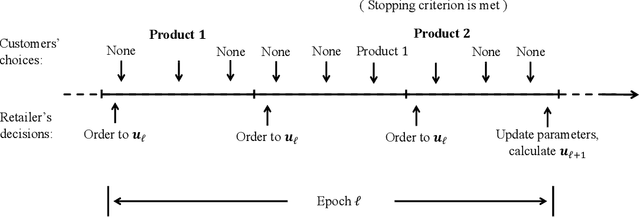
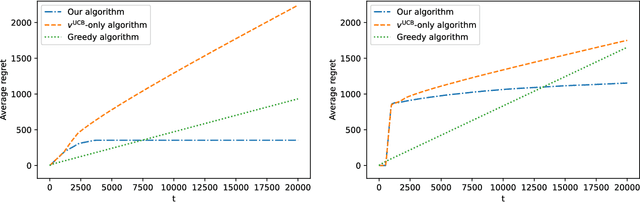
We study an online joint assortment-inventory optimization problem, in which we assume that the choice behavior of each customer follows the Multinomial Logit (MNL) choice model, and the attraction parameters are unknown a priori. The retailer makes periodic assortment and inventory decisions to dynamically learn from the realized demands about the attraction parameters while maximizing the expected total profit over time. In this paper, we propose a novel algorithm that can effectively balance the exploration and exploitation in the online decision-making of assortment and inventory. Our algorithm builds on a new estimator for the MNL attraction parameters, a novel approach to incentivize exploration by adaptively tuning certain known and unknown parameters, and an optimization oracle to static single-cycle assortment-inventory planning problems with given parameters. We establish a regret upper bound for our algorithm and a lower bound for the online joint assortment-inventory optimization problem, suggesting that our algorithm achieves nearly optimal regret rate, provided that the static optimization oracle is exact. Then we incorporate more practical approximate static optimization oracles into our algorithm, and bound from above the impact of static optimization errors on the regret of our algorithm. At last, we perform numerical studies to demonstrate the effectiveness of our proposed algorithm.
Scientific Computing Algorithms to Learn Enhanced Scalable Surrogates for Mesh Physics
Apr 01, 2023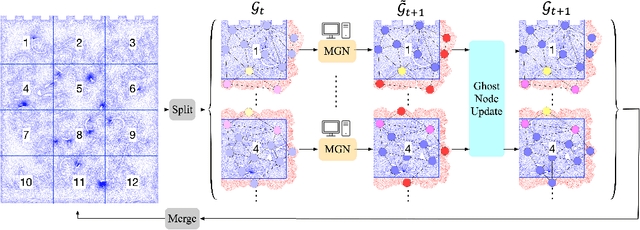

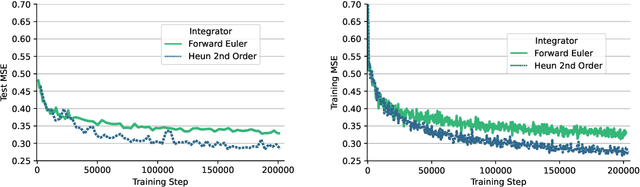
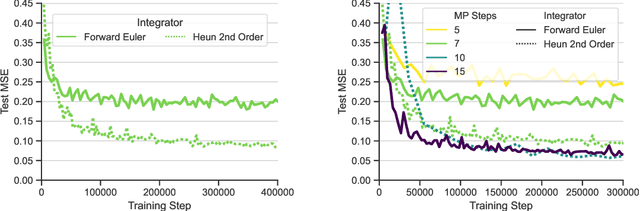
Data-driven modeling approaches can produce fast surrogates to study large-scale physics problems. Among them, graph neural networks (GNNs) that operate on mesh-based data are desirable because they possess inductive biases that promote physical faithfulness, but hardware limitations have precluded their application to large computational domains. We show that it is \textit{possible} to train a class of GNN surrogates on 3D meshes. We scale MeshGraphNets (MGN), a subclass of GNNs for mesh-based physics modeling, via our domain decomposition approach to facilitate training that is mathematically equivalent to training on the whole domain under certain conditions. With this, we were able to train MGN on meshes with \textit{millions} of nodes to generate computational fluid dynamics (CFD) simulations. Furthermore, we show how to enhance MGN via higher-order numerical integration, which can reduce MGN's error and training time. We validated our methods on an accompanying dataset of 3D $\text{CO}_2$-capture CFD simulations on a 3.1M-node mesh. This work presents a practical path to scaling MGN for real-world applications.
ASTF: Visual Abstractions of Time-Varying Patterns in Radio Signals
Sep 30, 2022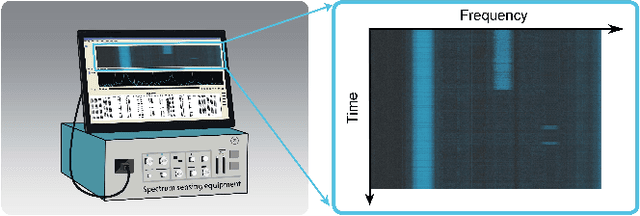
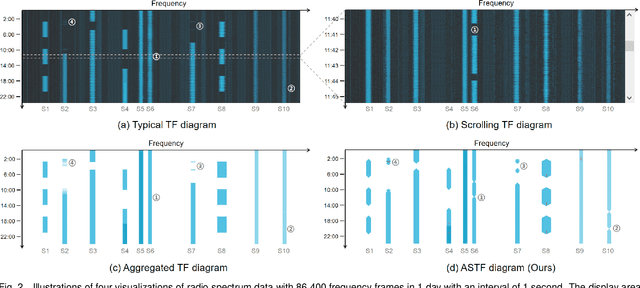
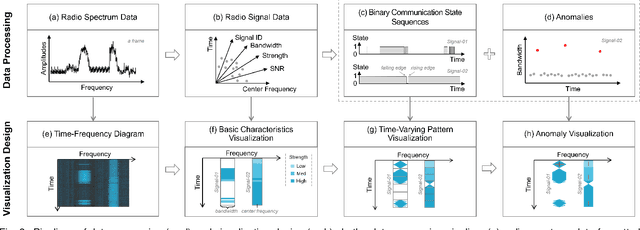
A time-frequency diagram is a commonly used visualization for observing the time-frequency distribution of radio signals and analyzing their time-varying patterns of communication states in radio monitoring and management. While it excels when performing short-term signal analyses, it becomes inadaptable for long-term signal analyses because it cannot adequately depict signal time-varying patterns in a large time span on a space-limited screen. This research thus presents an abstract signal time-frequency (ASTF) diagram to address this problem. In the diagram design, a visual abstraction method is proposed to visually encode signal communication state changes in time slices. A time segmentation algorithm is proposed to divide a large time span into time slices.Three new quantified metrics and a loss function are defined to ensure the preservation of important time-varying information in the time segmentation. An algorithm performance experiment and a user study are conducted to evaluate the effectiveness of the diagram for long-term signal analyses.
PACE: Data-Driven Virtual Agent Interaction in Dense and Cluttered Environments
Mar 24, 2023
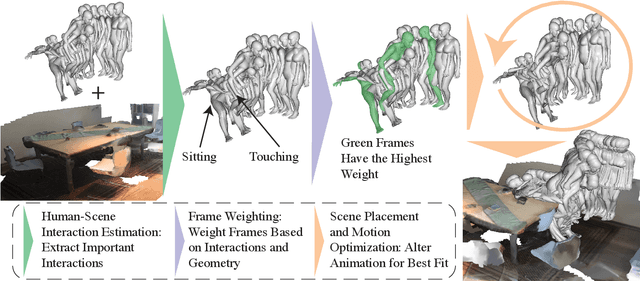
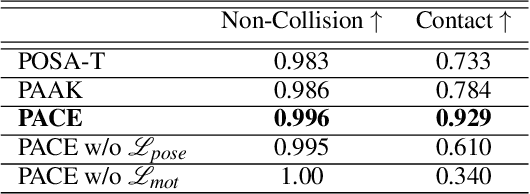
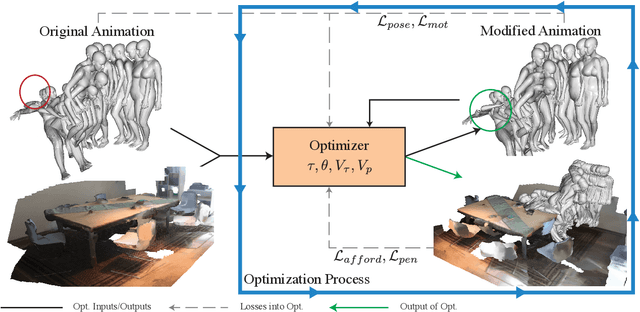
We present PACE, a novel method for modifying motion-captured virtual agents to interact with and move throughout dense, cluttered 3D scenes. Our approach changes a given motion sequence of a virtual agent as needed to adjust to the obstacles and objects in the environment. We first take the individual frames of the motion sequence most important for modeling interactions with the scene and pair them with the relevant scene geometry, obstacles, and semantics such that interactions in the agents motion match the affordances of the scene (e.g., standing on a floor or sitting in a chair). We then optimize the motion of the human by directly altering the high-DOF pose at each frame in the motion to better account for the unique geometric constraints of the scene. Our formulation uses novel loss functions that maintain a realistic flow and natural-looking motion. We compare our method with prior motion generating techniques and highlight the benefits of our method with a perceptual study and physical plausibility metrics. Human raters preferred our method over the prior approaches. Specifically, they preferred our method 57.1% of the time versus the state-of-the-art method using existing motions, and 81.0% of the time versus a state-of-the-art motion synthesis method. Additionally, our method performs significantly higher on established physical plausibility and interaction metrics. Specifically, we outperform competing methods by over 1.2% in terms of the non-collision metric and by over 18% in terms of the contact metric. We have integrated our interactive system with Microsoft HoloLens and demonstrate its benefits in real-world indoor scenes. Our project website is available at https://gamma.umd.edu/pace/.
Applications of Gaussian Processes at Extreme Lengthscales: From Molecules to Black Holes
Mar 24, 2023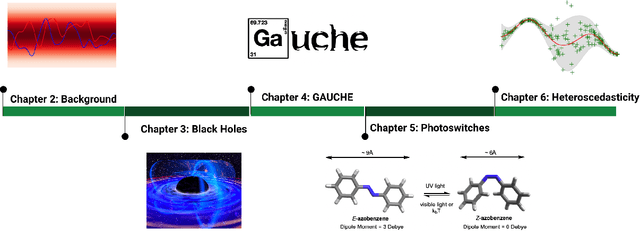
In many areas of the observational and experimental sciences data is scarce. Data observation in high-energy astrophysics is disrupted by celestial occlusions and limited telescope time while data derived from laboratory experiments in synthetic chemistry and materials science is time and cost-intensive to collect. On the other hand, knowledge about the data-generation mechanism is often available in the sciences, such as the measurement error of a piece of laboratory apparatus. Both characteristics, small data and knowledge of the underlying physics, make Gaussian processes (GPs) ideal candidates for fitting such datasets. GPs can make predictions with consideration of uncertainty, for example in the virtual screening of molecules and materials, and can also make inferences about incomplete data such as the latent emission signature from a black hole accretion disc. Furthermore, GPs are currently the workhorse model for Bayesian optimisation, a methodology foreseen to be a guide for laboratory experiments in scientific discovery campaigns. The first contribution of this thesis is to use GP modelling to reason about the latent emission signature from the Seyfert galaxy Markarian 335, and by extension, to reason about the applicability of various theoretical models of black hole accretion discs. The second contribution is to extend the GP framework to molecular and chemical reaction representations and to provide an open-source software library to enable the framework to be used by scientists. The third contribution is to leverage GPs to discover novel and performant photoswitch molecules. The fourth contribution is to introduce a Bayesian optimisation scheme capable of modelling aleatoric uncertainty to facilitate the identification of material compositions that possess intrinsic robustness to large scale fabrication processes.
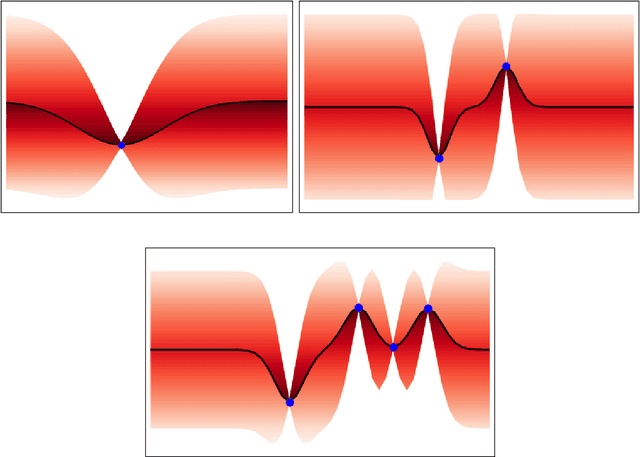
Training Time Adversarial Attack Aiming the Vulnerability of Continual Learning
Nov 29, 2022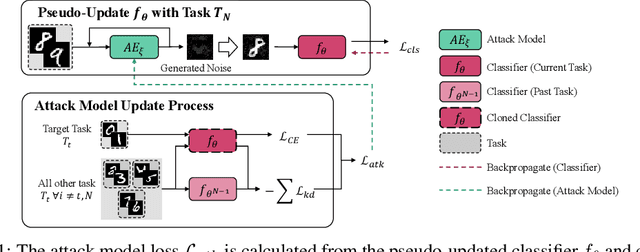
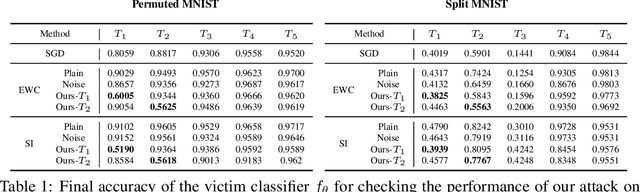

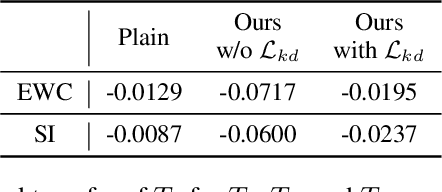
Generally, regularization-based continual learning models limit access to the previous task data to imitate the real-world setting which has memory and privacy issues. However, this introduces a problem in these models by not being able to track the performance on each task. In other words, current continual learning methods are vulnerable to attacks done on the previous task. We demonstrate the vulnerability of regularization-based continual learning methods by presenting simple task-specific training time adversarial attack that can be used in the learning process of a new task. Training data generated by the proposed attack causes performance degradation on a specific task targeted by the attacker. Experiment results justify the vulnerability proposed in this paper and demonstrate the importance of developing continual learning models that are robust to adversarial attack.
Solar Power Time Series Forecasting Utilising Wavelet Coefficients
Oct 01, 2022

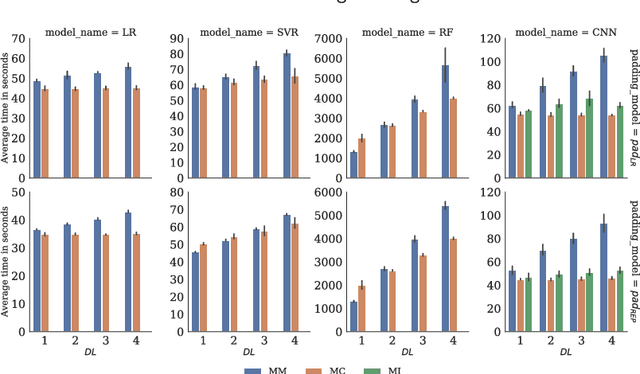
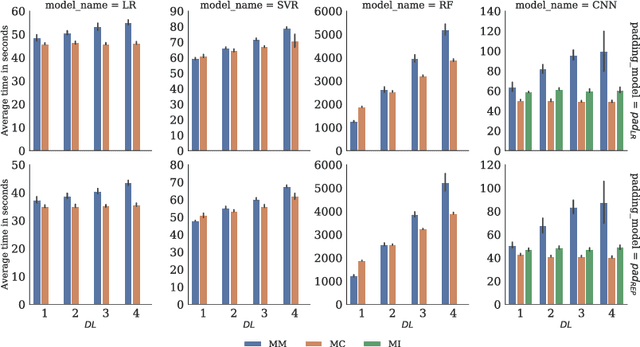
Accurate and reliable prediction of Photovoltaic (PV) power output is critical to electricity grid stability and power dispatching capabilities. However, Photovoltaic (PV) power generation is highly volatile and unstable due to different reasons. The Wavelet Transform (WT) has been utilised in time series applications, such as Photovoltaic (PV) power prediction, to model the stochastic volatility and reduce prediction errors. Yet the existing Wavelet Transform (WT) approach has a limitation in terms of time complexity. It requires reconstructing the decomposed components and modelling them separately and thus needs more time for reconstruction, model configuration and training. The aim of this study is to improve the efficiency of applying Wavelet Transform (WT) by proposing a new method that uses a single simplified model. Given a time series and its Wavelet Transform (WT) coefficients, it trains one model with the coefficients as features and the original time series as labels. This eliminates the need for component reconstruction and training numerous models. This work contributes to the day-ahead aggregated solar Photovoltaic (PV) power time series prediction problem by proposing and comprehensively evaluating a new approach of employing WT. The proposed approach is evaluated using 17 months of aggregated solar Photovoltaic (PV) power data from two real-world datasets. The evaluation includes the use of a variety of prediction models, including Linear Regression, Random Forest, Support Vector Regression, and Convolutional Neural Networks. The results indicate that using a coefficients-based strategy can give predictions that are comparable to those obtained using the components-based approach while requiring fewer models and less computational time.
Category Query Learning for Human-Object Interaction Classification
Mar 24, 2023
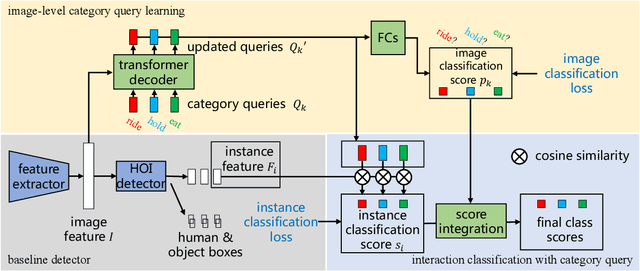
Unlike most previous HOI methods that focus on learning better human-object features, we propose a novel and complementary approach called category query learning. Such queries are explicitly associated to interaction categories, converted to image specific category representation via a transformer decoder, and learnt via an auxiliary image-level classification task. This idea is motivated by an earlier multi-label image classification method, but is for the first time applied for the challenging human-object interaction classification task. Our method is simple, general and effective. It is validated on three representative HOI baselines and achieves new state-of-the-art results on two benchmarks.
Decision Making for Human-in-the-loop Robotic Agents via Uncertainty-Aware Reinforcement Learning
Mar 14, 2023
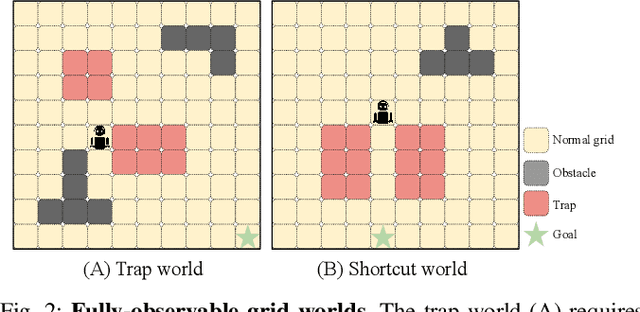
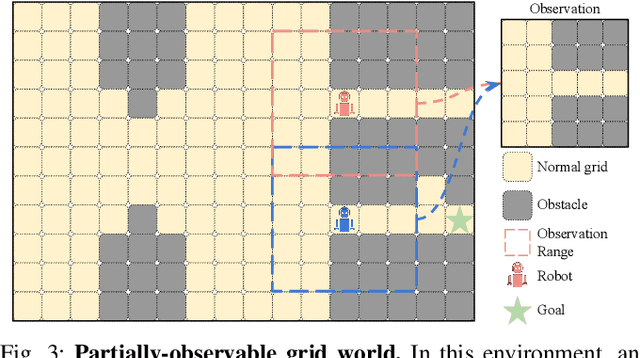
In a Human-in-the-Loop paradigm, a robotic agent is able to act mostly autonomously in solving a task, but can request help from an external expert when needed. However, knowing when to request such assistance is critical: too few requests can lead to the robot making mistakes, but too many requests can overload the expert. In this paper, we present a Reinforcement Learning based approach to this problem, where a semi-autonomous agent asks for external assistance when it has low confidence in the eventual success of the task. The confidence level is computed by estimating the variance of the return from the current state. We show that this estimate can be iteratively improved during training using a Bellman-like recursion. On discrete navigation problems with both fully- and partially-observable state information, we show that our method makes effective use of a limited budget of expert calls at run-time, despite having no access to the expert at training time.
Sketch2Saliency: Learning to Detect Salient Objects from Human Drawings
Mar 30, 2023
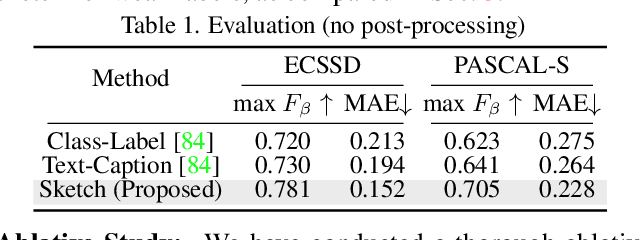

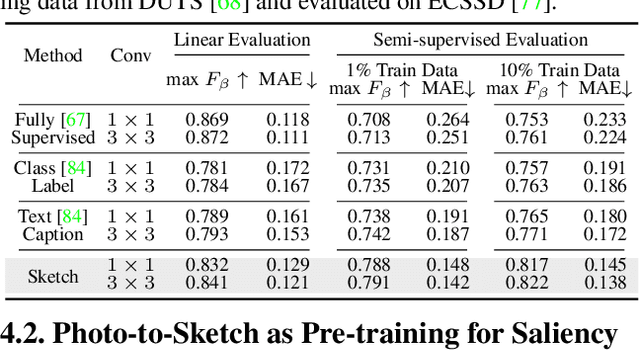
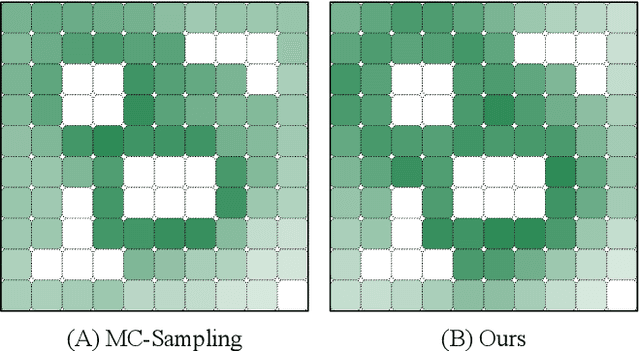
Human sketch has already proved its worth in various visual understanding tasks (e.g., retrieval, segmentation, image-captioning, etc). In this paper, we reveal a new trait of sketches - that they are also salient. This is intuitive as sketching is a natural attentive process at its core. More specifically, we aim to study how sketches can be used as a weak label to detect salient objects present in an image. To this end, we propose a novel method that emphasises on how "salient object" could be explained by hand-drawn sketches. To accomplish this, we introduce a photo-to-sketch generation model that aims to generate sequential sketch coordinates corresponding to a given visual photo through a 2D attention mechanism. Attention maps accumulated across the time steps give rise to salient regions in the process. Extensive quantitative and qualitative experiments prove our hypothesis and delineate how our sketch-based saliency detection model gives a competitive performance compared to the state-of-the-art.