 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Distributionally Robust Approach to Regret Optimal Control using the Wasserstein Distance
Apr 13, 2023
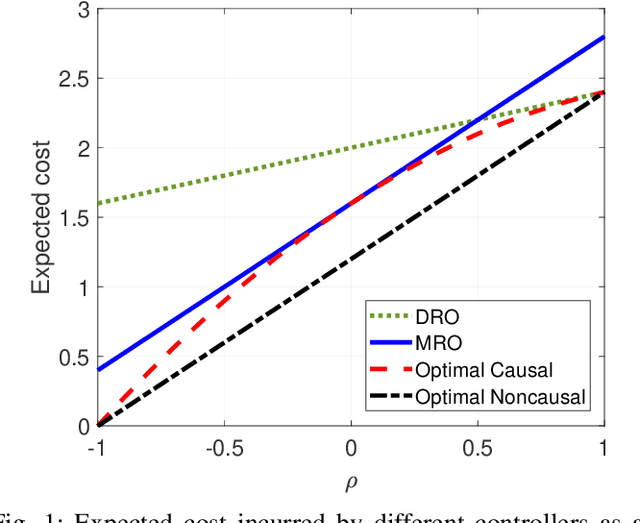
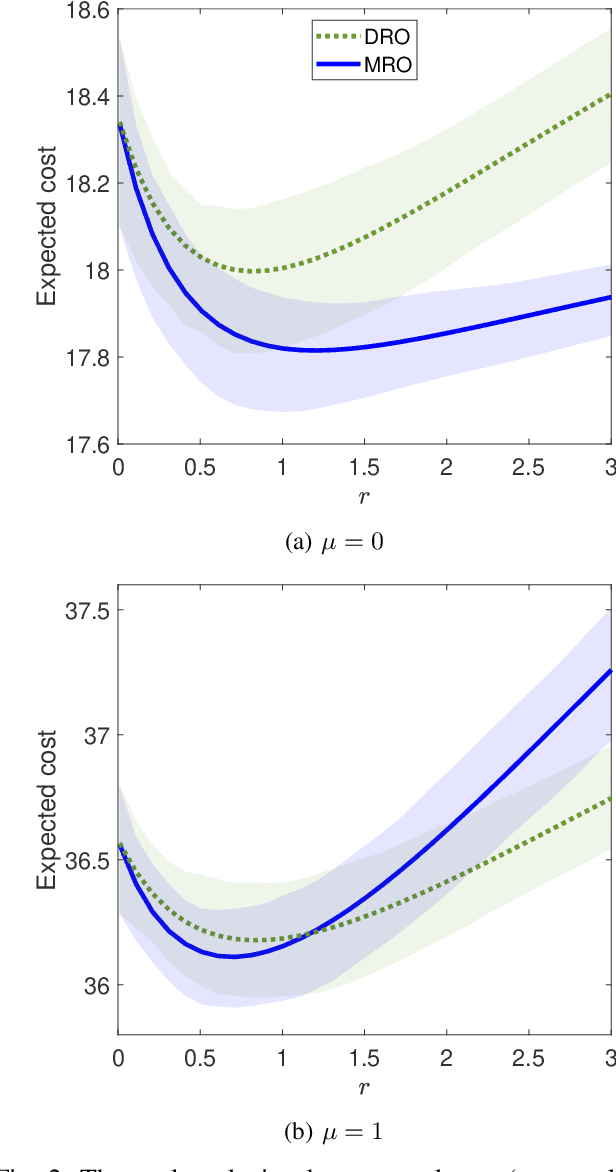

This paper proposes a distributionally robust approach to regret optimal control of discrete-time linear dynamical systems with quadratic costs subject to stochastic additive disturbance on the state process. The underlying probability distribution of the disturbance process is unknown, but assumed to lie in a given ball of distributions defined in terms of the type-2 Wasserstein distance. In this framework, strictly causal linear disturbance feedback controllers are designed to minimize the worst-case expected regret. The regret incurred by a controller is defined as the difference between the cost it incurs in response to a realization of the disturbance process and the cost incurred by the optimal noncausal controller which has perfect knowledge of the disturbance process realization at the outset. Building on a well-established duality theory for optimal transport problems, we show how to equivalently reformulate this minimax regret optimal control problem as a tractable semidefinite program. The equivalent dual reformulation also allows us to characterize a worst-case distribution achieving the worst-case expected regret in relation to the distribution at the center of the Wasserstein ball.
End-to-end codesign of Hessian-aware quantized neural networks for FPGAs and ASICs
Apr 13, 2023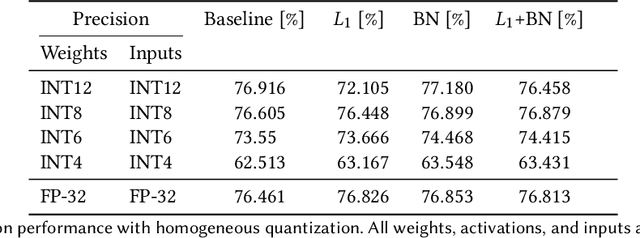
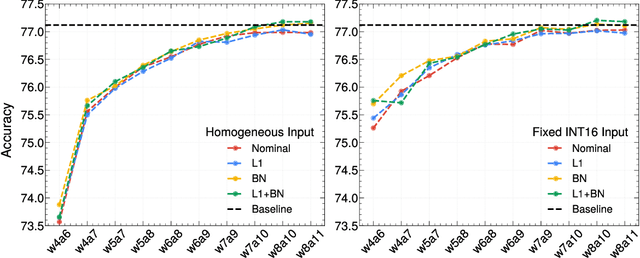
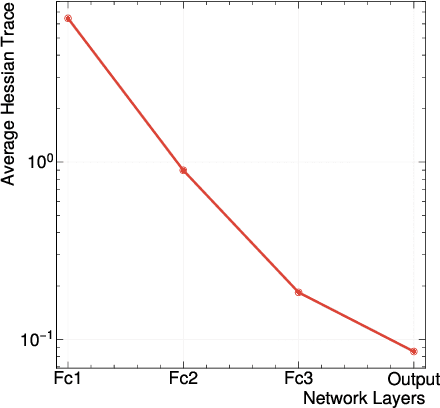
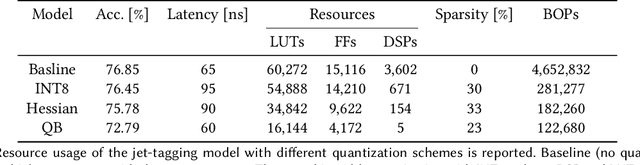
We develop an end-to-end workflow for the training and implementation of co-designed neural networks (NNs) for efficient field-programmable gate array (FPGA) and application-specific integrated circuit (ASIC) hardware. Our approach leverages Hessian-aware quantization (HAWQ) of NNs, the Quantized Open Neural Network Exchange (QONNX) intermediate representation, and the hls4ml tool flow for transpiling NNs into FPGA and ASIC firmware. This makes efficient NN implementations in hardware accessible to nonexperts, in a single open-sourced workflow that can be deployed for real-time machine learning applications in a wide range of scientific and industrial settings. We demonstrate the workflow in a particle physics application involving trigger decisions that must operate at the 40 MHz collision rate of the CERN Large Hadron Collider (LHC). Given the high collision rate, all data processing must be implemented on custom ASIC and FPGA hardware within a strict area and latency. Based on these constraints, we implement an optimized mixed-precision NN classifier for high-momentum particle jets in simulated LHC proton-proton collisions.
Soundini: Sound-Guided Diffusion for Natural Video Editing
Apr 13, 2023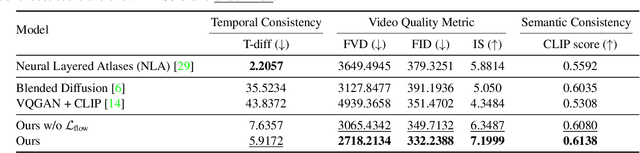

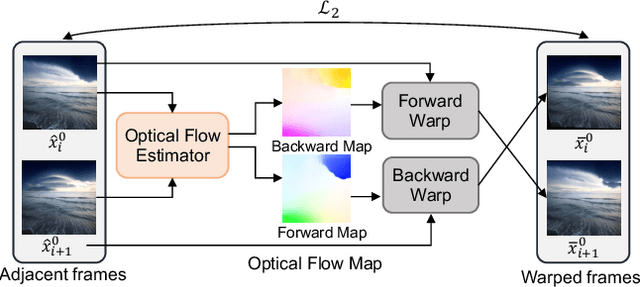

We propose a method for adding sound-guided visual effects to specific regions of videos with a zero-shot setting. Animating the appearance of the visual effect is challenging because each frame of the edited video should have visual changes while maintaining temporal consistency. Moreover, existing video editing solutions focus on temporal consistency across frames, ignoring the visual style variations over time, e.g., thunderstorm, wave, fire crackling. To overcome this limitation, we utilize temporal sound features for the dynamic style. Specifically, we guide denoising diffusion probabilistic models with an audio latent representation in the audio-visual latent space. To the best of our knowledge, our work is the first to explore sound-guided natural video editing from various sound sources with sound-specialized properties, such as intensity, timbre, and volume. Additionally, we design optical flow-based guidance to generate temporally consistent video frames, capturing the pixel-wise relationship between adjacent frames. Experimental results show that our method outperforms existing video editing techniques, producing more realistic visual effects that reflect the properties of sound. Please visit our page: https://kuai-lab.github.io/soundini-gallery/.
Sampling-based path planning under temporal logic constraints with real-time adaptation
Feb 22, 2023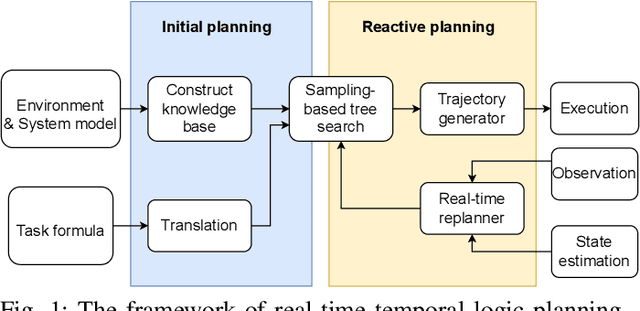
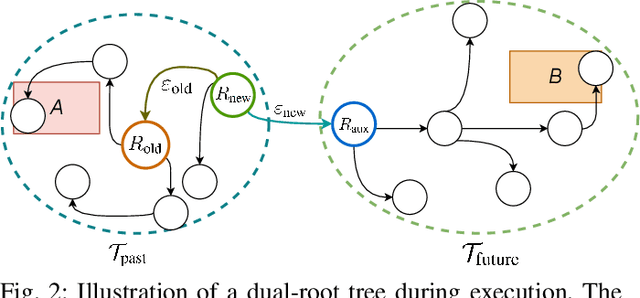
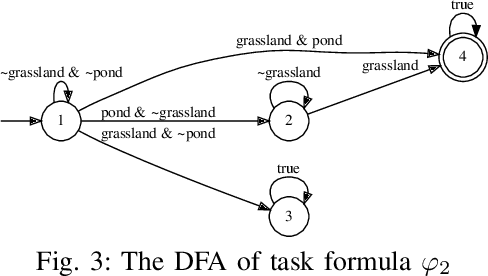
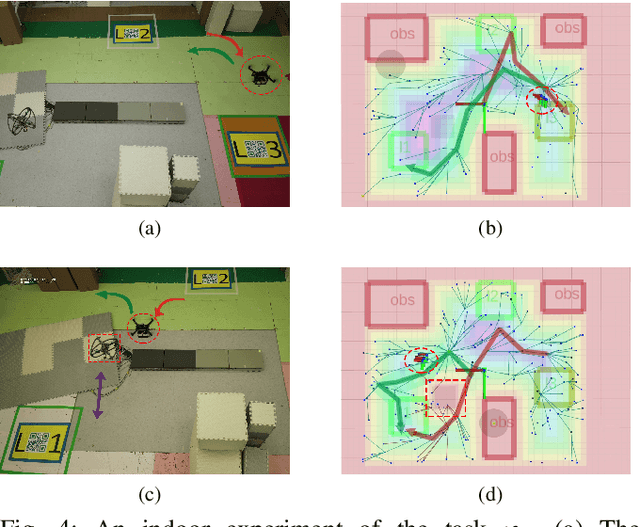
Replanning in temporal logic tasks is extremely difficult during the online execution of robots. This study introduces an effective path planner that computes solutions for temporal logic goals and instantly adapts to non-static and partially unknown environments. Given prior knowledge and a task specification, the planner first identifies an initial feasible solution by growing a sampling-based search tree. While carrying out the computed plan, the robot maintains a solution library to continuously enhance the unfinished part of the plan and store backup plans. The planner updates existing plans when meeting unexpected obstacles or recognizing flaws in prior knowledge. Upon a high-level path is obtained, a trajectory generator tracks the path by dividing it into segments of motion primitives. Our planner is integrated into an autonomous mobile robot system, further deployed on a multicopter with limited onboard processing power. In simulation and real-world experiments, our planner is demonstrated to swiftly and effectively adjust to environmental uncertainties.
Accelerated wind farm yaw and layout optimisation with multi-fidelity deep transfer learning wake models
Mar 28, 2023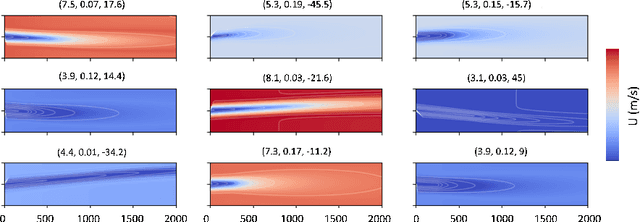

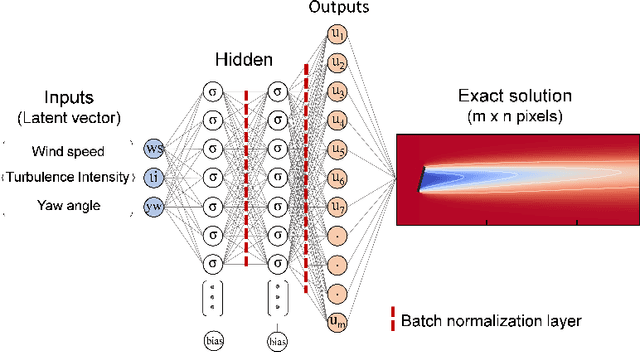

Wind farm modelling has been an area of rapidly increasing interest with numerous analytical as well as computational-based approaches developed to extend the margins of wind farm efficiency and maximise power production. In this work, we present the novel ML framework WakeNet, which can reproduce generalised 2D turbine wake velocity fields at hub-height over a wide range of yaw angles, wind speeds and turbulence intensities (TIs), with a mean accuracy of 99.8% compared to the solution calculated using the state-of-the-art wind farm modelling software FLORIS. As the generation of sufficient high-fidelity data for network training purposes can be cost-prohibitive, the utility of multi-fidelity transfer learning has also been investigated. Specifically, a network pre-trained on the low-fidelity Gaussian wake model is fine-tuned in order to obtain accurate wake results for the mid-fidelity Curl wake model. The robustness and overall performance of WakeNet on various wake steering control and layout optimisation scenarios has been validated through power-gain heatmaps, obtaining at least 90% of the power gained through optimisation performed with FLORIS directly. We also demonstrate that when utilising the Curl model, WakeNet is able to provide similar power gains to FLORIS, two orders of magnitude faster (e.g. 10 minutes vs 36 hours per optimisation case). The wake evaluation time of wakeNet when trained on a high-fidelity CFD dataset is expected to be similar, thus further increasing computational time gains. These promising results show that generalised wake modelling with ML tools can be accurate enough to contribute towards active yaw and layout optimisation, while producing realistic optimised configurations at a fraction of the computational cost, hence making it feasible to perform real-time active yaw control as well as robust optimisation under uncertainty.
Fides: A Generative Framework for Result Validation of Outsourced Machine Learning Workloads via TEE
Mar 31, 2023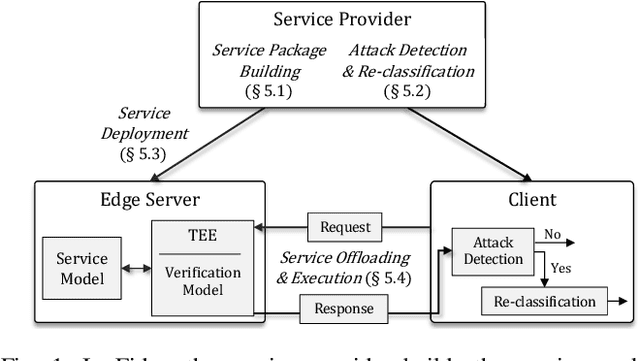
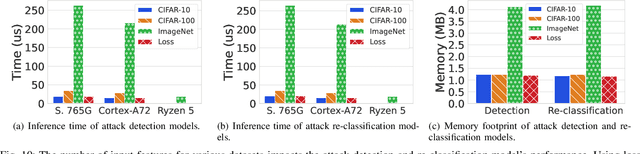
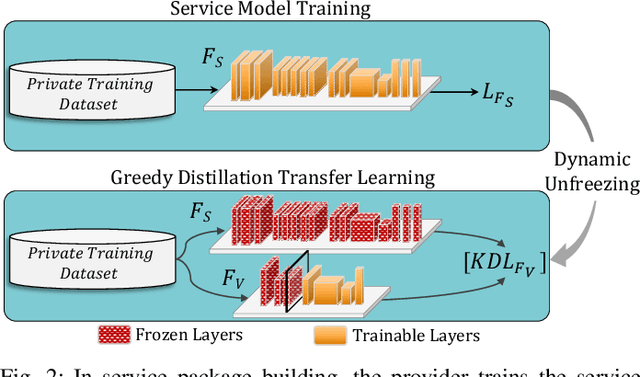
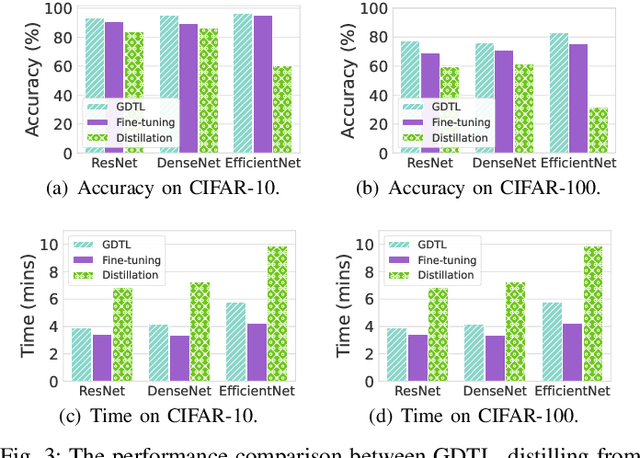
The growing popularity of Machine Learning (ML) has led to its deployment in various sensitive domains, which has resulted in significant research focused on ML security and privacy. However, in some applications, such as autonomous driving, integrity verification of the outsourced ML workload is more critical-a facet that has not received much attention. Existing solutions, such as multi-party computation and proof-based systems, impose significant computation overhead, which makes them unfit for real-time applications. We propose Fides, a novel framework for real-time validation of outsourced ML workloads. Fides features a novel and efficient distillation technique-Greedy Distillation Transfer Learning-that dynamically distills and fine-tunes a space and compute-efficient verification model for verifying the corresponding service model while running inside a trusted execution environment. Fides features a client-side attack detection model that uses statistical analysis and divergence measurements to identify, with a high likelihood, if the service model is under attack. Fides also offers a re-classification functionality that predicts the original class whenever an attack is identified. We devised a generative adversarial network framework for training the attack detection and re-classification models. The extensive evaluation shows that Fides achieves an accuracy of up to 98% for attack detection and 94% for re-classification.
MELT: Mutual Enhancement of Long-Tailed User and Item for Sequential Recommendation
Apr 17, 2023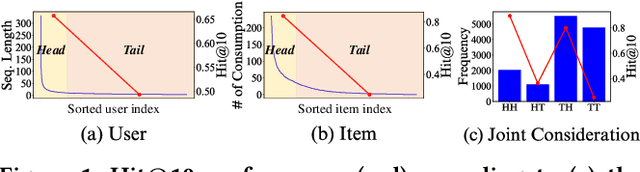
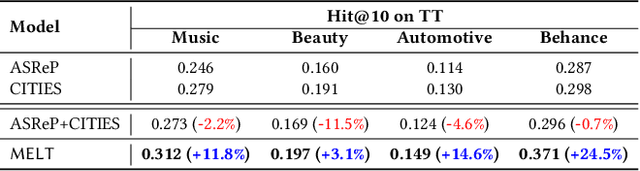
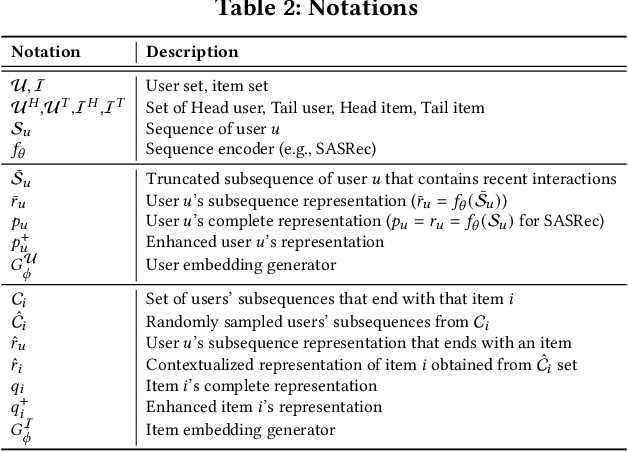
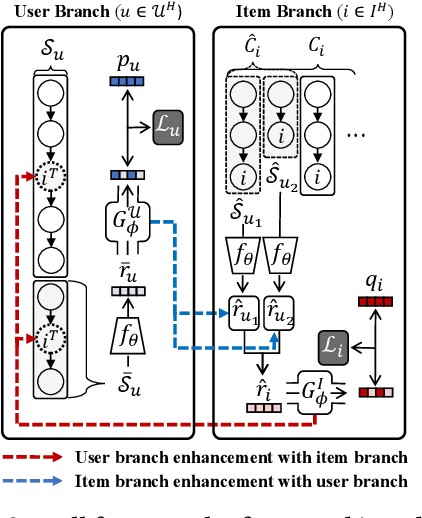
The long-tailed problem is a long-standing challenge in Sequential Recommender Systems (SRS) in which the problem exists in terms of both users and items. While many existing studies address the long-tailed problem in SRS, they only focus on either the user or item perspective. However, we discover that the long-tailed user and item problems exist at the same time, and considering only either one of them leads to sub-optimal performance of the other one. In this paper, we propose a novel framework for SRS, called Mutual Enhancement of Long-Tailed user and item (MELT), that jointly alleviates the long-tailed problem in the perspectives of both users and items. MELT consists of bilateral branches each of which is responsible for long-tailed users and items, respectively, and the branches are trained to mutually enhance each other, which is trained effectively by a curriculum learning-based training. MELT is model-agnostic in that it can be seamlessly integrated with existing SRS models. Extensive experiments on eight datasets demonstrate the benefit of alleviating the long-tailed problems in terms of both users and items even without sacrificing the performance of head users and items, which has not been achieved by existing methods. To the best of our knowledge, MELT is the first work that jointly alleviates the long-tailed user and item problems in SRS.
Efficient Video Action Detection with Token Dropout and Context Refinement
Apr 17, 2023
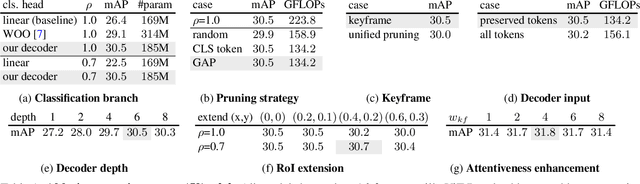
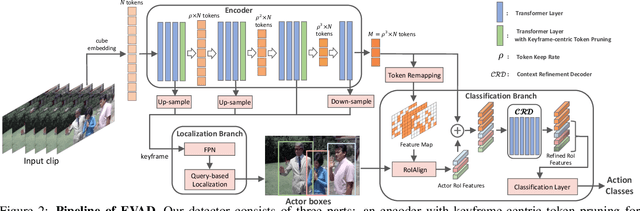
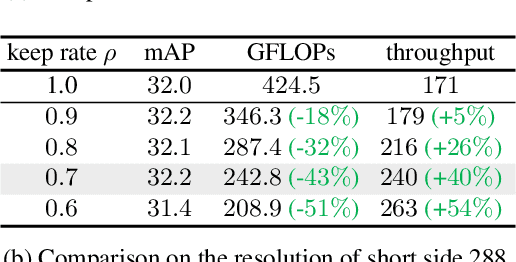
Streaming video clips with large-scale video tokens impede vision transformers (ViTs) for efficient recognition, especially in video action detection where sufficient spatiotemporal representations are required for precise actor identification. In this work, we propose an end-to-end framework for efficient video action detection (EVAD) based on vanilla ViTs. Our EVAD consists of two specialized designs for video action detection. First, we propose a spatiotemporal token dropout from a keyframe-centric perspective. In a video clip, we maintain all tokens from its keyframe, preserve tokens relevant to actor motions from other frames, and drop out the remaining tokens in this clip. Second, we refine scene context by leveraging remaining tokens for better recognizing actor identities. The region of interest (RoI) in our action detector is expanded into temporal domain. The captured spatiotemporal actor identity representations are refined via scene context in a decoder with the attention mechanism. These two designs make our EVAD efficient while maintaining accuracy, which is validated on three benchmark datasets (i.e., AVA, UCF101-24, JHMDB). Compared to the vanilla ViT backbone, our EVAD reduces the overall GFLOPs by 43% and improves real-time inference speed by 40% with no performance degradation. Moreover, even at similar computational costs, our EVAD can improve the performance by 1.0 mAP with higher resolution inputs. Code is available at https://github.com/MCG-NJU/EVAD.
RNN-Guard: Certified Robustness Against Multi-frame Attacks for Recurrent Neural Networks
Apr 17, 2023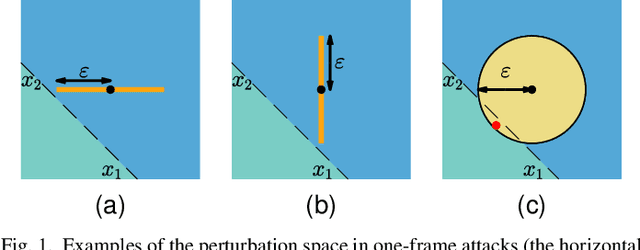
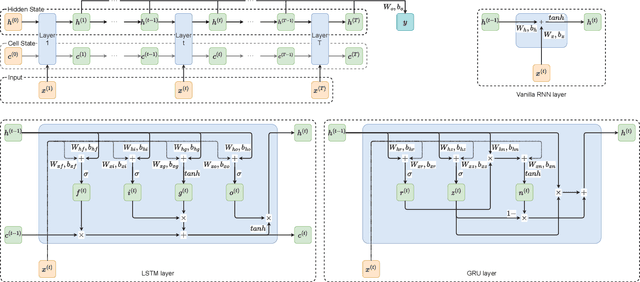
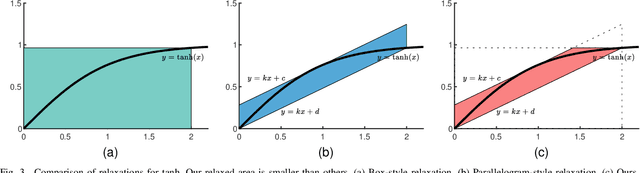
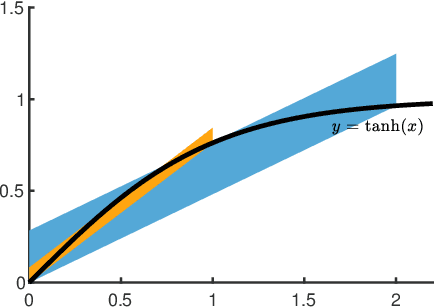
It is well-known that recurrent neural networks (RNNs), although widely used, are vulnerable to adversarial attacks including one-frame attacks and multi-frame attacks. Though a few certified defenses exist to provide guaranteed robustness against one-frame attacks, we prove that defending against multi-frame attacks remains a challenging problem due to their enormous perturbation space. In this paper, we propose the first certified defense against multi-frame attacks for RNNs called RNN-Guard. To address the above challenge, we adopt the perturb-all-frame strategy to construct perturbation spaces consistent with those in multi-frame attacks. However, the perturb-all-frame strategy causes a precision issue in linear relaxations. To address this issue, we introduce a novel abstract domain called InterZono and design tighter relaxations. We prove that InterZono is more precise than Zonotope yet carries the same time complexity. Experimental evaluations across various datasets and model structures show that the certified robust accuracy calculated by RNN-Guard with InterZono is up to 2.18 times higher than that with Zonotope. In addition, we extend RNN-Guard as the first certified training method against multi-frame attacks to directly enhance RNNs' robustness. The results show that the certified robust accuracy of models trained with RNN-Guard against multi-frame attacks is 15.47 to 67.65 percentage points higher than those with other training methods.
Goal-oriented Uncertainty Quantification for Inverse Problems via Variational Encoder-Decoder Networks
Apr 17, 2023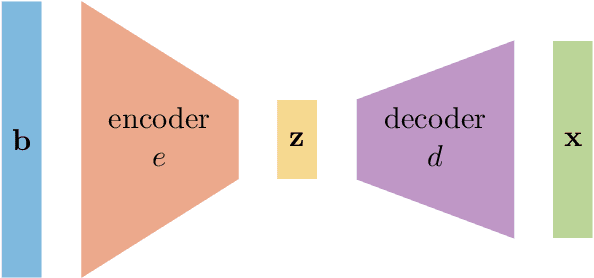

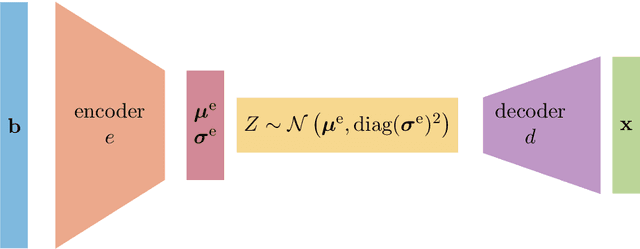
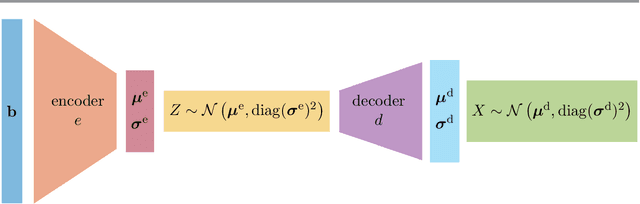
In this work, we describe a new approach that uses variational encoder-decoder (VED) networks for efficient goal-oriented uncertainty quantification for inverse problems. Contrary to standard inverse problems, these approaches are \emph{goal-oriented} in that the goal is to estimate some quantities of interest (QoI) that are functions of the solution of an inverse problem, rather than the solution itself. Moreover, we are interested in computing uncertainty metrics associated with the QoI, thus utilizing a Bayesian approach for inverse problems that incorporates the prediction operator and techniques for exploring the posterior. This may be particularly challenging, especially for nonlinear, possibly unknown, operators and nonstandard prior assumptions. We harness recent advances in machine learning, i.e., VED networks, to describe a data-driven approach to large-scale inverse problems. This enables a real-time goal-oriented uncertainty quantification for the QoI. One of the advantages of our approach is that we avoid the need to solve challenging inversion problems by training a network to approximate the mapping from observations to QoI. Another main benefit is that we enable uncertainty quantification for the QoI by leveraging probability distributions in the latent space. This allows us to efficiently generate QoI samples and circumvent complicated or even unknown forward models and prediction operators. Numerical results from medical tomography reconstruction and nonlinear hydraulic tomography demonstrate the potential and broad applicability of the approach.