 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
StageInteractor: Query-based Object Detector with Cross-stage Interaction
Apr 11, 2023
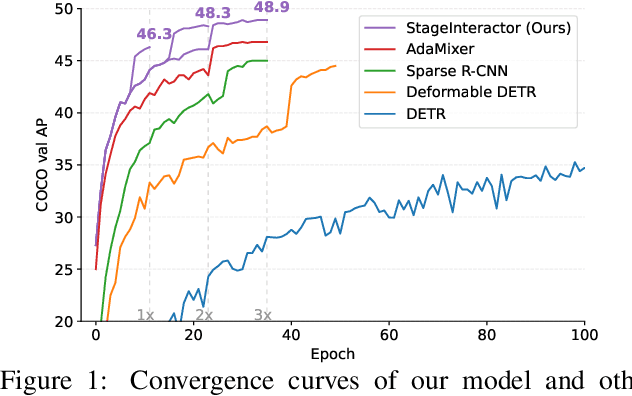
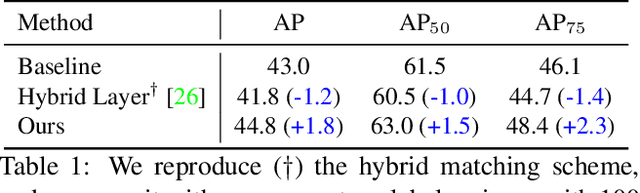
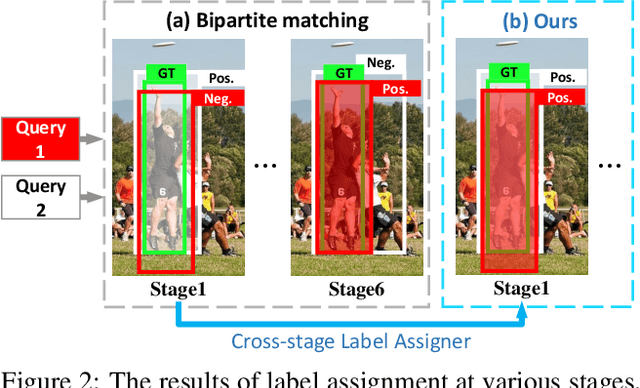
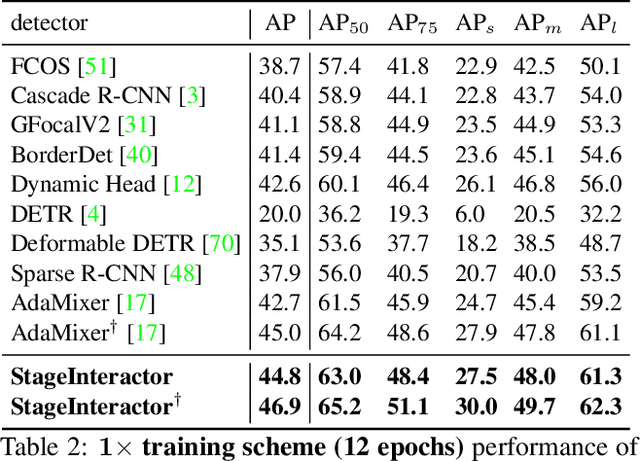
Previous object detectors make predictions based on dense grid points or numerous preset anchors. Most of these detectors are trained with one-to-many label assignment strategies. On the contrary, recent query-based object detectors depend on a sparse set of learnable queries and a series of decoder layers. The one-to-one label assignment is independently applied on each layer for the deep supervision during training. Despite the great success of query-based object detection, however, this one-to-one label assignment strategy demands the detectors to have strong fine-grained discrimination and modeling capacity. To solve the above problems, in this paper, we propose a new query-based object detector with cross-stage interaction, coined as StageInteractor. During the forward propagation, we come up with an efficient way to improve this modeling ability by reusing dynamic operators with lightweight adapters. As for the label assignment, a cross-stage label assigner is applied subsequent to the one-to-one label assignment. With this assigner, the training target class labels are gathered across stages and then reallocated to proper predictions at each decoder layer. On MS COCO benchmark, our model improves the baseline by 2.2 AP, and achieves 44.8 AP with ResNet-50 as backbone, 100 queries and 12 training epochs. With longer training time and 300 queries, StageInteractor achieves 51.1 AP and 52.2 AP with ResNeXt-101-DCN and Swin-S, respectively.
Towards Efficient Fine-tuning of Pre-trained Code Models: An Experimental Study and Beyond
Apr 11, 2023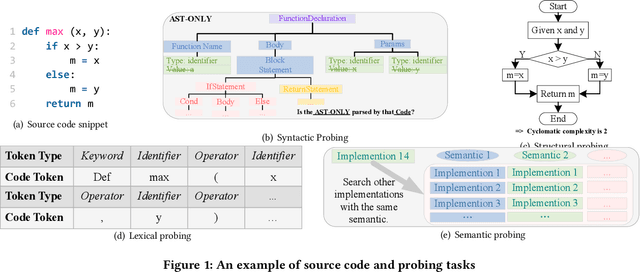

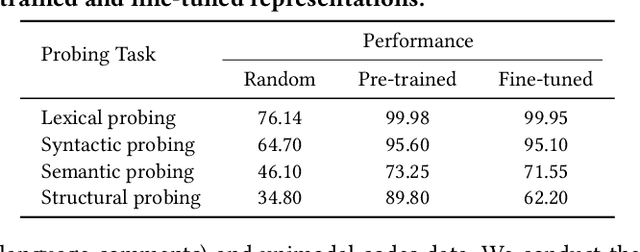
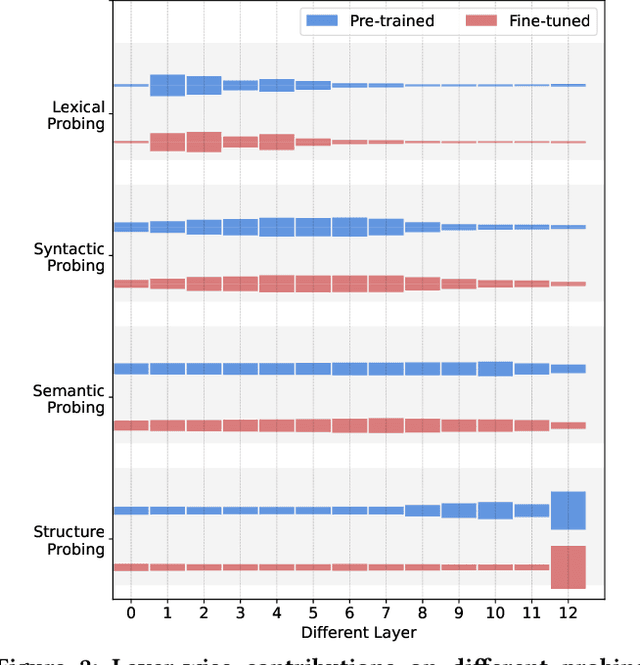
Recently, fine-tuning pre-trained code models such as CodeBERT on downstream tasks has achieved great success in many software testing and analysis tasks. While effective and prevalent, fine-tuning the pre-trained parameters incurs a large computational cost. In this paper, we conduct an extensive experimental study to explore what happens to layer-wise pre-trained representations and their encoded code knowledge during fine-tuning. We then propose efficient alternatives to fine-tune the large pre-trained code model based on the above findings. Our experimental study shows that (1) lexical, syntactic and structural properties of source code are encoded in the lower, intermediate, and higher layers, respectively, while the semantic property spans across the entire model. (2) The process of fine-tuning preserves most of the code properties. Specifically, the basic code properties captured by lower and intermediate layers are still preserved during fine-tuning. Furthermore, we find that only the representations of the top two layers change most during fine-tuning for various downstream tasks. (3) Based on the above findings, we propose Telly to efficiently fine-tune pre-trained code models via layer freezing. The extensive experimental results on five various downstream tasks demonstrate that training parameters and the corresponding time cost are greatly reduced, while performances are similar or better. Replication package including source code, datasets, and online Appendix is available at: \url{https://github.com/DeepSoftwareAnalytics/Telly}.
Echo of Neighbors: Privacy Amplification for Personalized Private Federated Learning with Shuffle Model
Apr 11, 2023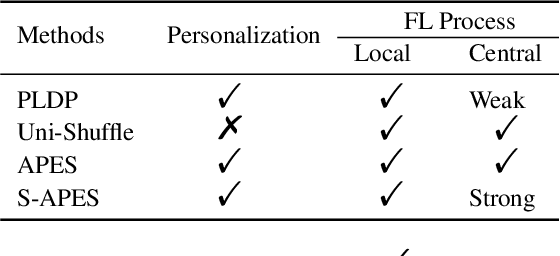
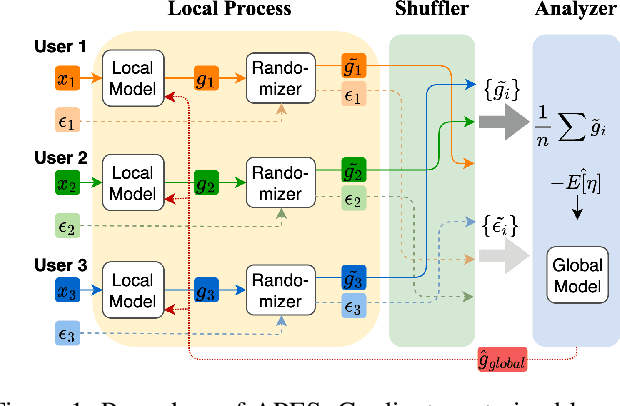

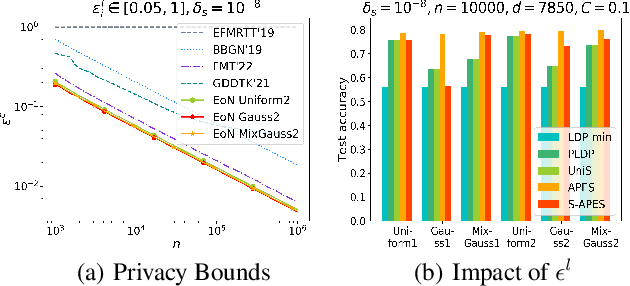
Federated Learning, as a popular paradigm for collaborative training, is vulnerable against privacy attacks. Different privacy levels regarding users' attitudes need to be satisfied locally, while a strict privacy guarantee for the global model is also required centrally. Personalized Local Differential Privacy (PLDP) is suitable for preserving users' varying local privacy, yet only provides a central privacy guarantee equivalent to the worst-case local privacy level. Thus, achieving strong central privacy as well as personalized local privacy with a utility-promising model is a challenging problem. In this work, a general framework (APES) is built up to strengthen model privacy under personalized local privacy by leveraging the privacy amplification effect of the shuffle model. To tighten the privacy bound, we quantify the heterogeneous contributions to the central privacy user by user. The contributions are characterized by the ability of generating "echos" from the perturbation of each user, which is carefully measured by proposed methods Neighbor Divergence and Clip-Laplace Mechanism. Furthermore, we propose a refined framework (S-APES) with the post-sparsification technique to reduce privacy loss in high-dimension scenarios. To the best of our knowledge, the impact of shuffling on personalized local privacy is considered for the first time. We provide a strong privacy amplification effect, and the bound is tighter than the baseline result based on existing methods for uniform local privacy. Experiments demonstrate that our frameworks ensure comparable or higher accuracy for the global model.
chatIPCC: Grounding Conversational AI in Climate Science
Apr 11, 2023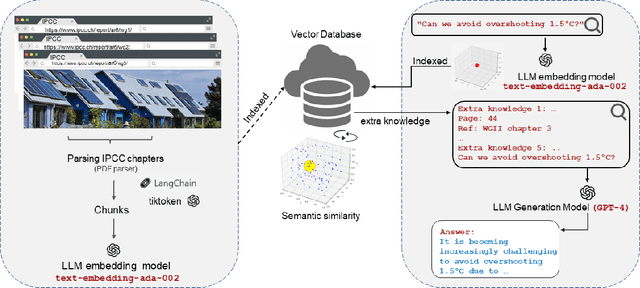
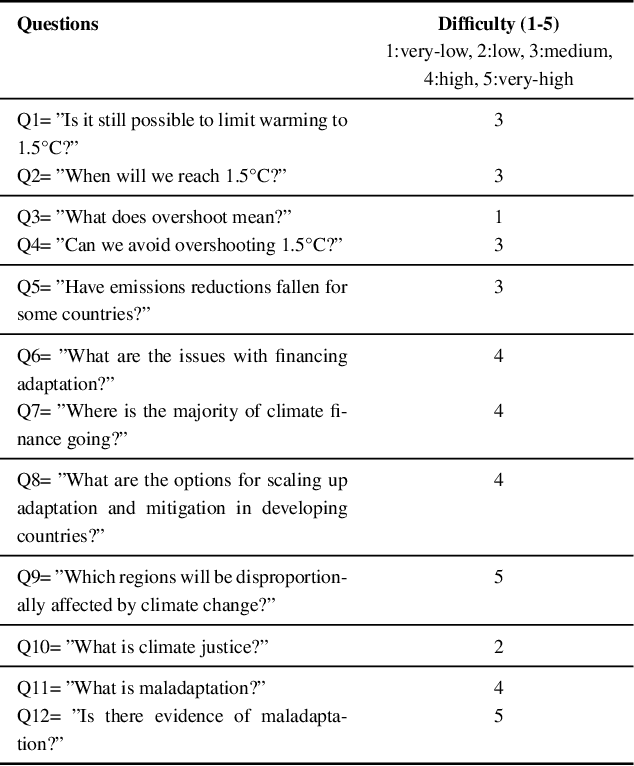
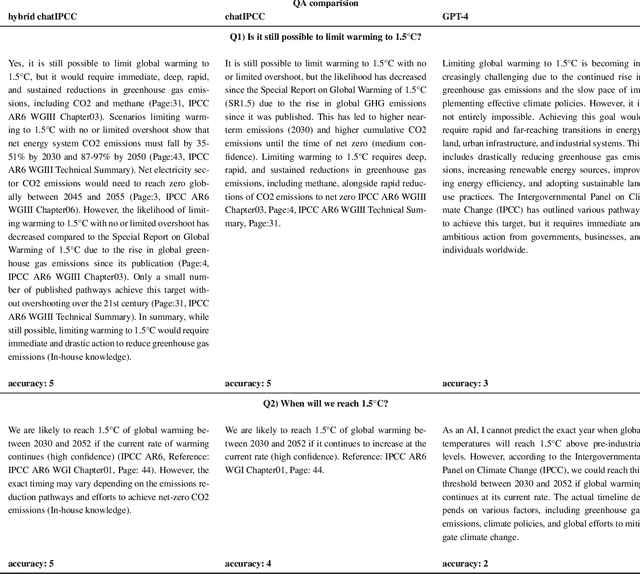

Large Language Models (LLMs) have made significant progress in recent years, achieving remarkable results in question-answering tasks (QA). However, they still face two major challenges: hallucination and outdated information after the training phase. These challenges take center stage in critical domains like climate change, where obtaining accurate and up-to-date information from reliable sources in a limited time is essential and difficult. To overcome these barriers, one potential solution is to provide LLMs with access to external, scientifically accurate, and robust sources (long-term memory) to continuously update their knowledge and prevent the propagation of inaccurate, incorrect, or outdated information. In this study, we enhanced GPT-4 by integrating the information from the Sixth Assessment Report of the Intergovernmental (IPCC AR6), the most comprehensive, up-to-date, and reliable source in this domain. We present our conversational AI prototype, available at www.chatclimate.ai/ipcc and demonstrate its ability to answer challenging questions accurately in three different QA scenarios: asking from 1) GPT-4, 2) chatIPCC, and 3) hybrid chatIPCC. The answers and their sources were evaluated by our team of IPCC authors, who used their expert knowledge to score the accuracy of the answers from 1 (very-low) to 5 (very-high). The evaluation showed that the hybrid chatIPCC provided more accurate answers, highlighting the effectiveness of our solution. This approach can be easily scaled for chatbots in specific domains, enabling the delivery of reliable and accurate information.
ChiroDiff: Modelling chirographic data with Diffusion Models
Apr 07, 2023



Generative modelling over continuous-time geometric constructs, a.k.a such as handwriting, sketches, drawings etc., have been accomplished through autoregressive distributions. Such strictly-ordered discrete factorization however falls short of capturing key properties of chirographic data -- it fails to build holistic understanding of the temporal concept due to one-way visibility (causality). Consequently, temporal data has been modelled as discrete token sequences of fixed sampling rate instead of capturing the true underlying concept. In this paper, we introduce a powerful model-class namely "Denoising Diffusion Probabilistic Models" or DDPMs for chirographic data that specifically addresses these flaws. Our model named "ChiroDiff", being non-autoregressive, learns to capture holistic concepts and therefore remains resilient to higher temporal sampling rate up to a good extent. Moreover, we show that many important downstream utilities (e.g. conditional sampling, creative mixing) can be flexibly implemented using ChiroDiff. We further show some unique use-cases like stochastic vectorization, de-noising/healing, abstraction are also possible with this model-class. We perform quantitative and qualitative evaluation of our framework on relevant datasets and found it to be better or on par with competing approaches.
CNN-based real-time 2D-3D deformable registration from a single X-ray projection
Dec 15, 2022
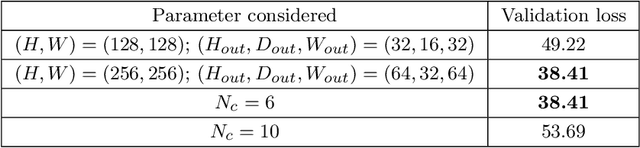
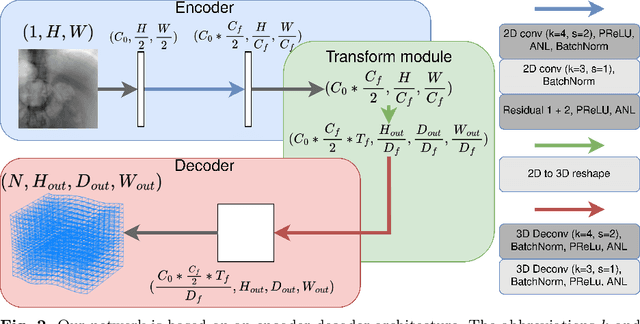
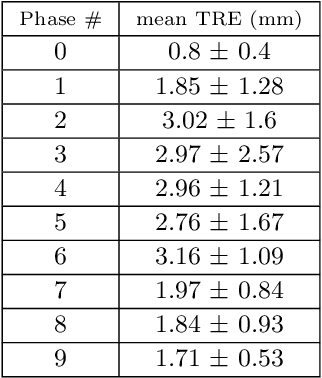
Purpose: The purpose of this paper is to present a method for real-time 2D-3D non-rigid registration using a single fluoroscopic image. Such a method can find applications in surgery, interventional radiology and radiotherapy. By estimating a three-dimensional displacement field from a 2D X-ray image, anatomical structures segmented in the preoperative scan can be projected onto the 2D image, thus providing a mixed reality view. Methods: A dataset composed of displacement fields and 2D projections of the anatomy is generated from the preoperative scan. From this dataset, a neural network is trained to recover the unknown 3D displacement field from a single projection image. Results: Our method is validated on lung 4D CT data at different stages of the lung deformation. The training is performed on a 3D CT using random (non domain-specific) diffeomorphic deformations, to which perturbations mimicking the pose uncertainty are added. The model achieves a mean TRE over a series of landmarks ranging from 2.3 to 5.5 mm depending on the amplitude of deformation. Conclusion: In this paper, a CNN-based method for real-time 2D-3D non-rigid registration is presented. This method is able to cope with pose estimation uncertainties, making it applicable to actual clinical scenarios, such as lung surgery, where the C-arm pose is planned before the intervention.
Tripletformer for Probabilistic Interpolation of Asynchronous Time Series
Oct 05, 2022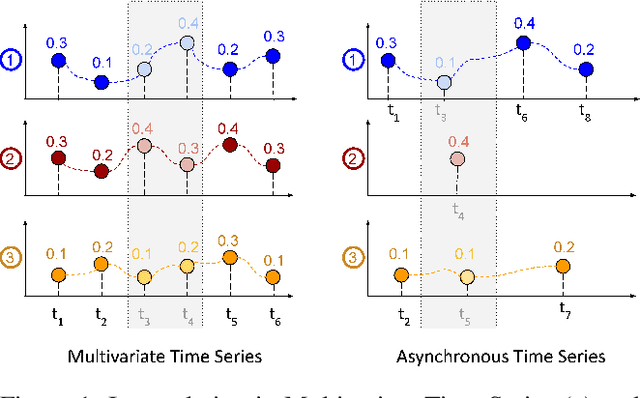
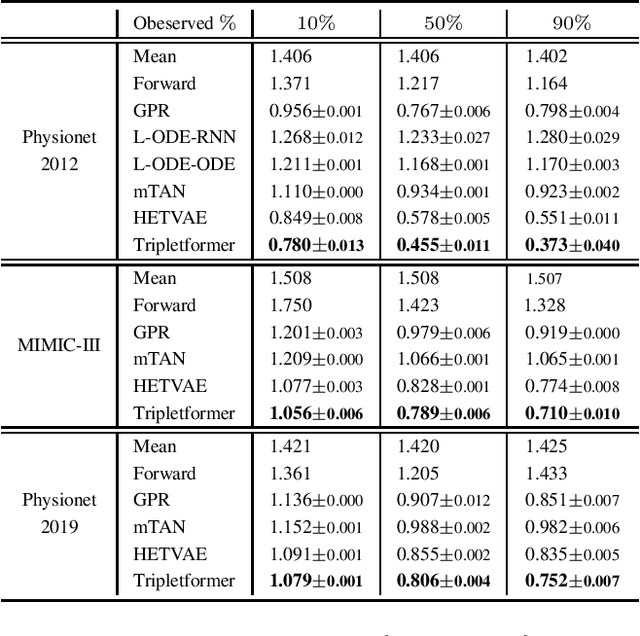
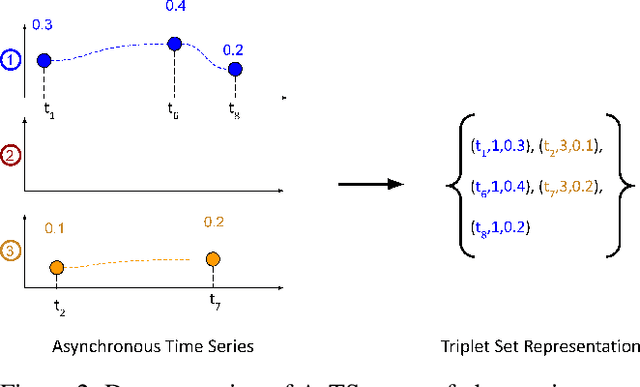
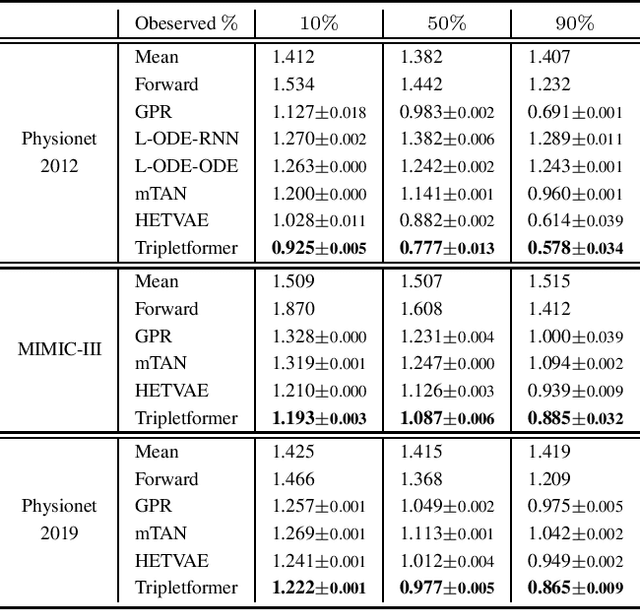
Asynchronous time series are often observed in several applications such as health care, astronomy, and climate science, and pose a significant challenge to the standard deep learning architectures. Interpolation of asynchronous time series is vital for many real-world tasks like root cause analysis, and medical diagnosis. In this paper, we propose a novel encoder-decoder architecture called Tripletformer, which works on the set of observations where each set element is a triple of time, channel, and value, for the probabilistic interpolation of the asynchronous time series. Both the encoder and the decoder of the Tripletformer are modeled using attention layers and fully connected layers and are invariant to the order in which set elements are presented. The proposed Tripletformer is compared with a range of baselines over multiple real-world and synthetic asynchronous time series datasets, and the experimental results attest that it produces more accurate and certain interpolations. We observe an improvement in negative loglikelihood error up to 33% over real and 800% over synthetic asynchronous time series datasets compared to the state-of-the-art model using the Tripletformer.
Augmented Collective Intelligence in Collaborative Ideation: Agenda and Challenges
Mar 31, 2023AI systems may be better thought of as peers than as tools. This paper explores applications of augmented collective intelligence (ACI) beneficial to collaborative ideation. Design considerations are offered for an experiment that evaluates the performance of hybrid human- AI collectives. The investigation described combines humans and large language models (LLMs) to ideate on increasingly complex topics. A promising real-time collection tool called Polis is examined to facilitate ACI, including case studies from citizen engagement projects in Taiwan and Bowling Green, Kentucky. The authors discuss three challenges to consider when designing an ACI experiment: topic selection, participant selection, and evaluation of results. The paper concludes that researchers should address these challenges to conduct empirical studies of ACI in collaborative ideation.
An Evaluation of Link Performance Based on Rainfall Attenuation for a LEO Communication Satellite Constellation Over Africa
Mar 31, 2023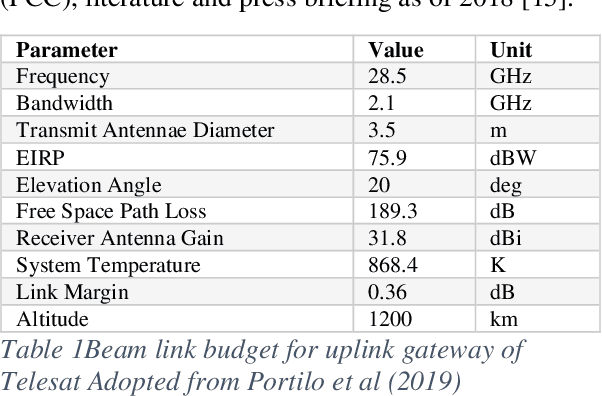
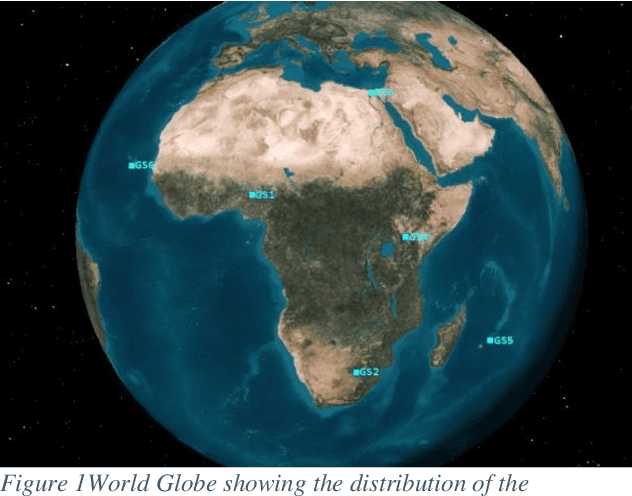
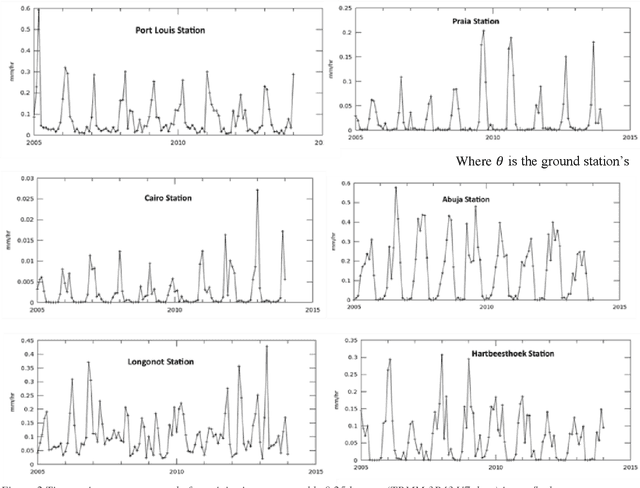
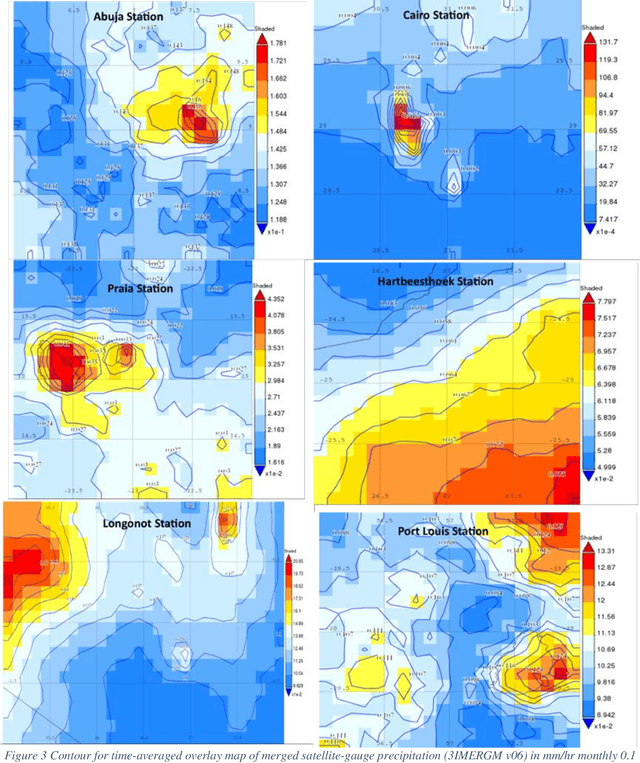
In this paper, we apply the ITU-R P.618-8 model with data from the ITU-R P.837-7, Tropical Rain Measuring Mission (TRMM) and Global Precipitation Mission (GPM) satellite to determine the level of attenuation and available link margin for a LEO system such as Telesat. The specific and predicted attenuation for chosen six candidate ground stations (Abuja, Hartbeesthoek, Cairo, Longonot, Port Louis and Praia) is computed and results presented for 0.001%-1% unavailability time in a year. Setting a link margin of 0.36dB, the available link margin and the best candidate ground station for a LEO system such as Telesat is determined. The approach used can be implemented for other potential ground stations and LEO communication systems over Africa.
SuperpixelGraph: Semi-automatic generation of building footprint through semantic-sensitive superpixel and neural graph networks
Apr 12, 2023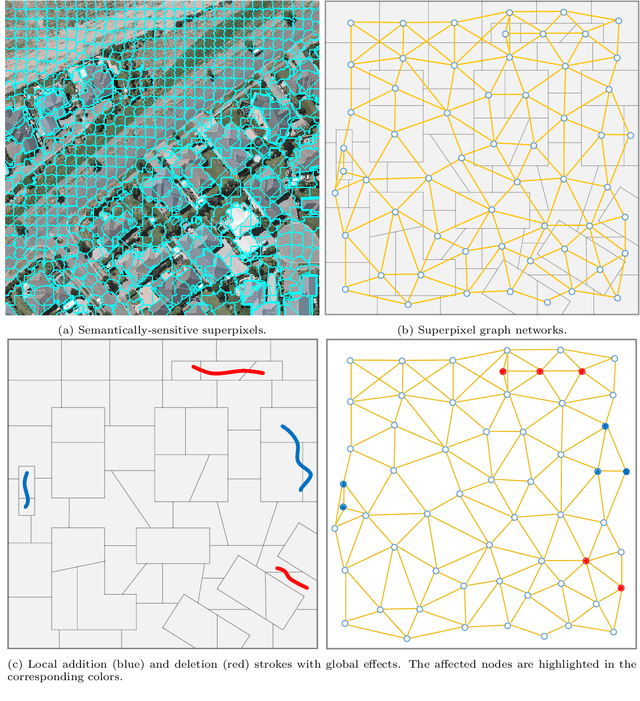
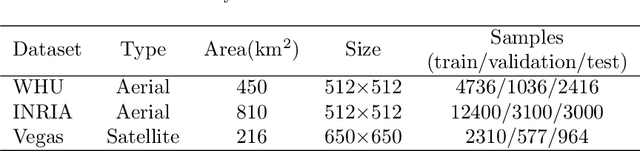
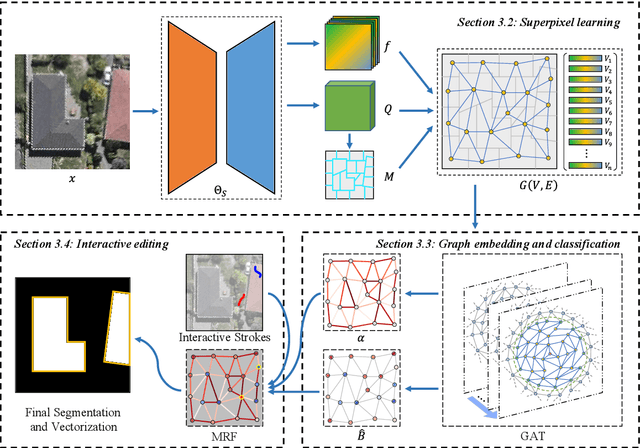
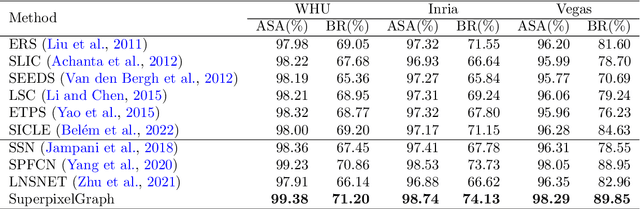
Most urban applications necessitate building footprints in the form of concise vector graphics with sharp boundaries rather than pixel-wise raster images. This need contrasts with the majority of existing methods, which typically generate over-smoothed footprint polygons. Editing these automatically produced polygons can be inefficient, if not more time-consuming than manual digitization. This paper introduces a semi-automatic approach for building footprint extraction through semantically-sensitive superpixels and neural graph networks. Drawing inspiration from object-based classification techniques, we first learn to generate superpixels that are not only boundary-preserving but also semantically-sensitive. The superpixels respond exclusively to building boundaries rather than other natural objects, while simultaneously producing semantic segmentation of the buildings. These intermediate superpixel representations can be naturally considered as nodes within a graph. Consequently, graph neural networks are employed to model the global interactions among all superpixels and enhance the representativeness of node features for building segmentation. Classical approaches are utilized to extract and regularize boundaries for the vectorized building footprints. Utilizing minimal clicks and straightforward strokes, we efficiently accomplish accurate segmentation outcomes, eliminating the necessity for editing polygon vertices. Our proposed approach demonstrates superior precision and efficacy, as validated by experimental assessments on various public benchmark datasets. We observe a 10\% enhancement in the metric for superpixel clustering and an 8\% increment in vector graphics evaluation, when compared with established techniques. Additionally, we have devised an optimized and sophisticated pipeline for interactive editing, poised to further augment the overall quality of the results.