 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Statistical and computational rates in high rank tensor estimation
Apr 08, 2023

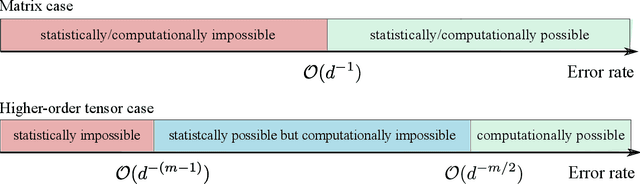
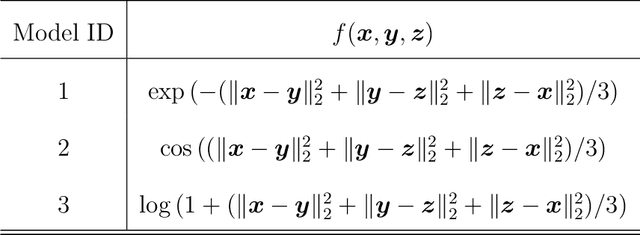
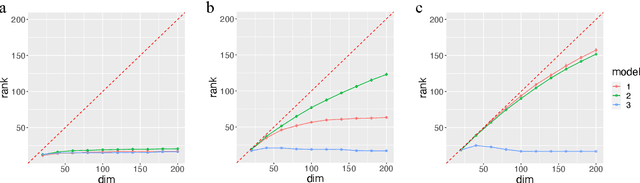
Higher-order tensor datasets arise commonly in recommendation systems, neuroimaging, and social networks. Here we develop probable methods for estimating a possibly high rank signal tensor from noisy observations. We consider a generative latent variable tensor model that incorporates both high rank and low rank models, including but not limited to, simple hypergraphon models, single index models, low-rank CP models, and low-rank Tucker models. Comprehensive results are developed on both the statistical and computational limits for the signal tensor estimation. We find that high-dimensional latent variable tensors are of log-rank; the fact explains the pervasiveness of low-rank tensors in applications. Furthermore, we propose a polynomial-time spectral algorithm that achieves the computationally optimal rate. We show that the statistical-computational gap emerges only for latent variable tensors of order 3 or higher. Numerical experiments and two real data applications are presented to demonstrate the practical merits of our methods.
Random Majority Opinion Diffusion: Stabilization Time, Absorbing States, and Influential Nodes
Feb 14, 2023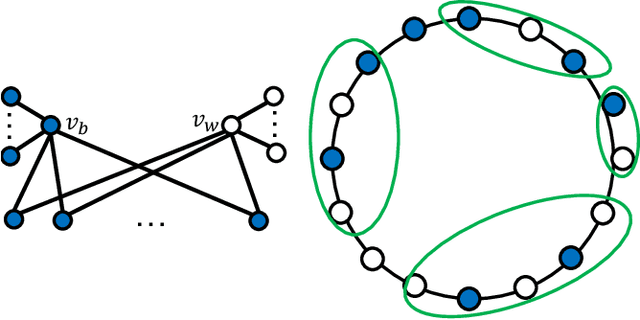


Consider a graph G with n nodes and m edges, which represents a social network, and assume that initially each node is blue or white. In each round, all nodes simultaneously update their color to the most frequent color in their neighborhood. This is called the Majority Model (MM) if a node keeps its color in case of a tie and the Random Majority Model (RMM) if it chooses blue with probability 1/2 and white otherwise. We prove that there are graphs for which RMM needs exponentially many rounds to reach a stable configuration in expectation, and such a configuration can have exponentially many states (i.e., colorings). This is in contrast to MM, which is known to always reach a stable configuration with one or two states in $O(m)$ rounds. For the special case of a cycle graph C_n, we prove the stronger and tight bounds of $\lceil n/2\rceil-1$ and $O(n^2)$ in MM and RMM, respectively. Furthermore, we show that the number of stable colorings in MM on C_n is equal to $\Theta(\Phi^n)$, where $\Phi = (1+\sqrt{5})/2$ is the golden ratio, while it is equal to 2 for RMM. We also study the minimum size of a winning set, which is a set of nodes whose agreement on a color in the initial coloring enforces the process to end in a coloring where all nodes share that color. We present tight bounds on the minimum size of a winning set for both MM and RMM. Furthermore, we analyze our models for a random initial coloring, where each node is colored blue independently with some probability $p$ and white otherwise. Using some martingale analysis and counting arguments, we prove that the expected final number of blue nodes is respectively equal to $(2p^2-p^3)n/(1-p+p^2)$ and pn in MM and RMM on a cycle graph C_n. Finally, we conduct some experiments which complement our theoretical findings and also lead to the proposal of some intriguing open problems and conjectures to be tackled in future work.
Computationally Budgeted Continual Learning: What Does Matter?
Mar 20, 2023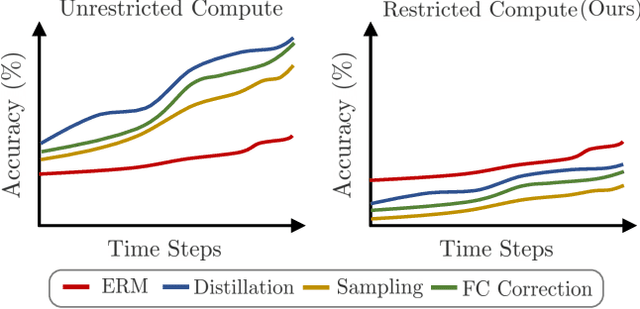
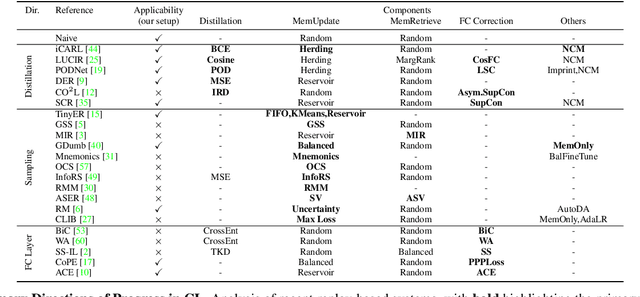
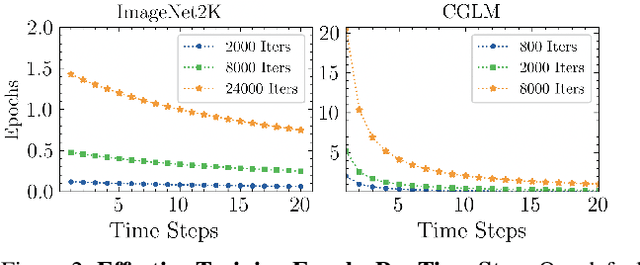
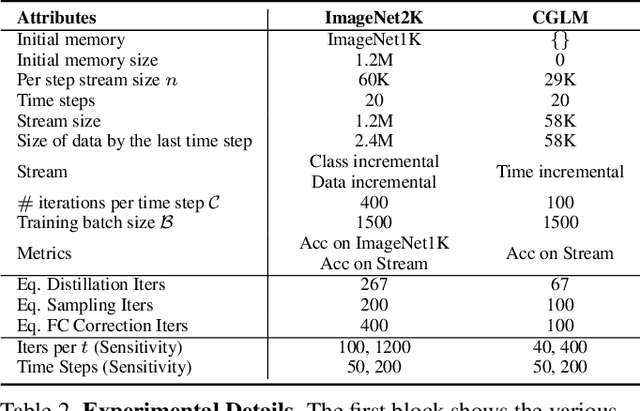
Continual Learning (CL) aims to sequentially train models on streams of incoming data that vary in distribution by preserving previous knowledge while adapting to new data. Current CL literature focuses on restricted access to previously seen data, while imposing no constraints on the computational budget for training. This is unreasonable for applications in-the-wild, where systems are primarily constrained by computational and time budgets, not storage. We revisit this problem with a large-scale benchmark and analyze the performance of traditional CL approaches in a compute-constrained setting, where effective memory samples used in training can be implicitly restricted as a consequence of limited computation. We conduct experiments evaluating various CL sampling strategies, distillation losses, and partial fine-tuning on two large-scale datasets, namely ImageNet2K and Continual Google Landmarks V2 in data incremental, class incremental, and time incremental settings. Through extensive experiments amounting to a total of over 1500 GPU-hours, we find that, under compute-constrained setting, traditional CL approaches, with no exception, fail to outperform a simple minimal baseline that samples uniformly from memory. Our conclusions are consistent in a different number of stream time steps, e.g., 20 to 200, and under several computational budgets. This suggests that most existing CL methods are particularly too computationally expensive for realistic budgeted deployment. Code for this project is available at: https://github.com/drimpossible/BudgetCL.
GNN-Assisted Phase Space Integration with Application to Atomistics
Mar 20, 2023
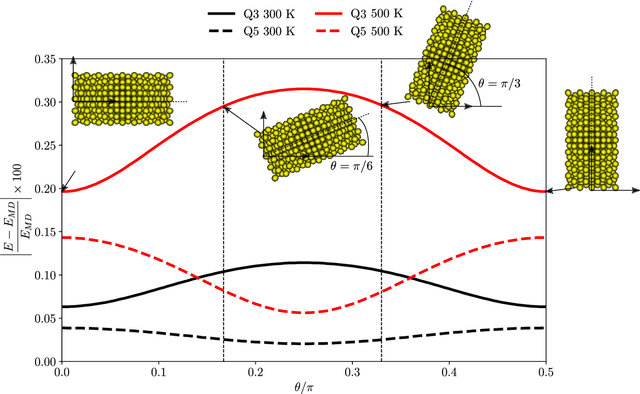
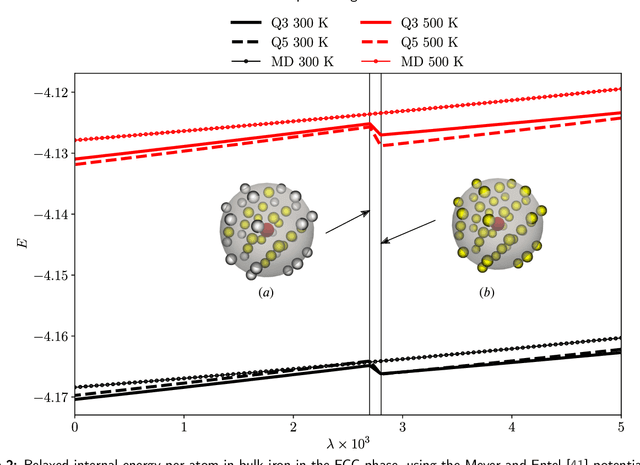

Overcoming the time scale limitations of atomistics can be achieved by switching from the state-space representation of Molecular Dynamics (MD) to a statistical-mechanics-based representation in phase space, where approximations such as maximum-entropy or Gaussian phase packets (GPP) evolve the atomistic ensemble in a time-coarsened fashion. In practice, this requires the computation of expensive high-dimensional integrals over all of phase space of an atomistic ensemble. This, in turn, is commonly accomplished efficiently by low-order numerical quadrature. We show that numerical quadrature in this context, unfortunately, comes with a set of inherent problems, which corrupt the accuracy of simulations -- especially when dealing with crystal lattices with imperfections. As a remedy, we demonstrate that Graph Neural Networks, trained on Monte-Carlo data, can serve as a replacement for commonly used numerical quadrature rules, overcoming their deficiencies and significantly improving the accuracy. This is showcased by three benchmarks: the thermal expansion of copper, the martensitic phase transition of iron, and the energy of grain boundaries. We illustrate the benefits of the proposed technique over classically used third- and fifth-order Gaussian quadrature, we highlight the impact on time-coarsened atomistic predictions, and we discuss the computational efficiency. The latter is of general importance when performing frequent evaluation of phase space or other high-dimensional integrals, which is why the proposed framework promises applications beyond the scope of atomistics.
V2V-based Collision-avoidance Decision Strategy for Autonomous Vehicles Interacting with Fully Occluded Pedestrians at Midblock on Multilane Roadways
Mar 23, 2023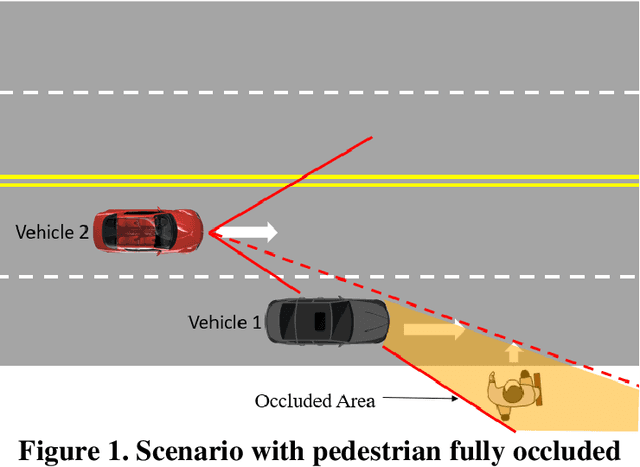

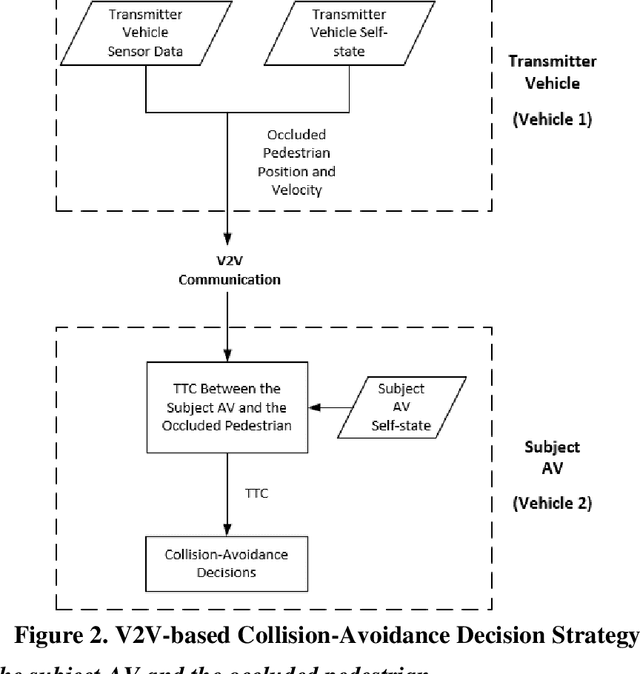
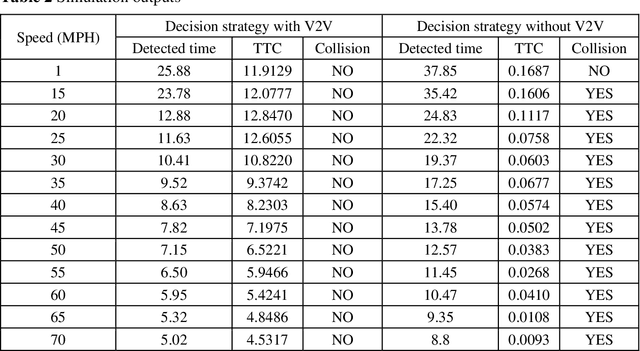
Pedestrian occlusion is challenging for autonomous vehicles (AVs) at midblock locations on multilane roadways because an AV cannot detect crossing pedestrians that are fully occluded by downstream vehicles in adjacent lanes. This paper tests the capability of vehicle-to-vehicle (V2V) communication between an AV and its downstream vehicles to share midblock pedestrian crossings information. The researchers developed a V2V-based collision-avoidance decision strategy and compared it to a base scenario (i.e., decision strategy without the utilization of V2V). Simulation results showed that for the base scenario, the near-zero time-to-collision (TTC) indicated no time for the AV to take appropriate action and resulted in dramatic braking followed by collisions. But the V2V-based collision-avoidance decision strategy allowed for a proportional braking approach to increase the TTC allowing the pedestrian to cross safely. To conclude, the V2V-based collision-avoidance decision strategy has higher safety benefits for an AV interacting with fully occluded pedestrians at midblock locations on multilane roadways.
Backdoor Defense via Adaptively Splitting Poisoned Dataset
Mar 23, 2023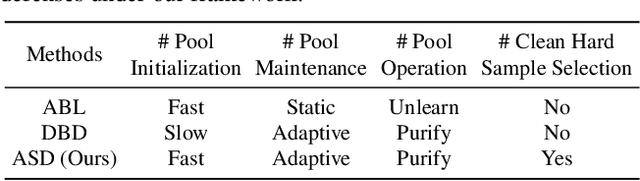
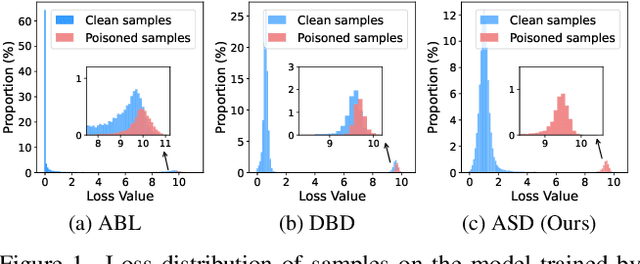
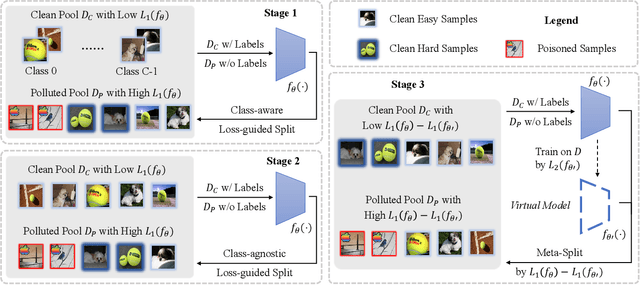
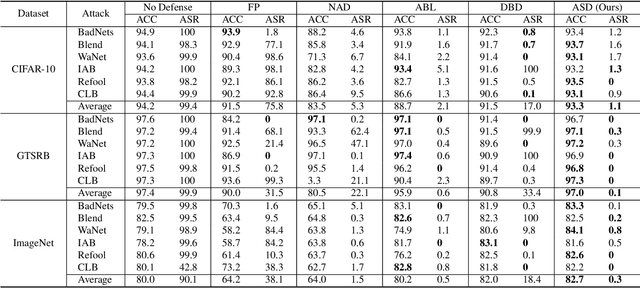
Backdoor defenses have been studied to alleviate the threat of deep neural networks (DNNs) being backdoor attacked and thus maliciously altered. Since DNNs usually adopt some external training data from an untrusted third party, a robust backdoor defense strategy during the training stage is of importance. We argue that the core of training-time defense is to select poisoned samples and to handle them properly. In this work, we summarize the training-time defenses from a unified framework as splitting the poisoned dataset into two data pools. Under our framework, we propose an adaptively splitting dataset-based defense (ASD). Concretely, we apply loss-guided split and meta-learning-inspired split to dynamically update two data pools. With the split clean data pool and polluted data pool, ASD successfully defends against backdoor attacks during training. Extensive experiments on multiple benchmark datasets and DNN models against six state-of-the-art backdoor attacks demonstrate the superiority of our ASD. Our code is available at https://github.com/KuofengGao/ASD.
AWT -- Clustering Meteorological Time Series Using an Aggregated Wavelet Tree
Dec 13, 2022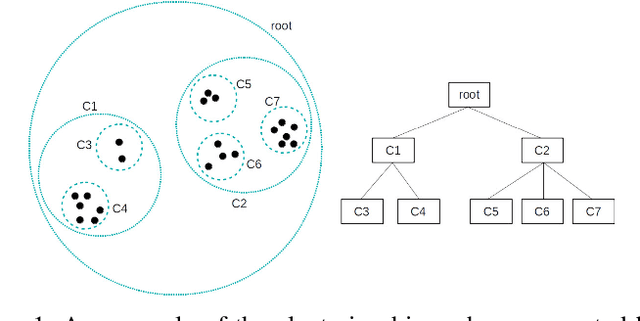
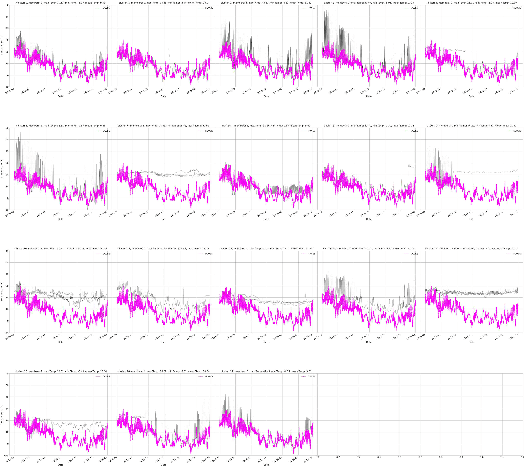
Both clustering and outlier detection play an important role for meteorological measurements. We present the AWT algorithm, a clustering algorithm for time series data that also performs implicit outlier detection during the clustering. AWT integrates ideas of several well-known K-Means clustering algorithms. It chooses the number of clusters automatically based on a user-defined threshold parameter, and it can be used for heterogeneous meteorological input data as well as for data sets that exceed the available memory size. We apply AWT to crowd sourced 2-m temperature data with an hourly resolution from the city of Vienna to detect outliers and to investigate if the final clusters show general similarities and similarities with urban land-use characteristics. It is shown that both the outlier detection and the implicit mapping to land-use characteristic is possible with AWT which opens new possible fields of application, specifically in the rapidly evolving field of urban climate and urban weather.
Improving Accuracy Without Losing Interpretability: A ML Approach for Time Series Forecasting
Dec 13, 2022
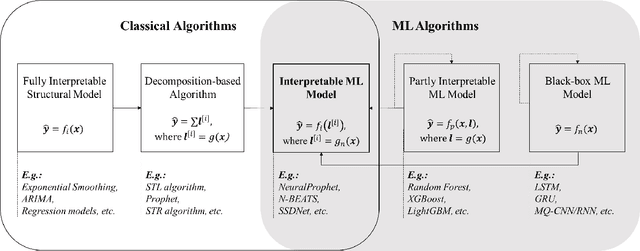
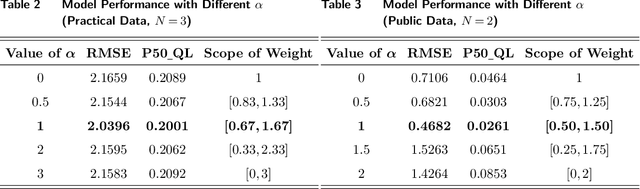
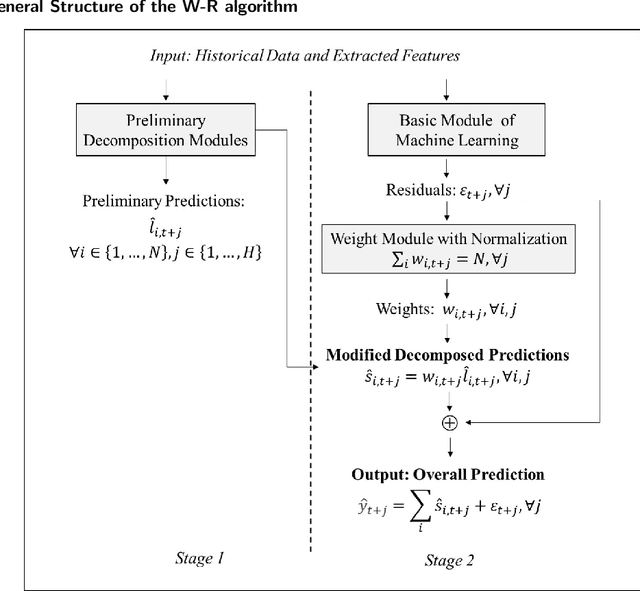
In time series forecasting, decomposition-based algorithms break aggregate data into meaningful components and are therefore appreciated for their particular advantages in interpretability. Recent algorithms often combine machine learning (hereafter ML) methodology with decomposition to improve prediction accuracy. However, incorporating ML is generally considered to sacrifice interpretability inevitably. In addition, existing hybrid algorithms usually rely on theoretical models with statistical assumptions and focus only on the accuracy of aggregate predictions, and thus suffer from accuracy problems, especially in component estimates. In response to the above issues, this research explores the possibility of improving accuracy without losing interpretability in time series forecasting. We first quantitatively define interpretability for data-driven forecasts and systematically review the existing forecasting algorithms from the perspective of interpretability. Accordingly, we propose the W-R algorithm, a hybrid algorithm that combines decomposition and ML from a novel perspective. Specifically, the W-R algorithm replaces the standard additive combination function with a weighted variant and uses ML to modify the estimates of all components simultaneously. We mathematically analyze the theoretical basis of the algorithm and validate its performance through extensive numerical experiments. In general, the W-R algorithm outperforms all decomposition-based and ML benchmarks. Based on P50_QL, the algorithm relatively improves by 8.76% in accuracy on the practical sales forecasts of JD.com and 77.99% on a public dataset of electricity loads. This research offers an innovative perspective to combine the statistical and ML algorithms, and JD.com has implemented the W-R algorithm to make accurate sales predictions and guide its marketing activities.
PopSparse: Accelerated block sparse matrix multiplication on IPU
Mar 29, 2023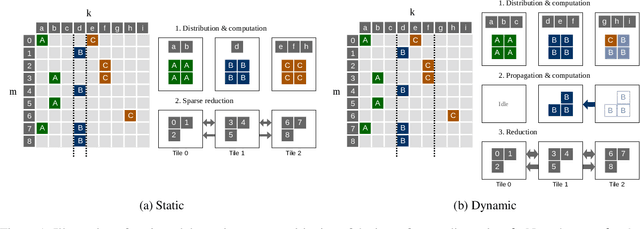
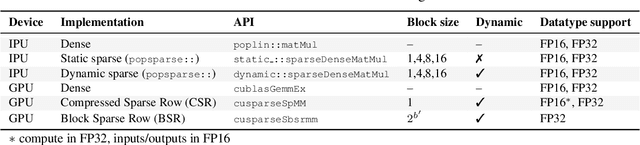
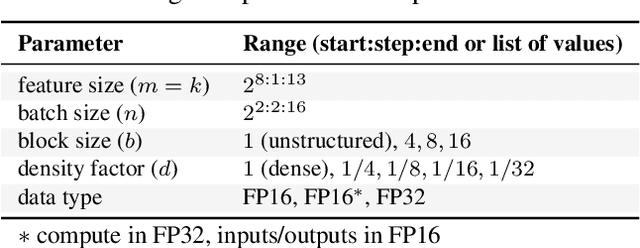
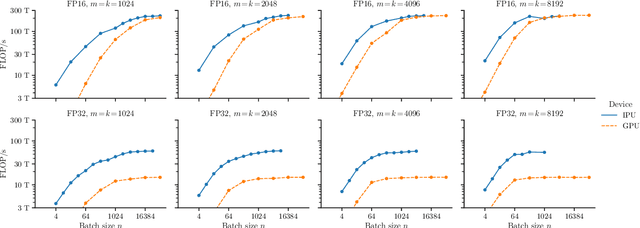
Reducing the computational cost of running large scale neural networks using sparsity has attracted great attention in the deep learning community. While much success has been achieved in reducing FLOP and parameter counts while maintaining acceptable task performance, achieving actual speed improvements has typically been much more difficult, particularly on general purpose accelerators (GPAs) such as NVIDIA GPUs using low precision number formats. In this work we introduce PopSparse, a library that enables fast sparse operations on Graphcore IPUs by leveraging both the unique hardware characteristics of IPUs as well as any block structure defined in the data. We target two different types of sparsity: static, where the sparsity pattern is fixed at compile-time; and dynamic, where it can change each time the model is run. We present benchmark results for matrix multiplication for both of these modes on IPU with a range of block sizes, matrix sizes and densities. Results indicate that the PopSparse implementations are faster than dense matrix multiplications on IPU at a range of sparsity levels with large matrix size and block size. Furthermore, static sparsity in general outperforms dynamic sparsity. While previous work on GPAs has shown speedups only for very high sparsity (typically 99\% and above), the present work demonstrates that our static sparse implementation outperforms equivalent dense calculations in FP16 at lower sparsity (around 90%).
Learning the Delay Using Neural Delay Differential Equations
Apr 03, 2023
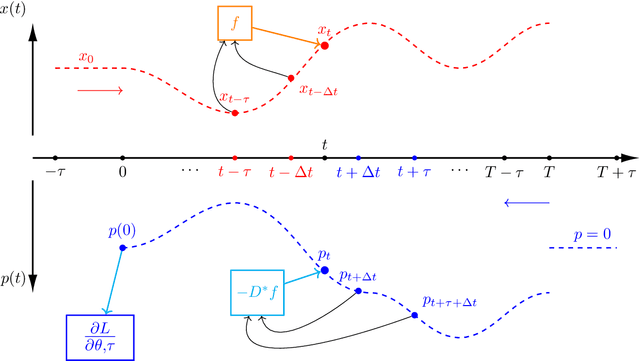
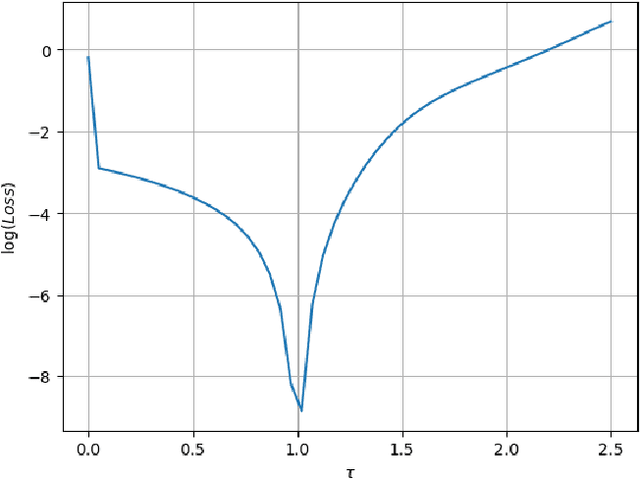
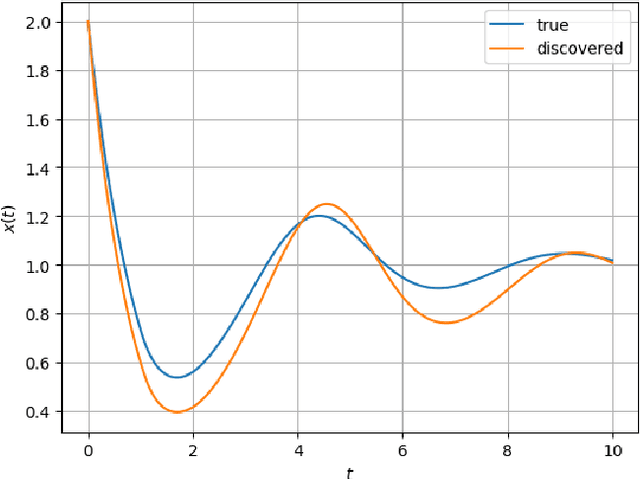
The intersection of machine learning and dynamical systems has generated considerable interest recently. Neural Ordinary Differential Equations (NODEs) represent a rich overlap between these fields. In this paper, we develop a continuous time neural network approach based on Delay Differential Equations (DDEs). Our model uses the adjoint sensitivity method to learn the model parameters and delay directly from data. Our approach is inspired by that of NODEs and extends earlier neural DDE models, which have assumed that the value of the delay is known a priori. We perform a sensitivity analysis on our proposed approach and demonstrate its ability to learn DDE parameters from benchmark systems. We conclude our discussion with potential future directions and applications.