 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
From Single-Hospital to Multi-Centre Applications: Enhancing the Generalisability of Deep Learning Models for Adverse Event Prediction in the ICU
Apr 07, 2023
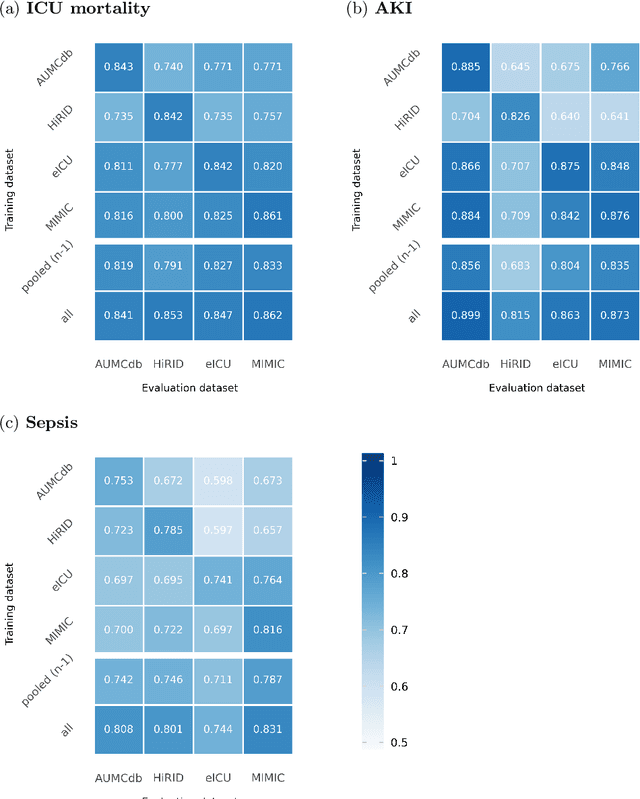
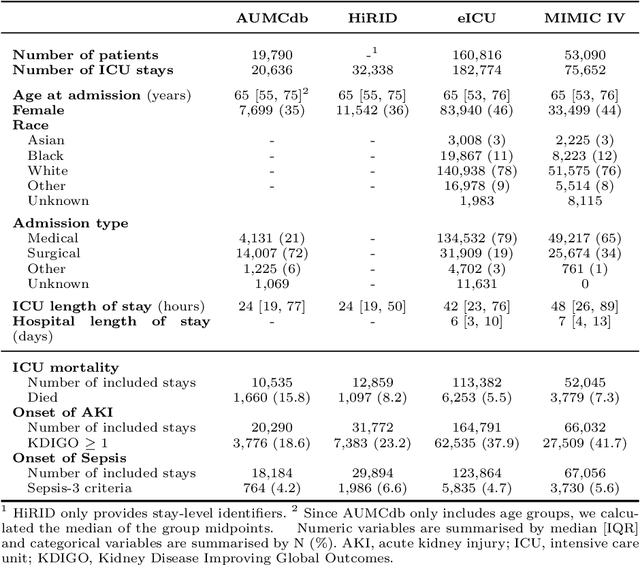
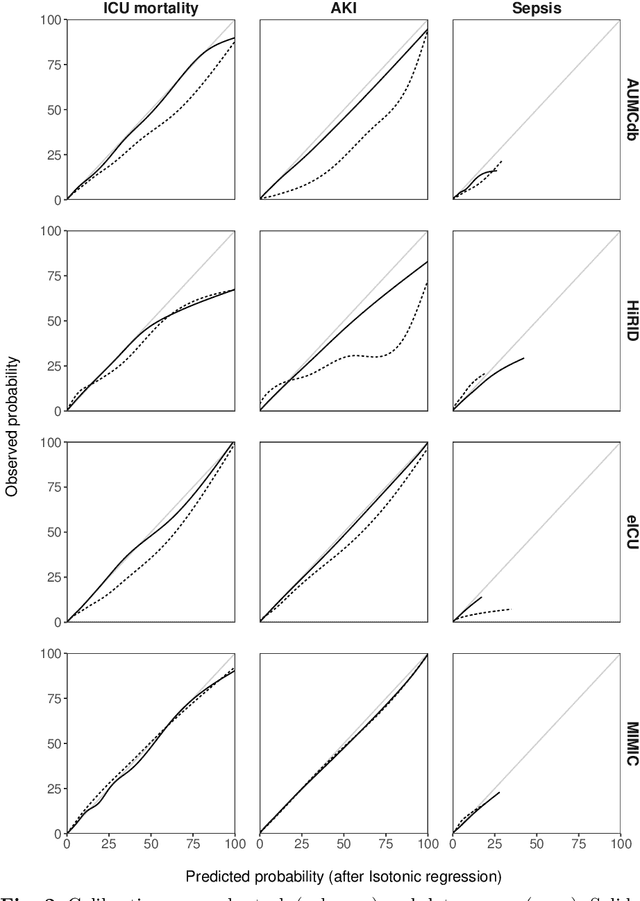
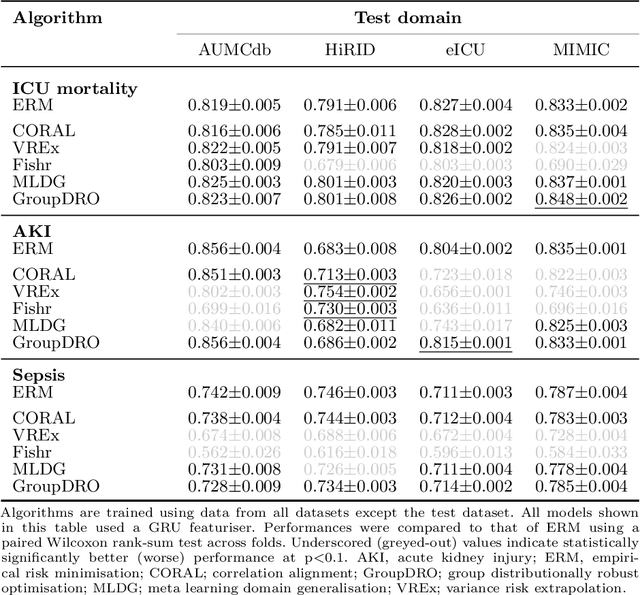
Deep learning (DL) can aid doctors in detecting worsening patient states early, affording them time to react and prevent bad outcomes. While DL-based early warning models usually work well in the hospitals they were trained for, they tend to be less reliable when applied at new hospitals. This makes it difficult to deploy them at scale. Using carefully harmonised intensive care data from four data sources across Europe and the US (totalling 334,812 stays), we systematically assessed the reliability of DL models for three common adverse events: death, acute kidney injury (AKI), and sepsis. We tested whether using more than one data source and/or explicitly optimising for generalisability during training improves model performance at new hospitals. We found that models achieved high AUROC for mortality (0.838-0.869), AKI (0.823-0.866), and sepsis (0.749-0.824) at the training hospital. As expected, performance dropped at new hospitals, sometimes by as much as -0.200. Using more than one data source for training mitigated the performance drop, with multi-source models performing roughly on par with the best single-source model. This suggests that as data from more hospitals become available for training, model robustness is likely to increase, lower-bounding robustness with the performance of the most applicable data source in the training data. Dedicated methods promoting generalisability did not noticeably improve performance in our experiments.
Can we learn better with hard samples?
Apr 07, 2023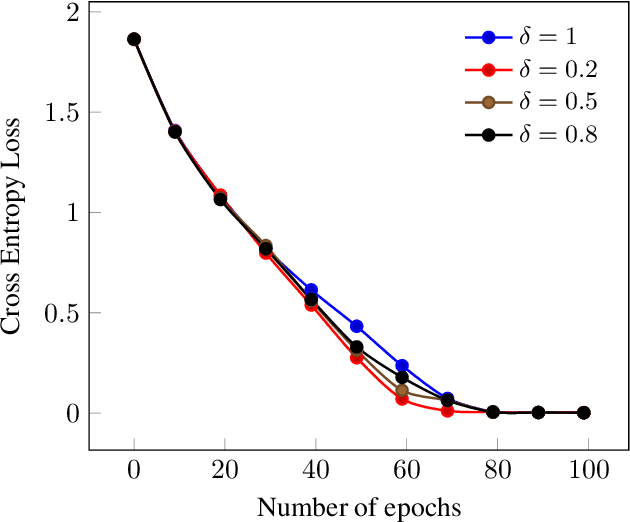
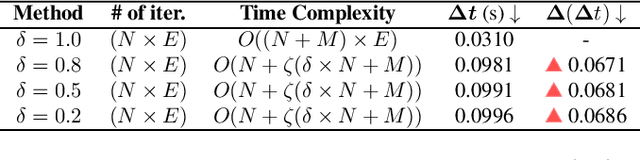
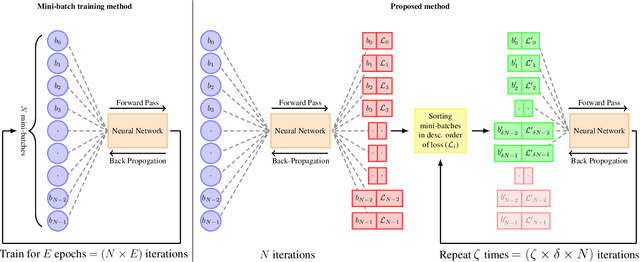

In deep learning, mini-batch training is commonly used to optimize network parameters. However, the traditional mini-batch method may not learn the under-represented samples and complex patterns in the data, leading to a longer time for generalization. To address this problem, a variant of the traditional algorithm has been proposed, which trains the network focusing on mini-batches with high loss. The study evaluates the effectiveness of the proposed training using various deep neural networks trained on three benchmark datasets (CIFAR-10, CIFAR-100, and STL-10). The deep neural networks used in the study are ResNet-18, ResNet-50, Efficient Net B4, EfficientNetV2-S, and MobilenetV3-S. The experimental results showed that the proposed method can significantly improve the test accuracy and speed up the convergence compared to the traditional mini-batch training method. Furthermore, we introduce a hyper-parameter delta ({\delta}) that decides how many mini-batches are considered for training. Experiments on various values of {\delta} found that the performance of the proposed method for smaller {\delta} values generally results in similar test accuracy and faster generalization. We show that the proposed method generalizes in 26.47% less number of epochs than the traditional mini-batch method in EfficientNet-B4 on STL-10. The proposed method also improves the test top-1 accuracy by 7.26% in ResNet-18 on CIFAR-100.
Optimizing Real-Time Performances for Timed-Loop Racing under F1TENTH
Dec 08, 2022
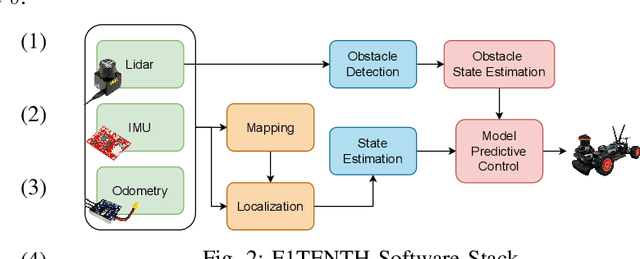
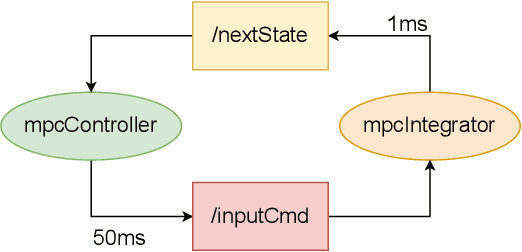

Motion planning and control in autonomous car racing are one of the most challenging and safety-critical tasks due to high speed and dynamism. The lower-level control nodes are expected to be highly optimized due to resource constraints of onboard embedded processing units, although there are strict latency requirements. Some of these guarantees can be provided at the application level, such as using ROS2's Real-Time executors. However, the performance can be far from satisfactory as many modern control algorithms (such as Model Predictive Control) rely on solving complicated online optimization problems at each iteration. In this paper, we present a simple yet effective multi-threading technique to optimize the throughput of online-control algorithms for resource-constrained autonomous racing platforms. We achieve this by maintaining a systematic pool of worker threads solving the optimization problem in parallel which can improve the system performance by reducing latency between control input commands. We further demonstrate the effectiveness of our method using the Model Predictive Contouring Control (MPCC) algorithm running on Nvidia's Xavier AGX platform.
Gradient-Descent Based Optimization of Constant Envelope OFDM Waveforms
Mar 16, 2023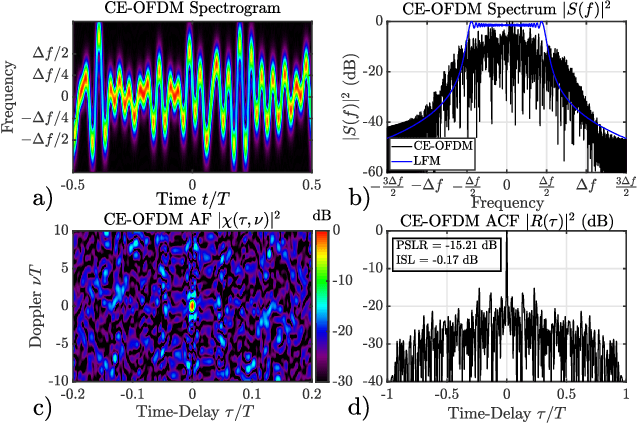
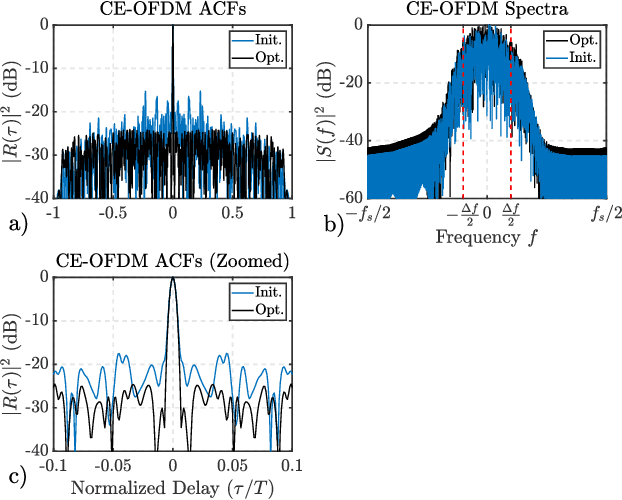
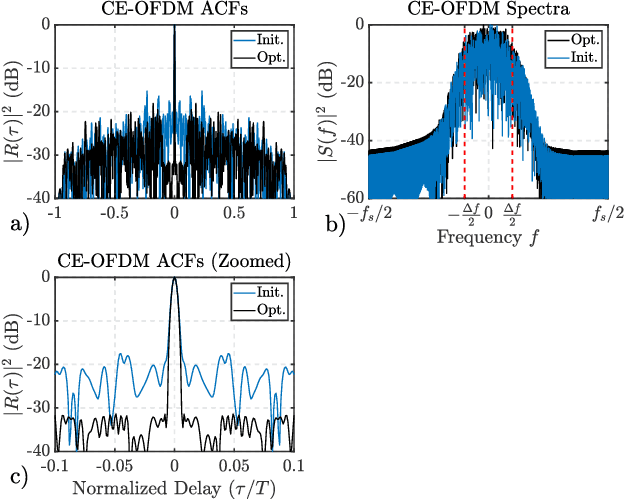
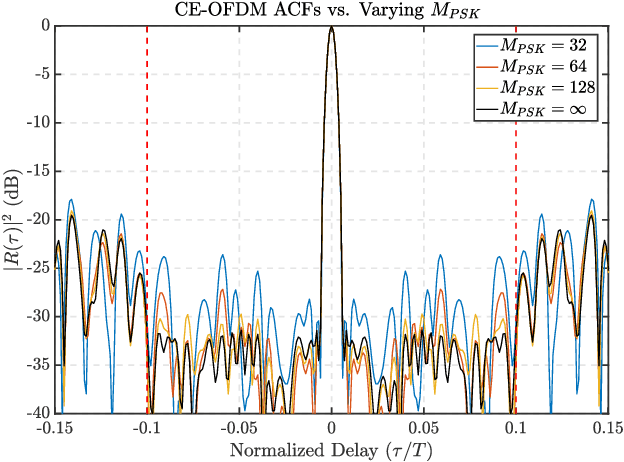
This paper describes a gradient-descent based optimization algorithm for synthesizing Constant Envelope Orthogonal Frequency Division Multiplexing (CE-OFDM) waveforms with low Auto-Correlation Function (ACF) sidelobes in a specified region of time-delays. The algorithm optimizes the Generalized Integrated Sidelobe Level (GISL) which controls the mainlobe and sidelobe structure of the waveform's ACF. The operations of this Gradient-Descent GISL (GD-GISL) algorithm are FFT-based making it computationally efficient. This computational efficiency facilitates the design of large dimensional waveform design problems. Simulations demonstrate the GD-GISL algorithm on CE-OFDM waveforms employing Phase-Shift Keying (PSK) symbols that take on a continuum of values (i.e, $M_{\text{PSK}} = \infty$). Results from these simulations show that the GD-GISL algorithm can indeed reduce ACF sidelobes in a desired region of time-delays. However, truncating the symbols to finite M-ary alphabets introduces perturbations to the waveform's instantaneous phase which increases the waveform's ACF sidelobe levels.
Anomaly Search Over Many Sequences With Switching Costs
Mar 16, 2023
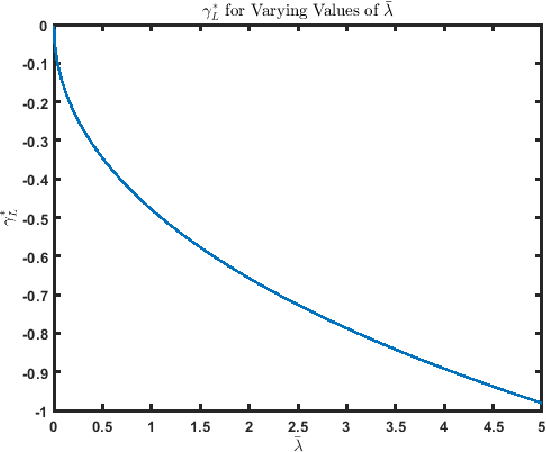
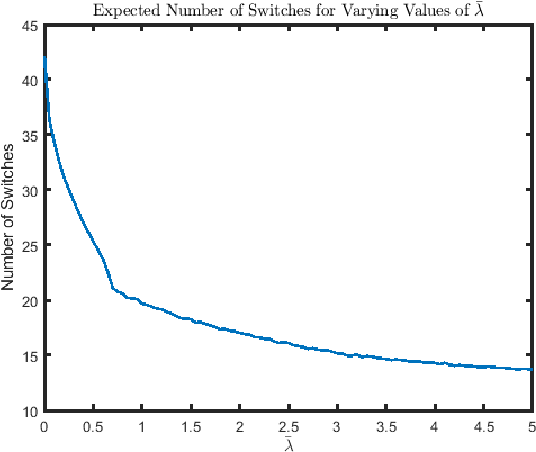
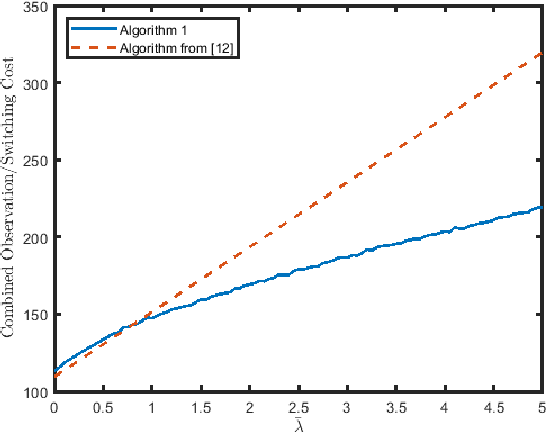
This paper considers the quickest search problem to identify anomalies among large numbers of data streams. These streams can model, for example, disjoint regions monitored by a mobile robot. A particular challenge is a version of the problem in which the experimenter must suffer a cost each time the data stream being sampled changes, such as the time the robot must spend moving between regions. In this paper, we propose an algorithm which accounts for switching costs by varying a confidence threshold that governs when the algorithm switches to a new data stream. Our main contributions are easily computable approximations for both the optimal value of this threshold and the optimal value of the parameter that determines when a stream must be re-sampled. Further, we empirically show (i) a uniform improvement for switching costs of interest and (ii) roughly equivalent performance for small switching costs when comparing to the closest available algorithm.
Spectral analysis of signals by time-domain statistical characterization and neural network processing: Application to correction of spectral amplitude alterations in pulse-like waveforms
Dec 23, 2022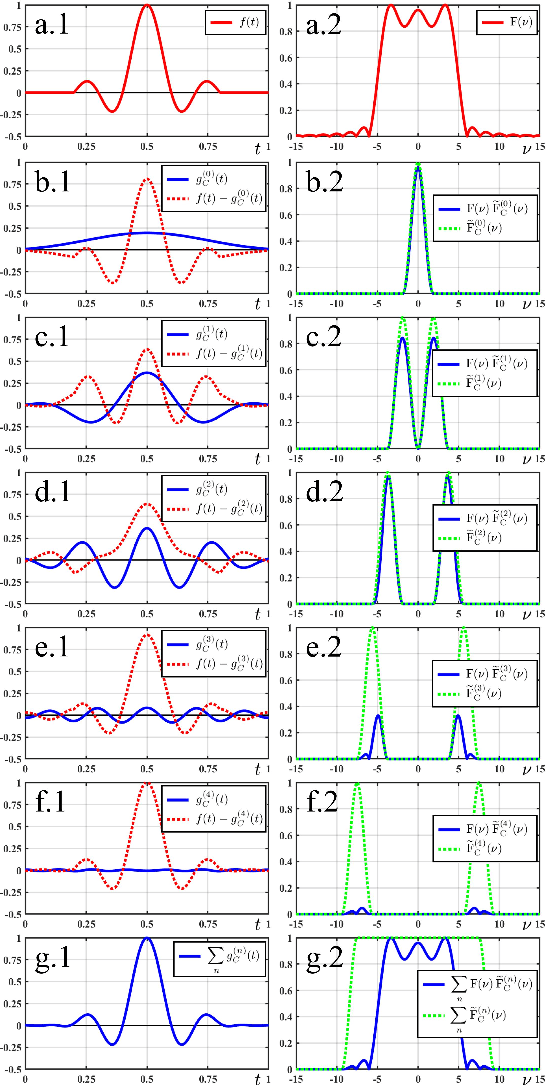
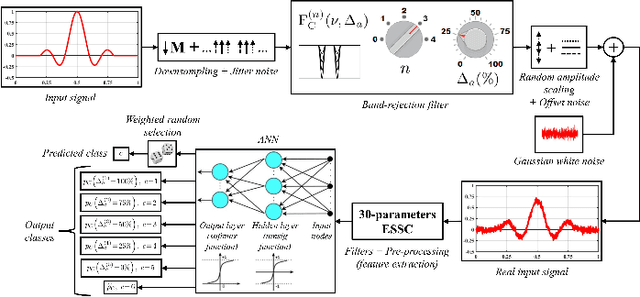
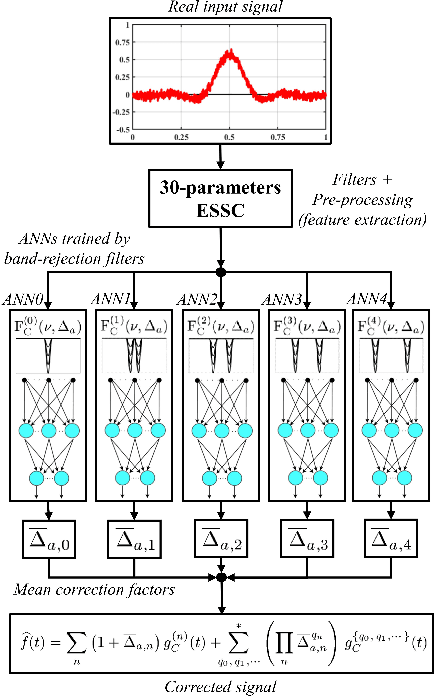
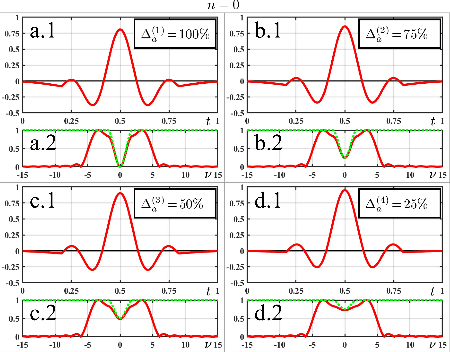
We present a time-domain method to detect and correct spectral alterations of signals by employing statistical characterization of waveforms and a pattern-recognition procedure using simple Artificial Neural Networks. The proposed strategy implements very-fast routines with a computational cost proportional to the number of signal samples, being convenient for applications in embedded environments with limited computational capabilities or fast real-time control tasks. We use the proposed algorithms to correct spectral amplitude attenuations in a pulse-like waveform with a sinc profile as an application example.
SkipConvGAN: Monaural Speech Dereverberation using Generative Adversarial Networks via Complex Time-Frequency Masking
Nov 22, 2022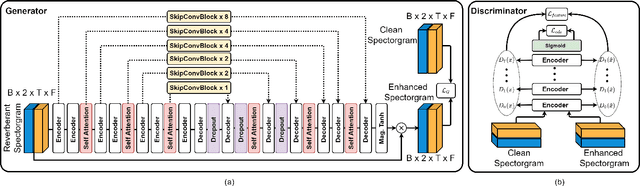
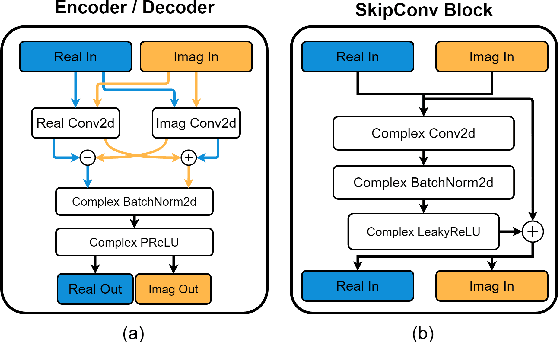
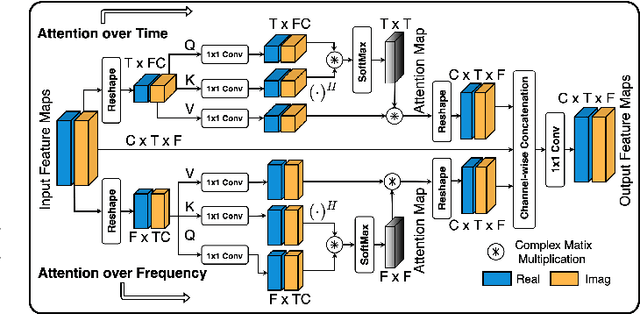
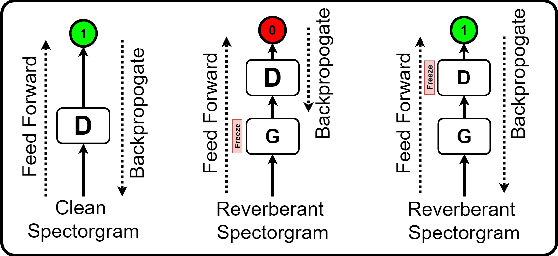
With the advancements in deep learning approaches, the performance of speech enhancing systems in the presence of background noise have shown significant improvements. However, improving the system's robustness against reverberation is still a work in progress, as reverberation tends to cause loss of formant structure due to smearing effects in time and frequency. A wide range of deep learning-based systems either enhance the magnitude response and reuse the distorted phase or enhance complex spectrogram using a complex time-frequency mask. Though these approaches have demonstrated satisfactory performance, they do not directly address the lost formant structure caused by reverberation. We believe that retrieving the formant structure can help improve the efficiency of existing systems. In this study, we propose SkipConvGAN - an extension of our prior work SkipConvNet. The proposed system's generator network tries to estimate an efficient complex time-frequency mask, while the discriminator network aids in driving the generator to restore the lost formant structure. We evaluate the performance of our proposed system on simulated and real recordings of reverberant speech from the single-channel task of the REVERB challenge corpus. The proposed system shows a consistent improvement across multiple room configurations over other deep learning-based generative adversarial frameworks.
Trimming Phonetic Alignments Improves the Inference of Sound Correspondence Patterns from Multilingual Wordlists
Mar 31, 2023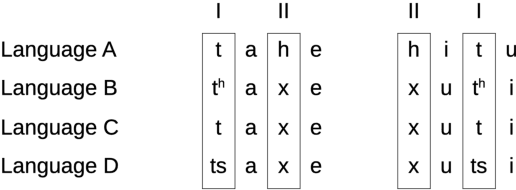
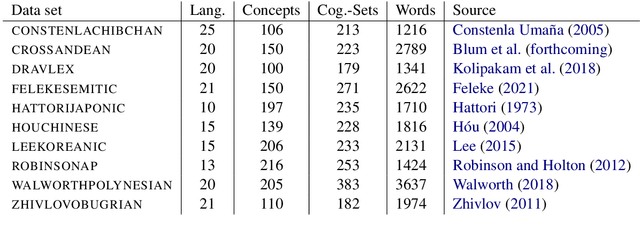

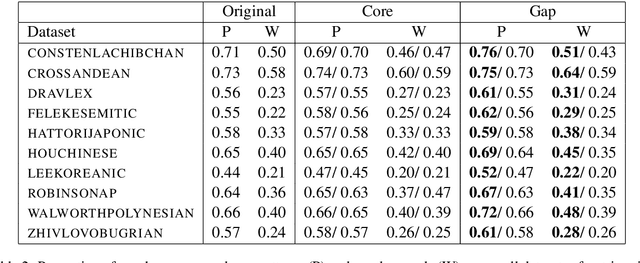
Sound correspondence patterns form the basis of cognate detection and phonological reconstruction in historical language comparison. Methods for the automatic inference of correspondence patterns from phonetically aligned cognate sets have been proposed, but their application to multilingual wordlists requires extremely well annotated datasets. Since annotation is tedious and time consuming, it would be desirable to find ways to improve aligned cognate data automatically. Taking inspiration from trimming techniques in evolutionary biology, which improve alignments by excluding problematic sites, we propose a workflow that trims phonetic alignments in comparative linguistics prior to the inference of correspondence patterns. Testing these techniques on a large standardized collection of ten datasets with expert annotations from different language families, we find that the best trimming technique substantially improves the overall consistency of the alignments. The results show a clear increase in the proportion of frequent correspondence patterns and words exhibiting regular cognate relations.
LiFe-net: Data-driven Modelling of Time-dependent Temperatures and Charging Statistics Of Tesla's LiFePo4 EV Battery
Dec 16, 2022

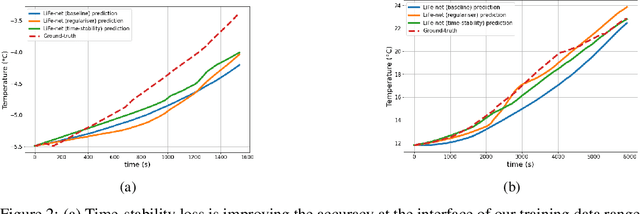
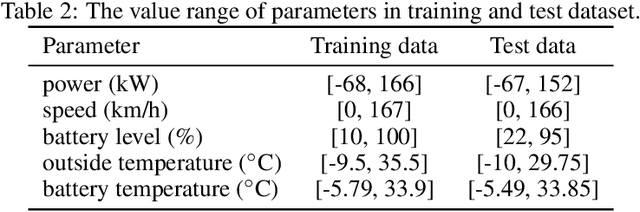
Modelling the temperature of Electric Vehicle (EV) batteries is a fundamental task of EV manufacturing. Extreme temperatures in the battery packs can affect their longevity and power output. Although theoretical models exist for describing heat transfer in battery packs, they are computationally expensive to simulate. Furthermore, it is difficult to acquire data measurements from within the battery cell. In this work, we propose a data-driven surrogate model (LiFe-net) that uses readily accessible driving diagnostics for battery temperature estimation to overcome these limitations. This model incorporates Neural Operators with a traditional numerical integration scheme to estimate the temperature evolution. Moreover, we propose two further variations of the baseline model: LiFe-net trained with a regulariser and LiFe-net trained with time stability loss. We compared these models in terms of generalization error on test data. The results showed that LiFe-net trained with time stability loss outperforms the other two models and can estimate the temperature evolution on unseen data with a relative error of 2.77 % on average.
Efficient Uncertainty Estimation with Gaussian Process for Reliable Dialog Response Retrieval
Mar 15, 2023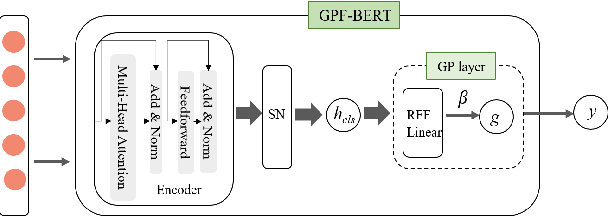
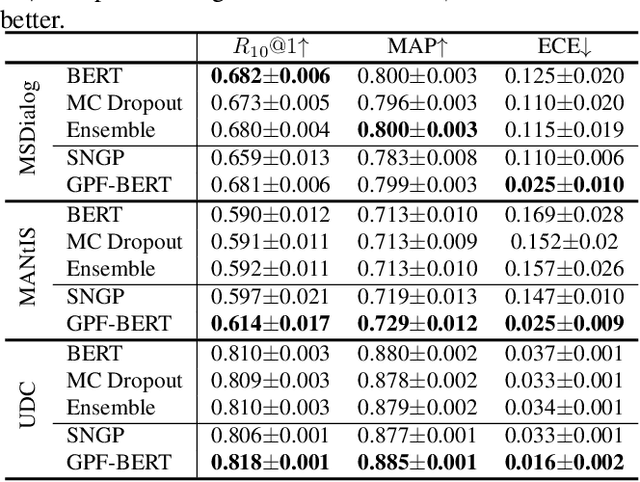
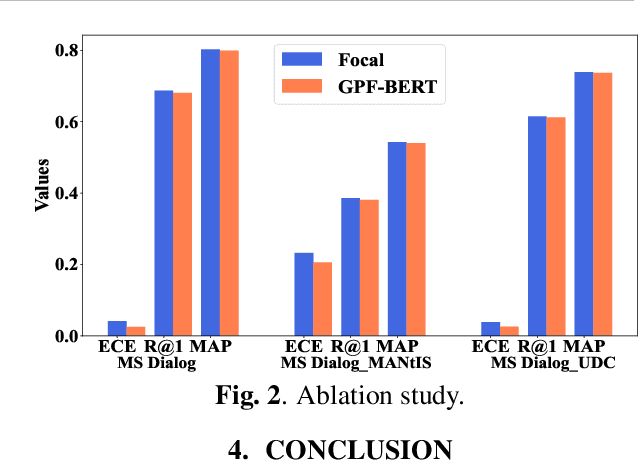
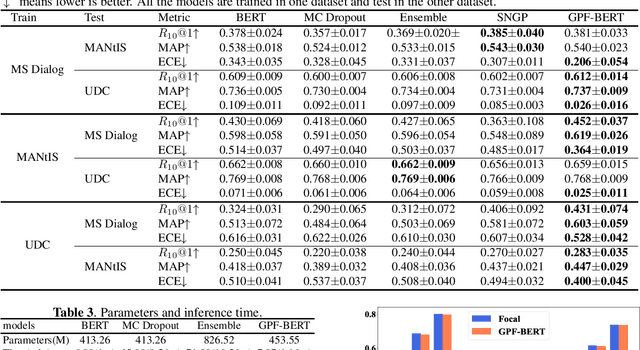
Deep neural networks have achieved remarkable performance in retrieval-based dialogue systems, but they are shown to be ill calibrated. Though basic calibration methods like Monte Carlo Dropout and Ensemble can calibrate well, these methods are time-consuming in the training or inference stages. To tackle these challenges, we propose an efficient uncertainty calibration framework GPF-BERT for BERT-based conversational search, which employs a Gaussian Process layer and the focal loss on top of the BERT architecture to achieve a high-quality neural ranker. Extensive experiments are conducted to verify the effectiveness of our method. In comparison with basic calibration methods, GPF-BERT achieves the lowest empirical calibration error (ECE) in three in-domain datasets and the distributional shift tasks, while yielding the highest $R_{10}@1$ and MAP performance on most cases. In terms of time consumption, our GPF-BERT has an 8$\times$ speedup.