 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
STAS: Spatial-Temporal Return Decomposition for Multi-agent Reinforcement Learning
Apr 15, 2023
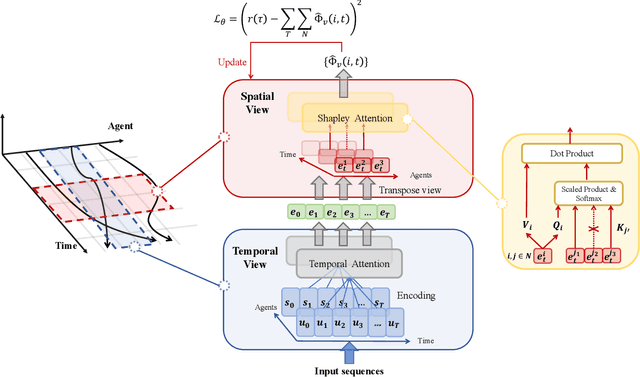
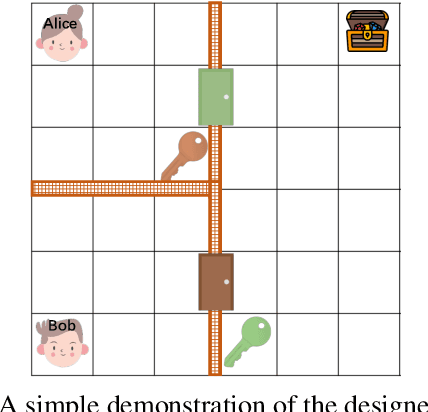
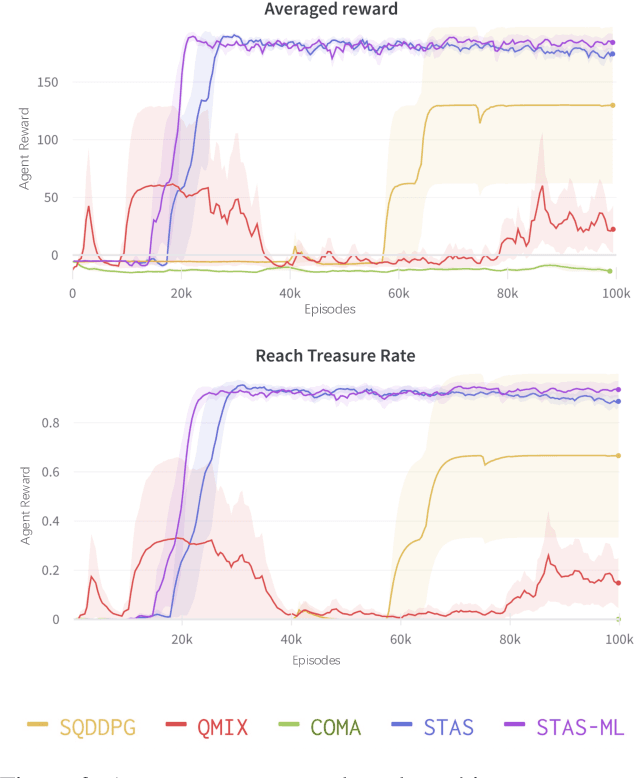
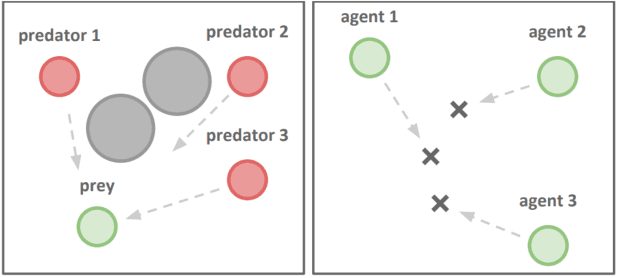
Centralized Training with Decentralized Execution (CTDE) has been proven to be an effective paradigm in cooperative multi-agent reinforcement learning (MARL). One of the major challenges is yet credit assignment, which aims to credit agents by their contributions. Prior studies focus on either implicitly decomposing the joint value function or explicitly computing the payoff distribution of all agents. However, in episodic reinforcement learning settings where global rewards can only be revealed at the end of the episode, existing methods usually fail to work. They lack the functionality of modeling complicated relations of the delayed global reward in the temporal dimension and suffer from large variance and bias. We propose a novel method named Spatial-Temporal Attention with Shapley (STAS) for return decomposition; STAS learns credit assignment in both the temporal and the spatial dimension. It first decomposes the global return back to each time step, then utilizes Shapley Value to redistribute the individual payoff from the decomposed global reward. To mitigate the computational complexity of Shapley Value, we introduce an approximation of marginal contribution and utilize Monte Carlo sampling to estimate Shapley Value. We evaluate our method on the classical Alice & Bob example and Multi-agent Particle Environments benchmarks across different scenarios, and we show our methods achieve an effective spatial-temporal credit assignment and outperform all state-of-art baselines.
Online Binaural Speech Separation of Moving Speakers With a Wavesplit Network
Mar 13, 2023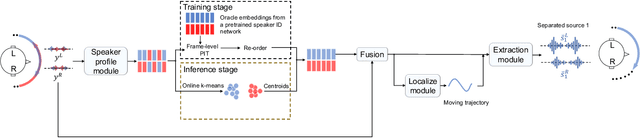
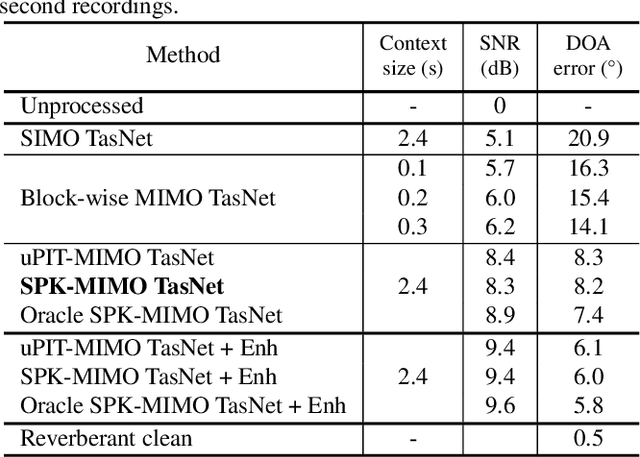
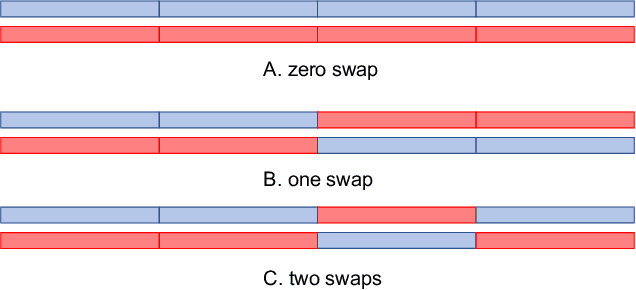
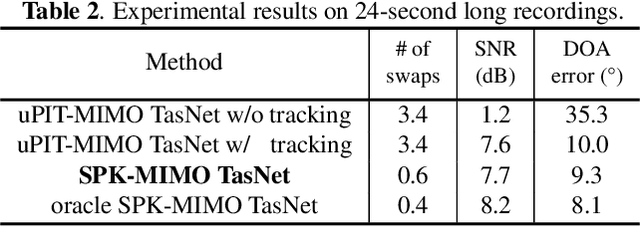
Binaural speech separation in real-world scenarios often involves moving speakers. Most current speech separation methods use utterance-level permutation invariant training (u-PIT) for training. In inference time, however, the order of outputs can be inconsistent over time particularly in long-form speech separation. This situation which is referred to as the speaker swap problem is even more problematic when speakers constantly move in space and therefore poses a challenge for consistent placement of speakers in output channels. Here, we describe a real-time binaural speech separation model based on a Wavesplit network to mitigate the speaker swap problem for moving speaker separation. Our model computes a speaker embedding for each speaker at each time frame from the mixed audio, aggregates embeddings using online clustering, and uses cluster centroids as speaker profiles to track each speaker throughout the long duration. Experimental results on reverberant, long-form moving multitalker speech separation show that the proposed method is less prone to speaker swap and achieves comparable performance with u-PIT based models with ground truth tracking in both separation accuracy and preserving the interaural cues.
CLVOS23: A Long Video Object Segmentation Dataset for Continual Learning
Apr 09, 2023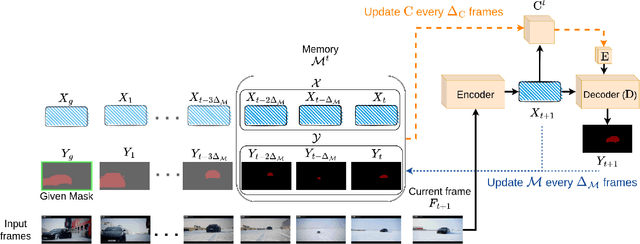
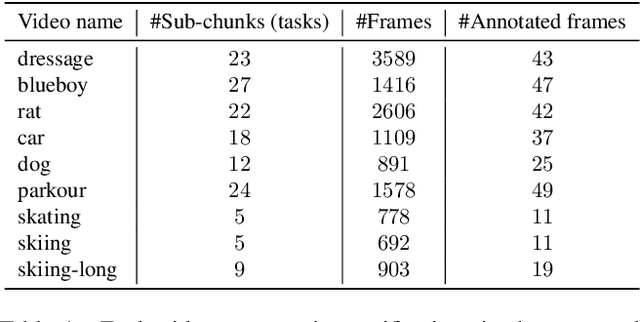


Continual learning in real-world scenarios is a major challenge. A general continual learning model should have a constant memory size and no predefined task boundaries, as is the case in semi-supervised Video Object Segmentation (VOS), where continual learning challenges particularly present themselves in working on long video sequences. In this article, we first formulate the problem of semi-supervised VOS, specifically online VOS, as a continual learning problem, and then secondly provide a public VOS dataset, CLVOS23, focusing on continual learning. Finally, we propose and implement a regularization-based continual learning approach on LWL, an existing online VOS baseline, to demonstrate the efficacy of continual learning when applied to online VOS and to establish a CLVOS23 baseline. We apply the proposed baseline to the Long Videos dataset as well as to two short video VOS datasets, DAVIS16 and DAVIS17. To the best of our knowledge, this is the first time that VOS has been defined and addressed as a continual learning problem.
Class-Specific Explainability for Deep Time Series Classifiers
Oct 11, 2022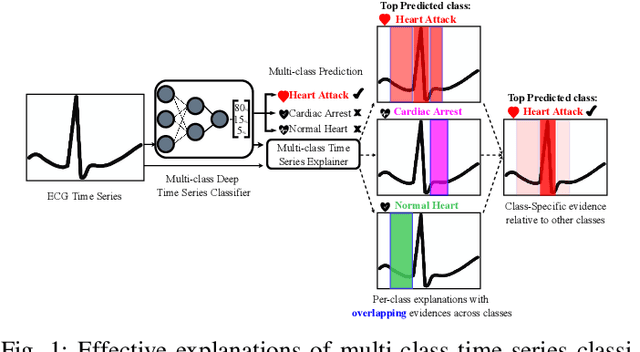
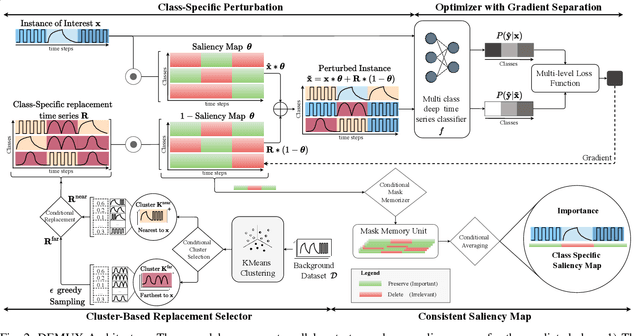

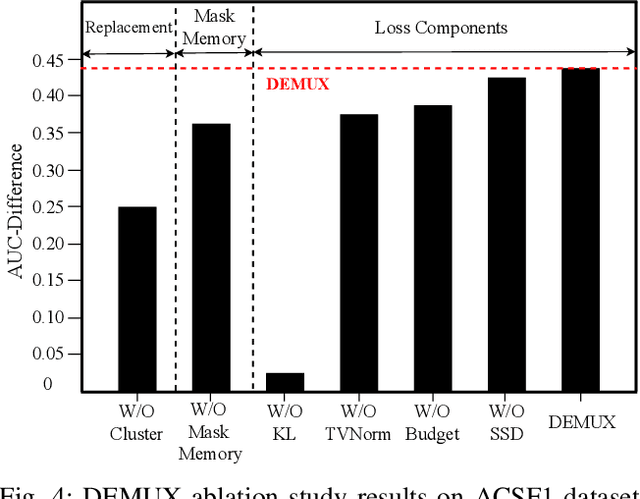
Explainability helps users trust deep learning solutions for time series classification. However, existing explainability methods for multi-class time series classifiers focus on one class at a time, ignoring relationships between the classes. Instead, when a classifier is choosing between many classes, an effective explanation must show what sets the chosen class apart from the rest. We now formalize this notion, studying the open problem of class-specific explainability for deep time series classifiers, a challenging and impactful problem setting. We design a novel explainability method, DEMUX, which learns saliency maps for explaining deep multi-class time series classifiers by adaptively ensuring that its explanation spotlights the regions in an input time series that a model uses specifically to its predicted class. DEMUX adopts a gradient-based approach composed of three interdependent modules that combine to generate consistent, class-specific saliency maps that remain faithful to the classifier's behavior yet are easily understood by end users. Our experimental study demonstrates that DEMUX outperforms nine state-of-the-art alternatives on five popular datasets when explaining two types of deep time series classifiers. Further, through a case study, we demonstrate that DEMUX's explanations indeed highlight what separates the predicted class from the others in the eyes of the classifier. Our code is publicly available at https://github.com/rameshdoddaiah/DEMUX.
TPMCF: Temporal QoS Prediction using Multi-Source Collaborative Features
Mar 30, 2023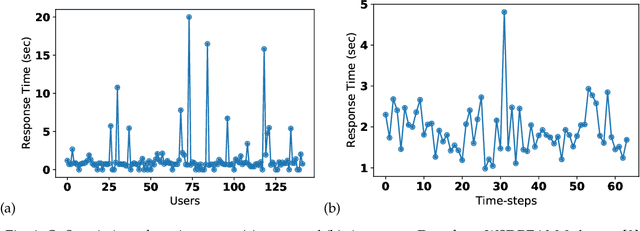
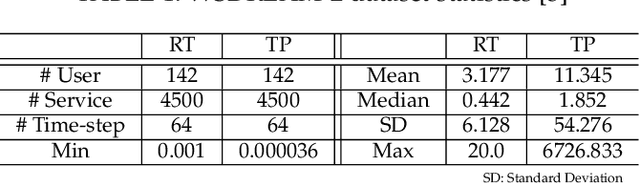
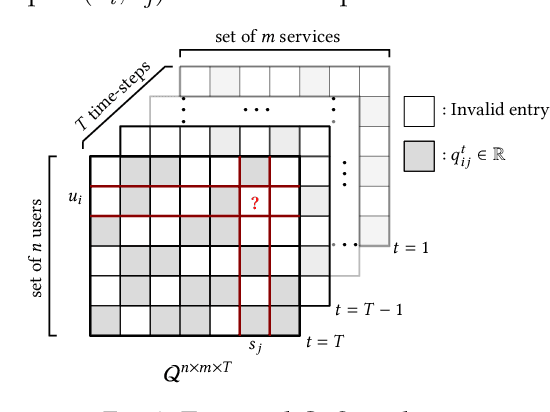
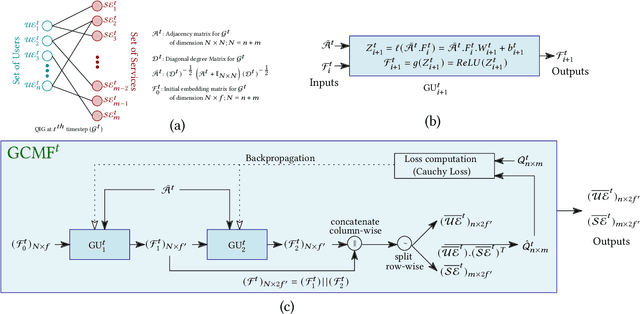
Recently, with the rapid deployment of service APIs, personalized service recommendations have played a paramount role in the growth of the e-commerce industry. Quality-of-Service (QoS) parameters determining the service performance, often used for recommendation, fluctuate over time. Thus, the QoS prediction is essential to identify a suitable service among functionally equivalent services over time. The contemporary temporal QoS prediction methods hardly achieved the desired accuracy due to various limitations, such as the inability to handle data sparsity and outliers and capture higher-order temporal relationships among user-service interactions. Even though some recent recurrent neural-network-based architectures can model temporal relationships among QoS data, prediction accuracy degrades due to the absence of other features (e.g., collaborative features) to comprehend the relationship among the user-service interactions. This paper addresses the above challenges and proposes a scalable strategy for Temporal QoS Prediction using Multi-source Collaborative-Features (TPMCF), achieving high prediction accuracy and faster responsiveness. TPMCF combines the collaborative-features of users/services by exploiting user-service relationship with the spatio-temporal auto-extracted features by employing graph convolution and transformer encoder with multi-head self-attention. We validated our proposed method on WS-DREAM-2 datasets. Extensive experiments showed TPMCF outperformed major state-of-the-art approaches regarding prediction accuracy while ensuring high scalability and reasonably faster responsiveness.
H2CGL: Modeling Dynamics of Citation Network for Impact Prediction
Apr 16, 2023
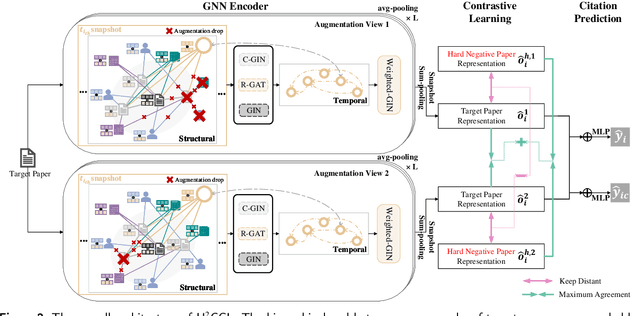

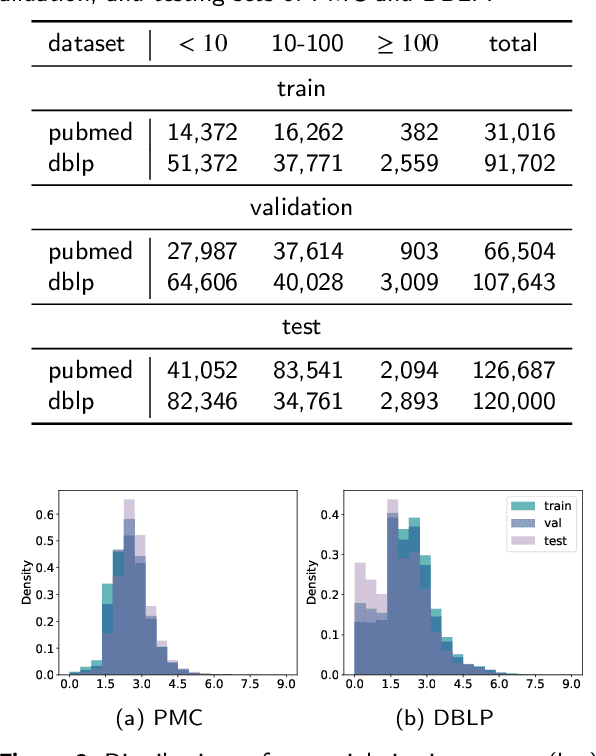
The potential impact of a paper is often quantified by how many citations it will receive. However, most commonly used models may underestimate the influence of newly published papers over time, and fail to encapsulate this dynamics of citation network into the graph. In this study, we construct hierarchical and heterogeneous graphs for target papers with an annual perspective. The constructed graphs can record the annual dynamics of target papers' scientific context information. Then, a novel graph neural network, Hierarchical and Heterogeneous Contrastive Graph Learning Model (H2CGL), is proposed to incorporate heterogeneity and dynamics of the citation network. H2CGL separately aggregates the heterogeneous information for each year and prioritizes the highly-cited papers and relationships among references, citations, and the target paper. It then employs a weighted GIN to capture dynamics between heterogeneous subgraphs over years. Moreover, it leverages contrastive learning to make the graph representations more sensitive to potential citations. Particularly, co-cited or co-citing papers of the target paper with large citation gap are taken as hard negative samples, while randomly dropping low-cited papers could generate positive samples. Extensive experimental results on two scholarly datasets demonstrate that the proposed H2CGL significantly outperforms a series of baseline approaches for both previously and freshly published papers. Additional analyses highlight the significance of the proposed modules. Our codes and settings have been released on Github (https://github.com/ECNU-Text-Computing/H2CGL)
Exploring the Use of ChatGPT as a Tool for Learning and Assessment in Undergraduate Computer Science Curriculum: Opportunities and Challenges
Apr 16, 2023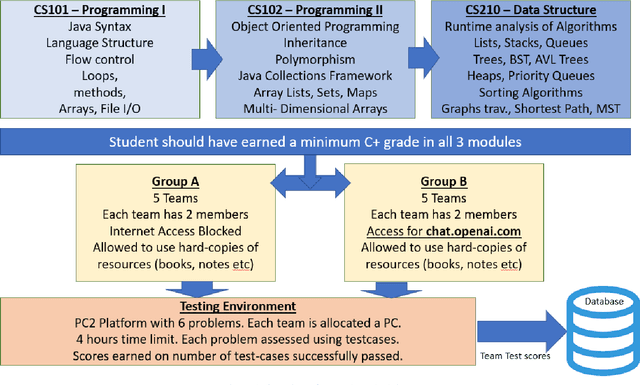
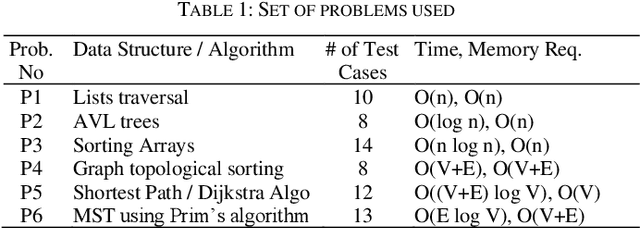
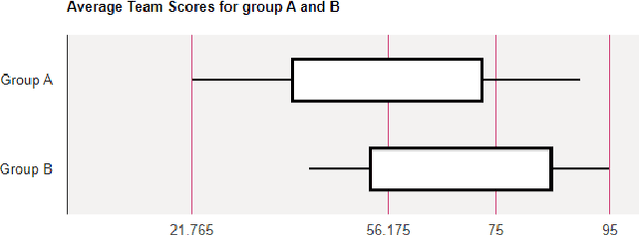
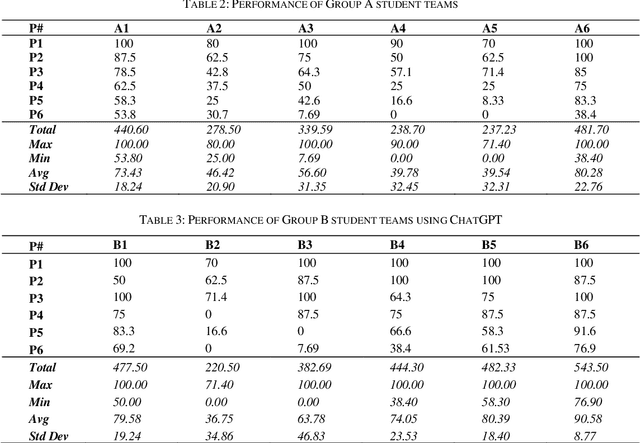
The application of Artificial intelligence for teaching and learning in the academic sphere is a trending subject of interest in the computing education. ChatGPT, as an AI-based tool, provides various advantages, such as heightened student involvement, cooperation, accessibility and availability. This paper addresses the prospects and obstacles associated with utilizing ChatGPT as a tool for learning and assessment in undergraduate Computer Science curriculum in particular to teaching and learning fundamental programming courses. Students having completed the course work for a Data Structures and Algorithms (a sophomore level course) participated in this study. Two groups of students were given programming challenges to solve within a short period of time. The control group (group A) had access to text books and notes of programming courses, however no Internet access was provided. Group B students were given access to ChatGPT and were encouraged to use it to help solve the programming challenges. The challenge was conducted in a computer lab environment using PC2 environment. Each team of students address the problem by writing executable code that satisfies certain number of test cases. Student teams were scored based on their performance in terms of number of successful passed testcases. Results show that students using ChatGPT had an advantage in terms of earned scores, however there were inconsistencies and inaccuracies in the submitted code consequently affecting the overall performance. After a thorough analysis, the paper's findings indicate that incorporating AI in higher education brings about various opportunities and challenges.
Deep learning universal crater detection using Segment Anything Model (SAM)
Apr 16, 2023
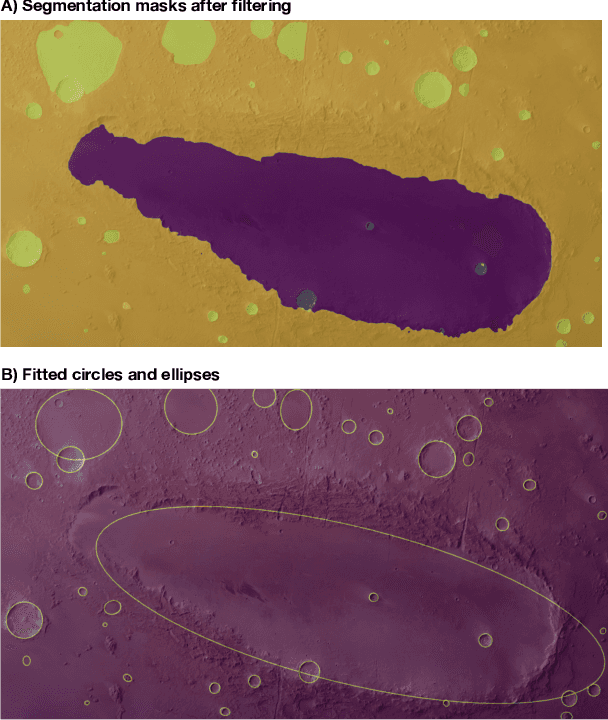


Craters are amongst the most important morphological features in planetary exploration. To that extent, detecting, mapping and counting craters is a mainstream process in planetary science, done primarily manually, which is a very laborious and time-consuming process. Recently, machine learning (ML) and computer vision have been successfully applied for both detecting craters and estimating their size. Existing ML approaches for automated crater detection have been trained in specific types of data e.g. digital elevation model (DEM), images and associated metadata for orbiters such as the Lunar Reconnaissance Orbiter Camera (LROC) etc.. Due to that, each of the resulting ML schemes is applicable and reliable only to the type of data used during the training process. Data from different sources, angles and setups can compromise the reliability of these ML schemes. In this paper we present a universal crater detection scheme that is based on the recently proposed Segment Anything Model (SAM) from META AI. SAM is a prompt-able segmentation system with zero-shot generalization to unfamiliar objects and images without the need for additional training. Using SAM we can successfully identify crater-looking objects in any type of data (e,g, raw satellite images Level-1 and 2 products, DEMs etc.) for different setups (e.g. Lunar, Mars) and different capturing angles. Moreover, using shape indexes, we only keep the segmentation masks of crater-like features. These masks are subsequently fitted with an ellipse, recovering both the location and the size/geometry of the detected craters.
Payload Grasping and Transportation by a Quadrotor with a Hook-Based Manipulator
Apr 05, 2023

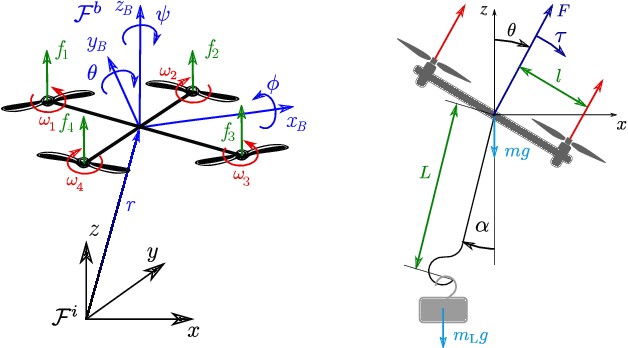

The paper proposes an efficient trajectory planning and control approach for payload grasping and transportation using an aerial manipulator. The proposed manipulator structure consists of a hook attached to a quadrotor using a 1 DoF revolute joint. To perform payload grasping, transportation, and release, first, time-optimal reference trajectories are designed through specific waypoints to ensure the fast and reliable execution of the tasks. Then, a two-stage motion control approach is developed based on a robust geometric controller for precise and reliable reference tracking and a linear--quadratic payload regulator for rapid setpoint stabilization of the payload swing. The proposed control architecture and design are evaluated in a high-fidelity physical simulator with external disturbances and also in real flight experiments.
Adaptive Human Matting for Dynamic Videos
Apr 12, 2023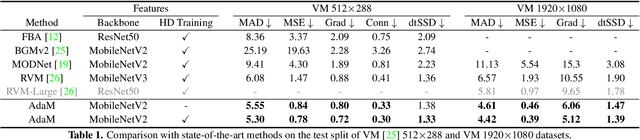

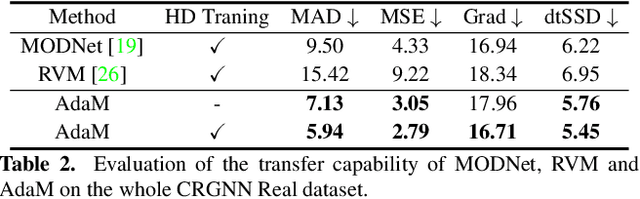
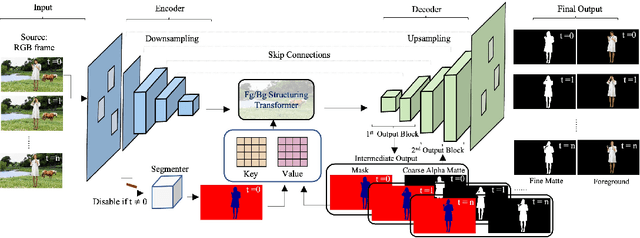
The most recent efforts in video matting have focused on eliminating trimap dependency since trimap annotations are expensive and trimap-based methods are less adaptable for real-time applications. Despite the latest tripmap-free methods showing promising results, their performance often degrades when dealing with highly diverse and unstructured videos. We address this limitation by introducing Adaptive Matting for Dynamic Videos, termed AdaM, which is a framework designed for simultaneously differentiating foregrounds from backgrounds and capturing alpha matte details of human subjects in the foreground. Two interconnected network designs are employed to achieve this goal: (1) an encoder-decoder network that produces alpha mattes and intermediate masks which are used to guide the transformer in adaptively decoding foregrounds and backgrounds, and (2) a transformer network in which long- and short-term attention combine to retain spatial and temporal contexts, facilitating the decoding of foreground details. We benchmark and study our methods on recently introduced datasets, showing that our model notably improves matting realism and temporal coherence in complex real-world videos and achieves new best-in-class generalizability. Further details and examples are available at https://github.com/microsoft/AdaM.