 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DetCLIPv2: Scalable Open-Vocabulary Object Detection Pre-training via Word-Region Alignment
Apr 10, 2023


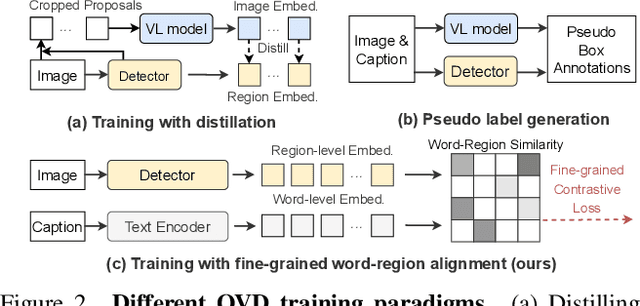
This paper presents DetCLIPv2, an efficient and scalable training framework that incorporates large-scale image-text pairs to achieve open-vocabulary object detection (OVD). Unlike previous OVD frameworks that typically rely on a pre-trained vision-language model (e.g., CLIP) or exploit image-text pairs via a pseudo labeling process, DetCLIPv2 directly learns the fine-grained word-region alignment from massive image-text pairs in an end-to-end manner. To accomplish this, we employ a maximum word-region similarity between region proposals and textual words to guide the contrastive objective. To enable the model to gain localization capability while learning broad concepts, DetCLIPv2 is trained with a hybrid supervision from detection, grounding and image-text pair data under a unified data formulation. By jointly training with an alternating scheme and adopting low-resolution input for image-text pairs, DetCLIPv2 exploits image-text pair data efficiently and effectively: DetCLIPv2 utilizes 13X more image-text pairs than DetCLIP with a similar training time and improves performance. With 13M image-text pairs for pre-training, DetCLIPv2 demonstrates superior open-vocabulary detection performance, e.g., DetCLIPv2 with Swin-T backbone achieves 40.4% zero-shot AP on the LVIS benchmark, which outperforms previous works GLIP/GLIPv2/DetCLIP by 14.4/11.4/4.5% AP, respectively, and even beats its fully-supervised counterpart by a large margin.
Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
Apr 10, 2023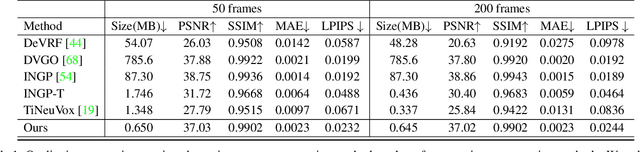
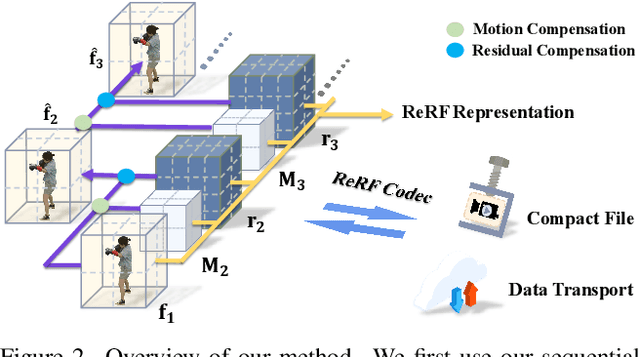
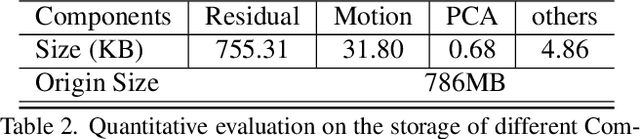
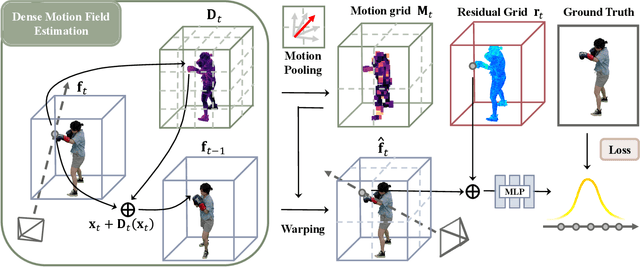
The success of the Neural Radiance Fields (NeRFs) for modeling and free-view rendering static objects has inspired numerous attempts on dynamic scenes. Current techniques that utilize neural rendering for facilitating free-view videos (FVVs) are restricted to either offline rendering or are capable of processing only brief sequences with minimal motion. In this paper, we present a novel technique, Residual Radiance Field or ReRF, as a highly compact neural representation to achieve real-time FVV rendering on long-duration dynamic scenes. ReRF explicitly models the residual information between adjacent timestamps in the spatial-temporal feature space, with a global coordinate-based tiny MLP as the feature decoder. Specifically, ReRF employs a compact motion grid along with a residual feature grid to exploit inter-frame feature similarities. We show such a strategy can handle large motions without sacrificing quality. We further present a sequential training scheme to maintain the smoothness and the sparsity of the motion/residual grids. Based on ReRF, we design a special FVV codec that achieves three orders of magnitudes compression rate and provides a companion ReRF player to support online streaming of long-duration FVVs of dynamic scenes. Extensive experiments demonstrate the effectiveness of ReRF for compactly representing dynamic radiance fields, enabling an unprecedented free-viewpoint viewing experience in speed and quality.
Binary Latent Diffusion
Apr 10, 2023

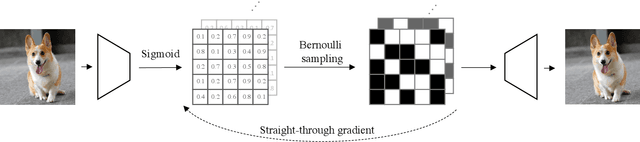
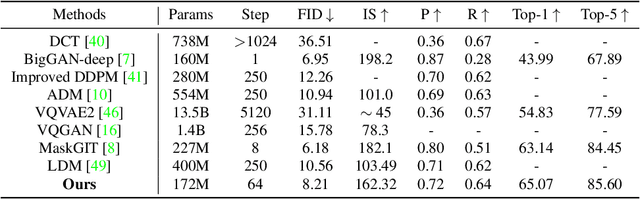
In this paper, we show that a binary latent space can be explored for compact yet expressive image representations. We model the bi-directional mappings between an image and the corresponding latent binary representation by training an auto-encoder with a Bernoulli encoding distribution. On the one hand, the binary latent space provides a compact discrete image representation of which the distribution can be modeled more efficiently than pixels or continuous latent representations. On the other hand, we now represent each image patch as a binary vector instead of an index of a learned cookbook as in discrete image representations with vector quantization. In this way, we obtain binary latent representations that allow for better image quality and high-resolution image representations without any multi-stage hierarchy in the latent space. In this binary latent space, images can now be generated effectively using a binary latent diffusion model tailored specifically for modeling the prior over the binary image representations. We present both conditional and unconditional image generation experiments with multiple datasets, and show that the proposed method performs comparably to state-of-the-art methods while dramatically improving the sampling efficiency to as few as 16 steps without using any test-time acceleration. The proposed framework can also be seamlessly scaled to $1024 \times 1024$ high-resolution image generation without resorting to latent hierarchy or multi-stage refinements.
First-order methods for Stochastic Variational Inequality problems with Function Constraints
Apr 10, 2023
The monotone Variational Inequality (VI) is an important problem in machine learning. In numerous instances, the VI problems are accompanied by function constraints which can possibly be data-driven, making the projection operator challenging to compute. In this paper, we present novel first-order methods for function constrained VI (FCVI) problem under various settings, including smooth or nonsmooth problems with a stochastic operator and/or stochastic constraints. First, we introduce the~{\texttt{OpConEx}} method and its stochastic variants, which employ extrapolation of the operator and constraint evaluations to update the variables and the Lagrangian multipliers. These methods achieve optimal operator or sample complexities when the FCVI problem is either (i) deterministic nonsmooth, or (ii) stochastic, including smooth or nonsmooth stochastic constraints. Notably, our algorithms are simple single-loop procedures and do not require the knowledge of Lagrange multipliers to attain these complexities. Second, to obtain the optimal operator complexity for smooth deterministic problems, we present a novel single-loop Adaptive Lagrangian Extrapolation~(\texttt{AdLagEx}) method that can adaptively search for and explicitly bound the Lagrange multipliers. Furthermore, we show that all of our algorithms can be easily extended to saddle point problems with coupled function constraints, hence achieving similar complexity results for the aforementioned cases. To our best knowledge, many of these complexities are obtained for the first time in the literature.
MHfit: Mobile Health Data for Predicting Athletics Fitness Using Machine Learning
Apr 10, 2023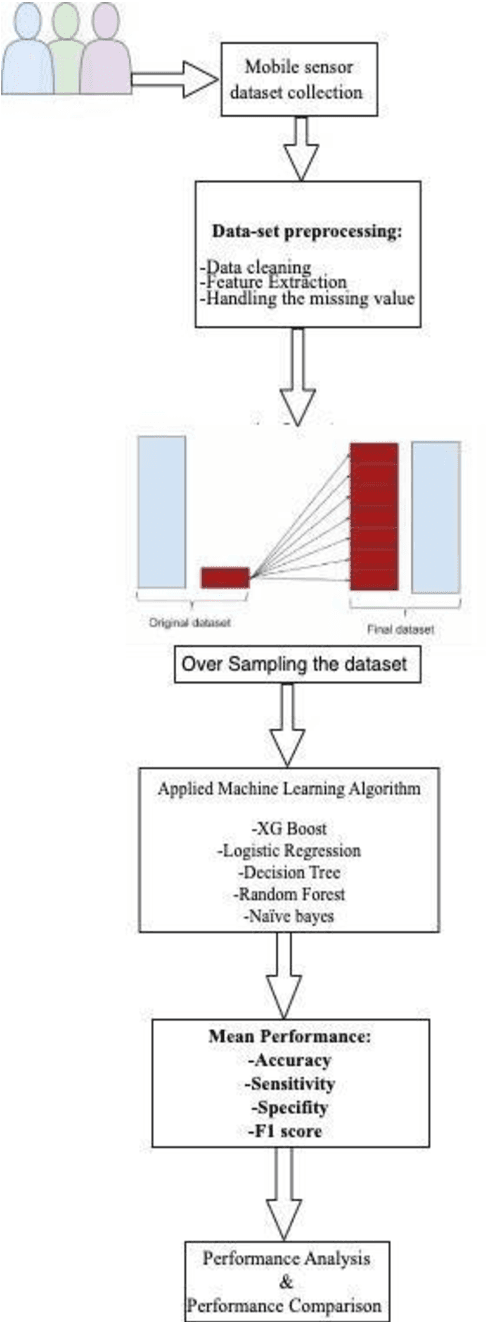
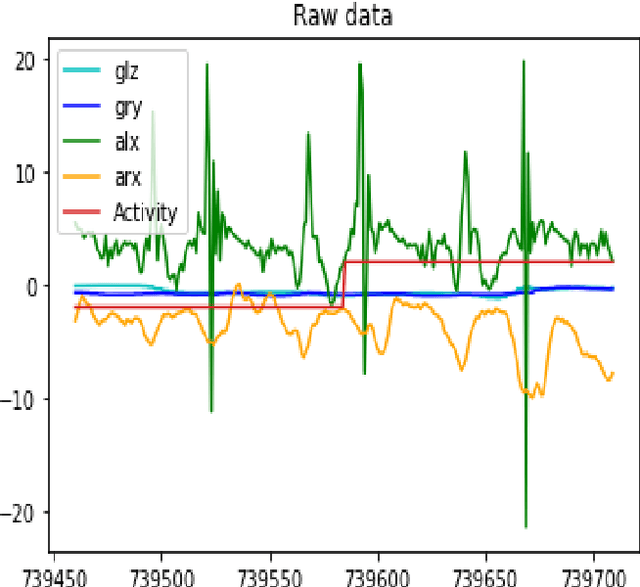
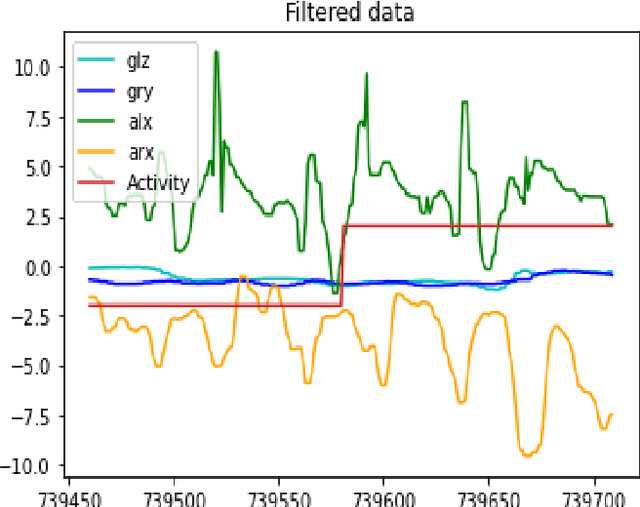
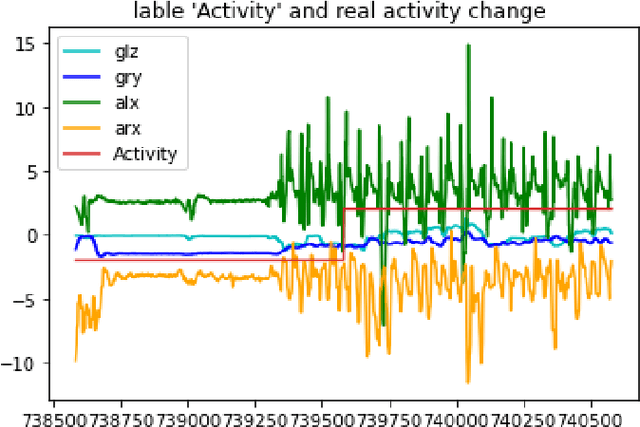
Mobile phones and other electronic gadgets or devices have aided in collecting data without the need for data entry. This paper will specifically focus on Mobile health data. Mobile health data use mobile devices to gather clinical health data and track patient vitals in real-time. Our study is aimed to give decisions for small or big sports teams on whether one athlete good fit or not for a particular game with the compare several machine learning algorithms to predict human behavior and health using the data collected from mobile devices and sensors placed on patients. In this study, we have obtained the dataset from a similar study done on mhealth. The dataset contains vital signs recordings of ten volunteers from different backgrounds. They had to perform several physical activities with a sensor placed on their bodies. Our study used 5 machine learning algorithms (XGBoost, Naive Bayes, Decision Tree, Random Forest, and Logistic Regression) to analyze and predict human health behavior. XGBoost performed better compared to the other machine learning algorithms and achieved 95.2% accuracy, 99.5% in sensitivity, 99.5% in specificity, and 99.66% in F1 score. Our research indicated a promising future in mhealth being used to predict human behavior and further research and exploration need to be done for it to be available for commercial use specifically in the sports industry.
Physics-informed neural networks in the recreation of hydrodynamic simulations from dark matter
Mar 24, 2023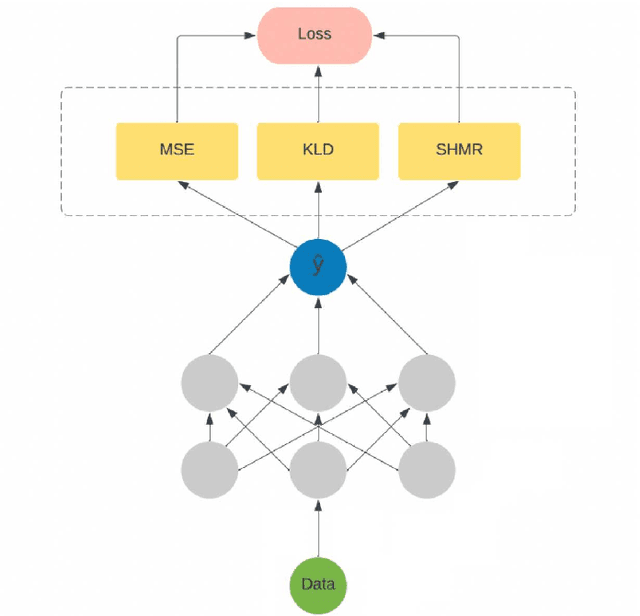
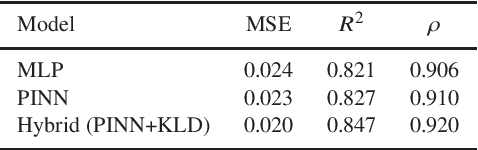
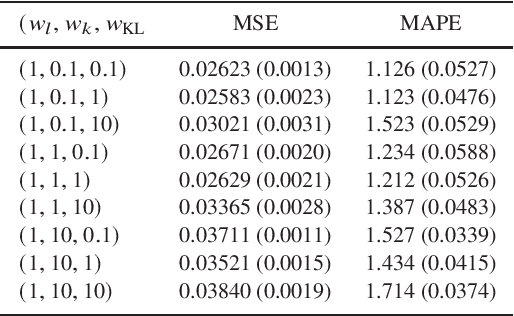
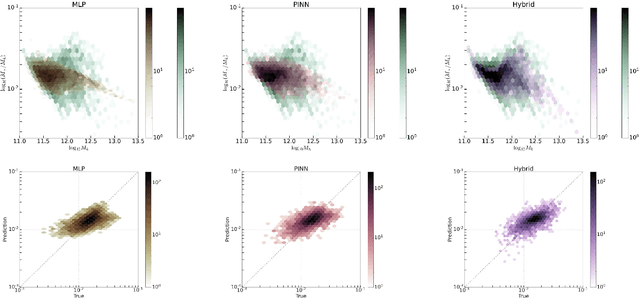
Physics-informed neural networks have emerged as a coherent framework for building predictive models that combine statistical patterns with domain knowledge. The underlying notion is to enrich the optimization loss function with known relationships to constrain the space of possible solutions. Hydrodynamic simulations are a core constituent of modern cosmology, while the required computations are both expensive and time-consuming. At the same time, the comparatively fast simulation of dark matter requires fewer resources, which has led to the emergence of machine learning algorithms for baryon inpainting as an active area of research; here, recreating the scatter found in hydrodynamic simulations is an ongoing challenge. This paper presents the first application of physics-informed neural networks to baryon inpainting by combining advances in neural network architectures with physical constraints, injecting theory on baryon conversion efficiency into the model loss function. We also introduce a punitive prediction comparison based on the Kullback-Leibler divergence, which enforces scatter reproduction. By simultaneously extracting the complete set of baryonic properties for the Simba suite of cosmological simulations, our results demonstrate improved accuracy of baryonic predictions based on dark matter halo properties, successful recovery of the fundamental metallicity relation, and retrieve scatter that traces the target simulation's distribution.
Valuing Players Over Time
Sep 08, 2022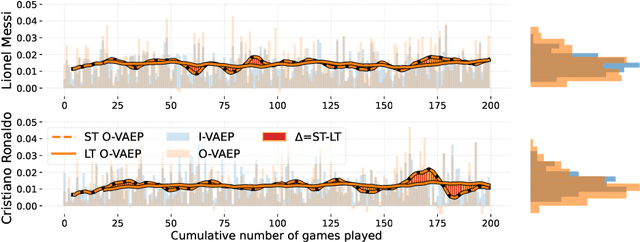
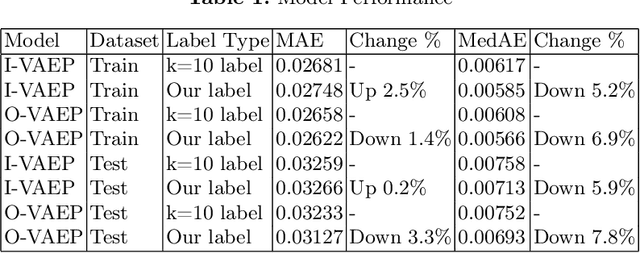
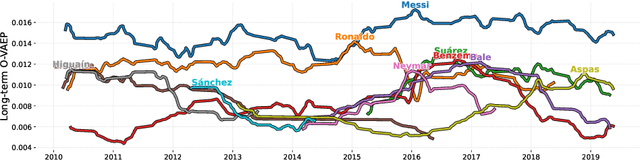
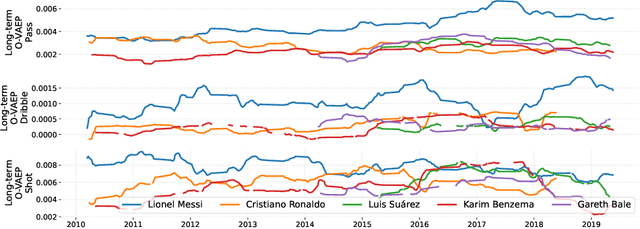
In soccer (or association football), players quickly go from heroes to zeroes, or vice-versa. Performance is not a static measure but a somewhat volatile one. Analyzing performance as a time series rather than a stationary point in time is crucial to making better decisions. This paper introduces and explores I-VAEP and O-VAEP models to evaluate actions and rate players' intention and execution. Then, we analyze these ratings over time and propose use cases to fundament our option of treating player ratings as a continuous problem. As a result, we present who were the best players and how their performance evolved, define volatility metrics to measure a player's consistency, and build a player development curve to assist decision-making.
Extending DNN-based Multiplicative Masking to Deep Subband Filtering for Improved Dereverberation
Mar 08, 2023
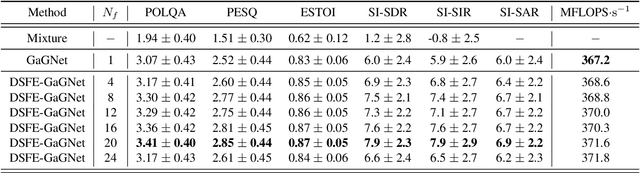
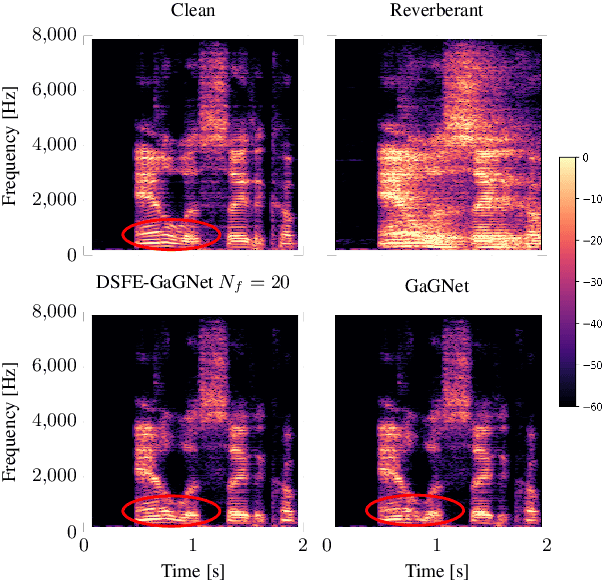
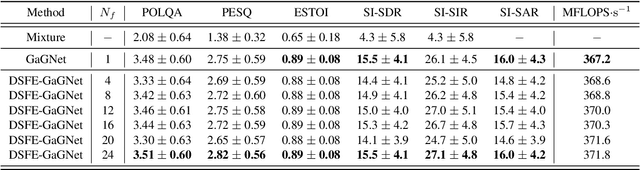
In this paper, we present a scheme for extending deep neural network-based multiplicative maskers to deep subband filters for speech restoration in the time-frequency domain. The resulting method can be generically applied to any deep neural network providing masks in the time-frequency domain, while requiring only few more trainable parameters and a computational overhead that is negligible for state-of-the-art neural networks. We demonstrate that the resulting deep subband filtering scheme outperforms multiplicative masking for dereverberation, while leaving the denoising performance virtually the same. We argue that this is because deep subband filtering in the time-frequency domain fits the subband approximation often assumed in the dereverberation literature, whereas multiplicative masking corresponds to the narrowband approximation generally employed in denoising.
LMDA-Net:A lightweight multi-dimensional attention network for general EEG-based brain-computer interface paradigms and interpretability
Mar 29, 2023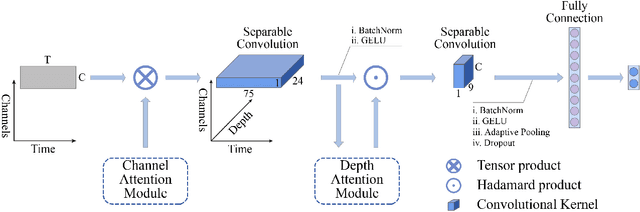
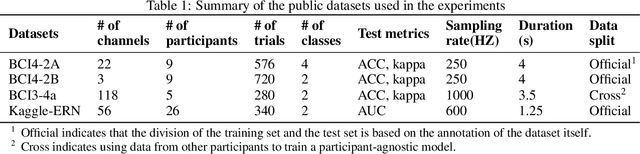
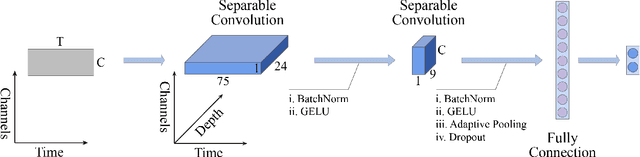
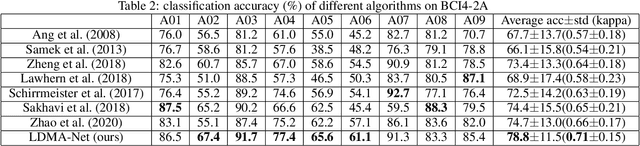
EEG-based recognition of activities and states involves the use of prior neuroscience knowledge to generate quantitative EEG features, which may limit BCI performance. Although neural network-based methods can effectively extract features, they often encounter issues such as poor generalization across datasets, high predicting volatility, and low model interpretability. Hence, we propose a novel lightweight multi-dimensional attention network, called LMDA-Net. By incorporating two novel attention modules designed specifically for EEG signals, the channel attention module and the depth attention module, LMDA-Net can effectively integrate features from multiple dimensions, resulting in improved classification performance across various BCI tasks. LMDA-Net was evaluated on four high-impact public datasets, including motor imagery (MI) and P300-Speller paradigms, and was compared with other representative models. The experimental results demonstrate that LMDA-Net outperforms other representative methods in terms of classification accuracy and predicting volatility, achieving the highest accuracy in all datasets within 300 training epochs. Ablation experiments further confirm the effectiveness of the channel attention module and the depth attention module. To facilitate an in-depth understanding of the features extracted by LMDA-Net, we propose class-specific neural network feature interpretability algorithms that are suitable for event-related potentials (ERPs) and event-related desynchronization/synchronization (ERD/ERS). By mapping the output of the specific layer of LMDA-Net to the time or spatial domain through class activation maps, the resulting feature visualizations can provide interpretable analysis and establish connections with EEG time-spatial analysis in neuroscience. In summary, LMDA-Net shows great potential as a general online decoding model for various EEG tasks.
TEMPERA: Test-Time Prompting via Reinforcement Learning
Nov 21, 2022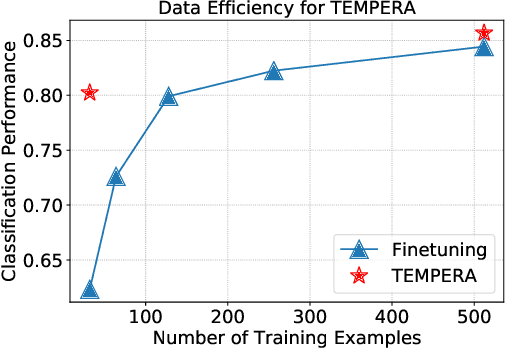


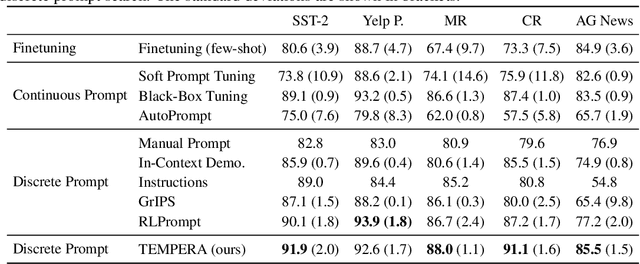
Careful prompt design is critical to the use of large language models in zero-shot or few-shot learning. As a consequence, there is a growing interest in automated methods to design optimal prompts. In this work, we propose Test-time Prompt Editing using Reinforcement learning (TEMPERA). In contrast to prior prompt generation methods, TEMPERA can efficiently leverage prior knowledge, is adaptive to different queries and provides an interpretable prompt for every query. To achieve this, we design a novel action space that allows flexible editing of the initial prompts covering a wide set of commonly-used components like instructions, few-shot exemplars, and verbalizers. The proposed method achieves significant gains compared with recent SoTA approaches like prompt tuning, AutoPrompt, and RLPrompt, across a variety of tasks including sentiment analysis, topic classification, natural language inference, and reading comprehension. Our method achieves 5.33x on average improvement in sample efficiency when compared to the traditional fine-tuning methods.