 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Decentralized federated learning methods for reducing communication cost and energy consumption in UAV networks
Apr 13, 2023
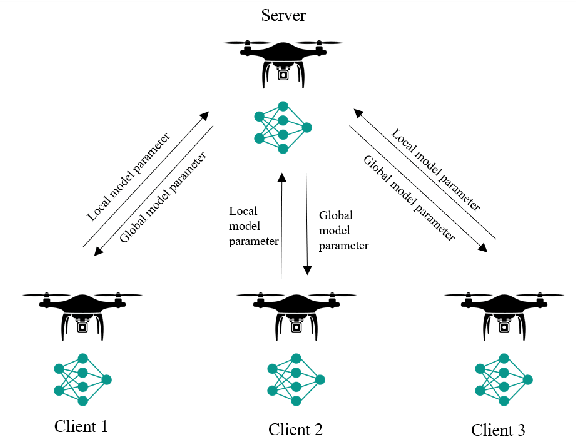
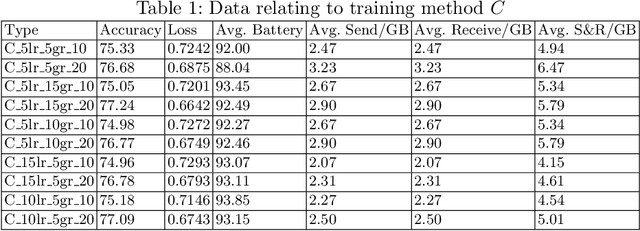
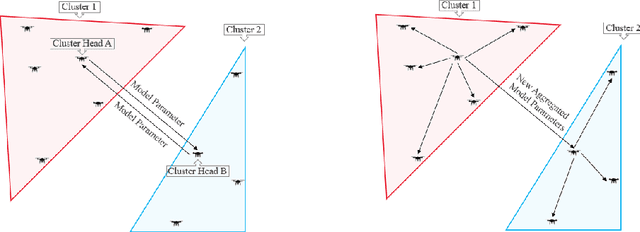
Unmanned aerial vehicles (UAV) or drones play many roles in a modern smart city such as the delivery of goods, mapping real-time road traffic and monitoring pollution. The ability of drones to perform these functions often requires the support of machine learning technology. However, traditional machine learning models for drones encounter data privacy problems, communication costs and energy limitations. Federated Learning, an emerging distributed machine learning approach, is an excellent solution to address these issues. Federated learning (FL) allows drones to train local models without transmitting raw data. However, existing FL requires a central server to aggregate the trained model parameters of the UAV. A failure of the central server can significantly impact the overall training. In this paper, we propose two aggregation methods: Commutative FL and Alternate FL, based on the existing architecture of decentralised Federated Learning for UAV Networks (DFL-UN) by adding a unique aggregation method of decentralised FL. Those two methods can effectively control energy consumption and communication cost by controlling the number of local training epochs, local communication, and global communication. The simulation results of the proposed training methods are also presented to verify the feasibility and efficiency of the architecture compared with two benchmark methods (e.g. standard machine learning training and standard single aggregation server training). The simulation results show that the proposed methods outperform the benchmark methods in terms of operational stability, energy consumption and communication cost.
Sequential Monte Carlo applied to virtual flow meter calibration
Apr 13, 2023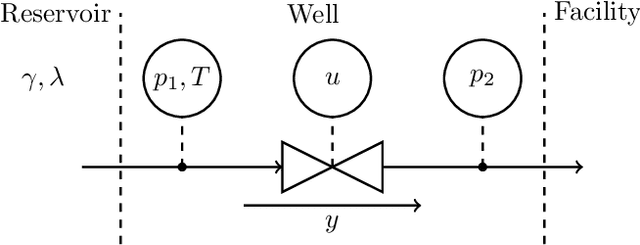
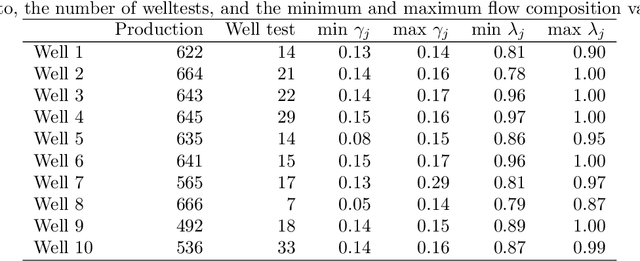
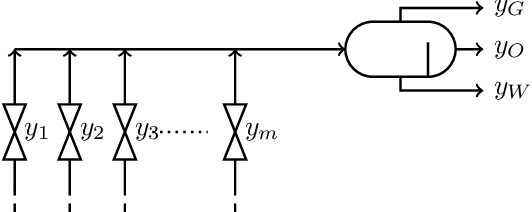
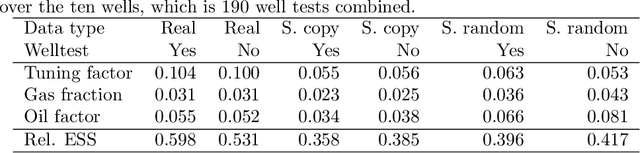
Soft-sensors are gaining popularity due to their ability to provide estimates of key process variables with little intervention required on the asset and at a low cost. In oil and gas production, virtual flow metering (VFM) is a popular soft-sensor that attempts to estimate multiphase flow rates in real time. VFMs are based on models, and these models require calibration. The calibration is highly dependent on the application, both due to the great diversity of the models, and in the available measurements. The most accurate calibration is achieved by careful tuning of the VFM parameters to well tests, but this can be work intensive, and not all wells have frequent well test data available. This paper presents a calibration method based on the measurement provided by the production separator, and the assumption that the observed flow should be equal to the sum of flow rates from each individual well. This allows us to jointly calibrate the VFMs continuously. The method applies Sequential Monte Carlo (SMC) to infer a tuning factor and the flow composition for each well. The method is tested on a case with ten wells, using both synthetic and real data. The results are promising and the method is able to provide reasonable estimates of the parameters without relying on well tests. However, some challenges are identified and discussed, particularly related to the process noise and how to manage varying data quality.
Improving Accuracy Without Losing Interpretability: A ML Approach for Time Series Forecasting
Dec 13, 2022
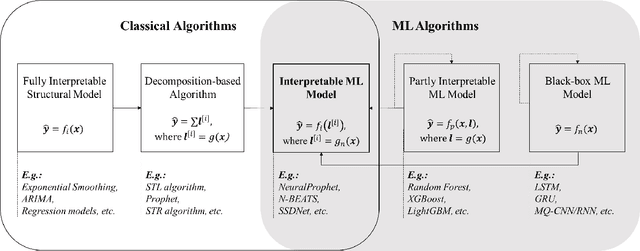
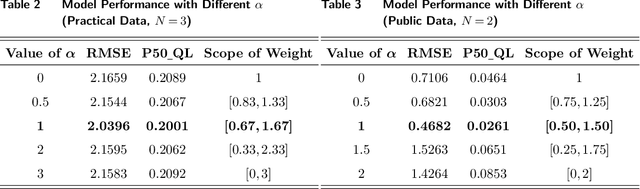
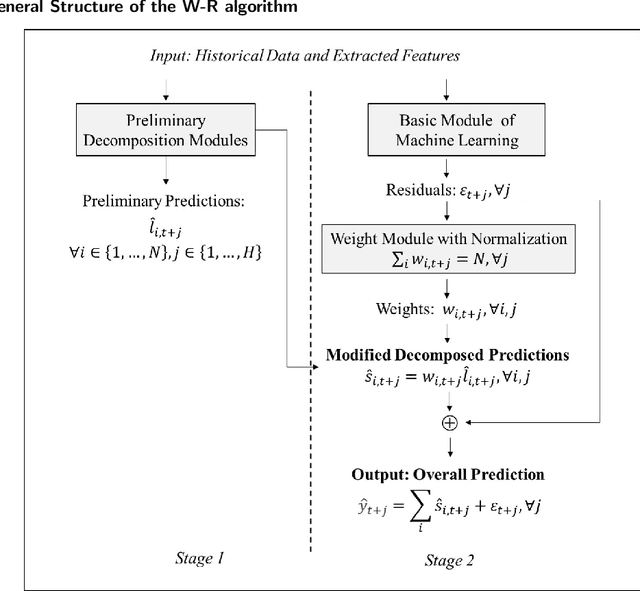
In time series forecasting, decomposition-based algorithms break aggregate data into meaningful components and are therefore appreciated for their particular advantages in interpretability. Recent algorithms often combine machine learning (hereafter ML) methodology with decomposition to improve prediction accuracy. However, incorporating ML is generally considered to sacrifice interpretability inevitably. In addition, existing hybrid algorithms usually rely on theoretical models with statistical assumptions and focus only on the accuracy of aggregate predictions, and thus suffer from accuracy problems, especially in component estimates. In response to the above issues, this research explores the possibility of improving accuracy without losing interpretability in time series forecasting. We first quantitatively define interpretability for data-driven forecasts and systematically review the existing forecasting algorithms from the perspective of interpretability. Accordingly, we propose the W-R algorithm, a hybrid algorithm that combines decomposition and ML from a novel perspective. Specifically, the W-R algorithm replaces the standard additive combination function with a weighted variant and uses ML to modify the estimates of all components simultaneously. We mathematically analyze the theoretical basis of the algorithm and validate its performance through extensive numerical experiments. In general, the W-R algorithm outperforms all decomposition-based and ML benchmarks. Based on P50_QL, the algorithm relatively improves by 8.76% in accuracy on the practical sales forecasts of JD.com and 77.99% on a public dataset of electricity loads. This research offers an innovative perspective to combine the statistical and ML algorithms, and JD.com has implemented the W-R algorithm to make accurate sales predictions and guide its marketing activities.
A deep learning Attention model to solve the Vehicle Routing Problem and the Pick-up and Delivery Problem with Time Windows
Dec 20, 2022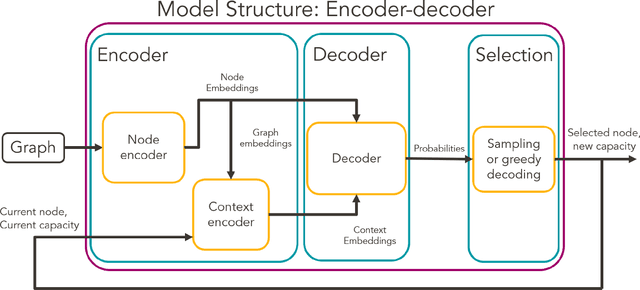
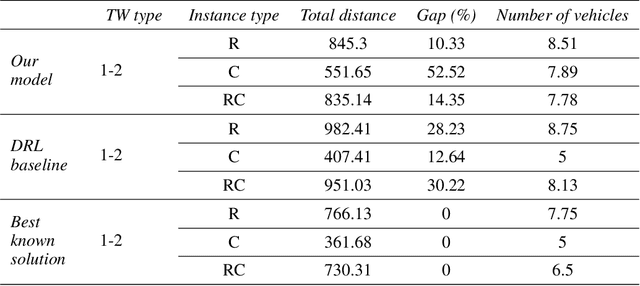
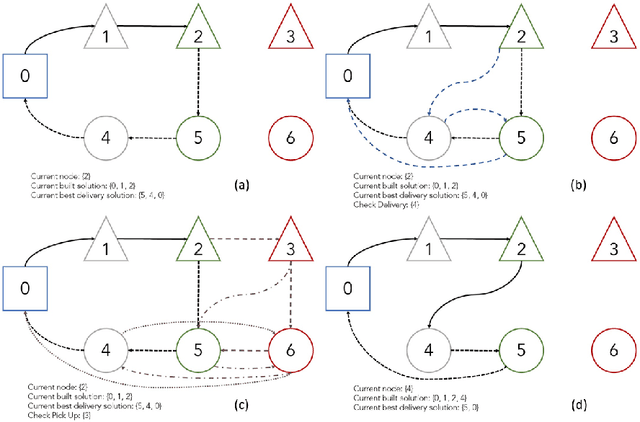
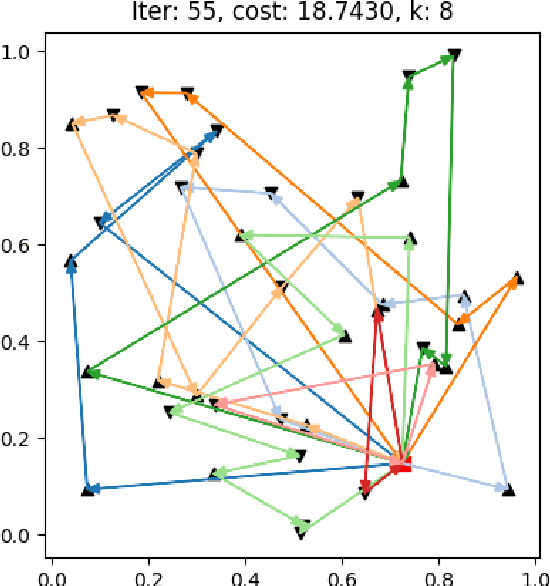
SNCF, the French public train company, is experimenting to develop new types of transportation services by tackling vehicle routing problems. While many deep learning models have been used to tackle efficiently vehicle routing problems, it is difficult to take into account time related constraints. In this paper, we solve the Capacitated Vehicle Routing Problem with Time Windows (CVRPTW) and the Capacitated Pickup and Delivery Problem with Time Windows (CPDPTW) with a constructive iterative Deep Learning algorithm. We use an Attention Encoder-Decoder structure and design a novel insertion heuristic for the feasibility check of the CPDPTW. Our models yields results that are better than best known learning solutions on the CVRPTW. We show the feasibility of deep learning techniques for solving the CPDPTW but witness the limitations of our iterative approach in terms of computational complexity.
A Note on "Efficient Task-Specific Data Valuation for Nearest Neighbor Algorithms"
Apr 09, 2023

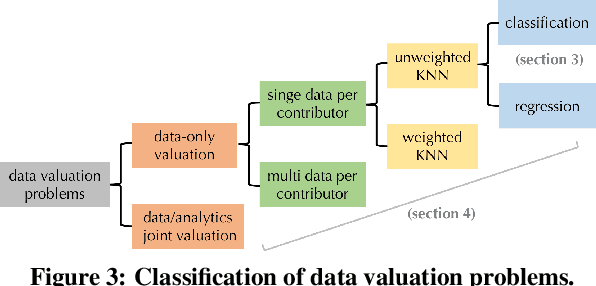

Data valuation is a growing research field that studies the influence of individual data points for machine learning (ML) models. Data Shapley, inspired by cooperative game theory and economics, is an effective method for data valuation. However, it is well-known that the Shapley value (SV) can be computationally expensive. Fortunately, Jia et al. (2019) showed that for K-Nearest Neighbors (KNN) models, the computation of Data Shapley is surprisingly simple and efficient. In this note, we revisit the work of Jia et al. (2019) and propose a more natural and interpretable utility function that better reflects the performance of KNN models. We derive the corresponding calculation procedure for the Data Shapley of KNN classifiers/regressors with the new utility functions. Our new approach, dubbed soft-label KNN-SV, achieves the same time complexity as the original method. We further provide an efficient approximation algorithm for soft-label KNN-SV based on locality sensitive hashing (LSH). Our experimental results demonstrate that Soft-label KNN-SV outperforms the original method on most datasets in the task of mislabeled data detection, making it a better baseline for future work on data valuation.
REFINER: Reasoning Feedback on Intermediate Representations
Apr 04, 2023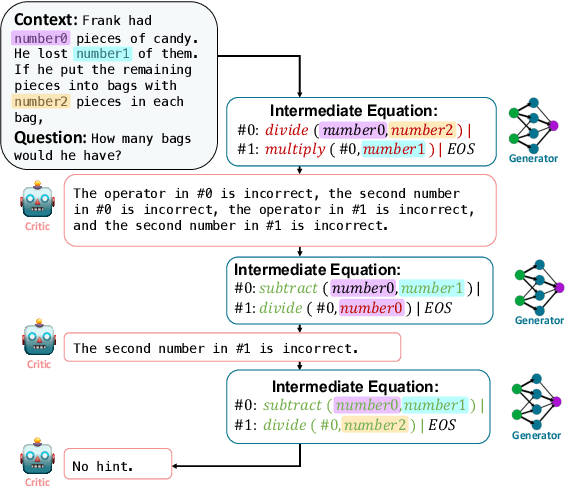
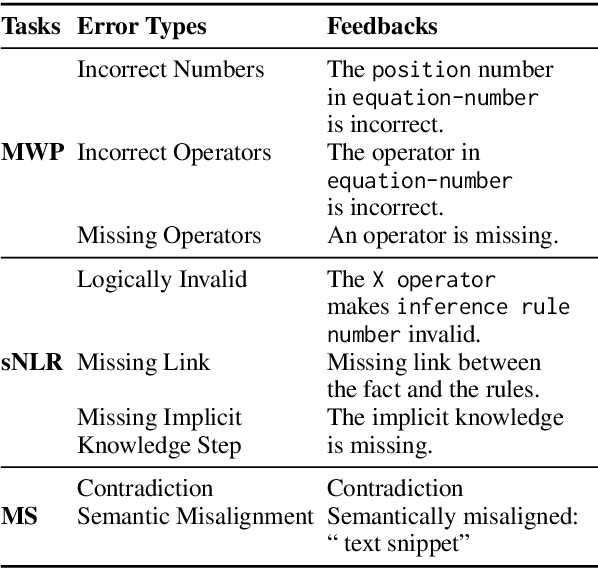
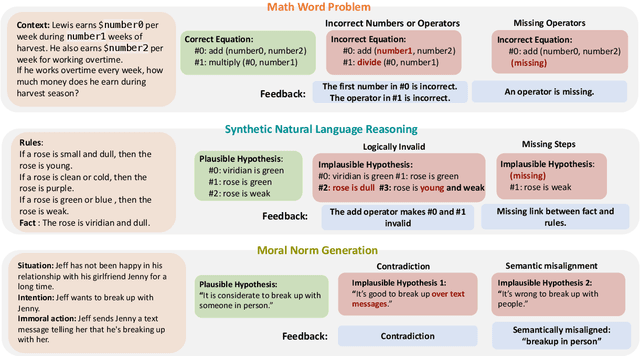
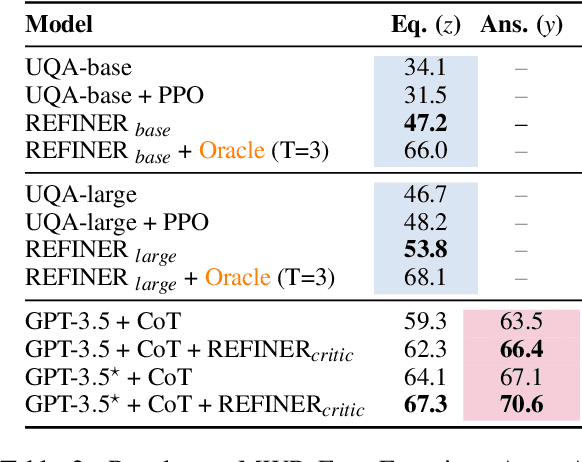
Language models (LMs) have recently shown remarkable performance on reasoning tasks by explicitly generating intermediate inferences, e.g., chain-of-thought prompting. However, these intermediate inference steps may be inappropriate deductions from the initial context and lead to incorrect final predictions. Here we introduce REFINER, a framework for finetuning LMs to explicitly generate intermediate reasoning steps while interacting with a critic model that provides automated feedback on the reasoning. Specifically, the critic provides structured feedback that the reasoning LM uses to iteratively improve its intermediate arguments. Empirical evaluations of REFINER on three diverse reasoning tasks show significant improvements over baseline LMs of comparable scale. Furthermore, when using GPT3.5 as the reasoner, the trained critic significantly improves reasoning without finetuning the reasoner. Finally, our critic model is trained without expensive human-in-the-loop data but can be substituted with humans at inference time.
Multimodal Neural Processes for Uncertainty Estimation
Apr 04, 2023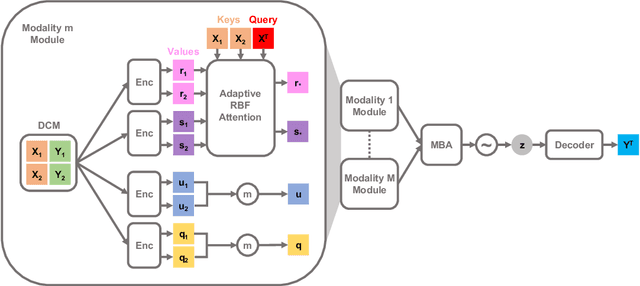
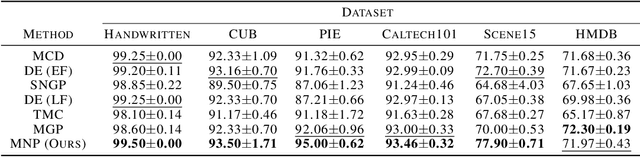
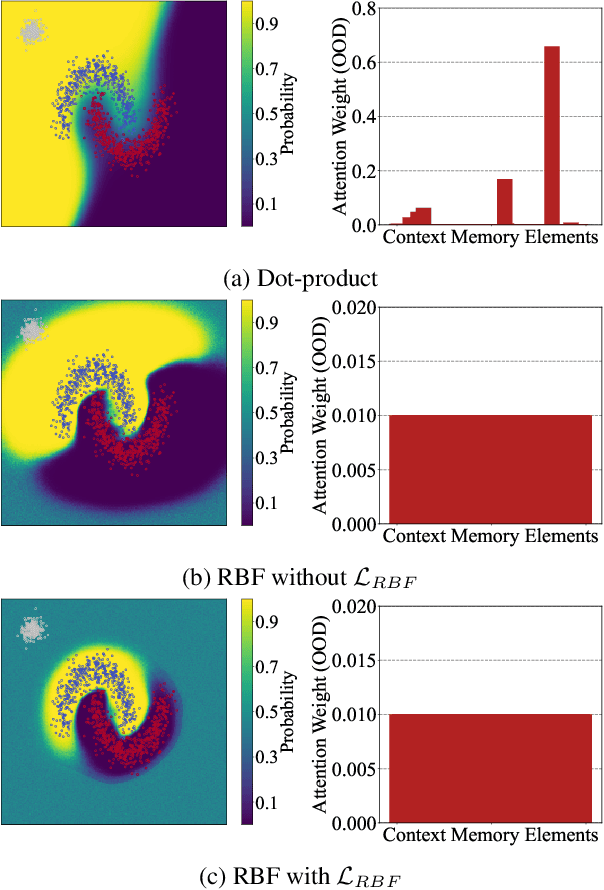
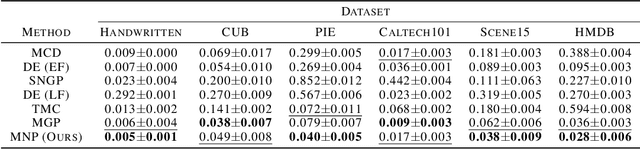
Neural processes (NPs) have brought the representation power of parametric deep neural networks and the reliable uncertainty estimation of non-parametric Gaussian processes together. Although recent development of NPs has shown success in both regression and classification, how to adapt NPs to multimodal data has not be carefully studied. For the first time, we propose a new model of NP family for multimodal uncertainty estimation, namely Multimodal Neural Processes. In a holistic and principled way, we develop a dynamic context memory updated by the classification error, a multimodal Bayesian aggregation mechanism to aggregate multimodal representations, and a new attention mechanism for calibrated predictions. In extensive empirical evaluation, our method achieves the state-of-the-art multimodal uncertainty estimation performance, showing its appealing ability of being robust against noisy samples and reliable in out-of-domain detection.
Predicting Short Term Energy Demand in Smart Grid: A Deep Learning Approach for Integrating Renewable Energy Sources in Line with SDGs 7, 9, and 13
Apr 14, 2023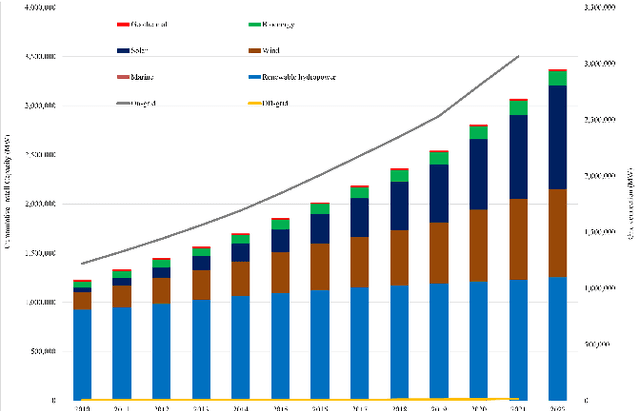
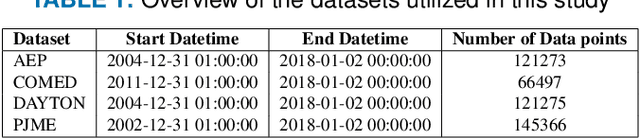
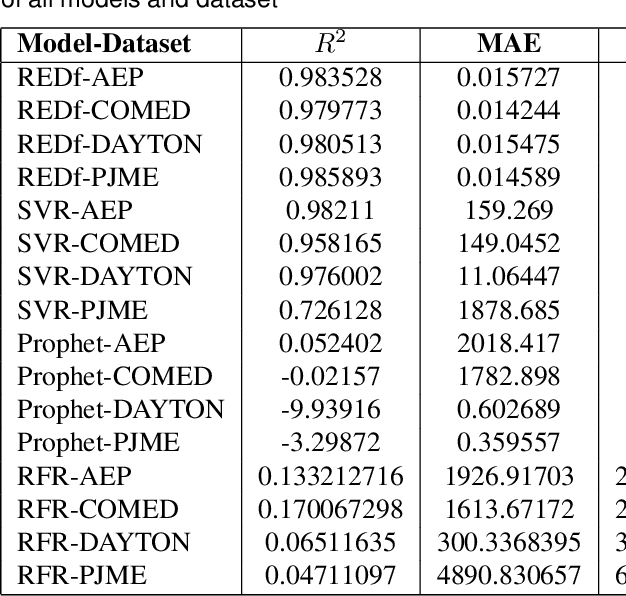
The integration of renewable energy sources into the power grid is becoming increasingly important as the world moves towards a more sustainable energy future in line with SDG 7. However, the intermittent nature of renewable energy sources can make it challenging to manage the power grid and ensure a stable supply of electricity, which is crucial for achieving SDG 9. In this paper, we propose a deep learning-based approach for predicting energy demand in a smart power grid, which can improve the integration of renewable energy sources by providing accurate predictions of energy demand. Our approach aligns with SDG 13 on climate action as it enables more efficient management of renewable energy resources. We use long short-term memory networks, which are well-suited for time series data, to capture complex patterns and dependencies in energy demand data. The proposed approach is evaluated using four datasets of historical short term energy demand data from different energy distribution companies including American Electric Power, Commonwealth Edison, Dayton Power and Light, and Pennsylvania-New Jersey-Maryland Interconnection. The proposed model is also compared with three other state of the art forecasting algorithms namely, Facebook Prophet, Support Vector Regressor, and Random Forest Regressor. The experimental results show that the proposed REDf model can accurately predict energy demand with a mean absolute error of 1.4%, indicating its potential to enhance the stability and efficiency of the power grid and contribute to achieving SDGs 7, 9, and 13. The proposed model also have the potential to manage the integration of renewable energy sources in an effective manner.
CAD-RADS scoring of coronary CT angiography with Multi-Axis Vision Transformer: a clinically-inspired deep learning pipeline
Apr 14, 2023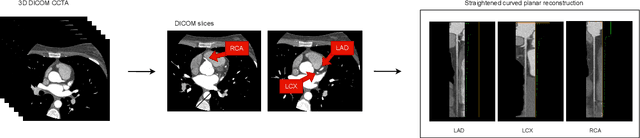

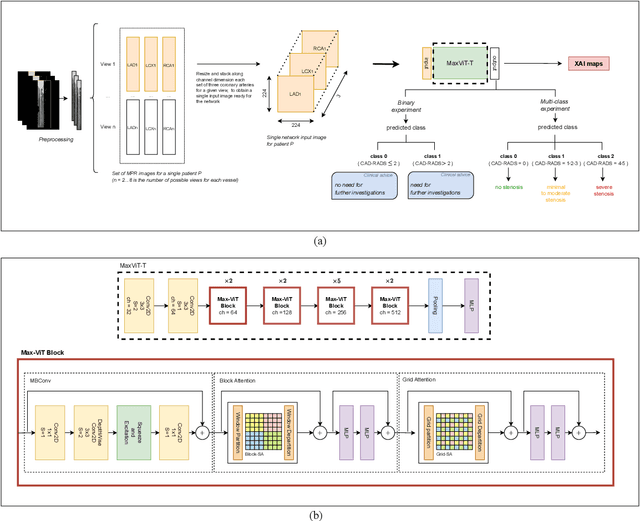
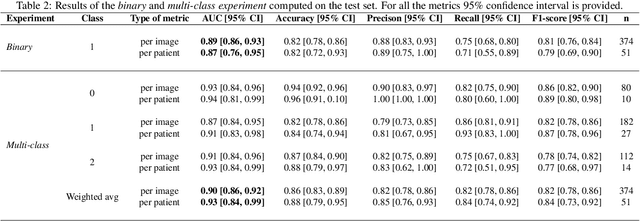
The standard non-invasive imaging technique used to assess the severity and extent of Coronary Artery Disease (CAD) is Coronary Computed Tomography Angiography (CCTA). However, manual grading of each patient's CCTA according to the CAD-Reporting and Data System (CAD-RADS) scoring is time-consuming and operator-dependent, especially in borderline cases. This work proposes a fully automated, and visually explainable, deep learning pipeline to be used as a decision support system for the CAD screening procedure. The pipeline performs two classification tasks: firstly, identifying patients who require further clinical investigations and secondly, classifying patients into subgroups based on the degree of stenosis, according to commonly used CAD-RADS thresholds. The pipeline pre-processes multiplanar projections of the coronary arteries, extracted from the original CCTAs, and classifies them using a fine-tuned Multi-Axis Vision Transformer architecture. With the aim of emulating the current clinical practice, the model is trained to assign a per-patient score by stacking the bi-dimensional longitudinal cross-sections of the three main coronary arteries along channel dimension. Furthermore, it generates visually interpretable maps to assess the reliability of the predictions. When run on a database of 1873 three-channel images of 253 patients collected at the Monzino Cardiology Center in Milan, the pipeline obtained an AUC of 0.87 and 0.93 for the two classification tasks, respectively. According to our knowledge, this is the first model trained to assign CAD-RADS scores learning solely from patient scores and not requiring finer imaging annotation steps that are not part of the clinical routine.
Unsupervised Learning Optical Flow in Multi-frame Dynamic Environment Using Temporal Dynamic Modeling
Apr 14, 2023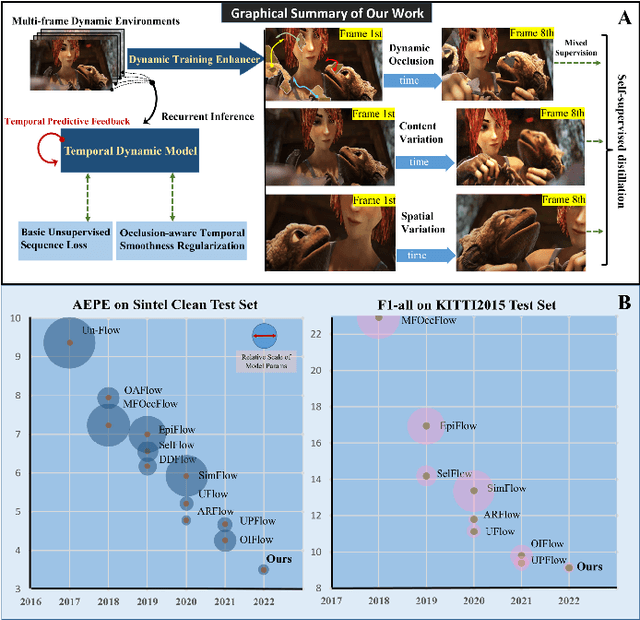
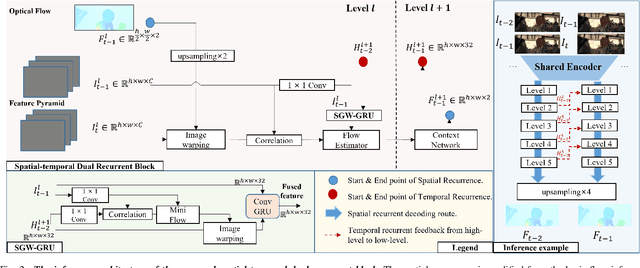
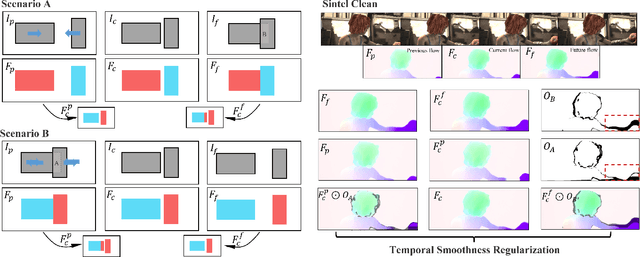
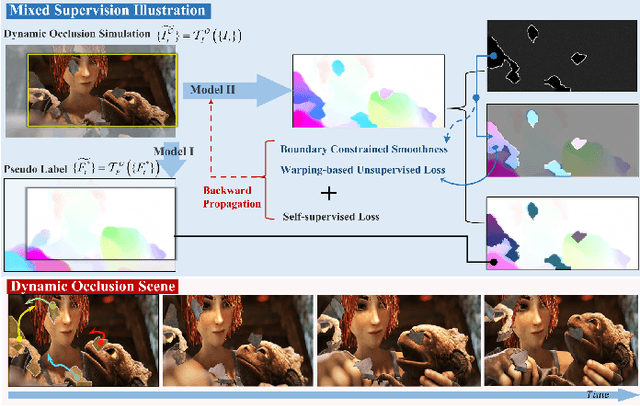
For visual estimation of optical flow, a crucial function for many vision tasks, unsupervised learning, using the supervision of view synthesis has emerged as a promising alternative to supervised methods, since ground-truth flow is not readily available in many cases. However, unsupervised learning is likely to be unstable when pixel tracking is lost due to occlusion and motion blur, or the pixel matching is impaired due to variation in image content and spatial structure over time. In natural environments, dynamic occlusion or object variation is a relatively slow temporal process spanning several frames. We, therefore, explore the optical flow estimation from multiple-frame sequences of dynamic scenes, whereas most of the existing unsupervised approaches are based on temporal static models. We handle the unsupervised optical flow estimation with a temporal dynamic model by introducing a spatial-temporal dual recurrent block based on the predictive coding structure, which feeds the previous high-level motion prior to the current optical flow estimator. Assuming temporal smoothness of optical flow, we use motion priors of the adjacent frames to provide more reliable supervision of the occluded regions. To grasp the essence of challenging scenes, we simulate various scenarios across long sequences, including dynamic occlusion, content variation, and spatial variation, and adopt self-supervised distillation to make the model understand the object's motion patterns in a prolonged dynamic environment. Experiments on KITTI 2012, KITTI 2015, Sintel Clean, and Sintel Final datasets demonstrate the effectiveness of our methods on unsupervised optical flow estimation. The proposal achieves state-of-the-art performance with advantages in memory overhead.