 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modelling black-box audio effects with time-varying feature modulation
Nov 01, 2022
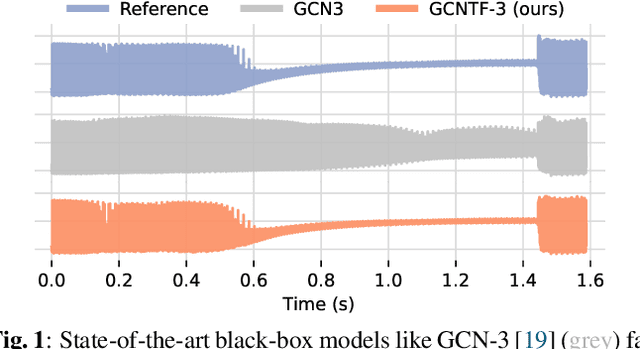
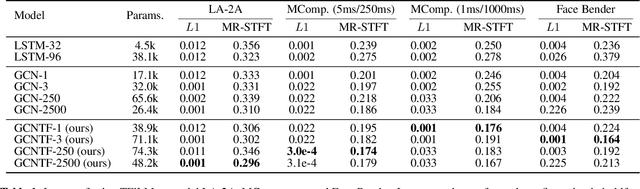
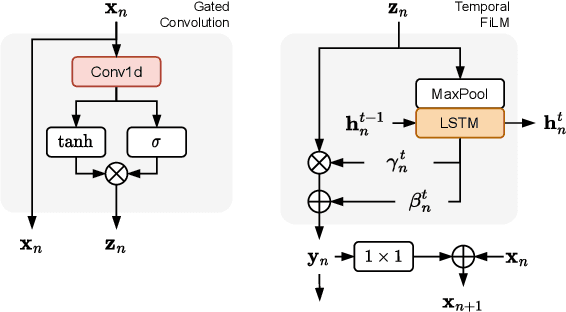
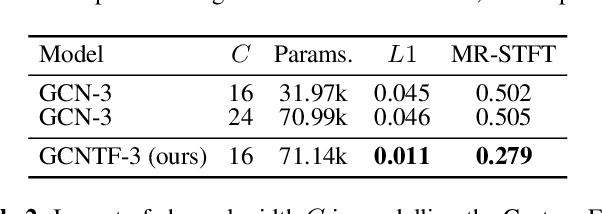
Deep learning approaches for black-box modelling of audio effects have shown promise, however, the majority of existing work focuses on nonlinear effects with behaviour on relatively short time-scales, such as guitar amplifiers and distortion. While recurrent and convolutional architectures can theoretically be extended to capture behaviour at longer time scales, we show that simply scaling the width, depth, or dilation factor of existing architectures does not result in satisfactory performance when modelling audio effects such as fuzz and dynamic range compression. To address this, we propose the integration of time-varying feature-wise linear modulation into existing temporal convolutional backbones, an approach that enables learnable adaptation of the intermediate activations. We demonstrate that our approach more accurately captures long-range dependencies for a range of fuzz and compressor implementations across both time and frequency domain metrics. We provide sound examples, source code, and pretrained models to faciliate reproducibility.
Contingency Games for Multi-Agent Interaction
Apr 14, 2023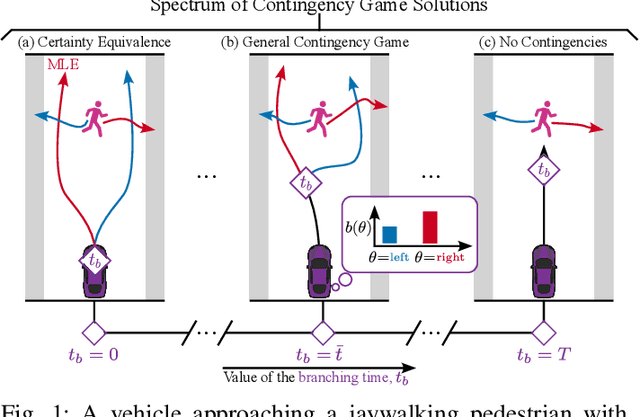
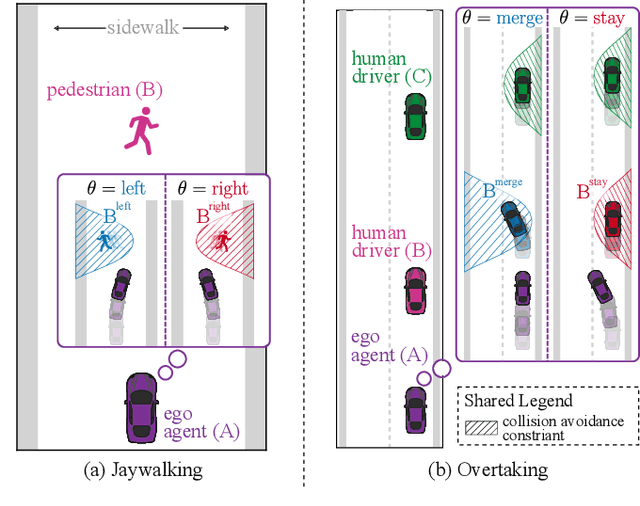
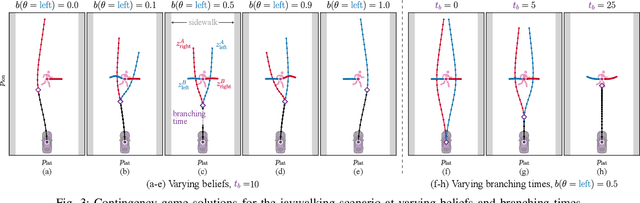
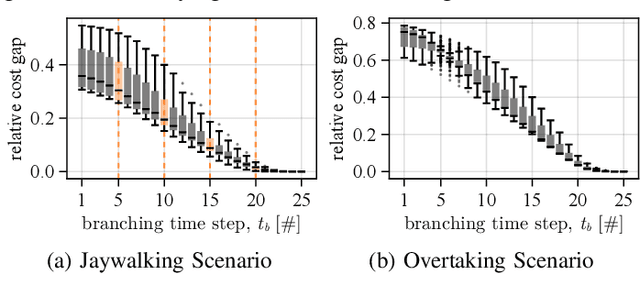
Contingency planning, wherein an agent generates a set of possible plans conditioned on the outcome of an uncertain event, is an increasingly popular way for robots to act under uncertainty. In this work, we take a game-theoretic perspective on contingency planning which is tailored to multi-agent scenarios in which a robot's actions impact the decisions of other agents and vice versa. The resulting contingency game allows the robot to efficiently coordinate with other agents by generating strategic motion plans conditioned on multiple possible intents for other actors in the scene. Contingency games are parameterized via a scalar variable which represents a future time at which intent uncertainty will be resolved. Varying this parameter enables a designer to easily adjust how conservatively the robot behaves in the game. Interestingly, we also find that existing variants of game-theoretic planning under uncertainty are readily obtained as special cases of contingency games. Lastly, we offer an efficient method for solving N-player contingency games with nonlinear dynamics and non-convex costs and constraints. Through a series of simulated autonomous driving scenarios, we demonstrate that plans generated via contingency games provide quantitative performance gains over game-theoretic motion plans that do not account for future uncertainty reduction.
Grouping Shapley Value Feature Importances of Random Forests for explainable Yield Prediction
Apr 14, 2023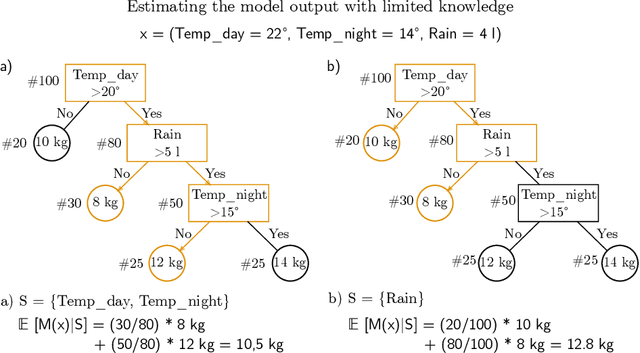
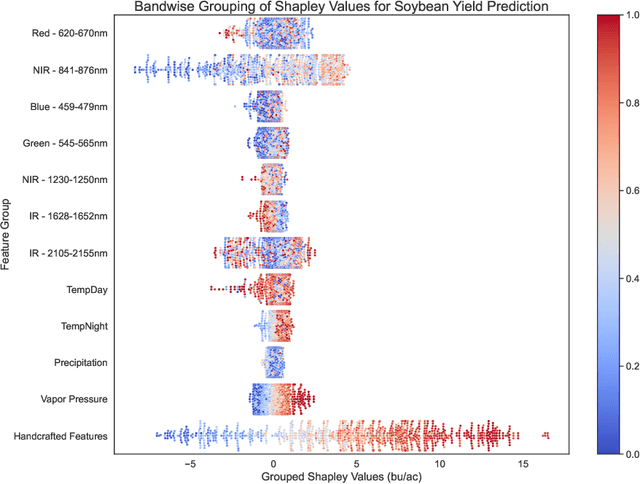
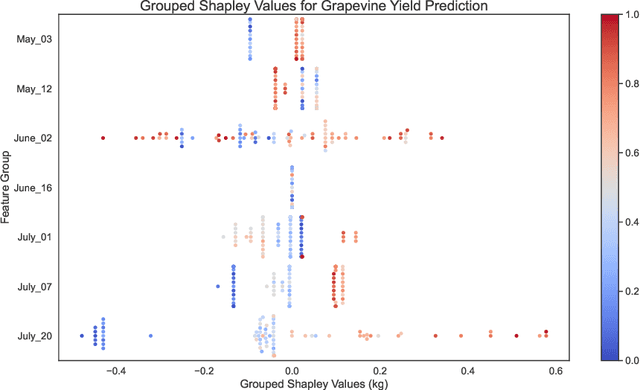
Explainability in yield prediction helps us fully explore the potential of machine learning models that are already able to achieve high accuracy for a variety of yield prediction scenarios. The data included for the prediction of yields are intricate and the models are often difficult to understand. However, understanding the models can be simplified by using natural groupings of the input features. Grouping can be achieved, for example, by the time the features are captured or by the sensor used to do so. The state-of-the-art for interpreting machine learning models is currently defined by the game-theoretic approach of Shapley values. To handle groups of features, the calculated Shapley values are typically added together, ignoring the theoretical limitations of this approach. We explain the concept of Shapley values directly computed for predefined groups of features and introduce an algorithm to compute them efficiently on tree structures. We provide a blueprint for designing swarm plots that combine many local explanations for global understanding. Extensive evaluation of two different yield prediction problems shows the worth of our approach and demonstrates how we can enable a better understanding of yield prediction models in the future, ultimately leading to mutual enrichment of research and application.
Collaborative Ground-Aerial Multi-Robot System for Disaster Response Missions with a Low-Cost Drone Add-On for Off-the-Shelf Drones
Apr 14, 2023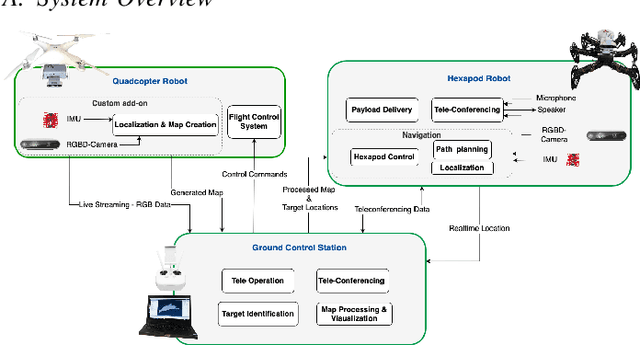


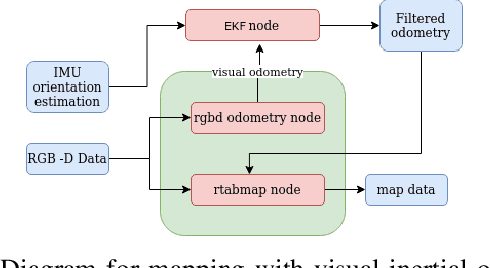
In disaster-stricken environments, it's vital to assess the damage quickly, analyse the stability of the environment, and allocate resources to the most vulnerable areas where victims might be present. These missions are difficult and dangerous to be conducted directly by humans. Using the complementary capabilities of both the ground and aerial robots, we investigate a collaborative approach of aerial and ground robots to address this problem. With an increased field of view, faster speed, and compact size, the aerial robot explores the area and creates a 3D feature-based map graph of the environment while providing a live video stream to the ground control station. Once the aerial robot finishes the exploration run, the ground control station processes the map and sends it to the ground robot. The ground robot, with its higher operation time, static stability, payload delivery and tele-conference capabilities, can then autonomously navigate to identified high-vulnerability locations. We have conducted experiments using a quadcopter and a hexapod robot in an indoor modelled environment with obstacles and uneven ground. Additionally, we have developed a low-cost drone add-on with value-added capabilities, such as victim detection, that can be attached to an off-the-shelf drone. The system was assessed for cost-effectiveness, energy efficiency, and scalability.
Novel features for the detection of bearing faults in railway vehicles
Apr 14, 2023
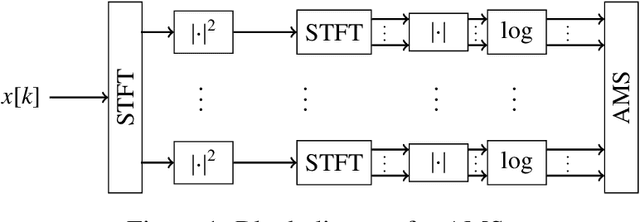

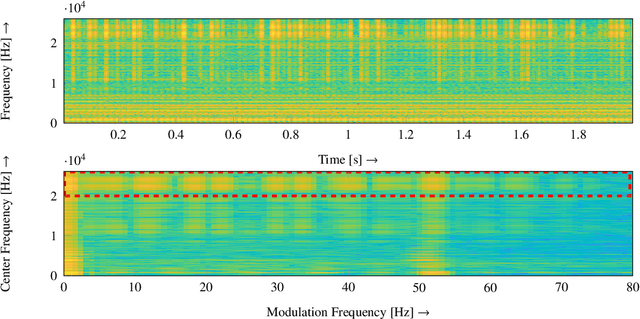
{In this paper, we address the challenging problem of detecting bearing faults from vibration signals. For this, several time- and frequency-domain features have been proposed already in the past. However, these features are usually evaluated on data originating from relatively simple scenarios and a significant performance loss can be observed if more realistic scenarios are considered. To overcome this, we introduce Mel-Frequency Cepstral Coefficients (MFCCs) and features extracted from the Amplitude Modulation Spectrogram (AMS) as features for the detection of bearing faults. Both AMS and MFCCs were originally introduced in the context of audio signal processing but it is demonstrated that a significantly improved classification performance can be obtained by using these features. Furthermore, to tackle the characteristic data imbalance problem in the context of bearing fault detection, i.e., typically much more data from healthy bearings than from damaged bearings is available, we propose to train a One-class \ac{SVM} with data from healthy bearings only. Bearing faults are then classified by the detection of outliers. Our approach is evaluated with data measured in a highly challenging scenario comprising a state-of-the-art commuter railway engine which is supplied by an industrial power converter and coupled to a load machine.
Synergies Between Federated Learning and O-RAN: Towards an Elastic Virtualized Architecture for Multiple Distributed Machine Learning Services
Apr 14, 2023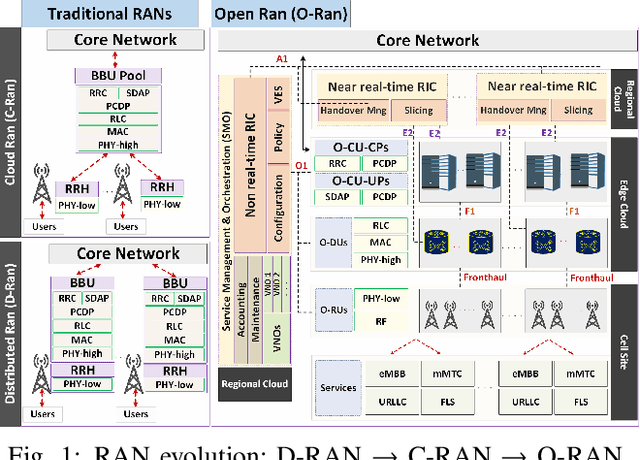
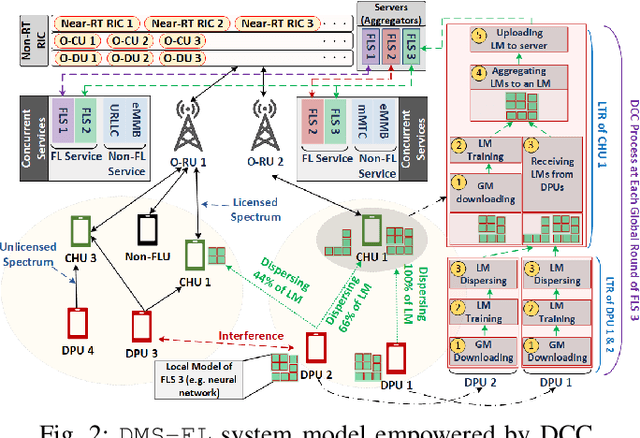
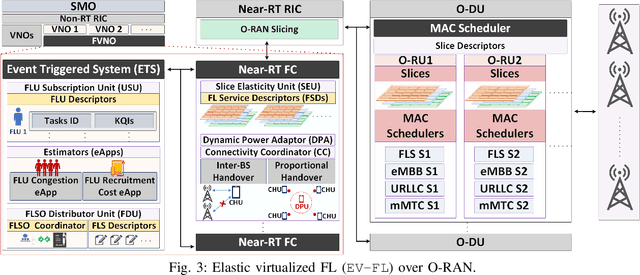
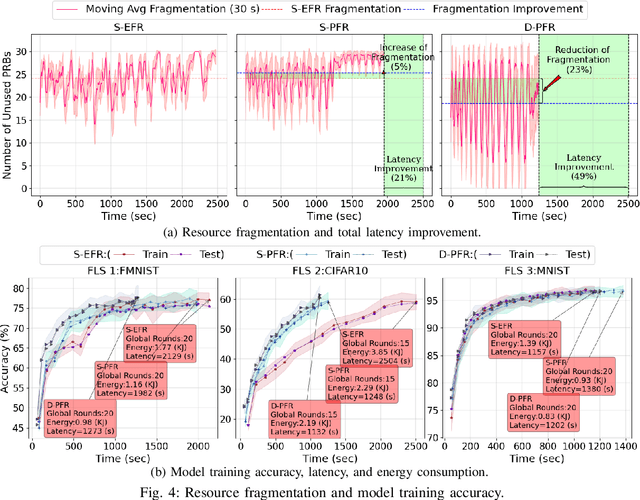
Federated learning (FL) is the most popular distributed machine learning technique. However, implementation of FL over modern wireless networks faces key challenges caused by (i) dynamics of the network conditions, (ii) coexistence of multiple FL services/tasks in the system, and (iii) concurrent execution of FL services with other network services, which are not jointly considered in prior works. Motivated by these challenges, we introduce a generic FL paradigm over next-generation (NextG) networks, called dynamic multi-service FL (DMS-FL). We identify three unexplored design considerations in DMS-FL: (i) FL service operator accumulation, (ii) wireless resource fragmentation, and (iii) signal strength fluctuations. We take the first steps towards addressing these design considerations through proposing a novel distributed ML architecture called elastic virtualized FL (EV-FL). EV-FL unleashes the full potential of Open RAN (O-RAN) systems and introduces an elastic resource provisioning methodology to execute FL services. It further constitutes a multi-time-scale FL management system that introduces three dimensions into existing FL architectures: (i) virtualization, (ii) scalability, and (iii) elasticity. Through investigating EV-FL, we reveal a series of open research directions for future work. We finally simulate EV-FL to demonstrate its potential to save wireless resources and increase fairness among FL services.
SmartBook: AI-Assisted Situation Report Generation
Mar 25, 2023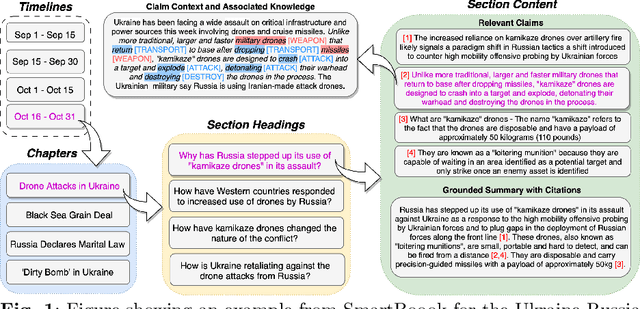
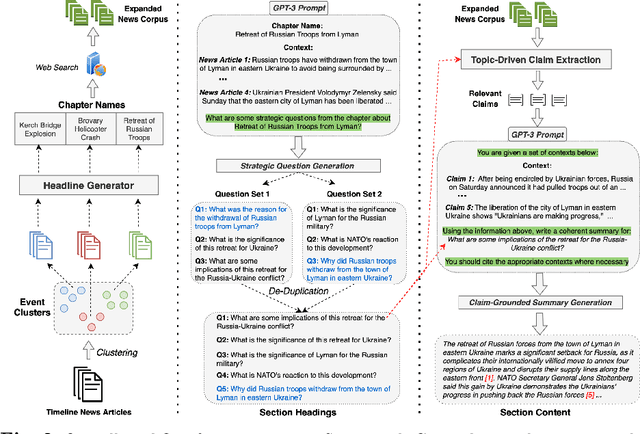


Emerging events, such as the COVID pandemic and the Ukraine Crisis, require a time-sensitive comprehensive understanding of the situation to allow for appropriate decision-making and effective action response. Automated generation of situation reports can significantly reduce the time, effort, and cost for domain experts when preparing their official human-curated reports. However, AI research toward this goal has been very limited, and no successful trials have yet been conducted to automate such report generation. We propose SmartBook, a novel task formulation targeting situation report generation, which consumes large volumes of news data to produce a structured situation report with multiple hypotheses (claims) summarized and grounded with rich links to factual evidence. We realize SmartBook for the Ukraine-Russia crisis by automatically generating intelligence analysis reports to assist expert analysts. The machine-generated reports are structured in the form of timelines, with each timeline organized by major events (or chapters), corresponding strategic questions (or sections) and their grounded summaries (or section content). Our proposed framework automatically detects real-time event-related strategic questions, which are more directed than manually-crafted analyst questions, which tend to be too complex, hard to parse, vague and high-level. Results from thorough qualitative evaluations show that roughly 82% of the questions in Smartbook have strategic importance, with at least 93% of the sections in the report being tactically useful. Further, experiments show that expert analysts tend to add more information into the SmartBook reports, with only 2.3% of the existing tokens being deleted, meaning SmartBook can serve as a useful foundation for analysts to build upon when creating intelligence reports.
Interaction-Aware Prompting for Zero-Shot Spatio-Temporal Action Detection
Apr 11, 2023
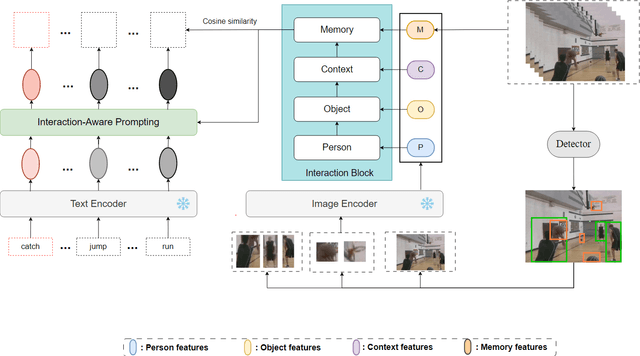

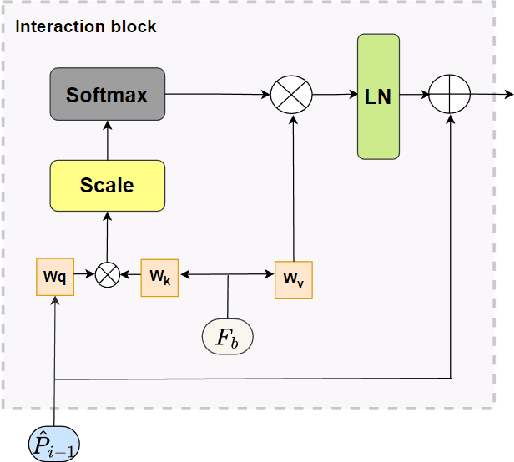
The goal of spatial-temporal action detection is to determine the time and place where each person's action occurs in a video and classify the corresponding action category. Most of the existing methods adopt fully-supervised learning, which requires a large amount of training data, making it very difficult to achieve zero-shot learning. In this paper, we propose to utilize a pre-trained visual-language model to extract the representative image and text features, and model the relationship between these features through different interaction modules to obtain the interaction feature. In addition, we use this feature to prompt each label to obtain more appropriate text features. Finally, we calculate the similarity between the interaction feature and the text feature for each label to determine the action category. Our experiments on J-HMDB and UCF101-24 datasets demonstrate that the proposed interaction module and prompting make the visual-language features better aligned, thus achieving excellent accuracy for zero-shot spatio-temporal action detection. The code will be released upon acceptance.
Benchmarking the Physical-world Adversarial Robustness of Vehicle Detection
Apr 11, 2023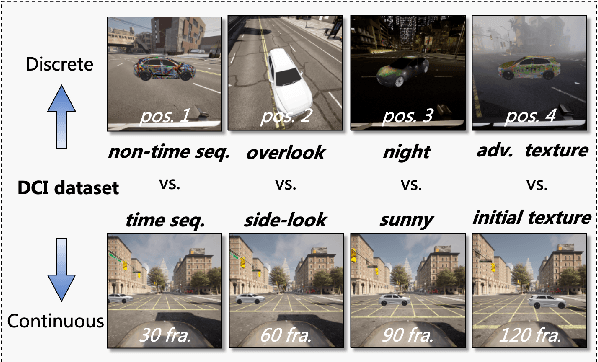
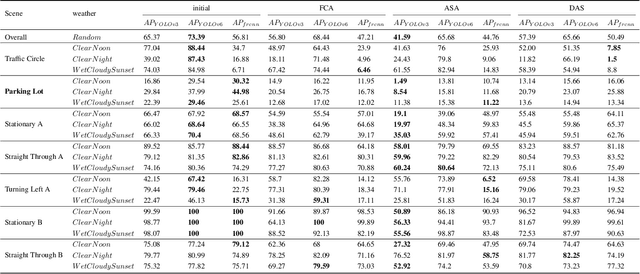
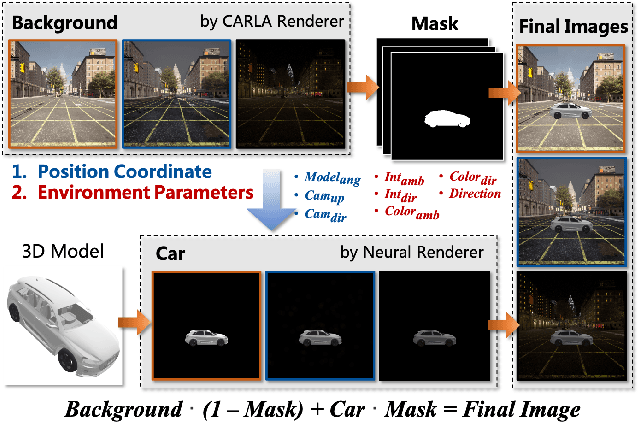
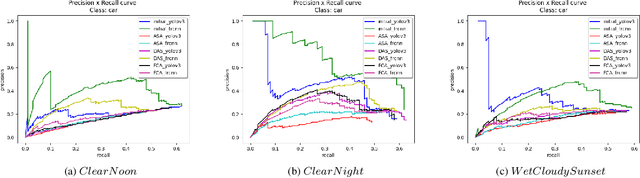
Adversarial attacks in the physical world can harm the robustness of detection models. Evaluating the robustness of detection models in the physical world can be challenging due to the time-consuming and labor-intensive nature of many experiments. Thus, virtual simulation experiments can provide a solution to this challenge. However, there is no unified detection benchmark based on virtual simulation environment. To address this challenge, we proposed an instant-level data generation pipeline based on the CARLA simulator. Using this pipeline, we generated the DCI dataset and conducted extensive experiments on three detection models and three physical adversarial attacks. The dataset covers 7 continuous and 1 discrete scenes, with over 40 angles, 20 distances, and 20,000 positions. The results indicate that Yolo v6 had strongest resistance, with only a 6.59% average AP drop, and ASA was the most effective attack algorithm with a 14.51% average AP reduction, twice that of other algorithms. Static scenes had higher recognition AP, and results under different weather conditions were similar. Adversarial attack algorithm improvement may be approaching its 'limitation'.
Simulation Analysis of Exploration Strategies and UAV Planning for Search and Rescue
Apr 11, 2023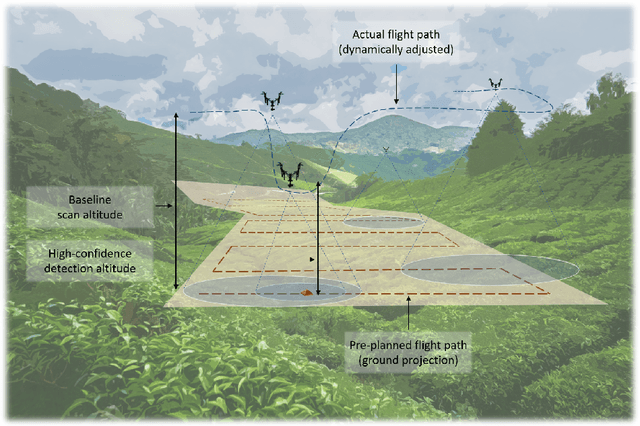



Aerial scans with unmanned aerial vehicles (UAVs) are becoming more widely adopted across industries, from smart farming to urban mapping. An application area that can leverage the strength of such systems is search and rescue (SAR) operations. However, with a vast variability in strategies and topology of application scenarios, as well as the difficulties in setting up real-world UAV-aided SAR operations for testing, designing an optimal flight pattern to search for and detect all victims can be a challenging problem. Specifically, the deployed UAV should be able to scan the area in the shortest amount of time while maintaining high victim detection recall rates. Therefore, low probability of false negatives (i.e., high recall) is more important than precision in this case. To address the issues mentioned above, we have developed a simulation environment that emulates different SAR scenarios and allows experimentation with flight missions to provide insight into their efficiency. The solution was developed with the open-source ROS framework and Gazebo simulator, with PX4 as the autopilot system for flight control, and YOLO as the object detector.