 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Reference Model for Collaborative Business Intelligence Virtual Assistants
Apr 20, 2023
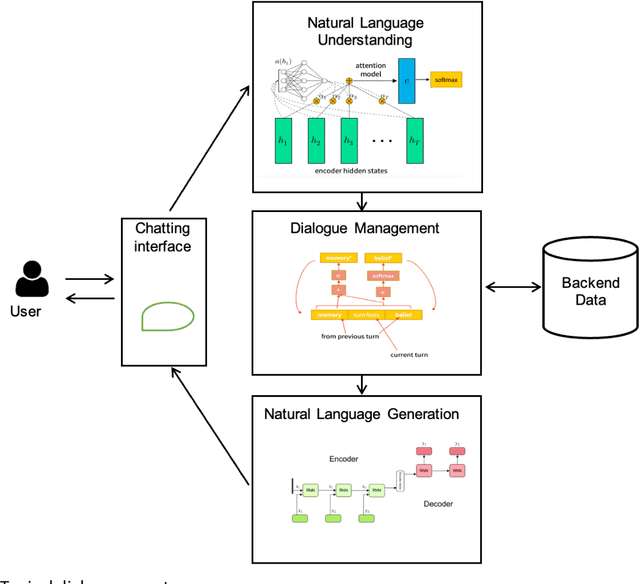
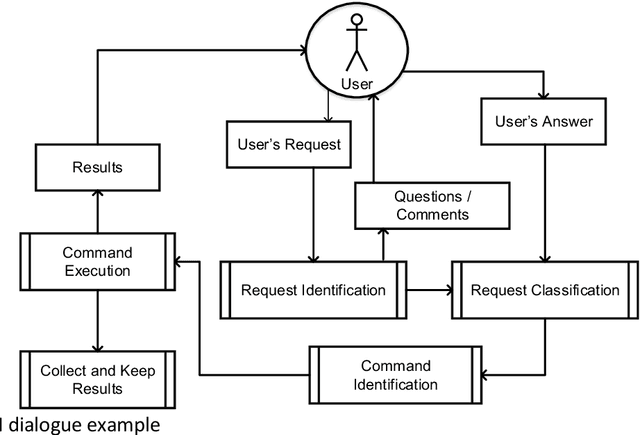
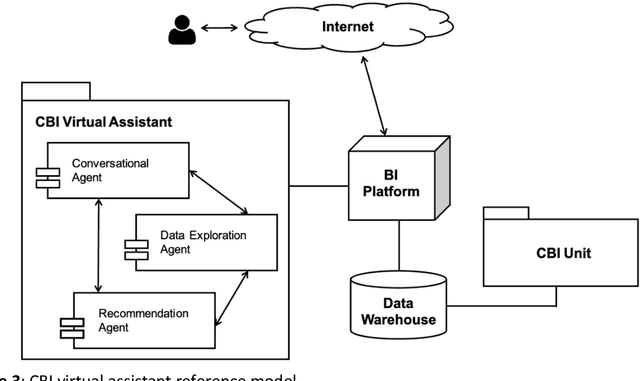
Collaborative Business Analysis (CBA) is a methodology that involves bringing together different stakeholders, including business users, analysts, and technical specialists, to collaboratively analyze data and gain insights into business operations. The primary objective of CBA is to encourage knowledge sharing and collaboration between the different groups involved in business analysis, as this can lead to a more comprehensive understanding of the data and better decision-making. CBA typically involves a range of activities, including data gathering and analysis, brainstorming, problem-solving, decision-making and knowledge sharing. These activities may take place through various channels, such as in-person meetings, virtual collaboration tools or online forums. This paper deals with virtual collaboration tools as an important part of Business Intelligence (BI) platform. Collaborative Business Intelligence (CBI) tools are becoming more user-friendly, accessible, and flexible, allowing users to customize their experience and adapt to their specific needs. The goal of a virtual assistant is to make data exploration more accessible to a wider range of users and to reduce the time and effort required for data analysis. It describes the unified business intelligence semantic model, coupled with a data warehouse and collaborative unit to employ data mining technology. Moreover, we propose a virtual assistant for CBI and a reference model of virtual tools for CBI, which consists of three components: conversational, data exploration and recommendation agents. We believe that the allocation of these three functional tasks allows you to structure the CBI issue and apply relevant and productive models for human-like dialogue, text-to-command transferring, and recommendations simultaneously. The complex approach based on these three points gives the basis for virtual tool for collaboration. CBI encourages people, processes, and technology to enable everyone sharing and leveraging collective expertise, knowledge and data to gain valuable insights for making better decisions. This allows to respond more quickly and effectively to changes in the market or internal operations and improve the progress.
Dual-Attention Neural Transducers for Efficient Wake Word Spotting in Speech Recognition
Apr 05, 2023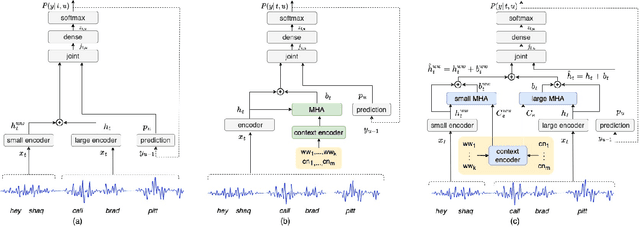
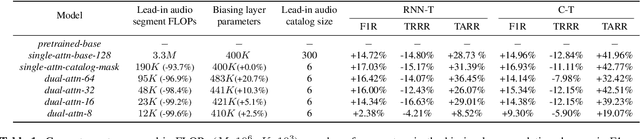
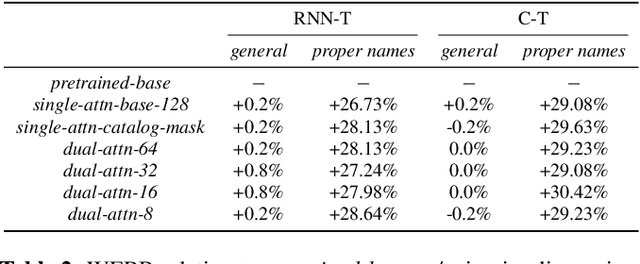
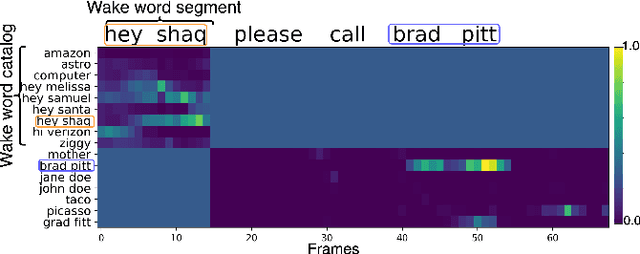
We present dual-attention neural biasing, an architecture designed to boost Wake Words (WW) recognition and improve inference time latency on speech recognition tasks. This architecture enables a dynamic switch for its runtime compute paths by exploiting WW spotting to select which branch of its attention networks to execute for an input audio frame. With this approach, we effectively improve WW spotting accuracy while saving runtime compute cost as defined by floating point operations (FLOPs). Using an in-house de-identified dataset, we demonstrate that the proposed dual-attention network can reduce the compute cost by $90\%$ for WW audio frames, with only $1\%$ increase in the number of parameters. This architecture improves WW F1 score by $16\%$ relative and improves generic rare word error rate by $3\%$ relative compared to the baselines.
Efficient Optimization-based Cable Force Allocation for Geometric Control of Multiple Quadrotors Transporting a Payload
Apr 05, 2023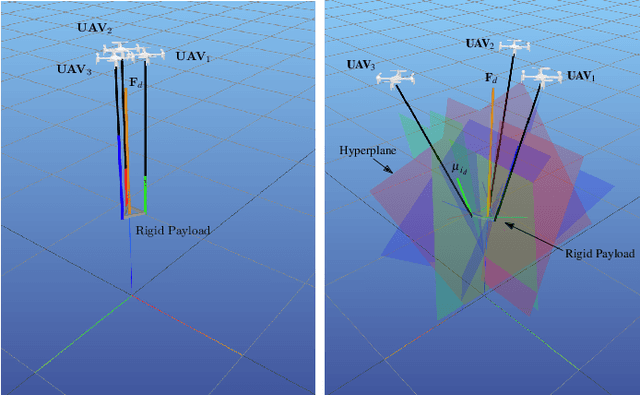

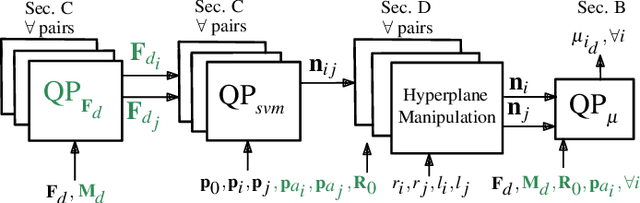
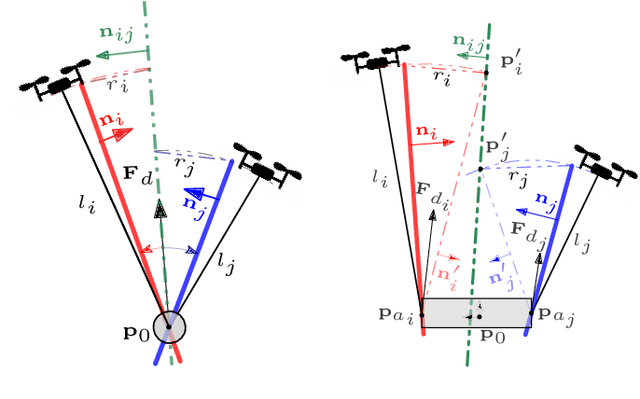
We consider transporting a heavy payload that is attached to multiple quadrotors. The current state-of-the-art controllers either do not avoid inter-robot collision at all, leading to crashes when tasked with carrying payloads that are small in size compared to the cable lengths, or use computational demanding nonlinear optimization. We propose an extension to an existing efficient geometric payload transport controller to effectively avoid such collisions by designing an optimized cable force allocation method, and thus retaining the original stability properties. Our approach introduces a cascade of carefully designed quadratic programs that can be solved efficiently on highly constrained embedded flight controllers. We demonstrate our method on challenging scenarios with up to three small quadrotors with various payloads and cable lengths, with our controller running in real-time directly on the robots.
Zoom is what you need: An empirical study of the power of zoom and spatial biases in image classification
Apr 11, 2023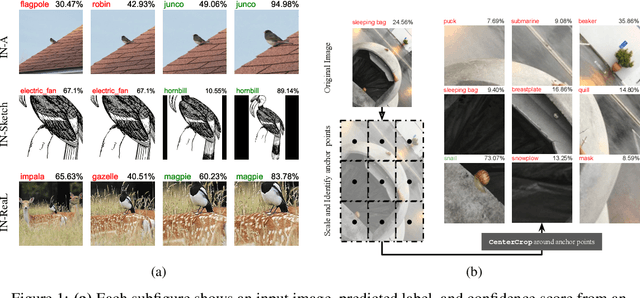



Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels. We study six popular networks ranging from AlexNet to CLIP and find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we explore the potential and limits of zoom transforms in image classification and uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zoom, we propose a state-of-the-art test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions. Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art TTA method. Additionally, we propose ImageNet-Hard, a new benchmark where zooming in alone often does not help state-of-the-art models better label images.
Improving Neural Radiance Fields with Depth-aware Optimization for Novel View Synthesis
Apr 11, 2023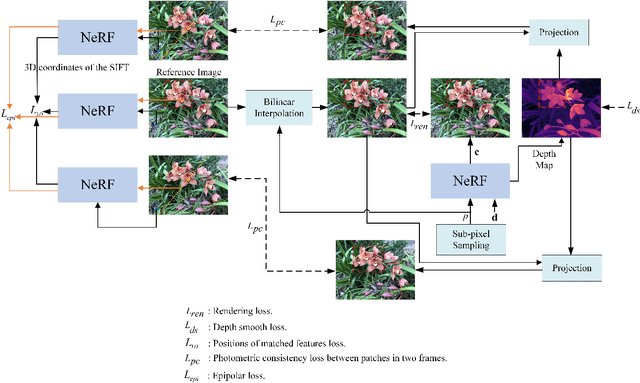

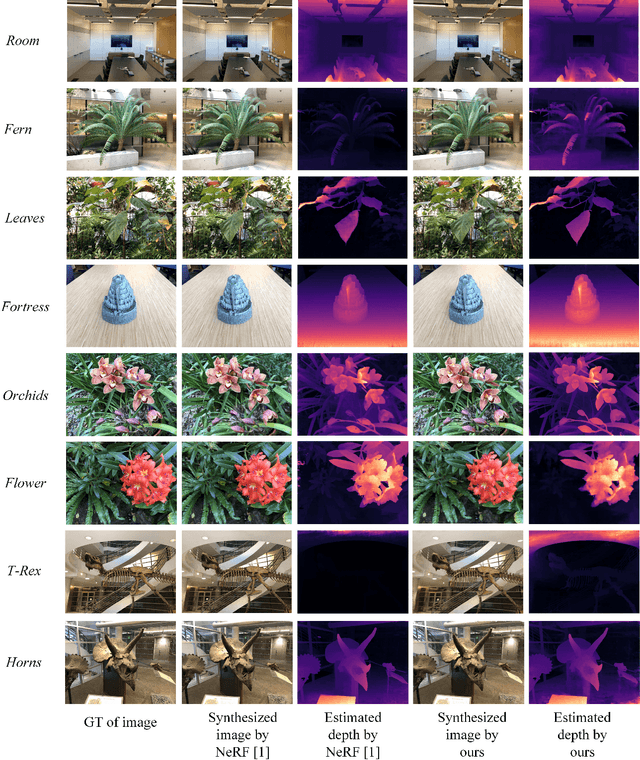

With dense inputs, Neural Radiance Fields (NeRF) is able to render photo-realistic novel views under static conditions. Although the synthesis quality is excellent, existing NeRF-based methods fail to obtain moderate three-dimensional (3D) structures. The novel view synthesis quality drops dramatically given sparse input due to the implicitly reconstructed inaccurate 3D-scene structure. We propose SfMNeRF, a method to better synthesize novel views as well as reconstruct the 3D-scene geometry. SfMNeRF leverages the knowledge from the self-supervised depth estimation methods to constrain the 3D-scene geometry during view synthesis training. Specifically, SfMNeRF employs the epipolar, photometric consistency, depth smoothness, and position-of-matches constraints to explicitly reconstruct the 3D-scene structure. Through these explicit constraints and the implicit constraint from NeRF, our method improves the view synthesis as well as the 3D-scene geometry performance of NeRF at the same time. In addition, SfMNeRF synthesizes novel sub-pixels in which the ground truth is obtained by image interpolation. This strategy enables SfMNeRF to include more samples to improve generalization performance. Experiments on two public datasets demonstrate that SfMNeRF surpasses state-of-the-art approaches. Code is available at https://github.com/XTU-PR-LAB/SfMNeRF
Task Difficulty Aware Parameter Allocation & Regularization for Lifelong Learning
Apr 11, 2023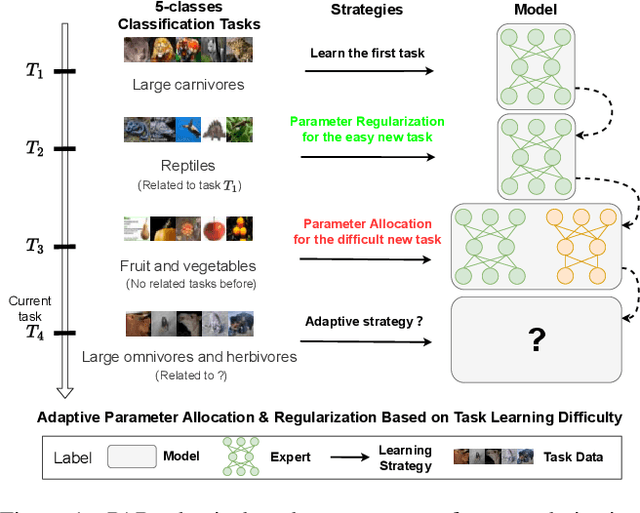
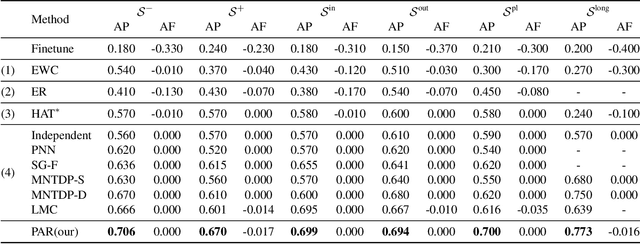
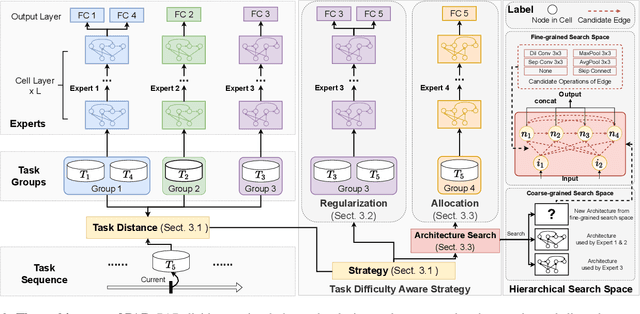

Parameter regularization or allocation methods are effective in overcoming catastrophic forgetting in lifelong learning. However, they solve all tasks in a sequence uniformly and ignore the differences in the learning difficulty of different tasks. So parameter regularization methods face significant forgetting when learning a new task very different from learned tasks, and parameter allocation methods face unnecessary parameter overhead when learning simple tasks. In this paper, we propose the Parameter Allocation & Regularization (PAR), which adaptively select an appropriate strategy for each task from parameter allocation and regularization based on its learning difficulty. A task is easy for a model that has learned tasks related to it and vice versa. We propose a divergence estimation method based on the Nearest-Prototype distance to measure the task relatedness using only features of the new task. Moreover, we propose a time-efficient relatedness-aware sampling-based architecture search strategy to reduce the parameter overhead for allocation. Experimental results on multiple benchmarks demonstrate that, compared with SOTAs, our method is scalable and significantly reduces the model's redundancy while improving the model's performance. Further qualitative analysis indicates that PAR obtains reasonable task-relatedness.
Electricity Demand Forecasting with Hybrid Statistical and Machine Learning Algorithms: Case Study of Ukraine
Apr 11, 2023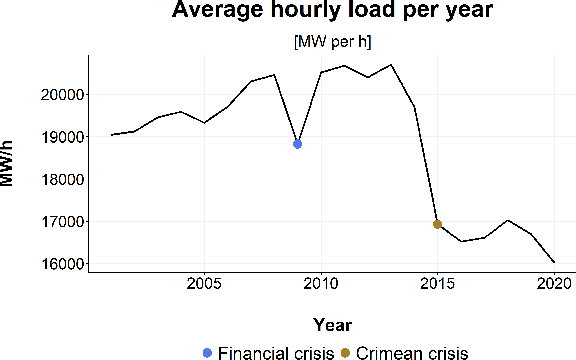
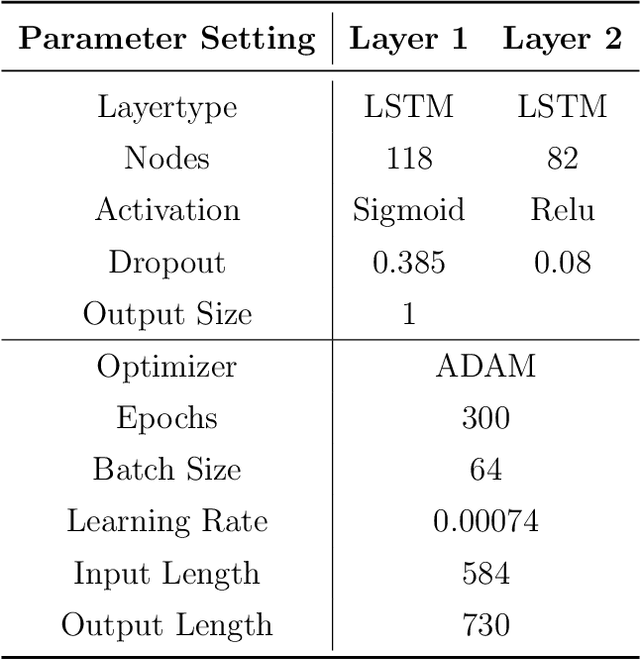
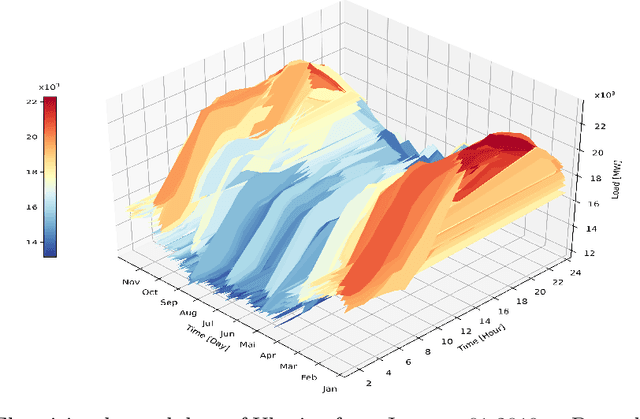
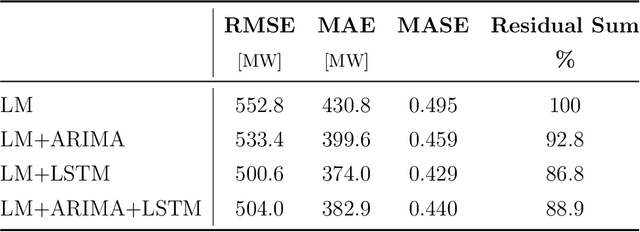
This article presents a novel hybrid approach using statistics and machine learning to forecast the national demand of electricity. As investment and operation of future energy systems require long-term electricity demand forecasts with hourly resolution, our mathematical model fills a gap in energy forecasting. The proposed methodology was constructed using hourly data from Ukraine's electricity consumption ranging from 2013 to 2020. To this end, we analysed the underlying structure of the hourly, daily and yearly time series of electricity consumption. The long-term yearly trend is evaluated using macroeconomic regression analysis. The mid-term model integrates temperature and calendar regressors to describe the underlying structure, and combines ARIMA and LSTM ``black-box'' pattern-based approaches to describe the error term. The short-term model captures the hourly seasonality through calendar regressors and multiple ARMA models for the residual. Results show that the best forecasting model is composed by combining multiple regression models and a LSTM hybrid model for residual prediction. Our hybrid model is very effective at forecasting long-term electricity consumption on an hourly resolution. In two years of out-of-sample forecasts with 17520 timesteps, it is shown to be within 96.83 \% accuracy.
TinyReptile: TinyML with Federated Meta-Learning
Apr 11, 2023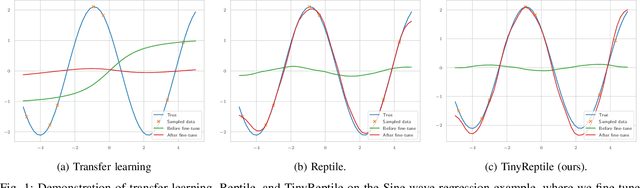
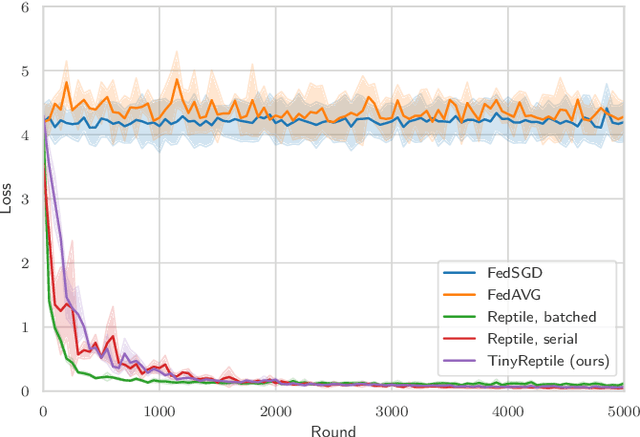
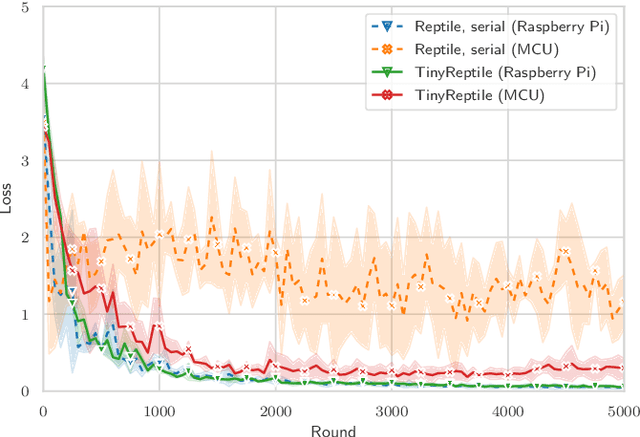

Tiny machine learning (TinyML) is a rapidly growing field aiming to democratize machine learning (ML) for resource-constrained microcontrollers (MCUs). Given the pervasiveness of these tiny devices, it is inherent to ask whether TinyML applications can benefit from aggregating their knowledge. Federated learning (FL) enables decentralized agents to jointly learn a global model without sharing sensitive local data. However, a common global model may not work for all devices due to the complexity of the actual deployment environment and the heterogeneity of the data available on each device. In addition, the deployment of TinyML hardware has significant computational and communication constraints, which traditional ML fails to address. Considering these challenges, we propose TinyReptile, a simple but efficient algorithm inspired by meta-learning and online learning, to collaboratively learn a solid initialization for a neural network (NN) across tiny devices that can be quickly adapted to a new device with respect to its data. We demonstrate TinyReptile on Raspberry Pi 4 and Cortex-M4 MCU with only 256-KB RAM. The evaluations on various TinyML use cases confirm a resource reduction and training time saving by at least two factors compared with baseline algorithms with comparable performance.
Random Majority Opinion Diffusion: Stabilization Time, Absorbing States, and Influential Nodes
Feb 14, 2023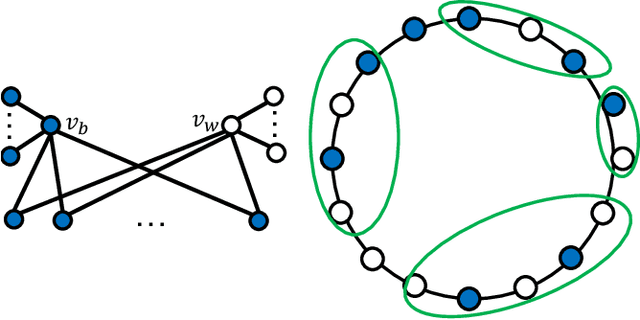


Consider a graph G with n nodes and m edges, which represents a social network, and assume that initially each node is blue or white. In each round, all nodes simultaneously update their color to the most frequent color in their neighborhood. This is called the Majority Model (MM) if a node keeps its color in case of a tie and the Random Majority Model (RMM) if it chooses blue with probability 1/2 and white otherwise. We prove that there are graphs for which RMM needs exponentially many rounds to reach a stable configuration in expectation, and such a configuration can have exponentially many states (i.e., colorings). This is in contrast to MM, which is known to always reach a stable configuration with one or two states in $O(m)$ rounds. For the special case of a cycle graph C_n, we prove the stronger and tight bounds of $\lceil n/2\rceil-1$ and $O(n^2)$ in MM and RMM, respectively. Furthermore, we show that the number of stable colorings in MM on C_n is equal to $\Theta(\Phi^n)$, where $\Phi = (1+\sqrt{5})/2$ is the golden ratio, while it is equal to 2 for RMM. We also study the minimum size of a winning set, which is a set of nodes whose agreement on a color in the initial coloring enforces the process to end in a coloring where all nodes share that color. We present tight bounds on the minimum size of a winning set for both MM and RMM. Furthermore, we analyze our models for a random initial coloring, where each node is colored blue independently with some probability $p$ and white otherwise. Using some martingale analysis and counting arguments, we prove that the expected final number of blue nodes is respectively equal to $(2p^2-p^3)n/(1-p+p^2)$ and pn in MM and RMM on a cycle graph C_n. Finally, we conduct some experiments which complement our theoretical findings and also lead to the proposal of some intriguing open problems and conjectures to be tackled in future work.
Pgx: Hardware-accelerated parallel game simulation for reinforcement learning
Mar 29, 2023
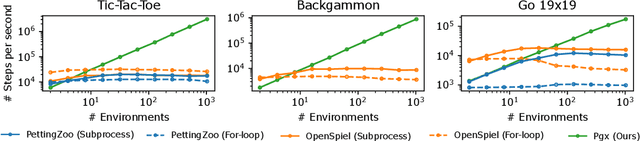
We propose Pgx, a collection of board game simulators written in JAX. Thanks to auto-vectorization and Just-In-Time compilation of JAX, Pgx scales easily to thousands of parallel execution on GPU/TPU accelerators. We found that the simulation of Pgx on a single A100 GPU is 10x faster than that of existing reinforcement learning libraries. Pgx implements games considered vital benchmarks in artificial intelligence research, such as Backgammon, Shogi, and Go. Pgx is available at https://github.com/sotetsuk/pgx.