 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Meaningful human command: Advance control directives as a method to enable moral and legal responsibility for autonomous weapons systems
Mar 14, 2023

21st Century war is increasing in speed, with conventional forces combined with massed use of autonomous systems and human-machine integration. However, a significant challenge is how humans can ensure moral and legal responsibility for systems operating outside of normal temporal parameters. This chapter considers whether humans can stand outside of real time and authorise actions for autonomous systems by the prior establishment of a contract, for actions to occur in a future context particularly in faster than real time or in very slow operations where human consciousness and concentration could not remain well informed. The medical legal precdent found in 'advance care directives' suggests how the time-consuming, deliberative process required for accountability and responsibility of weapons systems may be achievable outside real time captured in an 'advance control driective' (ACD). The chapter proposes 'autonomy command' scaffolded and legitimised through the construction of ACD ahead of the deployment of autonomous systems.
Dual-Attention Deep Reinforcement Learning for Multi-MAP 3D Trajectory Optimization in Dynamic 5G Networks
Mar 14, 2023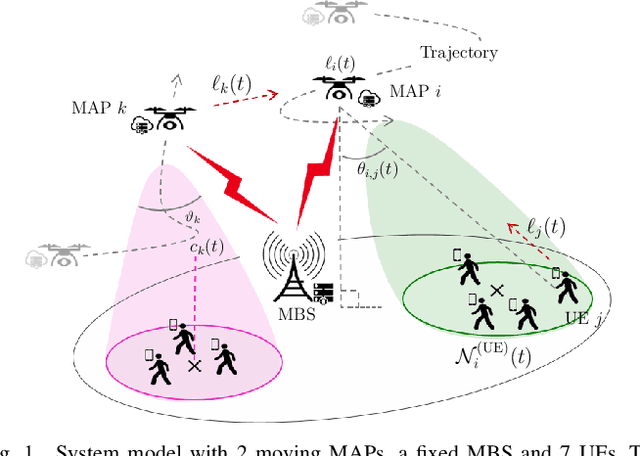
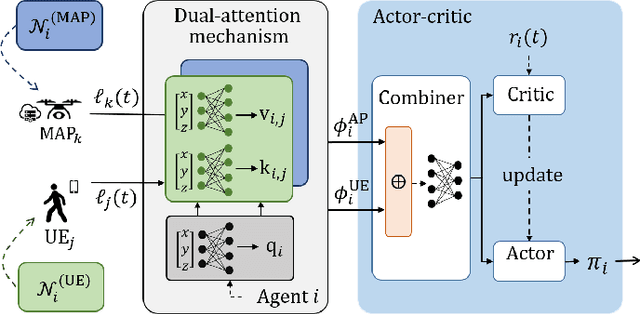
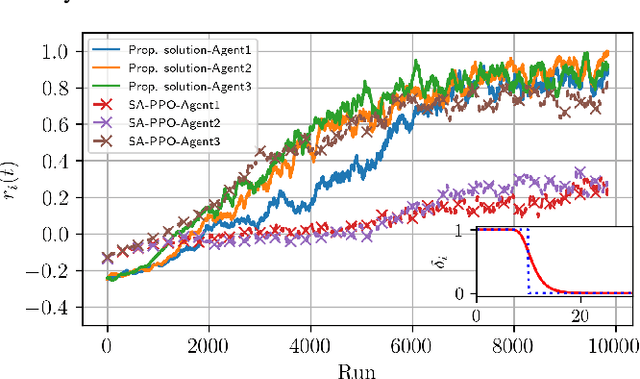
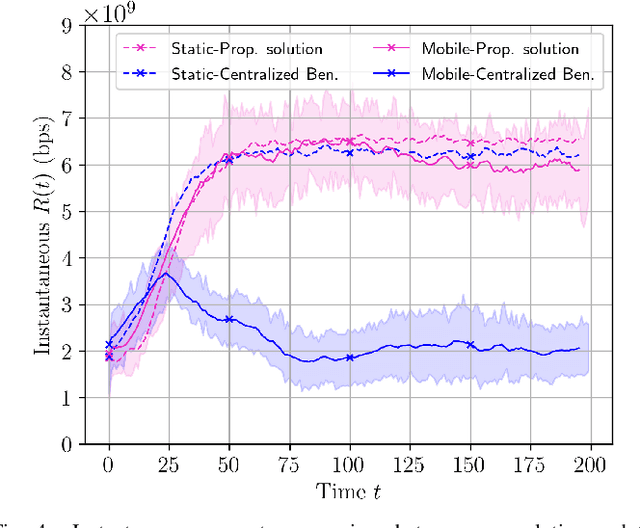
5G and beyond networks need to provide dynamic and efficient infrastructure management to better adapt to time-varying user behaviors (e.g., user mobility, interference, user traffic and evolution of the network topology). In this paper, we propose to manage the trajectory of Mobile Access Points (MAPs) under all these dynamic constraints with reduced complexity. We first formulate the placement problem to manage MAPs over time. Our solution addresses time-varying user traffic and user mobility through a Multi-Agent Deep Reinforcement Learning (MADRL). To achieve real-time behavior, the proposed solution learns to perform distributed assignment of MAP-user positions and schedules the MAP path among all users without centralized user's clustering feedback. Our solution exploits a dual-attention MADRL model via proximal policy optimization to dynamically move MAPs in 3D. The dual-attention takes into account information from both users and MAPs. The cooperation mechanism of our solution allows to manage different scenarios, without a priory information and without re-training, which significantly reduces complexity.
SmartBook: AI-Assisted Situation Report Generation
Mar 28, 2023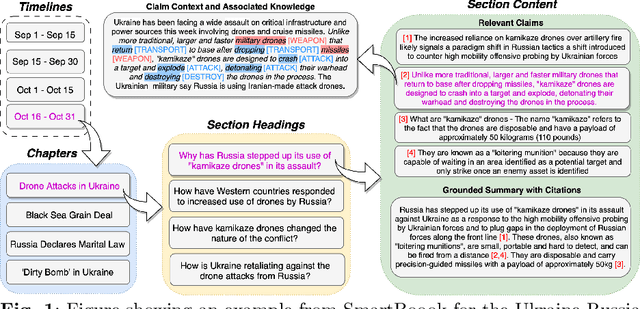
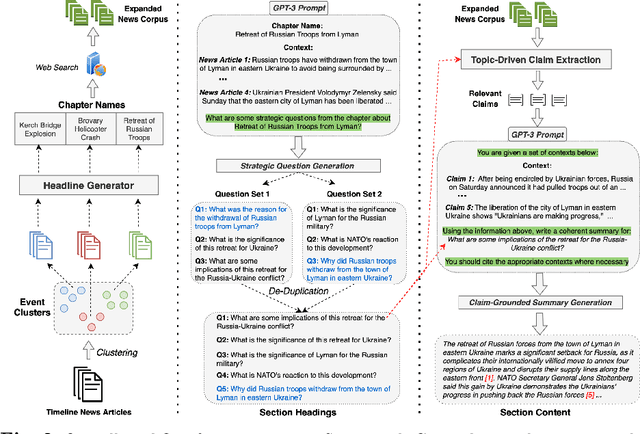


Emerging events, such as the COVID pandemic and the Ukraine Crisis, require a time-sensitive comprehensive understanding of the situation to allow for appropriate decision-making and effective action response. Automated generation of situation reports can significantly reduce the time, effort, and cost for domain experts when preparing their official human-curated reports. However, AI research toward this goal has been very limited, and no successful trials have yet been conducted to automate such report generation. We propose SmartBook, a novel task formulation targeting situation report generation, which consumes large volumes of news data to produce a structured situation report with multiple hypotheses (claims) summarized and grounded with rich links to factual evidence. We realize SmartBook for the Ukraine-Russia crisis by automatically generating intelligence analysis reports to assist expert analysts. The machine-generated reports are structured in the form of timelines, with each timeline organized by major events (or chapters), corresponding strategic questions (or sections) and their grounded summaries (or section content). Our proposed framework automatically detects real-time event-related strategic questions, which are more directed than manually-crafted analyst questions, which tend to be too complex, hard to parse, vague and high-level. Results from thorough qualitative evaluations show that roughly 82% of the questions in Smartbook have strategic importance, with at least 93% of the sections in the report being tactically useful. Further, experiments show that expert analysts tend to add more information into the SmartBook reports, with only 2.3% of the existing tokens being deleted, meaning SmartBook can serve as a useful foundation for analysts to build upon when creating intelligence reports.
Interacting Particle Langevin Algorithm for Maximum Marginal Likelihood Estimation
Mar 23, 2023We study a class of interacting particle systems for implementing a marginal maximum likelihood estimation (MLE) procedure to optimize over the parameters of a latent variable model. To do so, we propose a continuous-time interacting particle system which can be seen as a Langevin diffusion over an extended state space, where the number of particles acts as the inverse temperature parameter in classical settings for optimisation. Using Langevin diffusions, we prove nonasymptotic concentration bounds for the optimisation error of the maximum marginal likelihood estimator in terms of the number of particles in the particle system, the number of iterations of the algorithm, and the step-size parameter for the time discretisation analysis.
Real-Time Physics-Based Object Pose Tracking during Non-Prehensile Manipulation
Nov 24, 2022

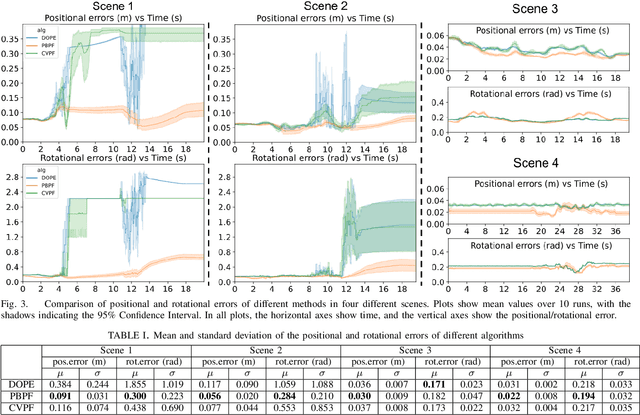
We propose a method to track the 6D pose of an object over time, while the object is under non-prehensile manipulation by a robot. At any given time during the manipulation of the object, we assume access to the robot joint controls and an image from a camera looking at the scene. We use the robot joint controls to perform a physics-based prediction of how the object might be moving. We then combine this prediction with the observation coming from the camera, to estimate the object pose as accurately as possible. We use a particle filtering approach to combine the control information with the visual information. We compare the proposed method with two baselines: (i) using only an image-based pose estimation system at each time-step, and (ii) a particle filter which does not perform the computationally expensive physics predictions, but assumes the object moves with constant velocity. Our results show that making physics-based predictions is worth the computational cost, resulting in more accurate tracking, and estimating object pose even when the object is not clearly visible to the camera.
Learning Situation Hyper-Graphs for Video Question Answering
Apr 18, 2023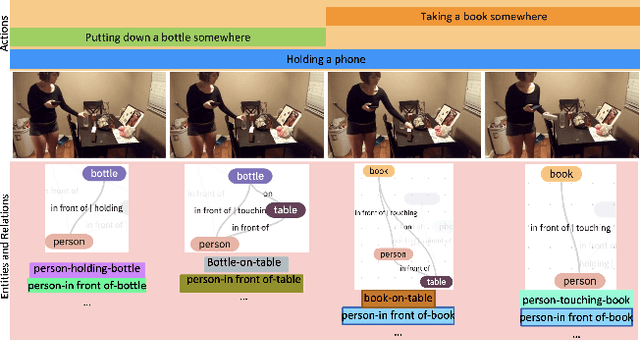

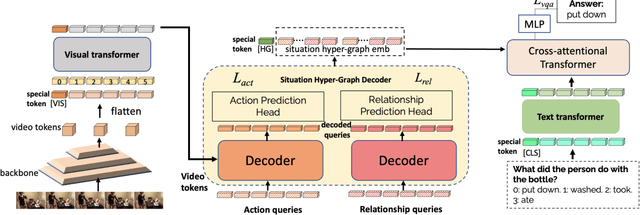

Answering questions about complex situations in videos requires not only capturing the presence of actors, objects, and their relations but also the evolution of these relationships over time. A situation hyper-graph is a representation that describes situations as scene sub-graphs for video frames and hyper-edges for connected sub-graphs and has been proposed to capture all such information in a compact structured form. In this work, we propose an architecture for Video Question Answering (VQA) that enables answering questions related to video content by predicting situation hyper-graphs, coined Situation Hyper-Graph based Video Question Answering (SHG-VQA). To this end, we train a situation hyper-graph decoder to implicitly identify graph representations with actions and object/human-object relationships from the input video clip. and to use cross-attention between the predicted situation hyper-graphs and the question embedding to predict the correct answer. The proposed method is trained in an end-to-end manner and optimized by a VQA loss with the cross-entropy function and a Hungarian matching loss for the situation graph prediction. The effectiveness of the proposed architecture is extensively evaluated on two challenging benchmarks: AGQA and STAR. Our results show that learning the underlying situation hyper-graphs helps the system to significantly improve its performance for novel challenges of video question-answering tasks.
Dealing With Heterogeneous 3D MR Knee Images: A Federated Few-Shot Learning Method With Dual Knowledge Distillation
Apr 18, 2023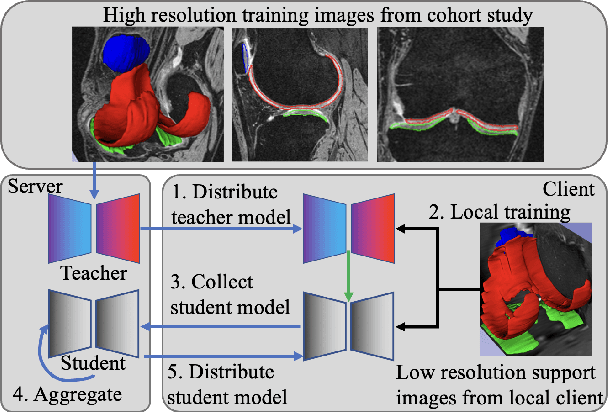

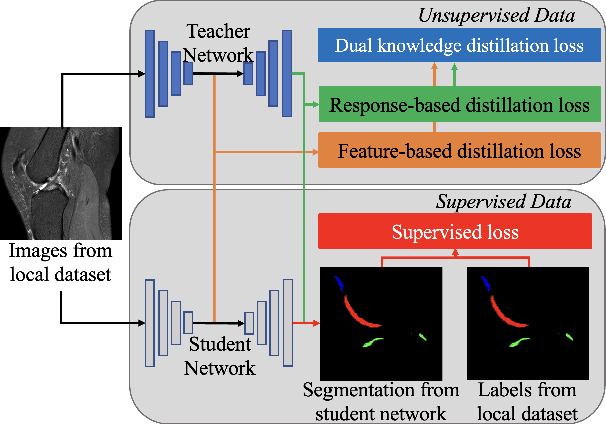
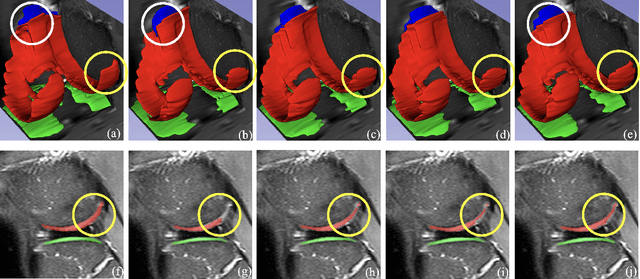
Federated Learning has gained popularity among medical institutions since it enables collaborative training between clients (e.g., hospitals) without aggregating data. However, due to the high cost associated with creating annotations, especially for large 3D image datasets, clinical institutions do not have enough supervised data for training locally. Thus, the performance of the collaborative model is subpar under limited supervision. On the other hand, large institutions have the resources to compile data repositories with high-resolution images and labels. Therefore, individual clients can utilize the knowledge acquired in the public data repositories to mitigate the shortage of private annotated images. In this paper, we propose a federated few-shot learning method with dual knowledge distillation. This method allows joint training with limited annotations across clients without jeopardizing privacy. The supervised learning of the proposed method extracts features from limited labeled data in each client, while the unsupervised data is used to distill both feature and response-based knowledge from a national data repository to further improve the accuracy of the collaborative model and reduce the communication cost. Extensive evaluations are conducted on 3D magnetic resonance knee images from a private clinical dataset. Our proposed method shows superior performance and less training time than other semi-supervised federated learning methods. Codes and additional visualization results are available at https://github.com/hexiaoxiao-cs/fedml-knee.
Event Camera and LiDAR based Human Tracking for Adverse Lighting Conditions in Subterranean Environments
Apr 18, 2023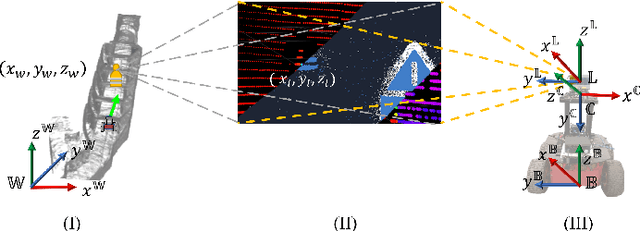



In this article, we propose a novel LiDAR and event camera fusion modality for subterranean (SubT) environments for fast and precise object and human detection in a wide variety of adverse lighting conditions, such as low or no light, high-contrast zones and in the presence of blinding light sources. In the proposed approach, information from the event camera and LiDAR are fused to localize a human or an object-of-interest in a robot's local frame. The local detection is then transformed into the inertial frame and used to set references for a Nonlinear Model Predictive Controller (NMPC) for reactive tracking of humans or objects in SubT environments. The proposed novel fusion uses intensity filtering and K-means clustering on the LiDAR point cloud and frequency filtering and connectivity clustering on the events induced in an event camera by the returning LiDAR beams. The centroids of the clusters in the event camera and LiDAR streams are then paired to localize reflective markers present on safety vests and signs in SubT environments. The efficacy of the proposed scheme has been experimentally validated in a real SubT environment (a mine) with a Pioneer 3AT mobile robot. The experimental results show real-time performance for human detection and the NMPC-based controller allows for reactive tracking of a human or object of interest, even in complete darkness.
Automated Formation Control Synthesis from Temporal Logic Specifications
Apr 01, 2023
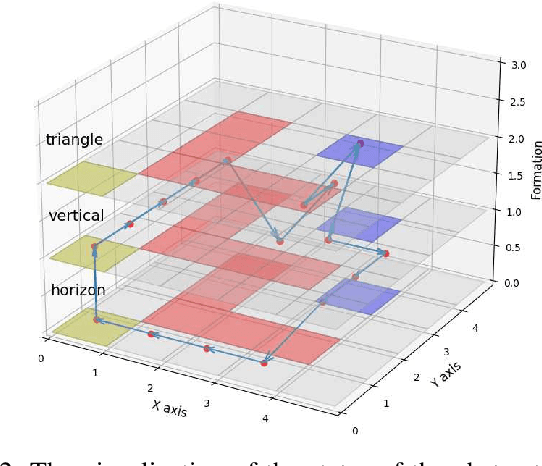
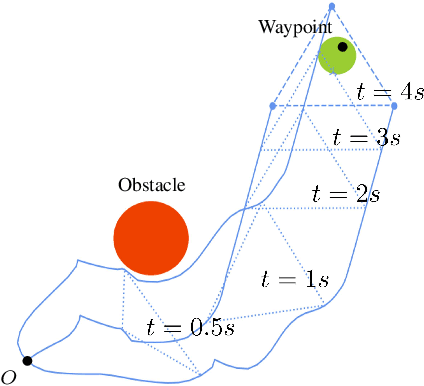
In this paper, we propose a novel framework using formal methods to synthesize a navigation control strategy for a multi-robot swarm system with automated formation. The main objective of the problem is to navigate the robot swarm toward a goal position while passing a series of waypoints. The formation of the robot swarm should be changed according to the terrain restrictions around the corresponding waypoint. Also, the motion of the robots should always satisfy certain runtime safety requirements, such as avoiding collision with other robots and obstacles. We prescribe the desired waypoints and formation for the robot swarm using a temporal logic (TL) specification. Then, we formulate the transition of the waypoints and the formation as a deterministic finite transition system (DFTS) and synthesize a control strategy subject to the TL specification. Meanwhile, the runtime safety requirements are encoded using control barrier functions, and fixed-time control Lyapunov functions ensure fixed-time convergence. A quadratic program (QP) problem is solved to refine the DFTS control strategy to generate the control inputs for the robots, such that both TL specifications and runtime safety requirements are satisfied simultaneously. This work enlights a novel solution for multi-robot systems with complicated task specifications. The efficacy of the proposed framework is validated with a simulation study.
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
Dec 01, 2022
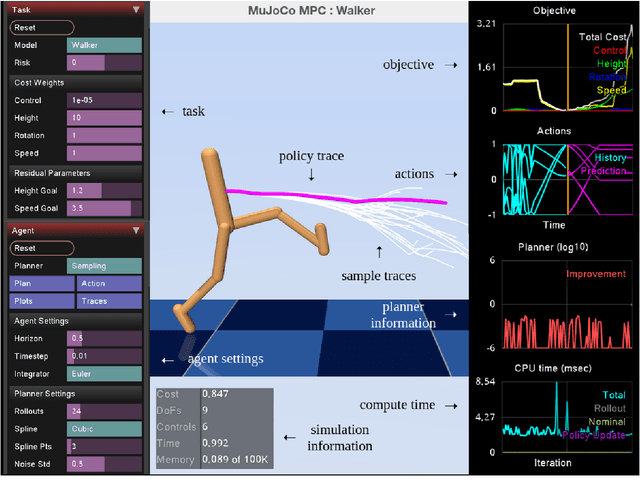
We introduce MuJoCo MPC (MJPC), an open-source, interactive application and software framework for real-time predictive control, based on MuJoCo physics. MJPC allows the user to easily author and solve complex robotics tasks, and currently supports three shooting-based planners: derivative-based iLQG and Gradient Descent, and a simple derivative-free method we call Predictive Sampling. Predictive Sampling was designed as an elementary baseline, mostly for its pedagogical value, but turned out to be surprisingly competitive with the more established algorithms. This work does not present algorithmic advances, and instead, prioritises performant algorithms, simple code, and accessibility of model-based methods via intuitive and interactive software. MJPC is available at: github.com/deepmind/mujoco_mpc, a video summary can be viewed at: dpmd.ai/mjpc.