 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Distillation with Continual Learning for Cyclic Domain Shifts
Apr 03, 2023
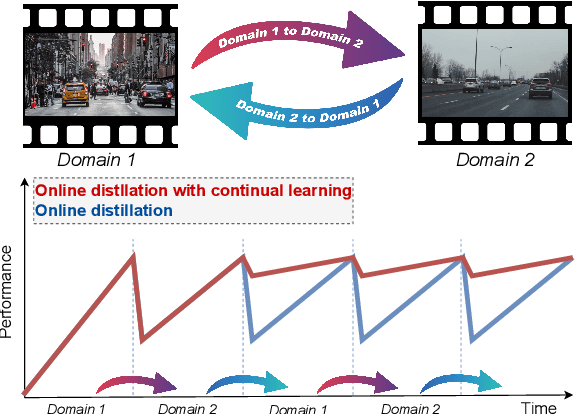
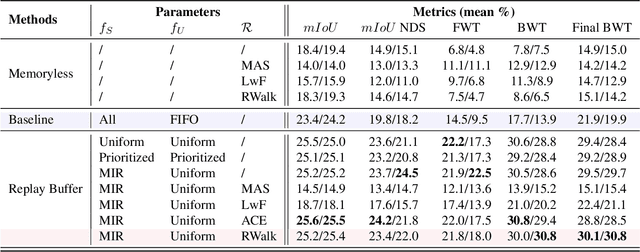
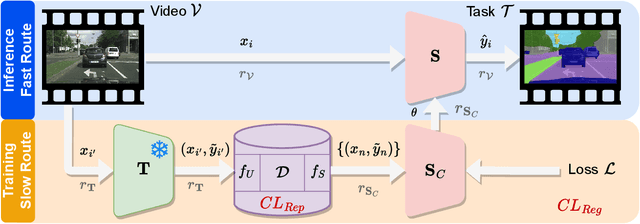
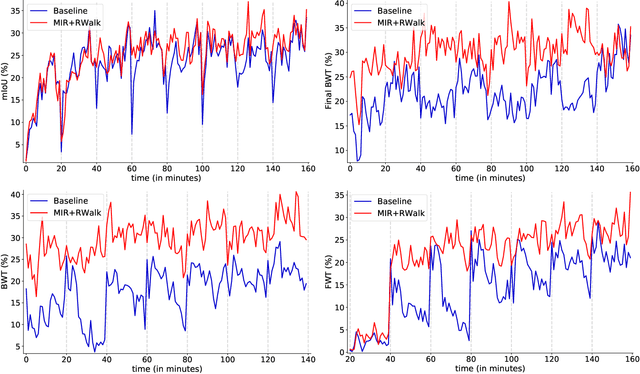
In recent years, online distillation has emerged as a powerful technique for adapting real-time deep neural networks on the fly using a slow, but accurate teacher model. However, a major challenge in online distillation is catastrophic forgetting when the domain shifts, which occurs when the student model is updated with data from the new domain and forgets previously learned knowledge. In this paper, we propose a solution to this issue by leveraging the power of continual learning methods to reduce the impact of domain shifts. Specifically, we integrate several state-of-the-art continual learning methods in the context of online distillation and demonstrate their effectiveness in reducing catastrophic forgetting. Furthermore, we provide a detailed analysis of our proposed solution in the case of cyclic domain shifts. Our experimental results demonstrate the efficacy of our approach in improving the robustness and accuracy of online distillation, with potential applications in domains such as video surveillance or autonomous driving. Overall, our work represents an important step forward in the field of online distillation and continual learning, with the potential to significantly impact real-world applications.
Semi-Automated Computer Vision based Tracking of Multiple Industrial Entities -- A Framework and Dataset Creation Approach
Apr 03, 2023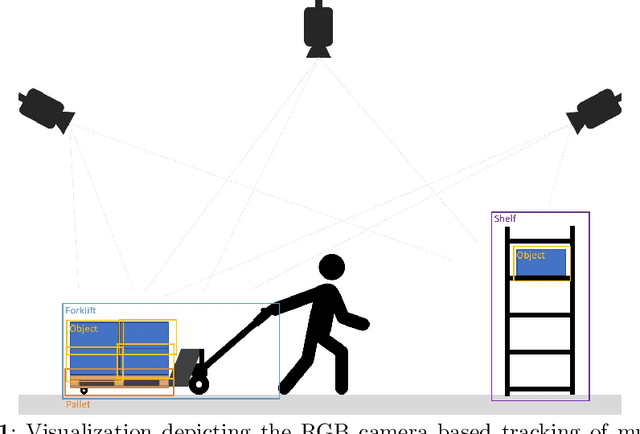
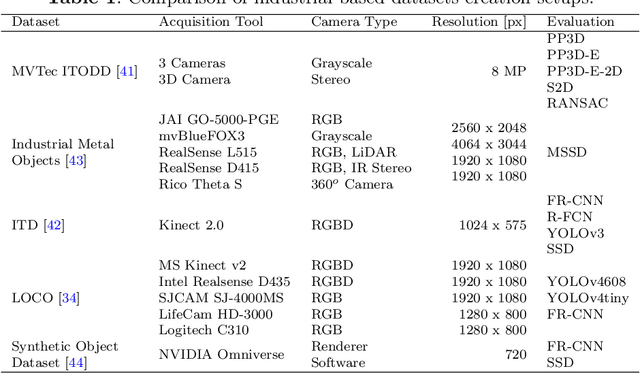
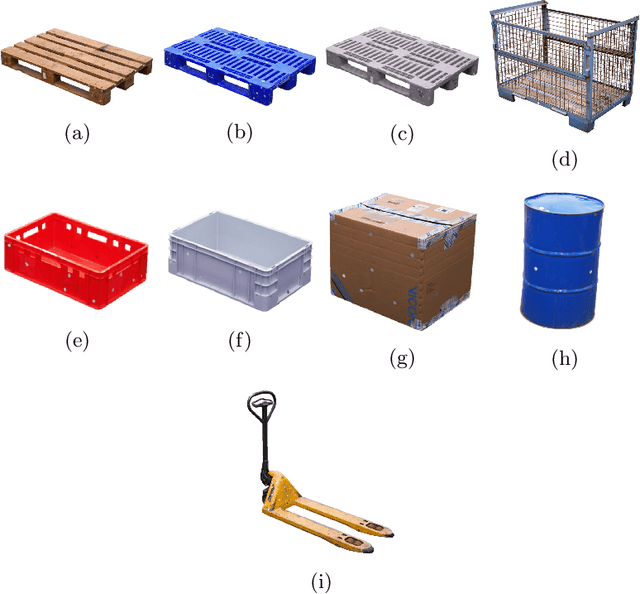

This contribution presents the TOMIE framework (Tracking Of Multiple Industrial Entities), a framework for the continuous tracking of industrial entities (e.g., pallets, crates, barrels) over a network of, in this example, six RGB cameras. This framework, makes use of multiple sensors, data pipelines and data annotation procedures, and is described in detail in this contribution. With the vision of a fully automated tracking system for industrial entities in mind, it enables researchers to efficiently capture high quality data in an industrial setting. Using this framework, an image dataset, the TOMIE dataset, is created, which at the same time is used to gauge the framework's validity. This dataset contains annotation files for 112,860 frames and 640,936 entity instances that are captured from a set of six cameras that perceive a large indoor space. This dataset out-scales comparable datasets by a factor of four and is made up of scenarios, drawn from industrial applications from the sector of warehousing. Three tracking algorithms, namely ByteTrack, Bot-Sort and SiamMOT are applied to this dataset, serving as a proof-of-concept and providing tracking results that are comparable to the state of the art.
Event-driven Fabric Blockchain - ROS 2 Interface: Towards Secure and Auditable Teleoperation of Mobile Robots
Apr 03, 2023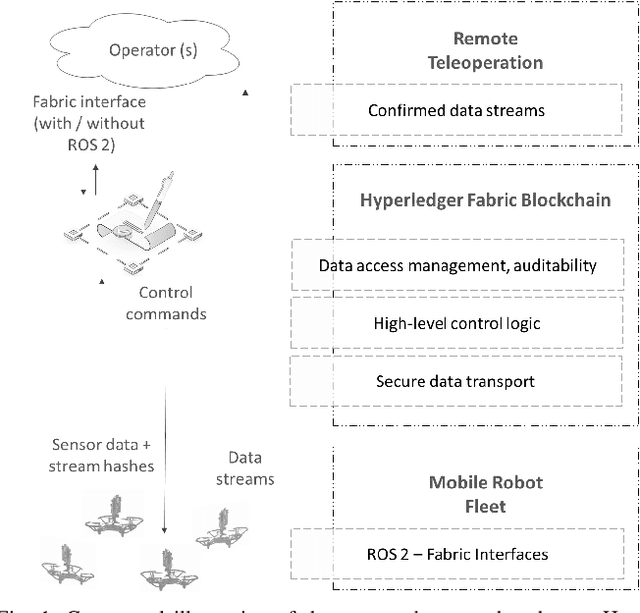
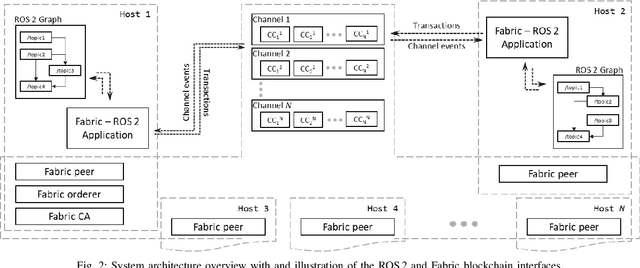
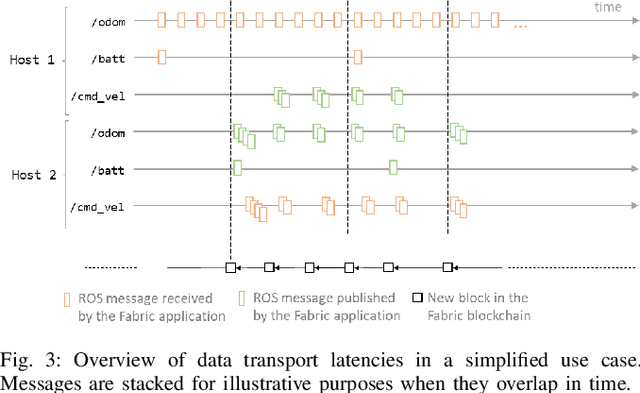
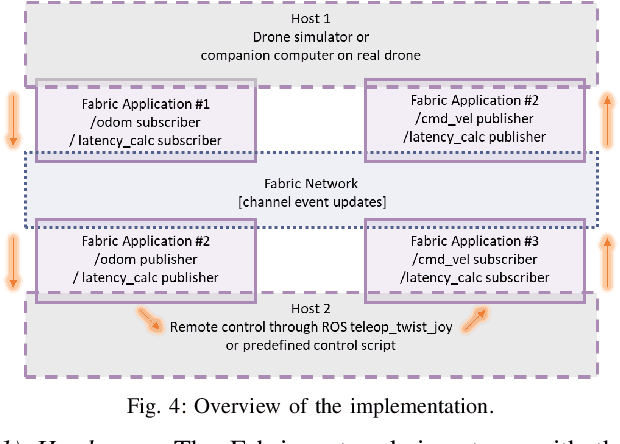
The integration of blockchain technology in robotic systems has been met by the community with a combination of hype and skepticism. The current literature shows that there is indeed potential for more secure and trustable distributed robotic systems. However, it is still unclear in what aspects of robotics beyond high-level decision making can blockchain technology be indeed usable. This paper explores the limits of a permissioned blockchain framework, Hyperledger Fabric, for teleoperation. Remote operation of mobile robots can benefit from the auditability and security properties of a blockchain. We study the potential benefits and the main limitations of such an approach. We introduce a new design and implementation for a event-driven Fabric-ROS 2 bridge that is able to maintain lower latencies at higher network loads than previous solutions. We also show this opens the door to more realistic use cases and applications. Our experiments with small aerial robots show latencies in the hundreds of milliseconds and simultaneous control of both a single and multi-robot system. We analyze the main trade-offs and limitations for real-world near real-time remote teleoperation.
Efficient Certified Training and Robustness Verification of Neural ODEs
Mar 09, 2023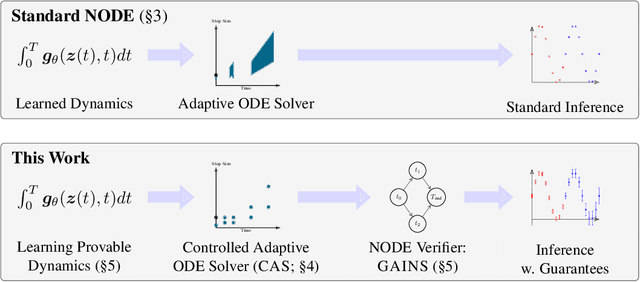
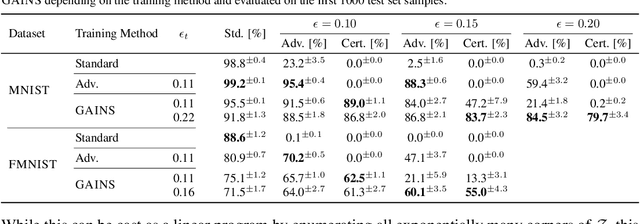
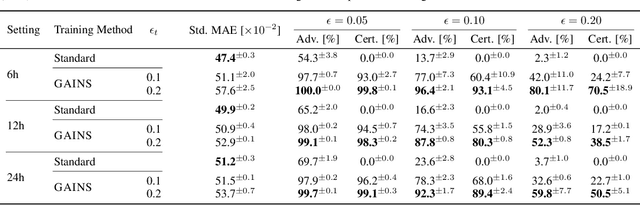

Neural Ordinary Differential Equations (NODEs) are a novel neural architecture, built around initial value problems with learned dynamics which are solved during inference. Thought to be inherently more robust against adversarial perturbations, they were recently shown to be vulnerable to strong adversarial attacks, highlighting the need for formal guarantees. However, despite significant progress in robustness verification for standard feed-forward architectures, the verification of high dimensional NODEs remains an open problem. In this work, we address this challenge and propose GAINS, an analysis framework for NODEs combining three key ideas: (i) a novel class of ODE solvers, based on variable but discrete time steps, (ii) an efficient graph representation of solver trajectories, and (iii) a novel abstraction algorithm operating on this graph representation. Together, these advances enable the efficient analysis and certified training of high-dimensional NODEs, by reducing the runtime from an intractable $O(\exp(d)+\exp(T))$ to ${O}(d+T^2 \log^2T)$ in the dimensionality $d$ and integration time $T$. In an extensive evaluation on computer vision (MNIST and FMNIST) and time-series forecasting (PHYSIO-NET) problems, we demonstrate the effectiveness of both our certified training and verification methods.
Implicit Neural Representations for Modeling of Abdominal Aortic Aneurysm Progression
Mar 02, 2023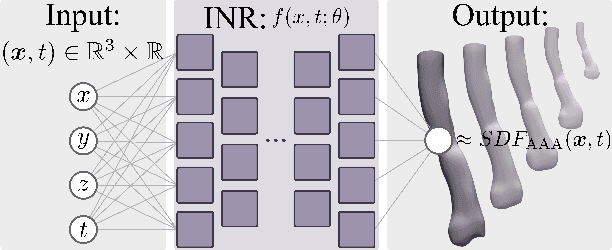
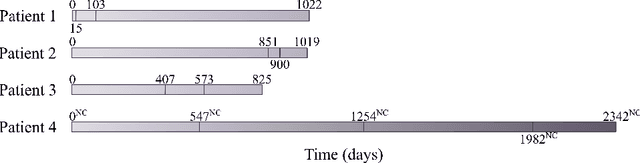
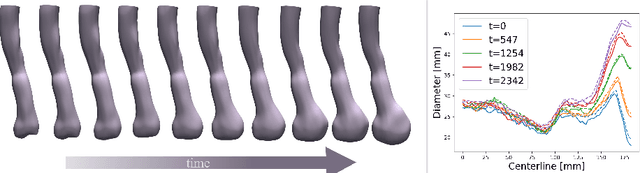
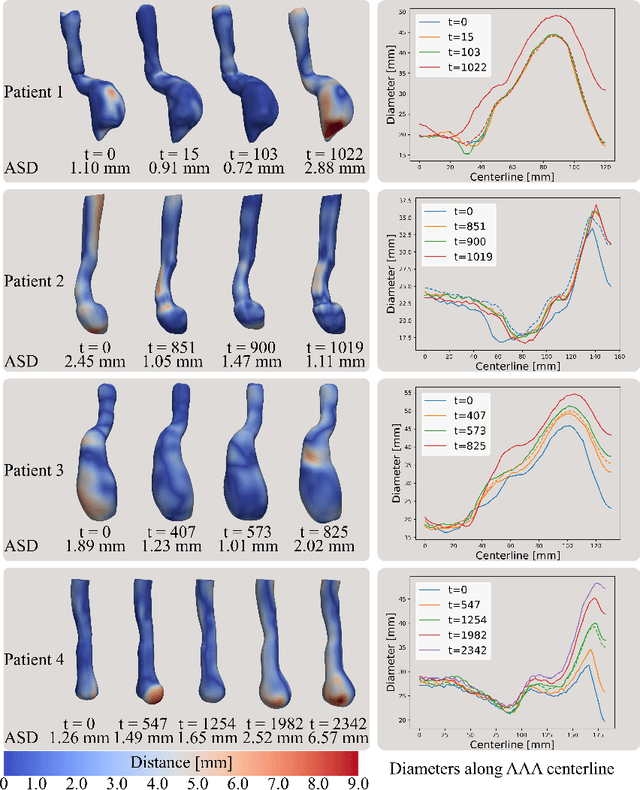
Abdominal aortic aneurysms (AAAs) are progressive dilatations of the abdominal aorta that, if left untreated, can rupture with lethal consequences. Imaging-based patient monitoring is required to select patients eligible for surgical repair. In this work, we present a model based on implicit neural representations (INRs) to model AAA progression. We represent the AAA wall over time as the zero-level set of a signed distance function (SDF), estimated by a multilayer perception that operates on space and time. We optimize this INR using automatically extracted segmentation masks in longitudinal CT data. This network is conditioned on spatiotemporal coordinates and represents the AAA surface at any desired resolution at any moment in time. Using regularization on spatial and temporal gradients of the SDF, we ensure proper interpolation of the AAA shape. We demonstrate the network's ability to produce AAA interpolations with average surface distances ranging between 0.72 and 2.52 mm from images acquired at highly irregular intervals. The results indicate that our model can accurately interpolate AAA shapes over time, with potential clinical value for a more personalised assessment of AAA progression.
ASTF: Visual Abstractions of Time-Varying Patterns in Radio Signals
Sep 30, 2022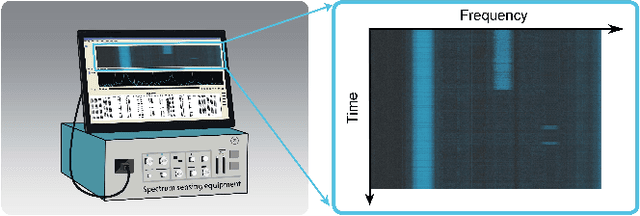
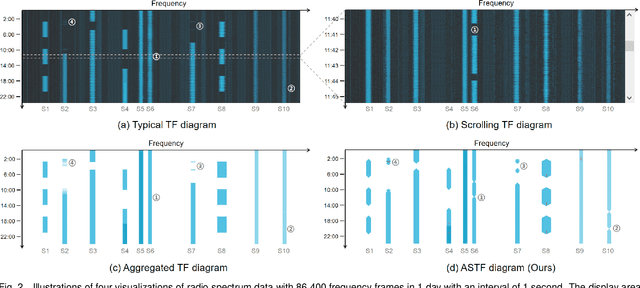
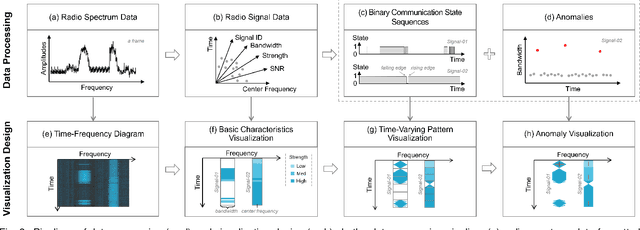
A time-frequency diagram is a commonly used visualization for observing the time-frequency distribution of radio signals and analyzing their time-varying patterns of communication states in radio monitoring and management. While it excels when performing short-term signal analyses, it becomes inadaptable for long-term signal analyses because it cannot adequately depict signal time-varying patterns in a large time span on a space-limited screen. This research thus presents an abstract signal time-frequency (ASTF) diagram to address this problem. In the diagram design, a visual abstraction method is proposed to visually encode signal communication state changes in time slices. A time segmentation algorithm is proposed to divide a large time span into time slices.Three new quantified metrics and a loss function are defined to ensure the preservation of important time-varying information in the time segmentation. An algorithm performance experiment and a user study are conducted to evaluate the effectiveness of the diagram for long-term signal analyses.
Deep Prototypical-Parts Ease Morphological Kidney Stone Identification and are Competitively Robust to Photometric Perturbations
Apr 08, 2023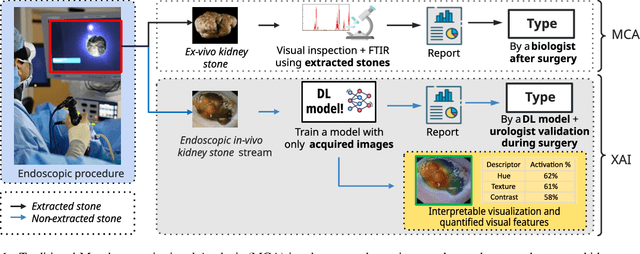
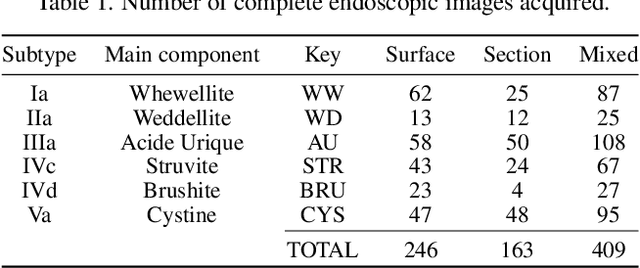

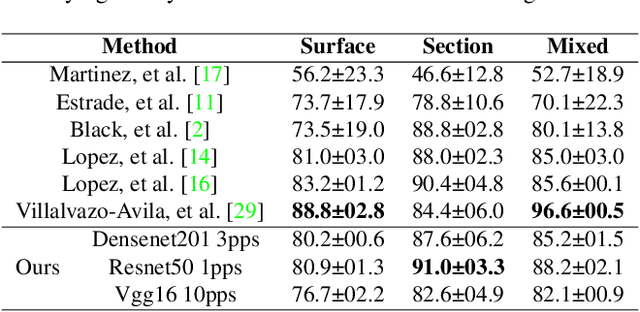
Identifying the type of kidney stones can allow urologists to determine their cause of formation, improving the prescription of appropriate treatments to diminish future relapses. Currently, the associated ex-vivo diagnosis (known as Morpho-constitutional Analysis, MCA) is time-consuming, expensive and requires a great deal of experience, as it requires a visual analysis component that is highly operator dependant. Recently, machine learning methods have been developed for in-vivo endoscopic stone recognition. Deep Learning (DL) based methods outperform non-DL methods in terms of accuracy but lack explainability. Despite this trade-off, when it comes to making high-stakes decisions, it's important to prioritize understandable Computer-Aided Diagnosis (CADx) that suggests a course of action based on reasonable evidence, rather than a model prescribing a course of action. In this proposal, we learn Prototypical Parts (PPs) per kidney stone subtype, which are used by the DL model to generate an output classification. Using PPs in the classification task enables case-based reasoning explanations for such output, thus making the model interpretable. In addition, we modify global visual characteristics to describe their relevance to the PPs and the sensitivity of our model's performance. With this, we provide explanations with additional information at the sample, class and model levels in contrast to previous works. Although our implementation's average accuracy is lower than state-of-the-art (SOTA) non-interpretable DL models by 1.5 %, our models perform 2.8% better on perturbed images with a lower standard deviation, without adversarial training. Thus, Learning PPs has the potential to create more robust DL models.
Energy-Efficient Optimization of Multi-User NOMA-Assisted Cooperative THz-SIMO MEC Systems
Apr 08, 2023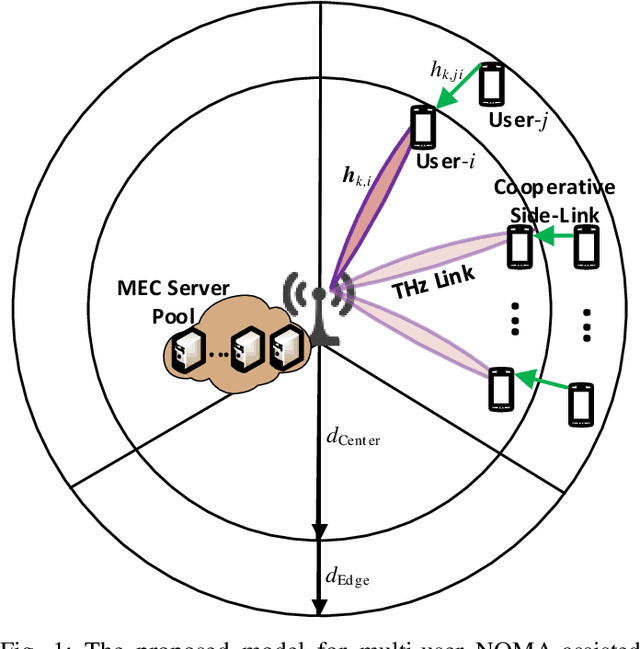
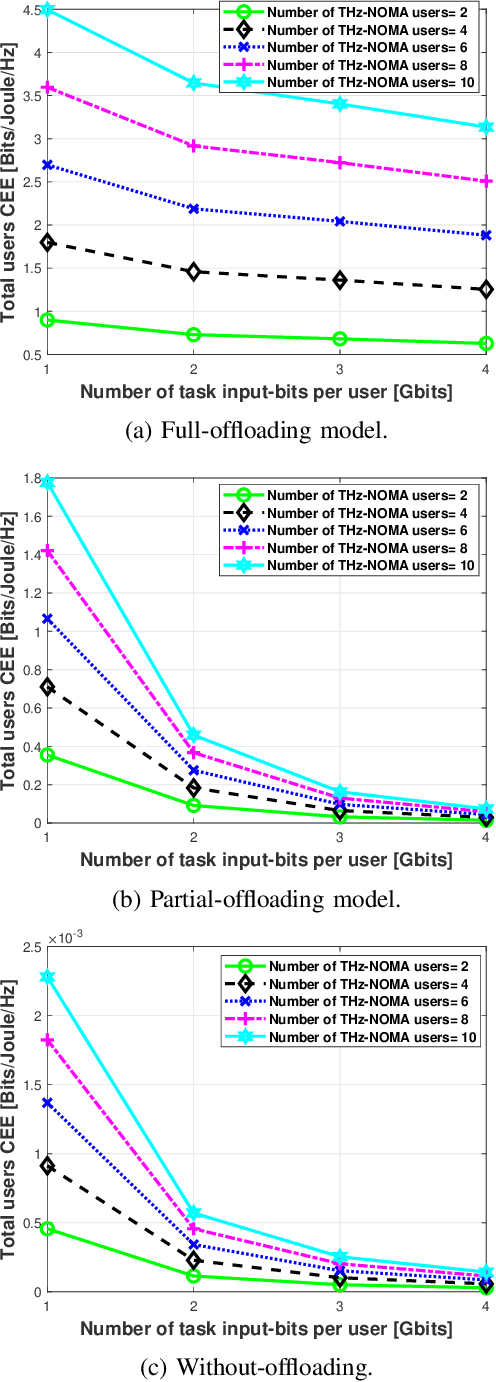
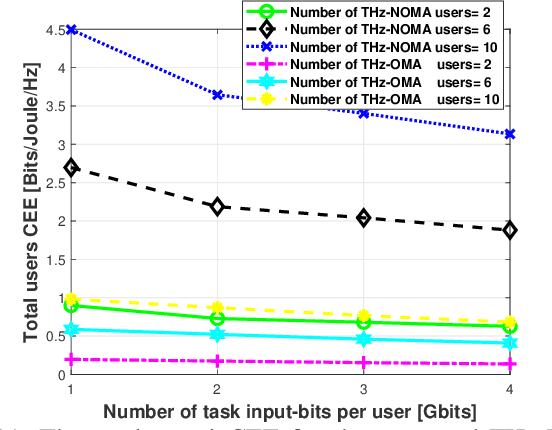
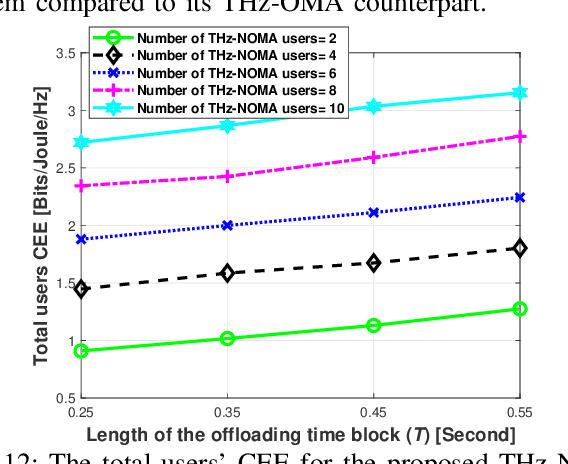
The various requirements in terms of data rates and latency in beyond 5G and 6G networks have motivated the integration of a variety of communications schemes and technologies to meet these requirements in such networks. Among these schemes are Terahertz (THz) communications, cooperative non-orthogonal multiple-access (NOMA)-enabled schemes, and mobile edge computing (MEC). THz communications offer abundant bandwidth for high-data-rate short-distance applications and NOMA-enabled schemes are promising schemes to realize the target spectral efficiencies and low latency requirements in future networks, while MEC would allow distributed processing and data offloading for the emerging applications in these networks. In this paper, an energy-efficient scheme of multi-user NOMA-assisted cooperative THz single-input multiple-output (SIMO) MEC systems is proposed to allow the uplink transmission of offloaded data from the far cell-edge users to the more computing resources in the base station (BS) through the cell-center users. To reinforce the performance of the proposed scheme, two optimization problems are formulated and solved, namely, the first problem minimizes the total users' energy consumption while the second problem maximizes the total users' computation energy efficiency (CEE) for the proposed scheme. In both problems, the NOMA user pairing, the BS receive beamforming, the transmission time allocation, and the NOMA transmission power allocation coefficients are optimized, while taking into account the full-offloading requirements of each user as well as the predefined latency constraint of the system. The obtained results reveal new insights into the performance and design of multi-user NOMA-assisted cooperative THz-SIMO MEC systems.
A Token-Wise Beam Search Algorithm for RNN-T
Feb 28, 2023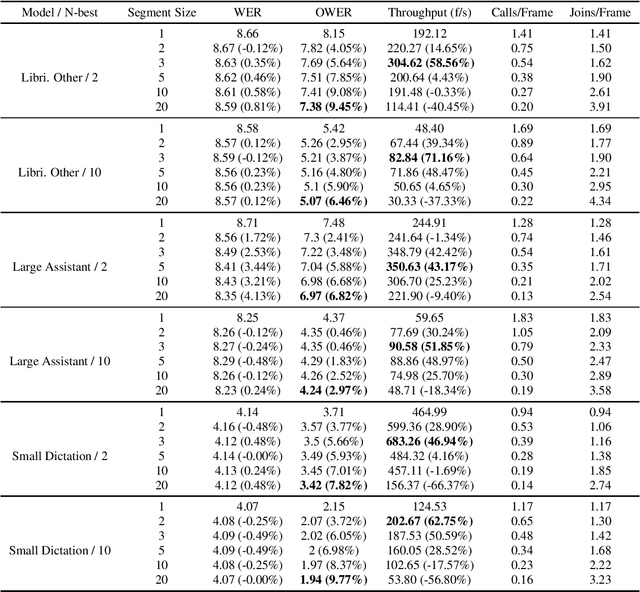
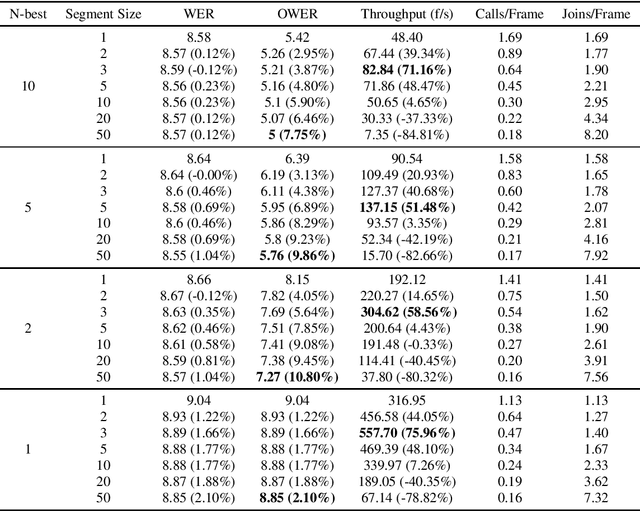
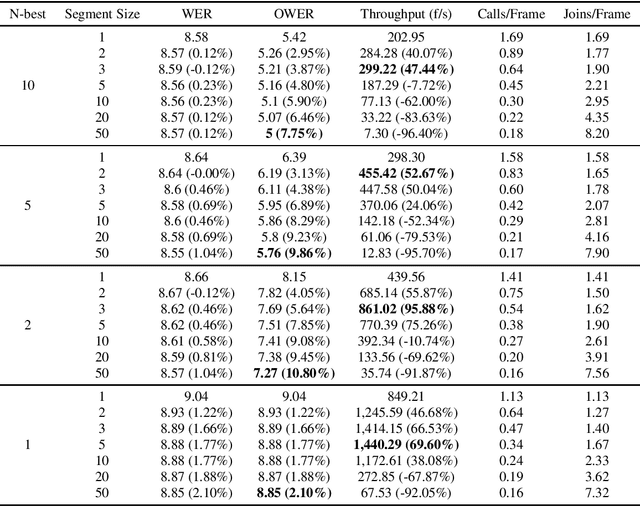
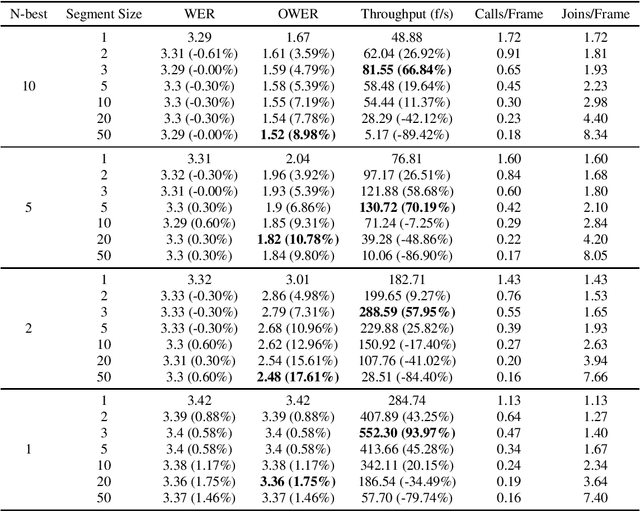
Standard Recurrent Neural Network Transducers (RNN-T) decoding algorithms for speech recognition are iterating over the time axis, such that one time step is decoded before moving on to the next time step. Those algorithms result in a large number of calls to the joint network, that were shown in previous work to be an important factor that reduces decoding speed. We present a decoding beam search algorithm that batches the joint network calls across a segment of time steps, which results in 40%-70% decoding speedups, consistently across all models and settings experimented with. In addition, aggregating emission probabilities over a segment may be seen as a better approximation to finding the most likely model output, causing our algorithm to improve oracle word error rate by up to 10% relative as the segment size increases, and to slightly improve general word error rate.
Incremental Learning of Acoustic Scenes and Sound Events
Feb 28, 2023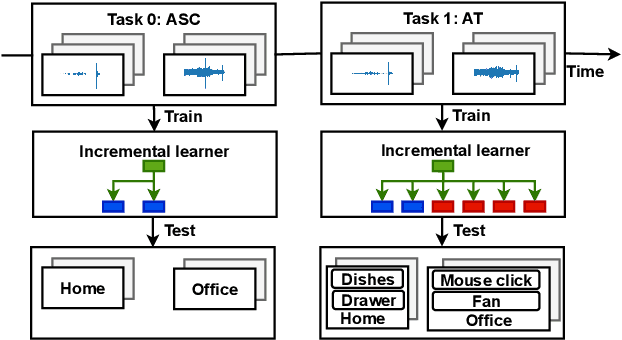
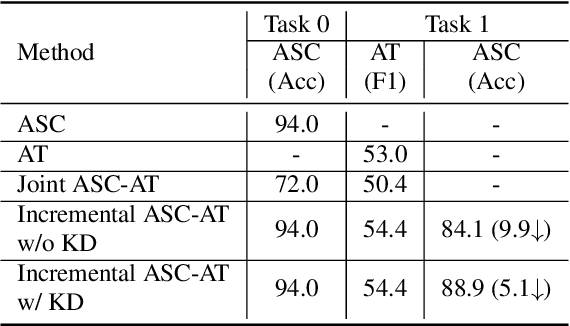
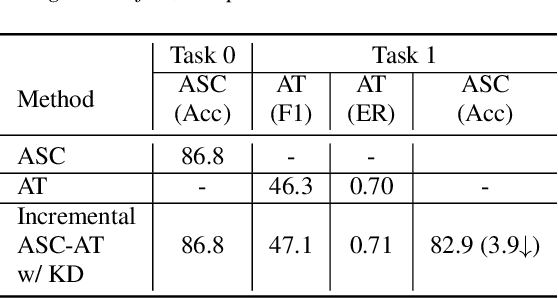
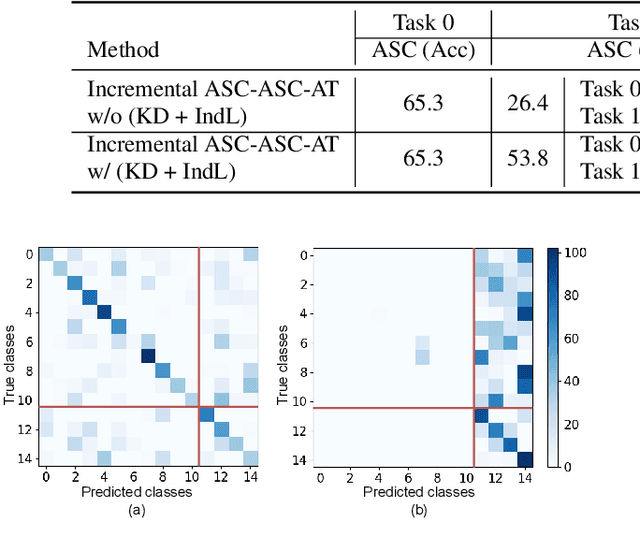
In this paper, we propose a method for incremental learning of two distinct tasks over time: acoustic scene classification (ASC) and audio tagging (AT). We use a simple convolutional neural network (CNN) model as an incremental learner to solve the tasks. Generally, incremental learning methods catastrophically forget the previous task when sequentially trained on a new task. To alleviate this problem, we use independent learning and knowledge distillation (KD) between the timesteps in learning. Experiments are performed on TUT 2016/2017 dataset, containing 4 acoustic scene classes and 25 sound event classes. The proposed incremental learner solves the AT task with an F1 score of 54.4% and the ASC task with an accuracy of 88.9% in an incremental time step, outperforming a multi-task system which solves ASC and AT at the same time. The ASC task performance degrades only by 5.1% from the initial time ASC accuracy of 94.0%.