 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
mmSense: Detecting Concealed Weapons with a Miniature Radar Sensor
Feb 28, 2023
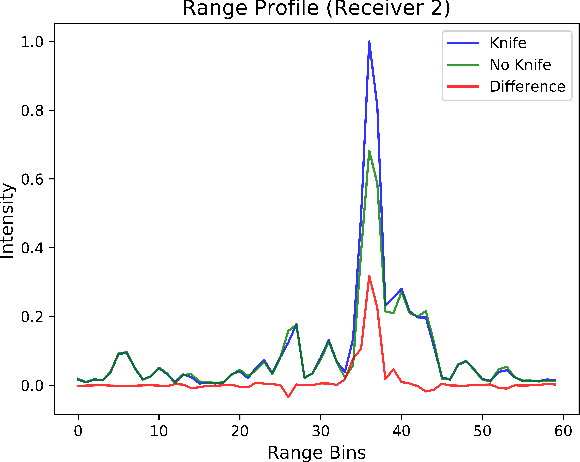
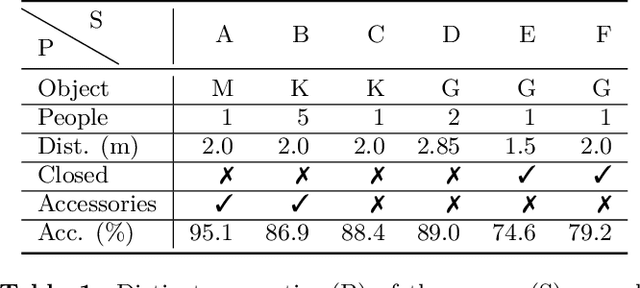
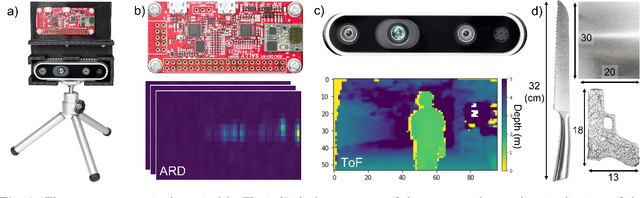
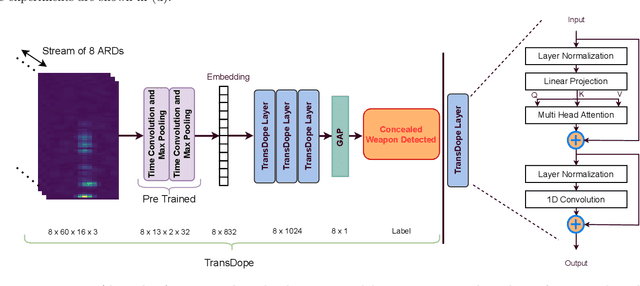
For widespread adoption, public security and surveillance systems must be accurate, portable, compact, and real-time, without impeding the privacy of the individuals being observed. Current systems broadly fall into two categories -- image-based which are accurate, but lack privacy, and RF signal-based, which preserve privacy but lack portability, compactness and accuracy. Our paper proposes mmSense, an end-to-end portable miniaturised real-time system that can accurately detect the presence of concealed metallic objects on persons in a discrete, privacy-preserving modality. mmSense features millimeter wave radar technology, provided by Google's Soli sensor for its data acquisition, and TransDope, our real-time neural network, capable of processing a single radar data frame in 19 ms. mmSense achieves high recognition rates on a diverse set of challenging scenes while running on standard laptop hardware, demonstrating a significant advancement towards creating portable, cost-effective real-time radar based surveillance systems.
Exploring Effective Factors for Improving Visual In-Context Learning
Apr 10, 2023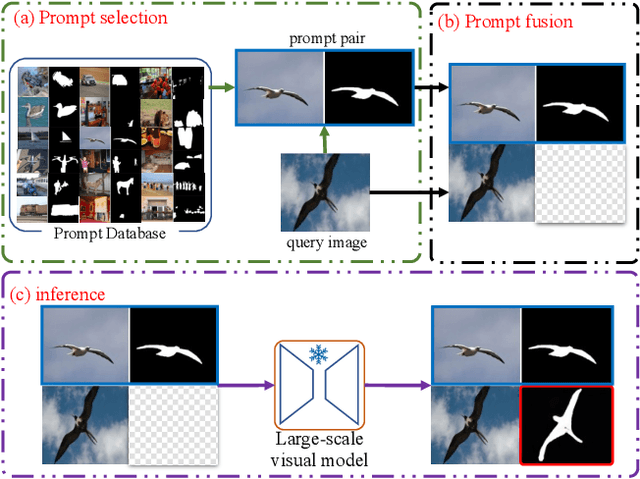
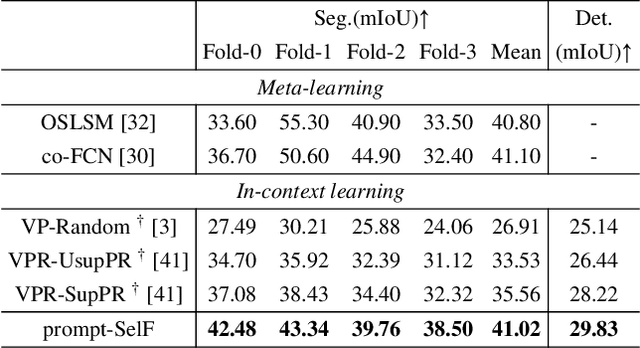
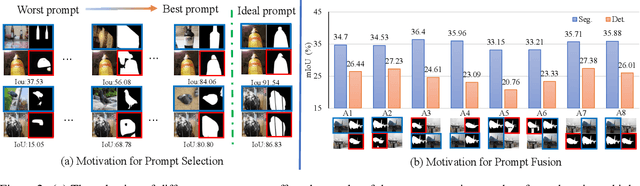

The In-Context Learning (ICL) is to understand a new task via a few demonstrations (aka. prompt) and predict new inputs without tuning the models. While it has been widely studied in NLP, it is still a relatively new area of research in computer vision. To reveal the factors influencing the performance of visual in-context learning, this paper shows that prompt selection and prompt fusion are two major factors that have a direct impact on the inference performance of visual context learning. Prompt selection is the process of identifying the most appropriate prompt or example to help the model understand new tasks. This is important because providing the model with relevant prompts can help it learn more effectively and efficiently. Prompt fusion involves combining knowledge from different positions within the large-scale visual model. By doing this, the model can leverage the diverse knowledge stored in different parts of the model to improve its performance on new tasks. Based these findings, we propose a simple framework prompt-SelF for visual in-context learning. Specifically, we first use the pixel-level retrieval method to select a suitable prompt, and then use different prompt fusion methods to activate all the knowledge stored in the large-scale model, and finally ensemble the prediction results obtained from different prompt fusion methods to obtain the final prediction results. And we conduct extensive experiments on single-object segmentation and detection tasks to demonstrate the effectiveness of prompt-SelF. Remarkably, the prompt-SelF has outperformed OSLSM based meta-learning in 1-shot segmentation for the first time. This indicated the great potential of visual in-context learning. The source code and models will be available at \url{https://github.com/syp2ysy/prompt-SelF}.
Regret Distribution in Stochastic Bandits: Optimal Trade-off between Expectation and Tail Risk
Apr 10, 2023

We study the trade-off between expectation and tail risk for regret distribution in the stochastic multi-armed bandit problem. We fully characterize the interplay among three desired properties for policy design: worst-case optimality, instance-dependent consistency, and light-tailed risk. We show how the order of expected regret exactly affects the decaying rate of the regret tail probability for both the worst-case and instance-dependent scenario. A novel policy is proposed to characterize the optimal regret tail probability for any regret threshold. Concretely, for any given $\alpha\in[1/2, 1)$ and $\beta\in[0, \alpha]$, our policy achieves a worst-case expected regret of $\tilde O(T^\alpha)$ (we call it $\alpha$-optimal) and an instance-dependent expected regret of $\tilde O(T^\beta)$ (we call it $\beta$-consistent), while enjoys a probability of incurring an $\tilde O(T^\delta)$ regret ($\delta\geq\alpha$ in the worst-case scenario and $\delta\geq\beta$ in the instance-dependent scenario) that decays exponentially with a polynomial $T$ term. Such decaying rate is proved to be best achievable. Moreover, we discover an intrinsic gap of the optimal tail rate under the instance-dependent scenario between whether the time horizon $T$ is known a priori or not. Interestingly, when it comes to the worst-case scenario, this gap disappears. Finally, we extend our proposed policy design to (1) a stochastic multi-armed bandit setting with non-stationary baseline rewards, and (2) a stochastic linear bandit setting. Our results reveal insights on the trade-off between regret expectation and regret tail risk for both worst-case and instance-dependent scenarios, indicating that more sub-optimality and inconsistency leave space for more light-tailed risk of incurring a large regret, and that knowing the planning horizon in advance can make a difference on alleviating tail risks.
Baldur: Whole-Proof Generation and Repair with Large Language Models
Mar 16, 2023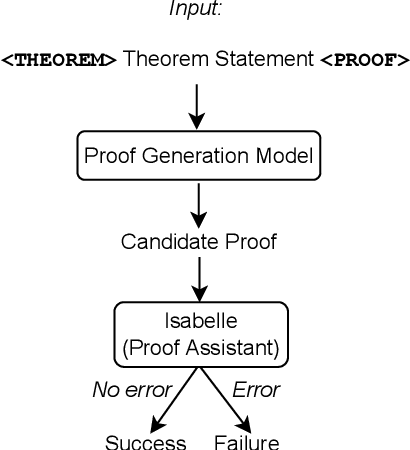
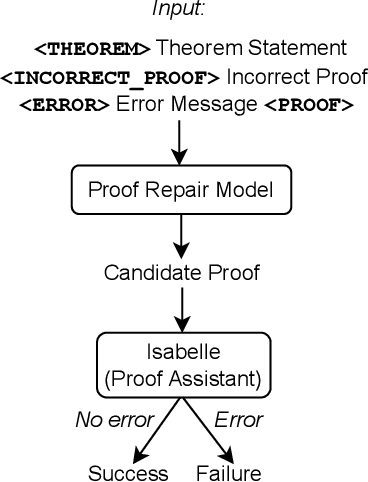
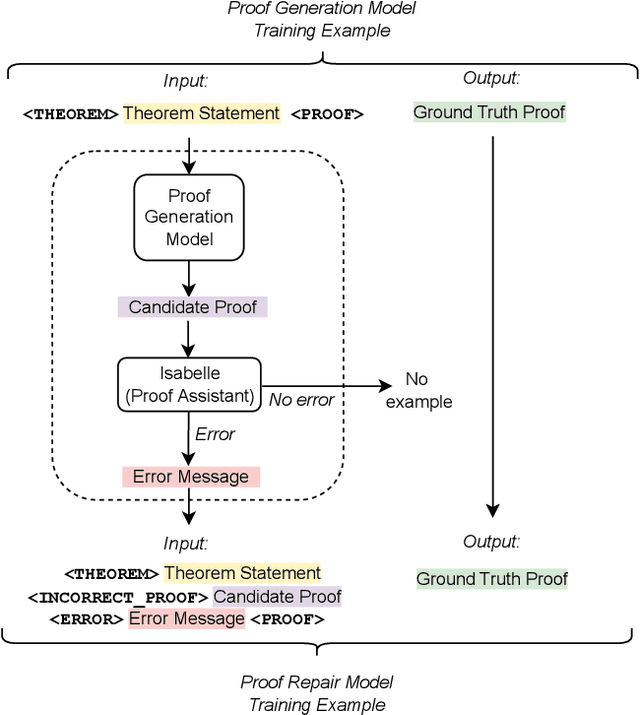
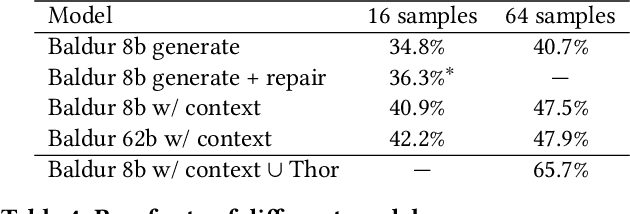
Formally verifying software properties is a highly desirable but labor-intensive task. Recent work has developed methods to automate formal verification using proof assistants, such as Coq and Isabelle/HOL, e.g., by training a model to predict one proof step at a time, and using that model to search through the space of possible proofs. This paper introduces a new method to automate formal verification: We use large language models, trained on natural language text and code and fine-tuned on proofs, to generate whole proofs for theorems at once, rather than one step at a time. We combine this proof generation model with a fine-tuned repair model to repair generated proofs, further increasing proving power. As its main contributions, this paper demonstrates for the first time that: (1) Whole-proof generation using transformers is possible and is as effective as search-based techniques without requiring costly search. (2) Giving the learned model additional context, such as a prior failed proof attempt and the ensuing error message, results in proof repair and further improves automated proof generation. (3) We establish a new state of the art for fully automated proof synthesis. We reify our method in a prototype, Baldur, and evaluate it on a benchmark of 6,336 Isabelle/HOL theorems and their proofs. In addition to empirically showing the effectiveness of whole-proof generation, repair, and added context, we show that Baldur improves on the state-of-the-art tool, Thor, by automatically generating proofs for an additional 8.7% of the theorems. Together, Baldur and Thor can prove 65.7% of the theorems fully automatically. This paper paves the way for new research into using large language models for automating formal verification.
ExoplANNET: A deep learning algorithm to detect and identify planetary signals in radial velocity data
Mar 16, 2023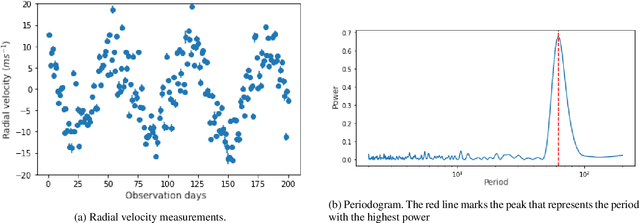
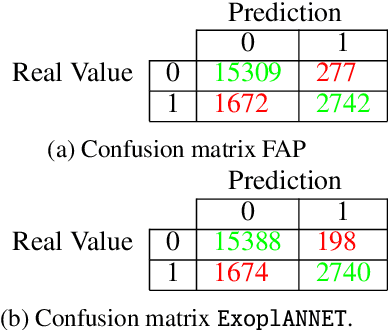
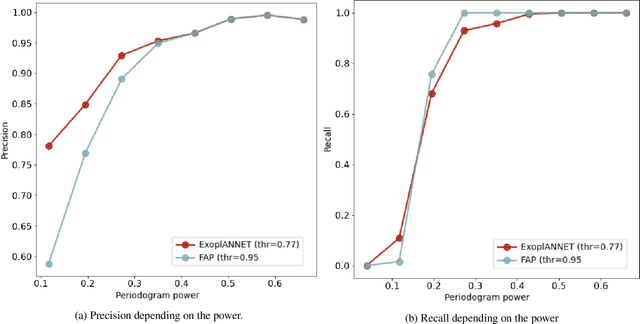
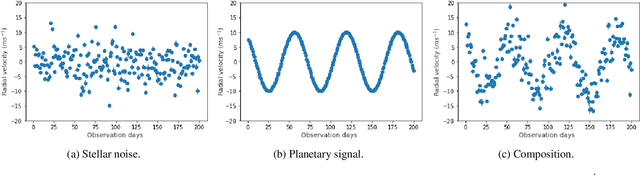
The detection of exoplanets with the radial velocity method consists in detecting variations of the stellar velocity caused by an unseen sub-stellar companion. Instrumental errors, irregular time sampling, and different noise sources originating in the intrinsic variability of the star can hinder the interpretation of the data, and even lead to spurious detections. In recent times, work began to emerge in the field of extrasolar planets that use Machine Learning algorithms, some with results that exceed those obtained with the traditional techniques in the field. We seek to explore the scope of the neural networks in the radial velocity method, in particular for exoplanet detection in the presence of correlated noise of stellar origin. In this work, a neural network is proposed to replace the computation of the significance of the signal detected with the radial velocity method and to classify it as of planetary origin or not. The algorithm is trained using synthetic data of systems with and without planetary companions. We injected realistic correlated noise in the simulations, based on previous studies of the behaviour of stellar activity. The performance of the network is compared to the traditional method based on null hypothesis significance testing. The network achieves 28 % fewer false positives. The improvement is observed mainly in the detection of small-amplitude signals associated with low-mass planets. In addition, its execution time is five orders of magnitude faster than the traditional method. The superior performance exhibited by the algorithm has only been tested on simulated radial velocity data so far. Although in principle it should be straightforward to adapt it for use in real time series, its performance has to be tested thoroughly. Future work should permit evaluating its potential for adoption as a valuable tool for exoplanet detection.
NeRFMeshing: Distilling Neural Radiance Fields into Geometrically-Accurate 3D Meshes
Mar 16, 2023
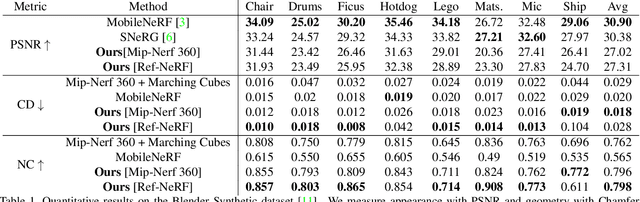


With the introduction of Neural Radiance Fields (NeRFs), novel view synthesis has recently made a big leap forward. At the core, NeRF proposes that each 3D point can emit radiance, allowing to conduct view synthesis using differentiable volumetric rendering. While neural radiance fields can accurately represent 3D scenes for computing the image rendering, 3D meshes are still the main scene representation supported by most computer graphics and simulation pipelines, enabling tasks such as real time rendering and physics-based simulations. Obtaining 3D meshes from neural radiance fields still remains an open challenge since NeRFs are optimized for view synthesis, not enforcing an accurate underlying geometry on the radiance field. We thus propose a novel compact and flexible architecture that enables easy 3D surface reconstruction from any NeRF-driven approach. Upon having trained the radiance field, we distill the volumetric 3D representation into a Signed Surface Approximation Network, allowing easy extraction of the 3D mesh and appearance. Our final 3D mesh is physically accurate and can be rendered in real time on an array of devices.
Solar Power Time Series Forecasting Utilising Wavelet Coefficients
Oct 01, 2022

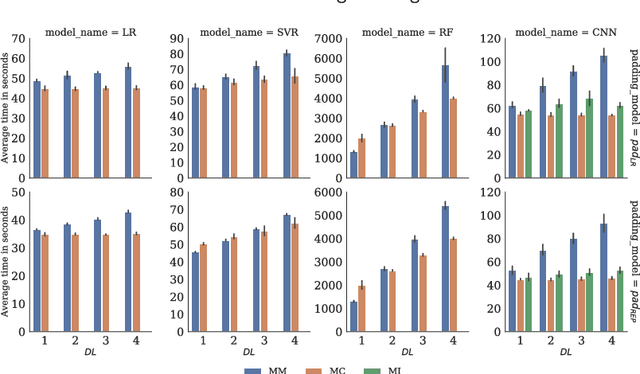
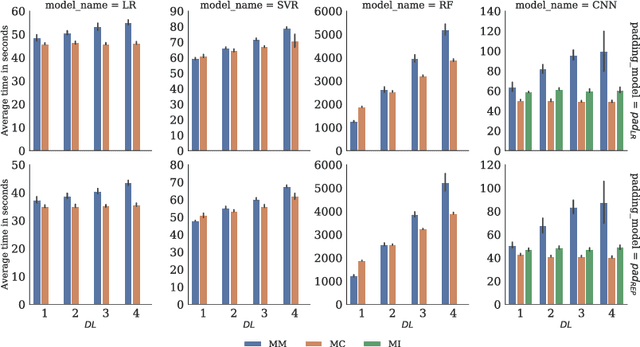
Accurate and reliable prediction of Photovoltaic (PV) power output is critical to electricity grid stability and power dispatching capabilities. However, Photovoltaic (PV) power generation is highly volatile and unstable due to different reasons. The Wavelet Transform (WT) has been utilised in time series applications, such as Photovoltaic (PV) power prediction, to model the stochastic volatility and reduce prediction errors. Yet the existing Wavelet Transform (WT) approach has a limitation in terms of time complexity. It requires reconstructing the decomposed components and modelling them separately and thus needs more time for reconstruction, model configuration and training. The aim of this study is to improve the efficiency of applying Wavelet Transform (WT) by proposing a new method that uses a single simplified model. Given a time series and its Wavelet Transform (WT) coefficients, it trains one model with the coefficients as features and the original time series as labels. This eliminates the need for component reconstruction and training numerous models. This work contributes to the day-ahead aggregated solar Photovoltaic (PV) power time series prediction problem by proposing and comprehensively evaluating a new approach of employing WT. The proposed approach is evaluated using 17 months of aggregated solar Photovoltaic (PV) power data from two real-world datasets. The evaluation includes the use of a variety of prediction models, including Linear Regression, Random Forest, Support Vector Regression, and Convolutional Neural Networks. The results indicate that using a coefficients-based strategy can give predictions that are comparable to those obtained using the components-based approach while requiring fewer models and less computational time.
Training Time Adversarial Attack Aiming the Vulnerability of Continual Learning
Nov 29, 2022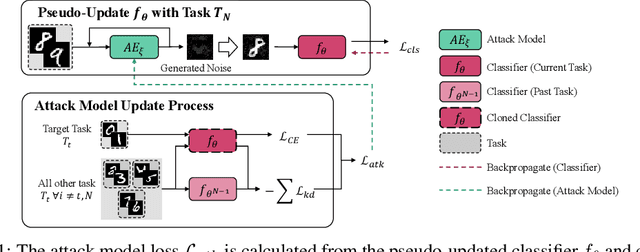
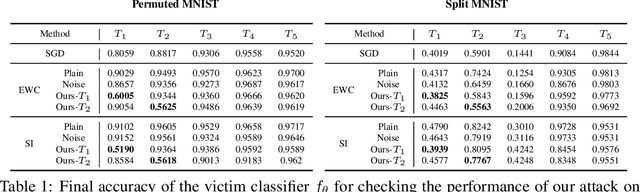

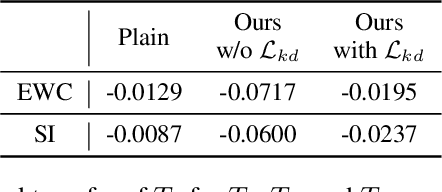
Generally, regularization-based continual learning models limit access to the previous task data to imitate the real-world setting which has memory and privacy issues. However, this introduces a problem in these models by not being able to track the performance on each task. In other words, current continual learning methods are vulnerable to attacks done on the previous task. We demonstrate the vulnerability of regularization-based continual learning methods by presenting simple task-specific training time adversarial attack that can be used in the learning process of a new task. Training data generated by the proposed attack causes performance degradation on a specific task targeted by the attacker. Experiment results justify the vulnerability proposed in this paper and demonstrate the importance of developing continual learning models that are robust to adversarial attack.
Decoupling Dynamic Monocular Videos for Dynamic View Synthesis
Apr 04, 2023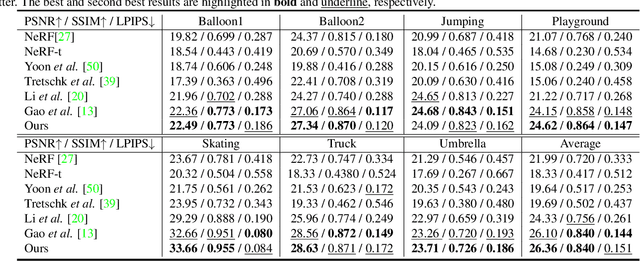

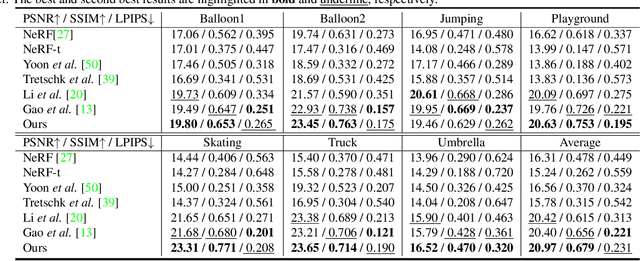
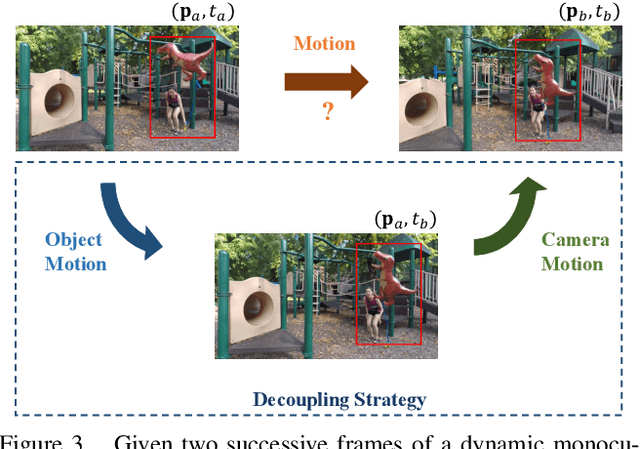
The challenge of dynamic view synthesis from dynamic monocular videos, i.e., synthesizing novel views for free viewpoints given a monocular video of a dynamic scene captured by a moving camera, mainly lies in accurately modeling the dynamic objects of a scene using limited 2D frames, each with a varying timestamp and viewpoint. Existing methods usually require pre-processed 2D optical flow and depth maps by additional methods to supervise the network, making them suffer from the inaccuracy of the pre-processed supervision and the ambiguity when lifting the 2D information to 3D. In this paper, we tackle this challenge in an unsupervised fashion. Specifically, we decouple the motion of the dynamic objects into object motion and camera motion, respectively regularized by proposed unsupervised surface consistency and patch-based multi-view constraints. The former enforces the 3D geometric surfaces of moving objects to be consistent over time, while the latter regularizes their appearances to be consistent across different viewpoints. Such a fine-grained motion formulation can alleviate the learning difficulty for the network, thus enabling it to produce not only novel views with higher quality but also more accurate scene flows and depth than existing methods requiring extra supervision. We will make the code publicly available.
Risk Sensitive Filtering with Randomly Delayed Measurements
Apr 04, 2023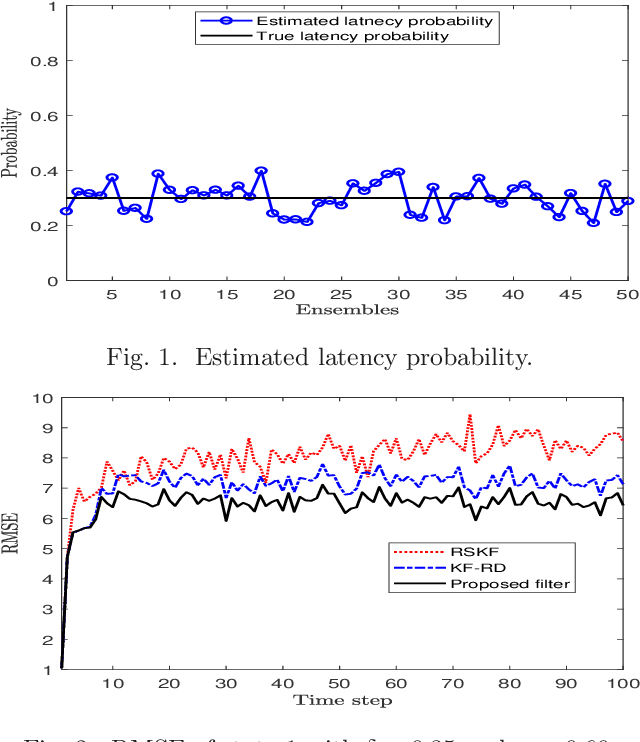
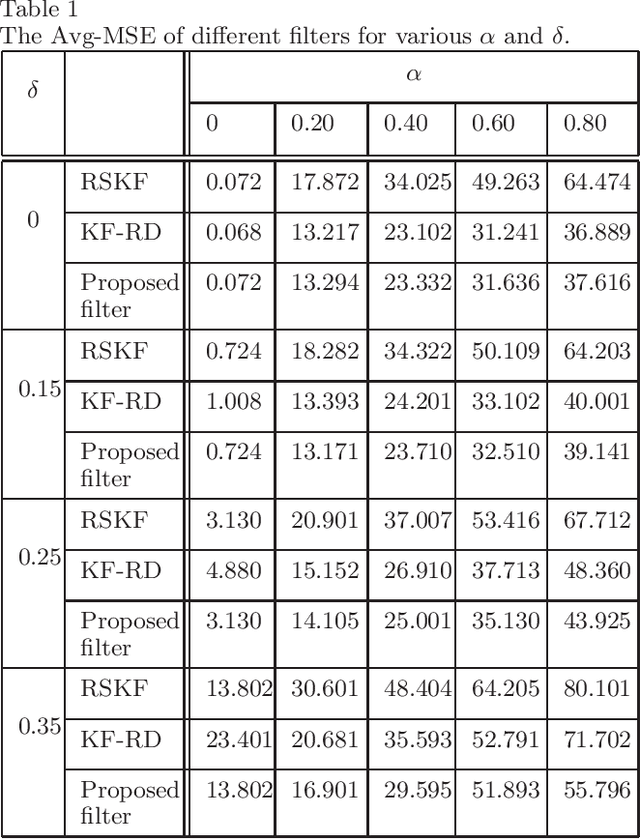

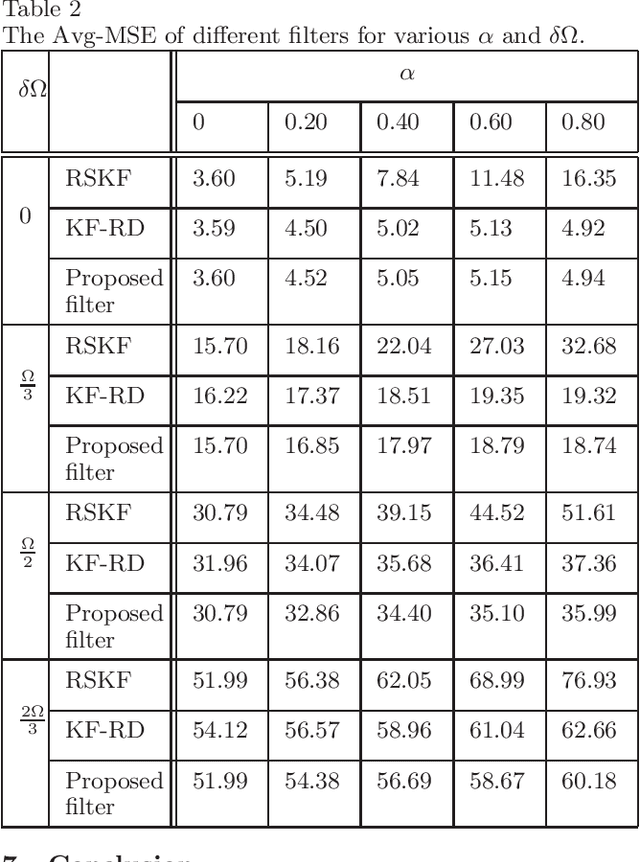
Conventional Bayesian estimation requires an accurate stochastic model of a system. However, this requirement is not always met in many practical cases where the system is not completely known or may differ from the assumed model. For such a system, we consider a scenario where the measurements are transmitted to a remote location using a common communication network and due to which, a delay is introduced while receiving the measurements. The delay that we consider here is random and one step maximum at a given time instant. For such a scenario, this paper develops a robust estimator for a linear Gaussian system by minimizing the risk sensitive error criterion that is defined as an expectation of the accumulated exponential quadratic error. The criteria for the stability of the risk sensitive Kalman filter (RSKF) are derived and the results are used to study the stability of the developed filter. Further, it is assumed that the latency probability related to delay is not known and it is estimated by maximizing the likelihood function. Simulation results suggest that the proposed filter shows acceptable performance under the nominal conditions, and it performs better than the Kalman filter for randomly delayed measurements and the RSKF in presence of both the model uncertainty and random delays.
* 15 pages and 6 Figures. The paper is published in Automatica