 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automated Time-frequency Domain Audio Crossfades using Graph Cuts
Jan 31, 2023
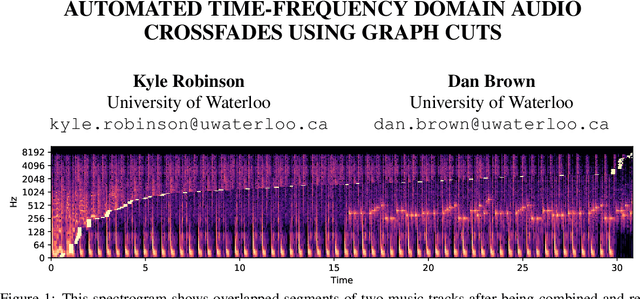
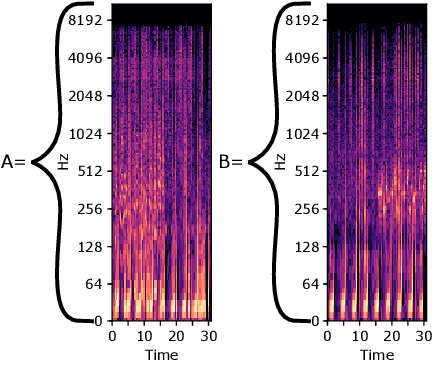
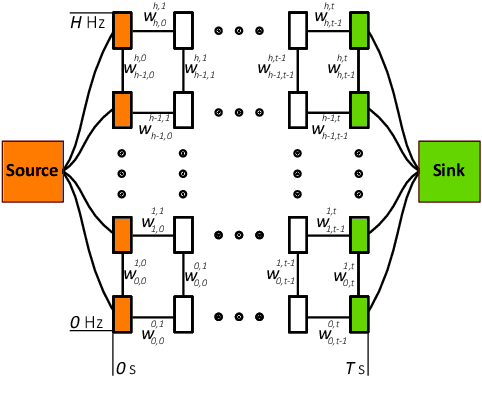
The problem of transitioning smoothly from one audio clip to another arises in many music consumption scenarios, especially as music consumption has moved from professionally curated and live-streamed radios to personal playback devices and services. we present the first steps toward a new method of automatically transitioning from one audio clip to another by discretizing the frequency spectrum into bins and then finding transition times for each bin. We phrase the problem as one of graph flow optimization; specifically min-cut/max-flow.
Multi PILOT: Learned Feasible Multiple Acquisition Trajectories for Dynamic MRI
Mar 23, 2023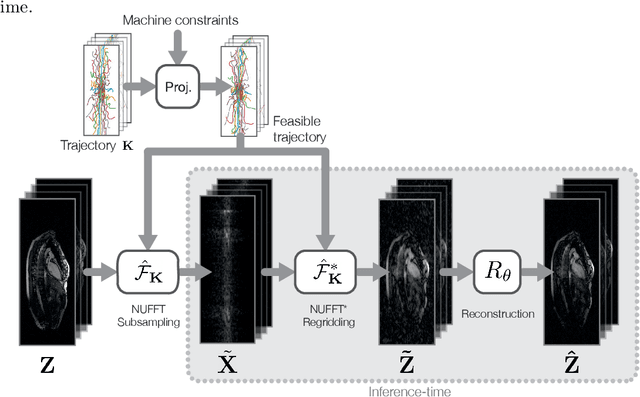
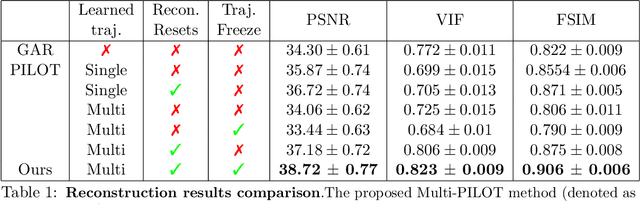
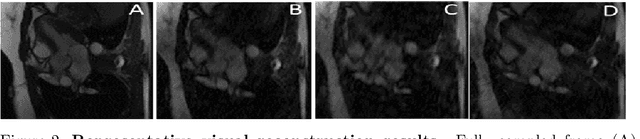
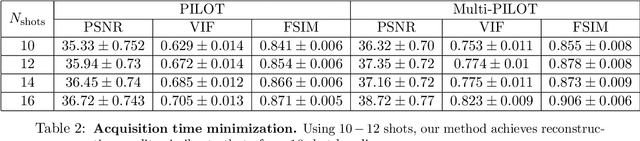
Dynamic Magnetic Resonance Imaging (MRI) is known to be a powerful and reliable technique for the dynamic imaging of internal organs and tissues, making it a leading diagnostic tool. A major difficulty in using MRI in this setting is the relatively long acquisition time (and, hence, increased cost) required for imaging in high spatio-temporal resolution, leading to the appearance of related motion artifacts and decrease in resolution. Compressed Sensing (CS) techniques have become a common tool to reduce MRI acquisition time by subsampling images in the k-space according to some acquisition trajectory. Several studies have particularly focused on applying deep learning techniques to learn these acquisition trajectories in order to attain better image reconstruction, rather than using some predefined set of trajectories. To the best of our knowledge, learning acquisition trajectories has been only explored in the context of static MRI. In this study, we consider acquisition trajectory learning in the dynamic imaging setting. We design an end-to-end pipeline for the joint optimization of multiple per-frame acquisition trajectories along with a reconstruction neural network, and demonstrate improved image reconstruction quality in shorter acquisition times. The code for reproducing all experiments is accessible at https://github.com/tamirshor7/MultiPILOT.
TriPlaneNet: An Encoder for EG3D Inversion
Mar 23, 2023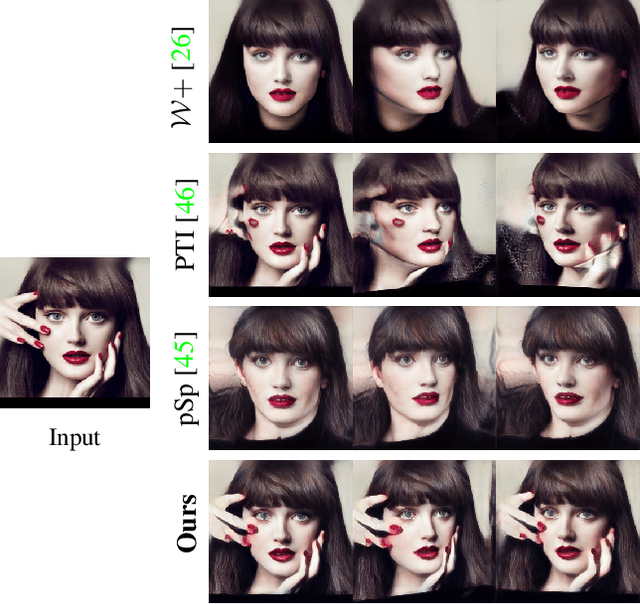
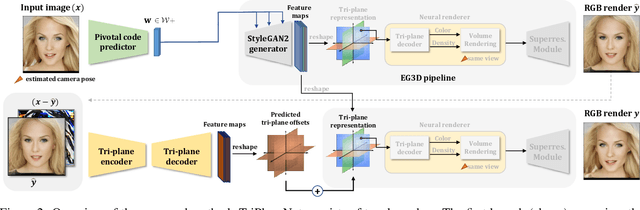
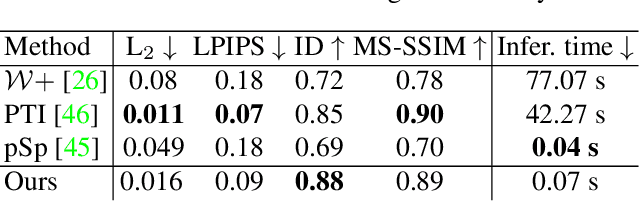

Recent progress in NeRF-based GANs has introduced a number of approaches for high-resolution and high-fidelity generative modeling of human heads with a possibility for novel view rendering. At the same time, one must solve an inverse problem to be able to re-render or modify an existing image or video. Despite the success of universal optimization-based methods for 2D GAN inversion, those, applied to 3D GANs, may fail to produce 3D-consistent renderings. Fast encoder-based techniques, such as those developed for StyleGAN, may also be less appealing due to the lack of identity preservation. In our work, we introduce a real-time method that bridges the gap between the two approaches by directly utilizing the tri-plane representation introduced for EG3D generative model. In particular, we build upon a feed-forward convolutional encoder for the latent code and extend it with a fully-convolutional predictor of tri-plane numerical offsets. As shown in our work, the renderings are similar in quality to optimization-based techniques and significantly outperform the baselines for novel view. As we empirically prove, this is a consequence of directly operating in the tri-plane space, not in the GAN parameter space, while making use of an encoder-based trainable approach.
Efficient and Direct Inference of Heart Rate Variability using Both Signal Processing and Machine Learning
Mar 23, 2023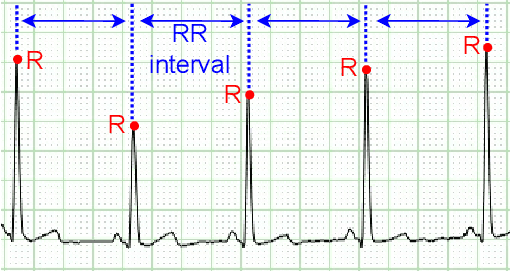
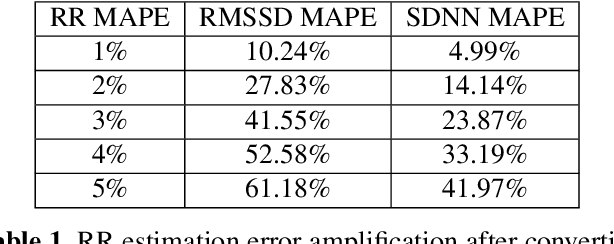
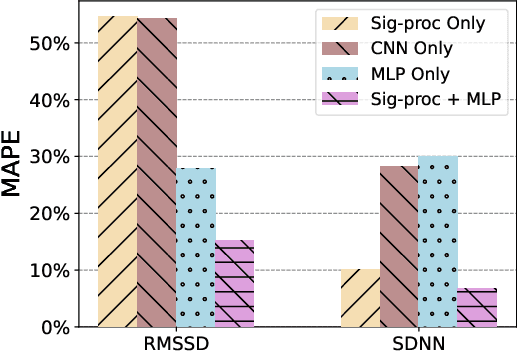

Heart Rate Variability (HRV) measures the variation of the time between consecutive heartbeats and is a major indicator of physical and mental health. Recent research has demonstrated that photoplethysmography (PPG) sensors can be used to infer HRV. However, many prior studies had high errors because they only employed signal processing or machine learning (ML), or because they indirectly inferred HRV, or because there lacks large training datasets. Many prior studies may also require large ML models. The low accuracy and large model sizes limit their applications to small embedded devices and potential future use in healthcare. To address the above issues, we first collected a large dataset of PPG signals and HRV ground truth. With this dataset, we developed HRV models that combine signal processing and ML to directly infer HRV. Evaluation results show that our method had errors between 3.5% to 25.7% and outperformed signal-processing-only and ML-only methods. We also explored different ML models, which showed that Decision Trees and Multi-level Perceptrons have 13.0% and 9.1% errors on average with models at most hundreds of KB and inference time less than 1ms. Hence, they are more suitable for small embedded devices and potentially enable the future use of PPG-based HRV monitoring in healthcare.
NVAutoNet: Fast and Accurate 360$^{\circ}$ 3D Perception For Self Driving
Mar 23, 2023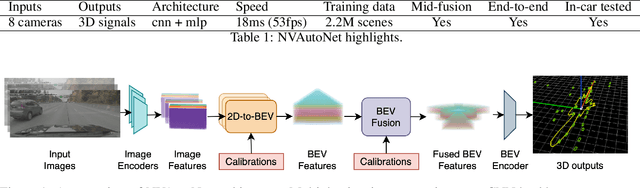

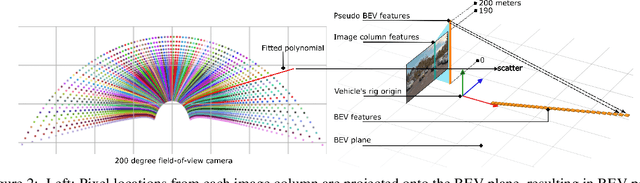
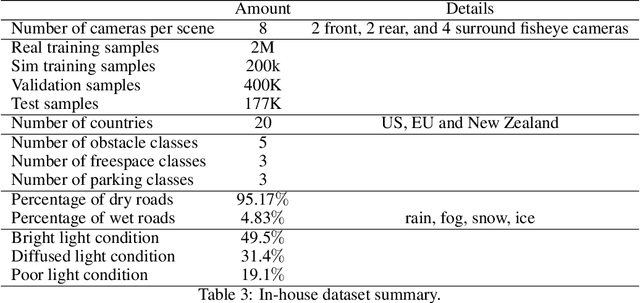
Robust real-time perception of 3D world is essential to the autonomous vehicle. We introduce an end-to-end surround camera perception system for self-driving. Our perception system is a novel multi-task, multi-camera network which takes a variable set of time-synced camera images as input and produces a rich collection of 3D signals such as sizes, orientations, locations of obstacles, parking spaces and free-spaces, etc. Our perception network is modular and end-to-end: 1) the outputs can be consumed directly by downstream modules without any post-processing such as clustering and fusion -- improving speed of model deployment and in-car testing 2) the whole network training is done in one single stage -- improving speed of model improvement and iterations. The network is well designed to have high accuracy while running at 53 fps on NVIDIA Orin SoC (system-on-a-chip). The network is robust to sensor mounting variations (within some tolerances) and can be quickly customized for different vehicle types via efficient model fine-tuning thanks of its capability of taking calibration parameters as additional inputs during training and testing. Most importantly, our network has been successfully deployed and being tested on real roads.
Automated Federated Learning in Mobile Edge Networks -- Fast Adaptation and Convergence
Mar 23, 2023
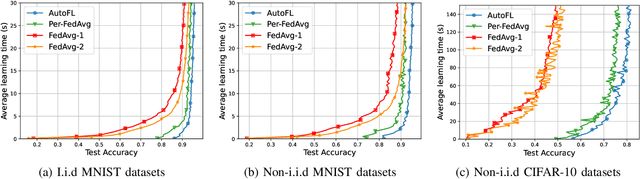
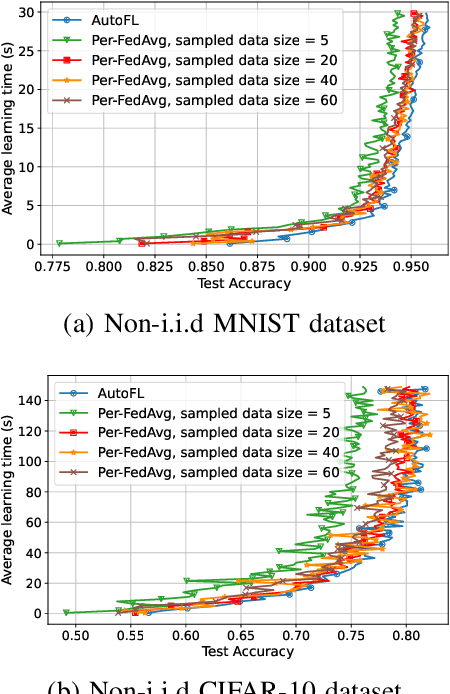
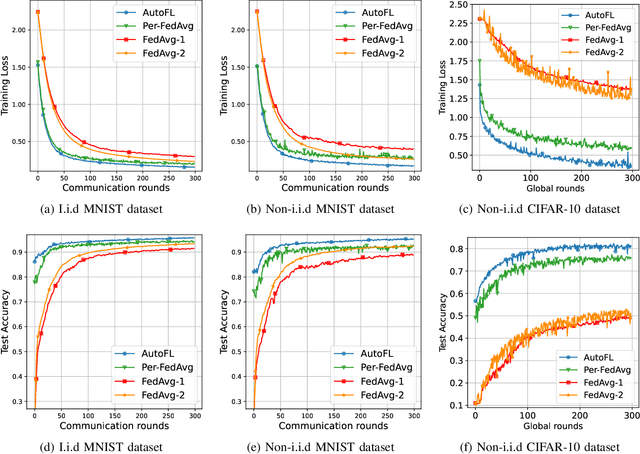
Federated Learning (FL) can be used in mobile edge networks to train machine learning models in a distributed manner. Recently, FL has been interpreted within a Model-Agnostic Meta-Learning (MAML) framework, which brings FL significant advantages in fast adaptation and convergence over heterogeneous datasets. However, existing research simply combines MAML and FL without explicitly addressing how much benefit MAML brings to FL and how to maximize such benefit over mobile edge networks. In this paper, we quantify the benefit from two aspects: optimizing FL hyperparameters (i.e., sampled data size and the number of communication rounds) and resource allocation (i.e., transmit power) in mobile edge networks. Specifically, we formulate the MAML-based FL design as an overall learning time minimization problem, under the constraints of model accuracy and energy consumption. Facilitated by the convergence analysis of MAML-based FL, we decompose the formulated problem and then solve it using analytical solutions and the coordinate descent method. With the obtained FL hyperparameters and resource allocation, we design a MAML-based FL algorithm, called Automated Federated Learning (AutoFL), that is able to conduct fast adaptation and convergence. Extensive experimental results verify that AutoFL outperforms other benchmark algorithms regarding the learning time and convergence performance.
Adiabatic replay for continual learning
Mar 23, 2023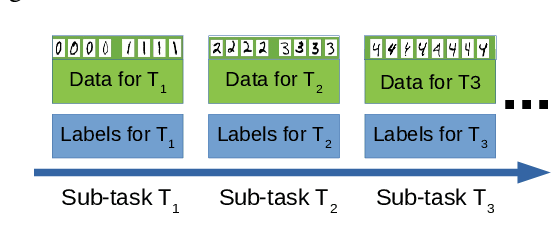

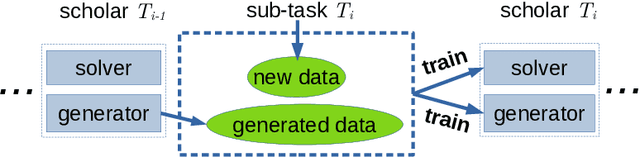
Conventional replay-based approaches to continual learning (CL) require, for each learning phase with new data, the replay of samples representing all of the previously learned knowledge in order to avoid catastrophic forgetting. Since the amount of learned knowledge grows over time in CL problems, generative replay spends an increasing amount of time just re-learning what is already known. In this proof-of-concept study, we propose a replay-based CL strategy that we term adiabatic replay (AR), which derives its efficiency from the (reasonable) assumption that each new learning phase is adiabatic, i.e., represents only a small addition to existing knowledge. Each new learning phase triggers a sampling process that selectively replays, from the body of existing knowledge, just such samples that are similar to the new data, in contrast to replaying all of it. Complete replay is not required since AR represents the data distribution by GMMs, which are capable of selectively updating their internal representation only where data statistics have changed. As long as additions are adiabatic, the amount of to-be-replayed samples need not to depend on the amount of previously acquired knowledge at all. We verify experimentally that AR is superior to state-of-the-art deep generative replay using VAEs.
FPTN: Fast Pure Transformer Network for Traffic Flow Forecasting
Mar 14, 2023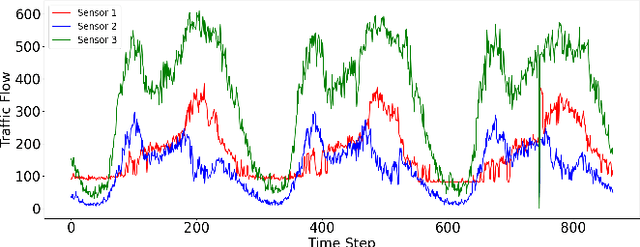
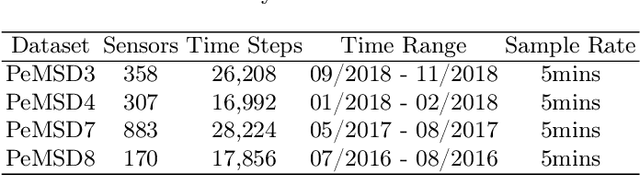
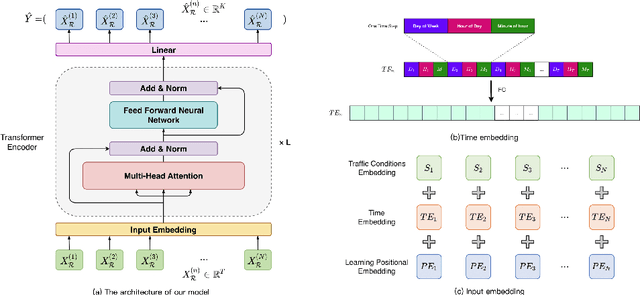
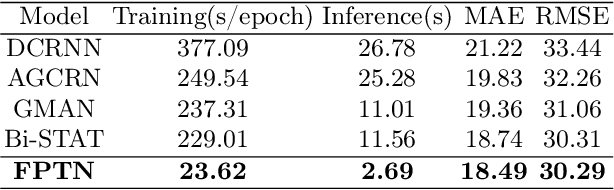
Traffic flow forecasting is challenging due to the intricate spatio-temporal correlations in traffic flow data. Existing Transformer-based methods usually treat traffic flow forecasting as multivariate time series (MTS) forecasting. However, too many sensors can cause a vector with a dimension greater than 800, which is difficult to process without information loss. In addition, these methods design complex mechanisms to capture spatial dependencies in MTS, resulting in slow forecasting speed. To solve the abovementioned problems, we propose a Fast Pure Transformer Network (FPTN) in this paper. First, the traffic flow data are divided into sequences along the sensor dimension instead of the time dimension. Then, to adequately represent complex spatio-temporal correlations, Three types of embeddings are proposed for projecting these vectors into a suitable vector space. After that, to capture the complex spatio-temporal correlations simultaneously in these vectors, we utilize Transformer encoder and stack it with several layers. Extensive experiments are conducted with 4 real-world datasets and 13 baselines, which demonstrate that FPTN outperforms the state-of-the-art on two metrics. Meanwhile, the computational time of FPTN spent is less than a quarter of other state-of-the-art Transformer-based models spent, and the requirements for computing resources are significantly reduced.
Efficient Image-Text Retrieval via Keyword-Guided Pre-Screening
Mar 14, 2023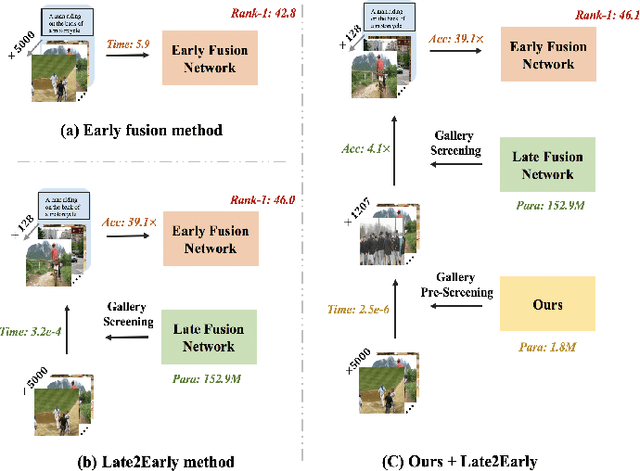
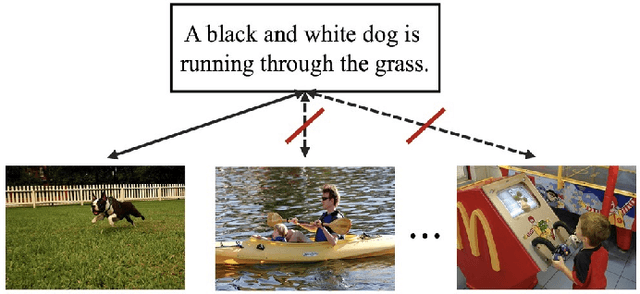
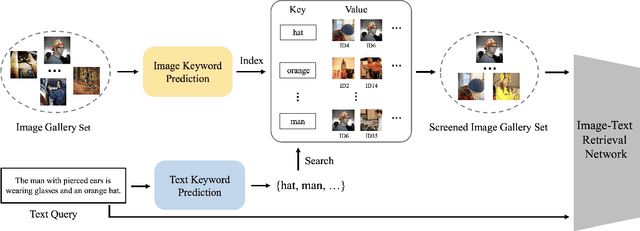
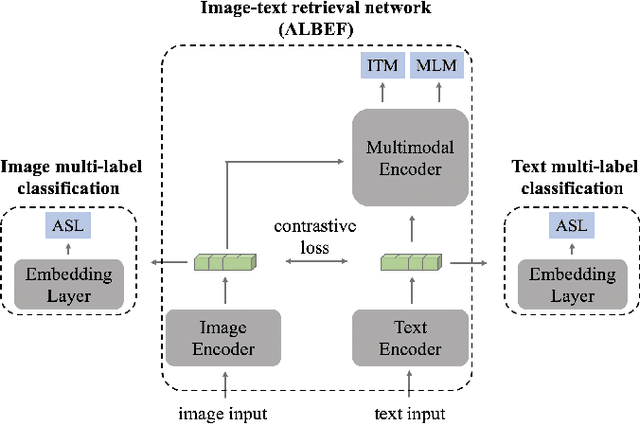
Under the flourishing development in performance, current image-text retrieval methods suffer from $N$-related time complexity, which hinders their application in practice. Targeting at efficiency improvement, this paper presents a simple and effective keyword-guided pre-screening framework for the image-text retrieval. Specifically, we convert the image and text data into the keywords and perform the keyword matching across modalities to exclude a large number of irrelevant gallery samples prior to the retrieval network. For the keyword prediction, we transfer it into a multi-label classification problem and propose a multi-task learning scheme by appending the multi-label classifiers to the image-text retrieval network to achieve a lightweight and high-performance keyword prediction. For the keyword matching, we introduce the inverted index in the search engine and create a win-win situation on both time and space complexities for the pre-screening. Extensive experiments on two widely-used datasets, i.e., Flickr30K and MS-COCO, verify the effectiveness of the proposed framework. The proposed framework equipped with only two embedding layers achieves $O(1)$ querying time complexity, while improving the retrieval efficiency and keeping its performance, when applied prior to the common image-text retrieval methods. Our code will be released.
Towards Active Learning for Action Spotting in Association Football Videos
Apr 09, 2023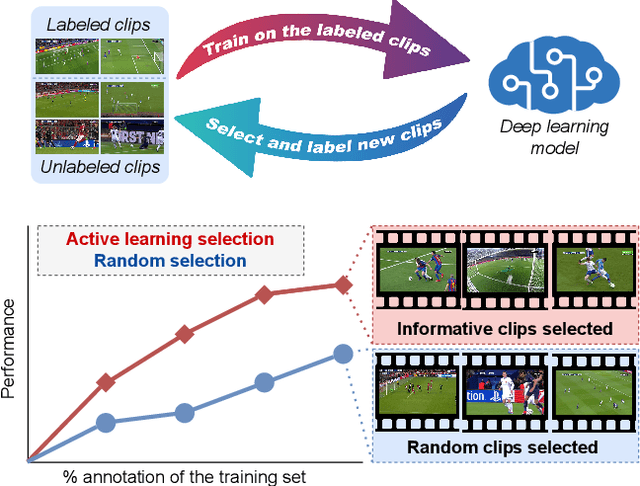
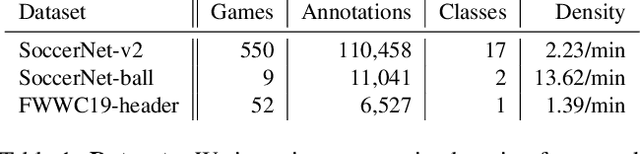
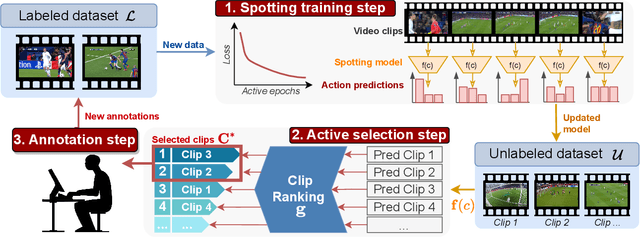

Association football is a complex and dynamic sport, with numerous actions occurring simultaneously in each game. Analyzing football videos is challenging and requires identifying subtle and diverse spatio-temporal patterns. Despite recent advances in computer vision, current algorithms still face significant challenges when learning from limited annotated data, lowering their performance in detecting these patterns. In this paper, we propose an active learning framework that selects the most informative video samples to be annotated next, thus drastically reducing the annotation effort and accelerating the training of action spotting models to reach the highest accuracy at a faster pace. Our approach leverages the notion of uncertainty sampling to select the most challenging video clips to train on next, hastening the learning process of the algorithm. We demonstrate that our proposed active learning framework effectively reduces the required training data for accurate action spotting in football videos. We achieve similar performances for action spotting with NetVLAD++ on SoccerNet-v2, using only one-third of the dataset, indicating significant capabilities for reducing annotation time and improving data efficiency. We further validate our approach on two new datasets that focus on temporally localizing actions of headers and passes, proving its effectiveness across different action semantics in football. We believe our active learning framework for action spotting would support further applications of action spotting algorithms and accelerate annotation campaigns in the sports domain.