 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Equivalence of Additive and Multiplicative Coupling in Spiking Neural Networks
Apr 11, 2023
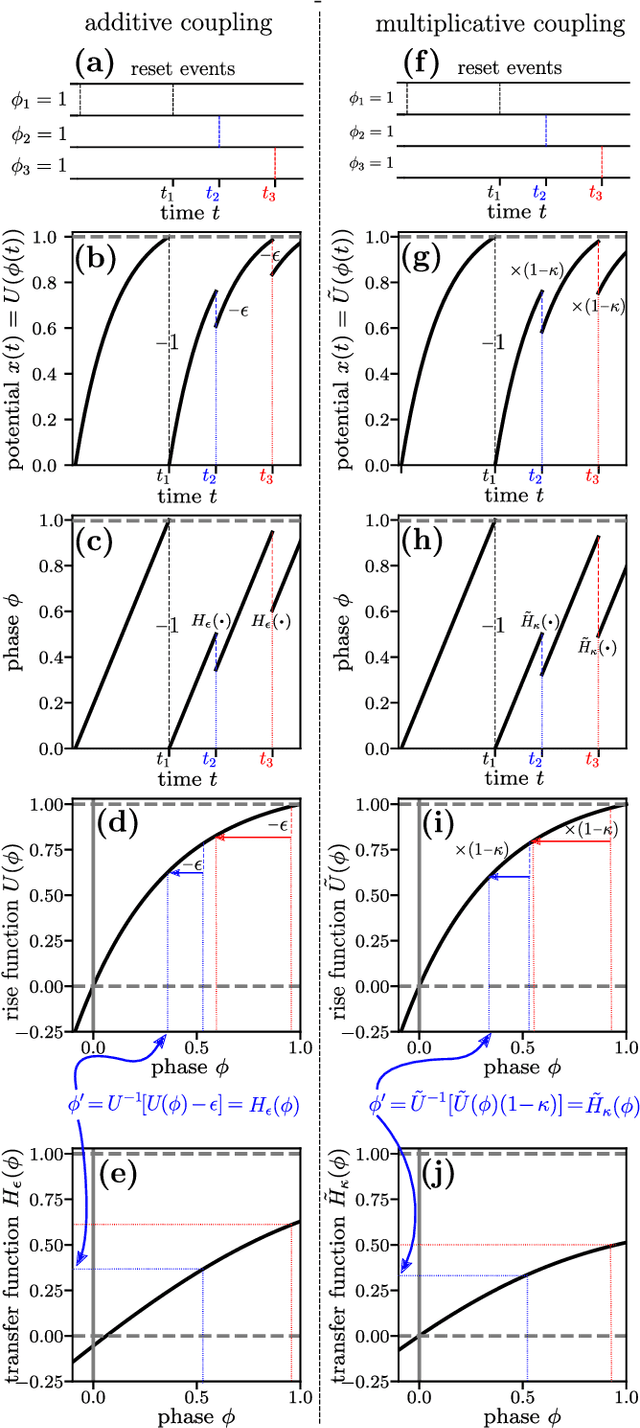
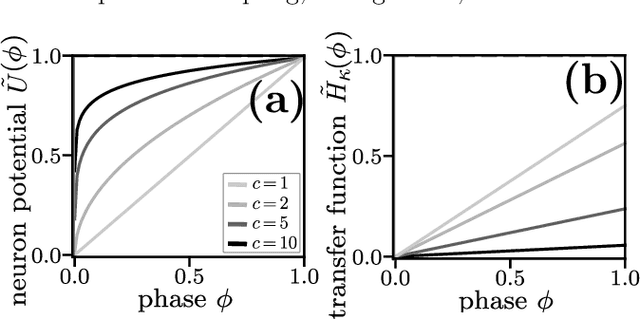
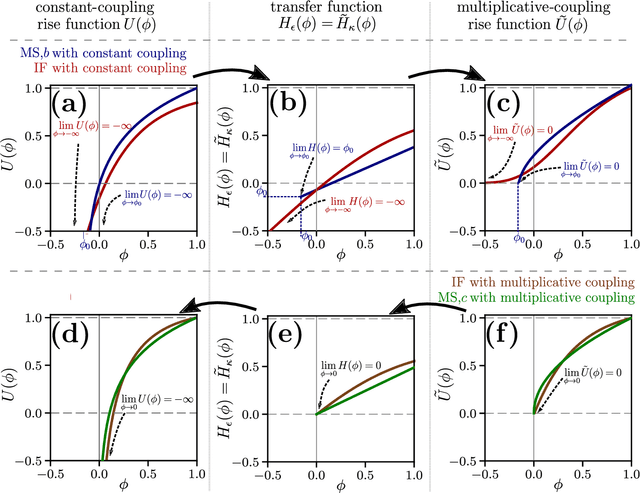
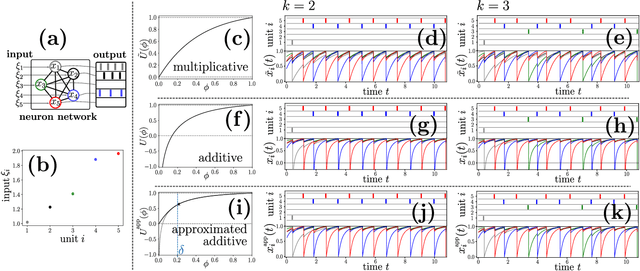
Spiking neural network models characterize the emergent collective dynamics of circuits of biological neurons and help engineer neuro-inspired solutions across fields. Most dynamical systems' models of spiking neural networks typically exhibit one of two major types of interactions: First, the response of a neuron's state variable to incoming pulse signals (spikes) may be additive and independent of its current state. Second, the response may depend on the current neuron's state and multiply a function of the state variable. Here we reveal that spiking neural network models with additive coupling are equivalent to models with multiplicative coupling for simultaneously modified intrinsic neuron time evolution. As a consequence, the same collective dynamics can be attained by state-dependent multiplicative and constant (state-independent) additive coupling. Such a mapping enables the transfer of theoretical insights between spiking neural network models with different types of interaction mechanisms as well as simpler and more effective engineering applications.
TrajFlow: Learning the Distribution over Trajectories
Apr 11, 2023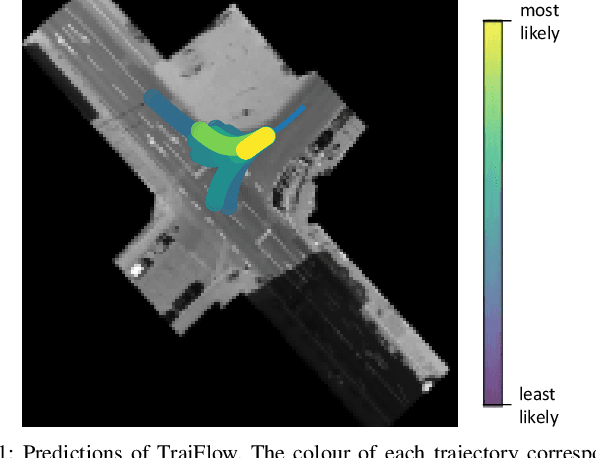
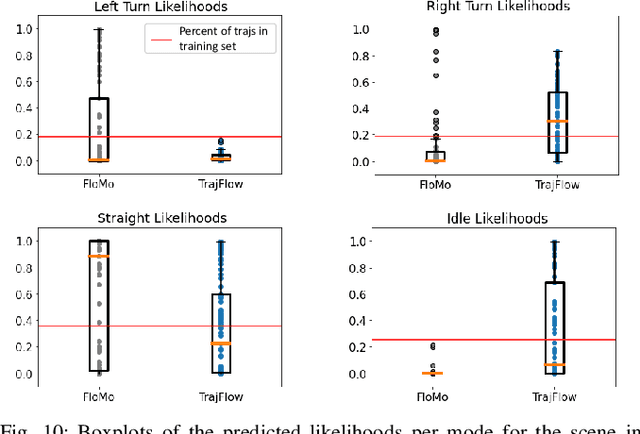
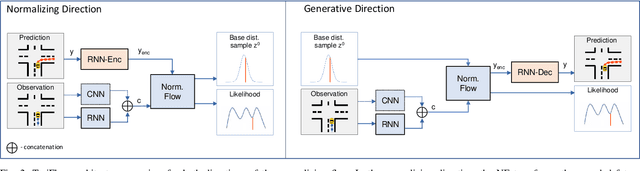
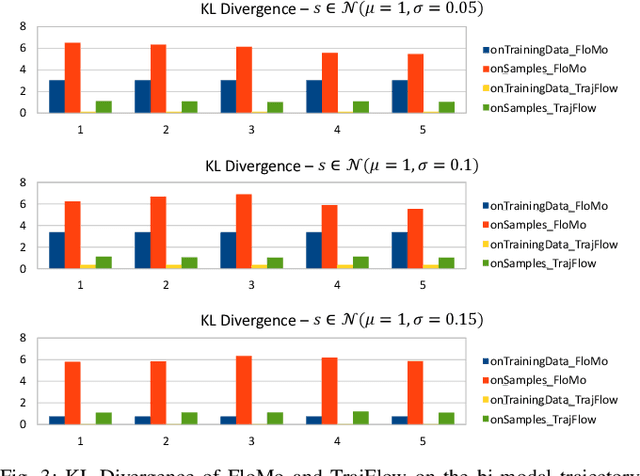
Predicting the future behaviour of people remains an open challenge for the development of risk-aware autonomous vehicles. An important aspect of this challenge is effectively capturing the uncertainty which is inherent to human behaviour. This paper studies an approach for probabilistic motion forecasting with improved accuracy in the predicted sample likelihoods. We are able to learn multi-modal distributions over the motions of an agent solely from data, while also being able to provide predictions in real-time. Our approach achieves state-of-the-art results on the inD dataset when evaluated with the standard metrics employed for motion forecasting. Furthermore, our approach also achieves state-of-the-art results when evaluated with respect to the likelihoods it assigns to its generated trajectories. Evaluations on artificial datasets indicate that the distributions learned by our model closely correspond to the true distributions observed in data and are not as prone towards being over-confident in a single outcome in the face of uncertainty.
Revisiting Single-gated Mixtures of Experts
Apr 11, 2023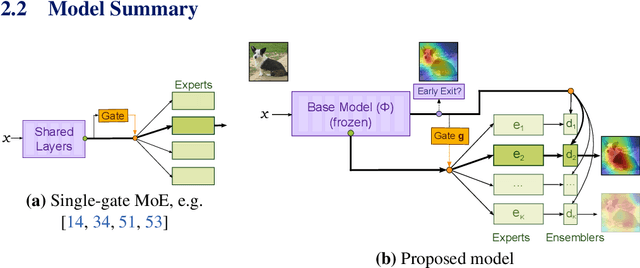
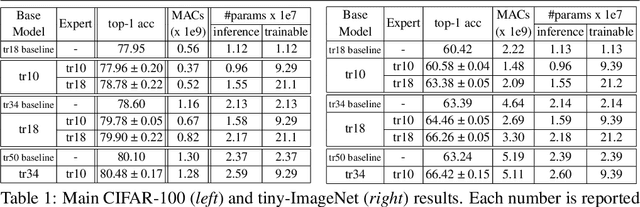
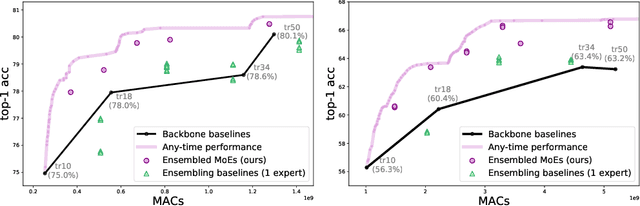
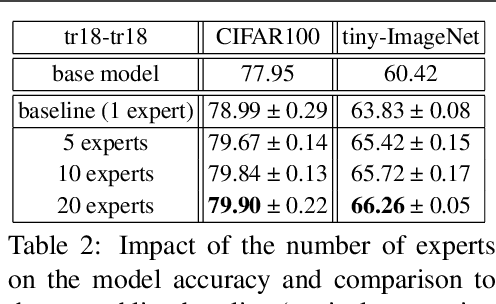
Mixture of Experts (MoE) are rising in popularity as a means to train extremely large-scale models, yet allowing for a reasonable computational cost at inference time. Recent state-of-the-art approaches usually assume a large number of experts, and require training all experts jointly, which often lead to training instabilities such as the router collapsing In contrast, in this work, we propose to revisit the simple single-gate MoE, which allows for more practical training. Key to our work are (i) a base model branch acting both as an early-exit and an ensembling regularization scheme, (ii) a simple and efficient asynchronous training pipeline without router collapse issues, and finally (iii) a per-sample clustering-based initialization. We show experimentally that the proposed model obtains efficiency-to-accuracy trade-offs comparable with other more complex MoE, and outperforms non-mixture baselines. This showcases the merits of even a simple single-gate MoE, and motivates further exploration in this area.
Age-Aware Gossiping in Network Topologies
Apr 06, 2023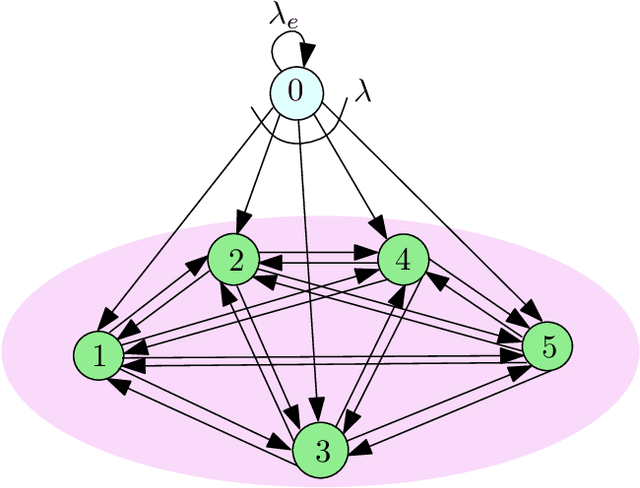
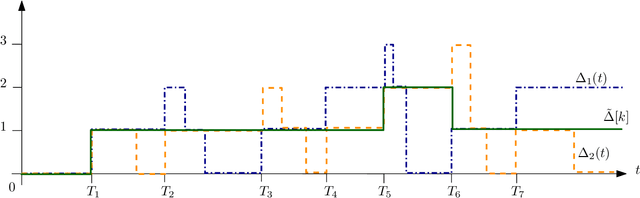
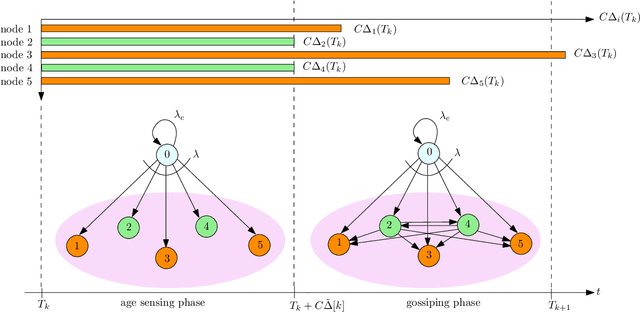
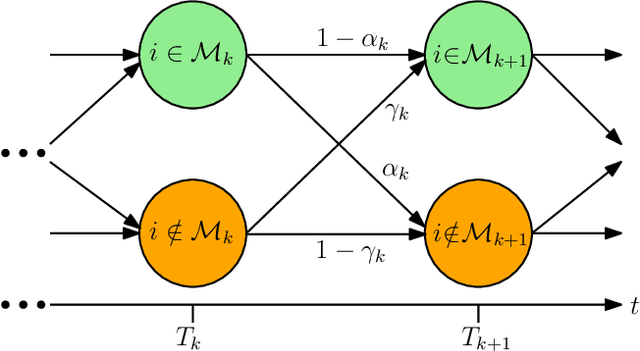
We consider a fully-connected wireless gossip network which consists of a source and $n$ receiver nodes. The source updates itself with a Poisson process and also sends updates to the nodes as Poisson arrivals. Upon receiving the updates, the nodes update their knowledge about the source. The nodes gossip the data among themselves in the form of Poisson arrivals to disperse their knowledge about the source. The total gossiping rate is bounded by a constraint. The goal of the network is to be as timely as possible with the source. We propose a scheme which we coin \emph{age sense updating multiple access in networks (ASUMAN)}, which is a distributed opportunistic gossiping scheme, where after each time the source updates itself, each node waits for a time proportional to its current age and broadcasts a signal to the other nodes of the network. This allows the nodes in the network which have higher age to remain silent and only the low-age nodes to gossip, thus utilizing a significant portion of the constrained total gossip rate. We calculate the average age for a typical node in such a network with symmetric settings, and show that the theoretical upper bound on the age scales as $O(1)$. ASUMAN, with an average age of $O(1)$, offers significant gains compared to a system where the nodes just gossip blindly with a fixed update rate, in which case the age scales as $O(\log n)$. Further, we analyzed the performance of ASUMAN for fractional, finitely connected, sublinear and hierarchical cluster networks. Finally, we show that the $O(1)$ age scaling can be extended to asymmetric settings as well. We give an example of power law arrivals, where nodes' ages scale differently but follow the $O(1)$ bound.
RFAConv: Innovating Spatial Attention and Standard Convolutional Operation
Apr 18, 2023
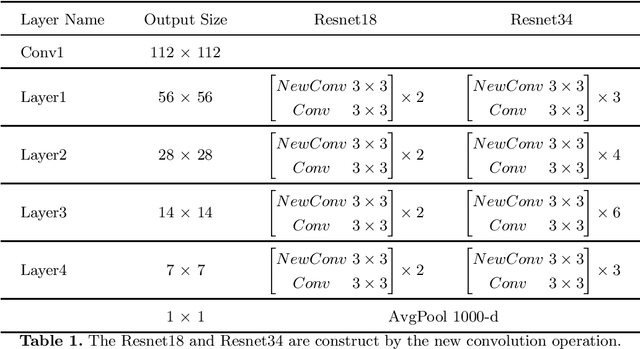
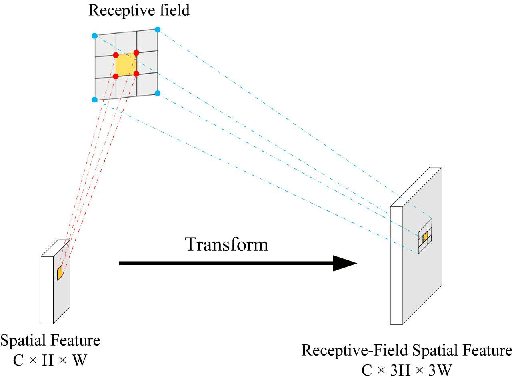
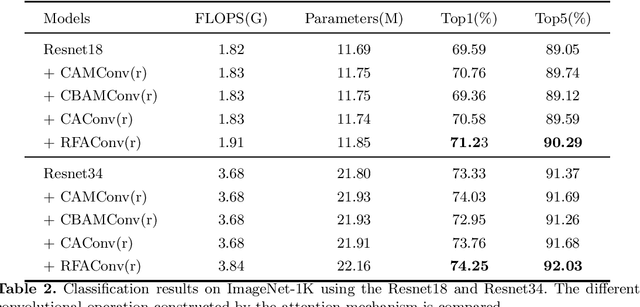
Spatial attention has been widely used to improve the performance of convolutional neural networks. However, it has certain limitations. In this paper, we propose a new perspective on the effectiveness of spatial attention, which is that the spatial attention mechanism essentially solves the problem of convolutional kernel parameter sharing. However, the information contained in the attention map generated by spatial attention is not sufficient for large-size convolutional kernels. Therefore, we propose a novel attention mechanism called Receptive-Field Attention (RFA). Existing spatial attention, such as Convolutional Block Attention Module (CBAM) and Coordinated Attention (CA) focus only on spatial features, which does not fully address the problem of convolutional kernel parameter sharing. In contrast, RFA not only focuses on the receptive-field spatial feature but also provides effective attention weights for large-size convolutional kernels. The Receptive-Field Attention convolutional operation (RFAConv), developed by RFA, represents a new approach to replace the standard convolution operation. It offers nearly negligible increment of computational cost and parameters, while significantly improving network performance. We conducted a series of experiments on ImageNet-1k, COCO, and VOC datasets to demonstrate the superiority of our approach. Of particular importance, we believe that it is time to shift focus from spatial features to receptive-field spatial features for current spatial attention mechanisms. In this way, we can further improve network performance and achieve even better results. The code and pre-trained models for the relevant tasks can be found at https://github.com/Liuchen1997/RFAConv.
Making Thermal Imaging More Equitable and Accurate: Resolving Solar Loading Biases
Apr 18, 2023
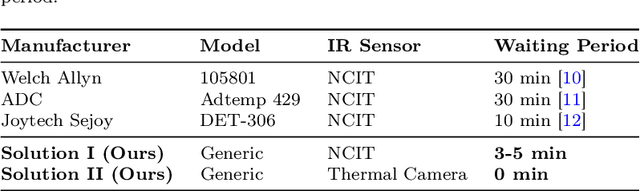
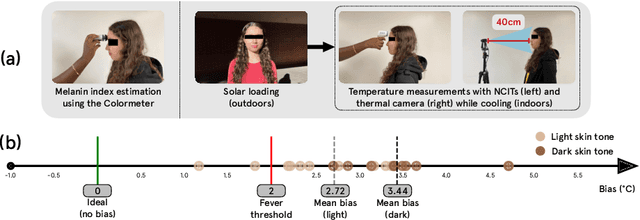

Thermal cameras and thermal point detectors are used to measure the temperature of human skin. These are important devices that are used everyday in clinical and mass screening settings, particularly in an epidemic. Unfortunately, despite the wide use of thermal sensors, the temperature estimates from thermal sensors do not work well in uncontrolled scene conditions. Previous work has studied the effect of wind and other environment factors on skin temperature, but has not considered the heating effect from sunlight, which is termed solar loading. Existing device manufacturers recommend that a subject who has been outdoors in sun re-acclimate to an indoor environment after a waiting period. The waiting period, up to 30 minutes, is insufficient for a rapid screening tool. Moreover, the error bias from solar loading is greater for darker skin tones since melanin absorbs solar radiation. This paper explores two approaches to address this problem. The first approach uses transient behavior of cooling to more quickly extrapolate the steady state temperature. A second approach explores the spatial modulation of solar loading, to propose single-shot correction with a wide-field thermal camera. A real world dataset comprising of thermal point, thermal image, subjective, and objective measurements of melanin is collected with statistical significance for the effect size observed. The single-shot correction scheme is shown to eliminate solar loading bias in the time of a typical frame exposure (33ms).
Safety Guaranteed Manipulation Based on Reinforcement Learning Planner and Model Predictive Control Actor
Apr 18, 2023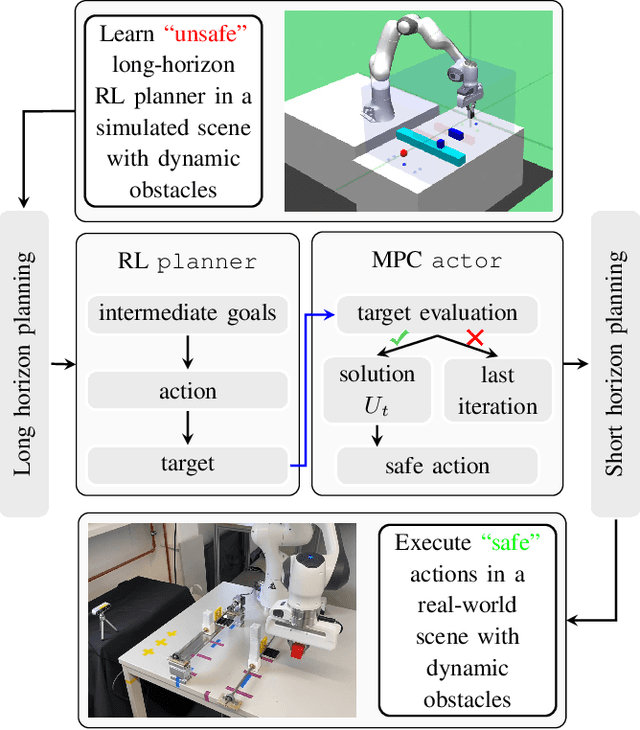
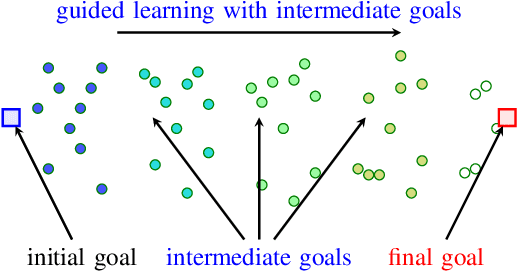
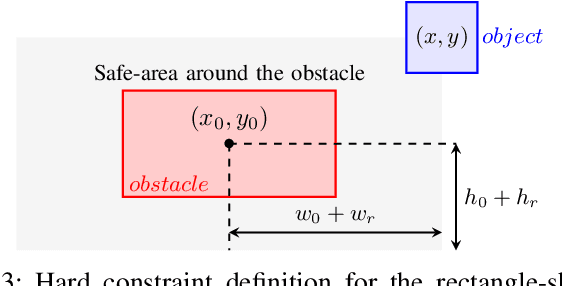

Deep reinforcement learning (RL) has been endowed with high expectations in tackling challenging manipulation tasks in an autonomous and self-directed fashion. Despite the significant strides made in the development of reinforcement learning, the practical deployment of this paradigm is hindered by at least two barriers, namely, the engineering of a reward function and ensuring the safety guaranty of learning-based controllers. In this paper, we address these challenging limitations by proposing a framework that merges a reinforcement learning \lstinline[columns=fixed]{planner} that is trained using sparse rewards with a model predictive controller (MPC) \lstinline[columns=fixed]{actor}, thereby offering a safe policy. On the one hand, the RL \lstinline[columns=fixed]{planner} learns from sparse rewards by selecting intermediate goals that are easy to achieve in the short term and promising to lead to target goals in the long term. On the other hand, the MPC \lstinline[columns=fixed]{actor} takes the suggested intermediate goals from the RL \lstinline[columns=fixed]{planner} as the input and predicts how the robot's action will enable it to reach that goal while avoiding any obstacles over a short period of time. We evaluated our method on four challenging manipulation tasks with dynamic obstacles and the results demonstrate that, by leveraging the complementary strengths of these two components, the agent can solve manipulation tasks in complex, dynamic environments safely with a $100\%$ success rate. Videos are available at \url{https://videoviewsite.wixsite.com/mpc-hgg}.
GUILGET: GUI Layout GEneration with Transformer
Apr 18, 2023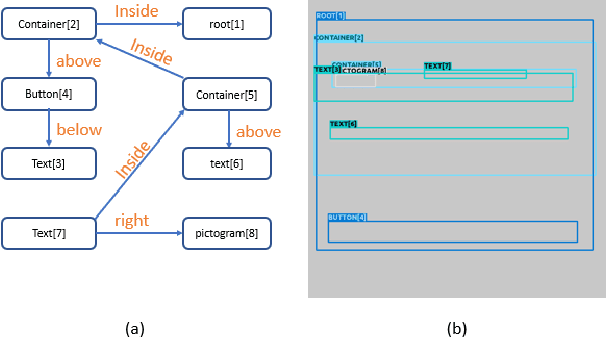

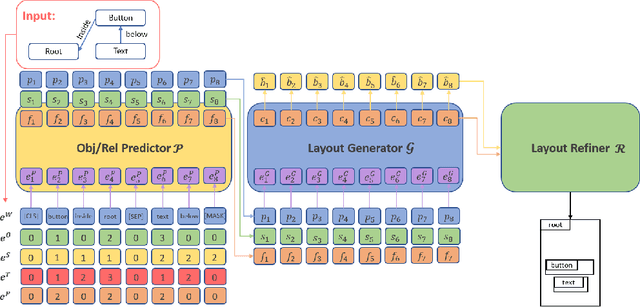
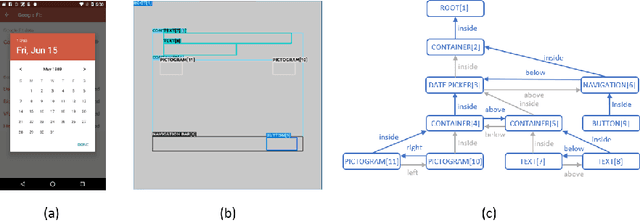
Sketching out Graphical User Interface (GUI) layout is part of the pipeline of designing a GUI and a crucial task for the success of a software application. Arranging all components inside a GUI layout manually is a time-consuming task. In order to assist designers, we developed a method named GUILGET to automatically generate GUI layouts from positional constraints represented as GUI arrangement graphs (GUI-AGs). The goal is to support the initial step of GUI design by producing realistic and diverse GUI layouts. The existing image layout generation techniques often cannot incorporate GUI design constraints. Thus, GUILGET needs to adapt existing techniques to generate GUI layouts that obey to constraints specific to GUI designs. GUILGET is based on transformers in order to capture the semantic in relationships between elements from GUI-AG. Moreover, the model learns constraints through the minimization of losses responsible for placing each component inside its parent layout, for not letting components overlap if they are inside the same parent, and for component alignment. Our experiments, which are conducted on the CLAY dataset, reveal that our model has the best understanding of relationships from GUI-AG and has the best performances in most of evaluation metrics. Therefore, our work contributes to improved GUI layout generation by proposing a novel method that effectively accounts for the constraints on GUI elements and paves the road for a more efficient GUI design pipeline.
Electromagnetic Interference Cancellation for RIS-Assisted Communications
Apr 10, 2023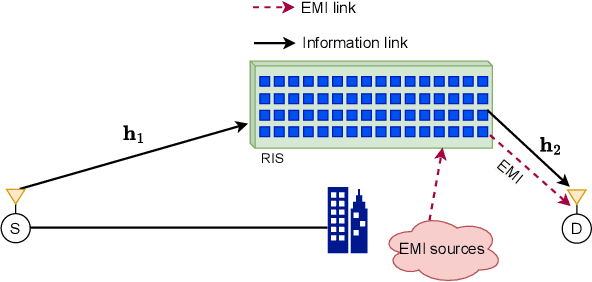
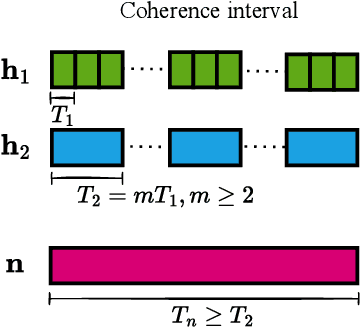
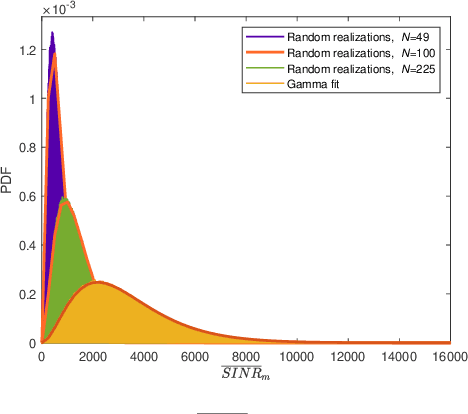
Reconfigurable intelligent surface (RIS)-empowered communication is an emerging technology that has recently received growing attention as a potential candidate for next-generation wireless communications. Although RISs have shown the potential of manipulating the wireless channel through passive beamforming, it is shown that they can also bring undesired side effects, such as reflecting the electromagnetic interference (EMI) from the surrounding environment to the receiver side. In this study, we propose a novel EMI cancellation scheme to mitigate the impact of the EMI by exploiting its special time-domain structure and considering a clever passive beamforming method at the RIS. Compared to its benchmark, computer simulations show that the proposed scheme achieves superior performance in terms of the average signal-to-interference-plus-noise ratio (SINR) and outage probability (OP), especially when the EMI power is comparable to the power of the information signal impinging on the RIS surface.
Anomalous Sound Detection using Audio Representation with Machine ID based Contrastive Learning Pretraining
Apr 10, 2023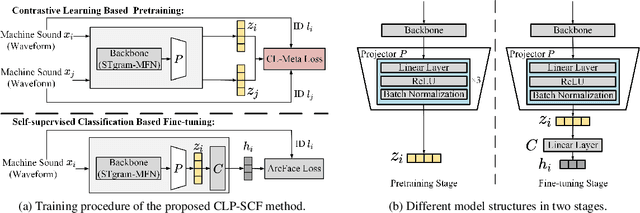
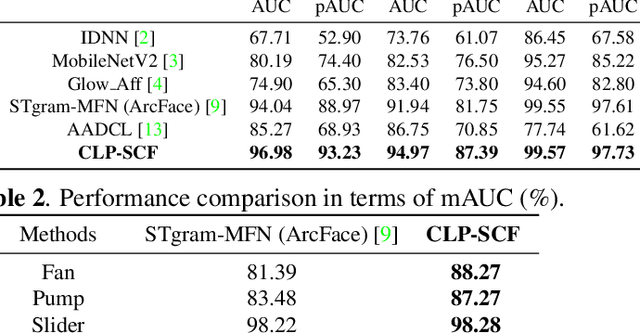
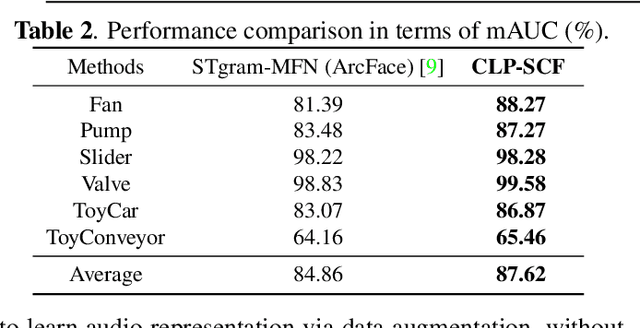
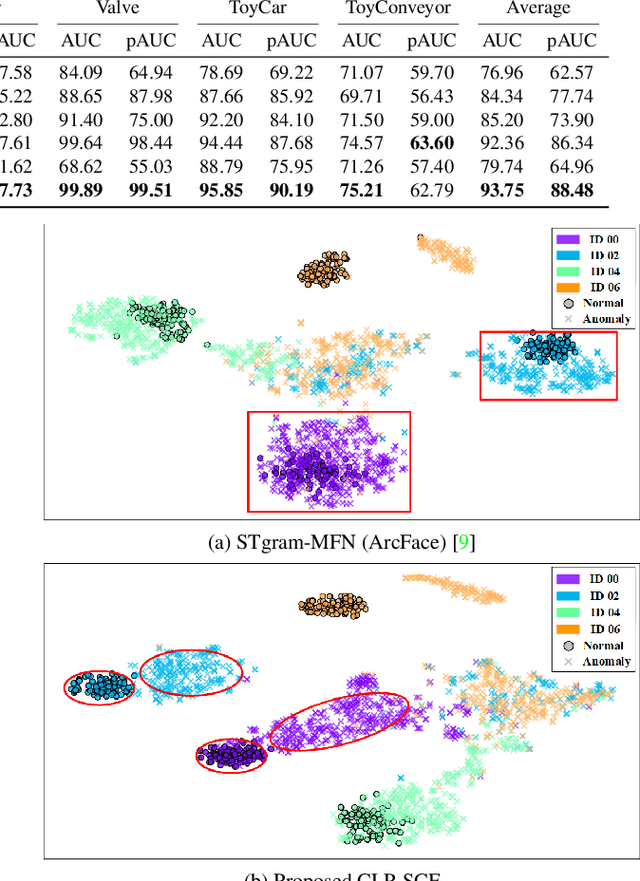
Existing contrastive learning methods for anomalous sound detection refine the audio representation of each audio sample by using the contrast between the samples' augmentations (e.g., with time or frequency masking). However, they might be biased by the augmented data, due to the lack of physical properties of machine sound, thereby limiting the detection performance. This paper uses contrastive learning to refine audio representations for each machine ID, rather than for each audio sample. The proposed two-stage method uses contrastive learning to pretrain the audio representation model by incorporating machine ID and a self-supervised ID classifier to fine-tune the learnt model, while enhancing the relation between audio features from the same ID. Experiments show that our method outperforms the state-of-the-art methods using contrastive learning or self-supervised classification in overall anomaly detection performance and stability on DCASE 2020 Challenge Task2 dataset.