 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AGI for Agriculture
Apr 12, 2023
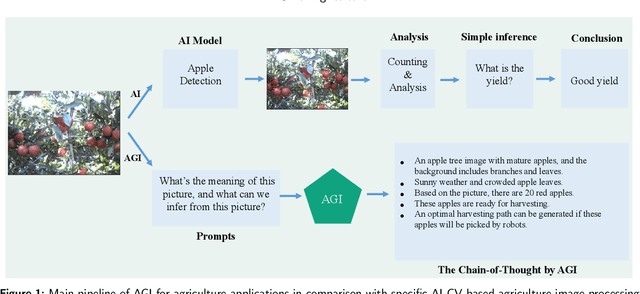
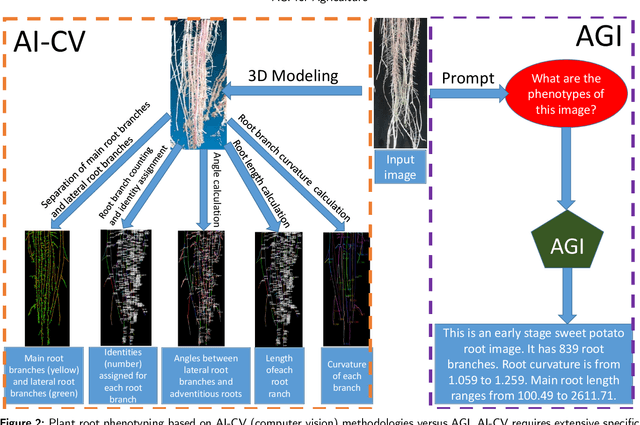
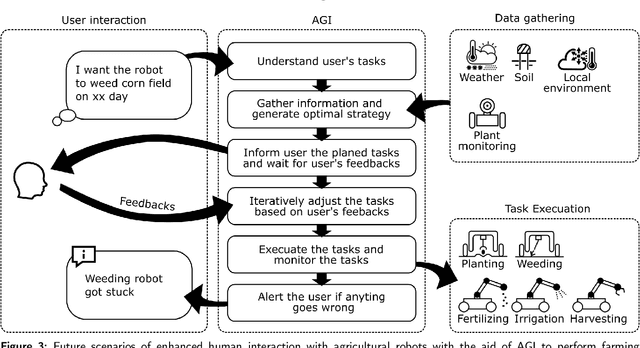
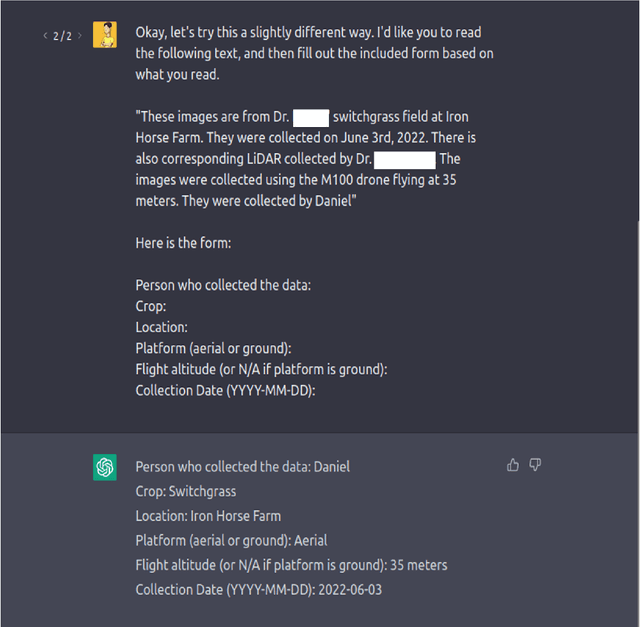
Artificial General Intelligence (AGI) is poised to revolutionize a variety of sectors, including healthcare, finance, transportation, and education. Within healthcare, AGI is being utilized to analyze clinical medical notes, recognize patterns in patient data, and aid in patient management. Agriculture is another critical sector that impacts the lives of individuals worldwide. It serves as a foundation for providing food, fiber, and fuel, yet faces several challenges, such as climate change, soil degradation, water scarcity, and food security. AGI has the potential to tackle these issues by enhancing crop yields, reducing waste, and promoting sustainable farming practices. It can also help farmers make informed decisions by leveraging real-time data, leading to more efficient and effective farm management. This paper delves into the potential future applications of AGI in agriculture, such as agriculture image processing, natural language processing (NLP), robotics, knowledge graphs, and infrastructure, and their impact on precision livestock and precision crops. By leveraging the power of AGI, these emerging technologies can provide farmers with actionable insights, allowing for optimized decision-making and increased productivity. The transformative potential of AGI in agriculture is vast, and this paper aims to highlight its potential to revolutionize the industry.
A Closer Look at Parameter-Efficient Tuning in Diffusion Models
Apr 12, 2023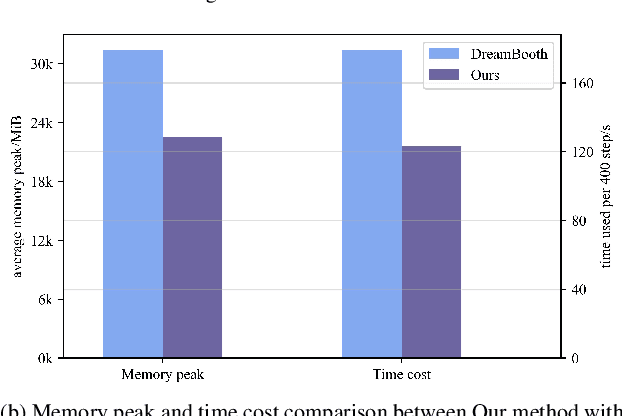

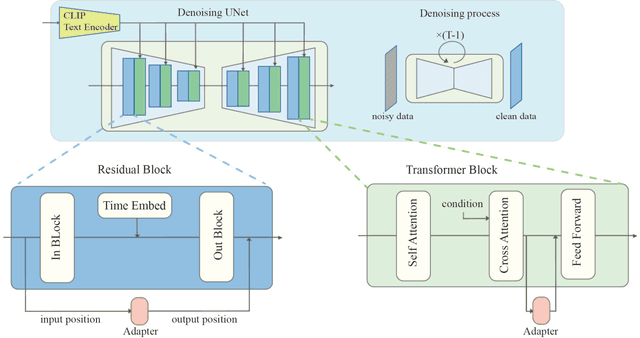
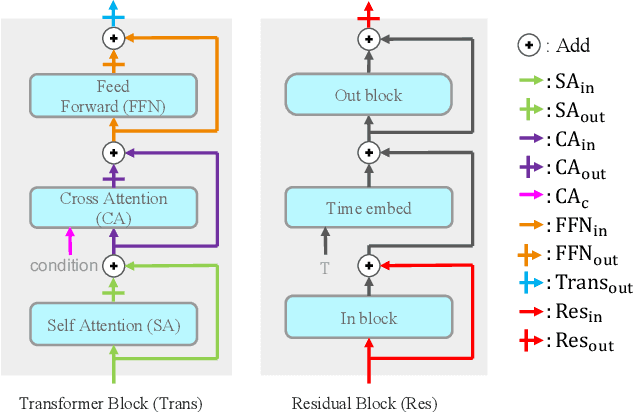
Large-scale diffusion models like Stable Diffusion are powerful and find various real-world applications while customizing such models by fine-tuning is both memory and time inefficient. Motivated by the recent progress in natural language processing, we investigate parameter-efficient tuning in large diffusion models by inserting small learnable modules (termed adapters). In particular, we decompose the design space of adapters into orthogonal factors -- the input position, the output position as well as the function form, and perform Analysis of Variance (ANOVA), a classical statistical approach for analyzing the correlation between discrete (design options) and continuous variables (evaluation metrics). Our analysis suggests that the input position of adapters is the critical factor influencing the performance of downstream tasks. Then, we carefully study the choice of the input position, and we find that putting the input position after the cross-attention block can lead to the best performance, validated by additional visualization analyses. Finally, we provide a recipe for parameter-efficient tuning in diffusion models, which is comparable if not superior to the fully fine-tuned baseline (e.g., DreamBooth) with only 0.75 \% extra parameters, across various customized tasks.
Dynamic Mixed Membership Stochastic Block Model for Weighted Labeled Networks
Apr 12, 2023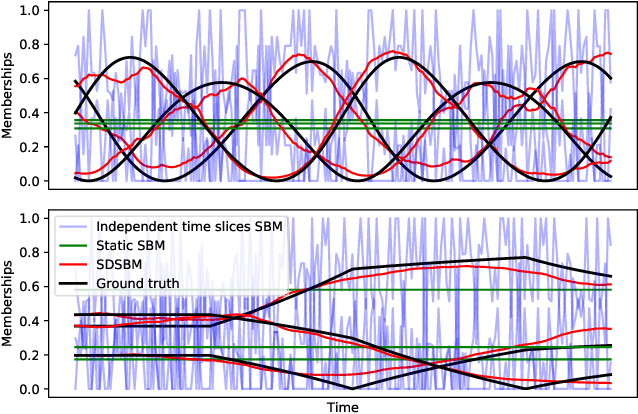
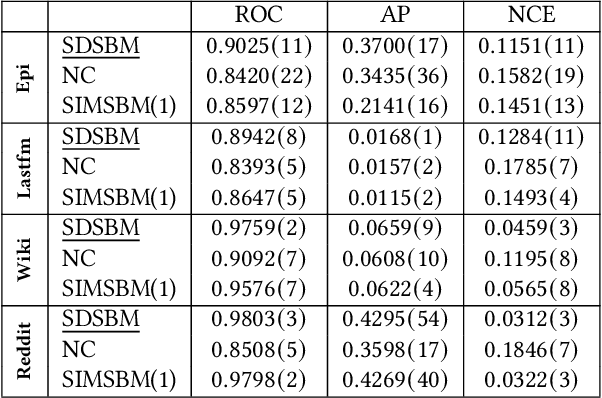
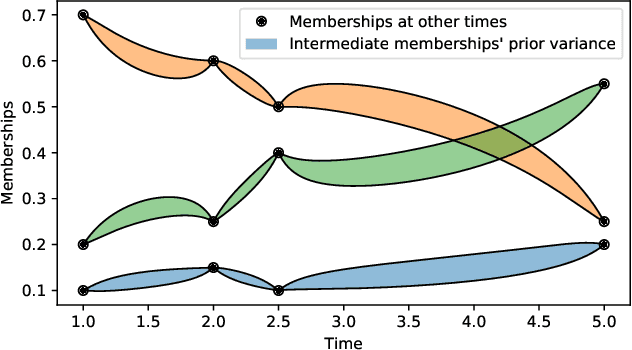
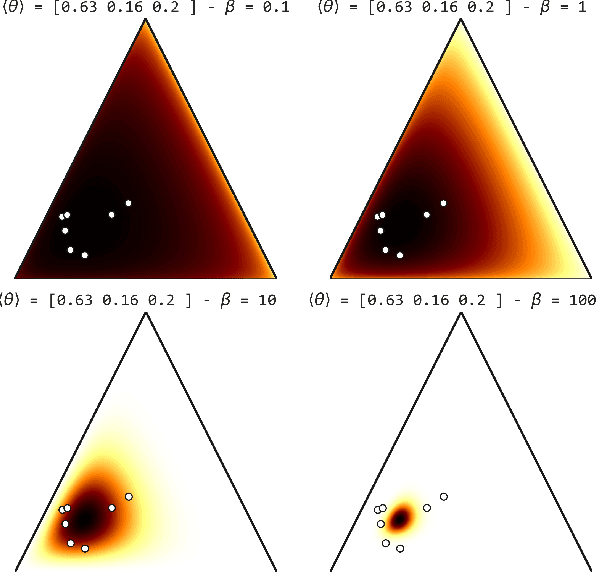
Most real-world networks evolve over time. Existing literature proposes models for dynamic networks that are either unlabeled or assumed to have a single membership structure. On the other hand, a new family of Mixed Membership Stochastic Block Models (MMSBM) allows to model static labeled networks under the assumption of mixed-membership clustering. In this work, we propose to extend this later class of models to infer dynamic labeled networks under a mixed membership assumption. Our approach takes the form of a temporal prior on the model's parameters. It relies on the single assumption that dynamics are not abrupt. We show that our method significantly differs from existing approaches, and allows to model more complex systems --dynamic labeled networks. We demonstrate the robustness of our method with several experiments on both synthetic and real-world datasets. A key interest of our approach is that it needs very few training data to yield good results. The performance gain under challenging conditions broadens the variety of possible applications of automated learning tools --as in social sciences, which comprise many fields where small datasets are a major obstacle to the introduction of machine learning methods.
Best Practices for 2-Body Pose Forecasting
Apr 12, 2023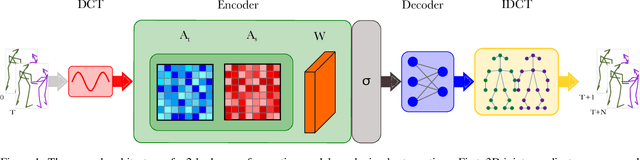


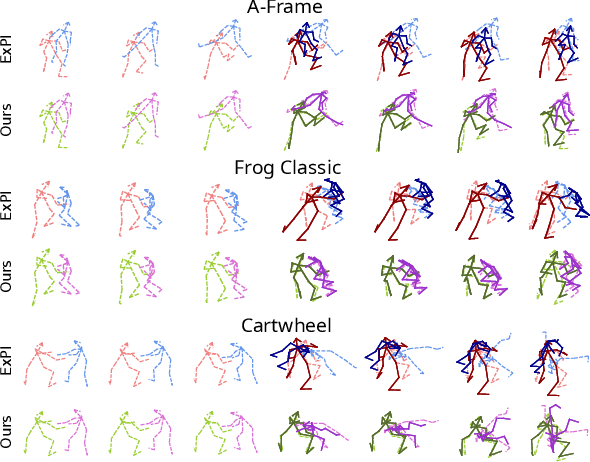
The task of collaborative human pose forecasting stands for predicting the future poses of multiple interacting people, given those in previous frames. Predicting two people in interaction, instead of each separately, promises better performance, due to their body-body motion correlations. But the task has remained so far primarily unexplored. In this paper, we review the progress in human pose forecasting and provide an in-depth assessment of the single-person practices that perform best for 2-body collaborative motion forecasting. Our study confirms the positive impact of frequency input representations, space-time separable and fully-learnable interaction adjacencies for the encoding GCN and FC decoding. Other single-person practices do not transfer to 2-body, so the proposed best ones do not include hierarchical body modeling or attention-based interaction encoding. We further contribute a novel initialization procedure for the 2-body spatial interaction parameters of the encoder, which benefits performance and stability. Altogether, our proposed 2-body pose forecasting best practices yield a performance improvement of 21.9% over the state-of-the-art on the most recent ExPI dataset, whereby the novel initialization accounts for 3.5%. See our project page at https://www.pinlab.org/bestpractices2body
Deep reinforcement learning reveals fewer sensors are needed for autonomous gust alleviation
Apr 06, 2023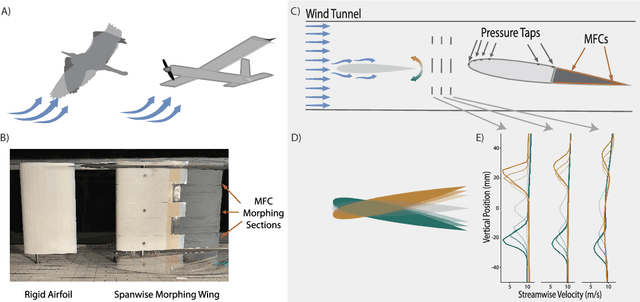
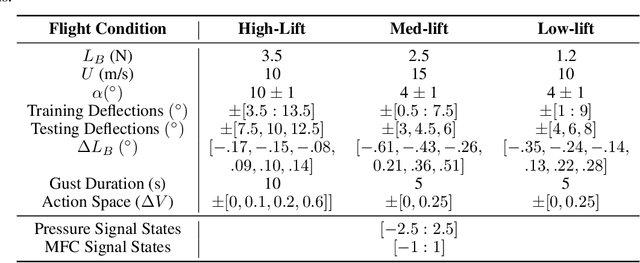
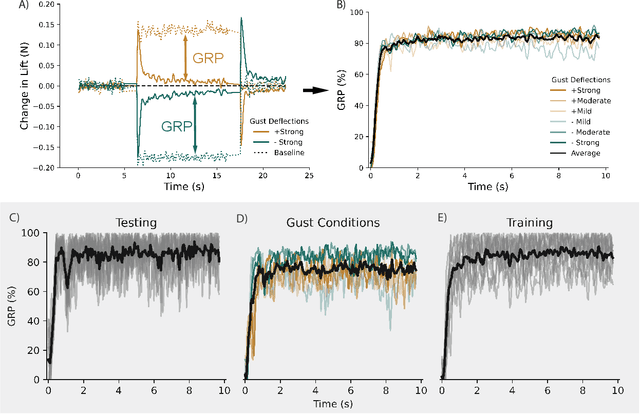
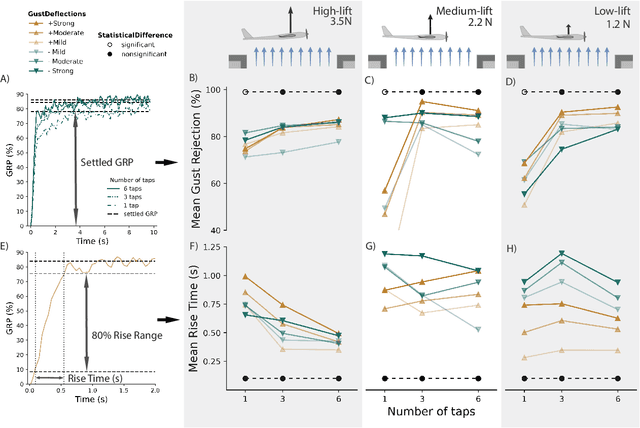
There is a growing need for uncrewed aerial vehicles (UAVs) to operate in cities. However, the uneven urban landscape and complex street systems cause large-scale wind gusts that challenge the safe and effective operation of UAVs. Current gust alleviation methods rely on traditional control surfaces and computationally expensive modeling to select a control action, leading to a slower response. Here, we used deep reinforcement learning to create an autonomous gust alleviation controller for a camber-morphing wing. This method reduced gust impact by 84%, directly from real-time, on-board pressure signals. Notably, we found that gust alleviation using signals from only three pressure taps was statistically indistinguishable from using six signals. This reduced-sensor fly-by-feel control opens the door to UAV missions in previously inoperable locations.
Morph-SSL: Self-Supervision with Longitudinal Morphing to Predict AMD Progression from OCT
Apr 17, 2023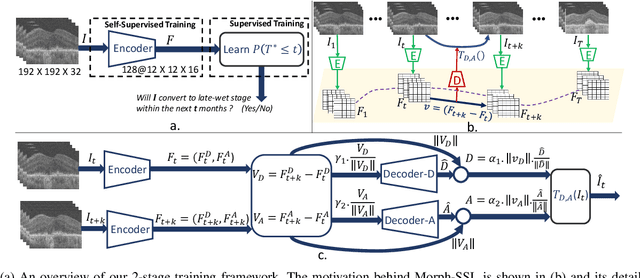
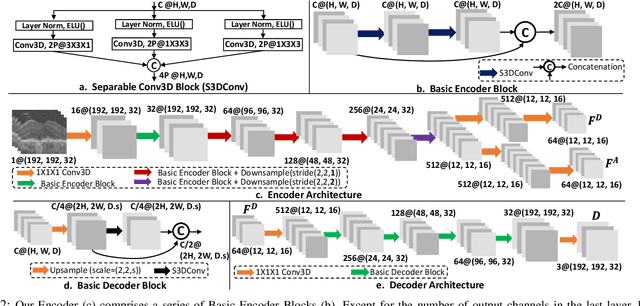

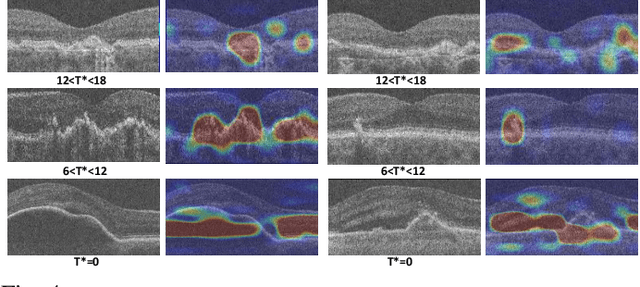
The lack of reliable biomarkers makes predicting the conversion from intermediate to neovascular age-related macular degeneration (iAMD, nAMD) a challenging task. We develop a Deep Learning (DL) model to predict the future risk of conversion of an eye from iAMD to nAMD from its current OCT scan. Although eye clinics generate vast amounts of longitudinal OCT scans to monitor AMD progression, only a small subset can be manually labeled for supervised DL. To address this issue, we propose Morph-SSL, a novel Self-supervised Learning (SSL) method for longitudinal data. It uses pairs of unlabelled OCT scans from different visits and involves morphing the scan from the previous visit to the next. The Decoder predicts the transformation for morphing and ensures a smooth feature manifold that can generate intermediate scans between visits through linear interpolation. Next, the Morph-SSL trained features are input to a Classifier which is trained in a supervised manner to model the cumulative probability distribution of the time to conversion with a sigmoidal function. Morph-SSL was trained on unlabelled scans of 399 eyes (3570 visits). The Classifier was evaluated with a five-fold cross-validation on 2418 scans from 343 eyes with clinical labels of the conversion date. The Morph-SSL features achieved an AUC of 0.766 in predicting the conversion to nAMD within the next 6 months, outperforming the same network when trained end-to-end from scratch or pre-trained with popular SSL methods. Automated prediction of the future risk of nAMD onset can enable timely treatment and individualized AMD management.
Predicting dynamic, motion-related changes in B0 field in the brain at a 7 T MRI using a subject-specific fine-tuned U-net
Apr 17, 2023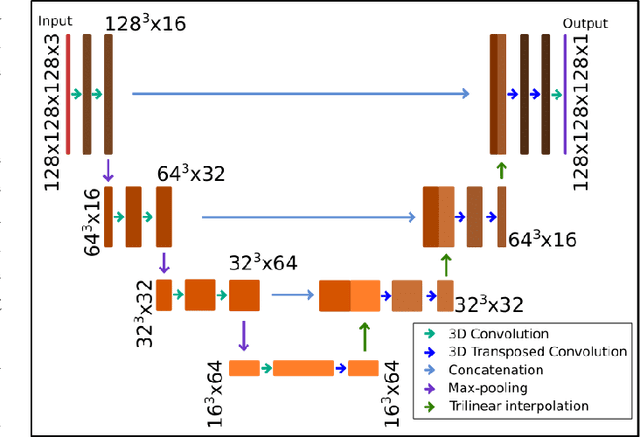
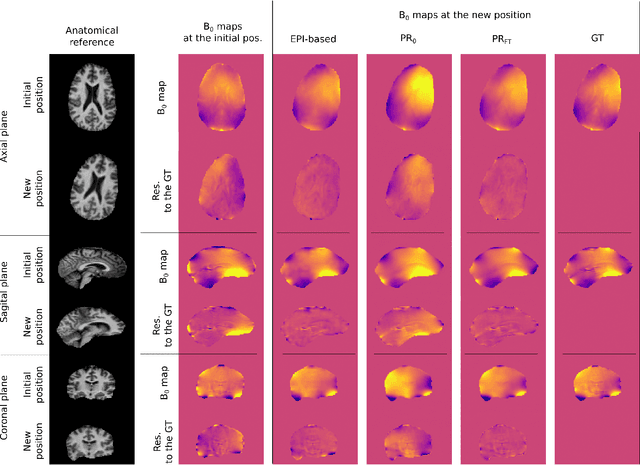
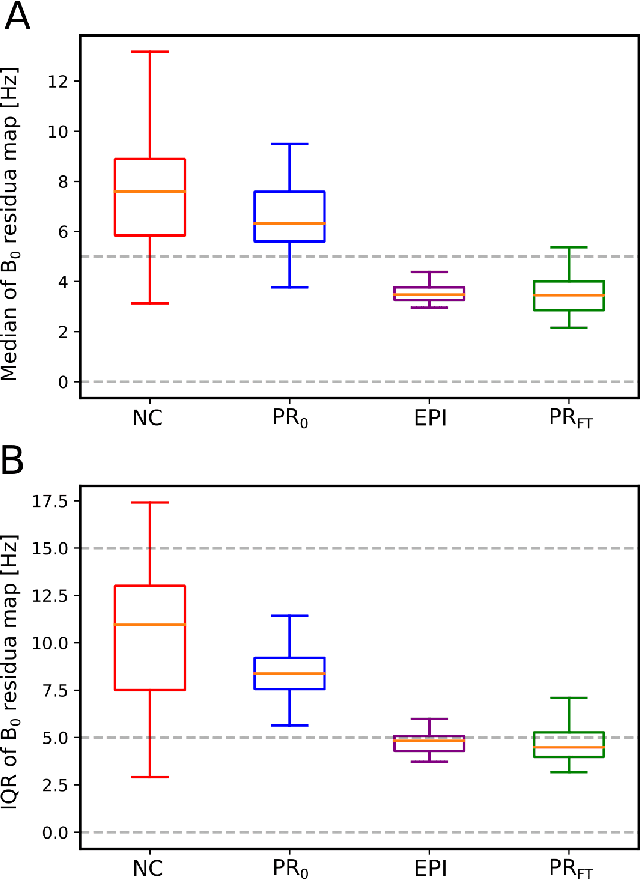
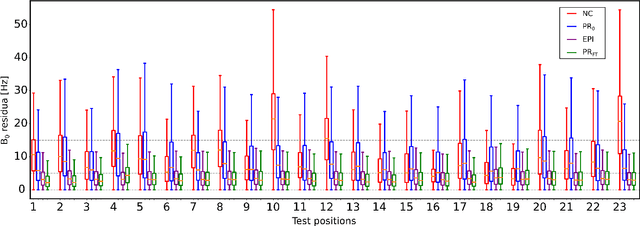
Subject movement during the magnetic resonance examination is inevitable and causes not only image artefacts but also deteriorates the homogeneity of the main magnetic field (B0), which is a prerequisite for high quality data. Thus, characterization of changes to B0, e.g. induced by patient movement, is important for MR applications that are prone to B0 inhomogeneities. We propose a deep learning based method to predict such changes within the brain from the change of the head position to facilitate retrospective or even real-time correction. A 3D U-net was trained on in vivo brain 7T MRI data. The input consisted of B0 maps and anatomical images at an initial position, and anatomical images at a different head position (obtained by applying a rigid-body transformation on the initial anatomical image). The output consisted of B0 maps at the new head positions. We further fine-tuned the network weights to each subject by measuring a limited number of head positions of the given subject, and trained the U-net with these data. Our approach was compared to established dynamic B0 field mapping via interleaved navigators, which suffer from limited spatial resolution and the need for undesirable sequence modifications. Qualitative and quantitative comparison showed similar performance between an interleaved navigator-equivalent method and proposed method. We therefore conclude that it is feasible to predict B0 maps from rigid subject movement and, when combined with external tracking hardware, this information could be used to improve the quality of magnetic resonance acquisitions without the use of navigators.
Bistatic CRLBs for TTD array resource allocation during JCAS
Mar 27, 2023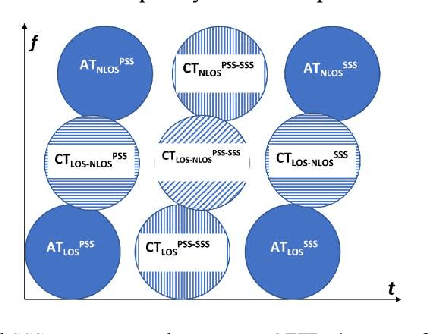
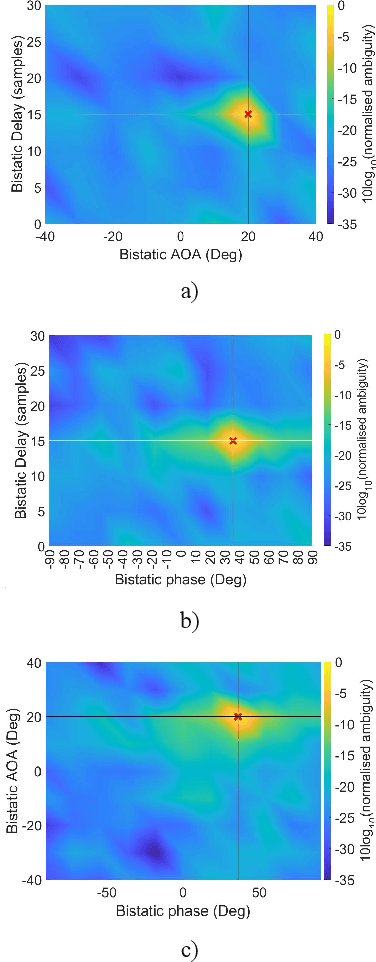
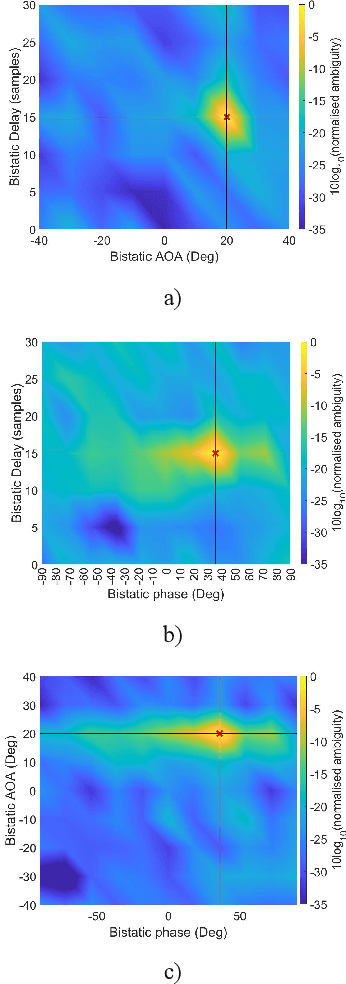
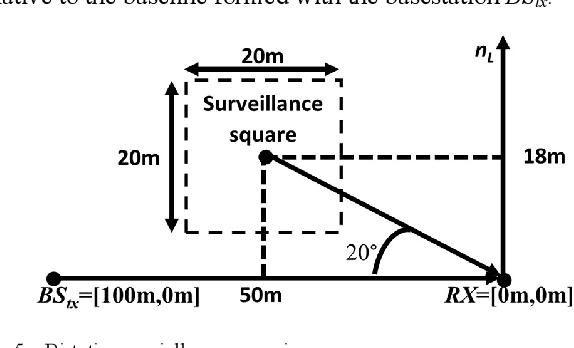
This paper conveys the theoretical sensing capability of a Joint Communication and Sensing (JCAS) system that utilizes a True-Time-Delay (TTD) array configuration. The TTD beamformer separates subcarrier beams into different angular locations for wide-beam coverage. The bistatic sensing performance of a TTD array configuration is modeled as a function of the number of array elements and the fractional power supplied by the transmitter. The sensing capability when employing a TTD array configuration is derived using the Cram\'er-Rao Lower Bound (CRLB) of a bistatic delay-AOA(Angle Of Arrival)-phase log-likelihood function which is obtained by cross-correlating complex eigenvectors extracted from the quadratic time-frequency domain representation of multicomponent phase-coded signals. The multicomponent phase-codes used here are synchronization signals that are defined by the 5G communications standard. The bistatic delay-AOA-phase estimation capability whilst utilizing these signals and a TTD configuration was seen to be highly non-linear with respect to the number of elements and fractional power supplied for the surveillance scenario shown; an allocation of 30 antenna elements supplied with maximum power made a sub-meter and sub-degree estimation capability theoretically possible.
Reducing Air Pollution through Machine Learning
Mar 22, 2023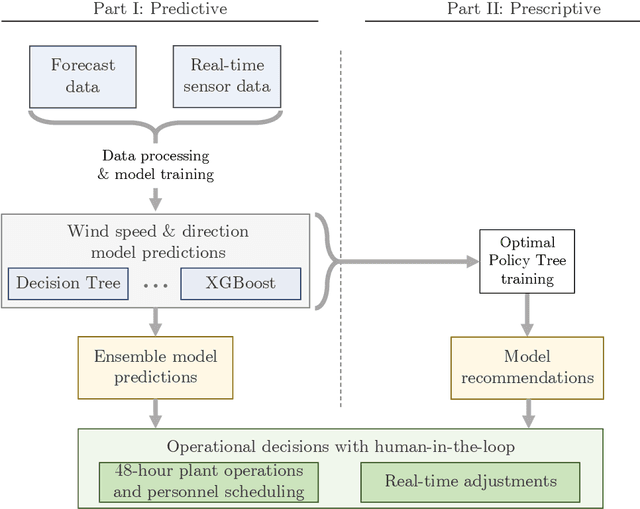


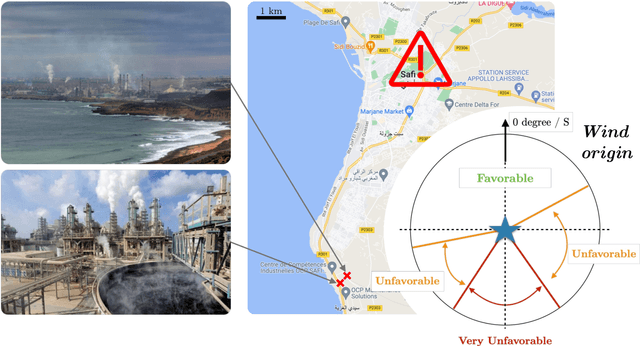
This paper presents a data-driven approach to mitigate the effects of air pollution from industrial plants on nearby cities by linking operational decisions with weather conditions. Our method combines predictive and prescriptive machine learning models to forecast short-term wind speed and direction and recommend operational decisions to reduce or pause the industrial plant's production. We exhibit several trade-offs between reducing environmental impact and maintaining production activities. The predictive component of our framework employs various machine learning models, such as gradient-boosted tree-based models and ensemble methods, for time series forecasting. The prescriptive component utilizes interpretable optimal policy trees to propose multiple trade-offs, such as reducing dangerous emissions by 33-47% and unnecessary costs by 40-63%. Our deployed models significantly reduced forecasting errors, with a range of 38-52% for less than 12-hour lead time and 14-46% for 12 to 48-hour lead time compared to official weather forecasts. We have successfully implemented the predictive component at the OCP Safi site, which is Morocco's largest chemical industrial plant, and are currently in the process of deploying the prescriptive component. Our framework enables sustainable industrial development by eliminating the pollution-industrial activity trade-off through data-driven weather-based operational decisions, significantly enhancing factory optimization and sustainability. This modernizes factory planning and resource allocation while maintaining environmental compliance. The predictive component has boosted production efficiency, leading to cost savings and reduced environmental impact by minimizing air pollution.
Discovering ordinary differential equations that govern time-series
Nov 05, 2022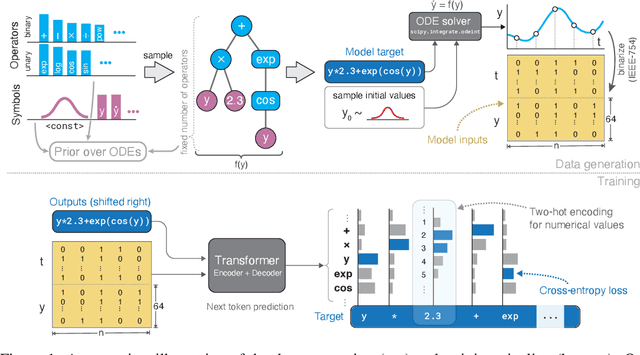
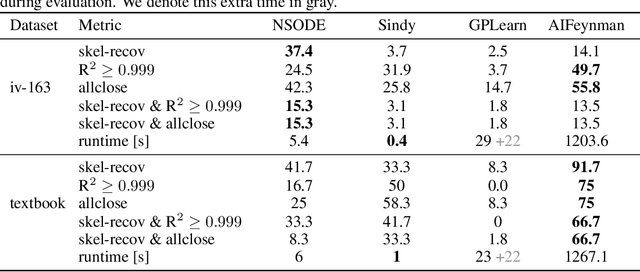
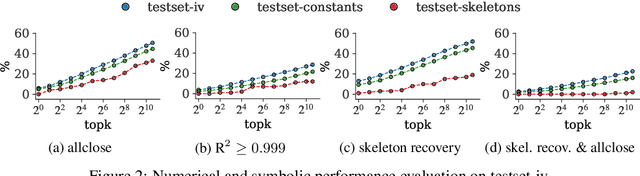
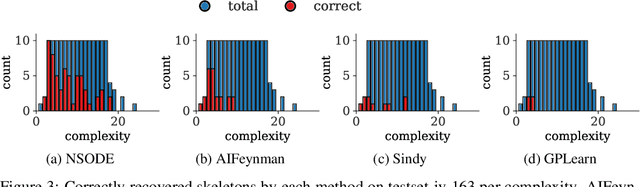
Natural laws are often described through differential equations yet finding a differential equation that describes the governing law underlying observed data is a challenging and still mostly manual task. In this paper we make a step towards the automation of this process: we propose a transformer-based sequence-to-sequence model that recovers scalar autonomous ordinary differential equations (ODEs) in symbolic form from time-series data of a single observed solution of the ODE. Our method is efficiently scalable: after one-time pretraining on a large set of ODEs, we can infer the governing laws of a new observed solution in a few forward passes of the model. Then we show that our model performs better or on par with existing methods in various test cases in terms of accurate symbolic recovery of the ODE, especially for more complex expressions.