 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Label-Free Concept Bottleneck Models
Apr 12, 2023
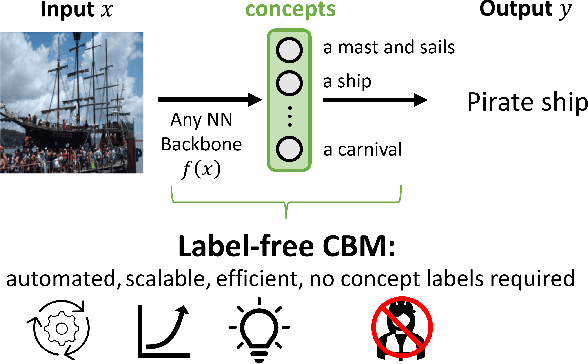
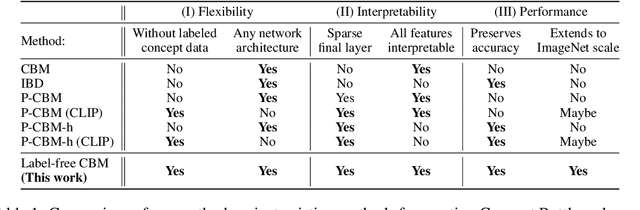
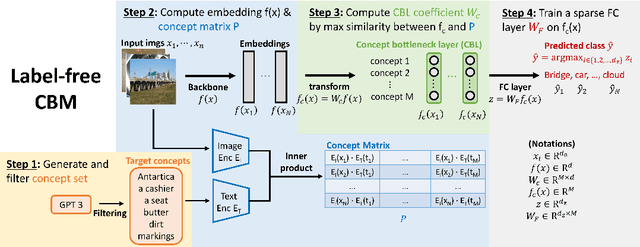
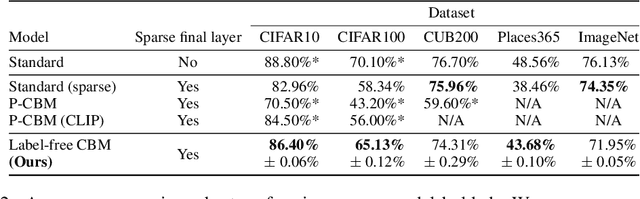
Concept bottleneck models (CBM) are a popular way of creating more interpretable neural networks by having hidden layer neurons correspond to human-understandable concepts. However, existing CBMs and their variants have two crucial limitations: first, they need to collect labeled data for each of the predefined concepts, which is time consuming and labor intensive; second, the accuracy of a CBM is often significantly lower than that of a standard neural network, especially on more complex datasets. This poor performance creates a barrier for adopting CBMs in practical real world applications. Motivated by these challenges, we propose Label-free CBM which is a novel framework to transform any neural network into an interpretable CBM without labeled concept data, while retaining a high accuracy. Our Label-free CBM has many advantages, it is: scalable - we present the first CBM scaled to ImageNet, efficient - creating a CBM takes only a few hours even for very large datasets, and automated - training it for a new dataset requires minimal human effort. Our code is available at https://github.com/Trustworthy-ML-Lab/Label-free-CBM.
DS-MPEPC: Safe and Deadlock-Avoiding Robot Navigation in Cluttered Dynamic Scenes
Mar 17, 2023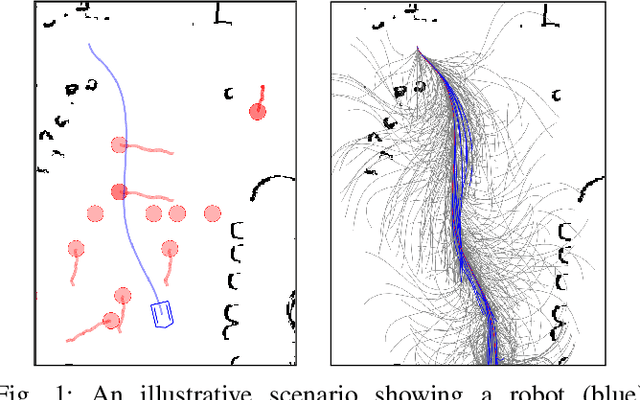
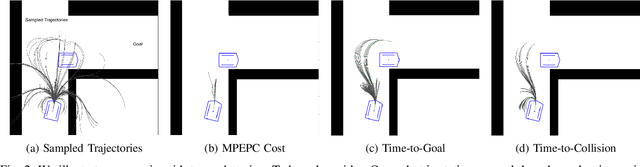
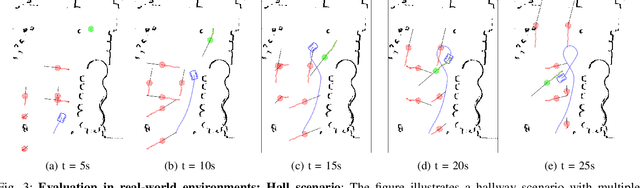
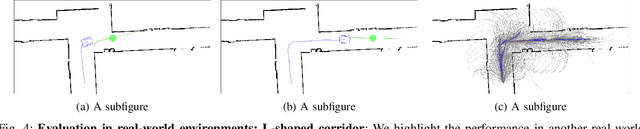
We present an algorithm for safe robot navigation in complex dynamic environments using a variant of model predictive equilibrium point control. We use an optimization formulation to navigate robots gracefully in dynamic environments by optimizing over a trajectory cost function at each timestep. We present a novel trajectory cost formulation that significantly reduces the conservative and deadlock behaviors and generates smooth trajectories. In particular, we propose a new collision probability function that effectively captures the risk associated with a given configuration and the time to avoid collisions based on the velocity direction. Moreover, we propose a terminal state cost based on the expected time-to-goal and time-to-collision values that helps in avoiding trajectories that could result in deadlock. We evaluate our cost formulation in multiple simulated and real-world scenarios, including narrow corridors with dynamic obstacles, and observe significantly improved navigation behavior and reduced deadlocks as compared to prior methods.
Refinement for Absolute Pose Regression with Neural Feature Synthesis
Mar 17, 2023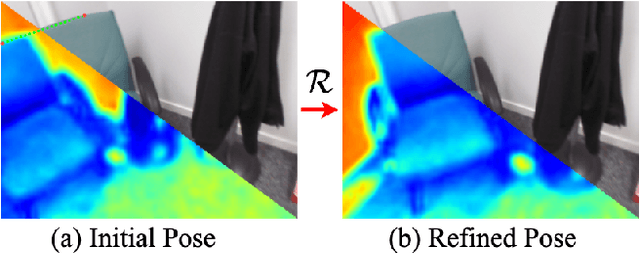
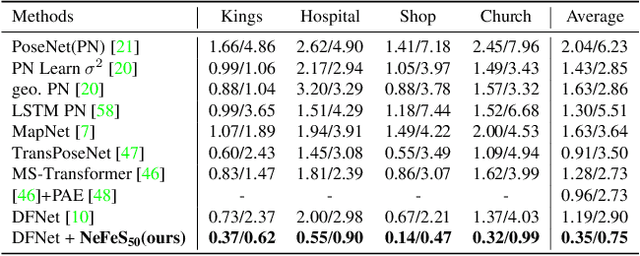
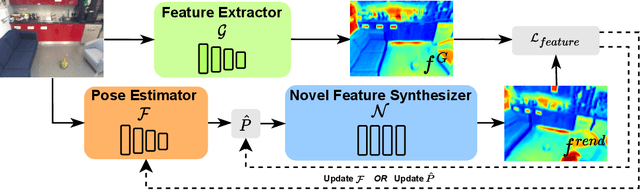

Absolute Pose Regression (APR) methods use deep neural networks to directly regress camera poses from RGB images. Despite their advantages in inference speed and simplicity, these methods still fall short of the accuracy achieved by geometry-based techniques. To address this issue, we propose a new model called the Neural Feature Synthesizer (NeFeS). Our approach encodes 3D geometric features during training and renders dense novel view features at test time to refine estimated camera poses from arbitrary APR methods. Unlike previous APR works that require additional unlabeled training data, our method leverages implicit geometric constraints during test time using a robust feature field. To enhance the robustness of our NeFeS network, we introduce a feature fusion module and a progressive training strategy. Our proposed method improves the state-of-the-art single-image APR accuracy by as much as 54.9% on indoor and outdoor benchmark datasets without additional time-consuming unlabeled data training.
NVAutoNet: Fast and Accurate 360$^{\circ}$ 3D Visual Perception For Self Driving
Mar 30, 2023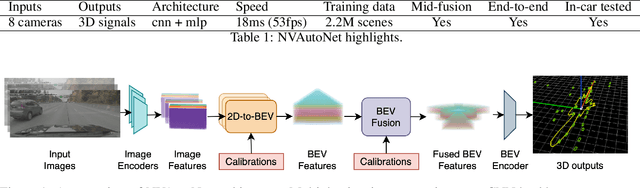

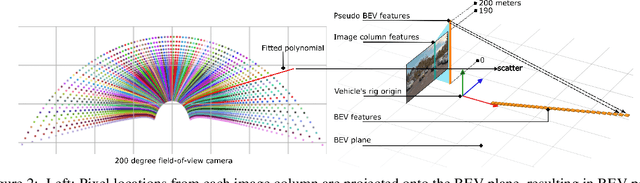
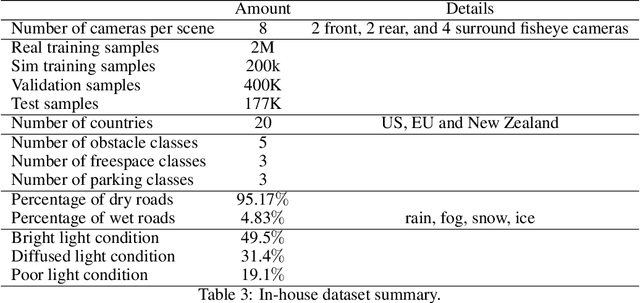
Robust real-time perception of 3D world is essential to the autonomous vehicle. We introduce an end-to-end surround camera perception system for self-driving. Our perception system is a novel multi-task, multi-camera network which takes a variable set of time-synced camera images as input and produces a rich collection of 3D signals such as sizes, orientations, locations of obstacles, parking spaces and free-spaces, etc. Our perception network is modular and end-to-end: 1) the outputs can be consumed directly by downstream modules without any post-processing such as clustering and fusion -- improving speed of model deployment and in-car testing 2) the whole network training is done in one single stage -- improving speed of model improvement and iterations. The network is well designed to have high accuracy while running at 53 fps on NVIDIA Orin SoC (system-on-a-chip). The network is robust to sensor mounting variations (within some tolerances) and can be quickly customized for different vehicle types via efficient model fine-tuning thanks of its capability of taking calibration parameters as additional inputs during training and testing. Most importantly, our network has been successfully deployed and being tested on real roads.
Multifactor Sequential Disentanglement via Structured Koopman Autoencoders
Mar 30, 2023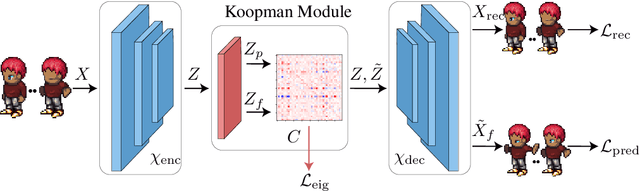

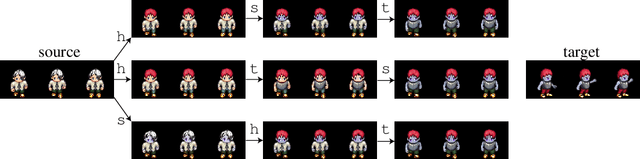
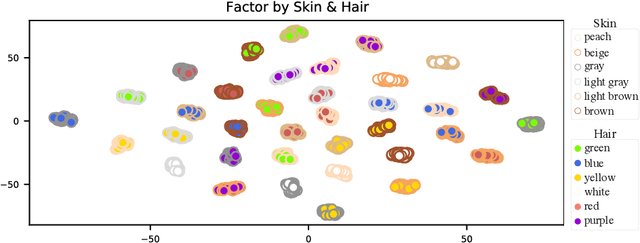
Disentangling complex data to its latent factors of variation is a fundamental task in representation learning. Existing work on sequential disentanglement mostly provides two factor representations, i.e., it separates the data to time-varying and time-invariant factors. In contrast, we consider multifactor disentanglement in which multiple (more than two) semantic disentangled components are generated. Key to our approach is a strong inductive bias where we assume that the underlying dynamics can be represented linearly in the latent space. Under this assumption, it becomes natural to exploit the recently introduced Koopman autoencoder models. However, disentangled representations are not guaranteed in Koopman approaches, and thus we propose a novel spectral loss term which leads to structured Koopman matrices and disentanglement. Overall, we propose a simple and easy to code new deep model that is fully unsupervised and it supports multifactor disentanglement. We showcase new disentangling abilities such as swapping of individual static factors between characters, and an incremental swap of disentangled factors from the source to the target. Moreover, we evaluate our method extensively on two factor standard benchmark tasks where we significantly improve over competing unsupervised approaches, and we perform competitively in comparison to weakly- and self-supervised state-of-the-art approaches. The code is available at https://github.com/azencot-group/SKD.
Towards End-to-End Generative Modeling of Long Videos with Memory-Efficient Bidirectional Transformers
Mar 27, 2023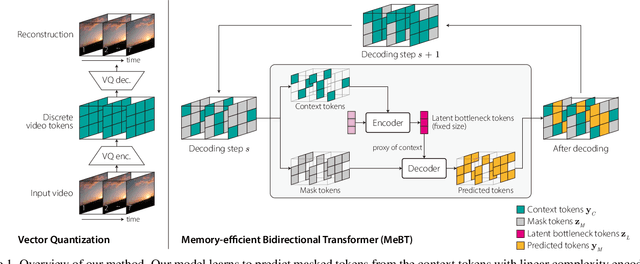
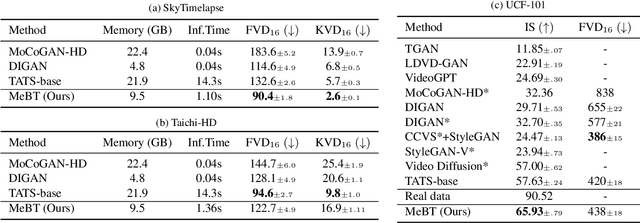
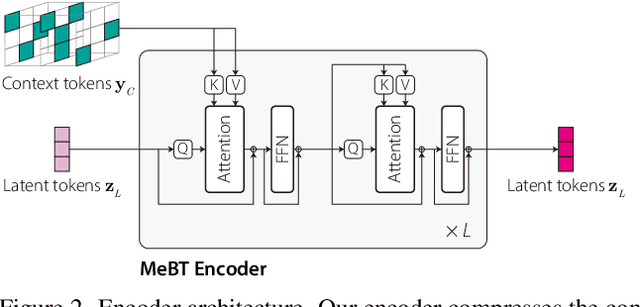
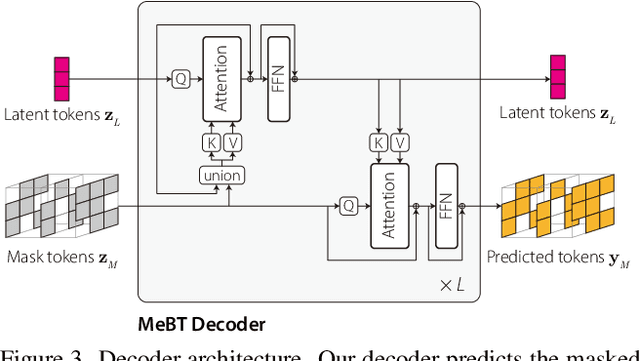
Autoregressive transformers have shown remarkable success in video generation. However, the transformers are prohibited from directly learning the long-term dependency in videos due to the quadratic complexity of self-attention, and inherently suffering from slow inference time and error propagation due to the autoregressive process. In this paper, we propose Memory-efficient Bidirectional Transformer (MeBT) for end-to-end learning of long-term dependency in videos and fast inference. Based on recent advances in bidirectional transformers, our method learns to decode the entire spatio-temporal volume of a video in parallel from partially observed patches. The proposed transformer achieves a linear time complexity in both encoding and decoding, by projecting observable context tokens into a fixed number of latent tokens and conditioning them to decode the masked tokens through the cross-attention. Empowered by linear complexity and bidirectional modeling, our method demonstrates significant improvement over the autoregressive Transformers for generating moderately long videos in both quality and speed. Videos and code are available at https://sites.google.com/view/mebt-cvpr2023 .
Optimal task and motion planning and execution for human-robot multi-agent systems in dynamic environments
Mar 27, 2023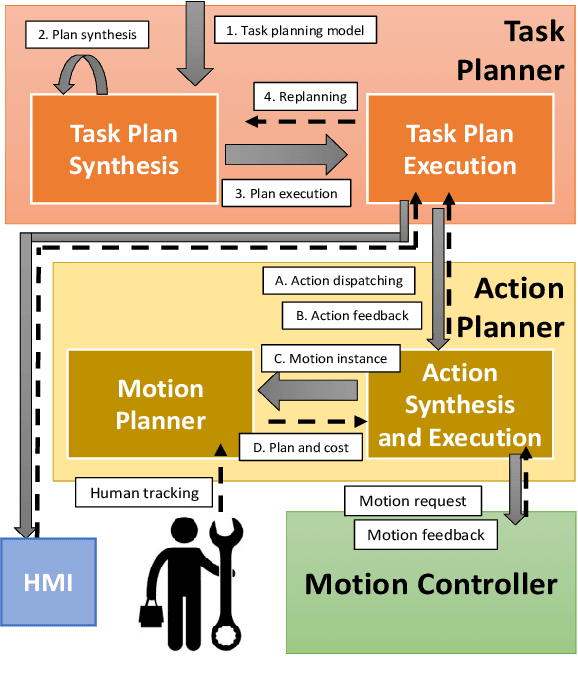
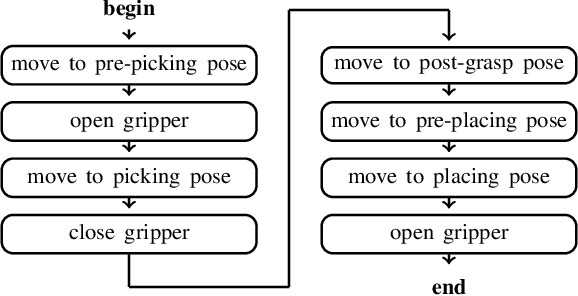
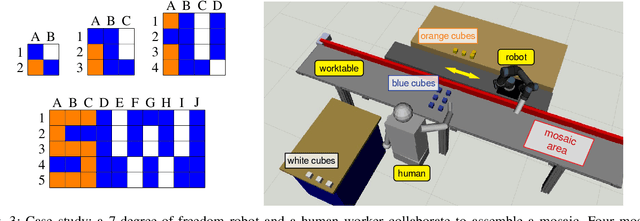
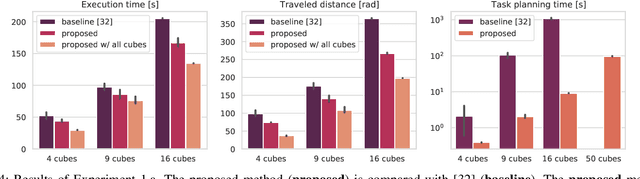
Combining symbolic and geometric reasoning in multi-agent systems is a challenging task that involves planning, scheduling, and synchronization problems. Existing works overlooked the variability of task duration and geometric feasibility that is intrinsic to these systems because of the interaction between agents and the environment. We propose a combined task and motion planning approach to optimize sequencing, assignment, and execution of tasks under temporal and spatial variability. The framework relies on decoupling tasks and actions, where an action is one possible geometric realization of a symbolic task. At the task level, timeline-based planning deals with temporal constraints, duration variability, and synergic assignment of tasks. At the action level, online motion planning plans for the actual movements dealing with environmental changes. We demonstrate the approach effectiveness in a collaborative manufacturing scenario, in which a robotic arm and a human worker shall assemble a mosaic in the shortest time possible. Compared with existing works, our approach applies to a broader range of applications and reduces the execution time of the process.
Connection-Based Scheduling for Real-Time Intersection Control
Oct 16, 2022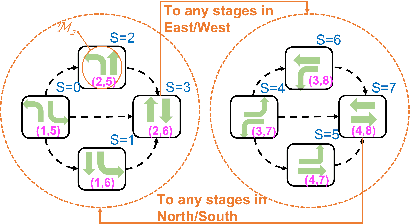
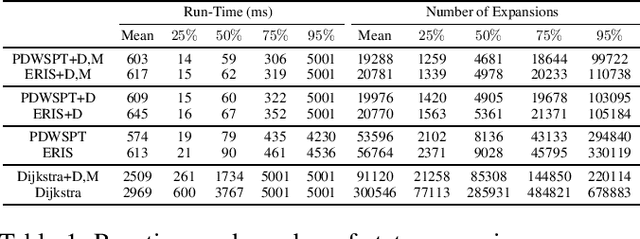
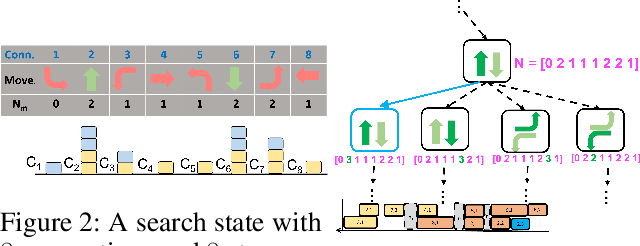
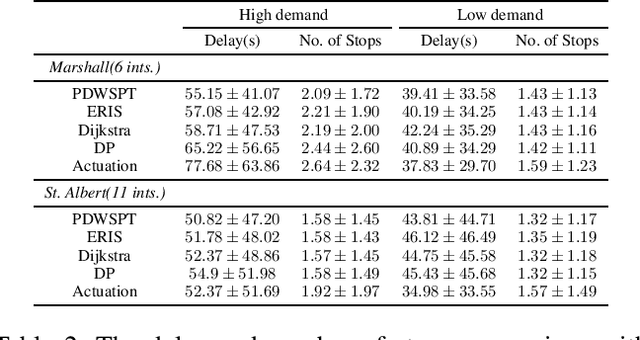
We introduce a heuristic scheduling algorithm for real-time adaptive traffic signal control to reduce traffic congestion. This algorithm adopts a lane-based model that estimates the arrival time of all vehicles approaching an intersection through different lanes, and then computes a schedule (i.e., a signal timing plan) that minimizes the cumulative delay incurred by all approaching vehicles. State space, pruning checks and an admissible heuristic for A* search are described and shown to be capable of generating an intersection schedule in real-time (i.e., every second). Due to the effectiveness of the heuristics, the proposed approach outperforms a less expressive Dynamic Programming approach and previous A*-based approaches in run-time performance, both in simulated test environments and actual field tests.
Unsupervised Anomaly Detection in Time-series: An Extensive Evaluation and Analysis of State-of-the-art Methods
Dec 06, 2022
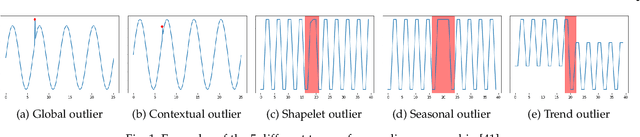
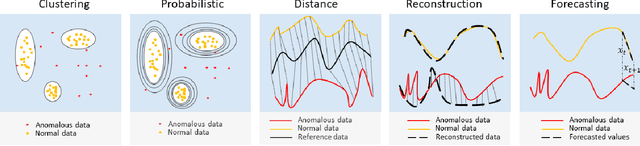
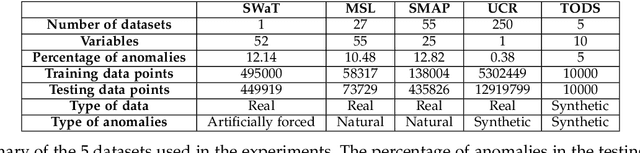
Unsupervised anomaly detection in time-series has been extensively investigated in the literature. Notwithstanding the relevance of this topic in numerous application fields, a complete and extensive evaluation of recent state-of-the-art techniques is still missing. Few efforts have been made to compare existing unsupervised time-series anomaly detection methods rigorously. However, only standard performance metrics, namely precision, recall, and F1-score are usually considered. Essential aspects for assessing their practical relevance are therefore neglected. This paper proposes an original and in-depth evaluation study of recent unsupervised anomaly detection techniques in time-series. Instead of relying solely on standard performance metrics, additional yet informative metrics and protocols are taken into account. In particular, (1) more elaborate performance metrics specifically tailored for time-series are used; (2) the model size and the model stability are studied; (3) an analysis of the tested approaches with respect to the anomaly type is provided; and (4) a clear and unique protocol is followed for all experiments. Overall, this extensive analysis aims to assess the maturity of state-of-the-art time-series anomaly detection, give insights regarding their applicability under real-world setups and provide to the community a more complete evaluation protocol.
Learning and Concentration for High Dimensional Linear Gaussians: an Invariant Subspace Approach
Apr 04, 2023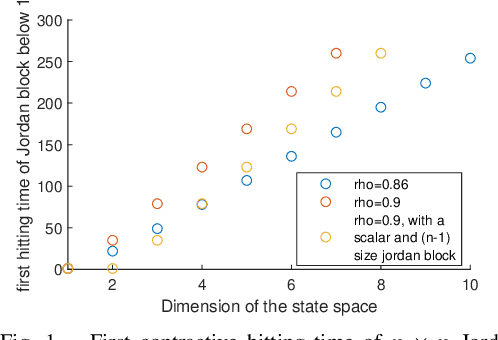
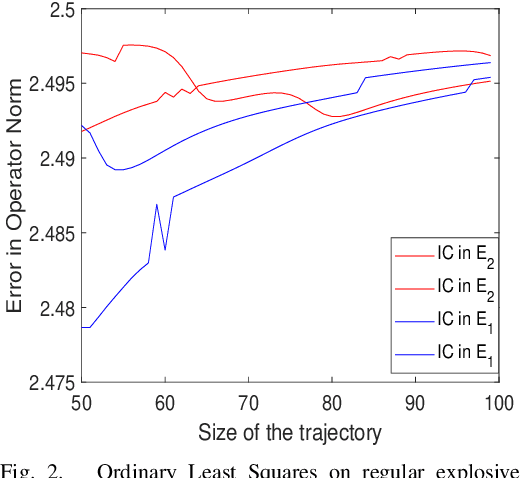
In this work, we study non-asymptotic bounds on correlation between two time realizations of stable linear systems with isotropic Gaussian noise. Consequently, via sampling from a sub-trajectory and using \emph{Talagrands'} inequality, we show that empirical averages of reward concentrate around steady state (dynamical system mixes to when closed loop system is stable under linear feedback policy ) reward , with high-probability. As opposed to common belief of larger the spectral radius stronger the correlation between samples, \emph{large discrepancy between algebraic and geometric multiplicity of system eigenvalues leads to large invariant subspaces related to system-transition matrix}; once the system enters the large invariant subspace it will travel away from origin for a while before coming close to a unit ball centered at origin where an isotropic Gaussian noise can with high probability allow it to escape the current invariant subspace it resides in, leading to \emph{bottlenecks} between different invariant subspaces that span $\mathbb{R}^{n}$, to be precise : system initiated in a large invariant subspace will be stuck there for a long-time: log-linear in dimension of the invariant subspace and inversely to log of inverse of magnitude of the eigenvalue. In the problem of Ordinary Least Squares estimate of system transition matrix via a single trajectory, this phenomenon is even more evident if spectrum of transition matrix associated to large invariant subspace is explosive and small invariant subspaces correspond to stable eigenvalues. Our analysis provide first interpretable and geometric explanation into intricacies of learning and concentration for random dynamical systems on continuous, high dimensional state space; exposing us to surprises in high dimensions