 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Video-kMaX: A Simple Unified Approach for Online and Near-Online Video Panoptic Segmentation
Apr 10, 2023
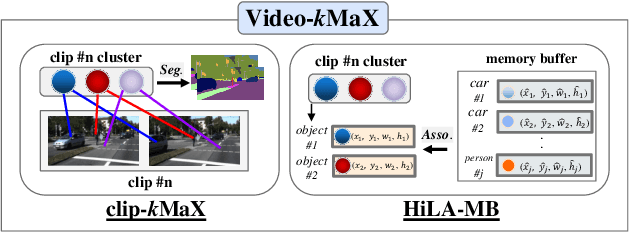
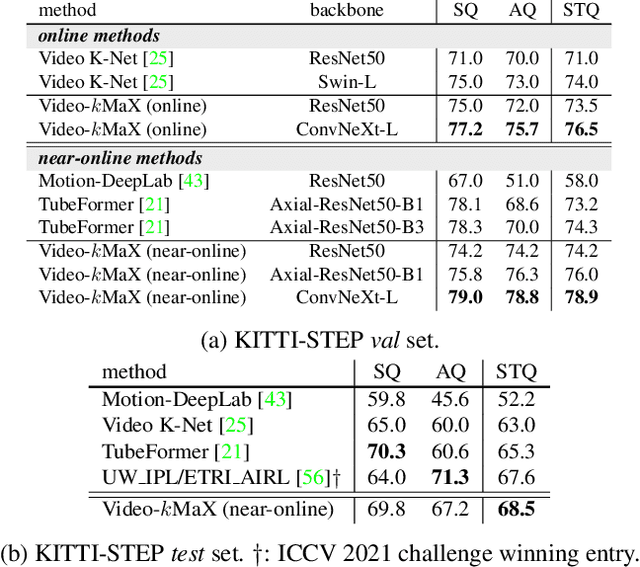
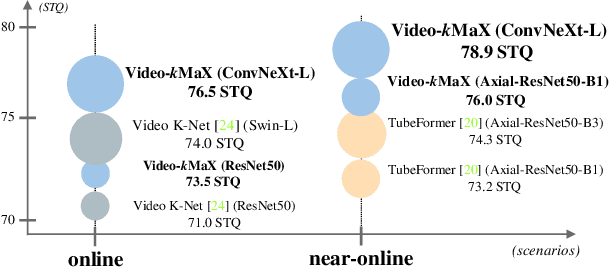
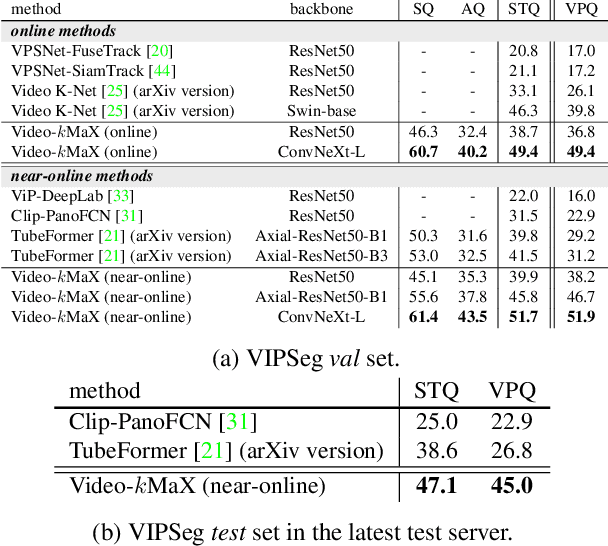
Video Panoptic Segmentation (VPS) aims to achieve comprehensive pixel-level scene understanding by segmenting all pixels and associating objects in a video. Current solutions can be categorized into online and near-online approaches. Evolving over the time, each category has its own specialized designs, making it nontrivial to adapt models between different categories. To alleviate the discrepancy, in this work, we propose a unified approach for online and near-online VPS. The meta architecture of the proposed Video-kMaX consists of two components: within clip segmenter (for clip-level segmentation) and cross-clip associater (for association beyond clips). We propose clip-kMaX (clip k-means mask transformer) and HiLA-MB (Hierarchical Location-Aware Memory Buffer) to instantiate the segmenter and associater, respectively. Our general formulation includes the online scenario as a special case by adopting clip length of one. Without bells and whistles, Video-kMaX sets a new state-of-the-art on KITTI-STEP and VIPSeg for video panoptic segmentation, and VSPW for video semantic segmentation. Code will be made publicly available.
VARS: Video Assistant Referee System for Automated Soccer Decision Making from Multiple Views
Apr 10, 2023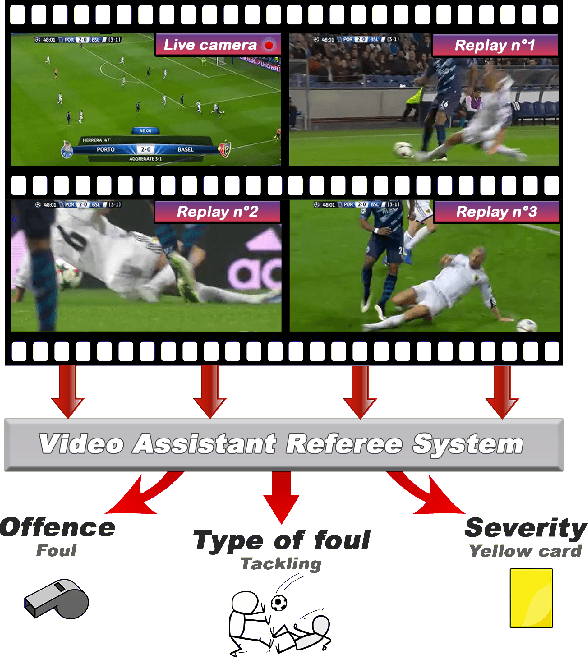
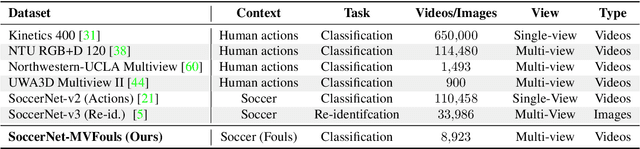

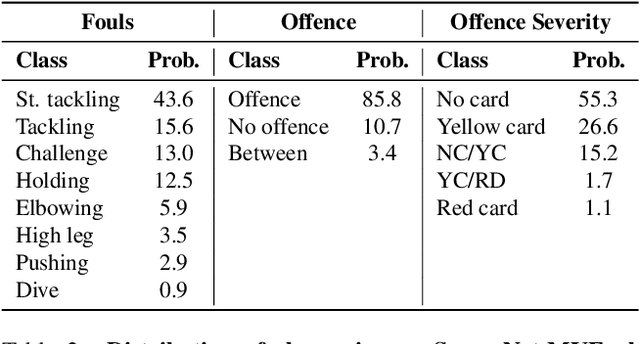
The Video Assistant Referee (VAR) has revolutionized association football, enabling referees to review incidents on the pitch, make informed decisions, and ensure fairness. However, due to the lack of referees in many countries and the high cost of the VAR infrastructure, only professional leagues can benefit from it. In this paper, we propose a Video Assistant Referee System (VARS) that can automate soccer decision-making. VARS leverages the latest findings in multi-view video analysis, to provide real-time feedback to the referee, and help them make informed decisions that can impact the outcome of a game. To validate VARS, we introduce SoccerNet-MVFoul, a novel video dataset of soccer fouls from multiple camera views, annotated with extensive foul descriptions by a professional soccer referee, and we benchmark our VARS to automatically recognize the characteristics of these fouls. We believe that VARS has the potential to revolutionize soccer refereeing and take the game to new heights of fairness and accuracy across all levels of professional and amateur federations.
EVC: Towards Real-Time Neural Image Compression with Mask Decay
Feb 10, 2023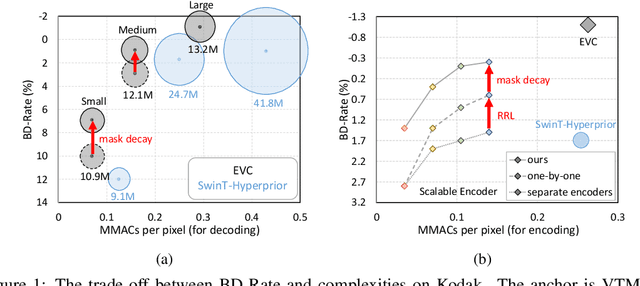
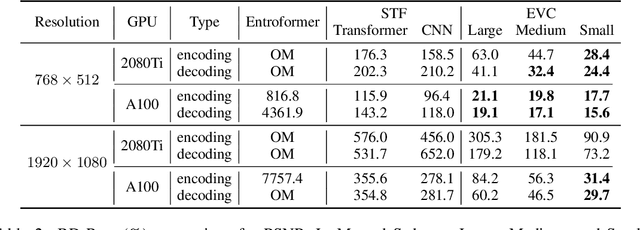
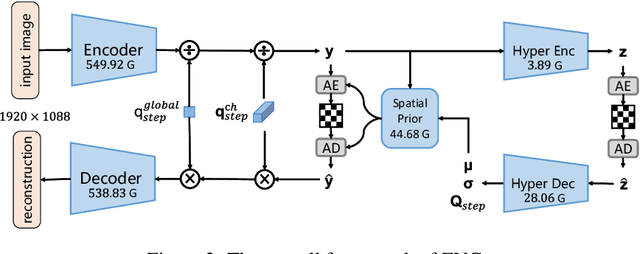
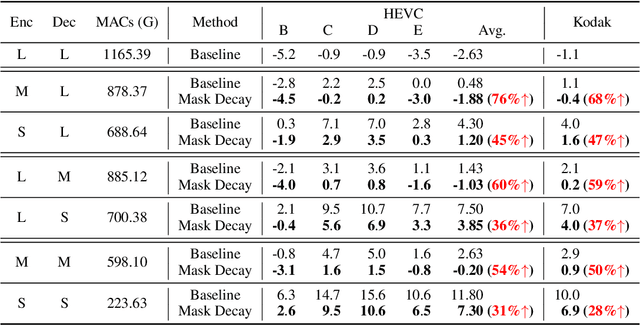
Neural image compression has surpassed state-of-the-art traditional codecs (H.266/VVC) for rate-distortion (RD) performance, but suffers from large complexity and separate models for different rate-distortion trade-offs. In this paper, we propose an Efficient single-model Variable-bit-rate Codec (EVC), which is able to run at 30 FPS with 768x512 input images and still outperforms VVC for the RD performance. By further reducing both encoder and decoder complexities, our small model even achieves 30 FPS with 1920x1080 input images. To bridge the performance gap between our different capacities models, we meticulously design the mask decay, which transforms the large model's parameters into the small model automatically. And a novel sparsity regularization loss is proposed to mitigate shortcomings of $L_p$ regularization. Our algorithm significantly narrows the performance gap by 50% and 30% for our medium and small models, respectively. At last, we advocate the scalable encoder for neural image compression. The encoding complexity is dynamic to meet different latency requirements. We propose decaying the large encoder multiple times to reduce the residual representation progressively. Both mask decay and residual representation learning greatly improve the RD performance of our scalable encoder. Our code is at https://github.com/microsoft/DCVC.
StarNet: Style-Aware 3D Point Cloud Generation
Mar 28, 2023
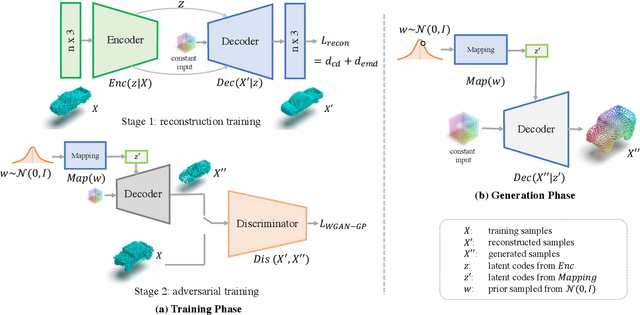
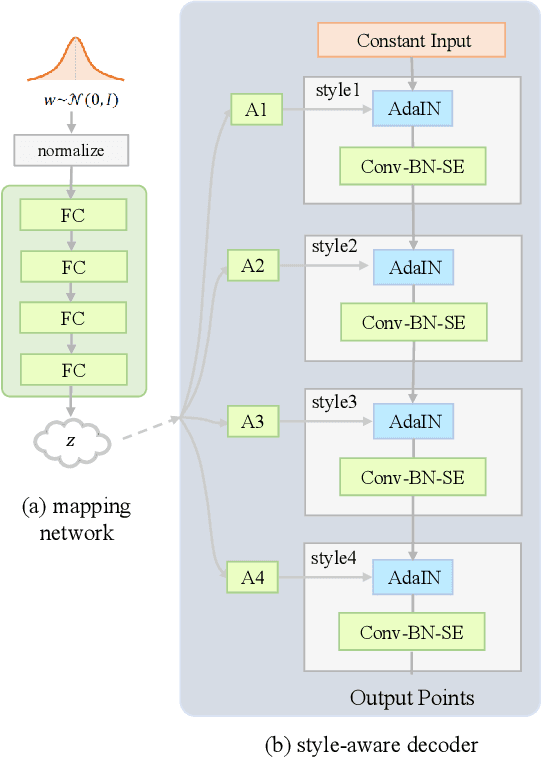

This paper investigates an open research task of reconstructing and generating 3D point clouds. Most existing works of 3D generative models directly take the Gaussian prior as input for the decoder to generate 3D point clouds, which fail to learn disentangled latent codes, leading noisy interpolated results. Most of the GAN-based models fail to discriminate the local geometries, resulting in the point clouds generated not evenly distributed at the object surface, hence degrading the point cloud generation quality. Moreover, prevailing methods adopt computation-intensive frameworks, such as flow-based models and Markov chains, which take plenty of time and resources in the training phase. To resolve these limitations, this paper proposes a unified style-aware network architecture combining both point-wise distance loss and adversarial loss, StarNet which is able to reconstruct and generate high-fidelity and even 3D point clouds using a mapping network that can effectively disentangle the Gaussian prior from input's high-level attributes in the mapped latent space to generate realistic interpolated objects. Experimental results demonstrate that our framework achieves comparable state-of-the-art performance on various metrics in the point cloud reconstruction and generation tasks, but is more lightweight in model size, requires much fewer parameters and less time for model training.
FeDiSa: A Semi-asynchronous Federated Learning Framework for Power System Fault and Cyberattack Discrimination
Mar 28, 2023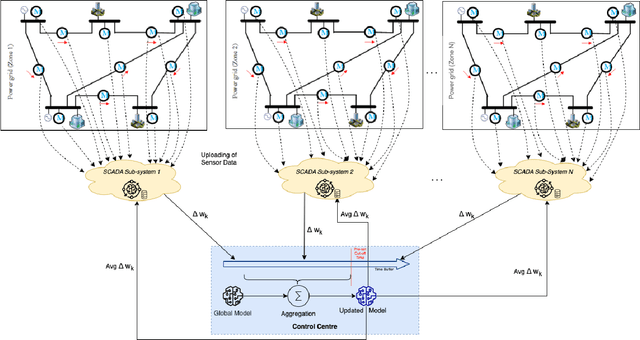
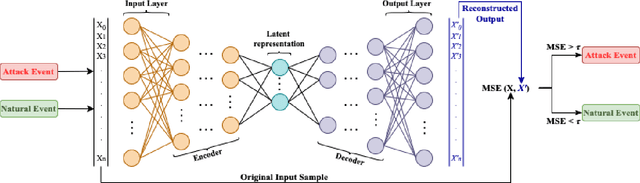
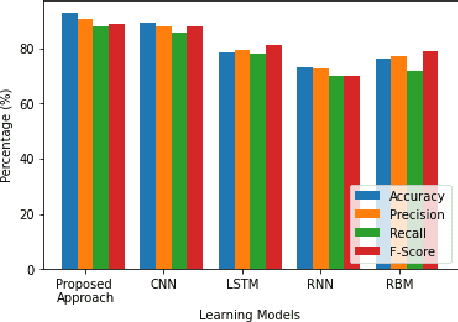
With growing security and privacy concerns in the Smart Grid domain, intrusion detection on critical energy infrastructure has become a high priority in recent years. To remedy the challenges of privacy preservation and decentralized power zones with strategic data owners, Federated Learning (FL) has contemporarily surfaced as a viable privacy-preserving alternative which enables collaborative training of attack detection models without requiring the sharing of raw data. To address some of the technical challenges associated with conventional synchronous FL, this paper proposes FeDiSa, a novel Semi-asynchronous Federated learning framework for power system faults and cyberattack Discrimination which takes into account communication latency and stragglers. Specifically, we propose a collaborative training of deep auto-encoder by Supervisory Control and Data Acquisition sub-systems which upload their local model updates to a control centre, which then perform a semi-asynchronous model aggregation for a new global model parameters based on a buffer system and a preset cut-off time. Experiments on the proposed framework using publicly available industrial control systems datasets reveal superior attack detection accuracy whilst preserving data confidentiality and minimizing the adverse effects of communication latency and stragglers. Furthermore, we see a 35% improvement in training time, thus validating the robustness of our proposed method.
SST: Real-time End-to-end Monocular 3D Reconstruction via Sparse Spatial-Temporal Guidance
Dec 13, 2022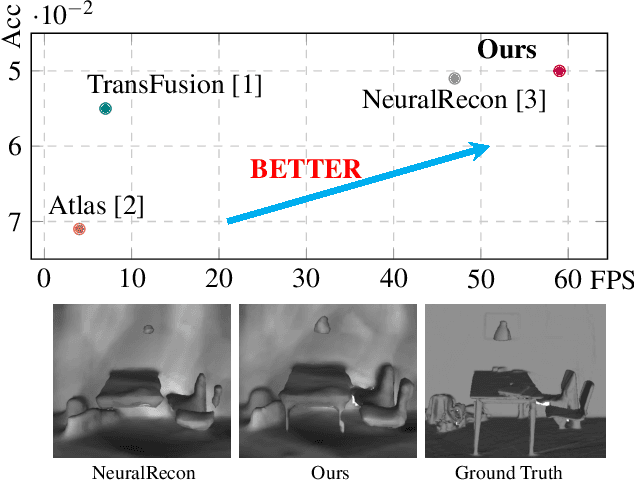
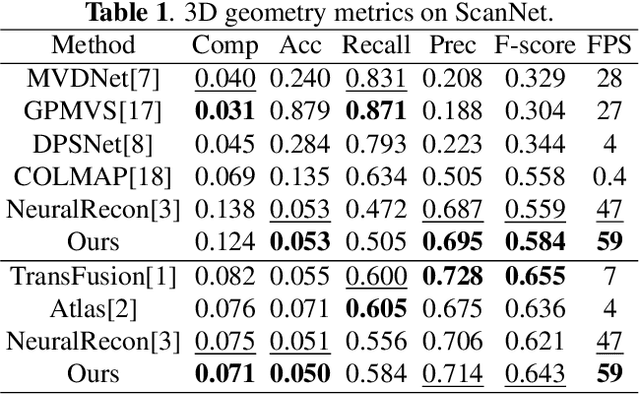
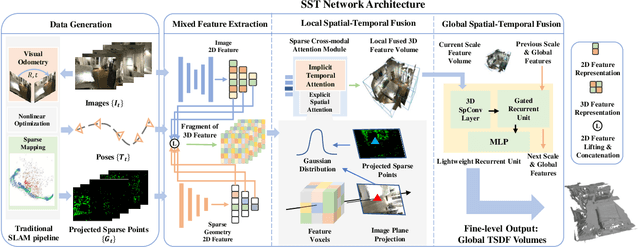
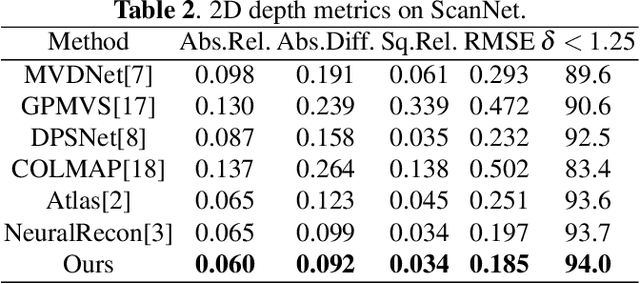
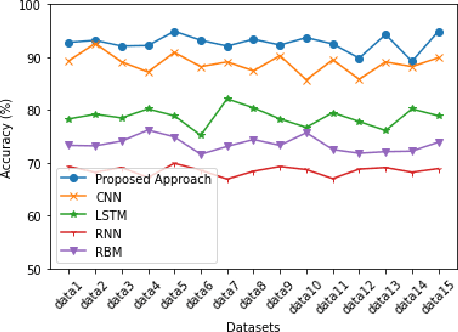
Real-time monocular 3D reconstruction is a challenging problem that remains unsolved. Although recent end-to-end methods have demonstrated promising results, tiny structures and geometric boundaries are hardly captured due to their insufficient supervision neglecting spatial details and oversimplified feature fusion ignoring temporal cues. To address the problems, we propose an end-to-end 3D reconstruction network SST, which utilizes Sparse estimated points from visual SLAM system as additional Spatial guidance and fuses Temporal features via a novel cross-modal attention mechanism, achieving more detailed reconstruction results. We propose a Local Spatial-Temporal Fusion module to exploit more informative spatial-temporal cues from multi-view color information and sparse priors, as well a Global Spatial-Temporal Fusion module to refine the local TSDF volumes with the world-frame model from coarse to fine. Extensive experiments on ScanNet and 7-Scenes demonstrate that SST outperforms all state-of-the-art competitors, whilst keeping a high inference speed at 59 FPS, enabling real-world applications with real-time requirements.
SMAE: Few-shot Learning for HDR Deghosting with Saturation-Aware Masked Autoencoders
Apr 14, 2023
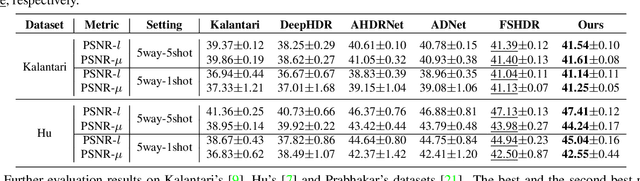
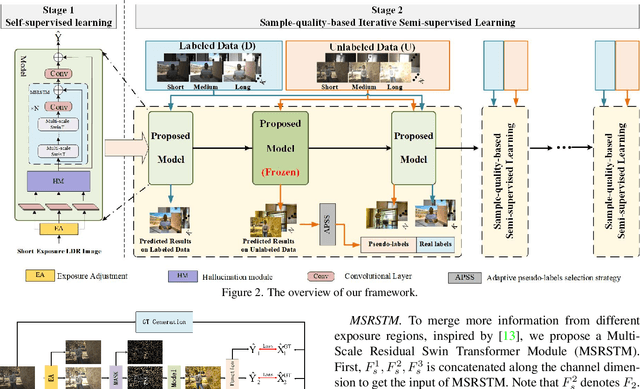
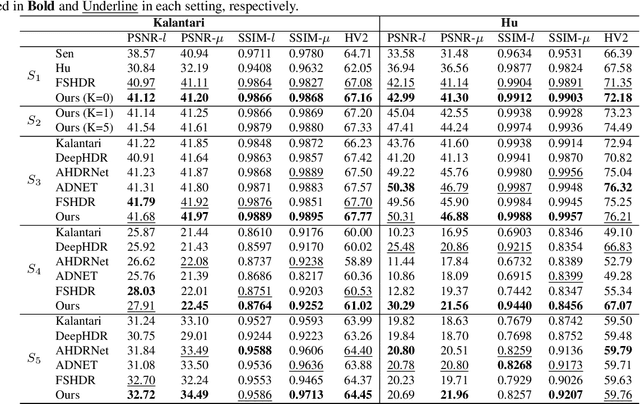
Generating a high-quality High Dynamic Range (HDR) image from dynamic scenes has recently been extensively studied by exploiting Deep Neural Networks (DNNs). Most DNNs-based methods require a large amount of training data with ground truth, requiring tedious and time-consuming work. Few-shot HDR imaging aims to generate satisfactory images with limited data. However, it is difficult for modern DNNs to avoid overfitting when trained on only a few images. In this work, we propose a novel semi-supervised approach to realize few-shot HDR imaging via two stages of training, called SSHDR. Unlikely previous methods, directly recovering content and removing ghosts simultaneously, which is hard to achieve optimum, we first generate content of saturated regions with a self-supervised mechanism and then address ghosts via an iterative semi-supervised learning framework. Concretely, considering that saturated regions can be regarded as masking Low Dynamic Range (LDR) input regions, we design a Saturated Mask AutoEncoder (SMAE) to learn a robust feature representation and reconstruct a non-saturated HDR image. We also propose an adaptive pseudo-label selection strategy to pick high-quality HDR pseudo-labels in the second stage to avoid the effect of mislabeled samples. Experiments demonstrate that SSHDR outperforms state-of-the-art methods quantitatively and qualitatively within and across different datasets, achieving appealing HDR visualization with few labeled samples.
Design of Efficient Point-Mass Filter with Application in Terrain Aided Navigation
Mar 09, 2023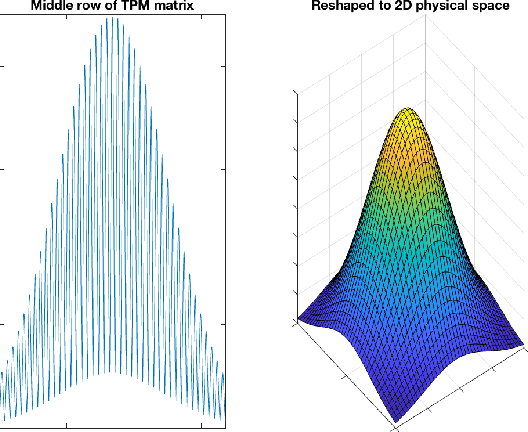
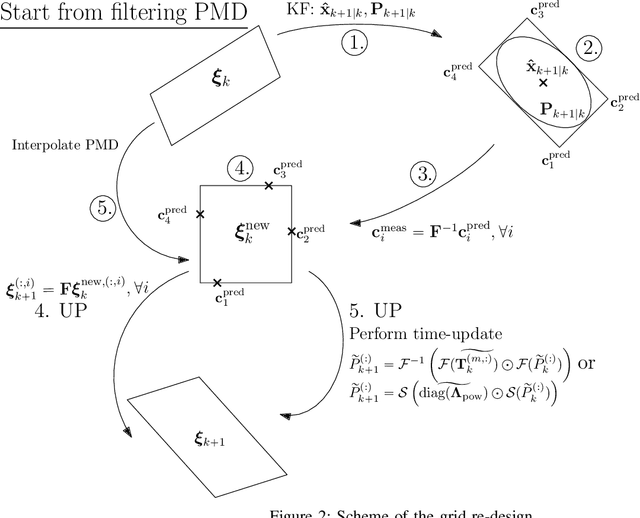
This paper deals with state estimation of stochastic models with linear state dynamics, continuous or discrete in time. The emphasis is laid on a numerical solution to the state prediction by the time-update step of the grid-point-based point-mass filter (PMF), which is the most computationally demanding part of the PMF algorithm. A novel efficient PMF (ePMF) estimator is proposed, designed, and discussed. By numerical illustrations, it is shown, that the proposed ePMF can lead to a time complexity reduction that exceeds 99.9% without compromising accuracy. The MATLAB code of the ePMF is released with this paper.
Faulty Branch Identification in Passive Optical Networks using Machine Learning
Apr 03, 2023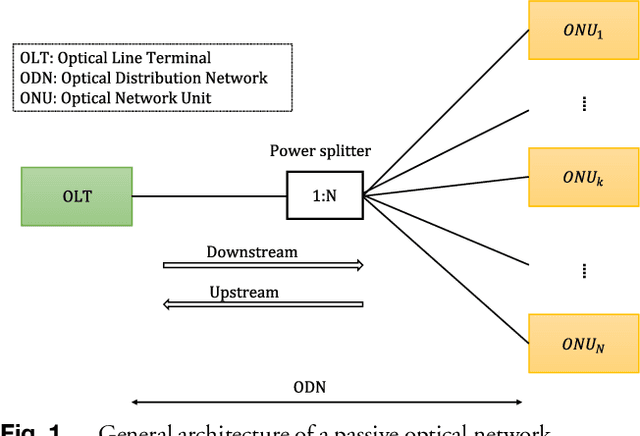

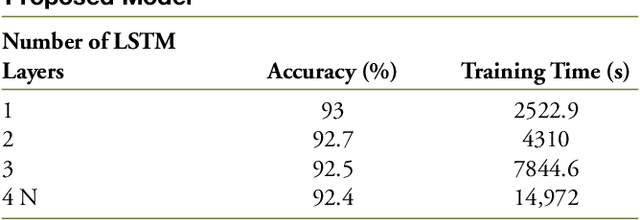
Passive optical networks (PONs) have become a promising broadband access network solution. To ensure a reliable transmission, and to meet service level agreements, PON systems have to be monitored constantly in order to quickly identify and localize networks faults. Typically, a service disruption in a PON system is mainly due to fiber cuts and optical network unit (ONU) transmitter/receiver failures. When the ONUs are located at different distances from the optical line terminal (OLT), the faulty ONU or branch can be identified by analyzing the recorded optical time domain reflectometry (OTDR) traces. However, faulty branch isolation becomes very challenging when the reflections originating from two or more branches with similar length overlap, which makes it very hard to discriminate the faulty branches given the global backscattered signal. Recently, machine learning (ML) based approaches have shown great potential for managing optical faults in PON systems. Such techniques perform well when trained and tested with data derived from the same PON system. But their performance may severely degrade, if the PON system (adopted for the generation of the training data) has changed, e.g. by adding more branches or varying the length difference between two neighboring branches. etc. A re-training of the ML models has to be conducted for each network change, which can be time consuming. In this paper, to overcome the aforementioned issues, we propose a generic ML approach trained independently of the network architecture for identifying the faulty branch in PON systems given OTDR signals for the cases of branches with close lengths. Such an approach can be applied to an arbitrary PON system without requiring to be re-trained for each change of the network. The proposed approach is validated using experimental data derived from PON system.
An End-to-End Human Simulator for Task-Oriented Multimodal Human-Robot Collaboration
Apr 02, 2023

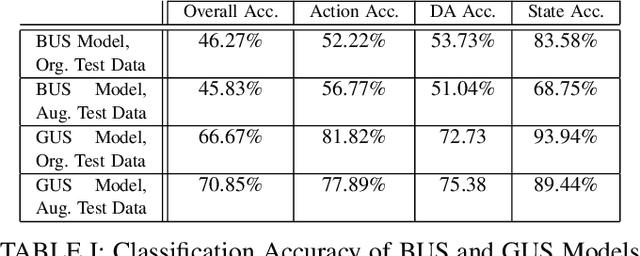
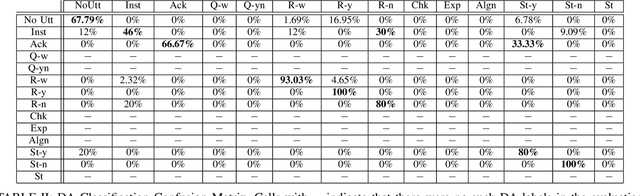
This paper proposes a neural network-based user simulator that can provide a multimodal interactive environment for training Reinforcement Learning (RL) agents in collaborative tasks involving multiple modes of communication. The simulator is trained on the existing ELDERLY-AT-HOME corpus and accommodates multiple modalities such as language, pointing gestures, and haptic-ostensive actions. The paper also presents a novel multimodal data augmentation approach, which addresses the challenge of using a limited dataset due to the expensive and time-consuming nature of collecting human demonstrations. Overall, the study highlights the potential for using RL and multimodal user simulators in developing and improving domestic assistive robots.