 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SamurAI: A Versatile IoT Node With Event-Driven Wake-Up and Embedded ML Acceleration
Apr 11, 2023
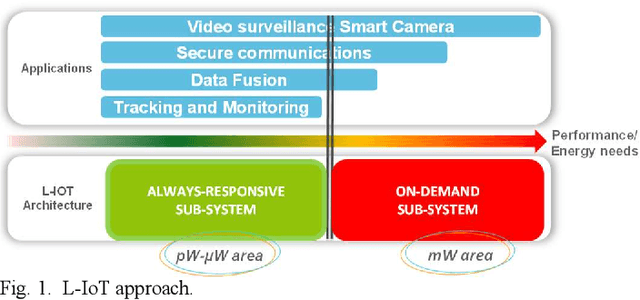
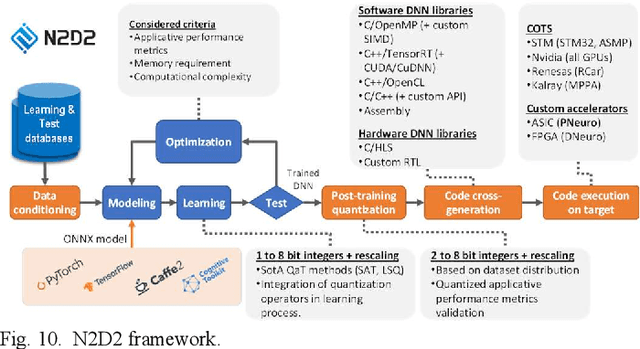
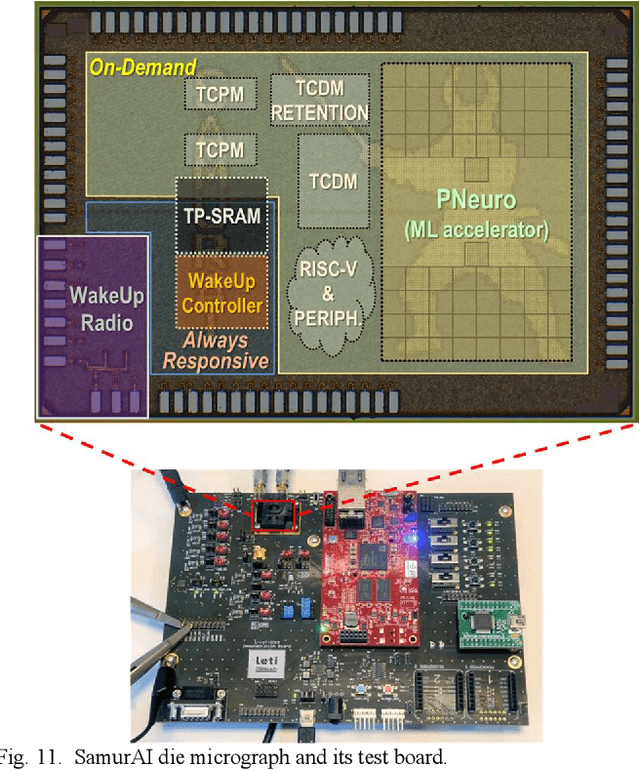
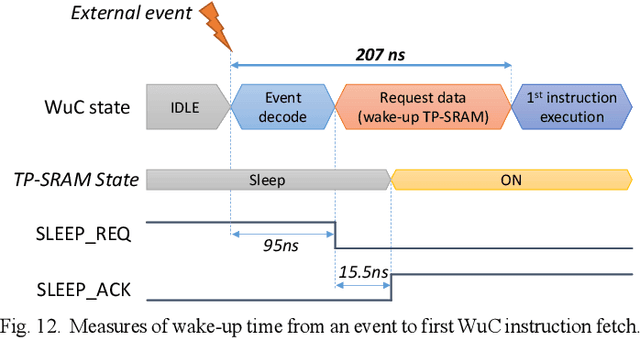
Increased capabilities such as recognition and self-adaptability are now required from IoT applications. While IoT node power consumption is a major concern for these applications, cloud-based processing is becoming unsustainable due to continuous sensor or image data transmission over the wireless network. Thus optimized ML capabilities and data transfers should be integrated in the IoT node. Moreover, IoT applications are torn between sporadic data-logging and energy-hungry data processing (e.g. image classification). Thus, the versatility of the node is key in addressing this wide diversity of energy and processing needs. This paper presents SamurAI, a versatile IoT node bridging this gap in processing and in energy by leveraging two on-chip sub-systems: a low power, clock-less, event-driven Always-Responsive (AR) part and an energy-efficient On-Demand (OD) part. AR contains a 1.7MOPS event-driven, asynchronous Wake-up Controller (WuC) with a 207ns wake-up time optimized for sporadic computing, while OD combines a deep-sleep RISC-V CPU and 1.3TOPS/W Machine Learning (ML) for more complex tasks up to 36GOPS. This architecture partitioning achieves best in class versatility metrics such as peak performance to idle power ratio. On an applicative classification scenario, it demonstrates system power gains, up to 3.5x compared to cloud-based processing, and thus extended battery lifetime.
From Clean Room to Machine Room: Commissioning of the First-Generation BrainScaleS Wafer-Scale Neuromorphic System
Mar 22, 2023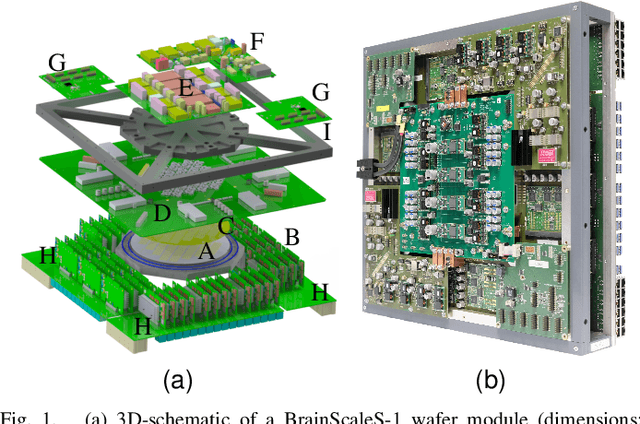
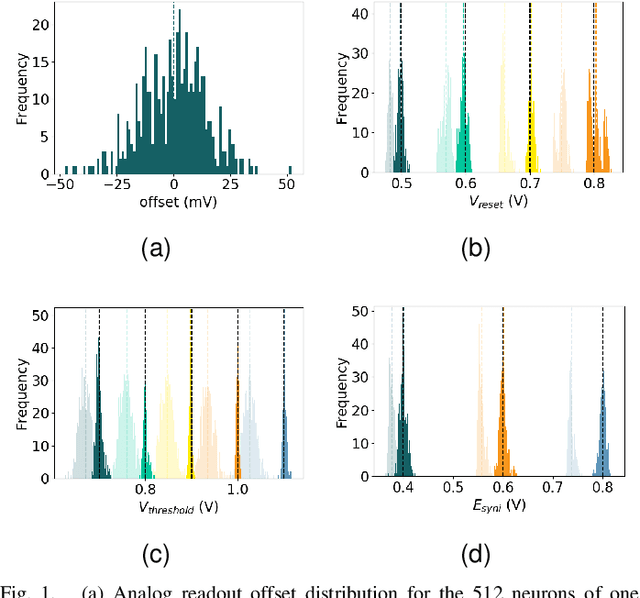
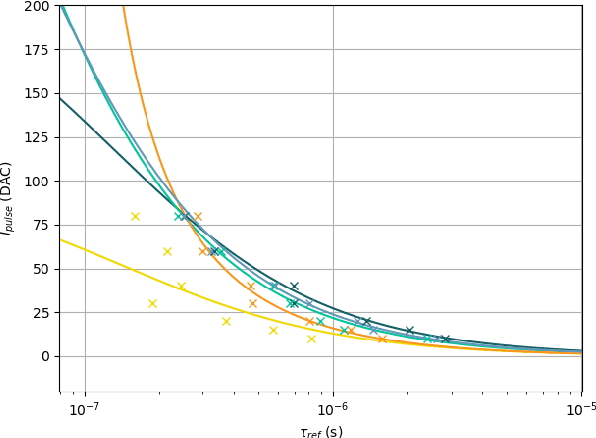
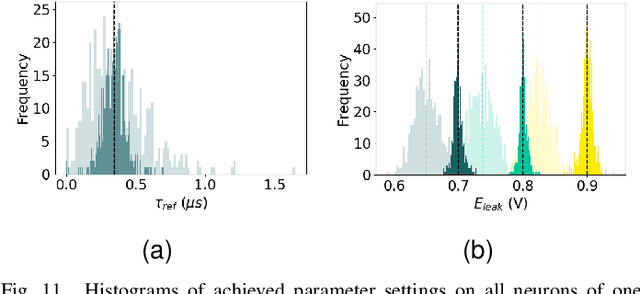
The first-generation of BrainScaleS, also referred to as BrainScaleS-1, is a neuromorphic system for emulating large-scale networks of spiking neurons. Following a "physical modeling" principle, its VLSI circuits are designed to emulate the dynamics of biological examples: analog circuits implement neurons and synapses with time constants that arise from their electronic components' intrinsic properties. It operates in continuous time, with dynamics typically matching an acceleration factor of 10000 compared to the biological regime. A fault-tolerant design allows it to achieve wafer-scale integration despite unavoidable analog variability and component failures. In this paper, we present the commissioning process of a BrainScaleS-1 wafer module, providing a short description of the system's physical components, illustrating the steps taken during its assembly and the measures taken to operate it. Furthermore, we reflect on the system's development process and the lessons learned to conclude with a demonstration of its functionality by emulating a wafer-scale synchronous firing chain, the largest spiking network emulation ran with analog components and individual synapses to date.
A Survey on Task Allocation and Scheduling in Robotic Network Systems
Mar 22, 2023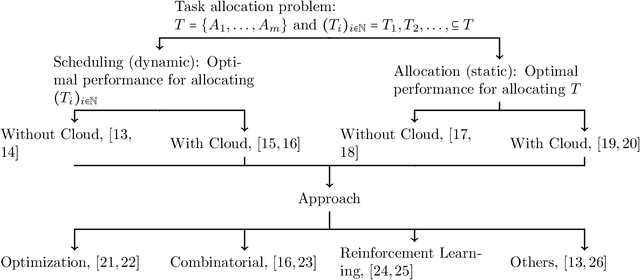
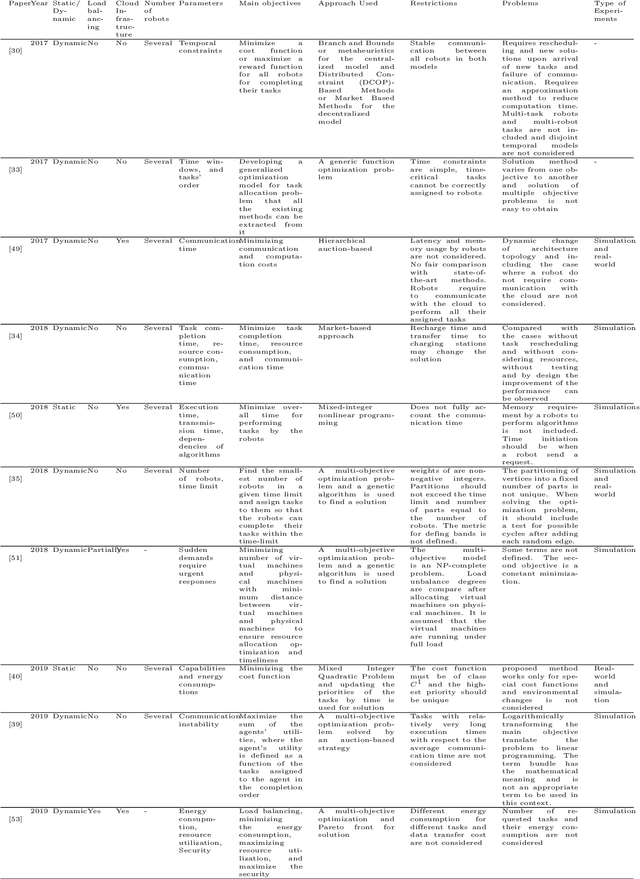
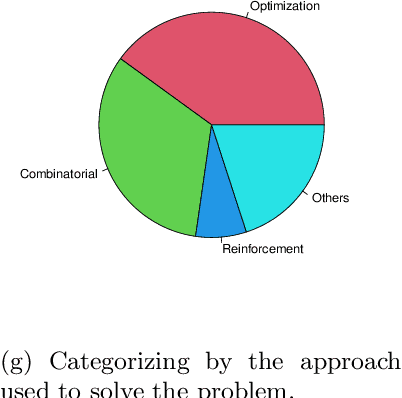
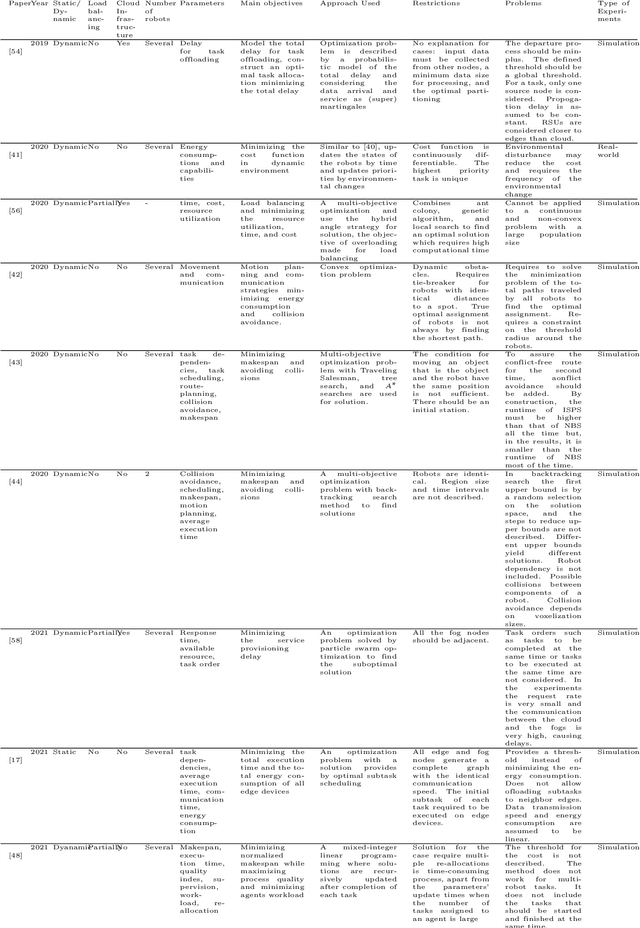
Cloud Robotics is helping to create a new generation of robots that leverage the nearly unlimited resources of large data centers (i.e., the cloud), overcoming the limitations imposed by on-board resources. Different processing power, capabilities, resource sizes, energy consumption, and so forth, make scheduling and task allocation critical components. The basic idea of task allocation and scheduling is to optimize performance by minimizing completion time, energy consumption, delays between two consecutive tasks, along with others, and maximizing resource utilization, number of completed tasks in a given time interval, and suchlike. In the past, several works have addressed various aspects of task allocation and scheduling. In this paper, we provide a comprehensive overview of task allocation and scheduling strategies and related metrics suitable for robotic network cloud systems. We discuss the issues related to allocation and scheduling methods and the limitations that need to be overcome. The literature review is organized according to three different viewpoints: Architectures and Applications, Methods and Parameters. In addition, the limitations of each method are highlighted for future research.
Waving Goodbye to Low-Res: A Diffusion-Wavelet Approach for Image Super-Resolution
Apr 05, 2023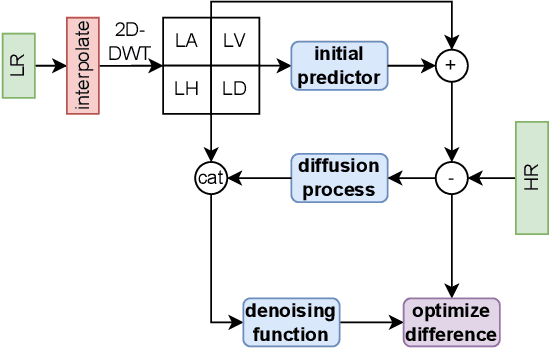
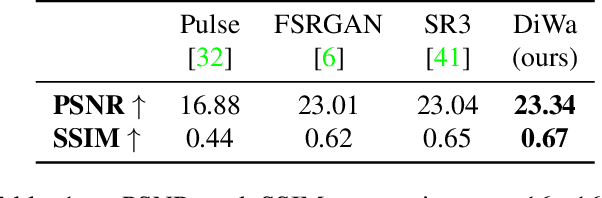
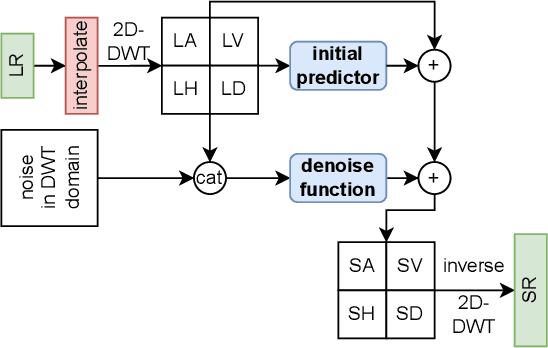
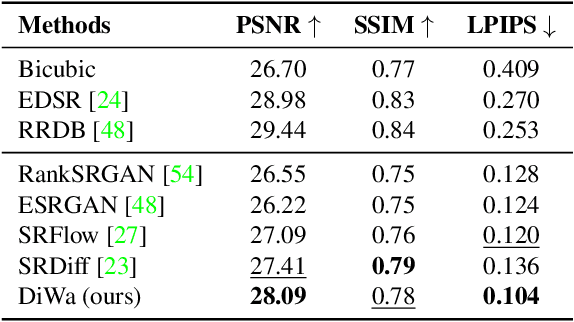
This paper presents a novel Diffusion-Wavelet (DiWa) approach for Single-Image Super-Resolution (SISR). It leverages the strengths of Denoising Diffusion Probabilistic Models (DDPMs) and Discrete Wavelet Transformation (DWT). By enabling DDPMs to operate in the DWT domain, our DDPM models effectively hallucinate high-frequency information for super-resolved images on the wavelet spectrum, resulting in high-quality and detailed reconstructions in image space. Quantitatively, we outperform state-of-the-art diffusion-based SISR methods, namely SR3 and SRDiff, regarding PSNR, SSIM, and LPIPS on both face (8x scaling) and general (4x scaling) SR benchmarks. Meanwhile, using DWT enabled us to use fewer parameters than the compared models: 92M parameters instead of 550M compared to SR3 and 9.3M instead of 12M compared to SRDiff. Additionally, our method outperforms other state-of-the-art generative methods on classical general SR datasets while saving inference time. Finally, our work highlights its potential for various applications.
High Accuracy Uncertainty-Aware Interatomic Force Modeling with Equivariant Bayesian Neural Networks
Apr 05, 2023Even though Bayesian neural networks offer a promising framework for modeling uncertainty, active learning and incorporating prior physical knowledge, few applications of them can be found in the context of interatomic force modeling. One of the main challenges in their application to learning interatomic forces is the lack of suitable Monte Carlo Markov chain sampling algorithms for the posterior density, as the commonly used algorithms do not converge in a practical amount of time for many of the state-of-the-art architectures. As a response to this challenge, we introduce a new Monte Carlo Markov chain sampling algorithm in this paper which can circumvent the problems of the existing sampling methods. In addition, we introduce a new stochastic neural network model based on the NequIP architecture and demonstrate that, when combined with our novel sampling algorithm, we obtain predictions with state-of-the-art accuracy as well as a good measure of uncertainty.
Efficient Deep Learning Models for Privacy-preserving People Counting on Low-resolution Infrared Arrays
Apr 12, 2023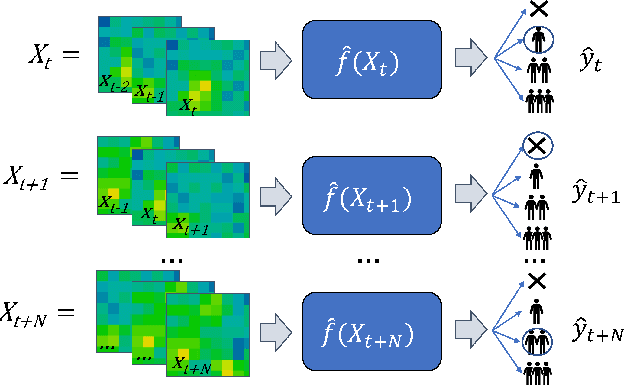
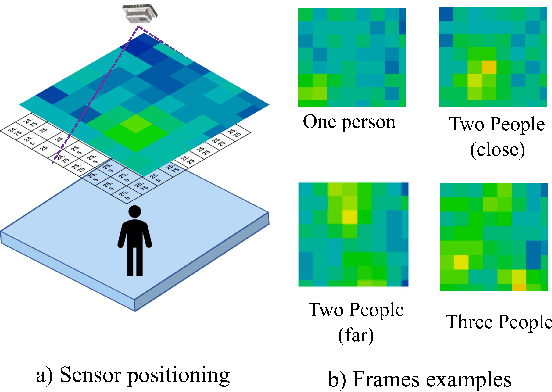
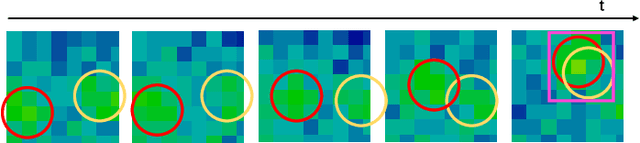
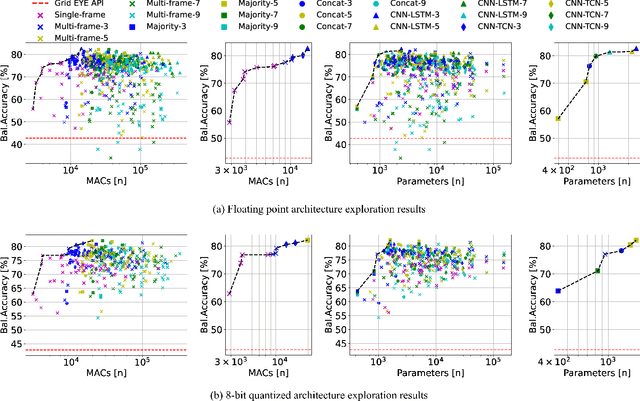
Ultra-low-resolution Infrared (IR) array sensors offer a low-cost, energy-efficient, and privacy-preserving solution for people counting, with applications such as occupancy monitoring. Previous work has shown that Deep Learning (DL) can yield superior performance on this task. However, the literature was missing an extensive comparative analysis of various efficient DL architectures for IR array-based people counting, that considers not only their accuracy, but also the cost of deploying them on memory- and energy-constrained Internet of Things (IoT) edge nodes. In this work, we address this need by comparing 6 different DL architectures on a novel dataset composed of IR images collected from a commercial 8x8 array, which we made openly available. With a wide architectural exploration of each model type, we obtain a rich set of Pareto-optimal solutions, spanning cross-validated balanced accuracy scores in the 55.70-82.70% range. When deployed on a commercial Microcontroller (MCU) by STMicroelectronics, the STM32L4A6ZG, these models occupy 0.41-9.28kB of memory, and require 1.10-7.74ms per inference, while consuming 17.18-120.43 $\mu$J of energy. Our models are significantly more accurate than a previous deterministic method (up to +39.9%), while being up to 3.53x faster and more energy efficient. Further, our models' accuracy is comparable to state-of-the-art DL solutions on similar resolution sensors, despite a much lower complexity. All our models enable continuous, real-time inference on a MCU-based IoT node, with years of autonomous operation without battery recharging.
Chance-Constrained Multi-Robot Motion Planning under Gaussian Uncertainties
Apr 04, 2023We consider a chance-constrained multi-robot motion planning problem in the presence of Gaussian motion and sensor noise. Our proposed algorithm, CC-K-CBS, leverages the scalability of kinodynamic conflict-based search (K-CBS) in conjunction with the efficiency of the Gaussian belief trees used in the Belief-A framework, and inherits the completeness guarantees of Belief-A's low-level sampling-based planner. We also develop three different methods for robot-robot probabilistic collision checking, which trade off computation with accuracy. Our algorithm generates motion plans driving each robot from its initial state to its goal while accounting for the evolution of its uncertainty with chance-constrained safety guarantees. Benchmarks compare computation time to conservatism of the collision checkers, in addition to characterizing the performance of the planner as a whole. Results show that CC-K-CBS can scale up to 30 robots.
Cross-modal tumor segmentation using generative blending augmentation and self training
Apr 04, 2023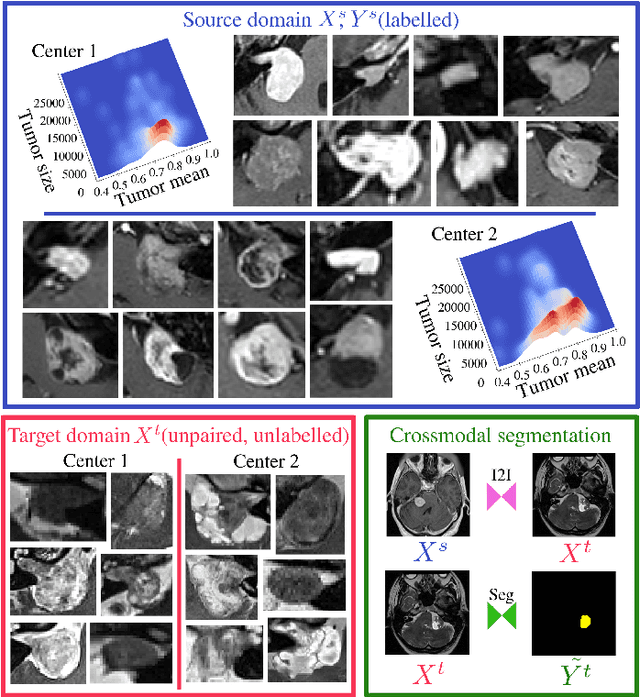
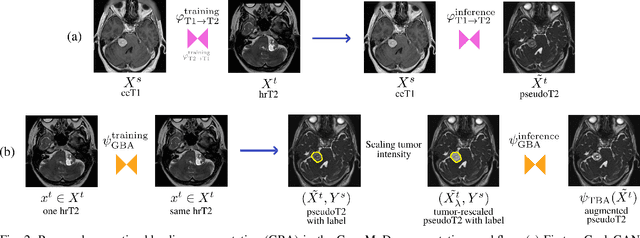
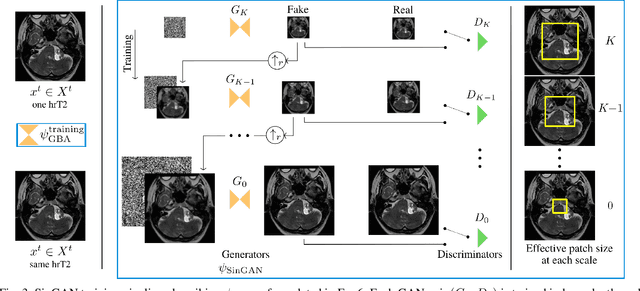
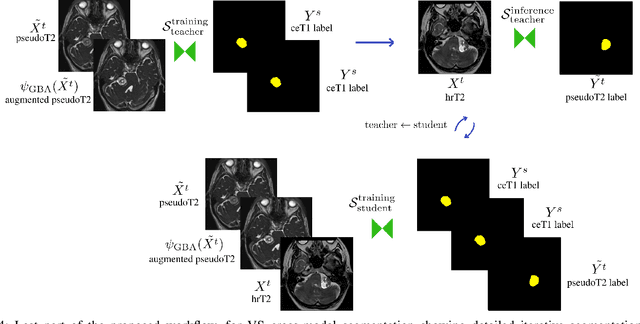
Deep learning for medical imaging is limited by data scarcity and domain shift, which lead to biased training sets that do not accurately represent deployment conditions. A related practical problem is cross-modal segmentation where the objective is to segment unlabelled domains using previously labelled images from other modalites, which is the context of the MICCAI CrossMoDA 2022 challenge on vestibular schwannoma (VS) segmentation. In this context, we propose a VS segmentation method that leverages conventional image-to-image translation and segmentation using iterative self training combined to a dedicated data augmentation technique called Generative Blending Augmentation (GBA). GBA is based on a one-shot 2D SinGAN generative model that allows to realistically diversify target tumor appearances in a downstream segmentation model, improving its generalization power at test time. Our solution ranked first on the VS segmentation task during the validation and test phase of the CrossModa 2022 challenge.
Can AI Put Gamma-Ray Astrophysicists Out of a Job?
Apr 04, 2023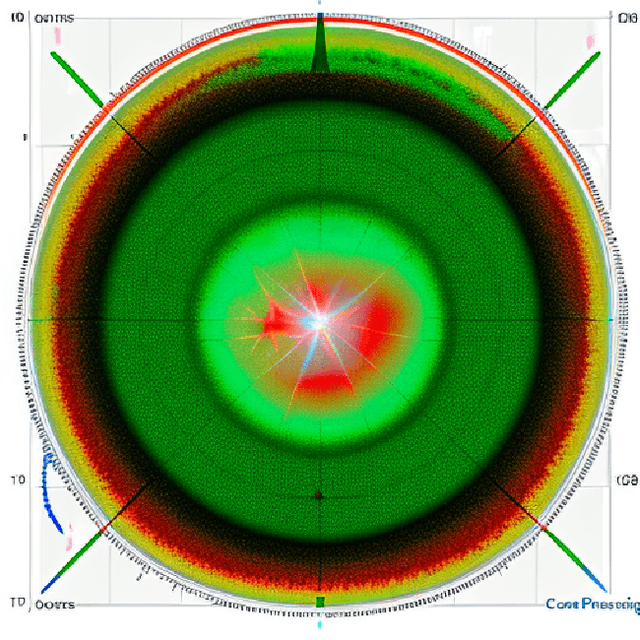
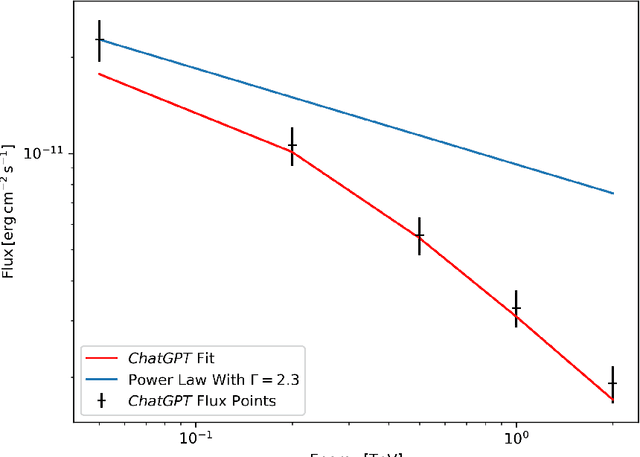
In what will likely be a litany of generative-model-themed arXiv submissions celebrating April the 1st, we evaluate the capacity of state-of-the-art transformer models to create a paper detailing the detection of a Pulsar Wind Nebula with a non-existent Imaging Atmospheric Cherenkov Telescope (IACT) Array. We do this to evaluate the ability of such models to interpret astronomical observations and sources based on language information alone, and to assess potential means by which fraudulently generated scientific papers could be identified during peer review (given that reliable generative model watermarking has yet to be deployed for these tools). We conclude that our jobs as astronomers are safe for the time being. From this point on, prompts given to ChatGPT and Stable Diffusion are shown in orange, text generated by ChatGPT is shown in black, whereas analysis by the (human) authors is in blue.
Deep Learning for Automated Experimentation in Scanning Transmission Electron Microscopy
Apr 04, 2023
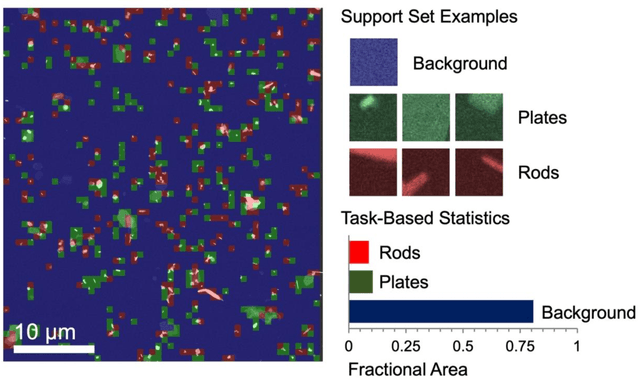
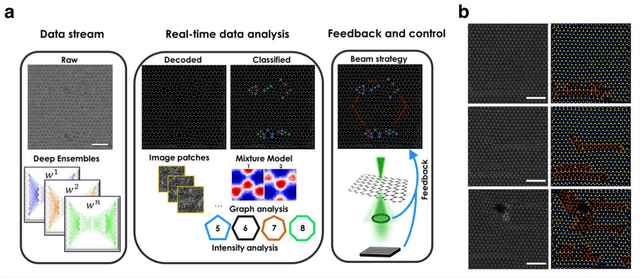
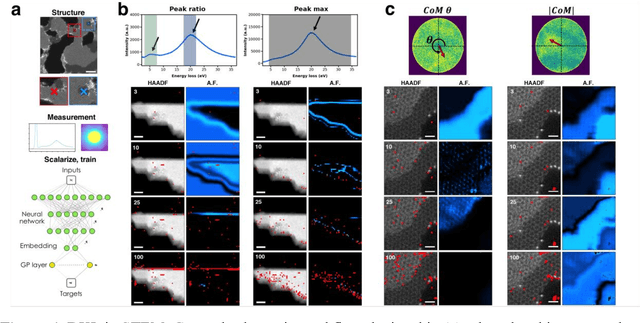
Machine learning (ML) has become critical for post-acquisition data analysis in (scanning) transmission electron microscopy, (S)TEM, imaging and spectroscopy. An emerging trend is the transition to real-time analysis and closed-loop microscope operation. The effective use of ML in electron microscopy now requires the development of strategies for microscopy-centered experiment workflow design and optimization. Here, we discuss the associated challenges with the transition to active ML, including sequential data analysis and out-of-distribution drift effects, the requirements for the edge operation, local and cloud data storage, and theory in the loop operations. Specifically, we discuss the relative contributions of human scientists and ML agents in the ideation, orchestration, and execution of experimental workflows and the need to develop universal hyper languages that can apply across multiple platforms. These considerations will collectively inform the operationalization of ML in next-generation experimentation.